目录
1.引言
最后的类和对象(下)就是给类和对象收尾了那么话不多说,接下来我们就进入类和对象(下)的内容------------------>

2.再探构造函数
1.之前我们实现构造函数时,初始化成员变量主要使用函数体内赋值,构造函数初始化还有一种方式,就是初始化列表 ,初始化列表的使用方式是以一个冒号开始,接着是一个以逗号分隔的数据成员列表,每个"成员变量"后面跟一个放在括号中的初始值或表达式
2.每个成员变量在初始化列表中只能出现一次,语法理解上初始化列表可以认为是每个成员变量定义初始化的地方
3.引用成员变量,const 成员变量,没有默认构造的类类型变量,必须放在初始化列表位置进行初始化,否则会编译报错
4.C++11支持在成员变量声明的位置给缺省值,这个缺省值主要是给没有显示在初始化列表初始化的成员使用的
5.尽量使用初始化列表初始化,因为那些你不在初始化列表初始化的成员也会走初始化列表,如果这个成员在声明位置给了缺省值,初始化列表会用这个缺省值初始化。如果你没有给缺省值,对于没有显示在初始化列表初始化的内置类型成员是否初始化取决于编译器,C++没有规定。对于没有显示在初始化列表初始化的自定义类型成员会调用这个成员类型的默认构造函数,如果没有默认构造会编译报错
6.初始化列表中按照成员变量在类中声明顺序进行初始化,跟成员在初始化列表出现的先后顺序无关。建议声明顺序和初始化列表顺序保持一致
第1点:
初始化列表具体如何用如下代码
cpp
class Date
{
public:
void Print() const;
Date(int year = 1, int month = 1, int day = 1)
:_year(year)
,_month(month)
,_day(day)
{
if (!CheckDate())
{
std::cout << "非法日期:";
Print();
}
}
private:
int _year;
int _month;
int _day;
};先用冒号,然后想要初始化的成员变量,括号里接初始化的值或表达式,随后如果还有想要初始化的成员变量,就用','分隔
第2点
语法理解上初始化列表可以认为是每个成员变量定义初始化的地方,这个怎么理解,我们来看下面代码
cpp
#include<iostream>
using namespace std;
class Date
{
public:
Date(int year = 1, int month = 1, int day = 1)
:_year(year)
, _month(month)
, _day(day)
{
}
private:
//声明
int _year;
int _month;
int _day;
};
int main()
{
//对象的定义
Date d1(2022, 2, 2);
return 0;
}首先,类中的成员变量是声明,Date d1(2022,2,2);是对象整体的定义,那么需不需要给对象里的成员变量定义呢,是需要的。初始化列表就是对象的成员变量初始化的地方,所以在初始化列表中每个成员变量只能出现一次
第3点
我们之前讲的年月日这些普通的变量可以在初始化列表,也可以在函数体内初始化,但是有几类只能在初始化列表初始化,也就是------引用成员变量,const 成员变量,没有默认构造的类类型变量
为什么这些一定要放在初始化列表中初始化,因为首先我们知道初始化列表是对象的成员变量初始化的地方。所以不管我们写不写,每个成员变量都会走初始化列表,为了初始化。那么,引用是需要在定义的时候初始化的,const修饰的变量也是需要在定义的时候初始化的,没有默认构造的类类型变量在定义的时候如果不接东西就没有对应的构造函数能与之匹配,所以这三种是需要在初始化列表部分初始化的
举个例子就是如下代码,如果我们在初始化列表中不对year,a和da初始化,那么程序就会报错
cs
#include<iostream>
using namespace std;
class A
{
public:
A(int a)
{
_a = a;
}
private:
int _a;
};
class Date
{
public:
Date(int year = 1, int month = 1, int day = 1)
:_year(year)
, _month(month)
, _day(day)
, year(month)
,a(1)
,da(2)
{
}
private:
int _year;
int _month;
int _day;
int& year;
const int a;
A da;
};
int main()
{
Date d1(2022, 2, 2);
return 0;
}所以之后我们写构造函数能用初始化列表初始化就用初始化列表初始化
第4点
在C++11后,我们可以给成员变量附缺省值,也就是如下代码,需要注意的是,这不是定义初始化,因为没有开空间,附缺省值的作用是在之后初始化列表时候如果我们没有主动写初始化,那么编译器就会将缺省值作为对应成员变量的初始化值,以代码为例就是如下
cpp
#include<iostream>
using namespace std;
class A
{
public:
A(int a)
{
_a = a;
}
private:
