在上一篇文章中,我们已经从整体上梳理了线程的概念,并深入对比了线程与进程之间的区别。
然而,理解"线程是什么"只是第一步,真正掌握线程的关键,在于能够在程序中创建、控制并管理线程的生命周期。
因此,从本篇开始,我们将进入一个更加偏"实战"的阶段------线程控制。
二、线程控制
1 POSIX 线程库
问题:Linux 中不存在真正的线程,为什么又有线程库?
在上一篇文章中我们得知:Linux 内核中不存在真正的线程,只存在轻量级进程。对于学习操作系统教材的初学者,如果直接面对 Linux 的轻量级进程,对于初学者来说学习成本较高,也不利于跨平台开发。因此,在用户态必须提供线程的概念,而无需关心底层的轻量级进程实现。基于这一需求,POSIX 标准定义了线程相关接口,并由 libc 实现进行封装,形成了 POSIX 线程库。
POSIX 线程库的本质是对 Linux 内核中 clone 等系统调用的封装,屏蔽 Linux 轻量级进程的相关内容,使得用户只需关注线程,无需关注轻量级进程。
对于 POSIX 线程库,绝大数函数名字都是以 "pthread_" 开头。使用 POSIX 线程库的函数需要引入头文件 <pthread.h> 且链接 POSIX 线程库时需要带 "-l pthread" 选项
cpp#include <pthread.h> g++ -o test test.cpp -l pthread
2 创建进程
cpp
#include <pthread.h>
int pthread_create(
pthread_t *thread,
const pthread_attr_t *attr,
void *(*start_routine)(void *),
void *arg
);功能:创建一个新线程。
参数说明:
pthread_t *thread:输出型参数,用来让调用层获取线程 ID
const pthread_attr_t *attr:线程属性(如:栈大小、分离状态等),一般传 NULL 表示使用默认的线程属性
void *(*start_routine)(void *):线程入口函数,类似主线程的 main 函数,线程创建后从这里执行
void *arg:传递给线程入口函数的参数,类型是 void* ,可以传任意类型的数据
返回值:成功返回0,失败返回错误码(不是返回 -1)
注意:pthread 系列函数出错时不依赖全局变量 errno返回错误,只是通过返回值返回错误核心原因:多线程环境下 errno 不安全
在传统C语言中,errno 是一个全局变量,用于保存最近一次系统调用错误。
但是在多线程环境中,如果多个线程同时运行:线程 A 调用失败,设置 errno,同时线程 B 调用失败,也设置 errno,就会导致 errno 会被不同线程互相覆盖,导致错误信息错乱。
解决方案:线程局部存储(TLS)
线程局部存储(TLS)本质是每个线程 "独享" 一份全局变量的机制,通常位于进程虚拟地址空间的内存映射区。
在现代 glibc 中:errno 不再是全局变量,而是每个线程都有独立的一份 errno。
但 pthread 系列函数依旧不依赖 errno 返回错误信息,而是通过返回值。
注意:上面设计依旧存在意义,虽然 pthread 不通过 errno 返回,但是 pthread 内部调用系统调用可能会修改 errno,而线程局部存储就保证了 errno 的线程安全。
结论:线程拥有独立的 errno
cpp
#include <pthread.h>
pthread_t pthread_self(void);功能:返回调用层的线程 ID
代码示例:
cpp
#include <iostream>
#include <pthread.h>
#include <string>
#include <cstring>
#include <cstdio>
#include <unistd.h>
void *routinue(void *arg)
{
std::string name = static_cast<const char*>(arg);
while(true)
{
std::cout << "新线程ID: " << pthread_self() << std::endl;
