文章目录
- 一、前言
- [二、DeepSeek-OCR 2](#二、DeepSeek-OCR 2)
-
- 图1
-
- 左侧:DeepEncoder (原始架构)
- [右侧:DeepEncoder V2 (新架构)](#右侧:DeepEncoder V2 (新架构))
- 图2
-
- 总体目的:展示并行化查询在不同视觉任务中的应用
- [左侧:DETR (DEtection TRansformer) 架构](#左侧:DETR (DEtection TRansformer) 架构)
- [右侧:BLIP2 架构](#右侧:BLIP2 架构)
- 关键信息点:并行化查询与双向自注意力
- 图3
-
- [DeepEncoder V2(视觉编码器)](#DeepEncoder V2(视觉编码器))
- [DeepSeek-3B (MOE-A570M) Decoder(解码器)](#DeepSeek-3B (MOE-A570M) Decoder(解码器))
- 图4
-
- [1. 总体目的](#1. 总体目的)
- [2. 模块与流程拆解](#2. 模块与流程拆解)
-
- [2.1 局部视图处理 (Local view)](#2.1 局部视图处理 (Local view))
- [2.2 全局视图处理 (Global view)](#2.2 全局视图处理 (Global view))
- [2.3 Token 合并与总计数](#2.3 Token 合并与总计数)
- [3. 关键信息与设计原理](#3. 关键信息与设计原理)
- 图5
-
- [1. 总体目的](#1. 总体目的)
- [2. 符号说明](#2. 符号说明)
- [3. 掩码架构的组成与协作](#3. 掩码架构的组成与协作)
-
- [3.1 左侧:注意力掩码的两种基本类型](#3.1 左侧:注意力掩码的两种基本类型)
- [3.2 右侧:DeepEncoder V2 的最终注意力掩码](#3.2 右侧:DeepEncoder V2 的最终注意力掩码)
- [4. 关键信息与设计原理](#4. 关键信息与设计原理)
- 问题1
-
- [重新理解 Figure 5:注意力掩码 (Attention Mask)](#重新理解 Figure 5:注意力掩码 (Attention Mask))
- 区域拆解与你的疑问解答
- 回答你的核心疑问:是只有右下角有因果顺序吗?
- 问题2
-
- [核心机制:将 2D 视觉顺序问题转化为 1D 语言建模问题](#核心机制:将 2D 视觉顺序问题转化为 1D 语言建模问题)
- 学习过程详解:通过"因果流查询"与"语言建模"
-
- [1. 因果流查询 (Causal Flow Queries) 的引入](#1. 因果流查询 (Causal Flow Queries) 的引入)
- [2. 语言模型作为视觉编码器 (LM as Vision Encoder)](#2. 语言模型作为视觉编码器 (LM as Vision Encoder))
- [3. 数据和标签的质量](#3. 数据和标签的质量)
- [4. 逐步训练策略 (Staged Training Pipelines)](#4. 逐步训练策略 (Staged Training Pipelines))
- 总结学习机制
一、前言
仅供参考,未经实验验证。
二、DeepSeek-OCR 2
论文标题: DeepSeek-OCR 2: Visual Causal Flow(DeepSeek-OCR 2:视觉因果流)
(DeepSeekMath-V2:迈向自我验证的数学推理)
作者: Haoran Wei, Yaofeng Sun, Yukun Li
机构: DeepSeek-AI
发表时间: 2026年1月28日
GitHub: https://github.com/deepseek-ai/DeepSeek-OCR-2
论文地址: https://arxiv.org/pdf/2601.20552
图1
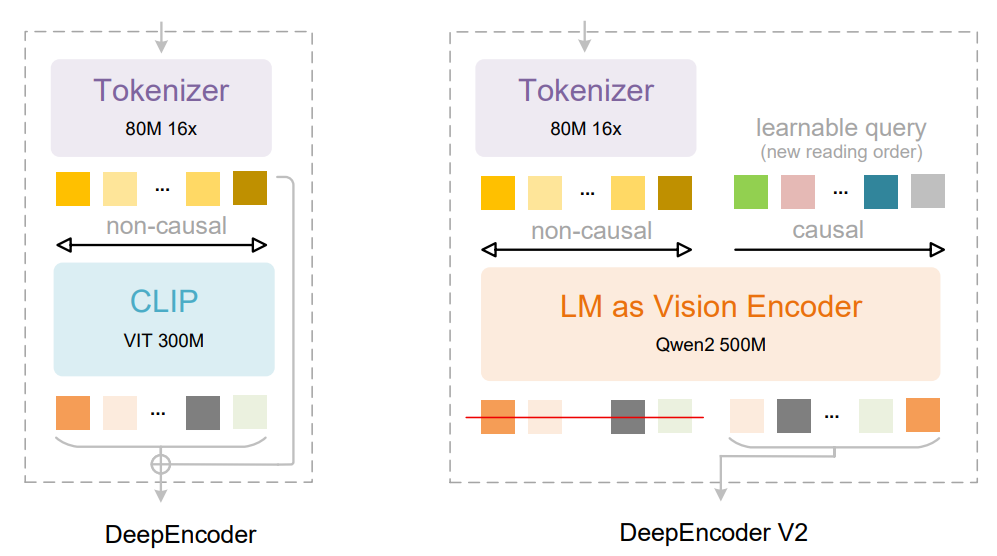
Figure 1 详细展示了 DeepSeek-OCR 模型中视觉编码器 DeepEncoder 的演进,从原始的 DeepEncoder 架构升级到本文提出的 DeepEncoder V2 架构。这张图的核心目的是对比新旧架构,突出 DeepEncoder V2 如何通过引入语言模型风格的编码器和因果流查询(causal flow query)机制,实现视觉token的动态重排序,从而更好地模拟人类的视觉感知和阅读逻辑。
接下来,我们将按照从左到右的顺序,分步详细解析这两个架构:
左侧:DeepEncoder (原始架构)
原始的 DeepEncoder 架构主要由两部分组成:
-
Tokenizer (80M 16x)
- 功能: 这是视觉信息的分词器和压缩器。它接收原始图像作为输入,并将其转化为一系列视觉 token。
- 设计原理: 标签 "80M 16x" 表示它是一个拥有8000万参数的模块,能够将视觉信息进行16倍的压缩。这意味着一张图像会被处理成数量更少、但信息密度更高的视觉 token 序列。
- 特点: 这些视觉 token 被标记为 "non-causal"(非因果),表明它们是以一种固定的、预定义的顺序(例如,从左到右,从上到下)排列的,不具备动态调整顺序的能力。
-
CLIP (ViT 300M)
- 功能: 作为视觉编码器,CLIP (Contrastive Language-Image Pre-training) 的视觉Transformer (ViT) 部分负责从这些非因果的视觉 token 中提取高级特征。它是一个预训练模型,擅长捕捉图像的全局上下文信息。
- 设计原理: CLIP 通常使用双向注意力(bidirectional attention),这意味着每个视觉 token 在处理时可以考虑到序列中的所有其他 token,从而获得全局的感知能力。
- 输出: CLIP 处理后的特征被进一步传递,最终用于下游任务。
总结 DeepEncoder: 这是一个标准的视觉编码器设计,将图像转换为固定顺序的视觉 token,然后通过强大的预训练模型(如 CLIP)提取特征。其局限性在于,它无法根据图像内容的语义结构动态调整视觉 token 的阅读顺序,这与人类灵活的视觉感知模式不符。