int _a;
};
class Date
{
public:
Date(int year = 10, int month = 10, int day = 10)
: year(month)
,a(1)
,da(2)
{
}
private:
int _year = 1;
int _month = 1;
int _day = 1;
int& year;
const int a;
A da;
};
int main()
{
Date d1(2022, 2, 2);
return 0;
}注意:1.如果缺省值和初始化列表同时存在,初始化列表的优先级是比缺省值高的
2.有了这一特性后,我们不写默认构造函数,编译器自动生成的默认构造函数也会初始化(在我们赋缺省值的情况下),因为不管是什么构造函数,都会有初始话列表,因为编译器自动生成的默认构造函数初始化列表未定义,所以会用我们所给的缺省值进行初始化,代码如下
cpp
#include<iostream>
using namespace std;
class A
{
public:
A(int a)
{
_a = a;
}
private:
int _a;
};
class Date
{
public:
/*Date(int year = 1, int month = 1, int day = 1)
: year(month)
,a(1)
,da(2)
{
}*/
void Print()
{
cout << _year << "年" << _month << "月" << _day << "日" << endl;
}
private:
int _year = 1;
int _month = 1;
int _day = 1;
/*int& year;
const int a;
A da;*/
};
int main()
{
Date d1;
d1.Print();
return 0;
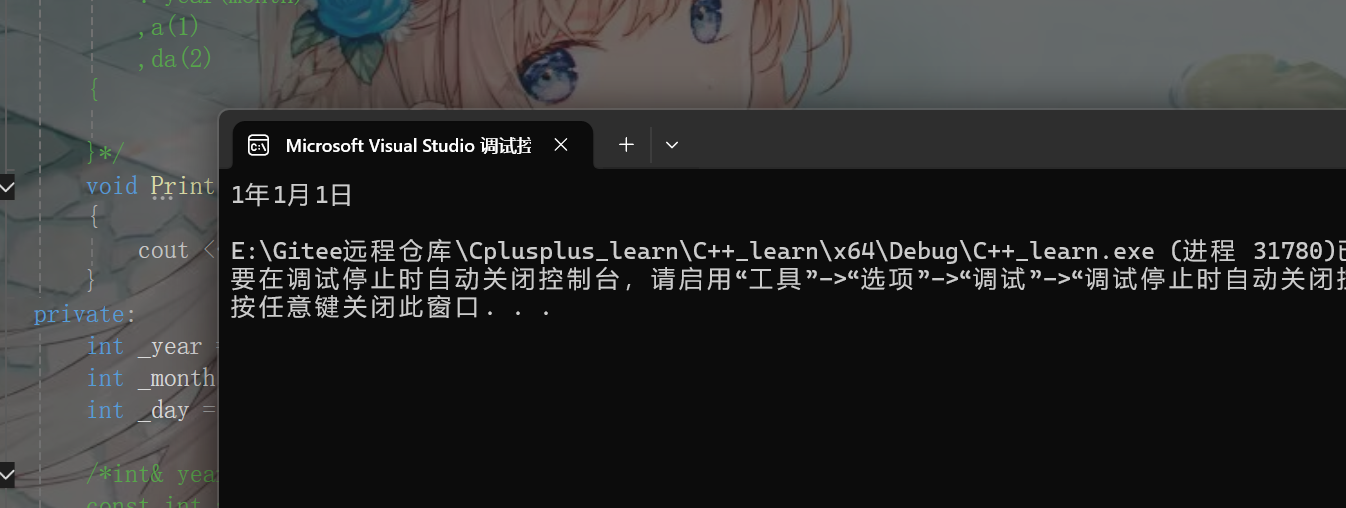
}这段代码我们是没给默认构造函数的,用的是编译器默认生成的默认构造,我们输出可以发现确实是根据缺省值初始化了
缺省值很好的弥补了内置类型没有做处理的点
缺省值不是只能写值,也可以写表达式之类的
第5点
这一点主要就是上面四点的汇总,直接看就行,第六点也没什么要讲的,这里就不讲了
初始化列表总结:
无论是否显示写初始化列表,每个构造函数都有初始化列表
无论是否在初始化列表显示初始化成员变量,每个成员变量都要走初始化列表初始化
最后我们来看一道题训练一下
下面程序的运行结果是什么
cpp
#include<iostream>
using namespace std;
class A
{
public:
A(int a)
:_a1(a)
, _a2(_a1)
{}
void Print() {
cout << _a1 << " " << _a2 << endl;
}
private:
int _a2 = 2;
int _a1 = 2;
};
int main()
{
A aa(1);
aa.Print();
return 0;
}这个代码的运行最终输出结果是1 随机值 ,接下来我们来分析,首先成员变量声明的顺序是_a2,_a1,那么初始化列表初始化的时候就是按成员变量声明的顺序,那么_a2先初始化,此时_a1还没初始化,所以_a1是随机值,所以_a2就是随机值,随后对_a1初始化,a是1,所以_a1是1,所以_a1是1,_a2是随机值,所以输出是1 随机值
3.类型转换
1.C++支持内置类型隐式类型转换为类类型对象,需要有相关内置类型为参数的构造函数
2.构造函数前面 加explicit就不再支持隐式类型转换
3.类类型的对象之间也可以隐式转换,需要相应的构造函数支持
第一点:
cpp
#include<iostream>
using namespace std;
class A
{
public:
A(int a1):_a1(a1)
{
}
void Print()
{
cout << _a1 << " " << _a2 << endl;
}
private:
int _a1;
int _a2;
};
int main()
{
A a1 = 2;
a1.Print();
return 0;
}上述代码中的a1就是隐式类型转换,这个类型转换和内置类型的隐式类型转换是相似的
2先构造一个临时对象,再去拷贝构造到a1(但是编译器遇到连续构造+拷贝构造会优化成直接构造),我们可以通过自己实现一个拷贝构造函数后调试观察
我们通过这个可以发现,因为隐式类型转换会先构造出一个临时对象,临时对象具有常性,所以引用时候需要加const
cpp
A& a2 = a1;
const A& a3 = 2;这个隐式类型转换的巧妙之处很容易体现,如下代码
cpp
#include<iostream>
using namespace std;
class A
{
public:
A(int a1=0) :_a1(a1)
{
}
void Print()
{
cout << _a1 << " " << _a2 << endl;
}
private:
int _a1;
int _a2;
};
class Stack
{
public:
void Push(const A& aa)
{
//...