sleep(1);
}
}
int main()
{
pthread_t tid;
int n = pthread_create(&tid, nullptr, routinue, (char*)"thread-1");
if(n != 0)
{
std::cerr << "线程创建错误: " << strerror(n) << std::endl;
}
while(true)
{
std::cout << "主线程ID: " << pthread_self() <<std::endl;
sleep(1);
}
pthread_join(tid, nullptr);
return 0;
}
cpp
./thread
主线程ID: 新线程ID: 140427408905984140427425818432
新线程ID: 140427408905984
主线程ID: 140427425818432
新线程ID: 140427408905984主线程ID:
140427425818432
新线程ID: 140427408905984
主线程ID: 140427425818432
新线程ID: 140427408905984
主线程ID: 140427425818432使用PS命令查看线程信息**-L** 选项:打印线程信息
cpp
ps -aL | head -1 && ps -aL | grep thread
PID LWP TTY TIME CMD
19621 19621 pts/0 00:00:00 thread
19621 19622 pts/0 00:00:00 thread在 Linux 内核中,LWP 就是轻量级进程的 ID,在这里有一个轻量级进程的 ID 与进程 ID 相同,它就是该进程的主线程。
对于 pthread_self 得到的线程 ID,是 pthread 库维持的线程ID。 本质是虚拟地址空间上的一个地址(线程控制块(TCB)的起始地址),它里面记录着这个线程的基本信息,包括线程 ID、线程栈、线程局部变量、寄存器等属性。其中线程 ID、线程栈、线程局部存储都是线程独有的。
对于 Linux 内核,它是不认识库层面的线程 ID,在调度、执行线程的时候只认识 LWP。
主线程的栈在虚拟地址空间的栈区上,而其他线程的栈在内存映射区上。
对于打印的信息为什么是混乱的,是因为多个线程共享同一个文件描述符,操作同一个内核文件对象。同时,如果使用的是带缓冲的 I/O(如:std::cout、printf),它们还会共享对应的用户态缓冲区。当多个线程没有进行同步,同时执行输出操作时,各个线程的输出可能发生交叉,最终导致打印信息混乱。
3 线程终止
3.1 为什么需要线程终止
线程完成自己的任务后,需要结束运行并释放相应资源。如果不能正确终止,不仅浪费系统资源,还可能导致线程资源泄漏。因此,POSIX 线程库提供了多种线程终止方式。
3.2 线程终止的四种方式
(1)线程函数执行结束(最常见)
cpp
void* routine(void* arg)
{
// 执行任务
return nullptr;
}(2)调用 pthread_exit()
cpp
#include <pthread.h>
void pthread_exit(void* retval);功能:终止当前线程,返回线程退出值(retval:表示线程退出值,原理后面讲)
cpp
void* routine(void*)
{
// 执行任务
pthread_exit((void*)"success");
}注意:对于线程终止,不能采用exit()。因为exit()的作用是终止整个进程。
(3)通过 pthread_cancel 请求取消线程
可以向指定线程发送一个取消请求:
cpp
#include <pthread.h>
int pthread_cancel(pthread_t thread);作用:pthread_cancel 并不会立即终止目标线程,它只是发送一个取消请求。目标线程通常会在执行到取消点时响应该请求并退出。因此,线程是否能够及时退出,还取决于其取消状态、取消类型以及是否执行到了取消点。在绝大数情况下都会响应,进而线程退出。(如果对其感兴趣,可以查阅相关资源进行理解)
(4)整个进程结束