右侧:DeepEncoder V2 (新架构)
DeepEncoder V2 是本文的核心创新,旨在解决 DeepEncoder 的局限性。它在 DeepEncoder 的基础上进行了关键性改进:
-
Tokenizer (80M 16x)
- 功能与设计原理: 这部分与原始 DeepEncoder 中的 Tokenizer 相同,负责将图像分词并压缩为 "non-causal" 的视觉 token。
-
LM as Vision Encoder (Qwen2 500M)
- 核心替换: DeepEncoder V2 用一个语言模型(Language Model, LM)风格的架构取代了原始的 CLIP 组件。这里具体实例化为 Qwen2 500M,这是一个拥有5亿参数的语言模型。
- 设计动机: 引入语言模型架构是为了利用其处理序列数据的强大能力和因果推理机制。
- 双流注意力机制: 这是其关键创新。
- 左侧 (non-causal): 原始的视觉 token 仍然采用双向注意力(bidirectional attention)。这确保了它们能够像 CLIP ViT 一样,保留对整个图像的全局建模能力,捕捉视觉特征的完整上下文。
- 右侧 (causal): 引入了**"learnable query"(可学习查询),这些查询被称作"causal flow query"(因果流查询)。这些查询采用 因果注意力(causal attention),即每个查询 token 只能关注它自己以及它之前的视觉 token 和查询 token。这意味着这些查询可以 逐步地、有顺序地处理信息,并动态地调整视觉 token 的逻辑顺序**("new reading order")。
-
Causal Flow Query (可学习查询)
- 作用: 这些可学习查询是 DeepEncoder V2 实现"视觉因果流"的核心。它们被附加在视觉 token 序列之后,通过因果注意力机制,能够根据图像语义智能地重构和排序视觉信息。
- 工作机制: 论文中提到,每个查询 token 可以关注所有的视觉 token 和所有先前的查询 token。这种设计使得查询能够**渐进式地(progressive)**对视觉信息进行因果重排序。这就像人类在阅读复杂文档时,眼球会根据语义线索灵活跳跃和回溯,而不是严格遵循从左到右、从上到下的固定模式。
总结 DeepEncoder V2: DeepEncoder V2 通过将视觉编码器替换为语言模型风格的架构,并引入了带有因果注意力机制的可学习查询,赋予了模型动态重排序视觉 token 的能力 。这种设计使得模型能够基于图像的语义结构,而非简单的空间坐标,生成一个更符合人类视觉感知和阅读逻辑的视觉信息序列。最终,只有这些经过因果重排序的查询输出(而非全部视觉 token)被送入后续的 LLM 解码器,从而实现了更深层次的视觉理解和推理。
通过这一创新,DeepSeek-OCR 2 旨在弥合 2D 图像结构与 1D 语言模型处理序列数据之间的鸿沟,为文档理解等任务带来显著的性能提升,尤其是在处理复杂布局的文档时。
图2
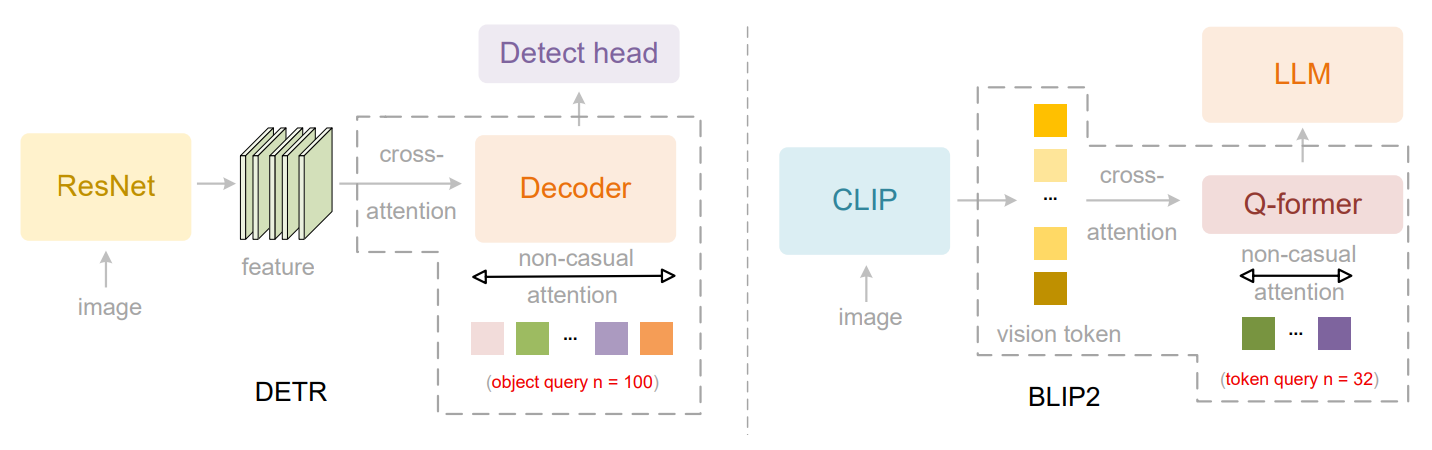
图2详细展示了两种先进的计算机视觉模型架构:DETR (用于目标检测)和 BLIP2(用于视觉Token压缩),它们都采用了**并行化查询(Parallelized Queries)**的核心思想。本图的目的是通过对比这两种模型,阐明并行化查询如何在不同任务中被有效利用,并且都依赖于查询之间的双向自注意力机制。
接下来,我将像一位专业的讲解员一样,分步详细解析这两个架构。
总体目的:展示并行化查询在不同视觉任务中的应用
DETR和BLIP2虽然解决的问题不同(DETR侧重于直接从图像中检测目标,而BLIP2侧重于高效地将视觉信息压缩并对齐到语言模型),但它们都突破了传统序列处理的限制,引入了"并行化查询"这一概念。这意味着模型不再需要像处理文本序列那样严格地从左到右或从上到下处理所有视觉信息,而是通过一组可学习的查询(Queries)并行地提取和压缩关键信息。
左侧:DETR (DEtection TRansformer) 架构
DETR是一种创新的目标检测模型,它将Transformer架构引入目标检测领域,实现了端到端的检测,无需复杂的NMS(非极大值抑制)等后处理步骤。
-
输入与特征提取:
image(图像输入): 原始图像作为模型的输入。ResNet(骨干网络): 图像首先通过一个ResNet骨干网络(或其他CNN),提取出多尺度的图像特征feature。这些特征包含了图像的语义和空间信息。
-
解码器 (Decoder):
cross attention(交叉注意力): 解码器接收ResNet提取的feature。它通过交叉注意力机制,让查询(Queries)能够"看到"并从图像特征中提取相关信息。object query n = 100(目标查询): DETR的核心创新之一是使用了一组固定数量(这里是100个)的可学习查询,称为"目标查询"(object query)。这些查询是可学习的嵌入向量,它们在训练过程中学会编码关于潜在目标的先验知识,例如形状、大小和位置。non-causal attention(非因果注意力 / 双向自注意力): 这些目标查询之间会进行双向自注意力(bidirectional self-attention)。这意味着每个目标查询在处理时可以相互参考,交换信息。例如,一个查询可能最初关注图像的某个区域,通过与其他查询的交互,它能了解到其他查询关注的区域,从而更好地理解整个场景中的目标关系,并调整自身的关注点,共同形成对图像中所有目标的预测。这种并行处理和信息交互是DETR能够直接预测目标集合的关键。- 输出到
Detect head: 解码器处理后的查询表示被送入Detect head。
-
检测头 (Detect head):
Detect head: 这是一个简单的预测网络,它接收解码器输出的每个目标查询的最终表示,并将其转换为具体的检测结果,包括目标的类别和边界框坐标。
