
在人工智能与教育深度融合的今天,语音评测技术(Speech Evaluation)已成为语言学习、在线教育、智能客服等领域的核心基础设施。无论是英语四六级口语考试、普通话水平测试,还是儿童语言启蒙应用,都离不开稳定、精准的语音评测能力。
然而,对于许多前端开发者而言,语音评测似乎总隔着一层"黑盒"------如何从前端采集音频?如何与云端AI服务建立稳定连接?如何处理流式数据并实时展示评测结果?这些问题往往让人望而却步。
本文将带你从零开始,基于Vue.js 和WebSocket协议,构建一个完整的语音评测Web应用。我们将深入剖析:
-
WebSocket 流式通信的鉴权与连接机制
-
音频数据的分帧编码与传输策略
-
评测结果的结构化解析与可视化渲染
-
企业级应用的代码架构与优化思路
无论你是正在开发教育产品的工程师,还是对语音AI技术感兴趣的前端开发者,相信这篇文章都能为你提供有价值的参考。文中所有敏感凭证信息均已脱敏,你可以放心参考核心逻辑。
一、语音评测技术概览
1.1 什么是语音评测
语音评测(Speech Evaluation / Speech Assessment)是指通过人工智能算法,对说话人的发音进行多维度的自动评分和分析。与简单的语音识别(ASR)不同,评测不仅要"听清"说了什么,还要"评价"说得怎么样。
一个完整的语音评测系统通常输出以下维度:
-
总体得分(Overall):反映整体发音质量
-
发音准确度(Pronunciation):音素级别的发音正确率
-
声调/重音(Tone/Stress):对于中文、英语等声调语言尤为重要
-
流利度(Fluency):语速、停顿、连贯性
-
完整度(Integrity):是否完整朗读了参考文本
-
韵律(Rhythm):节奏感和自然度
1.2 主流技术架构
当前主流的语音评测API通常采用 WebSocket 全双工通信 协议,其典型架构如下:
text
┌─────────────┐ WebSocket ┌─────────────┐
│ 前端应用 │ ◄──────────────────► │ 云侧评测 │
│ (Vue/React) │ (流式音频+结果) │ 服务 │
└─────────────┘ └─────────────┘WebSocket 的优势在于:
-
低延迟:建立连接后无需重复握手,适合实时交互
-
双向通信:前端可持续发送音频帧,后端可实时返回中间结果
-
流式处理:支持边录边评,用户体验更佳
1.3 我们的目标
本篇文章要实现的目标是:一个可直接运行的语音评测演示页面,具备以下功能:
-
支持
.mp3/.speex等常见音频格式上传 -
支持中文、英文、日语、韩语等多语种评测
-
支持字、句、段落三种评测粒度
-
实时显示评测进度和中间结果
-
结构化展示最终评测报告(总分、维度分、单词级详情)
-
一键复制JSON原始数据和解析结果
二、项目准备与环境搭建
2.1 技术选型
| 技术 | 版本 | 用途 |
|---|---|---|
| Vue.js | 2.x | 前端框架 |
| WebSocket | RFC 6455 | 实时通信协议 |
| Crypto Subtle API | W3C标准 | Web端HMAC-SHA256签名 |
| Base64 | --- | 音频数据编码 |
说明:虽然示例中使用的是Vue 2语法,但核心逻辑同样适用于Vue 3、React等主流框架。
2.2 项目结构
text
src/
├── components/
│ └── SpeechEvaluation.vue # 核心组件(所有代码集中于此)
├── App.vue # 根组件
└── main.js # 入口文件为便于理解和演示,我们将所有逻辑封装在单个 .vue 文件中。实际生产项目可按需拆分为:
-
services/websocket.js--- WebSocket 连接管理 -
services/auth.js--- 鉴权签名生成 -
utils/audio.js--- 音频处理工具 -
components/ResultPanel.vue--- 结果展示子组件
2.3 依赖说明
本项目无任何第三方npm依赖,所有功能均基于浏览器原生API实现:
-
WebSocket:浏览器原生支持 -
crypto.subtle:现代浏览器内置加密模块 -
FileReader/ArrayBuffer:文件读取与二进制操作 -
atob/btoa:Base64编解码
三、核心功能模块详解
