NSGA-II 多目标优化 + SHAP 可解释分析:锂电池工艺参数的协同寻优
一、为什么锂电池制造需要"多目标"思维
锂电池的性能从来不是某一个指标的独角戏。比容量决定了续航里程,内阻影响充放电效率和发热水平,表面缺陷率直接关系安全性和循环寿命。这三个目标彼此牵制:提高涂布速度可以增加产能,但可能引入更多表面缺陷;增加固含量有助于提升容量,却以牺牲浆料流动性为代价。
传统的"单目标最优 → 固定其余约束"思路在真实产线上很难成立。工艺工程师面对的真实问题是一个多维、带冲突的搜索空间:同时让容量尽量高、内阻尽量低、缺陷率尽量低。这三个方向天然互斥,不存在唯一最优解,能提供的是一组Pareto最优解集------即无法在不损害任何一个目标的前提下继续改进另一个目标的解集合。
本文复现了一套端到端的工艺参数协同优化系统:以11个机器学习代理模型(含自研NumPy版LSTM)替代物理实验,在代理模型表面运行NSGA-II进化搜索获得Pareto前沿,再用SHAP值拆解每个工艺参数对三个目标的贡献方向与强度。全线代码基于Python生态(scikit-learn、SHAP、CatBoost、XGBoost),无GPU依赖,在普通办公主机上可完整跑通。
二、系统总览:从原始数据到可部署的工艺窗口
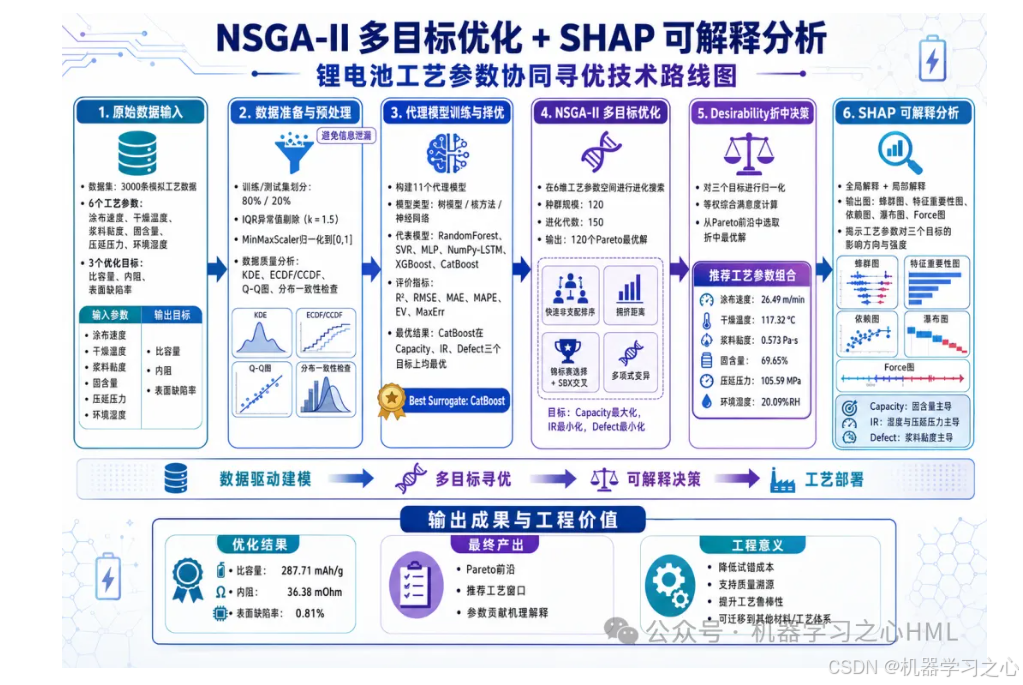
2.1 数据准备与预处理
原始数据集包含3000条模拟锂电池工艺记录,每条记录包含6个工艺参数和3个目标变量:
| 工艺参数 | 符号 | 单位 | 物理含义 |
|---|---|---|---|
| 涂布速度 | Speed | m/min | 浆料在集流体上的涂覆线速度 |
| 干燥温度 | Temp | °C | 极片烘干温度 |
| 浆料黏度 | Visc | Pa·s | 浆料流动阻力 |
| 固含量 | Solid | % | 浆料中活性物质质量占比 |
| 压延压力 | Pressure | MPa | 极片辊压压力 |
| 环境湿度 | Humidity | %RH | 车间相对湿度 |
| 目标变量 | 符号 | 单位 | 优化方向 |
|---|---|---|---|
| 比容量 | Capacity | mAh/g | 最大化 |
| 内阻 | IR | mOhm | 最小化 |
| 表面缺陷率 | Defect | % | 最小化 |
数据按80/20划分训练集与测试集。训练集经IQR异常值剔除(k=1.5)后,对输入特征和目标变量分别进行MinMaxScaler归一化至0,1区间。预处理环节生成了KDE分布图、ECDF/CCDF尾部分析图、Q-Q正态偏离图、清洗前后对比图以及训练/测试分布一致性检查图,完整追踪数据质量变化。
2.2 代理模型训练与择优