DETR的设计原理和目标: DETR旨在简化目标检测流程。通过使用一组可学习的并行查询和Transformer解码器,它直接将图像特征转换为一组目标预测,摆脱了传统检测方法中复杂的锚框设计和NMS步骤,实现了端到端的检测。
右侧:BLIP2 架构
BLIP2是一种高效的视觉-语言预训练模型,其核心目标是高效地将冻结的预训练图像编码器(如CLIP)与冻结的预训练语言模型(LLM)对齐,实现多模态理解。
-
输入与视觉Token提取:
image(图像输入): 原始图像作为模型输入。CLIP(视觉编码器): 图像首先通过一个预训练好的视觉编码器,例如CLIP的视觉Transformer(ViT)部分。CLIP将图像编码成一系列的视觉Token (vision token)。这些视觉Token包含了图像的局部和全局视觉信息。
-
Q-former (查询转换器):
cross attention(交叉注意力): Q-former接收CLIP输出的vision token。它通过交叉注意力机制,让其内部的查询(Queries)能够从大量的视觉Token中提取和聚合信息。token query n = 32(Token查询): BLIP2的核心是Q-former,它使用了一组少量(这里是32个)的可学习查询,称为"Token查询"(token query)。这些查询是可学习的嵌入向量,它们被设计用来从数百个视觉Token中提取最具代表性和压缩性的信息。non-causal attention(非因果注意力 / 双向自注意力): 这些Token查询之间也会进行双向自注意力(bidirectional self-attention)。与DETR类似,这允许查询之间相互交流信息,协同工作,以更好地压缩和提炼视觉特征。这种机制确保了即使查询数量很少,也能捕捉到图像的全局上下文,并且相互之间能够形成一个连贯的表示。- 输出到
LLM: Q-former处理后的32个Token查询的表示被送入后续的LLM。
-
大型语言模型 (LLM):
LLM: 这是一个预训练好的大型语言模型(如OPT、FlanT5等)。Q-former将视觉信息压缩成LLM能够理解的少量Token,这些Token随后作为LLM的输入,使其能够进行视觉-语言任务,如图像描述、视觉问答等。
BLIP2的设计原理和目标: BLIP2旨在解决将大量视觉信息直接输入到LLM的计算效率问题,并弥合视觉和语言模态之间的语义鸿沟。通过Q-former中的少量并行化查询,它能够高效地从视觉编码器中提取并压缩关键视觉特征,然后将其传递给LLM,从而实现强大的多模态理解能力,同时保持计算效率。
关键信息点:并行化查询与双向自注意力
无论是DETR的"目标查询"还是BLIP2的"Token查询",它们都体现了并行化查询的核心理念:
- 并行处理: 一组查询可以同时处理,而不是顺序处理,大大提高了效率。
- 可学习性: 这些查询是可学习的,意味着它们在训练过程中会根据任务需求,自动学习如何关注图像中的特定信息。
- 双向自注意力: 两种模型中的查询都使用
non-causal attention(即双向自注意力)。这是至关重要的,它使得查询之间能够充分地相互作用、交换信息,从而共同构建一个更丰富、更全局的理解。例如,在DETR中,一个查询可以根据另一个查询的预测来调整自己的目标边界框;在BLIP2中,查询可以协同压缩视觉信息,确保没有遗漏关键的视觉概念。
总而言之,图2展示了并行化查询作为一种强大的机制,如何在不同视觉任务中实现高效的信息提取、压缩和理解,为现代计算机视觉和多模态模型提供了重要的架构基础。
图3
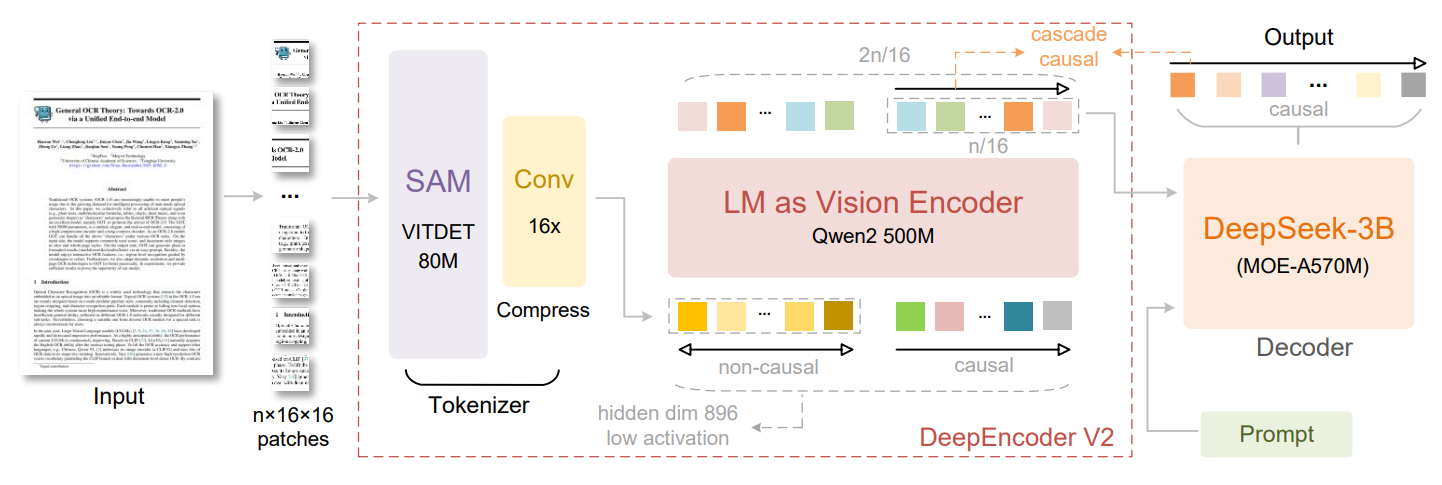
图3展示的是 DeepSeek-OCR 2 的整体架构,特别是其核心组件 DeepEncoder V2 的设计理念和工作流程。
总体目的:
该图旨在说明 DeepSeek-OCR 2 如何通过引入一个全新的编码器------DeepEncoder V2------来处理图像输入,并将其转化为语言模型(LM)可理解的视觉序列。相较于前代 DeepEncoder,DeepEncoder V2 的核心创新在于用一个类语言模型(LM-style)的架构替换了原有的 CLIP 模块,并通过定制化的注意力掩码(attention mask),实现了对视觉 Token 的因果建模(causal modeling)和更高效的知识压缩,从而更好地模拟人类阅读文档时的因果推理过程。
架构分步解析:
整个 DeepSeek-OCR 2 的架构可以被清晰地划分为**编码器(DeepEncoder V2)和解码器(DeepSeek-3B)**两大部分。
DeepEncoder V2(视觉编码器)
DeepEncoder V2 是整个系统的关键创新点,其内部包含以下主要模块:
-
Tokenizer(分词器)
- 输入: 原始图像(通常是文档页面)。图像首先被分割成
n × 16 × 16的小块(patches)。 - 模块组成:
- SAM VITDET 80M: 这是一个基于 SAM (Segment Anything Model) 的视觉 Transformer (ViT) 检测器,拥有 80M 参数。它负责从图像中提取初步的视觉特征。
- Conv (16x): 卷积层,用于进一步处理 SAM 的输出,并实现
16倍的 Token 压缩。
- 功能和设计原理:
- 特征提取与压缩: 这个 Tokenizer 的主要作用是将高分辨率的 2D 图像转化为一系列低维度的视觉 Token。通过 16 倍的压缩,它显著减少了后续处理的计算成本和内存占用。
- 知识继承: 它继承了 DeepEncoder 的视觉 Token 压缩机制,确保了高效的特征表示。
- 输出: 经过压缩的视觉 Token 序列。
- 输入: 原始图像(通常是文档页面)。图像首先被分割成
-
LM as Vision Encoder (Qwen2 500M)(作为视觉编码器的语言模型)
- 输入: Tokenizer 输出的视觉 Token 序列。
- 模块组成: 这是一个基于 Qwen2 (500M 参数) 的轻量级语言模型架构。
- 功能和设计原理:
- 核心创新: 这是 DeepEncoder V2 与 DeepEncoder 的主要区别。它将一个语言模型用作视觉编码器,旨在赋予其处理视觉信息时像语言模型那样进行因果推理的能力。
