说明:文档围绕老师画的重点展开,但仍然需要过一遍PPT。考试题型:选择题、填空题、简答题、复杂分析题、一道应用题。
文章目录
- [第一讲 绪论](#第一讲 绪论)
- [第二讲 神经网络基础](#第二讲 神经网络基础)
- [第三讲 注意力机制](#第三讲 注意力机制)
第一讲 绪论
-
token、token化是什么?它和传统NLP中的分词有什么区别?token 词表是怎么产生的?注意一个token不一定等于一个词。
答:Token 是模型处理文本的最小单位,但它不一定对应一个"词"或一个"字"。Tokenization 是将原始文本字符串转换为整数索引序列的过程。原始文本: "Hello world!"
↓
Tokenizer 处理
↓
Token ID 序列: [15496, 995, 0] ← 每个整数对应词表中的一个条目
↓
模型输入(Embedding 层查找)
完整流程
文本 → 预处理(规范化、Unicode 处理)→ 切分 → 查词表 → Token IDs词表是从海量语料中统计学习出来的,不是人工编写的。高频组合被合并为独立 token,低频组合被拆分为子词,这是 BPE 等算法的核心智慧。
| 维度 | 传统 NLP 分词 | 现代 Tokenization(LLM) |
|---|---|---|
| 目标 | 语言学意义上的"正确切分" | 为神经网络提供高效、无歧义、可逆的表示 |
| 粒度 | 通常是词或字 | 子词(subword),动态决定 |
| OOV 问题 | 严重(未登录词无法处理) | 基本解决(任何词都能拆成子词) |
| 词表大小 | 几万到几十万 | 通常 32K~200K(如 GPT-4 约 100K) |
| 语言无关性 | 每种语言需要独立分词器 | 多语言统一处理 |
| 可逆性 | 分词后难以精确还原原文 | 必须可逆(detokenize 能还原原文) |
| 空格处理 | 通常忽略或特殊处理 | 空格本身可能是 token(如 GPT 用 Ġ 表示词前空格) |
- 神经网络语言模型(A neural probabilistic language model),三层,输入词的向量表示,输出是:当前输入下,最可能的下一个词。
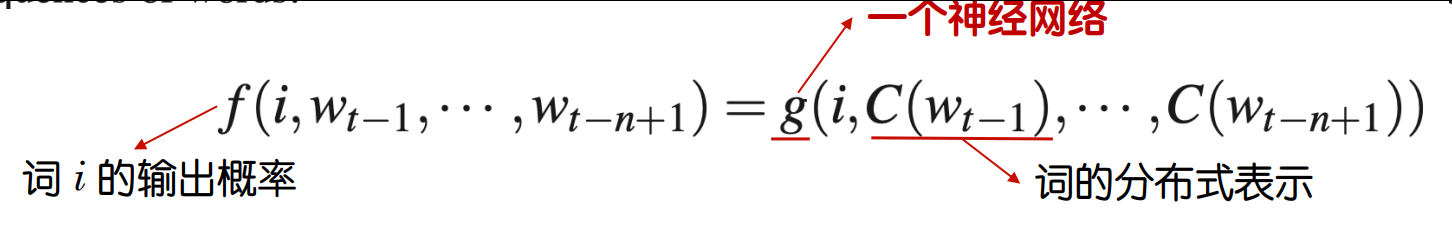
第二讲 神经网络基础
- 要会神经网络
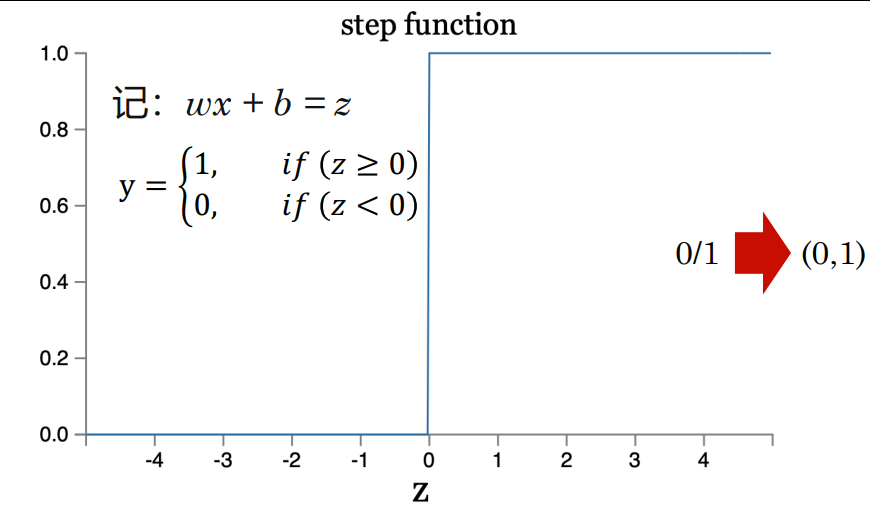
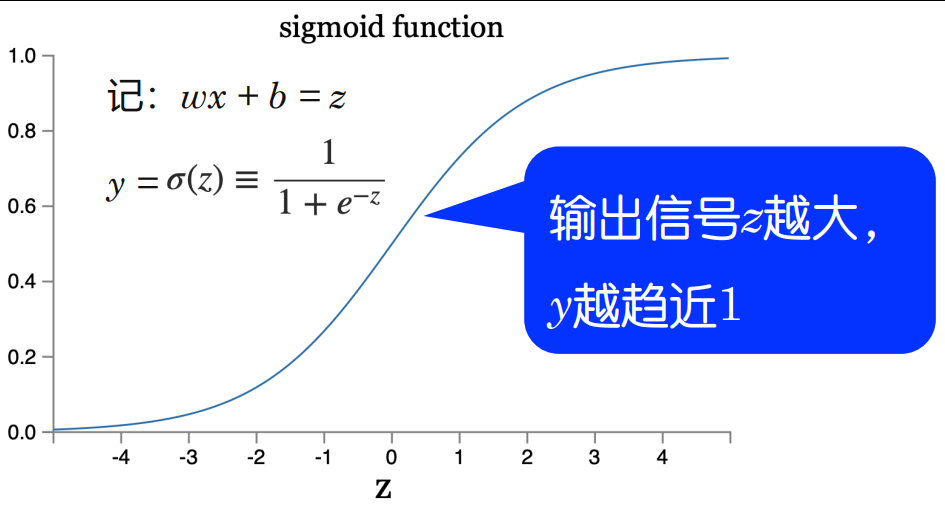
- 激活函数。非0即1的激活函数不便于反向传播,用sigmoid,sigmoid公式、曲线、有什么好处?