考虑到锂电池工艺参数与性能目标之间通常是强非线性、带交互效应的黑箱映射关系,本项目构建了覆盖树模型、核方法、神经网络三大类别的11个代理模型:RandomForest、ExtraTrees、GBDT、AdaBoost、SVR、KNN、Ridge、BP神经网络(MLP)、LSTM神经网络(纯NumPy实现)、XGBoost、CatBoost。
其中LSTM为不依赖PyTorch/TensorFlow的纯NumPy实现,包含完整的前向传播与BPTT(通过时间的反向传播)训练循环,优化器采用Adam。这一设计的价值在于:在无法安装深度学习框架的生产环境中,仍可训练一个具备时序建模能力的代理模型。
所有模型在测试集上按R2、RMSE、MAE、MAPE、EV、MaxErr六项指标评估,每个目标选出R2最优模型作为后续NSGA-II的适应度函数。
2.3 NSGA-II多目标优化
将最优代理模型封装为预测函数,在6维工艺参数空间(以原始数据min/max为搜索边界)内运行NSGA-II进化算法,种群规模120、进化150代,最终获得120个Pareto最优解。
2.4 折中最优解选取
从Pareto前沿中,使用Desirability函数(各目标min-max归一化后等权合成)选出综合满意度最高的折中解,作为推荐工艺参数组合。
2.5 SHAP可解释分析
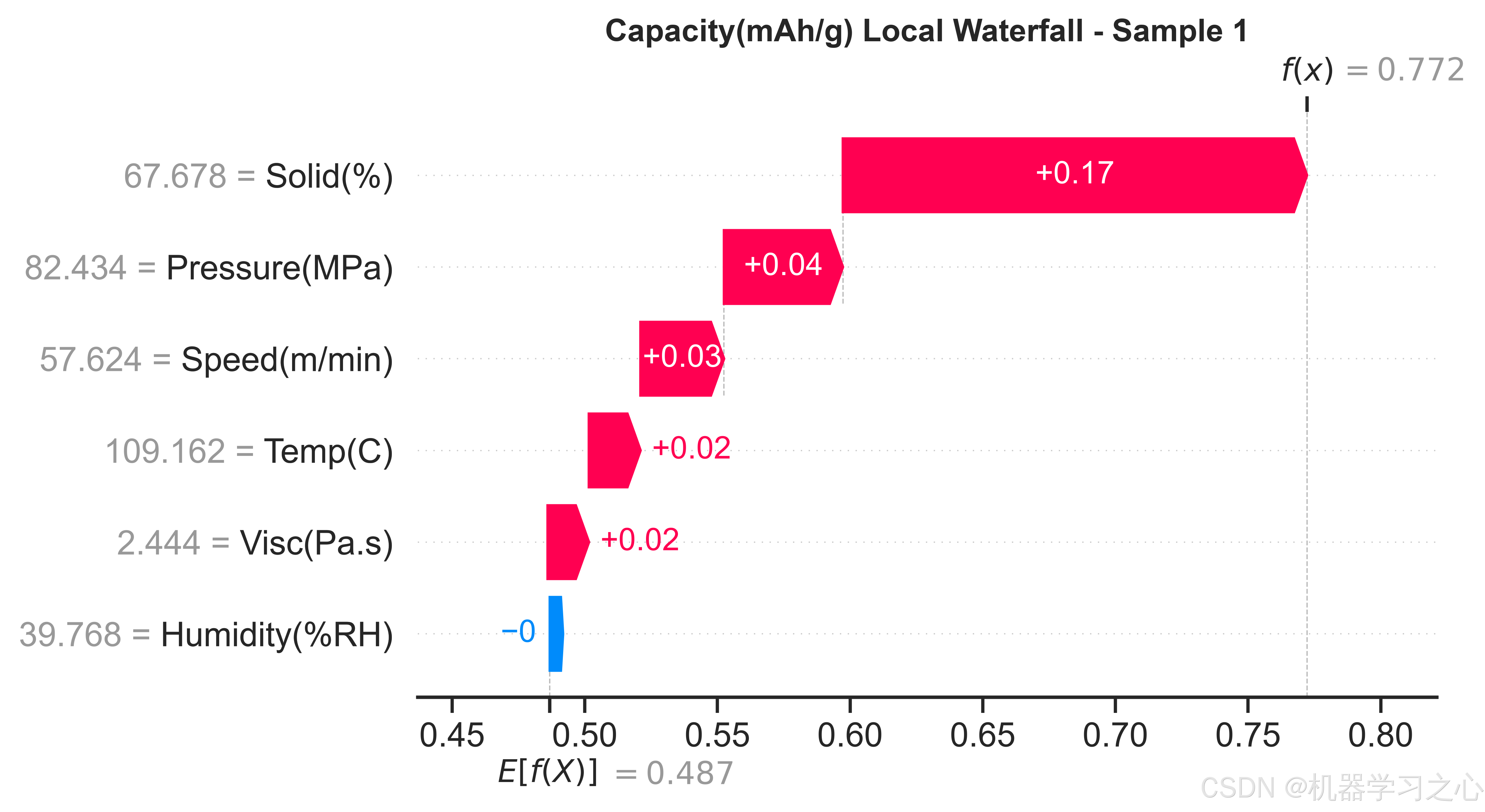
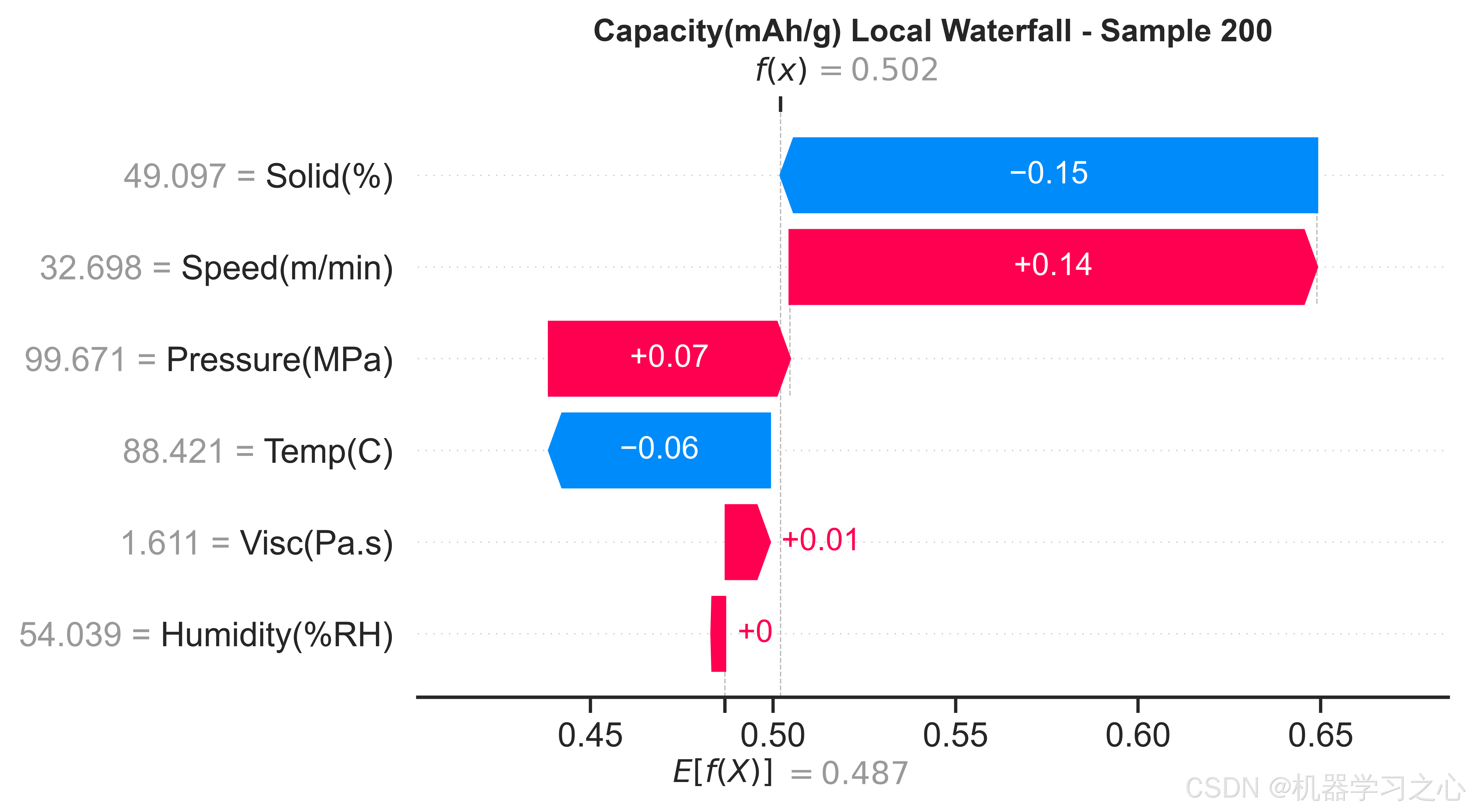
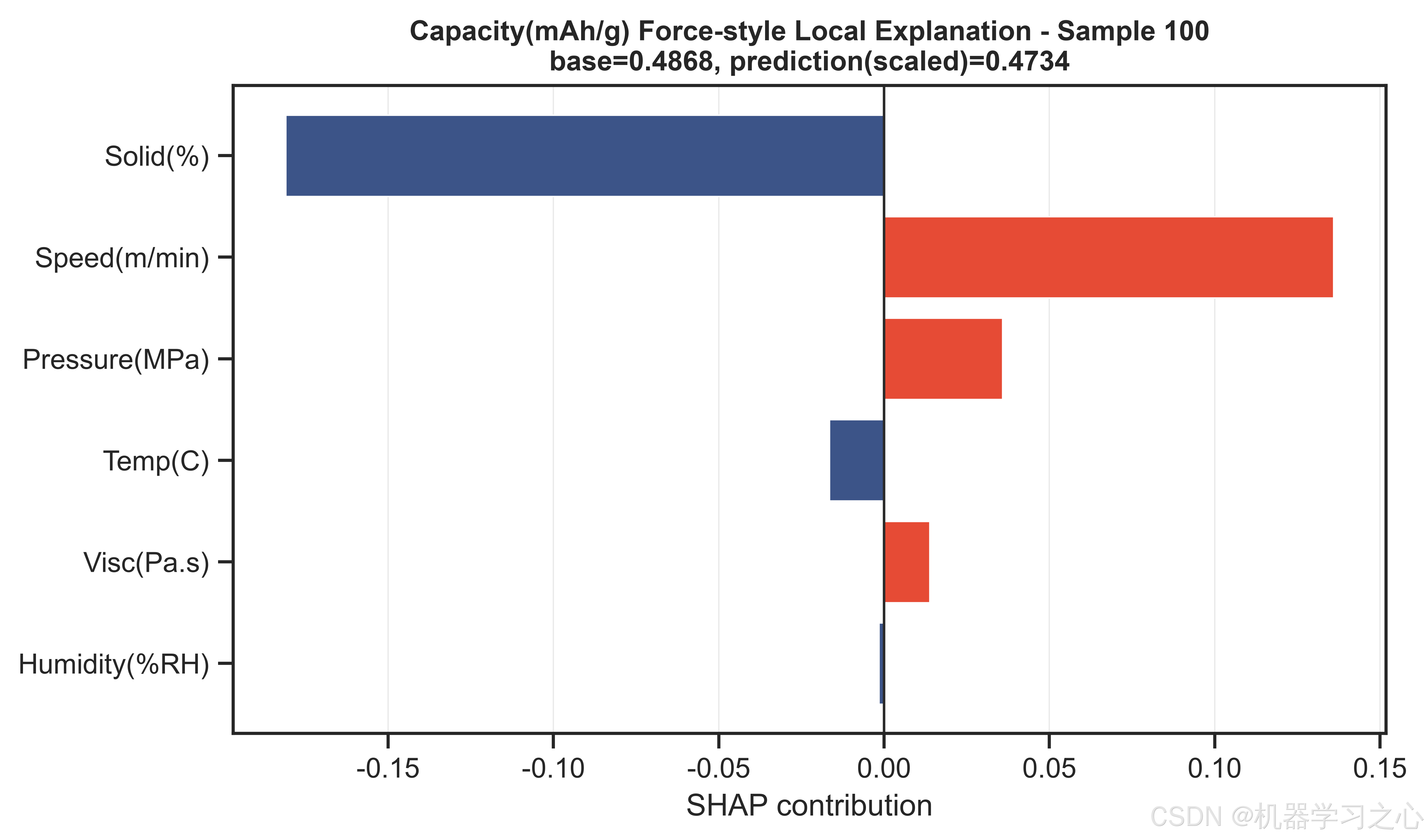
对三个目标的最优代理模型分别计算SHAP值,输出蜂群图、特征重要性条形图、2×3特征依赖图(含LOWESS平滑趋势线)、瀑布图(单样本决策路径)和force图(多样本叠加),从全局和局部两个粒度揭示工艺参数对性能目标的影响规律。
三、算法核心:NSGA-II 的四个算子
NSGA-II(Non-dominated Sorting Genetic Algorithm II)由Deb等人在2002年提出,是多目标进化优化领域引用量最高的算法之一。其核心改进在于用快速非支配排序替代了早期NSGA的O(MN³)排序,并将拥挤距离作为多样性保持机制,避免了共享参数的手动调参。
3.1 快速非支配排序
对于种群中任意两个个体p和q,若p在所有目标上不劣于q且至少在某一目标上严格优于q,则称p支配q(记作 p ≺ q)。快速非支配排序通过两轮遍历为每个个体标记支配计数和被支配集合,将所有支配计数为0的个体归入第一前沿(Pareto前沿),然后迭代移除已分层个体、更新支配计数,逐层构建后续前沿。复杂度为O(MN²),其中M为目标数量,N为种群大小。
算法伪码如下:
输入:种群目标矩阵 F(N × M)
输出:分层后的前沿列表 fronts
- 对每个个体 p,计算 n_domp(支配p的个体数)和 Sp(p支配的个体集合)