}
private:
A a[10];
int _top;
};
int main()
{
Stack st;
st.Push(2);
A aa1 = 2;
st.Push(aa1);
return 0;
}我们实现的Stack类的功能里的Push,我们想要往里面压入东西,常规来讲是用aa1的方式,但是有了隐式类型转换后,我们就可以直接传值,然后通过隐式类型转换来实现,这样看着也舒服多了
注 :在C++11前,隐式类型转换只支持单参数,多参数是不支持的,但在C++11及以后,多参数也支持了,就是要加上{}包起来
4.static成员
- 用static修饰的成员变量,称之为静态成员变量,静态成员变量一定要在类外进行初始化
- 静态成员变量为当前类的所有对象所共享,不属于某个具体的对象,不存在对象中,存放在静态区
- 用static修饰的成员函数,称之为静态成员函数,静态成员函数没有this指针
- 静态成员函数中可以访问其他的静态成员,但是不能访问非静态的,因为没有this指针
- 非静态的成员函数,可以访问任意的静态成员变量和静态成员函数
- 突破类域就可以访问静态成员,可以通过 类名::静态成员 或者 对象.静态成员 来访问静态成员变量和静态成员函数
- 静态成员也是类的成员,受public,protected,private访问限定符的限制
- 静态成员变量不能在声明位置给缺省值初始化,因为缺省值是给构造函数初始化列表的,静态成员变量不属于某个对象,不走构造函数初始化列表
第一、二点
static修饰成员变量举个例子就是如下代码
cpp
static int count;静态成员变量是当前类的所有对象共享的,不属于某个具体的对象中,所以对于静态成员变量而言是不可以用初始化列表的,因为初始化列表是用来初始化的,而对于静态成员变量而言,多实例化几个对象,如果静态成员变量会走初始化列表,就进行了多次初始化,这是不行的。也可以从另一个角度来看,静态成员变量是存放在静态区的,初始化列表并不能对静态区进行初始化。
但是在静态区的成员是需要初始化的,所以静态成员变量一定要在类外进行初始化,也就是如下代码
cpp
#include<iostream>
using namespace std;
class A
{
public:
private:
static int count;
};
int A::count = 0;
int main()
{
return 0;
}拓展 :为什么不能在类内赋值,因为类内给成员变量赋值其实不是赋值,而是赋缺省值,但是初始化列表并不会遇到静态成员演变量(静态成员变量在这里只是声明,没有实体),所以这个缺省值也就没用了,自然就不会初始化
有一个例外,那就是static const整型常量
编译器允许它在类内初始化,是因为它是编译期常量,不需要存储实体或者只存在符号表,属于特殊的一种,并不是"类内缺省值+初始化列表"那套逻辑,举个例子就是如下代码
cpp
#include<iostream>
using namespace std;
class A
{
public:
private:
static int count;
static const int a = 10;
};
int A::count = 0;
int main()
{
return 0;
}第三点
静态成员函数和静态成员变量一样,也是一个类中所有对象通用的,所以静态成员函数没有this指针,运用如下代码
cpp
#include<iostream>
using namespace std;
class A
{
public:
A()
{
count++;
}
A(const A& a)
{
count++;
}
~A()
{
count--;
}
static int GetA()
{
return count;
}
private:
static int count;
static const int a = 10;
};
int A::count = 0;
int main()
{
A a1, a2;
A a3(a1);
cout << A::GetA() << endl;
return 0;
}第四点
因为静态成员函数没有this指针,那么自然静态成员函数就无法访问成员变量,只能访问静态成员变量,因为静态成员变量直接访问就行,但是成员变量需要通过对应的this指针访问
第五点
非静态成员函数既可以访问静态成员函数也可以访问静态成员变量,举个例子就是如下代码
cpp
#include<iostream>