- 双流注意力机制:
- "non-causal"部分(非因果): 这部分对应于原始的视觉 Token。它们之间采用双向自注意力(bidirectional attention),类似于传统的 ViT,允许每个视觉 Token 能够"看到"并聚合所有其他视觉 Token 的信息,从而保持全局的上下文建模能力(类似于 CLIP 的能力)。这些 Token 保留了原始视觉特征的丰富性。
- "causal"部分(因果): 这部分是新引入的可学习查询(learnable queries) ,被称为"因果流 Token(causal flow tokens)"。它们被附加在视觉 Token 之后。这些查询采用因果注意力(causal attention),类似于解码器式的 LLM,即每个查询只能"看到"它自身以及其之前的视觉 Token 和因果流 Token。
- 视觉 Token 重排序能力: 通过这种特殊的注意力掩码(图5有更详细的解释),因果流查询能够智能地重新排序视觉 Token,以更好地反映文档的语义阅读顺序,从而模拟人类视觉感知的因果驱动流。这解决了传统 VLM 中僵化的栅格扫描顺序(top-left to bottom-right)与人类灵活阅读模式不符的问题。
- 信息蒸馏: 最终,只有这些"因果流 Token"的输出(图中的
cascade causal部分)会被送入到后续的解码器。这意味着这个 LM-style 视觉编码器不仅能理解图像内容,还能将这些内容按照有意义的阅读顺序进行"蒸馏"和组织。
- 输出: 一组经过因果重排序和语义提炼的视觉特征表示(即
cascade causalToken)。
DeepSeek-3B (MOE-A570M) Decoder(解码器)
- 输入:
- DeepEncoder V2 输出的因果流 Token。
- Prompt(提示): 用户提供的文本提示,用于指导解码器生成特定的输出。
hidden dim 896,low activation: 这表示编码器与解码器之间的接口,其中hidden dim 896是特征维度,low activation可能指向某种优化策略或特征特性。
- 模块组成:
- 这是一个 DeepSeek-3B 的解码器,采用了 MoE (Mixture-of-Experts) 架构,拥有约 500M 的活跃参数。
- 功能和设计原理:
- 语言生成: 解码器接收来自编码器的视觉信息和文本提示,然后执行自回归推理,生成最终的输出序列。
- 继承与优化: DeepSeek-OCR 2 沿用了 DeepSeek-OCR 的解码器,主要专注于编码器的改进。MoE 架构有助于在保持高性能的同时提高效率。
- 级联因果推理: 编码器负责视觉 Token 的语义重排序,而解码器则在这些已经因果排序的表示上执行进一步的自回归推理。这形成了一个两阶段的级联因果推理结构,旨在实现更深层次的 2D 图像理解。
- 输出: 最终的文本输出序列,反映了对输入图像内容的理解和解析(例如,文档的文本内容和阅读顺序)。
总结与关键设计:
DeepSeek-OCR 2 的核心在于其 DeepEncoder V2。它通过将一个 Qwen2 语言模型改造为视觉编码器,并巧妙地结合了双向自注意力(用于原始视觉 Token 的全局上下文理解)和因果注意力(用于可学习查询的语义重排序),从而实现了对文档视觉内容的"因果流"建模。这种设计能够更好地模拟人类灵活的视觉感知和阅读模式,克服了传统 VLM 中固定栅格扫描顺序的局限性,最终在文档阅读逻辑和 OCR 性能上取得了显著提升。
图4
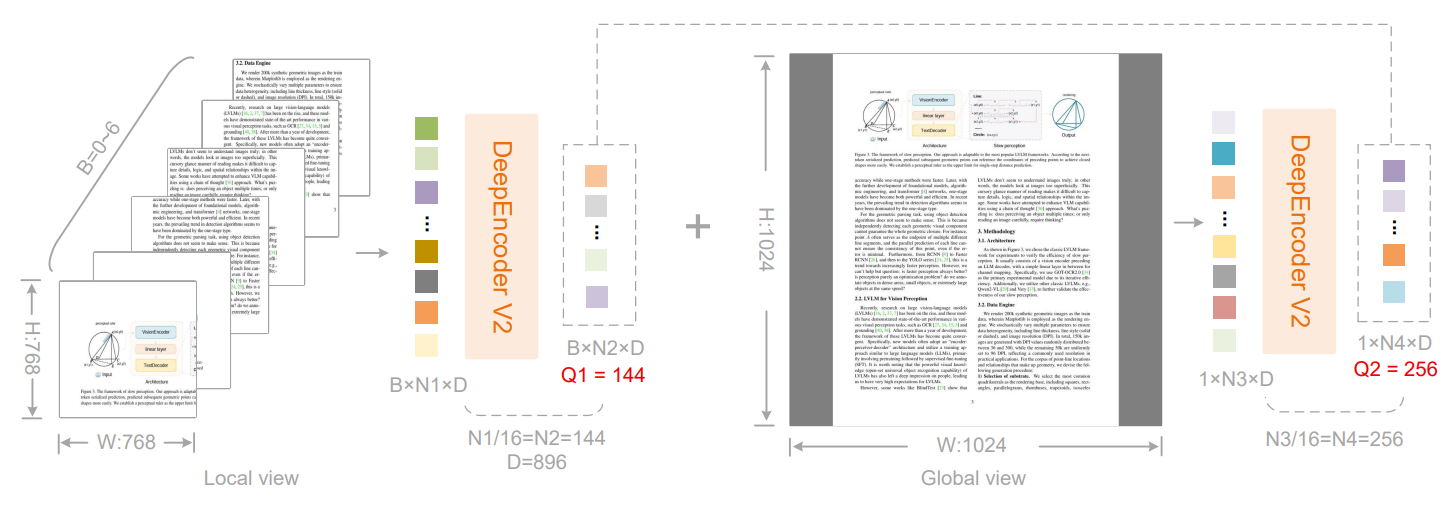
图4详细展示了 DeepSeek-OCR 2 中 DeepEncoder V2 如何通过多裁剪(multi-crop)策略来计算并生成视觉 Token 的数量。这个策略的目的是为了有效地处理不同尺寸和复杂布局的图像,并确保编码器能够获得足够且灵活的视觉信息来执行因果推理。
1. 总体目的
这张图的核心目的是解释 DeepEncoder V2 如何根据输入图像的尺寸和是否采用局部裁剪,动态地产生总计 256 到 1120 个视觉 Token 。它通过结合一个固定的**全局视图(Global view)和可选的多个局部视图(Local view)**来实现这一目标,从而在保持高效信息压缩的同时,为后续的语言模型解码器提供丰富且语义有序的视觉信息。
2. 模块与流程拆解
该图将视觉 Token 的生成过程分为两个主要部分:局部视图处理 和全局视图处理,它们的结果最终会被整合。
2.1 局部视图处理 (Local view)
- 输入图像分辨率: 局部视图通常处理分辨率为
H:768 × W:768的图像区域。这代表了从原始大图中裁剪出的较小、聚焦的区域。 - 多裁剪策略 (
B=0~6):B表示局部裁剪的数量,可以从0到6个不等。这意味着系统可以根据需要,从原始图像中提取0到6个768 × 768的局部区域进行分析。- 设计动机: 这种多裁剪策略允许模型聚焦于图像中的特定细节,尤其对于文档中包含复杂图表、小字体文本或非线性布局的区域,能够提供更精细的视觉输入。
- DeepEncoder V2 处理:
- 每个局部裁剪后的
768 × 768图像块都会被送入 DeepEncoder V2 进行处理。 - Tokenization (N1/16=N2=144): DeepEncoder V2 内部的视觉分词器(如图3所示的 SAM-Conv 模块)会将
768 × 768的图像压缩成更少的视觉 Token。具体来说,N1是原始 Token 数量,经过16倍压缩后得到N2个 Token。对于768 × 768的图像,N2 = (768/16) * (768/16) = 48 * 48 = 2304。然而,图中标注N2 = 144,这表示这里指的是因果流查询 Token 的数量 ,即Q1 = 144。这是因为 DeepEncoder V2 的一个关键设计是,每个局部视图共享一组统一的144个查询嵌入(参考论文 3.2.3 节)。 - 输出维度 (D=896): 每个 Token 的嵌入维度为
D=896。 - 局部视图的总输出: 因此,
B个局部视图会产生B × N2 × D的 Token 序列,即B × 144 × 896维的特征。