- 将 n_domp==0 的个体加入 fronts0
- i = 0;当 frontsi 非空时循环:
- 对 frontsi 中每个 p,遍历 Sp 中的每个 q:
- n_domq -= 1
- 若 n_domq == 0,将 q 加入下一前沿
- i += 1
3.2 拥挤距离
在同一前沿内,拥挤距离衡量个体的密度------距离越大说明周围解越稀疏,越值得保留以维持种群多样性。对每个目标维度m,将前沿内的个体按m排序,边界个体的拥挤距离设为无穷大,中间个体的拥挤距离为相邻两个体在第m个目标上归一化差值的累加:
di=∑m=1MFi+1,m−Fi−1,mFmmax−Fmmin d_i = \sum_{m=1}^{M} \frac{F_{i+1,m} - F_{i-1,m}}{F_{m}^{\max} - F_{m}^{\min}} di=m=1∑MFmmax−FmminFi+1,m−Fi−1,m
3.3 锦标赛选择与SBX交叉
选择算子采用二元锦标赛:从种群中随机抽取两个个体,优先选择rank更小(前沿层数更靠前)的个体;若rank相同,选择拥挤距离更大的个体。这种机制同时驱动收敛(向Pareto前沿逼近)和多样性(向稀疏区域扩散)。
交叉算子为模拟二进制交叉(SBX, Simulated Binary Crossover),其核心思想是用一个随机扩展因子β模拟二进制串单点交叉在实值空间中的效果。对于父代x₁< x₂,子代c₁、c₂满足:
c1=0.5(x1+x2)−βq(x2−x1) c_1 = 0.5(x_1 + x_2) - \\beta_q(x_2 - x_1) c1=0.5(x1+x2)−βq(x2−x1)
c2=0.5(x1+x2)+βq(x2−x1) c_2 = 0.5(x_1 + x_2) + \\beta_q(x_2 - x_1) c2=0.5(x1+x2)+βq(x2−x1)
其中βq服从与分布指数ηc(本项目设定为15.0)相关的概率分布,使得子代更大可能落在父代附近,同时保留远处探索的可能性。交叉概率设为0.9。
3.4 多项式变异
对每个决策变量以1/n_var的概率触发变异,变异幅度遵循多项式分布。分布指数ηm(本项目设定为20.0)越大,变异倾向于更小幅度的扰动------ηm→∞时退化为均匀分布,ηm→0时使得子代更易落入边界附近。
3.5 环境选择(μ + λ)
每代将当前种群(μ个)与子代(λ个,本项目μ=λ=120)合并为μ+λ个候选个体,经过快速非支配排序后从第一前沿开始逐层填充下一代种群,直到某层无法完整容纳时按拥挤距离排序截断。
四、Desirability函数:从Pareto集合到单一推荐
NSGA-II输出的是一个由120个互不支配的解构成的Pareto前沿,但产线部署需要的是一个确定的工艺参数组合。本项目采用Desirability函数法进行后验选择。
对每个目标进行min-max归一化,方向根据优化方向调整:
- 容量(越大越好):d1=C−CminCmax−Cmind_1 = \frac{C - C_{\min}}{C_{\max} - C_{\min}}d1=Cmax−CminC−Cmin
- 内阻(越小越好):d2=1−R−RminRmax−Rmind_2 = 1 - \frac{R - R_{\min}}{R_{\max} - R_{\min}}d2=1−Rmax−RminR−Rmin
- 缺陷率(越小越好):d3=1−D−DminDmax−Dmind_3 = 1 - \frac{D - D_{\min}}{D_{\max} - D_{\min}}d3=1−Dmax−DminD−Dmin
总Desirability为三个分量的等权平均:
D=d1+d2+d33 D = \frac{d_1 + d_2 + d_3}{3} D=3d1+d2+d3
取D值最大的解作为推荐的折中最优工艺参数组合。
五、代理模型:11个模型的全面对抗
5.1 模型体系与超参数
| 模型 | 核心超参数 |
|---|---|
| RandomForest | n_estimators=260, max_depth=None |
| ExtraTrees | n_estimators=260 |
| GBDT | n_estimators=320, lr=0.045, max_depth=3 |
| AdaBoost | base=DecisionTree(max_depth=5), n_estimators=220 |
| SVR | C=10.0, gamma=scale, epsilon=0.015 |
| KNN | n_neighbors=12, weights=distance |
| Ridge | alpha=0.08 |
| BP Neural Network | MLP(96,64), relu, early_stopping |
| LSTM Neural Network | 纯NumPy版: hidden=24, epochs=90, batch=128, lr=0.012 |
| XGBoost | n_estimators=260, max_depth=4, lr=0.045 |
| CatBoost | iterations=360, depth=6, lr=0.045 |
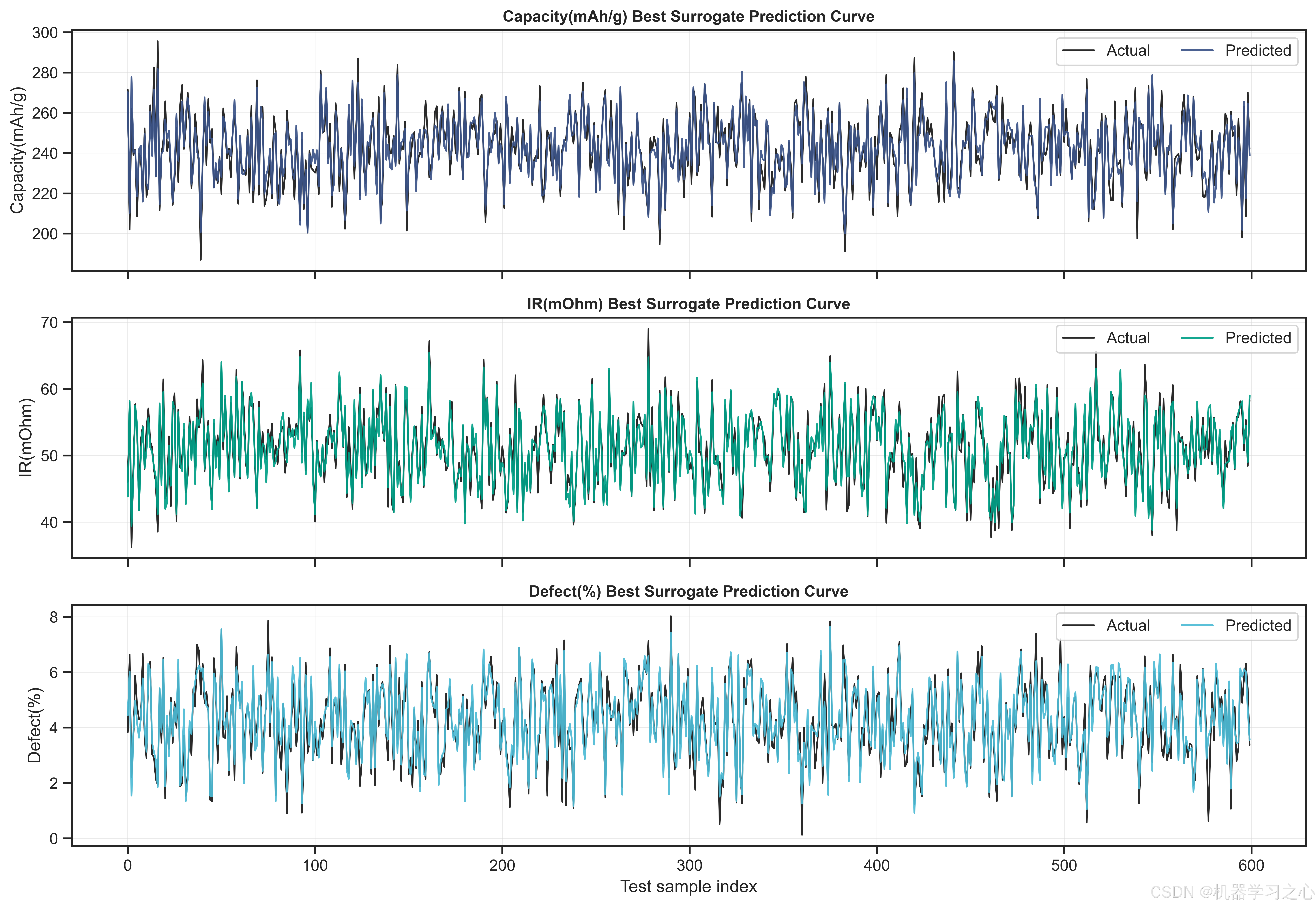
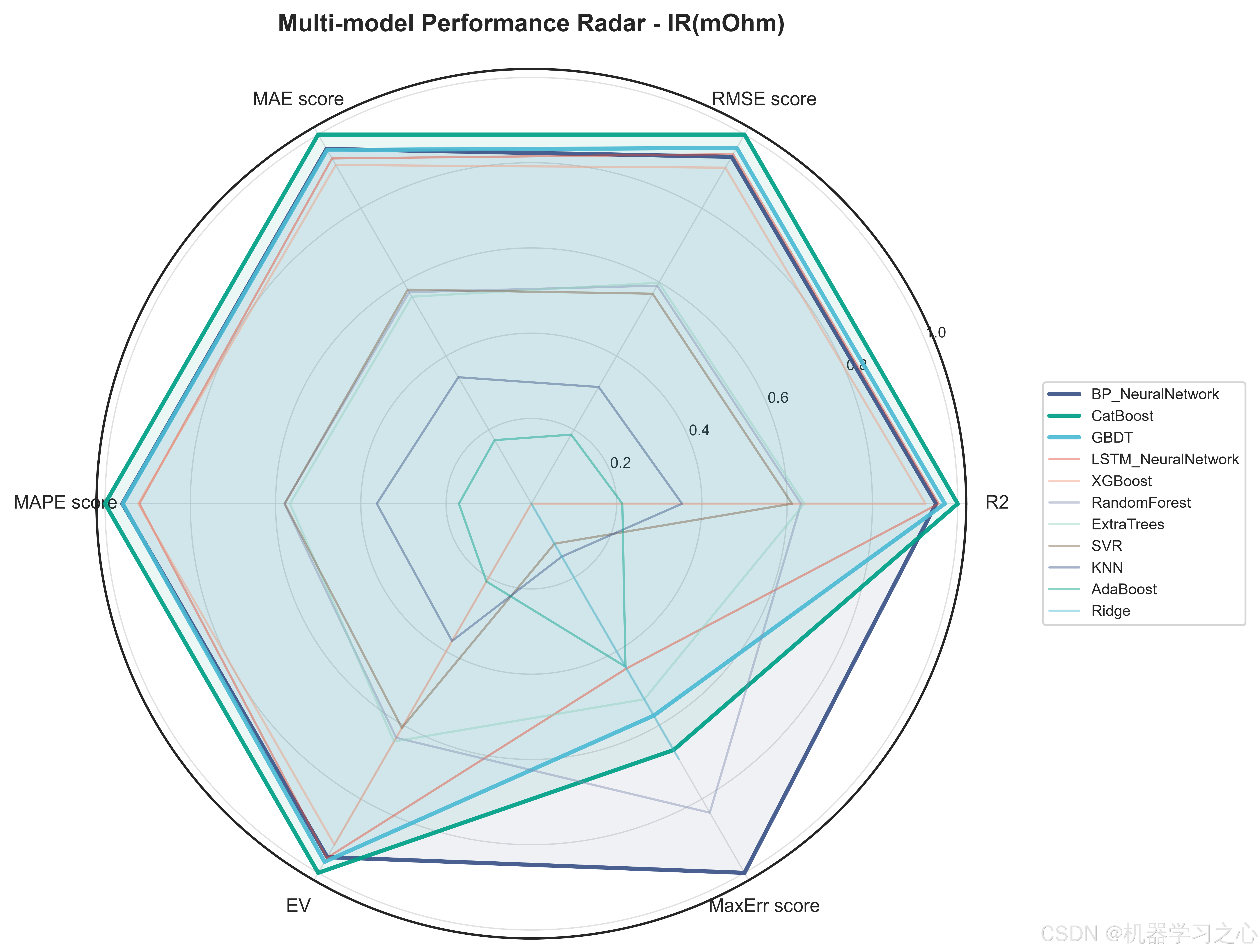
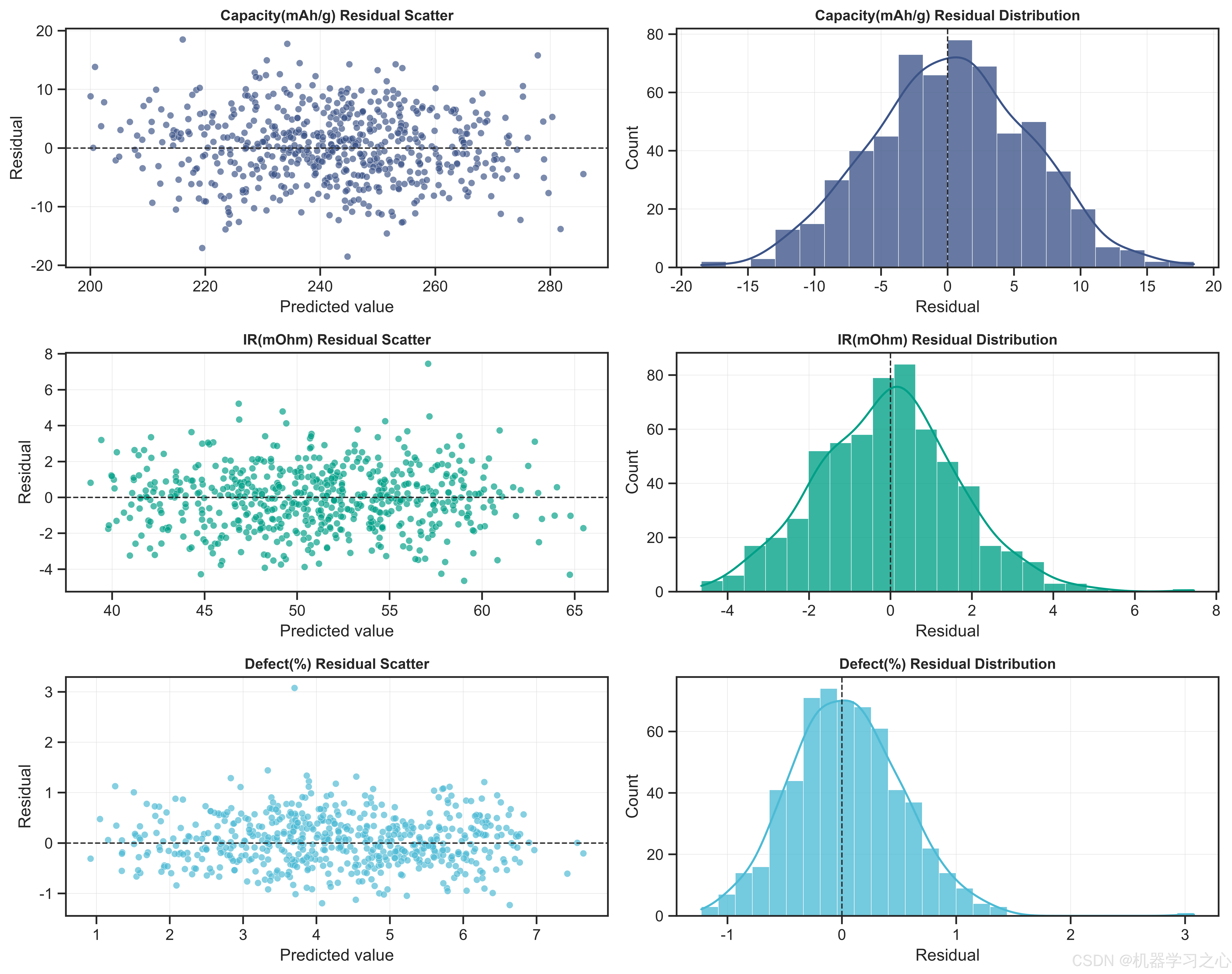
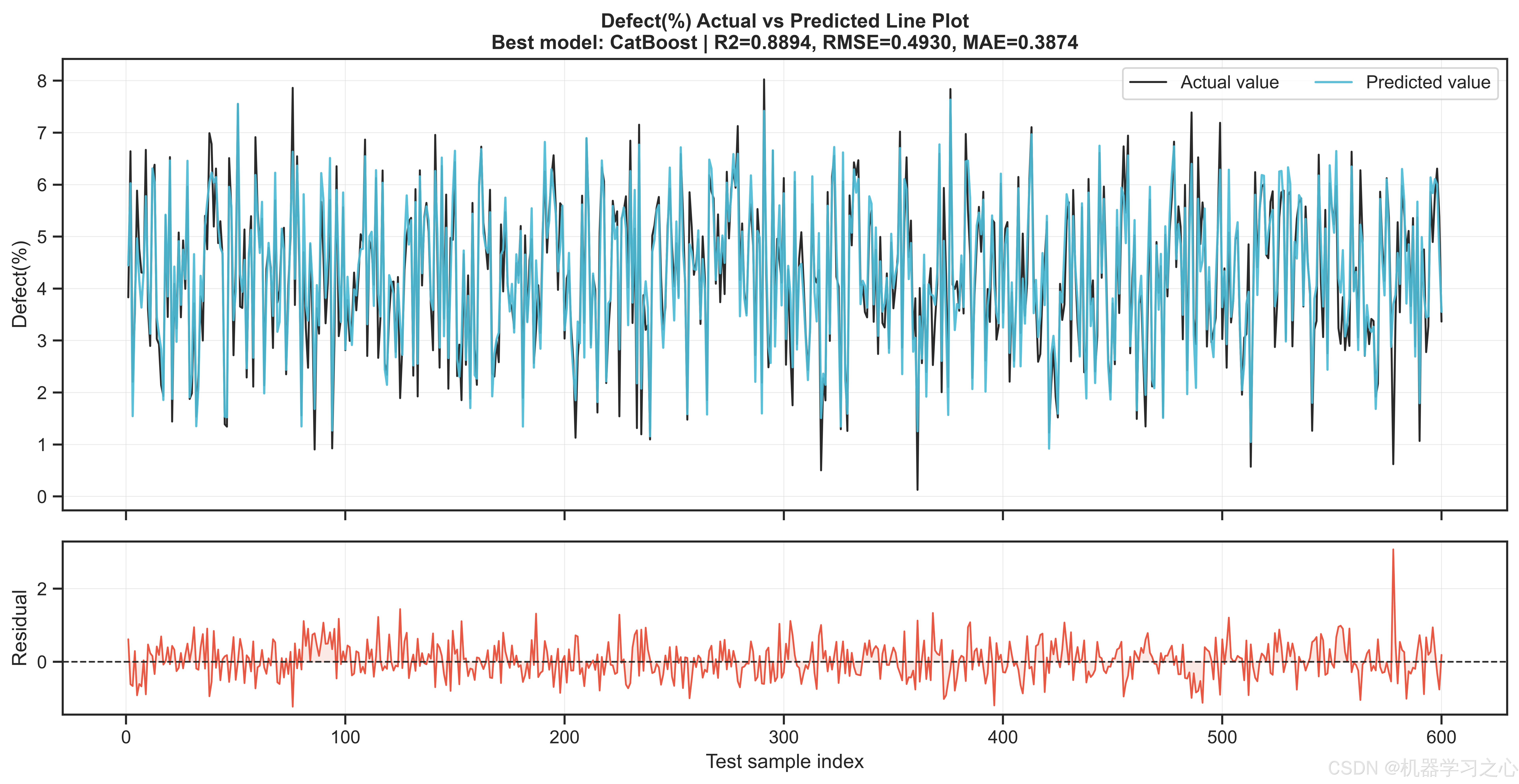
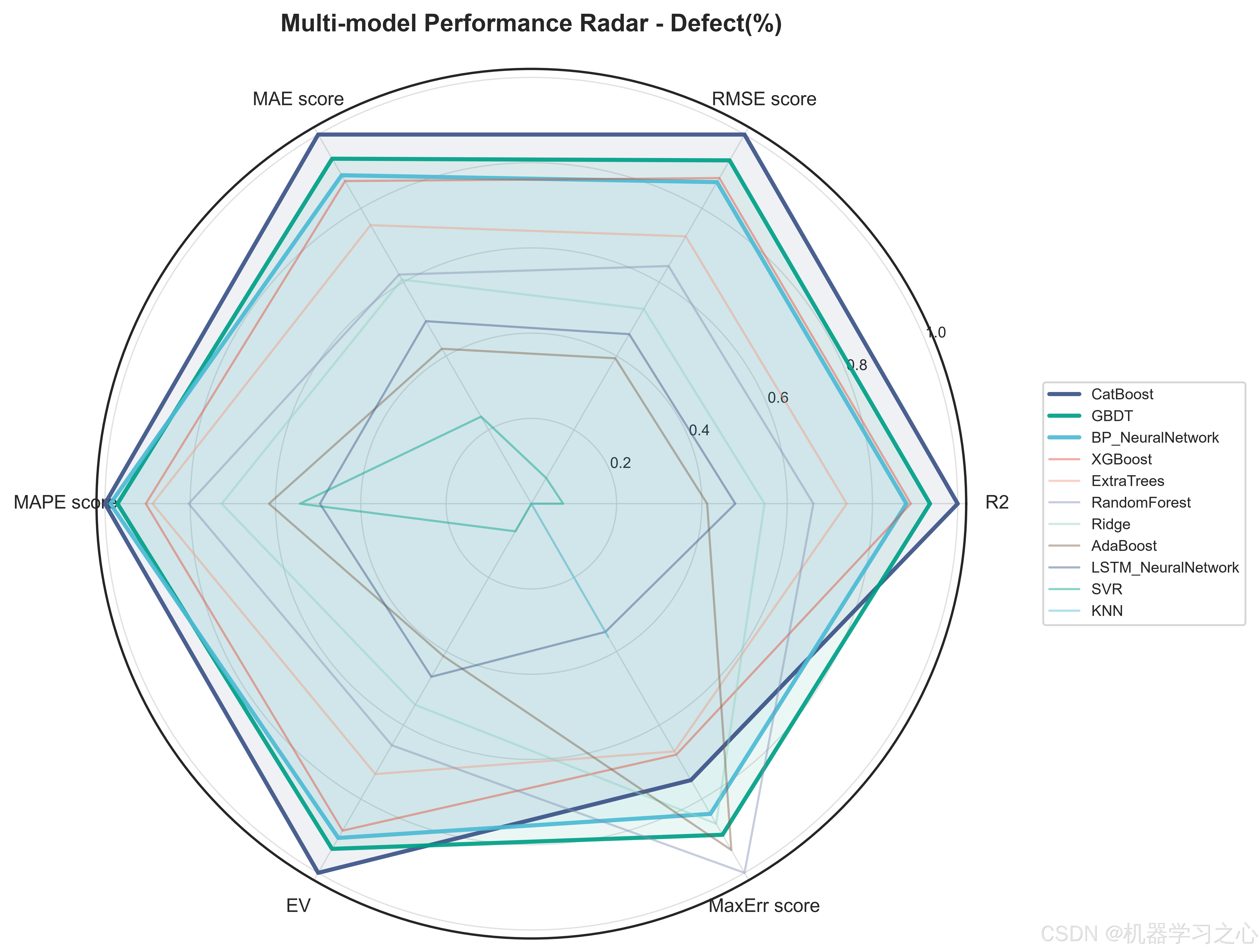