答:曲线见图,公式:
y = 1 1 + e − z w x + b = z y=\frac{1}{1+e^{-z}} \\ wx+b=z y=1+e−z1wx+b=z
好处:a.输出天然是概率(0到1之间),b.处处平滑可导,导数解析形式简洁,意味着前向传播和反向传播的梯度计算都很直接。c.单调且连续。
- sigmoid和softmax区别:
Sigmoid 是"逐元素独立压缩",Softmax 是"向量整体归一化"。
| Sigmoid | Softmax | |
|---|---|---|
| 输入 | 单个标量 z z z | 一个向量 z = z 1 , z 2 , . . . , z K \mathbf{z} = z_1, z_2, ..., z_K z=z1,z2,...,zK |
| 输出 | 单个值 ∈ ( 0 , 1 ) \in (0,1) ∈(0,1) | 一个向量,每个元素 ∈ ( 0 , 1 ) \in (0,1) ∈(0,1),且总和为 1 |
| 关系 | 各输出相互独立 | 各输出相互竞争(此消彼长) |
| 典型场景 | 二分类、多标签分类 | 多分类(单标签) |
s o f t max ( z i ) = e z i Σ j = 1 K e z j soft\max \left( z_i \right) =\frac{e^{z_i}}{\varSigma _{j=1}^{K}e^{z_j}} softmax(zi)=Σj=1Kezjezi
- 损失函数,其他都会,这里讲解交叉熵损失函数。
L = − Σ i = 1 n y i log ( y ^ i ) L=-\varSigma _{i=1}^{n}y_i\log \left( \hat{y}_i \right) L=−Σi=1nyilog(y^i)
| 符号 | 含义 |
|---|---|
| y i y_i yi | 第 i i i 类的真实标签(one-hot 编码,真实类别为 1,其余为 0) |
| y ^ i \hat{y}_i y^i | 模型预测的第 i i i 类的概率(通常由 Softmax 输出) |
| n n n | 类别总数 |
假设是 3 分类问题(猫、狗、鸟):
| 猫 | 狗 | 鸟 | ||
|---|---|---|---|---|
| 真实标签 y y y | 0 | 1 | 0 | (one-hot:真实是"狗") |
| 预测概率 y ^ \hat{y} y^ | 0.1 | 0.7 | 0.2 | (Softmax 输出) |
计算损失: L = − log ( 0.7 ) L=-\log \left( 0.7 \right) L=−log(0.7)
由于 one-hot 的特性,只有真实类别那一项有贡献,其他项都是 0×something=0 。
交叉熵衡量的是两个概率分布之间的差异:
y :真实的"目标分布"(one-hot,所有概率集中在正确类别)
y_hat:模型的"预测分布"(Softmax 输出的分散概率)
损失越小 → 预测分布
y_hat越接近真实分布 y → 模型对正确类别的预测概率越高。
-
激活函数是怎么工作起作用的?常见的损失函数?梯度下降怎么下降到最小点?
答:上层多个或单个神经元加权求和,经过激活函数得到输出,根据任务场景设计激活函数即可,比如二分类问题用sigmiod,多分类用softmax,解决异或问题/给神经网络非线性判别能力:用非线性的激活函数。MAE,MSE,交叉熵损失函数。梯度下降法,沿着损失函数的负梯度方向,配合学习率做梯度下降,损失函数则会下降到最小点。
-
常见的网络结构:RNN(处理时序数据,预测下一个词之前,已经记录了历史所有词状态),RNN的缺点 梯度消失梯度爆炸。
-
梯度消失梯度爆炸分别是什么?
梯度消失:反向传播时,梯度逐层衰减,前面层的参数几乎不更新,模型"冻住"了。根本原因是激活函数导数 < 1,多层连乘后梯度指数级缩小。
梯度爆炸:反向传播时,梯度逐层放大,前面层的参数更新幅度巨大,损失函数震荡甚至NaN。根本原因:权重初始化过大或激活函数导数 > 1,多层连乘后梯度指数级膨胀。
-
LSTM,增加记忆细胞,来解决RNN的梯度消失 梯度爆炸。记忆细胞可以实现有选择性的长期记忆。
-
encoder-decoder,用于处理序列到序列任务的架构。将输入序列先通过编码器压缩为一个中间表示,再由解码器根据该表示逐步生成输出序列,编码器、解码器都是神经网络。
第三讲 注意力机制
-
Transformer论文、qkv, attention,自注意力计算的过程(PPT图,自注意力计算的整个过程要考,需要非常熟练)
-
关于缩放点积注意力,缩放是什么、为什么要缩放、作用和效果?