using namespace std;
class A
{
public:
A()
{
count++;
}
A(const A& a)
{
count++;
}
~A()
{
count--;
}
static int GetA()
{
return count;
}
int _GetA()
{
count -= GetA();
return count;
}
private:
static int count;
static const int a = 10;
};
int A::count = 0;
int main()
{
A a1, a2;
A a3(a1);
cout << A::GetA() << endl;
cout << a1._GetA() << endl;
return 0;
}第六点
这点其实我们可以把静态成员想象成全局变量或全局函数,只是放在了类域之中,所以只要突破类域就可以访问了(就是要注意访问权限)
第七点
静态成员也是累的成员,所以我们要注意访问权限的问题,如果是私有或保护,我们直接通过突破类域去访问也是访问不到的,需要注意
第八点在前面第一二点的时候就讲过了,就不多赘述了
接下来我们来看一道题,通过static成员的方式来解决他
求1+2+3+...+n_牛客题霸_牛客网,AC代码如下(这道题纯粹是为了出题而出的题,在实践中没有意义,但是在现在可以帮助我们训练一下运用static的方式)
cpp
class Run{
public:
Run()
{
ans+=cnt;
cnt++;
}
static int Get()
{
return ans;
}
private:
static int cnt;
static int ans;
};
class Solution {
public:
int Sum_Solution(int n) {
Run a[n];
return Run::Get();
}
};
int Run::cnt = 1;
int Run::ans = 0;5.有元
- 友元提供了一种突破类访问限定符封装的方式,友元分为:友元函数和友元类,在函数声明或者类声明的前面加friend,并且把友元声明放到一个类的里面(任意位置,一般是放在最前面)
- 外部友元函数可访问类的私有和保护成员,友元函数仅仅是一种声明,他不是类的成员函数
- 友元函数可以在类定义的任何地方声明,不受类访问限定符限制
- 一个函数可以是多个类的友元函数
- 友元类中的成员函数都可以是另一个类的友元函数,都可以访问另一个类中的私有和保护成员
- 友元类的关系是单向的,不具有交换性,比如A类是B类的友元,但B类不是A类的友元
- 友元类关系不能传递,如果A是B的友元,B是C的友元,但是A不是C的友元
- 优势提供了便利,但是友元会增加耦合度,破坏了封装,所以友元不宜多用
第一,二,三点
这三点在类和对象中的时候就基本提过了,这里就直接写一下有元是如何写的,代码如下
cpp
#include <iostream>
using namespace std;
class A
{
friend void Print(const A& aa);
private:
int _a1 = 1;
int _a2 = 2;
};
void Print(const A& aa)
{
cout << aa._a1 << endl;
}
int main()
{
A a1;
Print(a1);
return 0;
}第四点
这个也是很简单易懂,我来举个例子
cpp
#include <iostream>
using namespace std;
class A
{
friend void Print(const A& aa, const B& bb);
private:
int _a1 = 1;
int _a2 = 2;
};
class B
{
friend void Print(const A& aa, const B& bb);
private:
int _b1 = 1;
int _b2 = 2;
};
void Print(const A& aa,const B& bb)
{
cout << aa._a1 << " " << bb._b2 << endl;;
}
int main()
{
A a1;
B b1;
Print(a1, b1);
return 0;
}但这个代码其实是有问题的,因为在A类中的友元声明中,B是找不到的,所以要给B前置声明,最后可以运行的代码如下