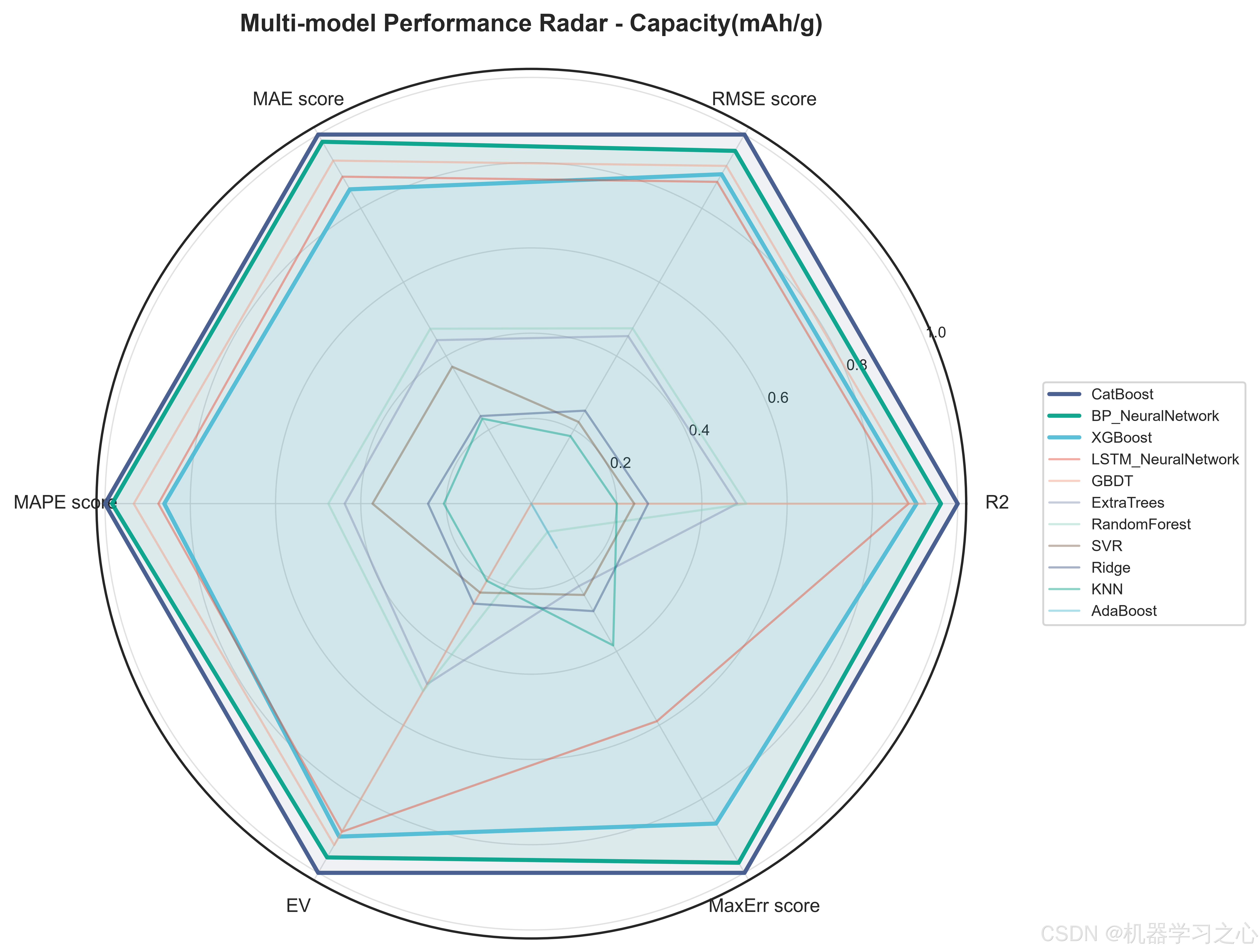
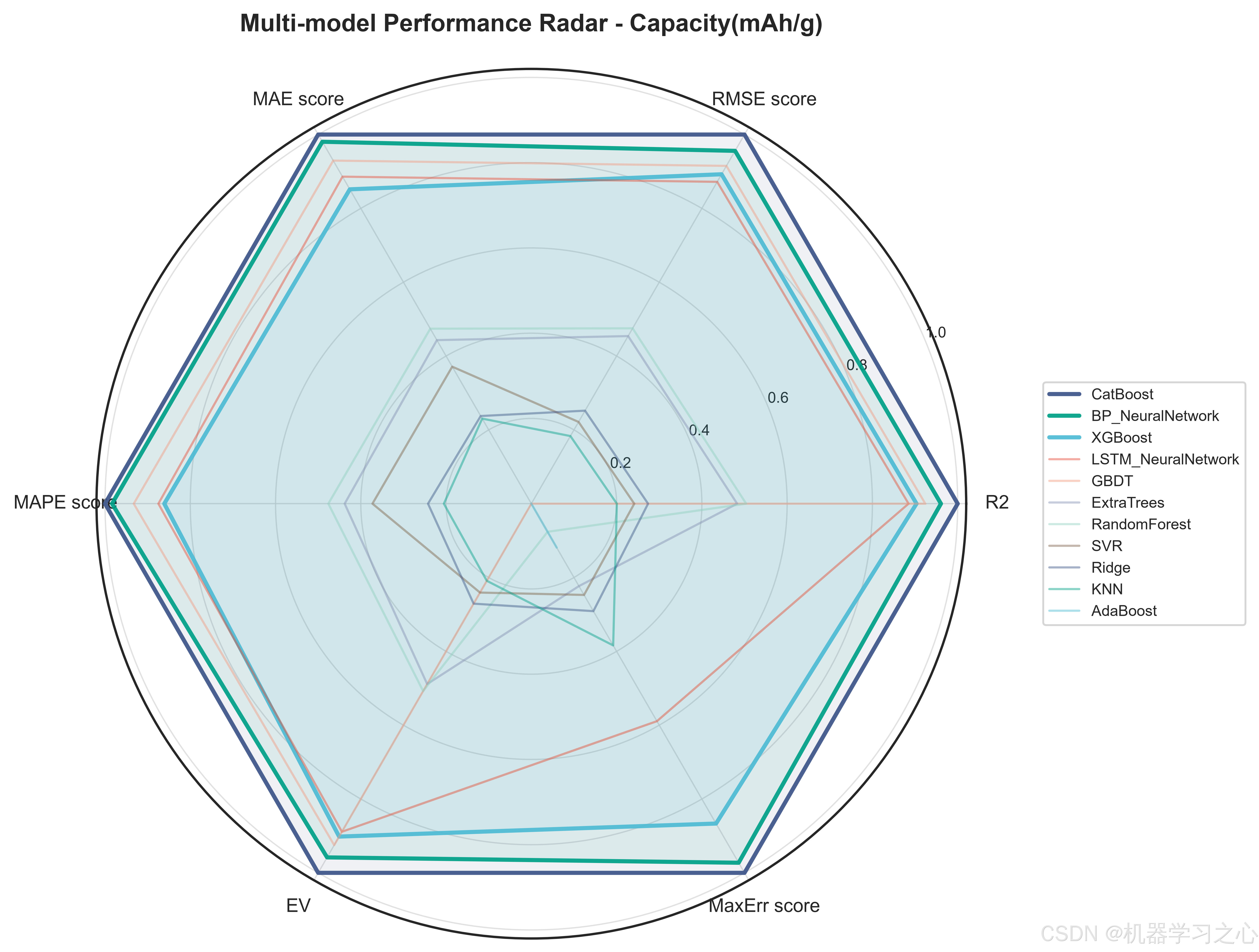
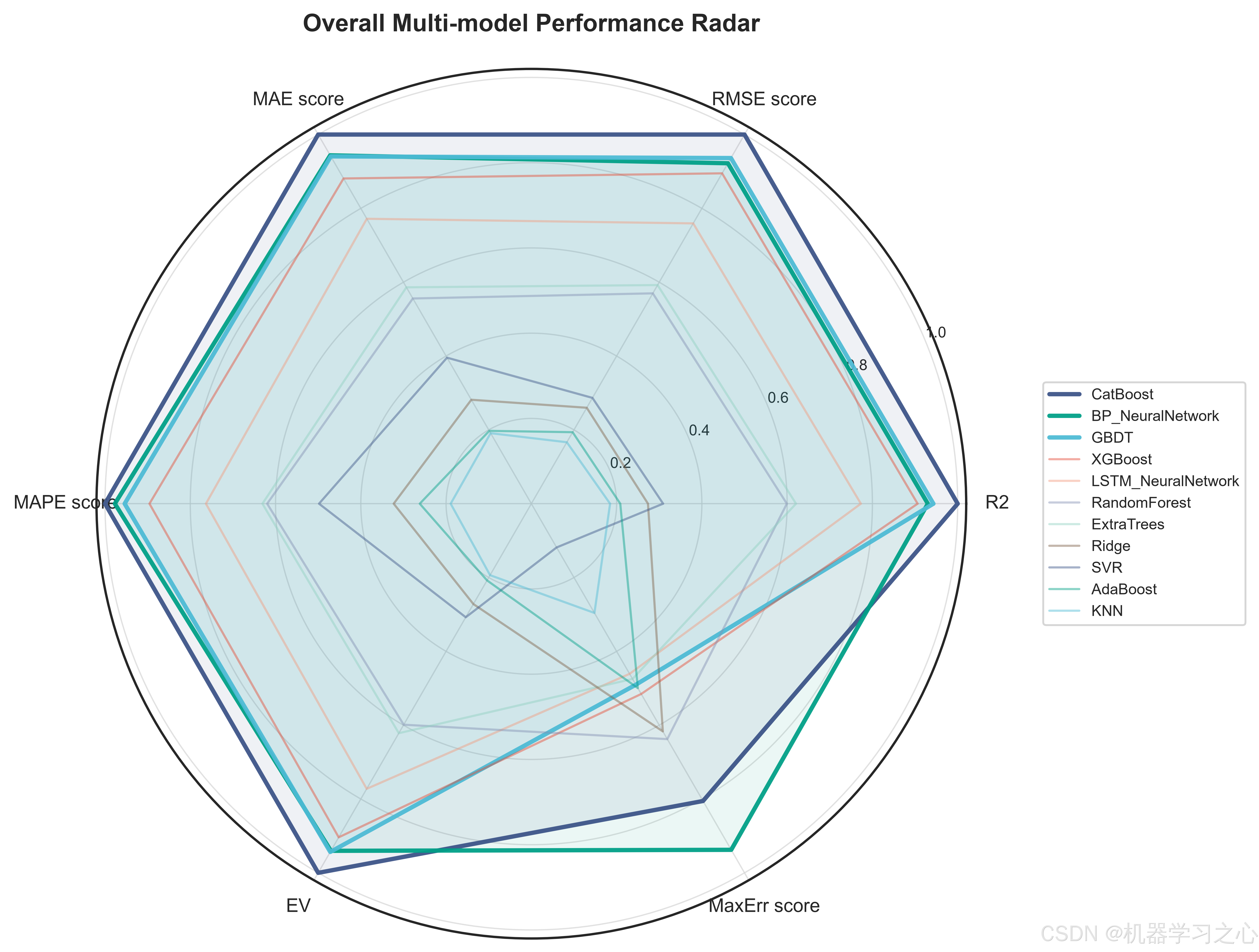
5.2 模型对决结果
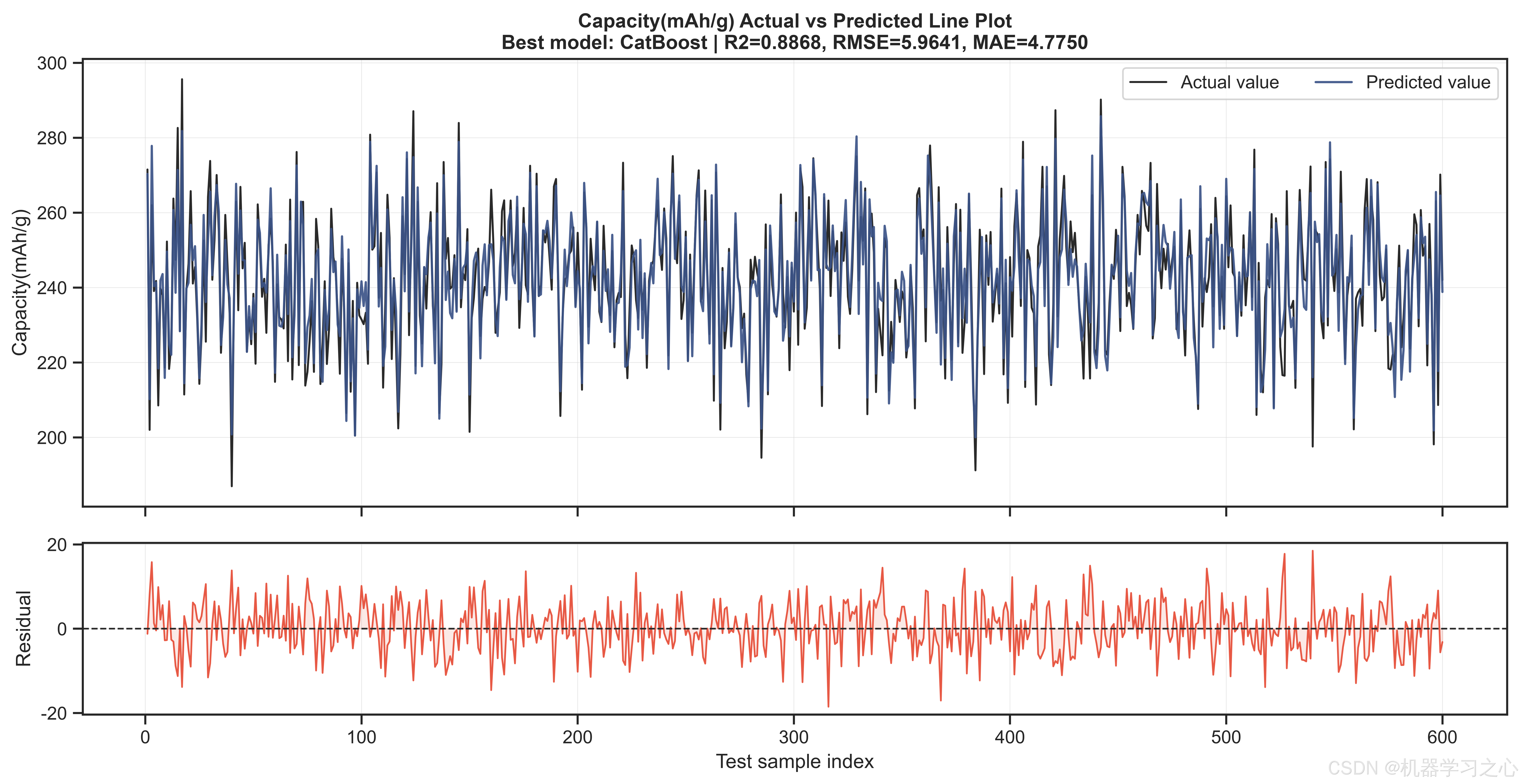
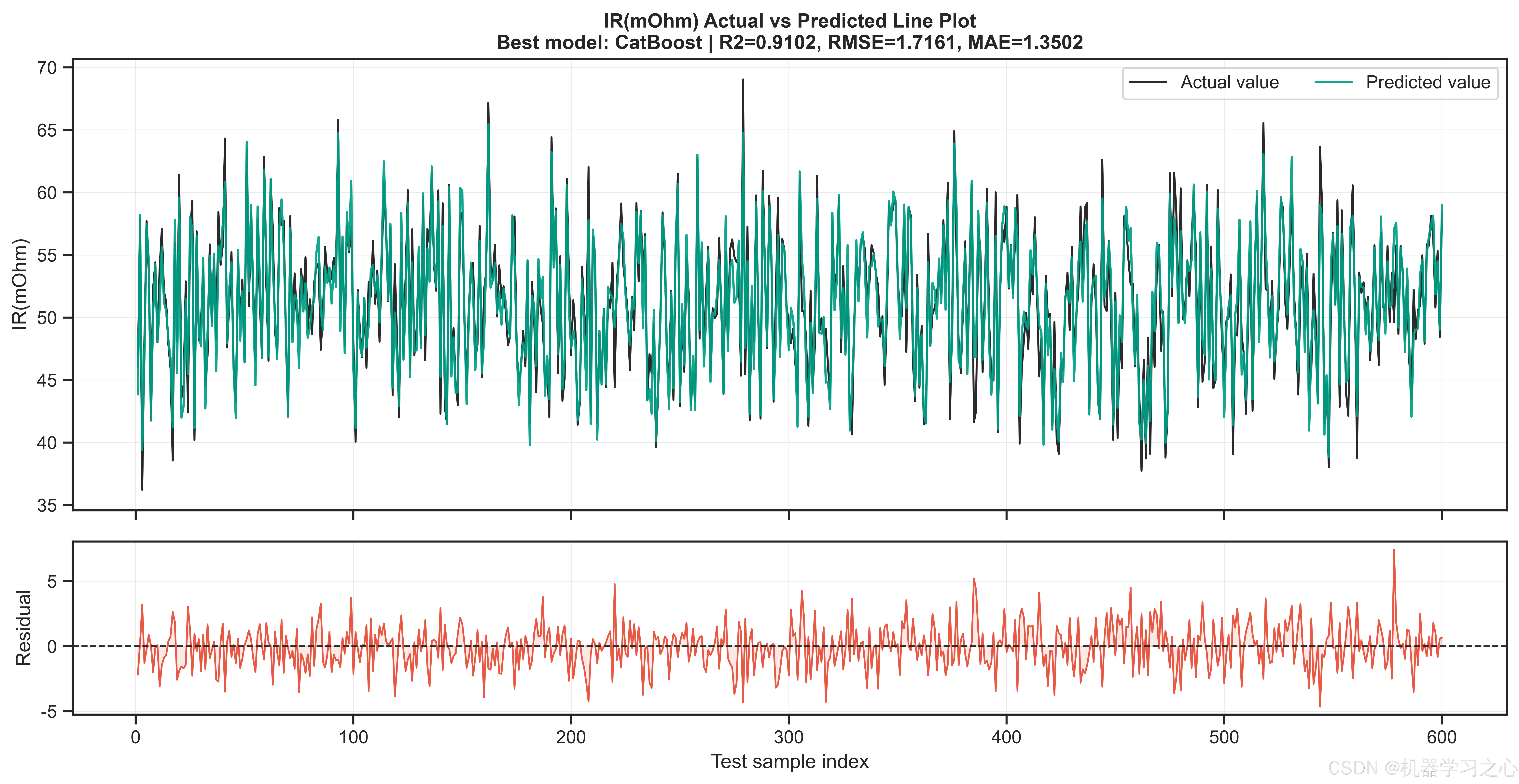
三个目标上的最优模型惊人地统一------CatBoost在全部三个目标上均以最高R2胜出:
| 目标 | 最优模型 | R² | RMSE | MAPE |
|---|---|---|---|---|
| Capacity(mAh/g) | CatBoost | 0.8868 | 5.964 | 1.99% |
| IR(mOhm) | CatBoost | 0.9102 | 1.716 | 2.67% |
| Defect(%) | CatBoost | 0.8894 | 0.493 | 13.40% |
值得注意的是,内阻目标的预测精度最高(R²=0.910),缺陷率的MAPE较高(13.4%)主要是由于缺陷率本身数值量级较小(通常<3%),绝对误差在可接受范围内。BP神经网络和LSTM神经网络分别以R²=0.884和0.879在容量目标上紧随CatBoost,表明神经网络在捕捉工艺参数-目标之间的非线性映射方面同样有效,但树模型的梯度提升策略在中小规模表格数据上仍占优势。
Ridge和KNN在三个目标上均垫底,验证了锂电池工艺-性能关系的高度非线性------线性模型和纯距离度量无法充分拟合这种复杂的交互效应。
六、NSGA-II 优化结果
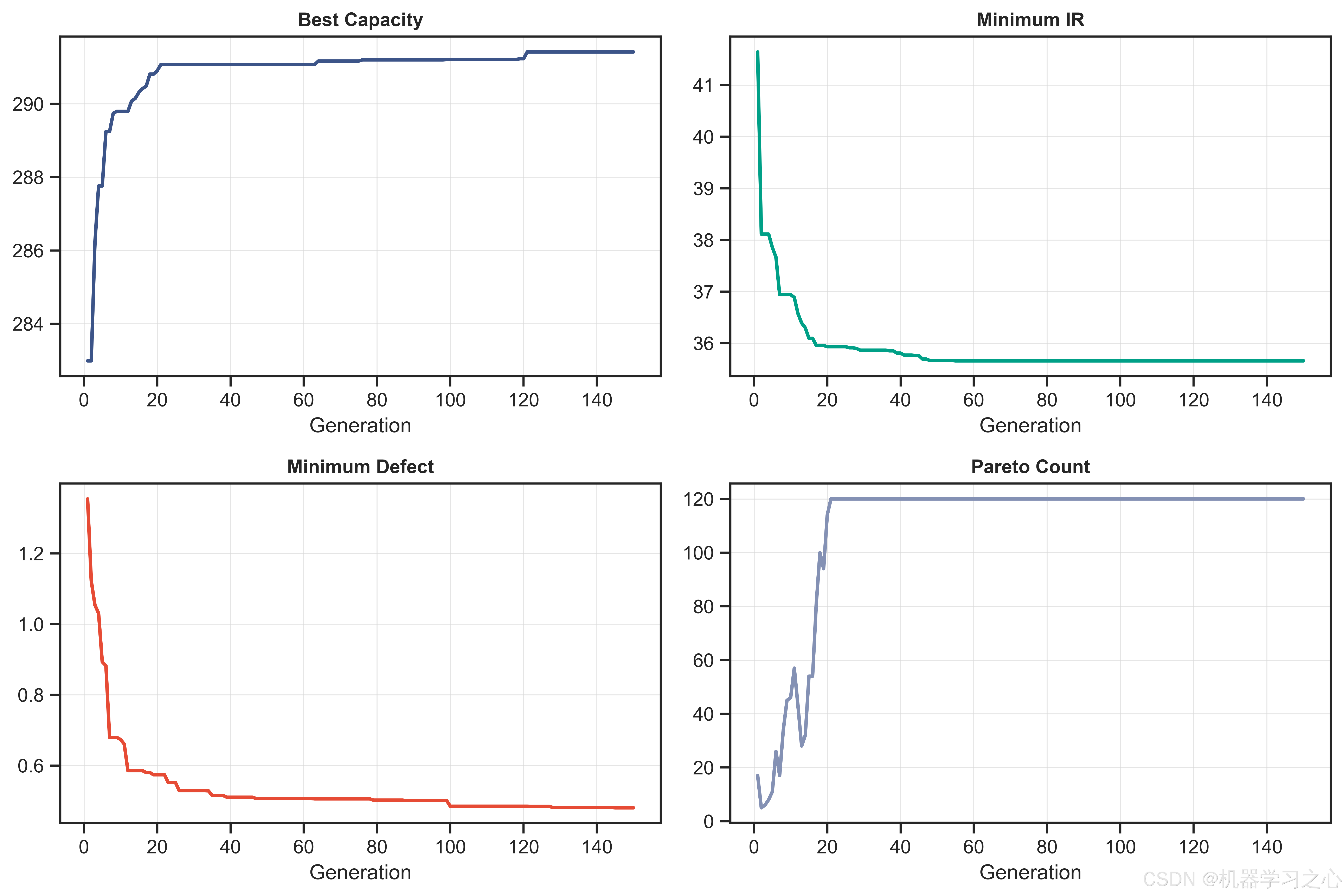
6.1 收敛过程
NSGA-II在150代中呈现出清晰的收敛轨迹。Pareto解数量从第1代的17个迅速增长至约第20代的120个并保持稳定。三个目标的最优值持续改善:
- Best Capacity:282.99 → 291.42 mAh/g(+8.43)
- Best IR:41.64 → 35.66 mOhm(-5.98)
- Best Defect:1.354% → 0.480%(-0.874%)
IR在约第20代后收敛,Defect在约第55代后趋于稳定,而Capacity在第120代仍有微幅提升。这表明三个目标对搜索空间的敏感区域不同------容量对极端参数组合更敏感,需要更多代数探索边界区域。
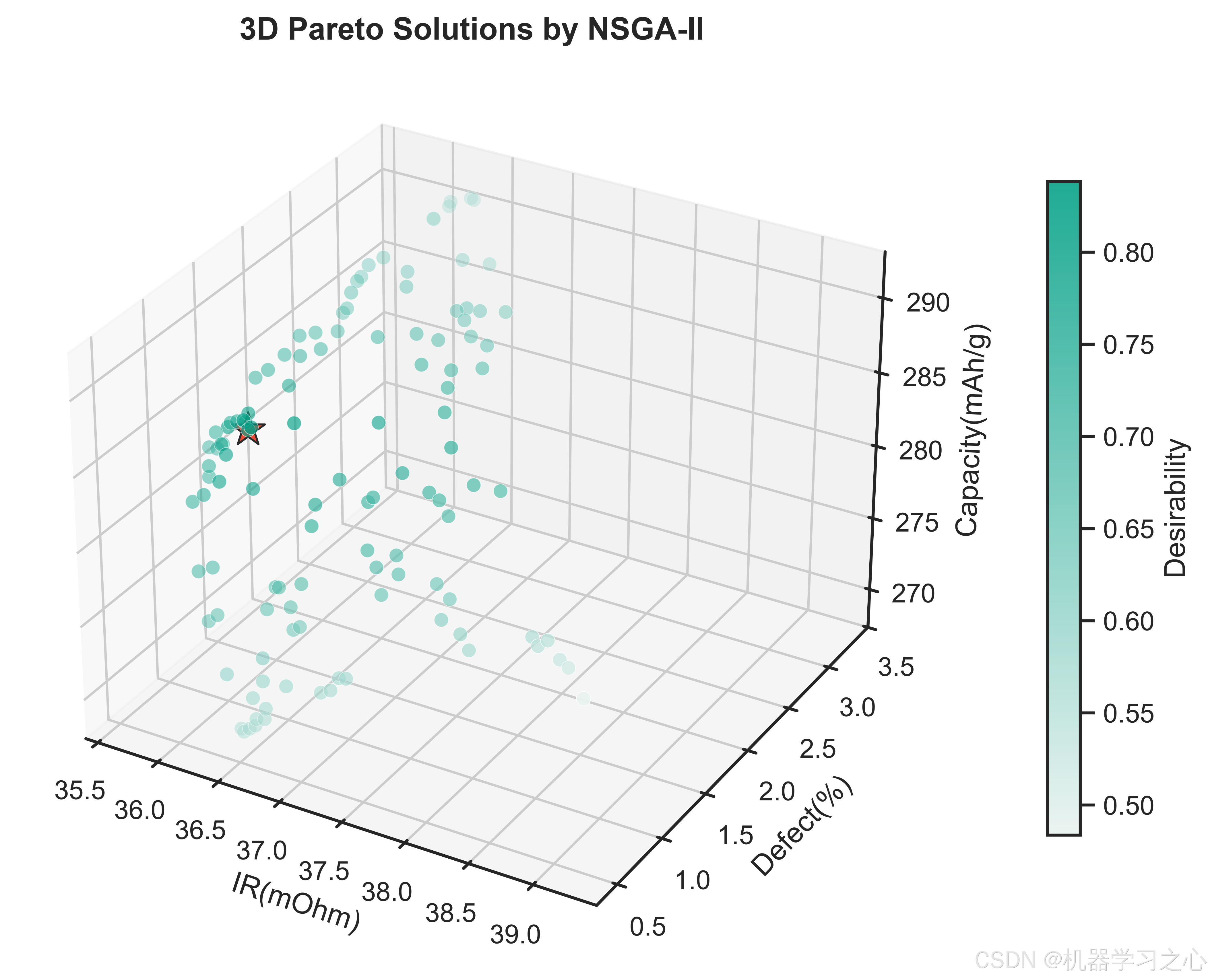
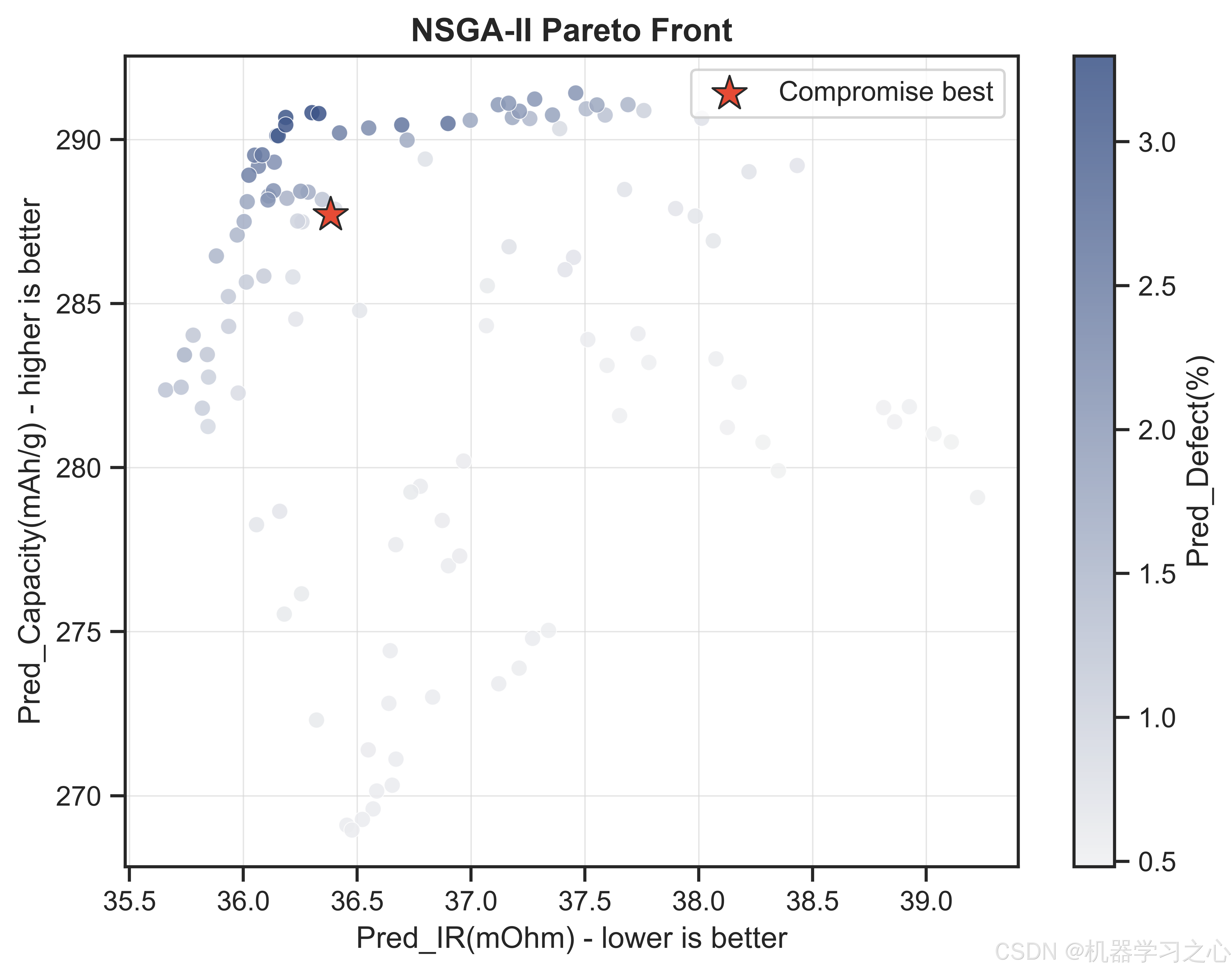
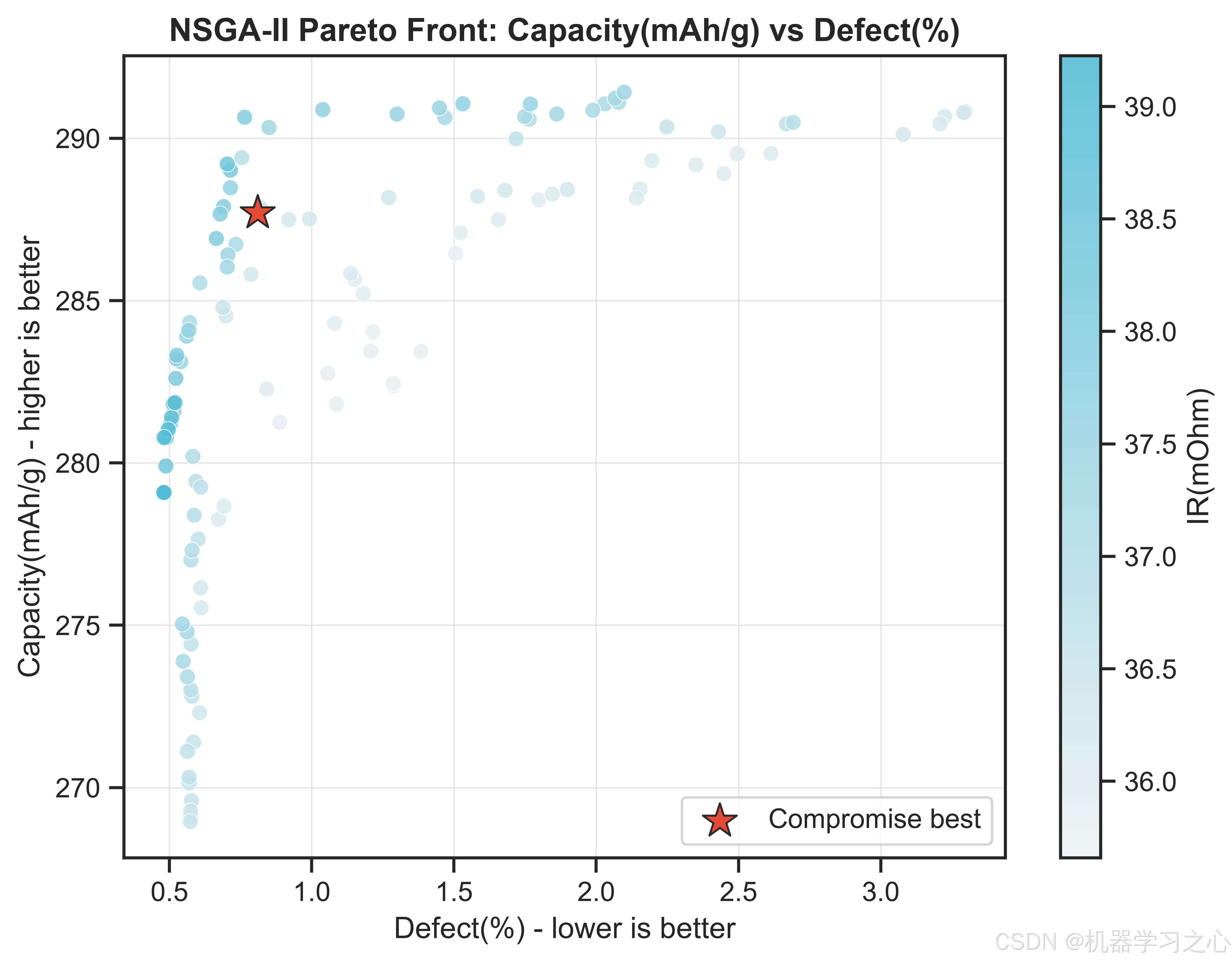
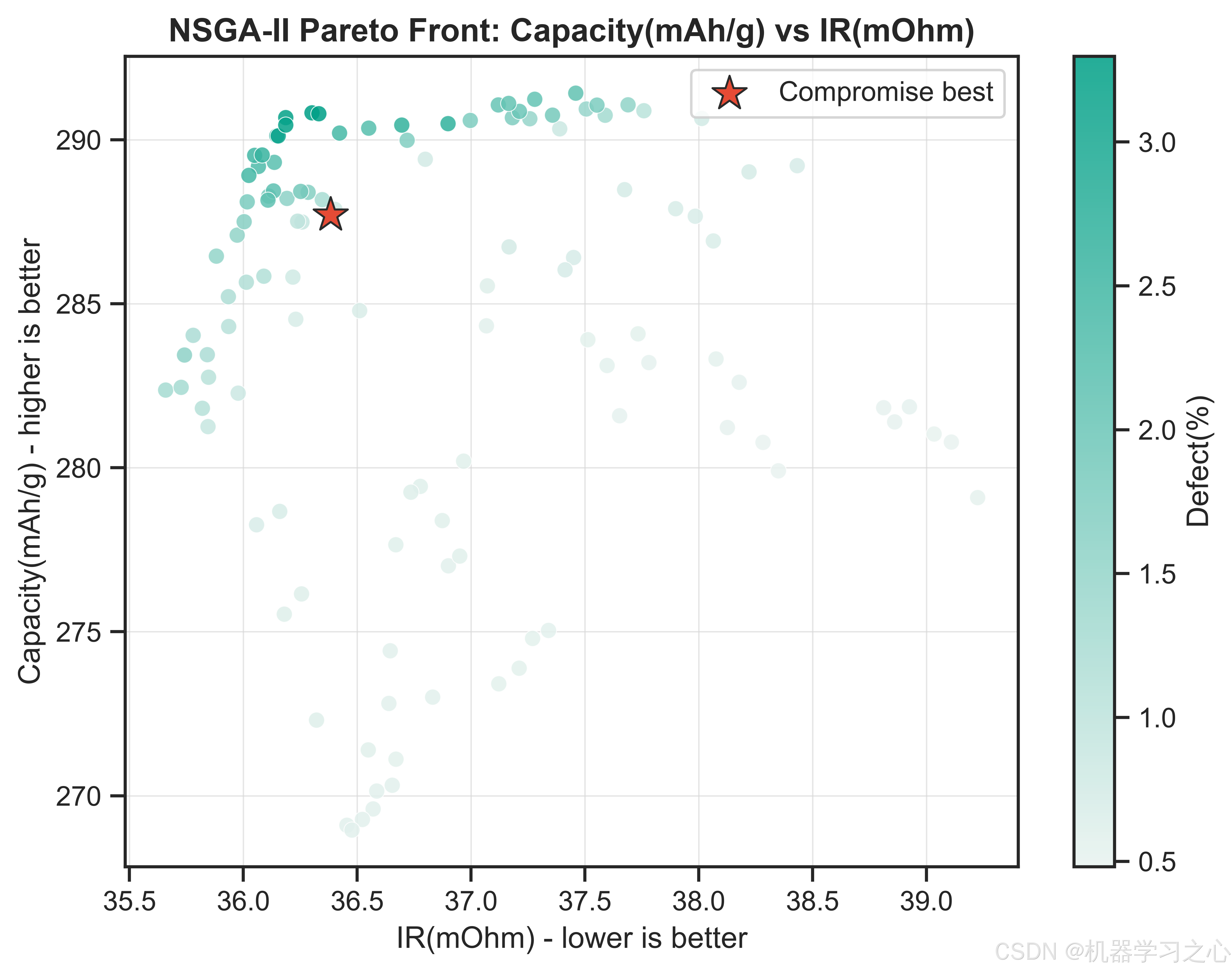