- 每个局部裁剪后的
2.2 全局视图处理 (Global view)
- 输入图像分辨率: 全局视图处理的是分辨率为
H:1024 × W:1024的图像,这通常代表了整个文档页面的宏观视图。 - DeepEncoder V2 处理:
1024 × 1024的全局视图被送入 DeepEncoder V2。- Tokenization (N3/16=N4=256): 同样,经过
16倍压缩后,全局视图产生N4个 Token。对于1024 × 1024的图像,N4 = (1024/16) * (1024/16) = 64 * 64 = 4096。然而,图中标注N4 = 256,这与局部视图类似,表示这里是因果流查询 Token 的数量 ,即Q2 = 256。 - 输出维度 (D=896): 每个 Token 的嵌入维度同样为
D=896。 - 全局视图的总输出: 全局视图会产生
1 × N4 × D的 Token 序列,即1 × 256 × 896维的特征。
2.3 Token 合并与总计数
- 合并: 局部视图和全局视图生成的 Token 序列会被**拼接(concatenation)**起来。
- 总 Token 数量:
- 当没有局部视图(即
B=0)时,只有全局视图产生 Token,此时总 Token 数量为Q2 = 256个。 - 当有
B=6个局部视图时,总 Token 数量为B × Q1 + Q2 = 6 × 144 + 256 = 864 + 256 = 1120个。
- 当没有局部视图(即
- 范围: 因此,DeepEncoder V2 最终输出的视觉 Token 数量在 256 到 1120 之间。
3. 关键信息与设计原理
- 多裁剪策略的灵活性: 这种策略允许 DeepSeek-OCR 2 根据图像的复杂性或尺寸,灵活地调整输入到语言模型解码器的视觉 Token 数量。对于内容较少的简单图像,可以只使用全局视图(256个Token),减少计算量;对于信息丰富的复杂文档(如报纸),则可以通过增加局部视图的数量(最多1120个Token)来捕获更多细节。
- 因果流查询 (Causal Flow Queries):
Q1=144和Q2=256明确指出了是因果流查询 Token 的数量。这些查询 Token 是 DeepEncoder V2 实现因果推理和视觉 Token 重排序的关键。它们不是直接的图像像素特征,而是可学习的嵌入,通过因果注意力机制,能够以语义上有意义的顺序组织视觉信息。 - 对齐 LLM 解码器: DeepEncoder V2 最终输出的这些因果排序后的视觉 Token 会被送入 LLM 解码器。这种设计使得视觉编码器能够更好地模拟人类阅读的因果流,并与 LLM 解码器的单向注意力模式自然对齐,从而弥合了 2D 空间结构和 1D 因果语言建模之间的鸿沟。
- Token 预算管理: 论文提到 DeepSeek-OCR 2 的最大 Token 计数(1120)低于其前身 DeepSeek-OCR 的 1156,但与 Gemini-3-Pro 的最大视觉 Token 预算相匹配。这表明其在提高性能的同时,有效控制了计算资源的使用。
通过这种精巧的多裁剪和两阶段 Token 生成机制,DeepSeek-OCR 2 的 DeepEncoder V2 能够在不同粒度上捕捉图像信息,并以一种因果有序的方式将其呈现给后续的语言模型,极大地提升了模型对文档阅读逻辑的理解能力。
图5
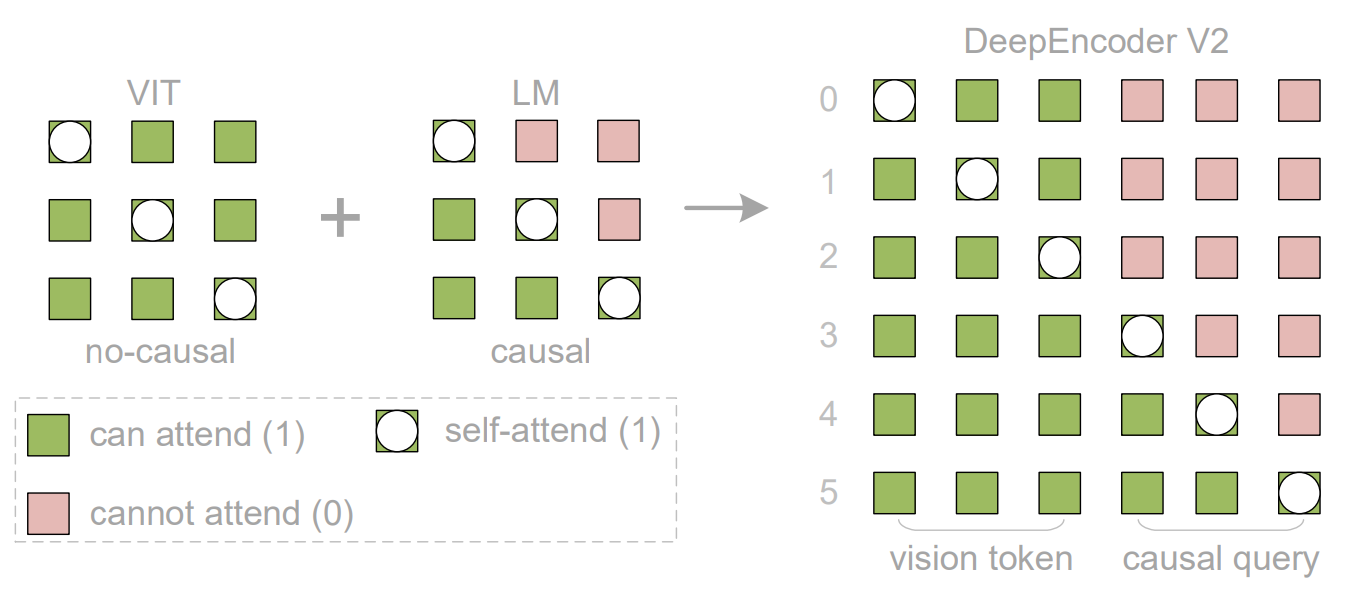
这张图(Figure 5)详细展示了 DeepEncoder V2 中注意力掩码(Attention Mask)的架构设计 。其核心目的是将视觉处理中常用的双向注意力(类似ViT)与语言模型中用于因果序列处理的三角注意力(类似LLM解码器)相结合,以实现对视觉信息的因果流重排序。
1. 总体目的
Figure 5 旨在说明 DeepEncoder V2 如何通过自定义的注意力掩码来融合两种不同的注意力机制:
- 双向注意力(Bidirectional Attention,类似ViT):用于原始的视觉 Token (vision tokens),确保它们能够像传统的视觉编码器一样,获得全局的感受野。
- 因果注意力(Causal Attention,类似LLM解码器):用于新引入的因果流查询 Token (causal query),使其能够实现逐步的、有顺序的视觉信息重排序。
通过这种组合,DeepEncoder V2 赋予了视觉编码器进行因果推理的能力,使其能够智能地重新组织视觉 Token 的顺序,更好地模拟人类阅读文档时自上而下、语义驱动的扫描模式。
2. 符号说明
在深入理解掩码结构之前,我们首先明确图中使用的颜色和形状所代表的含义:
- 绿色方块 (
can attend (1)):表示查询(Query)Token 可以关注(attend to)到对应的键(Key)/值(Value)Token。在注意力计算中,这意味着该位置的注意力权重为 1(或非零)。 - 白色圆圈 (
self-attend (1)) :表示查询 Token 关注到其自身的键/值 Token。这本质上也是can attend (1)的一种特殊情况,只是明确指出是自注意力。 - 粉色方块 (
cannot attend (0)):表示查询 Token 无法关注到对应的键/值 Token。在注意力计算中,这意味着该位置的注意力权重为 0。
3. 掩码架构的组成与协作
整个 DeepEncoder V2 的注意力掩码 M M M 是由两部分沿序列维度拼接而成的:一个用于视觉 Token 的双向掩码和一个用于因果流查询 Token 的因果三角掩码。
3.1 左侧:注意力掩码的两种基本类型
图的左侧展示了构建 DeepEncoder V2 掩码的两个基本组成部分:
-
VIT (Vision Transformer) 掩码 (
no-causal)- 结构: 这是一个典型的双向注意力掩码 ,图中以一个 3x3 的矩阵示例。对于矩阵中的每个查询 Token(行),它都可以关注到序列中的所有键/值 Token(列),包括它自己。