cpp
#include <iostream>
using namespace std;
class B;
class A
{
friend void Print(const A& aa, const B& bb);
private:
int _a1 = 1;
int _a2 = 2;
};
class B
{
friend void Print(const A& aa, const B& bb);
private:
int _b1 = 1;
int _b2 = 2;
};
void Print(const A& aa,const B& bb)
{
cout << aa._a1 << " " << bb._b2 << endl;;
}
int main()
{
A a1;
B b1;
Print(a1, b1);
return 0;
}第五点
类作为友元其实就相当于是友元类中的所有成员函数都变成了友元,也就是说友元类中的所有成员函数都可以访问另一个类的私有保护成员,代码样例如下
cpp
#include <iostream>
using namespace std;
class B;
class A
{
friend class B;
private:
int _a1 = 1;
int _a2 = 2;
};
class B
{
public:
void func1(const A& aa)
{
cout << aa._a1 << endl;
}
void func2(const A& aa)
{
cout << aa._a2 << endl;
}
private:
int _b1 = 1;
int _b2 = 2;
};
int main()
{
A a1;
B b1;
b1.func1(a1);
b1.func2(a1);
return 0;
}第六,七,八点
这几点就很容易理解了,就不过多赘述了
6.内部类
- 如果一个类定义在另一个类的内部,这个内部类就叫做内部类,内部类是一个独立的类,跟定义在全局相比,他只是受外部类类域限制和访问限定符限制,所以外部类定义的对象中不包含内部类
- 内部类默认是外部类的友元类
- 内部类本质也是一种封装,当A类跟B类紧密关联,A类实现出来主要就是给B类使用,那么可以考虑把A类设计为B的内部类,如果放到private/protected位置,那么A类就是B类的专属内部类,其他地方都用不了
第一点
内部类是个什么样子呢,以下面样例为例,B就是A的内部类
cpp
#include <iostream>
using namespace std;
class A
{
public:
class B
{
public:
void func1(const A& aa)
{
cout << aa._a1 << endl;
}
void func2()
{
cout << _a2 << endl;
}
private:
int _b1 = 11;
};
private:
int _a1 = 1;
static int _a2;
};
int A::_a2 = 2;
int main()
{
return 0;
}内部类是一个独立的类,跟定义在全局相比,他只是受外部类类域限制和访问限定符限制,所以外部类定义的对象中不包含内部类,这句话的意思就是B是A的内部类,但是A的大小不会包含B,B只是多了限制,但是还是独立的类(B不是A的成员),我们可以通过下面这个代码来看A,B的大小
cpp
cout << sizeof(A) << endl << sizeof(A::B) << endl;最终输出为4 4,说明A的大小并没有涵盖B,所以B其实依旧是独立的类
因为B是A的内部类,所以直接定义是定义不了的,得指定类域,也就是如下
cpp
A a1;
A::B b1;第二点
也就是说内部类中的成员函数可以直接访问对应类的私有成员,就以这个代码为例
cpp
#include <iostream>
using namespace std;
class A
{
public:
class B
{
public:
void func1(const A& aa)
{
cout << aa._a1 << endl;
}
void func2()
{
cout << _a2 << endl;
}
private:
int _b1 = 11;
};
private:
int _a1 = 1;
static int _a2;
};
int A::_a2 = 2;
int main()