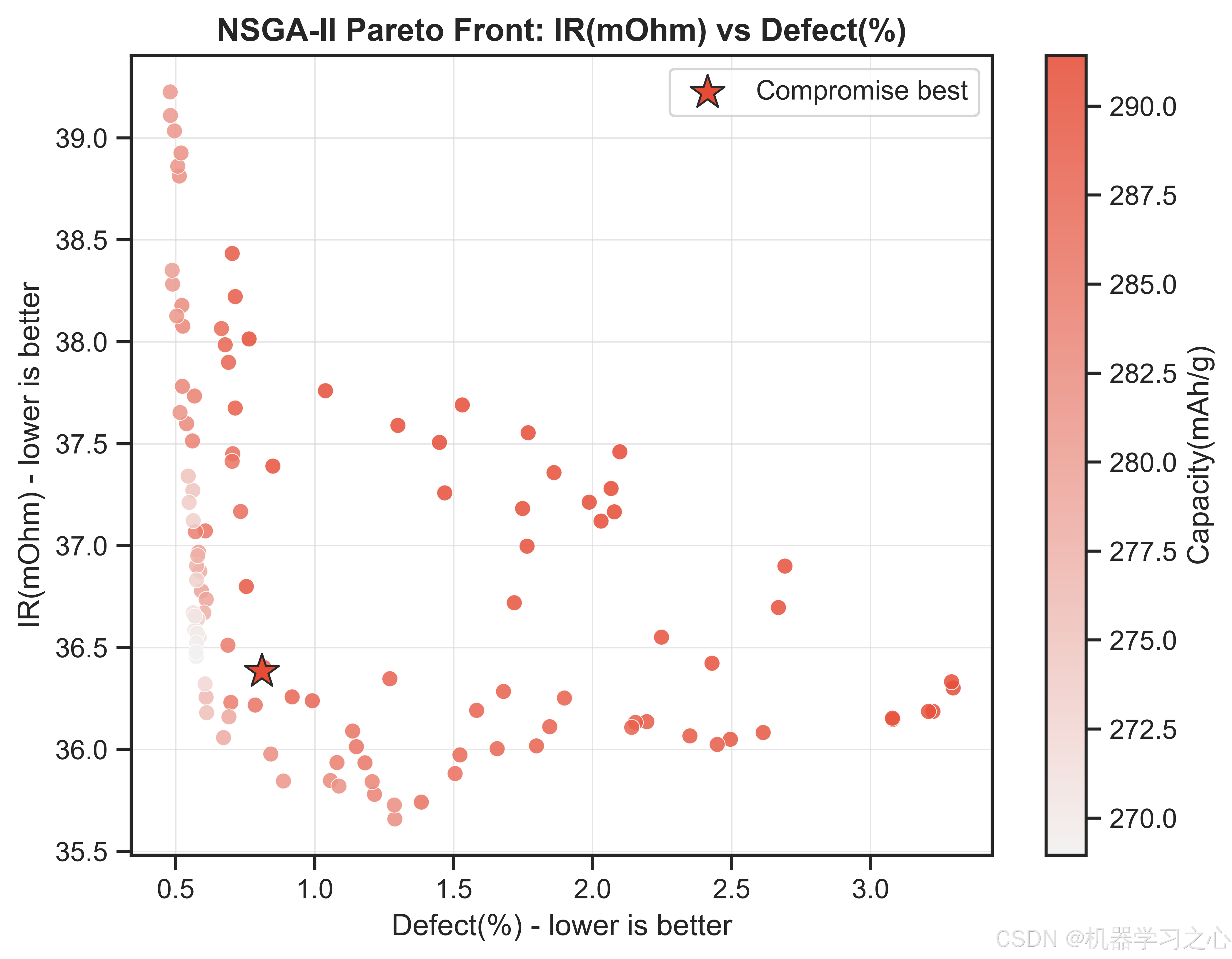
6.2 折中最优解
推荐工艺参数组合(Desirability=0.8382)为:
| 工艺参数 | 推荐值 |
|---|---|
| 涂布速度 | 26.49 m/min |
| 干燥温度 | 117.32 °C |
| 浆料黏度 | 0.573 Pa·s |
| 固含量 | 69.65% |
| 压延压力 | 105.59 MPa |
| 环境湿度 | 20.09%RH |
该参数组合下预测的电池性能为:
- 比容量:287.71 mAh/g
- 内阻:36.38 mOhm
- 表面缺陷率:0.81%
七、SHAP解释:工艺参数如何影响电池性能
SHAP(SHapley Additive exPlanations)基于博弈论中的Shapley值,将模型预测分解为各特征的边际贡献。对于特征j,SHAP值φⱼ定义为该特征在所有可能特征子集上的边际贡献的加权平均:
ϕj=∑S⊆F∖{j}∣S∣!(∣F∣−∣S∣−1)!∣F∣!f(S∪{j})−f(S) \phi_j = \sum_{S \subseteq F \setminus \{j\}} \frac{|S|!(|F|-|S|-1)!}{|F|!} \left f(S \\cup \\{j\\}) - f(S) \\right ϕj=S⊆F∖{j}∑∣F∣!∣S∣!(∣F∣−∣S∣−1)!f(S∪{j})−f(S)
其中F为全体特征集合,S为不包含特征j的任意子集,f(S)为仅使用S中特征时的模型预测。
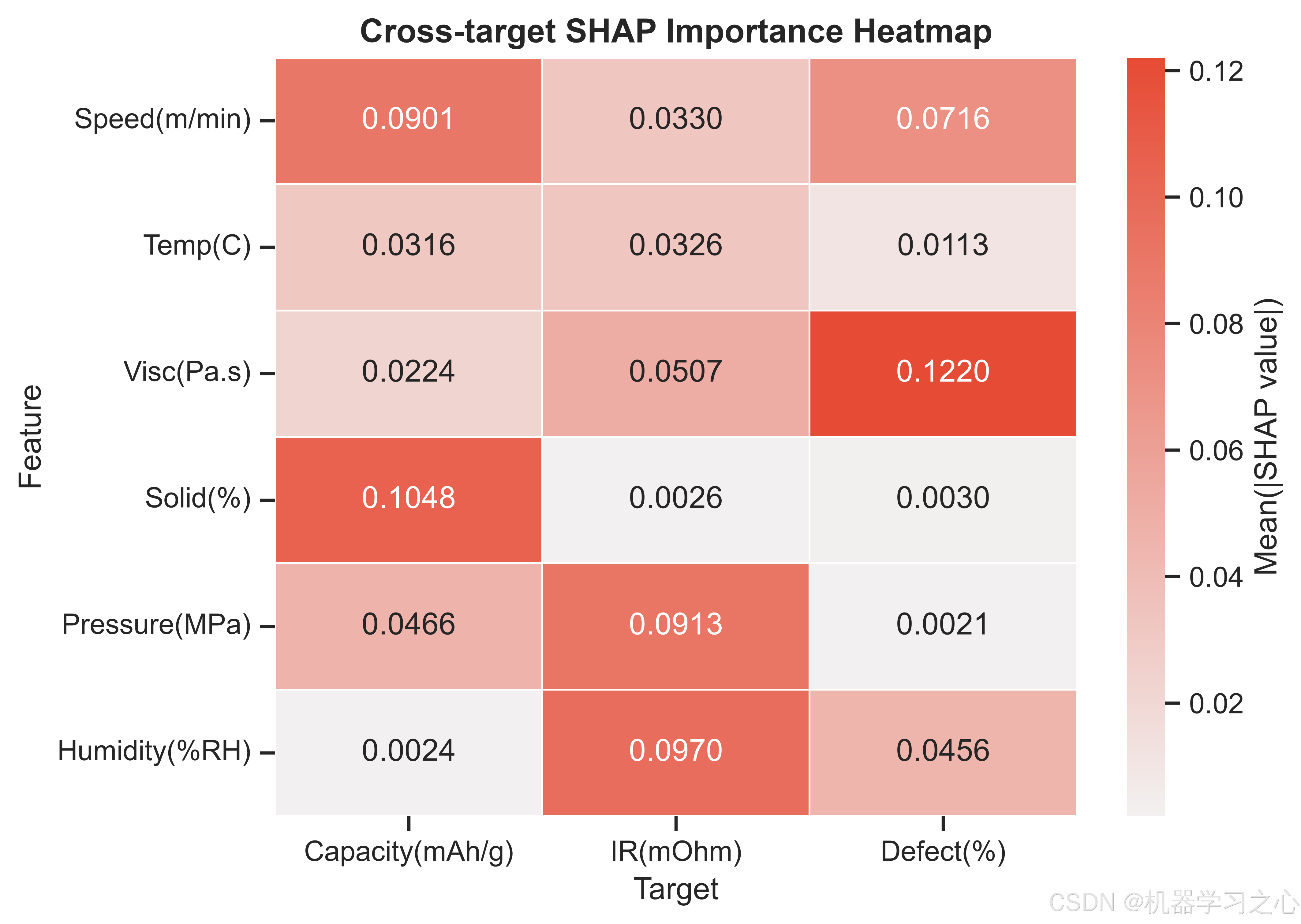
对本项目的三个CatBoost模型分别计算SHAP值,结果如下:
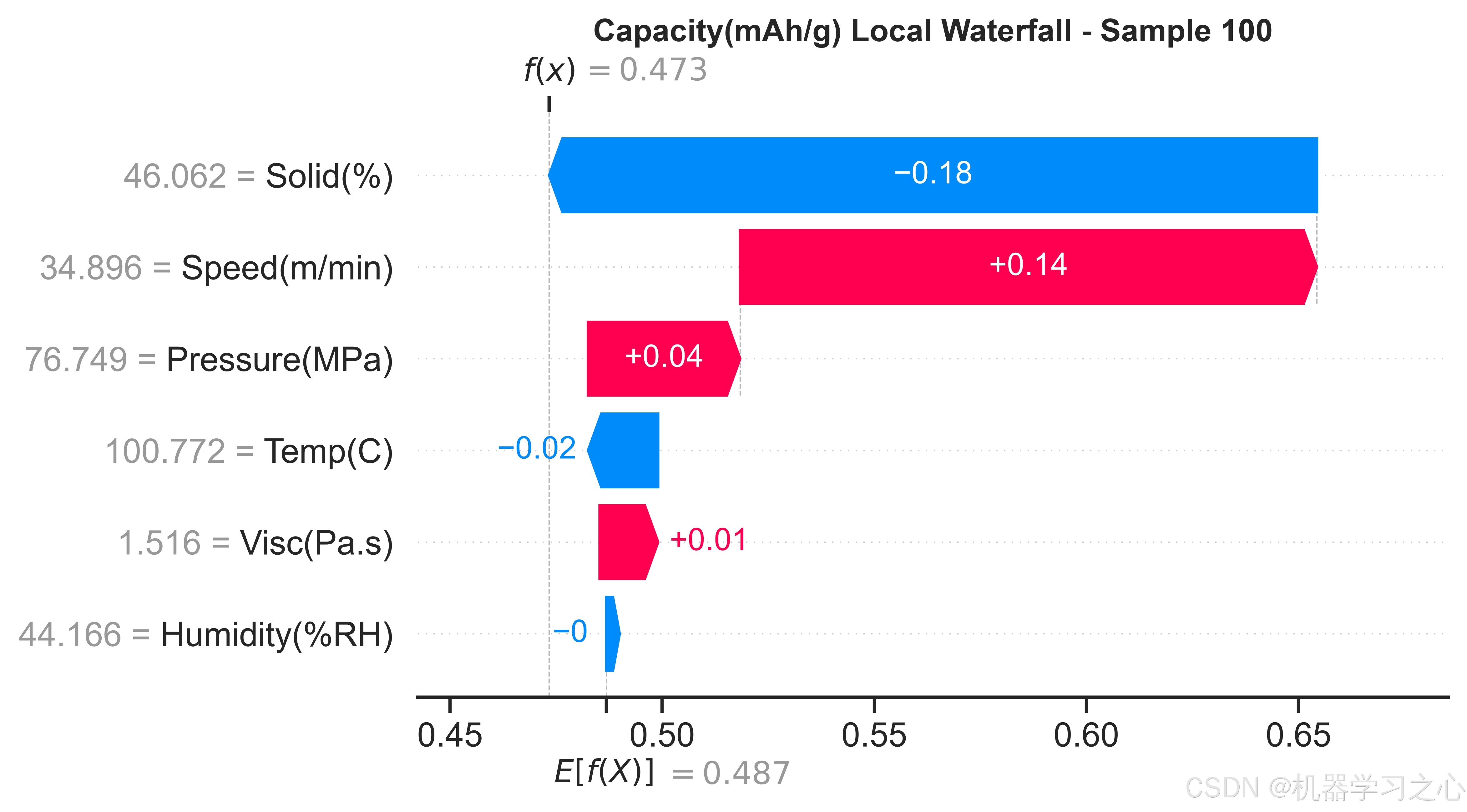
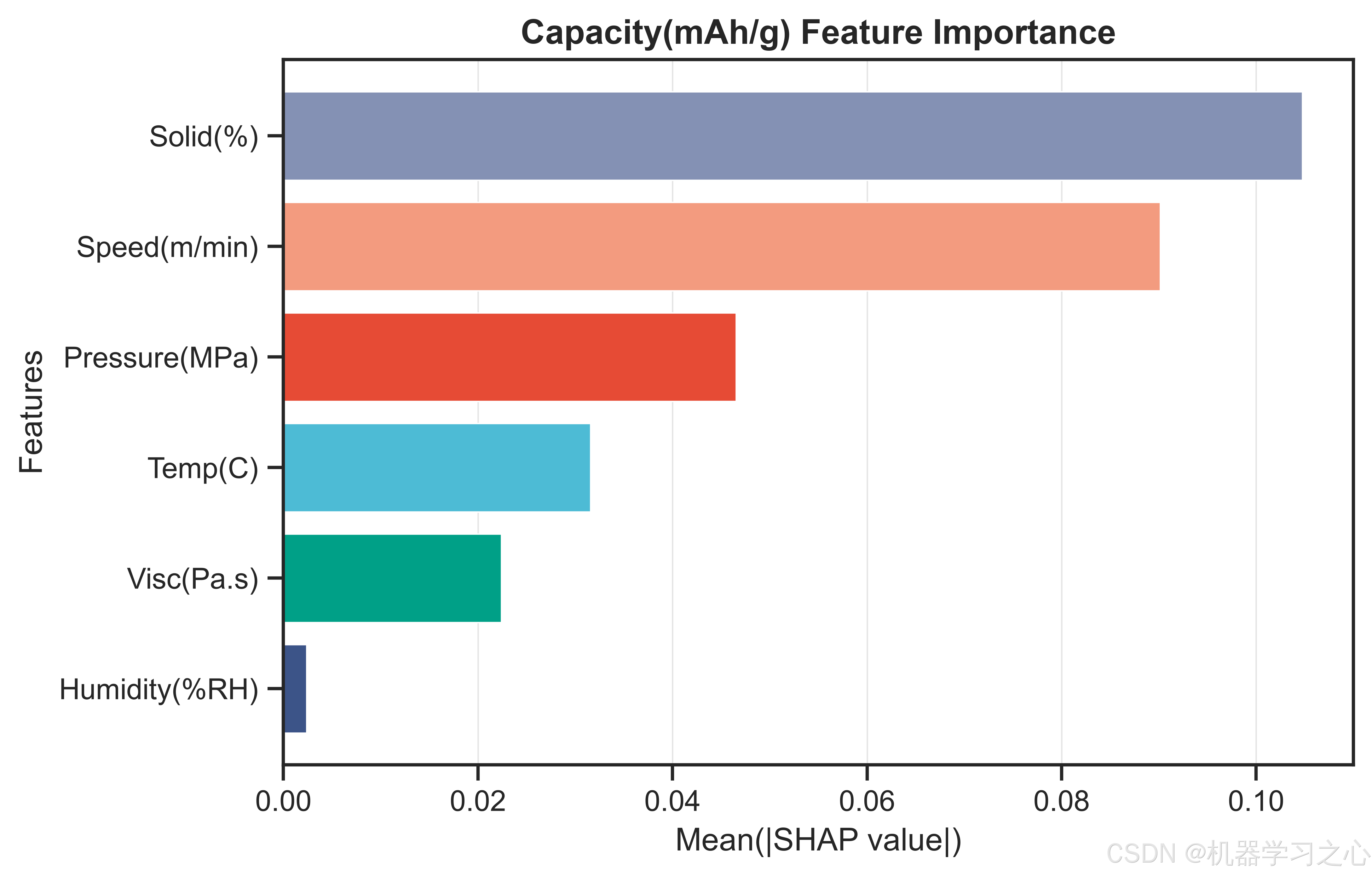
7.1 比容量(Capacity)------ 固含量主导
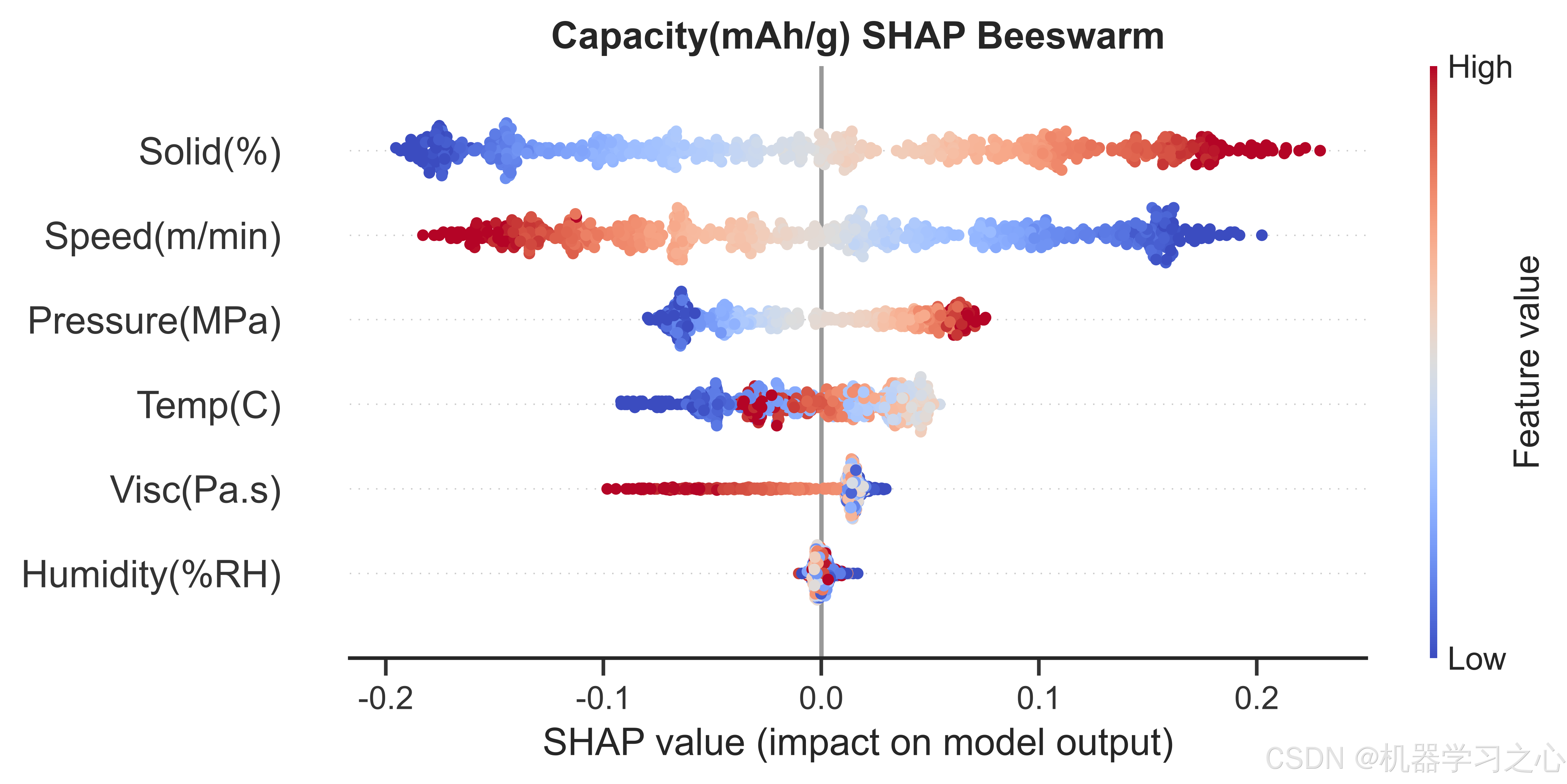
全局特征重要性排名(按Mean|SHAP|):
- Solid(%) --- 0.1048
- Speed(m/min) --- 0.0901
- Pressure(MPa) --- 0.0466
- Temp© --- 0.0316
- Visc(Pa.s) --- 0.0224
- Humidity(%RH) --- 0.0024
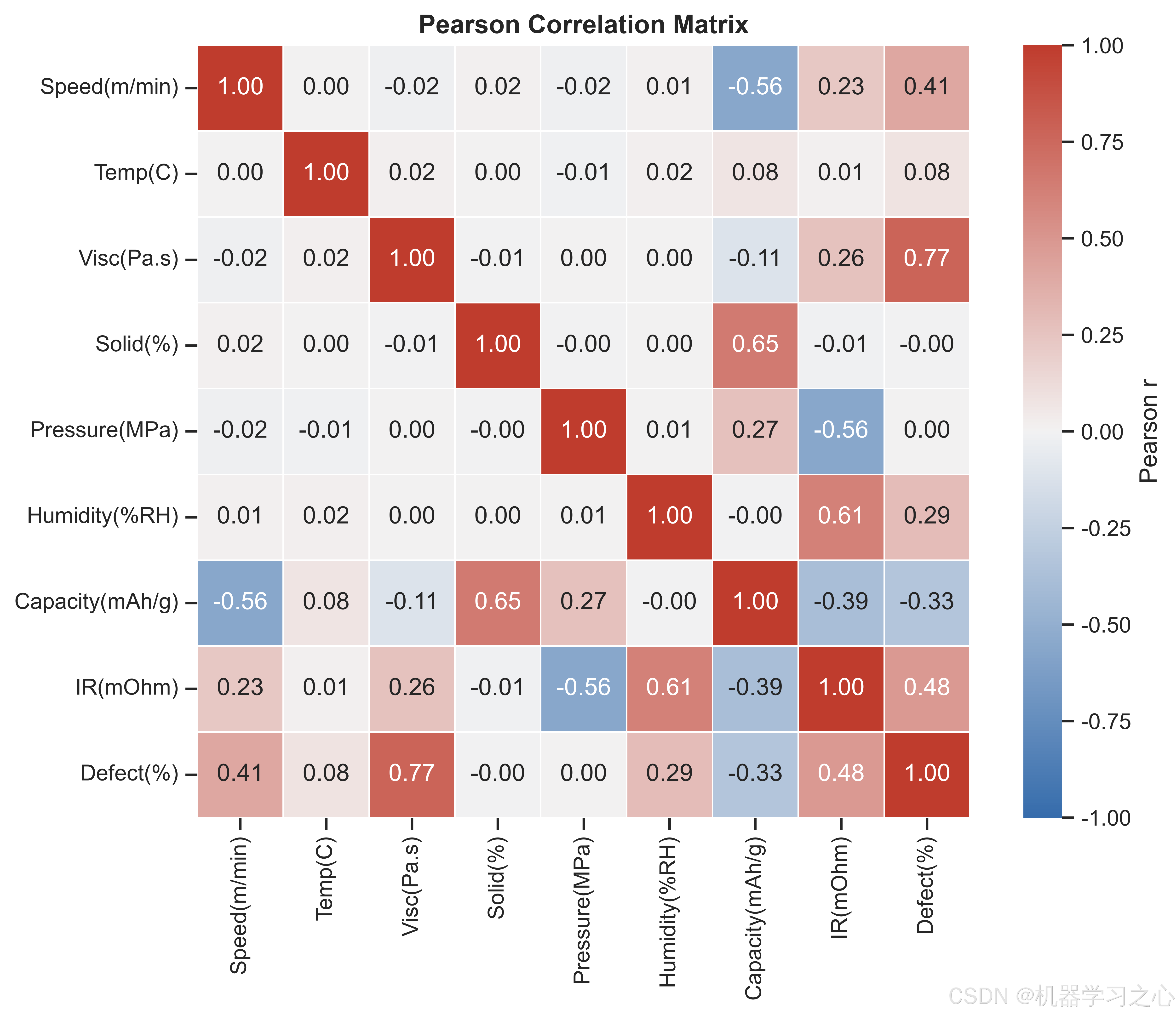
固含量对容量的影响量级约为第二名涂布速度的1.16倍,约是湿度的44倍。SHAP依赖图揭示:固含量在65-72%区间内与容量呈正相关,这符合电化学直觉------更高的活性物质占比提供更多的锂离子嵌入位点。涂布速度的SHAP依赖图呈现出先正后负的趋势:适中的速度(22-30 m/min)有利于容量,过高速度可能导致涂层不均匀、活性物质分布变差。