这是Transformer架构中**缩放点积注意力(Scaled Dot-Product Attention)**的核心设计,也是自注意力最基础的关键优化。下面从「是什么、为什么要缩放、作用、效果」四个层面,结合两张图完整解释。
一、缩放的定义
自注意力的第一步,是用查询向量q和键向量k计算注意力分数,原始的计算方式是两个向量的点积(内积):\alpha_{i,j} = q^i \cdot k^j
而"缩放",就是在内积计算完成后,除以一个固定的缩放因子 \boldsymbol{\sqrt{d_k}}(d_k 是q、k向量的维度大小),修正后的分数为:
\alpha_{i,j} = \frac{q^i \cdot k^j}{\sqrt{d_k}}
之后再输入Softmax函数,得到最终的注意力权重。
二、为什么要缩放:核心矛盾是「内积方差随维度膨胀」
1. 数学本质:内积方差和维度线性正相关
我们可以做一个最基础的假设:q、k向量的每个分量都是独立同分布、均值为0、方差为1的随机变量(神经网络初始化的常用设定):- 单个分量的乘积 q_i \cdot k_i,方差为 Var(q_i k_i) = 1
- 内积是 d_k 个分量乘积的求和:q\cdot k = \sum_{i=1}^{d_k} q_i k_i
- 根据方差的可加性,内积的总方差为 Var(q\cdot k) = d_k \times 1 = d_k
结论很直观:向量维度越高,q、k内积的数值波动就越大,数值范围越广。
对应第一张图的例子:
5维的全1向量q和全3向量k,内积就已经达到15;如果是Transformer常用的512维向量,内积数值会达到数百上千,不同token的分数差异会被极度放大。2. 直接后果:Softmax分布极端尖锐,梯度消失
Softmax函数有一个关键特性:输入的数值差异越大,输出的概率分布就越极端------最大的输入值会被放大到接近1,其余所有值都会被压缩到接近0,形成"针尖状"的分布(近似one-hot)。对应第二张图的左图:
输入序列[1, 2, 7, 12, 8, 5, 2, 1]中,最大值12和其他值差异很大,Softmax后几乎只有第3个token拥有注意力权重,其余token的权重几乎为0。这种情况会带来两个致命问题:
- 注意力表达能力失效:模型几乎只能关注单个token,无法同时给多个相关词分配合理权重,丢失了上下文的关联信息(比如长句子里的多个指代、多组语义关联)。
- 梯度消失,训练瘫痪:Softmax在输入差异极大时会进入"饱和区",梯度趋近于0;反向传播时参数几乎无法更新,模型直接训练不动。
三、缩放机制的核心作用
缩放因子 \sqrt{d_k} 的本质,就是内积的标准差。除以它相当于对内积做了标准化:Var\left( \frac{q\cdot k}{\sqrt{d_k}} \right) = \frac{Var(q\cdot k)}{d_k} = \frac{d_k}{d_k} = 1
它的作用可以总结为3点:
-
统一数值尺度,消除维度影响
无论向量维度d_k是大是小,缩放后的内积方差都被归一化到1,让不同维度的注意力计算都处于稳定的数值区间,不会因为维度升高就出现数值爆炸。 -
软化Softmax分布,保留多token关联
拉平内积的数值差异,避免Softmax输出极端的"赢家通吃"分布,让模型可以同时给多个相关token分配注意力权重,保留更丰富的上下文语义。 -
稳定梯度,保障训练收敛
避免Softmax进入饱和区,让反向传播的梯度保持在合理范围,解决高维度下的梯度消失问题,让深层、高维的大模型可以正常训练。
四、缩放后的实际效果
对应第二张图的右图:
将同样的输入除以缩放因子后,Softmax的输出变得非常平缓------每个token都分配到了合理的注意力权重,最大值不再"一家独大",权重分布更均匀。最终对模型的收益:
- 语义能力提升:注意力可以同时捕捉多组上下文关联(比如长指代、多义词、搭配关系),语义理解更准确;
- 训练稳定性提升:高维度(512、1024甚至更高维)的注意力也能稳定收敛,支撑起大模型的参数规模;
- 数值鲁棒性提升:避免训练中出现数值溢出、梯度爆炸/消失等工程问题。
这个设计来自Transformer的开山论文《Attention Is All You Need》,是自注意力最基础也最关键的优化之一。
-
1111