{
A a1;
A::B b1;
b1.func1(a1);
b1.func2();
cout << sizeof(A) << endl << sizeof(A::B) << endl;
return 0;
}第三点
这点的体现可以下面优化部分体现
会了内部类后,求1+2+3+...+n_牛客题霸_牛客网我们这道题还可以优化一下,先前的写法我们是可以在别的地方调用Run的,但是如果讲Run变为Solution类的私有内部类,就可以避免其余操作影响最终结果,优化为如下代码
cpp
class Solution {
private:
class Run {
public:
Run() {
ans += cnt;
cnt++;
}
};
static int cnt;
static int ans;
public:
int Sum_Solution(int n) {
Run a[n];
return ans;
}
};
int Solution::cnt = 1;
int Solution::ans = 0;7.匿名对象
- 用 类型(实参)定义出来的对象叫做匿名对象,相比之前我们定义的 类型 对象名(实参)定义出来的叫有名对象
- 匿名对象生命周期只在当前一行,一般临时定义一个对象当前用一下即可,就可以定义匿名对象
第一,二点
匿名对象相比于有名对象其实就是少了一个对象名,我们通过代码来看
cpp
#include <iostream>
using namespace std;
class A
{
public:
A(int a = 0)
:_a(a)
{
}
private:
int _a;
};
int main()
{
A a1;//有名对象
A a2(1);//有名对象
A();//匿名对象
A(1);//匿名对象
return 0;
}那么匿名对象有什么用呢
就比如说我们只是想调用一下对象里的一个函数,这个函数又不会涉及到对象中的成员变量,这个时候我们就可以通过匿名对象来调用,样例如下
cpp
#include <iostream>
using namespace std;
class A
{
public:
A(int a = 0)
{
count++;
}
A(const A& a)
{
count++;
}
~A()
{
count--;
}
int Ret()
{
return count;
}
private:
static int count;
};
int A::count = 0;
int main()
{
A a1, a2;
A a3(a1);
return 0;
}如果说,我们现在目的是统计再实例化一个对象之后实例化了多少个对象,有俩种方式,如下,我们可以发现方式二是更方便点的,而且我们不用自己实例化对象,匿名对象这行结束后他就会自动销毁,所以之后匿名对象还是比较常用的
cpp
方式一(有名对象方式)
A a4;
cout << a4.Ret() << endl;
方式二(匿名对象方式)
cout << A().Ret() << endl;我们可以这么理解,有名对象可以在当前域中长期用,匿名对象就是一次性的
拓展:
- const引用可以延长匿名对象的生命周期,这个后面再说
- 匿名对象也能用于传参,如下
greater<int> gt;
sort(a,a+8,gt);
这是有名对象的方式
sort(a,a+8,greater<int>());
这是匿名对象的方式
8.对象拷贝时的编译器优化(拓展/了解)
- 现代编译器会为了尽可能提高程序的效率,在不影响正确性的情况下会尽可能减少一些传参和传返回值的过程中可以省略的拷贝
- 如何优化C++标准并没有严格规定,各个编译器会根据情况自行处理,当前主流的相对新一点的编译器对于连续一个表达式步骤中的连续拷贝会进行合并优化,有些更新更"激进"的编译器还会进行跨行跨表达式的合并优化
- linux下可以将下面代码拷贝到test.cpp文件,编译时用g++ test.cpp -fno-elide-constructors的方式关闭构造相关的优化
对象拷贝时的编译器优化其实在我们先前讲隐式转化的时候就遇到过了,隐式转化是先构造为临时对象,随后再对临时对象进行拷贝构造,但是在现在的编译器中,已经优化成了直接构造
接下来,我们就通过实例来分析讲解,首先,类是下面的这个类
cpp
class A
{
public:
A(int a = 0)
: _a1(a)
{
cout << "A(int a)" << endl;