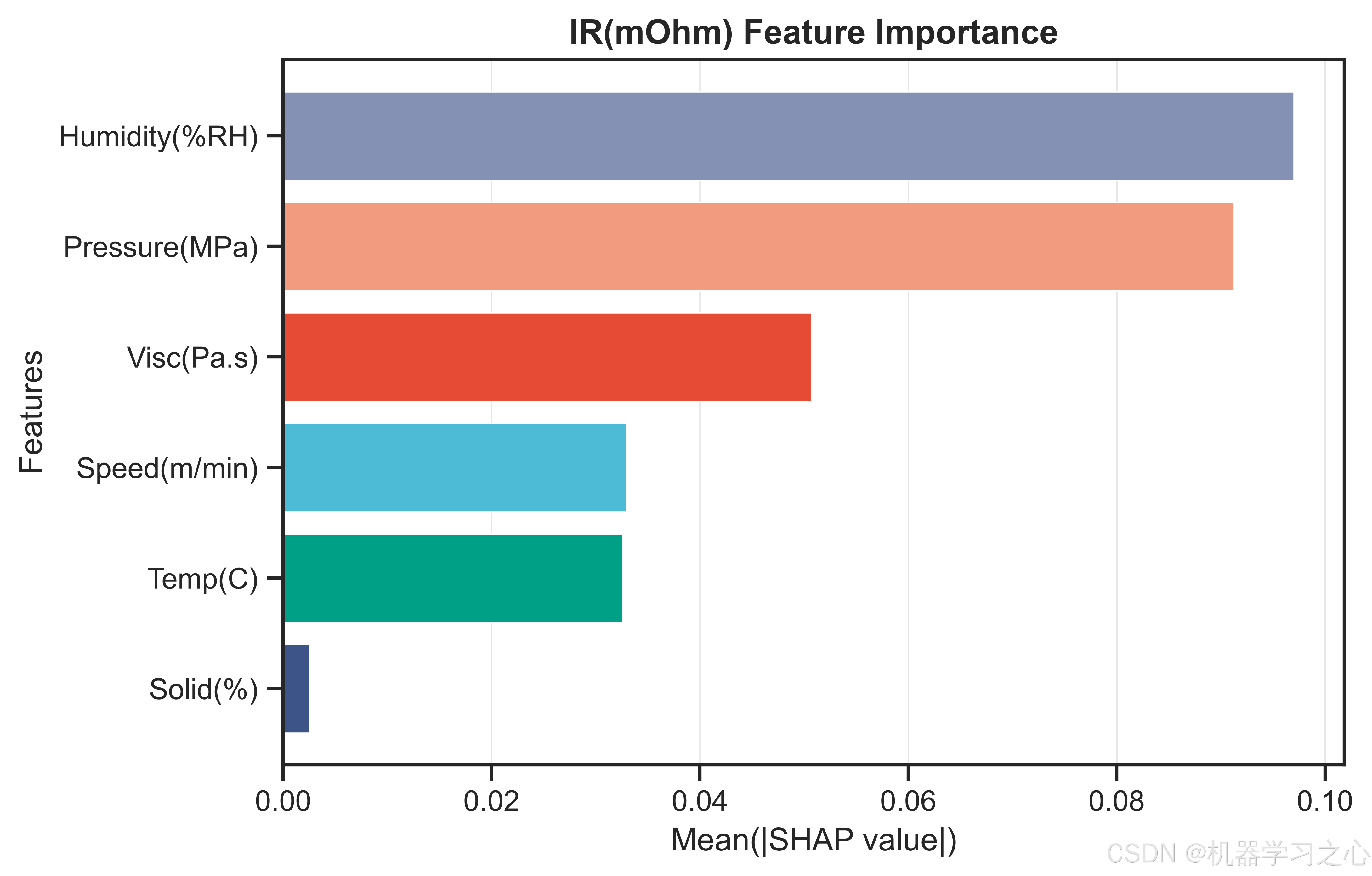
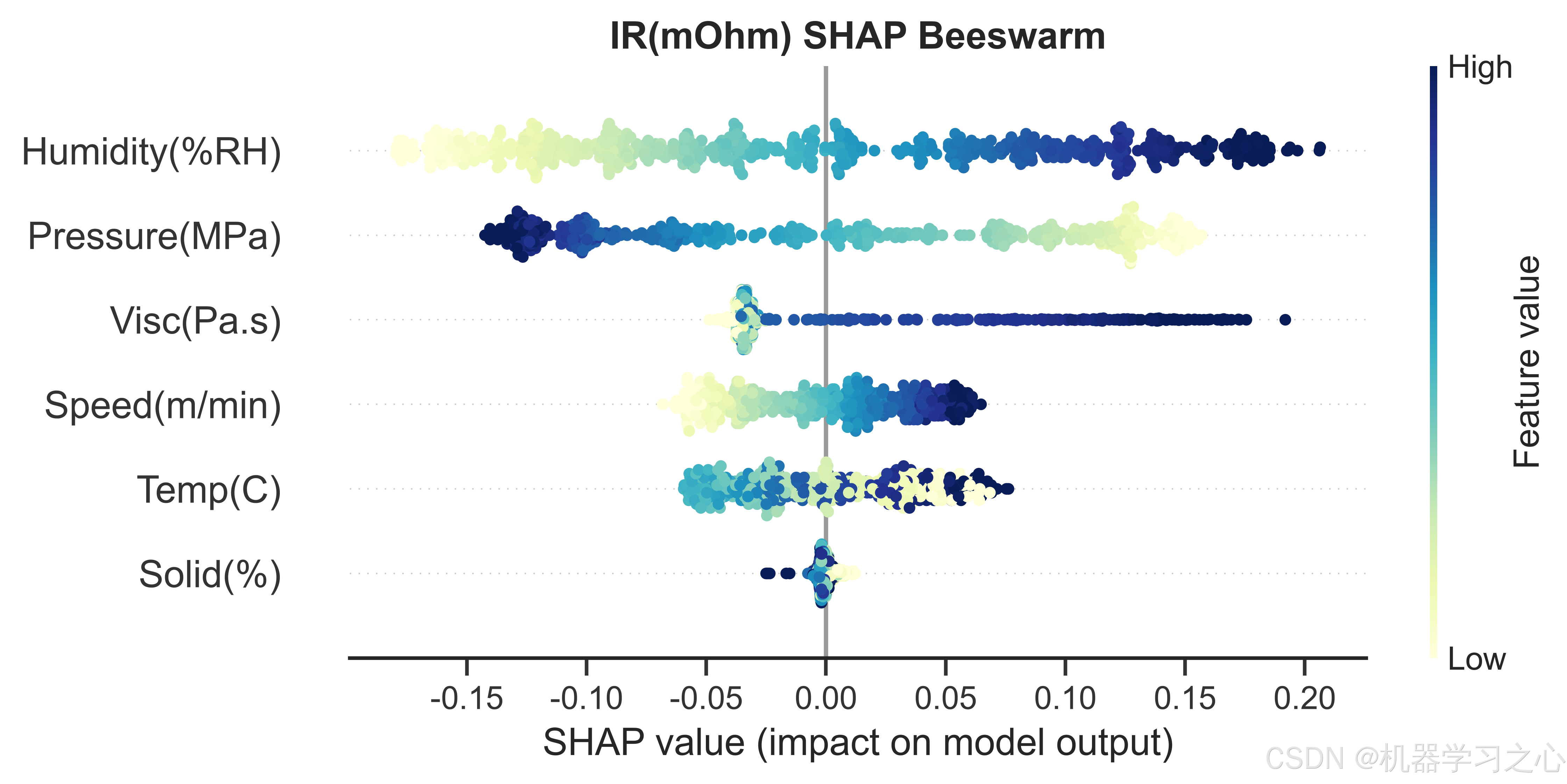
7.2 内阻(IR)------ 压延压力与湿度双核驱动
- Humidity(%RH) --- 0.0970
- Pressure(MPa) --- 0.0913
- Visc(Pa.s) --- 0.0507
- Speed(m/min) --- 0.0330
- Temp© --- 0.0326
- Solid(%) --- 0.0026
压延压力和湿度的SHAP贡献几乎持平,且远高于其他四个特征。这与锂电池物理机理高度吻合:压延压力直接影响极片的孔隙率和压实密度,高压力降低颗粒间接触电阻但过度压缩会破坏活性材料结构;湿度影响电解液中的水分含量,水分与LiPF₆反应生成HF,腐蚀集流体并增加界面阻抗。
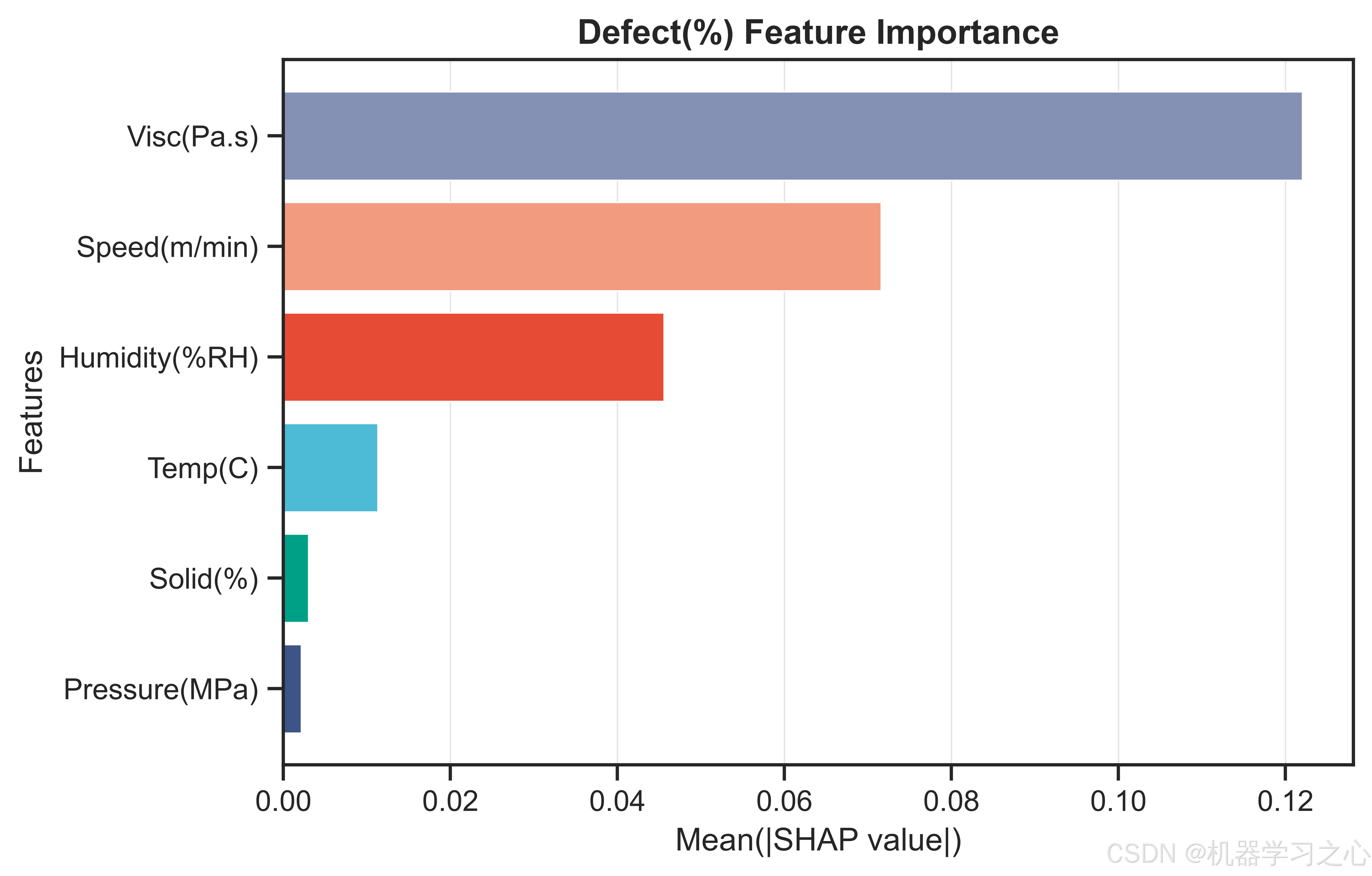
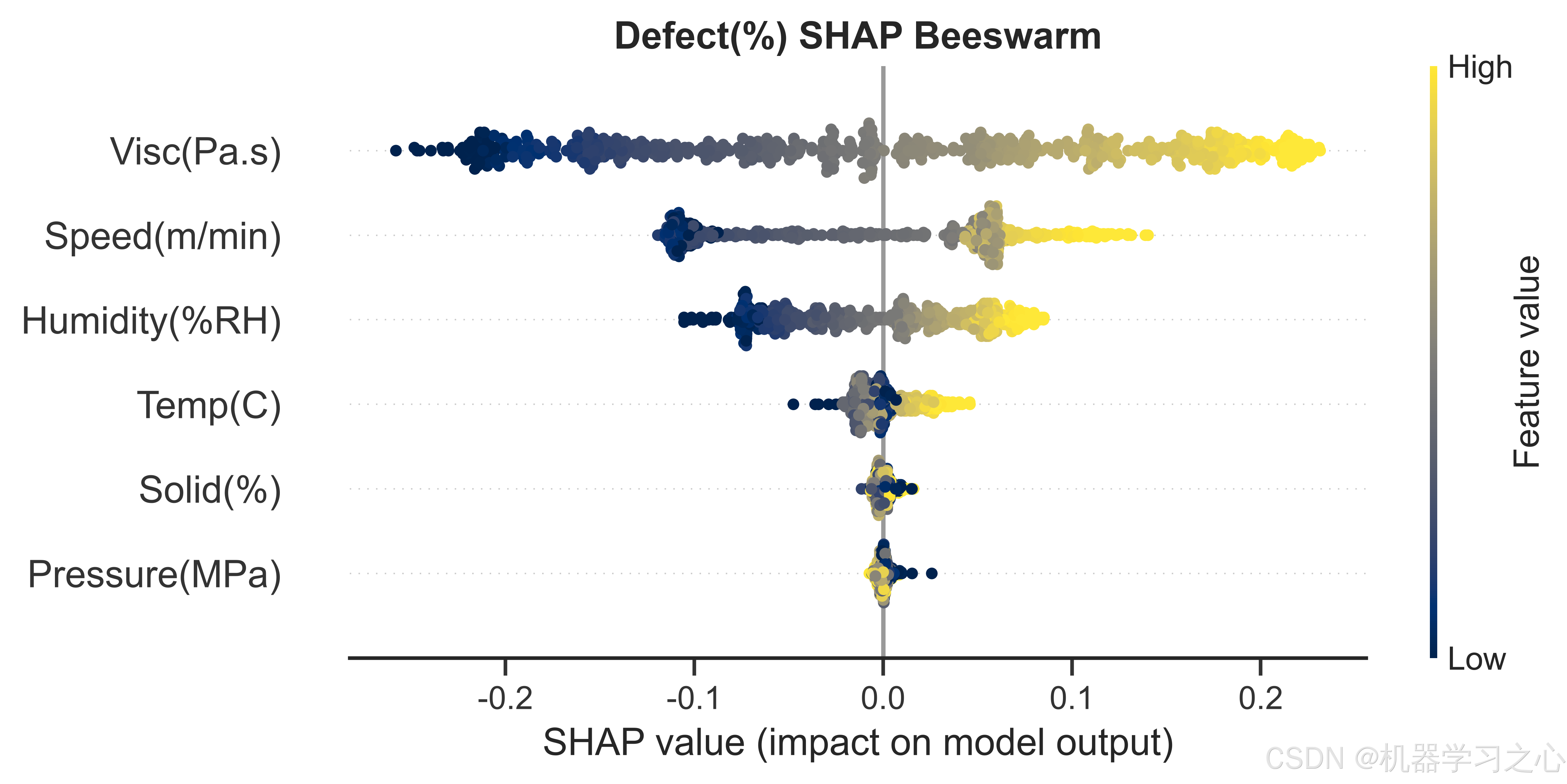
7.3 缺陷率(Defect)------ 黏度一家独大
- Visc(Pa.s) --- 0.1220
- Speed(m/min) --- 0.0716
- Humidity(%RH) --- 0.0456
- Temp© --- 0.0113
- Solid(%) --- 0.0030
- Pressure(MPa) --- 0.0021
浆料黏度的SHAP重要性(0.122)约为第二名涂布速度的1.7倍,形成了明显的断层领先。这直接印证了涂布工艺的工程经验:黏度过高导致浆料流平性差、涂布面密度不均匀;黏度过低则引发浆料沉降和边缘效应。依赖图显示黏度在0.4-0.8 Pa·s区间内对缺陷率的影响相对平缓,超过该区间后缺陷率急剧增加。
八、参数设定汇总
| 参数 | 设定值 | 说明 |
|---|---|---|
| 数据集 | 3000条模拟数据 | 80%训练 / 20%测试 |
| 异常值处理 | IQR, k=1.5 | 仅作用于训练集 |
| 归一化 | MinMaxScaler 0,1 | 输入+输出分别归一化 |
| 代理模型数 | 11个 | 含自研NumPy-LSTM |
| 评价指标 | R², RMSE, MAE, MAPE, EV, MaxErr | 六维综合评价 |
| NSGA-II种群 | 120 | μ=λ=120 |
| NSGA-II代数 | 150 | 约55代后主要收敛 |
| SBX交叉 | ηc=15.0, prob=0.9 | 模拟二进制交叉 |
| 多项式变异 | ηm=20.0 | 1/n_var 逐变量触发 |