3.1 音频上传与预处理
3.1.1 文件上传组件
音频文件上传是整个流程的第一步。我们使用 <input type="file"> 配合隐藏触发和拖拽式UI,提升用户体验:
vue
<div class="upload-area" @click="$refs.fileInput.click()">
<input
type="file"
ref="fileInput"
accept=".mp3,.speex"
@change="handleFileUpload"
style="display: none"
/>
<div class="upload-content">
<span class="upload-icon">📤</span>
<span>{{ fileName || '点击上传音频文件' }}</span>
<span v-if="fileSize" class="file-size">{{ fileSize }}</span>
</div>
</div>3.1.2 文件读取与存储
当用户选择文件后,通过 FileReader 将文件读取为 ArrayBuffer,并转换为 Uint8Array 格式以便后续分帧处理:
javascript
handleFileUpload(event) {
const file = event.target.files[0]
if (!file) return
this.fileName = file.name
this.fileSize = (file.size / 1024).toFixed(2) + ' KB'
const reader = new FileReader()
reader.onload = (e) => {
// 存储为Uint8Array,便于分帧切片
this.audioData = new Uint8Array(e.target.result)
}
reader.readAsArrayBuffer(file)
}技术要点:
-
使用
Uint8Array而非Blob,是因为我们需要精确控制每一帧的字节切片 -
文件大小显示保留两位小数,单位KB,提升可读性
3.2 WebSocket 鉴权连接(HMAC-SHA256签名)
3.2.1 为什么需要鉴权
语音评测API通常不是完全开放的,需要通过 appid、apiKey、apiSecret 三元组进行身份认证。常见的鉴权方式是在WebSocket连接URL中携带签名参数,服务端验证签名合法性。
3.2.2 签名生成流程
以讯飞开放平台为例,鉴权URL的生成步骤如下:
-
构建签名原始字符串:
text
host: {hostname} date: {GMT时间} GET {path} HTTP/1.1 -
使用 apiSecret 进行 HMAC-SHA256 加密,得到签名
-
组装 Authorization 头:
text
api_key="{apiKey}", algorithm="hmac-sha256", headers="host date request-line", signature="{signature}" -
Base64编码 Authorization,拼接到WebSocket URL
3.2.3 浏览器端实现
现代浏览器提供了 crypto.subtle API,支持在浏览器端直接进行HMAC加密,无需依赖任何第三方库:
javascript
async getAuthUrl() {
const url = new URL(this.hostUrl)
const date = new Date().toUTCString()
// 1. 构建签名原始字符串
const preStr = `host: ${url.hostname}\ndate: ${date}\nGET ${url.pathname} HTTP/1.1`
// 2. HMAC-SHA256加密
const encoder = new TextEncoder()
const key = await crypto.subtle.importKey(
'raw',
encoder.encode(this.apiSecret),
{ name: 'HMAC', hash: 'SHA-256' },
false,
['sign']
)
const signatureBuffer = await crypto.subtle.sign(
'HMAC',
key,
encoder.encode(preStr)