}
A(const A& aa)
:_a1(aa._a1)
{
cout << "A(const A& aa)" << endl;
}
A& operator=(const A& aa)
{
cout << "A& operator=(const A& aa)" << endl;
if (this != &aa)
{
_a1 = aa._a1;
} return*this;
}
~A()
{
cout << "~A()" << endl;
}
private:
int _a1 = 1;
};
void f1(A aa)
{}
A f2()
{
A aa;
return aa;
}我们先看传值传参
接下来,我们先看下面俩种情况
cpp
int main()
{
A a1 = 1;
const A& a2 = 1;
return 0;
}A a1 = 1
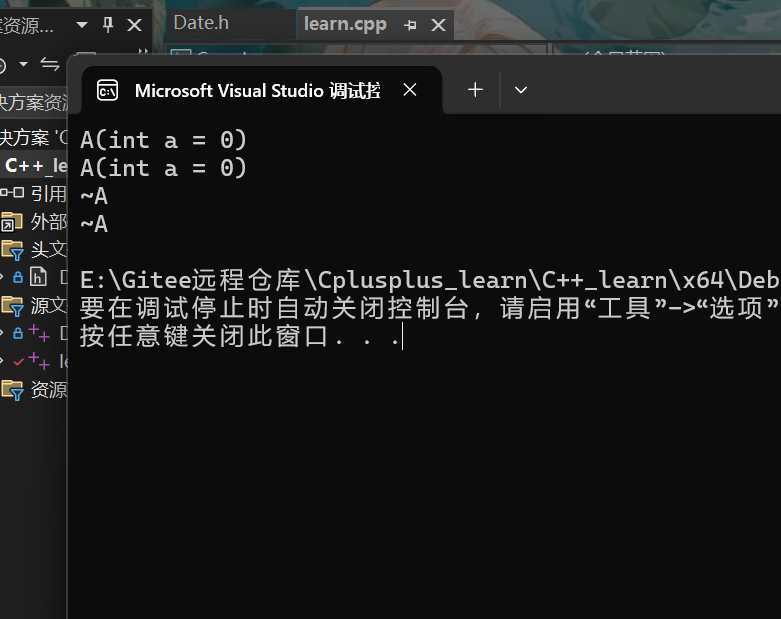
这行就是先对1构造一个临时对象。随后再对临时对象拷贝构造给a1,按照这个思路的话会构造俩次,但其实这种情况编译器会优化为直接构造,也就是一次构造完成
const A& a2 = 1
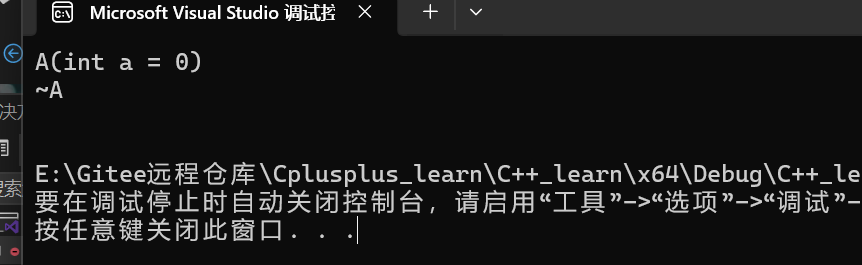
这行就是取别名,所以1构造一个临时对象,随后a2就是这个临时对象的别名
所以这段程序运行过程会是俩次构造和俩次析构,运行结果如下图
接下来我们来看传值传参的情况
cpp
int main()
{
// 传值传参
// 构造+拷⻉构造
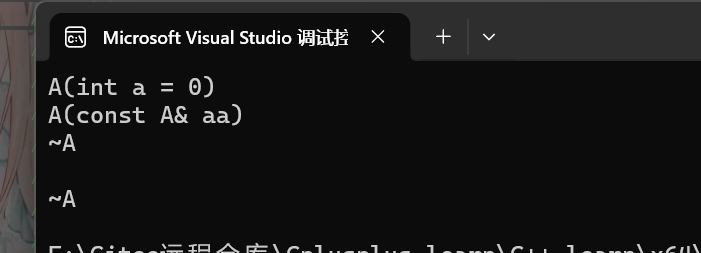
A aa1;
f1(aa1);
cout << endl;
return 0;
}在先前我们已经讲了传值传参会调用拷贝构造,那么这边会不会优化呢,是不会的,因为优化现在大多是针对一个表达式连续拷贝才进行优化,这个代码运行的效果如下
我们也学了匿名对象,所以我们可以把这个代码优化为如下形式,这个时候因为连续拷贝,所以编译器就进行了优化,代码块如下
cpp
int main()
{
//匿名对象
f1(A());
cout << endl;
return 0;
}效果如下
隐式类型转化的情况
cpp
int main()
{
//隐式类型,连续构造+拷⻉构造->优化为直接构造
f1(1);
return 0;
}这也是因为连续构造的情况,先是构造临时对象接受1,传参时候因为是传值传参,又要进行拷贝构造,所以编译器直接优化为了直接构造
传返回值的情况
样例一
cpp
int main()
{
// 传值返回
// 不优化的情况下传值返回,编译器会⽣成⼀个拷⻉返回对象的临时对象作为函数调⽤表达式的返回值
// ⽆优化 (vs2019 debug)
// ⼀些编译器会优化得更厉害,将构造的局部对象和拷⻉构造的临时对象优化为直接构造(vs2022 debug)
f2();
cout << endl;
return 0;
}f2函数内会构造一个对象,因为是传值返回,所以返回的是一个临时对象,所以还会有一次拷贝构造,但是VS2022优化比较厉害,会把这俩步优化为直接构造,在19版可以看到构造和拷贝构造,22版的情况下效果是如下图
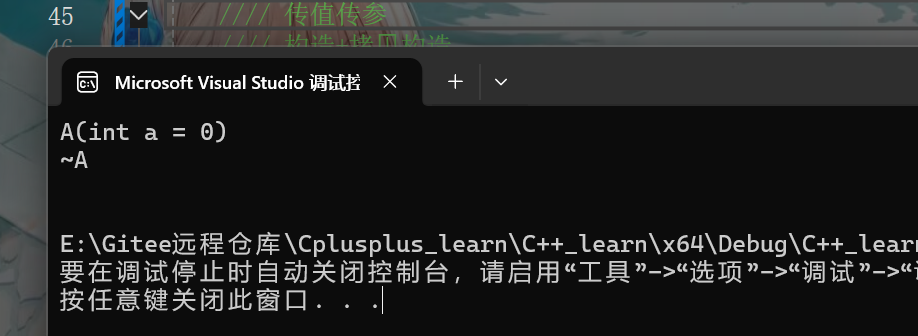
这边的优化其实就是把f2函数内的aa构造给优化掉了,直接就是对返回值进行构造临时对象了,我们可以再加一点代码来观察,代码如下
cpp
#include<iostream>
using namespace std;
class A
{
public:
A(int a = 0)
:_a(a)
{
cout << "A(int a = 0)" << endl;
}
A(const A& aa)
:_a(aa._a)
{
cout << "A(const A& aa)" << endl;
}
A& operator=(const A& aa)
{
cout << "A operator=(const A& aa)" << endl;
if (this != &aa)
{
this->_a = aa._a;
}
return *this;
}
~A()
{
cout << "~A" << endl;
}
void Print()
{
cout << _a << endl;
}
private:
int _a = 1;
};
void f1(A aa)
{}
A f2()
{
A aa;
return aa;