在主函数中 return 0; 或者在任何线程中调用 exit(0) 都会导致整个进程结束,因此所有线程都会一起结束.。
4 线程等待
4.1 为什么需要线程等待
默认情况下,线程创建后处于 Joinable(可连接) 状态。当线程执行结束时,并不是所有资源都会立即释放,而是会保留部分资源,等待其他线程调用 pthread_join() 进行回收。
已经释放的资源
线程执行流结束后,一些仅与线程运行过程相关的资源已经不再需要,例如:
- LWP(轻量级进程)结束运行,不再参与 CPU 调度
- CPU 寄存器上下文被释放
- 线程执行状态等运行时资源被内核回收
这些资源会随着线程退出而释放。
尚未释放的资源
为了支持其他线程获取线程的退出状态,线程仍需要保留部分资源,例如:
- 线程栈
- 线程控制块(TCB)维护的线程描述信息(如线程退出值、线程 ID、退出状态等)
- 线程局部存储(TLS)
这些资源不会在线程结束时立即释放,而是会一直保留,直到其他线程调用 pthread_join() 完成回收后,才会真正释放。
因此,线程等待的主要作用,就是回收线程退出后仍然保留的资源,并获取线程的退出状态。
4.2 pthread_join
cpp
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);功能:阻塞等待目标线程结束
参数说明:
pthread_t thread:需要等待的目标线程ID
void **retval:输出型参数,用于接收线程退出值,不关心线程退出值时传 nullptr
线程返回值:retval 为什么是 void**示例:
cppvoid* routine(void*) { return (void*)100; }主线程:
cppvoid* ret = nullptr; pthread_join(tid, &ret); std::cout << (long)ret << std::endl;我们定义 ret 时,ret 变量本身是占用内存空间,有虚拟地址的,只不过占用的空间里面存放的是空指针(即0x00000000),传参传递的是 ret 的地址,意味着 pthread_join,可以用二级指针接收参数,对其解引用得到的是 ret 占用的空间,可以给其赋值。
注意:上述过程并没有发生空指针的解引用
注意事项一个线程只能被 join 一次
多个线程不能同时 join 同一个线程
线程不能等待自己
线程状态为分离时,不能被 join
5 线程分离
默认情况下,新创建的线程都处于 joinable(可连接) 状态。当线程退出后,其部分资源不会立即释放,而是需要其他线程调用 pthread_join() 进行回收。
然而,在实际开发中,并不是所有线程都需要获取退出状态。例如,一些后台工作线程、日志线程等,它们执行完任务后即可退出,并不需要其他线程等待。因此,如果确定该线程执行完不需要被获取退出状态,可以将线程状态设置为 Detached(分离) 状态。
分离状态的线程在退出时会自动回收线程资源,无需其他线程再调用 pthread_join() 。
cpp
#include <pthread.h>
int pthread_detach(pthread_t thread);功能:将指定线程设置为分离状态
参数:需要分离的目标线程 ID
线程既可以由其他线程进行分离,也可以实现自分离。
例如:
cpp
// 其他线程分离目标线程
pthread_detach(tid);
cpp
// 线程自己分离自己
pthread_detach(pthread_self());需要注意的是,线程一旦被设置为分离状态,其退出后资源会自动释放,因此不能再调用 pthread_join() 对其进行等待,否则将导致调用失败。
6 线程控制综合案例------线程生命周期演示
cpp
#include <iostream>
#include <pthread.h>
#include <string>
#include <cstring>
#include <unistd.h>
// A 线程分离执行,需要 join
void* Routine_A(void* arg)
{
std::string name = static_cast<const char*>(arg);