)
const signature = btoa(String.fromCharCode(...new Uint8Array(signatureBuffer)))
// 3. 构建authorization
const authOrigin = `api_key="${this.apiKey}", algorithm="hmac-sha256", headers="host date request-line", signature="${signature}"`
const authorization = btoa(authOrigin)
// 4. 完整URL
const wsUrl = `wss://${url.hostname}${url.pathname}?host=${url.hostname}&date=${encodeURIComponent(date)}&authorization=${encodeURIComponent(authorization)}`
return wsUrl
}安全提示:
-
appid、apiKey、apiSecret应存放在后端服务中,前端仅通过接口获取已签好的URL -
本文为演示方便将其放在前端,生产环境务必将敏感信息迁移至后端
3.3 WebSocket 连接与生命周期管理
3.3.1 建立连接
封装 connectWebSocket 方法,返回一个 Promise,便于调用方等待连接成功:
javascript
connectWebSocket(wsUrl) {
return new Promise((resolve, reject) => {
this.wsClient = new WebSocket(wsUrl)
this.wsClient.onopen = () => {
this.connectionStatus = '✅ 连接成功'
this.sendAudioData() // 连接成功后立即开始发送音频
resolve()
}
this.wsClient.onmessage = (event) => {
this.handleMessage(event.data)
}
this.wsClient.onerror = (error) => {
this.connectionStatus = '❌ 连接错误'
reject(error)
}
this.wsClient.onclose = () => {
this.connectionStatus = '🔌 连接已关闭'
this.isLoading = false
}
})
}3.3.2 连接状态可视化
通过状态点(Status Dot)和文字描述,让用户实时感知连接状态:
vue
<div class="status-bar" v-if="connectionStatus">
<span :class="['status-dot', statusClass]"></span>
<span>{{ connectionStatus }}</span>
</div>javascript
statusClass() {
if (!this.connectionStatus) return ''
if (this.connectionStatus.includes('成功')) return 'success'
if (this.connectionStatus.includes('错误') || this.connectionStatus.includes('失败')) return 'error'
return 'info'
}3.4 音频分帧与流式发送
3.4.1 分帧策略
语音评测服务通常要求音频以**帧(Frame)**为单位发送,每帧包含固定大小的音频数据(如1280字节)。分帧发送的好处:
-
降低单次传输负载,避免网络拥塞
-
支持边录边评的实时场景
-
服务端可以边接收边处理,减少首包延迟
3.4.2 帧结构设计
每帧数据包含三部分:
-
音频数据:Base64编码的音频片段
-
帧序号(seq):递增序列,用于服务端重组
-
状态标识(status):0=开始帧,1=中间帧,2=结束帧
3.4.3 核心发送逻辑
javascript
sendAudioData() {
const frameSize = 1280
let seq = 0
let status = 0
let offset = 0
const totalLength = this.audioData.length