- 含义: 图中所有的位置都是绿色方块或白色圆圈(表示自关注),没有粉色方块。这意味着每个 Token 都能看到序列中的所有其他 Token。
- 功能: 这种机制确保了原始视觉 Token 能够拥有全局感受野,捕捉图像中各个部分之间的全面关系,类似于传统 ViT 模型。
-
LM (Language Model) 掩码 (
causal)- 结构: 这是一个典型的因果(或三角)注意力掩码 ,同样以一个 3x3 的矩阵示例。对于矩阵中的每个查询 Token(行),它只能关注到序列中它自己以及它之前的键/值 Token。
- 含义: 图中对角线及左下方的位置是绿色方块或白色圆圈,而右上方的所有位置都是粉色方块。这意味着一个 Token 无法"看到"它后面的 Token。
- 功能: 这种机制强制执行了序列的因果依赖性,类似于自回归语言模型解码器,其中每个词的生成只依赖于它前面的词。这对于实现视觉 Token 的"重排序"和逐步推理至关重要。
3.2 右侧:DeepEncoder V2 的最终注意力掩码
图的右侧展示了 DeepEncoder V2 中最终构建的注意力掩码。这个掩码是上述两种基本掩码的拼接结果,并应用于两类 Token:
- 视觉 Token (vision token):图中最左边的 3 列(示例中)。
- 因果查询 Token (causal query):图中右边的 3 列(示例中)。
我们来看这个 DeepEncoder V2 掩码的具体结构,它是一个 6x6 的矩阵(示例,实际大小由 n 和 m 决定):
-
视觉 Token 的注意力模式(左侧区块)
- 对于前 3 行(代表 3 个视觉 Token 作为查询),它们关注前 3 列(代表 3 个视觉 Token 作为键/值),形成一个
3x3的双向注意力区块。所有这些位置都是绿色方块或白色圆圈。这意味着每个视觉 Token 都可以关注所有其他的视觉 Token。 - 对于前 3 行(视觉 Token 作为查询),它们关注后 3 列(因果查询 Token 作为键/值),也是双向注意力。所有的视觉 Token 都可以关注所有的因果查询 Token。
- 对于前 3 行(代表 3 个视觉 Token 作为查询),它们关注前 3 列(代表 3 个视觉 Token 作为键/值),形成一个
-
因果查询 Token 的注意力模式(右侧区块)
- 对于后 3 行(代表 3 个因果查询 Token 作为查询),它们关注前 3 列(视觉 Token 作为键/值),形成一个
3x3的双向注意力区块。所有的因果查询 Token 都可以关注所有的视觉 Token。这确保了因果查询能够从原始视觉信息中提取特征。 - 对于后 3 行(因果查询 Token 作为查询),它们关注后 3 列(因果查询 Token 作为键/值),形成一个
3x3的因果(三角)注意力区块。这意味着每个因果查询 Token 只能关注它自己以及它前面的因果查询 Token。例如,第 0 行的因果查询只能关注第 0 列的自己,第 1 行的因果查询可以关注第 0 和第 1 列的自己和前一个,以此类推。
- 对于后 3 行(代表 3 个因果查询 Token 作为查询),它们关注前 3 列(视觉 Token 作为键/值),形成一个
总结公式化表示(论文中 Equation 1):
M = 1 m × m 0 m × n 1 n × m LowerTri ( n ) M = \begin{bmatrix} \mathbf{1}{m \times m} & \mathbf{0}{m \times n} \\ \mathbf{1}_{n \times m} & \text{LowerTri}(n) \end{bmatrix} M=1m×m1n×m0m×nLowerTri(n)
其中:
- m m m 是原始视觉 Token 的数量。
- n n n 是因果查询 Token 的数量。
- 1 m × m \mathbf{1}_{m \times m} 1m×m:表示一个 m × m m \times m m×m 的全 1 矩阵,对应视觉 Token 之间的双向注意力。
- 0 m × n \mathbf{0}{m \times n} 0m×n:表示一个 m × n m \times n m×n 的全 0 矩阵,对应视觉 Token 不能 关注因果查询 Token 的情况(这与图中示例略有不同,图中示例是视觉 Token 可以关注因果查询,而公式表示不能。论文文本描述是"视觉 Token 采用双向注意力...因果流查询采用因果注意力",结合图5,更准确的理解是视觉Token和因果查询Token之间是双向的,而因果查询Token内部是因果的。公式可能是一个简化表示或特定阶段的掩码。**根据图5, 0 m × n \mathbf{0}{m \times n} 0m×n 应该改为 1 m × n \mathbf{1}_{m \times n} 1m×n,表示视觉 Token 可以关注因果查询 Token。** )。
- 1 n × m \mathbf{1}_{n \times m} 1n×m:表示一个 n × m n \times m n×m 的全 1 矩阵,对应因果查询 Token 可以关注视觉 Token。
- LowerTri ( n ) \text{LowerTri}(n) LowerTri(n):表示一个 n × n n \times n n×n 的下三角矩阵(对角线及以下为 1,以上为 0),对应因果查询 Token 内部的因果注意力。
根据图5的实际展示,更符合视觉的公式结构应该是:
M DeepEncoder V2 = 1 m × m 1 m × n 1 n × m LowerTri ( n ) M_{\text{DeepEncoder V2}} = \begin{bmatrix} \mathbf{1}{m \times m} & \mathbf{1}{m \times n} \\ \mathbf{1}_{n \times m} & \text{LowerTri}(n) \end{bmatrix} MDeepEncoder V2=1m×m1n×m1m×nLowerTri(n)
这表示:
- 左上角 ( m × m m \times m m×m):视觉 Token 对视觉 Token 的双向注意力。