| 选择机制 | 二元锦标赛 | 低rank + 高拥挤距离 |
| Pareto解数量 | 120 | 稳定于第20代 |
| SHAP Explainer | TreeExplainer | 优先,失败回退通用Explainer |
| 随机种子 | 42 | 全流程固定 |
九、运行环境
本项目未依赖GPU或分布式集群,在普通Windows/Linux/macOS办公主机上即可完整运行。核心依赖如下:
- Python 3.8+
- NumPy ≥ 1.21, Pandas ≥ 1.3, SciPy ≥ 1.7
- scikit-learn ≥ 1.0
- Matplotlib ≥ 3.5, Seaborn ≥ 0.11
- SHAP ≥ 0.41
- statsmodels ≥ 0.13(LOWESS平滑用)
- CatBoost ≥ 1.0(可选,缺省时自动跳过)
- XGBoost ≥ 1.7(可选,缺省时自动跳过)
图形输出使用Agg后端(非交互模式),支持直接部署在无桌面环境的服务器上批量运行。所有图形以600 DPI保存,配色方案基于Nature/Okabe-Ito SCI论文风格(#3C5488蓝色系为主色调),可直用于期刊投稿。
十、应用场景与工程价值
这套方法论并非"玩具示例",其背后的"代理模型 + 多目标进化优化 + 可解释分析"三件套在真实工业场景中有明确的应用路径。
虚拟工艺窗口探索 --- 产线试错成本极高(材料、能耗、停机时间),代理模型可在秒级时间内遍历数百万种参数组合,定位有潜力的工艺窗口后再进行少量验证实验。本项目中单次NSGA-II运行仅需调用约3.6万次代理模型预测(120种群 × 150代 × 2次预测/代),总耗时在毫秒级。
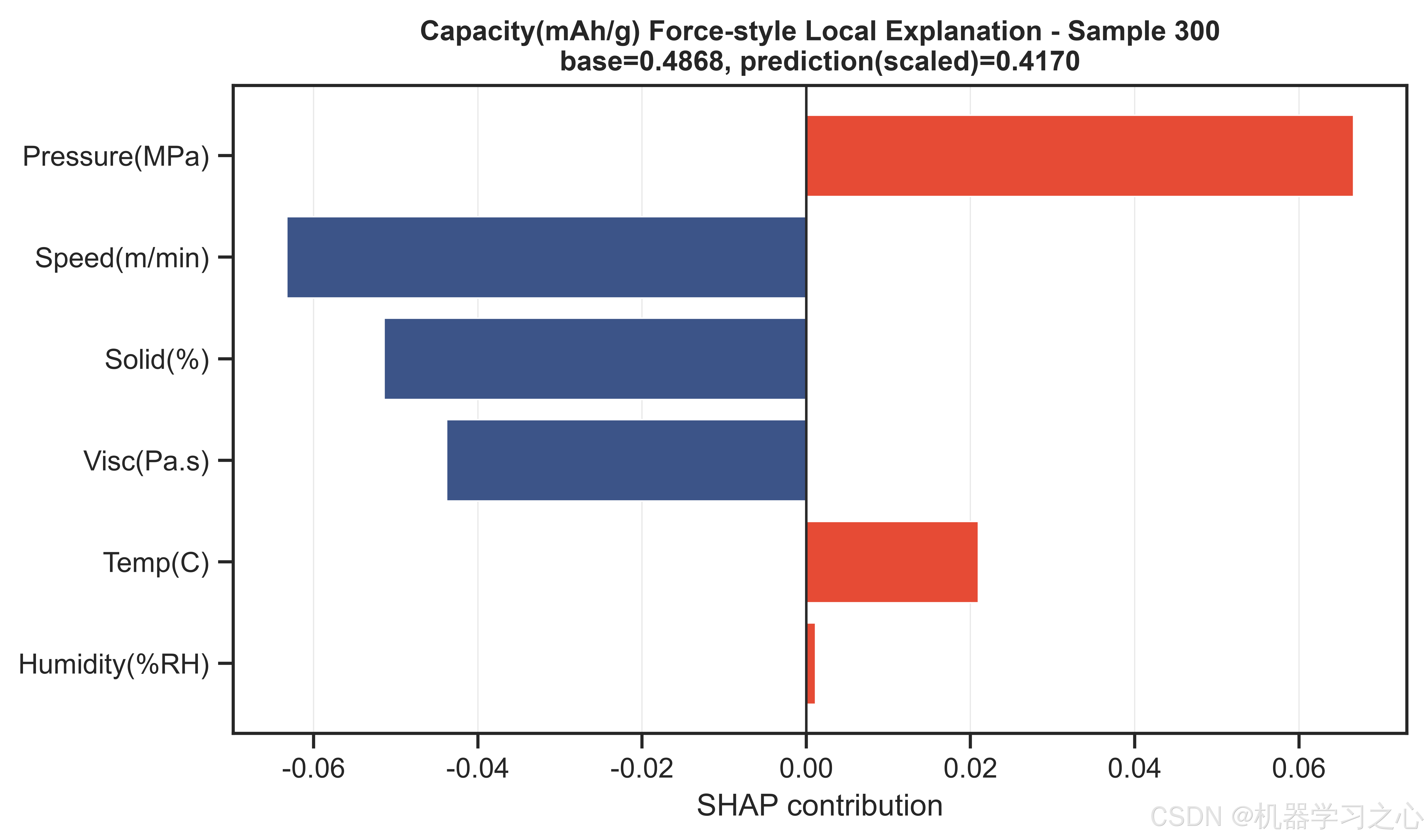
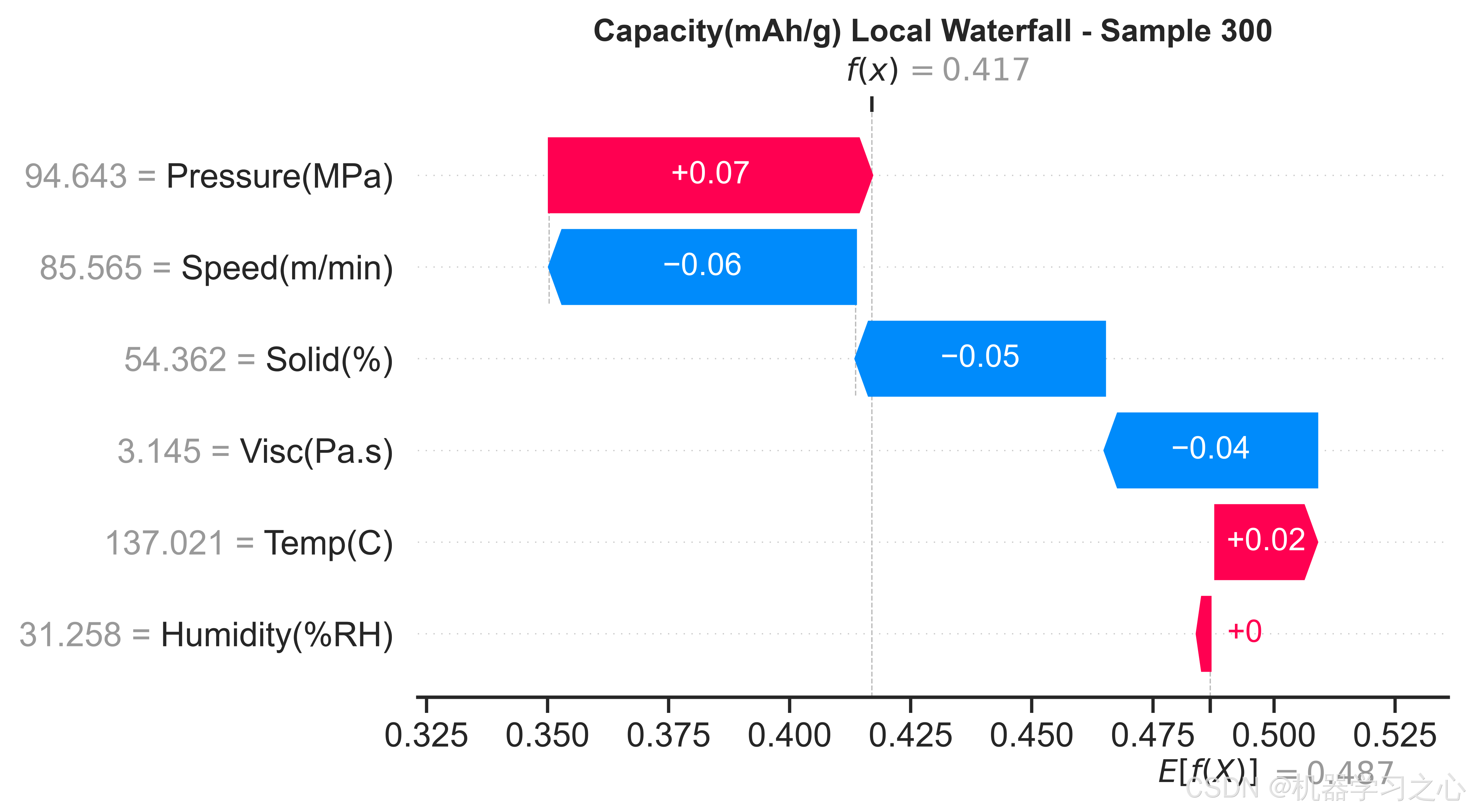
质量溯源与故障诊断 --- SHAP分析提供了逐样本的归因能力。当某批次电池出现异常缺陷率时,可以对异常样本计算SHAP瀑布图,定位是哪个工艺参数的偏离贡献了最大的预测偏移,从而反向追踪产线问题。
鲁棒工艺窗口设计 --- Pareto前沿本身就是一种鲁棒性工具。前沿上的每个点代表一个"边界":给定容量水平下能实现的最低内阻和缺陷率。工程师可以在前沿上选择距离三个目标极端点较远的中间地带,这些点对工艺波动(如温度±2°C的随机扰动)具有更好的容忍度。
模型体系的可扩展性 --- 11个模型的对抗式评估策略可以无缝迁移到其他材料体系(如钠离子电池、固态电解质)或工艺类型(如注液、化成),只需替换输入特征和目标变量的定义。
从工程落地角度看,这套工作流最重要的产出不是某一个具体的工艺参数值,而是一套可复现、可审计、可迁移的计算实验框架。当新材料体系或新设备上线时,只需重新跑一次全流程即可获得适配的工艺指导。