// 构建请求JSON
const buildRequest = (audioData, seq, status) => {
const audioBase64 = btoa(String.fromCharCode.apply(null, audioData))
return JSON.stringify({
header: { app_id: this.appid, status: status },
parameter: { st: { /* 评测参数 */ } },
payload: {
data: {
encoding: 'lame',
sample_rate: 16000,
channels: 1,
bit_depth: 16,
audio: audioBase64,
seq: seq,
status: status
}
}
})
}
const sendFrame = () => {
if (status === 2 || this.wsCloseFlag) return
if (offset >= totalLength) {
// 发送结束帧(空数据)
status = 2
const lastFrame = new Uint8Array([0])
this.wsClient.send(buildRequest(lastFrame, seq, status))
return
}
const end = Math.min(offset + frameSize, totalLength)
const chunk = this.audioData.slice(offset, end)
this.wsClient.send(buildRequest(chunk, seq, status))
offset = end
seq++
if (status === 0) status = 1
// 间隔40ms发送下一帧(模拟实时流)
setTimeout(sendFrame, 40)
}
sendFrame()
}关键参数说明:
-
frameSize = 1280:每帧1280字节,约对应80ms的16kHz单声道音频 -
setTimeout(sendFrame, 40):40ms间隔发送,模拟实时音频流,避免服务端超时
3.5 消息接收与结果解析
3.5.1 响应数据结构
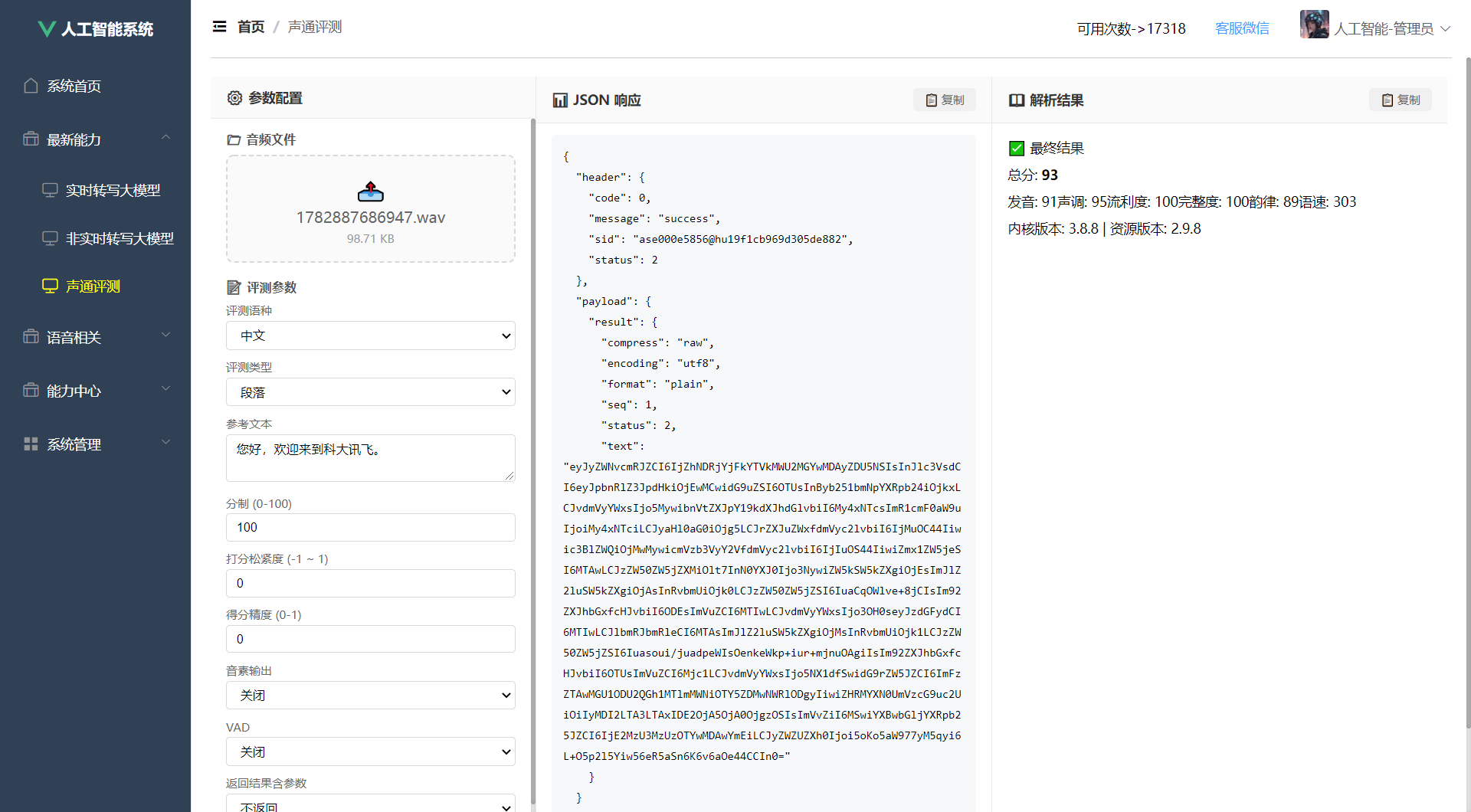
服务端返回的每条消息均为JSON格式,核心结构如下:
json
{
"header": {
"code": 0,
"message": "success",
"status": 1
},
"payload": {
"result": {
"text": "Base64编码的评测结果",
"status": 2
}
}
}-
header.code:0表示成功,非0表示错误 -
payload.result.status:1表示中间结果,2表示最终结果 -
payload.result.text:Base64编码的JSON字符串,解码后包含详细评测数据
3.5.2 消息处理流程
javascript
handleMessage(data) {
const response = JSON.parse(data)
this.jsonResult = response
if (response.header.code !== 0) {
this.connectionStatus = `❌ 错误: ${response.header.message}`
return
}
if (response.payload?.result?.text) {
const decodedText = atob(response.payload.result.text)
const result = JSON.parse(decodedText)
if (response.payload.result.status === 2) {
this.wsCloseFlag = true
this.parseResult(result, false)
this.connectionStatus = '✅ 评测完成'
this.isLoading = false
this.wsClient.close()
} else {
this.parseResult(result, true) // 显示中间结果
this.connectionStatus = '⏳ 评测中...'