- 右上角 ( m × n m \times n m×n):视觉 Token 对因果查询 Token 的双向注意力。
- 左下角 ( n × m n \times m n×m):因果查询 Token 对视觉 Token 的双向注意力。
- 右下角 ( n × n n \times n n×n):因果查询 Token 对因果查询 Token 的因果注意力。
4. 关键信息与设计原理
- 两阶段因果推理:DeepEncoder V2 的这种掩码设计,实现了"编码器语义重排序视觉 Token,而LLM解码器对这些有序序列进行自回归推理"的两阶段因果推理。
- 模拟人类视觉:传统 VLM 强制的栅格扫描顺序(从左上到右下)与人类视觉遵循的语义驱动、因果相关的扫描模式不符。DeepEncoder V2 通过这种注意力掩码,让模型能够更灵活地重排序视觉信息,更接近人类的视觉感知。
- 因果流查询的作用:这些可学习的因果流查询 Token 是实现视觉 Token 重排序的关键。它们通过因果注意力机制,能够逐步地、有逻辑地组织和提炼视觉信息,从而更好地服务于下游的 LLM 解码器。
- 弥合 2D 与 1D 鸿沟:通过将 2D 图像理解分解为编码器中的 1D 因果重排序和解码器中的 1D 因果推理,DeepEncoder V2 尝试弥合 2D 空间结构与 1D 语言模型之间的差距,为实现真正的 2D 视觉推理提供了新的架构思路。
问题1
我没懂啊,右下角是因果查询那岂不是只有右下角是有因果顺序的,左上角和左下角都是没有因果的?可是我们实际考虑的不是整张图都要按因果顺序读吗?而且图中左上角3乘3都是绿色,右上角都是粉色,这啥意思
我们来一步步、更细致地拆解 Figure 5,并回答你的具体问题:
重新理解 Figure 5:注意力掩码 (Attention Mask)
首先,我们把 Figure 5 看作一张地图,它告诉 AI 在处理信息时,哪些部分可以互相"看到"和"关注" 。这张地图的横轴和纵轴都代表了模型中的一系列"令牌"(Tokens)。
为了便于理解,我们把这些 Token 分成两类:
- 视觉令牌 (Vision Tokens):这是从原始图片中提取出来的小块信息,代表了图像的原始特征。
- 因果查询令牌 (Causal Query Tokens) :这是 DeepEncoder V2 新引入的、可学习的特殊令牌,它们的功能是推理并重新组织视觉信息的阅读顺序。你可以把它们想象成 AI 的"思考过程"或"思考线索"。
图 5 的结构是关键: 它是一个**拼接(Concatenation)**而成的矩阵。
- 列 (Columns) 代表"被关注"的信息 (Keys/Values) :
- 左半部分(
m列):是视觉令牌。 - 右半部分(
n列):是因果查询令牌。
- 左半部分(
- 行 (Rows) 代表"发起关注"的令牌 (Queries) :
- 上半部分(
m行):是视觉令牌。 - 下半部分(
n行):是因果查询令牌。
- 上半部分(
理解了这个基本结构,我们再来看每个区域:
区域拆解与你的疑问解答
现在,我们把注意力掩码分成 4 个主要区域(像一个 2x2 的矩阵):
+-------------------------------+------------------------------------+
| 视觉令牌关注视觉令牌 | 视觉令牌关注因果查询令牌 |
| (Vision Query -> Vision Key) | (Vision Query -> Causal Query Key) |
| (左上角 3x3 绿色) | (右上角 粉色) |
+-------------------------------+------------------------------------+
| 因果查询令牌关注视觉令牌 | 因果查询令牌关注因果查询令牌 |
| (Causal Query -> Vision Key) | (Causal Query -> Causal Query Key) |
| (左下角 绿色) | (右下角 三角形) |
+-------------------------------+------------------------------------+-
左上角区域(3x3 绿色方块):视觉令牌关注视觉令牌
- 含义: 这里的绿色表示,每个视觉令牌(作为查询)都可以双向地关注所有其他视觉令牌(作为键)。
- 为什么是绿色? 这是为了让 AI 能够像传统的 Vision Transformer (ViT) 那样,充分理解图像的全局上下文和所有原始视觉信息。就像你扫描整个页面,先对所有内容有个大致印象。这个阶段没有强制的因果顺序,因为原始的视觉信息本身是平铺的,需要先全面感知。
-
右上角区域(粉色方块):视觉令牌关注因果查询令牌
- 含义: 这里的粉色表示,视觉令牌不能关注因果查询令牌。
- 为什么是粉色? 这是为了保持功能分离。视觉令牌的职责是提供原始图像特征,而不是去"思考"或"重新排序"。"思考"和"排序"是因果查询令牌的职责。如果视觉令牌也能关注因果查询,可能会引入不必要的复杂性或干扰因果查询的学习目标。
-
左下角区域(绿色方块):因果查询令牌关注视觉令牌
- 含义: 这里的绿色表示,每个因果查询令牌(作为查询)都可以关注所有视觉令牌(作为键)。
- 为什么是绿色? 这是非常关键的一步!因果查询令牌之所以能"推理"和"重新排序"视觉信息,就是因为它能看到所有的原始视觉特征。它需要从这些特征中提取信息,来决定最佳的阅读顺序。
-
右下角区域(三角形掩码):因果查询令牌关注因果查询令牌
- 含义: 这里的下三角绿色 表示,每个因果查询令牌(作为查询)只能关注它自己和它前面已经产生的因果查询令牌(作为键)。
- 为什么是三角形? 这是体现"因果性"的核心所在。它模仿了语言模型 (LLM) 的自回归(Autoregressive)生成模式 。
- 想象一下你正在写一个句子。你写的每个词都依赖于你已经写过的所有前面的词,但你不能预知你还没写出来的词。
- 同样,每个因果查询令牌在尝试理解和重排视觉顺序时,它只能基于之前已经"思考"出的线索 来做出当前这个"思考步骤"的决定。这使得它能够逐步地、有逻辑地构建一个阅读顺序,而不是一次性随机决定。
回答你的核心疑问:是只有右下角有因果顺序吗?