}
int main()
{
// 传值返回
// 不优化的情况下传值返回,编译器会⽣成⼀个拷⻉返回对象的临时对象作为函数调⽤表达式的返回值
// ⽆优化 (vs2019 debug)
// ⼀些编译器会优化得更厉害,将构造的局部对象和拷⻉构造的临时对象优化为直接构造(vs2022 debug)
f2().Print();
cout << "***********************";
return 0;
}他的输出效果如下
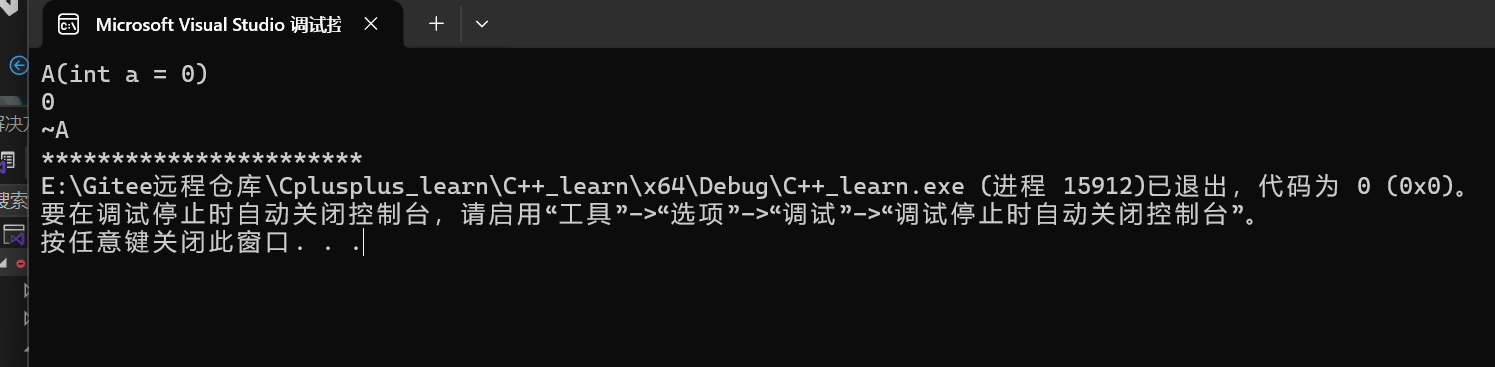
我们可以发现析构是在调用函数之后,是在程序结束前,所以这是临时对象的拷贝析构,因此f2函数内的aa对象就被优化掉了
22的优化其实是很激进的,我们把代码再改一手,变为如下代码
cpp
#include<iostream>
using namespace std;
class A
{
public:
A(int a = 0)
:_a(a)
{
cout << "A(int a = 0)" << endl;
}
A(const A& aa)
:_a(aa._a)
{
cout << "A(const A& aa)" << endl;
}
A& operator=(const A& aa)
{
cout << "A operator=(const A& aa)" << endl;
if (this != &aa)
{
this->_a = aa._a;
}
return *this;
}
~A()
{
cout << "~A" << endl;
}
A& operator++()
{
_a++;
return *this;
}
void Print()
{
cout << _a << endl;
}
private:
int _a = 1;
};
void f1(A aa)
{}
A f2()
{
A aa;
++aa;
return aa;
}
int main()
{
// 传值返回
// 不优化的情况下传值返回,编译器会⽣成⼀个拷⻉返回对象的临时对象作为函数调⽤表达式的返回值
// ⽆优化 (vs2019 debug)
// ⼀些编译器会优化得更厉害,将构造的局部对象和拷⻉构造的临时对象优化为直接构造(vs2022 debug)
f2().Print();
cout << "***********************";
return 0;
}在有了自增的情况下,编译器依旧可以优化为单次构造,他以++运算结束后对象内的成员为基准直接构造临时对象返回,我们通过运行结果就可以看出来
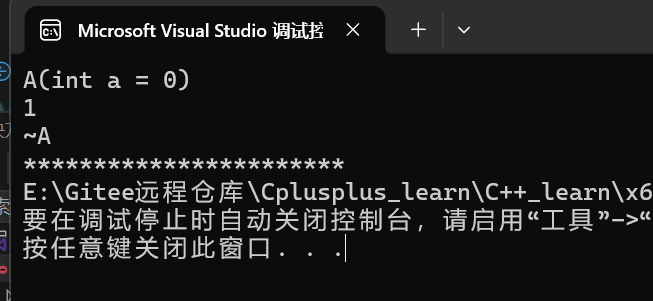
样例二
cpp
int main()
{
// 返回时⼀个表达式中,连续拷⻉构造+拷⻉构造->优化⼀个拷⻉构造 (vs2019 debug)
// ⼀些编译器会优化得更厉害,进⾏跨⾏合并优化,将构造的局部对象aa和拷⻉的临时对象和接收返回值对象aa2优化为⼀个直接构造。(vs2022 debug)
A aa2 = f2();
cout << "******************";
return 0;
}这个代码块首先是要构造aa对象,因为是传值返回,所以要拷贝构造(生成临时对象),然后再对这个临时对象拷贝构造实例化出aa2
但在22版本的VS中,编译器会把这三步构造直接优化成一步构造,效果如下
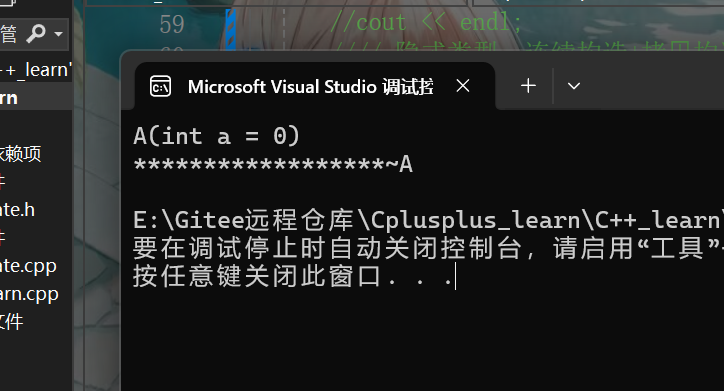
我们可以发现,编译器把aa和临时对象全优化掉了
样例三
cpp
int main()
{
A aa1;
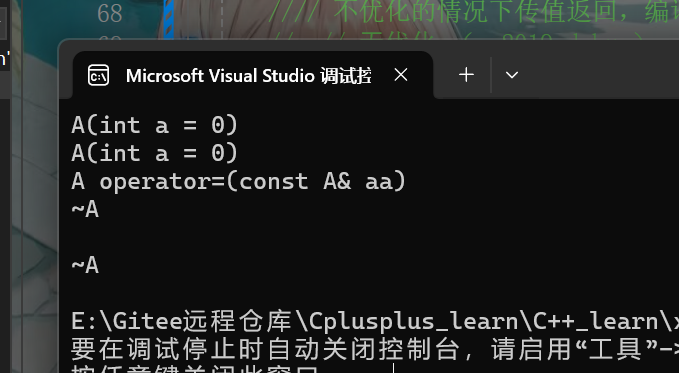
// ⼀个表达式中,开始构造,中间拷⻉构造+赋值重载->⽆法优化(vs2019 debug
// ⼀些编译器会优化得更厉害,进⾏跨⾏合并优化,将构造的局部对象aa和拷⻉临时对象合并为⼀个直接构造(vs2022 debug)
aa1 = f2();
cout << endl;
return 0;
}这个代码块就是先构造,构造完后,函数体内先构造aa,再拷贝构造一个临时对象返回,随后用赋值运算符重载赋值
实际运行效果如下,我们可以发现f2函数的构造和拷贝构造被优化成了一个构造
9.结语
那么,C++类和对象的内容就全部讲解完毕啦,希望以上内容对你有所帮助,感谢观看,若觉得写的还可以,可以分享给朋友一起来看哦,毕竟一起进步更有动力嘛,当然能关注一下就更好啦