}
}
}3.5.3 评测结果深度解析
评测结果 result 对象通常包含以下字段:
| 字段 | 类型 | 说明 |
|---|---|---|
overall |
number | 总分(0-100) |
pronunciation |
number | 发音得分 |
tone |
number | 声调得分 |
fluency |
number | 流利度得分 |
integrity |
number | 完整度得分 |
words |
array | 单词/字级别的详细评分 |
warning |
array | 警告信息列表 |
单词级详情 words 数组中的每个元素包含:
json
{
"word": "您好",
"pinyin": "nin hao",
"readType": 0,
"scores": {
"overall": 95,
"pronunciation": 92,
"tone": 98
}
}其中 readType 表示读法类型:
-
0:正常
-
1:增读(多读了字)
-
2:漏读(少读了字)
-
3:重复
-
4:错读
3.5.4 结果可视化渲染
我们将解析结果渲染为结构清晰的HTML,包含:
-
总分:醒目大号字体展示
-
维度得分:使用标签化布局展示各维度分数
-
单词详情:列表展示每个字的拼音、得分和读法状态
vue
<div class="word-details">
<ul>
<li v-for="word in words" :key="index">
<span class="word-text">{{ word.word }}</span>
<span class="word-pinyin">{{ word.pinyin }}</span>
<span class="word-score">总分: {{ word.scores.overall }}</span>
<span class="word-readtype">{{ getReadTypeLabel(word.readType) }}</span>
</li>
</ul>
</div>3.6 结果复制与清空功能
3.6.1 复制JSON原始数据
javascript
copyJson() {
if (this.jsonResult) {
navigator.clipboard.writeText(this.formattedJson).then(() => {
alert('JSON已复制到剪贴板')
})
}
}3.6.2 复制解析后的文本
javascript
copyParsed() {
if (this.parsedResult) {
// 去除HTML标签,只保留纯文本
const text = this.parsedResult.replace(/<[^>]*>/g, '')
navigator.clipboard.writeText(text).then(() => {
alert('解析结果已复制到剪贴板')
})
}
}3.6.3 清空全部状态
清空操作需重置所有数据变量,并主动关闭WebSocket连接以释放资源:
javascript
clearAll() {
this.audioData = null
this.fileName = ''
this.fileSize = ''
this.jsonResult = null
this.parsedResult = ''
this.connectionStatus = ''
this.isLoading = false
this.wsCloseFlag = false
if (this.wsClient) {
this.wsClient.close()
this.wsClient = null
}
}四、UI/UX 设计与交互优化
4.1 三栏布局设计
页面采用经典的三栏布局,从左到右依次为:
| 区域 | 功能 | 宽度 |
|---|---|---|
| 左侧面板 | 参数配置 + 操作按钮 | 340px(固定) |
| 中间面板 | JSON原始响应展示 | flex:1 |
| 右侧面板 | 解析结果可视化展示 | flex:1 |
这种布局设计让开发者可以对照查看原始数据和解析结果,便于调试和问题定位。
4.2 响应式适配
针对小屏设备(平板、手机),三栏布局自动变为纵向堆叠:
css
@media (max-width: 992px) {
.container {
flex-direction: column;
height: auto;
}
.left-panel {
width: 100%;
max-height: 400px;
}
.center-panel, .right-panel {
height: 300px;
}
}4.3 交互反馈优化
-
上传区域:hover时边框变蓝,提示可交互
-
评测按钮:点击后变为"评测中..."并禁用,防止重复提交
-
连接状态:实时显示连接状态及对应颜色标识
-
滚动优化:结果区域独立滚动,互不影响
五、企业级优化与最佳实践
5.1 安全性增强
敏感信息保护 :
当前代码中 appid、apiKey、apiSecret 硬编码在前端,存在泄露风险。生产环境应采用以下方案:
javascript
// 方案一:后端代理
// 前端请求后端接口获取已签名的WebSocket URL
const { wsUrl } = await axios.get('/api/get-ws-url', {
params: { refText: this.params.refText }
})
this.connectWebSocket(wsUrl)
// 方案二:后端WebSocket代理
// 前端直接连接后端WebSocket,由后端与第三方服务通信CORS与域名校验 :
确保WebSocket连接仅允许白名单域名发起,防止盗用。
5.2 性能优化
内存管理:
-
发送完音频数据后,及时释放
audioData引用 -
使用
revokeObjectURL释放临时URL(若使用了createObjectURL)
大数据量处理:
-
评测结果JSON可能较大(如长段落评测),使用虚拟滚动展示单词列表
-
对结果数据进行分页或懒加载
网络优化:
-
根据网络状况动态调整帧大小和发送间隔
-
实现断线重连机制(指数退避重试)
5.3 可维护性提升
配置抽离 :
将API配置、评测参数默认值等抽离到独立的 config.js 文件:
javascript
// config.js
export const API_CONFIG = {
appid: process.env.VUE_APP_APPID,
hostUrl: process.env.VUE_APP_HOST_URL
}
export const DEFAULT_PARAMS = {
lang: 'cn',
core: 'para',
scale: 100,
// ...