你的理解是正确的:
-
右下角(因果查询令牌关注因果查询令牌) 确实是唯一直接体现"因果顺序"的区域。它确保了因果查询令牌在自身内部的交互中遵循严格的顺序性,从而逐步推理出视觉流的因果关系。
-
但,这不代表整张图没有因果顺序! 这里的"因果顺序"不是指原始视觉令牌 的物理排列顺序,而是指 DeepEncoder V2 如何"理解"和"重组"这些视觉信息,并最终输出一个带有因果阅读逻辑的表示。
关键在于整个 DeepEncoder V2 的工作流程:
- 视觉令牌 (Vision Tokens) 负责全面感知图片,不带因果顺序(左上角)。
- 因果查询令牌 (Causal Query Tokens) 负责:
- 从所有视觉令牌中提取信息(左下角绿色)。
- 然后,利用自身内部的因果链条式推理 (右下角三角形),将这些提取到的信息重组和排序。
最终结果:
DeepEncoder V2 的输出是仅由这些因果查询令牌组成的序列(论文第 3 页,主贡献 (4) 提到"only the causal flow tokens---the latter half of the encoder outputs---are fed to the LLM 24 decoder")。
虽然原始的视觉令牌本身没有因果顺序,但通过因果查询令牌的"思考"和"重组"过程,输出给后续 LLM 解码器的信息已经是一个"因果有序"的视觉流。这个有序的流就包含了 DeepEncoder V2 推理出来的"阅读逻辑"。
所以,你可以这样理解:DeepEncoder V2 像一个聪明的读者。它先快速浏览所有文字和图片(视觉令牌的全局关注),然后,它在心里默默地,一步步地,根据内容的逻辑,决定先看哪段、再看哪段(因果查询令牌的因果关注),最终形成一个有逻辑的阅读顺序。
问题2
如果因果查询令牌的输出决定了阅读顺序,那么模型是如何通过训练来学习这种特定的视觉逻辑的?
这是一个非常核心且深入的问题!模型学习视觉逻辑(即阅读顺序)的过程是 DeepSeek-OCR 2 最关键的创新点之一。它不是通过一个简单的"阅读顺序损失"来直接监督,而是通过一个巧妙的两阶段级联因果推理架构 和语言建模目标来间接学习和涌现的。
我们来详细拆解这个学习过程:
核心机制:将 2D 视觉顺序问题转化为 1D 语言建模问题
传统的 VLM 模型的痛点在于,它们将 2D 图像像素以僵硬的栅格扫描顺序(从上到下,从左到右)扁平化为 1D 序列,然后送入 LLM。这与人类灵活、语义驱动的视觉感知模式相悖。
DeepSeek-OCR 2 的核心思想是:让 Vision Encoder (DeepEncoder V2) 本身就具备"理解并重排"视觉信息的能力,生成一个符合人类阅读逻辑的"因果视觉流",然后将这个流交给 LLM Decoder 进行后续的语言理解和生成。 这样,2D 图像理解就被分解为两个级联的 1D 因果推理子任务:
- Encoder 阶段:视觉信息的因果重排序 (Causal Reordering of Visual Tokens)
- Decoder 阶段:基于重排序信息的自回归推理 (Autoregressive Reasoning)
现在,我们重点关注 Encoder 阶段如何学习这种重排序能力。
学习过程详解:通过"因果流查询"与"语言建模"
DeepEncoder V2 的训练主要通过以下几个关键机制协同作用:
1. 因果流查询 (Causal Flow Queries) 的引入
- 功能: 这些是可学习的、类似 LLM Query 的令牌。它们不直接代表图像内容,而是作为"思考线索"或"推理路径",通过与原始视觉令牌的交互,来构建一个语义上有序的视觉序列。
- 注意力机制:
- 关注所有视觉令牌 (Attention to Vision Tokens): 正如 Figure 5 左下角所示,每个因果查询令牌都可以双向地关注所有原始视觉令牌。这意味着它能够从整个图像中提取任何它认为有用的视觉特征,来指导其重排序的决策。
- 因果自注意力 (Causal Self-Attention): 正如 Figure 5 右下角的下三角掩码所示,每个因果查询令牌在关注自身序列时,只能关注它自己和它前面已经生成的因果查询令牌。这种严格的因果性是模仿 LLM 的自回归生成模式,迫使模型逐步地、有逻辑地构建一个视觉流。它不能"偷看"未来的顺序,只能基于当前已有的信息进行推理。
2. 语言模型作为视觉编码器 (LM as Vision Encoder)
- 架构选择: DeepEncoder V2 用一个紧凑的 LLM 架构(如 Qwen2-0.5B)替换了 DeepEncoder 中的 CLIP 模块。这意味着 Vision Encoder 内部的层结构、参数初始化和训练范式都更接近于语言模型。
- 训练目标: 在 Encoder 预训练阶段 (Stage 1),DeepEncoder V2 与一个轻量级解码器 20 耦合,共同使用语言建模目标 (Language Modeling Objective) 进行优化,具体是下一个令牌预测 (Next Token Prediction) 。
- 关键点: 这意味着模型被训练去预测给定图像和前面生成内容的情况下,下一个文本令牌是什么。
- 如何关联到阅读顺序? 当模型尝试预测下一个文本令牌时,它需要一个有逻辑的、符合人类阅读习惯的视觉上下文。如果因果查询令牌能成功地将视觉信息重排成一个"正确"的阅读顺序,那么后续的轻量级解码器就能更容易、更准确地预测出正确的文本序列。反之,如果重排的顺序是混乱的,解码器就很难生成正确的文本。
- 间接学习: 因此,模型不是直接被告知"这个区域应该在那个区域之前",而是通过优化整体的语言建模性能来间接学习到"什么样的视觉顺序最有利于生成正确的文本"。因果流查询令牌的任务就是找到这种最佳顺序。
3. 数据和标签的质量
- 文档 OCR 数据集: DeepSeek-OCR 2 主要在大量的文档 OCR 数据(如 OmniDocBench v1.5)上进行训练。这些文档包含复杂的布局、公式、表格等,它们本身就内含清晰的逻辑结构和阅读顺序。
- 标签精细化: 论文提到对布局检测的标签进行了精细化,合并了语义相似的类别(如"图标题"和"图说明")。这意味着训练数据提供了高质量的布局和内容结构信息,这些信息是模型学习阅读逻辑的基础。
4. 逐步训练策略 (Staged Training Pipelines)
- Encoder 预训练 (Stage 1): 视觉分词器和 LLM 风格的编码器在此阶段获取特征提取、令牌压缩和令牌重排序的基本能力。
- 查询增强 (Stage 2): 在此阶段,冻结视觉分词器,同时优化 LLM 编码器和 LLM 解码器,以增强查询表示。这进一步强化了编码器的令牌重排序能力和视觉知识压缩能力。
- 解码器专业化 (Stage 3): 冻结所有编码器参数,仅更新 DeepSeek-LLM 解码器。这有助于 LLM 更好地理解 DeepEncoder V2 重排序后的视觉令牌。
总结学习机制
模型通过训练学习视觉逻辑(阅读顺序)的过程可以概括为:
- 因果流查询令牌 被赋予了在自身序列中因果自注意力 的能力(逐步推理)和关注所有原始视觉令牌的能力(全面感知)。
- 通过语言建模目标 (预测下一个文本令牌),模型被"激励"去生成一个最能帮助解码器准确生成文本的视觉序列。
- 如果因果流查询令牌能够根据图像的语义结构,将视觉信息重排成一个符合人类阅读习惯的逻辑顺序,那么解码器就能更有效地完成语言建模任务,从而获得更低的损失。
- 在大规模、高质量的文档数据上进行训练,这些文档本身就蕴含了丰富的阅读逻辑,为模型提供了学习的"真理"。
- 分阶段训练策略逐步强化了因果流查询令牌的重排序能力。
这种间接学习方式,利用了语言模型强大的自回归能力和对上下文逻辑的敏感性,将视觉领域的"阅读顺序"问题巧妙地转化为了一个语言建模问题,让模型通过"生成正确文本"这一目标,反向学习到"如何正确阅读图像"的内在逻辑。