}错误处理增强:
-
区分网络错误、鉴权错误、业务错误,给出不同提示
-
记录错误日志(可接入Sentry等监控平台)
单元测试 :
对核心函数(如签名生成、结果解析)编写单元测试,保证代码健壮性。
5.4 用户体验进阶
进度条 :
显示音频上传和评测进度,提升等待体验。
历史记录 :
将评测结果存入本地存储(localStorage)或云端,方便用户回溯。
导出报告 :
支持将评测结果导出为PDF或图片格式,便于分享和打印。
多语言支持 :
界面文字支持中英文切换,适配国际化场景。
六、常见问题与排障指南
6.1 WebSocket连接失败
| 现象 | 可能原因 | 解决方案 |
|---|---|---|
WebSocket connection failed |
签名错误 | 检查 apiKey/apiSecret 是否正确 |
401 Unauthorized |
签名过期 | 检查系统时间是否准确(GMT时间) |
CORS error |
跨域限制 | 服务端配置允许的Origin |
Connection timeout |
网络不通 | 检查防火墙/代理设置 |
6.2 音频发送问题
| 现象 | 可能原因 | 解决方案 |
|---|---|---|
服务端返回 invalid audio format |
编码格式不匹配 | 确认 encoding 参数与实际音频一致 |
| 音频断断续续 | 帧间隔过大或过小 | 调整 setTimeout 间隔 |
| 评测结果为空 | 音频静音或无效 | 检查音频文件是否有有效语音 |
6.3 结果解析异常
| 现象 | 可能原因 | 解决方案 |
|---|---|---|
atob decoding failed |
非Base64编码 | 检查响应数据结构 |
result.words is undefined |
评测类型不匹配 | 确认 core 参数(word/sent/para) |
得分显示为 N/A |
缺少对应维度 | 部分语种或评测类型不返回所有维度 |
七、扩展与演进方向
7.1 实时录音评测
当前方案基于已录制好的音频文件上传。更贴近真实应用场景的是实时录音评测,即用户边说话边评测。实现思路:
-
使用
MediaRecorderAPI 或AudioWorklet采集麦克风音频 -
将采集到的音频数据实时分帧发送
-
在用户说话过程中,实时显示评分变化
7.2 多模态评测
结合语音评测与视频分析,可扩展为:
-
发音口型检测:通过摄像头分析用户口型是否标准
-
情感分析:判断用户发音时的情绪状态(自信/紧张)
7.3 个性化学习报告
基于多次评测数据,生成用户的学习画像:
-
薄弱音素分析(如 /r/ 和 /l/ 混淆)
-
进步曲线图
-
针对性练习推荐
八、总结
本文从零开始,完整实现了一个基于 Vue.js 和 WebSocket 的语音评测Web应用。我们深入探讨了:
-
鉴权机制:浏览器端 HMAC-SHA256 签名生成
-
流式通信:WebSocket 连接管理与生命周期
-
音频处理:文件读取、分帧编码与流式发送
-
结果解析:评测数据结构详解与可视化渲染
-
工程实践:安全性、性能、可维护性优化
语音评测是一个融合了前端工程、网络通信、音频处理、AI算法等多学科知识的领域。希望本文能为你打开一扇门,让你在实际项目中更加得心应手。
核心技术点回顾:
-
WebSocket 流式通信
-
HMAC-SHA256 鉴权签名
-
音频分帧传输
-
评测结果结构化解析
-
Vue.js 响应式数据驱动UI
后续学习建议:
-
深入 WebSocket 协议(RFC 6455)
-
学习 Web Audio API 进行音频处理
-
了解语音信号处理基础(MFCC、音素识别)
-
研究不同云服务商的评测API差异
附录:完整代码索引
文中所有代码均可在以下位置找到完整实现:
| 功能模块 | 对应方法/属性 |
|---|---|
| 音频上传 | handleFileUpload |
| 鉴权签名 | getAuthUrl |
| WebSocket连接 | connectWebSocket |
| 音频发送 | sendAudioData |
| 消息处理 | handleMessage |
| 结果解析 | parseResult |
| 复制功能 | copyJson / copyParsed |
| 清空重置 | clearAll |