int cnt = 5;
while(cnt--)
{
std::cout << name << " ID: " << pthread_self() << std::endl;
sleep(1);
}
return (void*)100;
}
// B 线程分离执行
void* Routine_B(void* arg)
{
pthread_detach(pthread_self());
std::string name = static_cast<const char*>(arg);
int cnt = 5;
while(cnt--)
{
std::cout << name << " ID: " << pthread_self() << std::endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tid_A;
int n = pthread_create(&tid_A, nullptr, Routine_A, (char*)"thread_A");
if(n != 0)
{
std::cerr << "pthread_create fail: " << strerror(n) << std::endl;
return 1;
}
pthread_t tid_B;
n = pthread_create(&tid_B, nullptr, Routine_B, (char*)"thread_B");
if(n != 0)
{
std::cerr << "pthread_create fail: " << strerror(n) << std::endl;
return 1;
}
// 获取 A 的返回值并打印
void* ret = nullptr;
pthread_join(tid_A, &ret);
std::cout << "线程 A 的返回值: " << (long long)ret << std::endl;
// 防止主线程退出时线程 B 没有结束
sleep(10);
return 0;
}
cpp
./thread
thread_A ID: 139667748501248
thread_B ID: 139667740108544
thread_A ID: 139667748501248
thread_B ID: 139667740108544
thread_A ID: 139667748501248
thread_B ID: 139667740108544
thread_A ID: 139667748501248
thread_B ID: 139667740108544
thread_A ID: 139667748501248
thread_B ID: 139667740108544
线程 A 的返回值: 1007 线程在 POSIX 库中的底层原理
在前面的内容中,我们已经介绍了线程 ID、线程栈、线程局部存储(TLS)等基本概念,并简单了解了它们的作用。然而,这些内容更多停留在现象层面,并没有深入分析它们在底层究竟是如何实现的。
本章节将从 pthread_create() 被调用开始,结合 Linux 内核和 POSIX 线程库(pthread)的实现机制,完整分析一个线程从创建、运行到退出的整个生命周期。
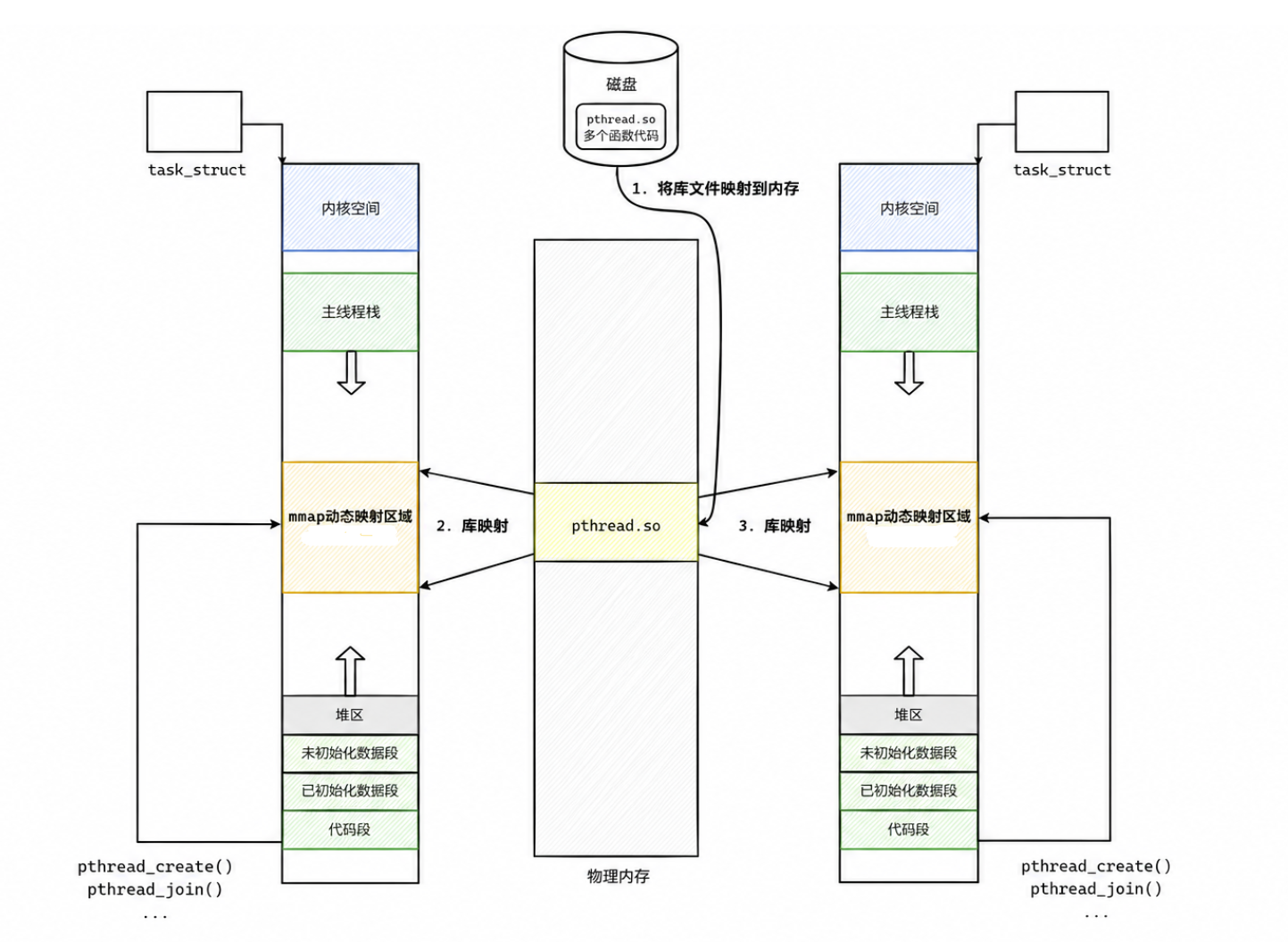
可执行程序、静态库和动态库均采用 ELF格式。链接阶段,链接器会将目标文件中的各个节进行合并、完成重定位,并生成程序头、动态链接信息以及 GOT、PLT 等数据结构。对于动态库,可执行文件中仅保留对动态库的依赖信息,而不会将库代码直接复制到可执行文件中。
当程序运行时,内核首先加载可执行文件,并启动动态链接器。动态链接器通过 mmap 系统调用将所需的动态库映射到进程虚拟地址空间的 mmap 动态映射区,建立相应的虚拟内存区域。在程序首次访问这些页面时,内核再通过缺页异常建立虚拟地址与物理页之间的映射关系。随后,动态链接器根据重定位信息解析外部符号,并将函数或全局变量的实际地址写入 GOT等数据结构,使程序能够正确访问动态库中的代码和数据。
pthread_create() 究竟做了什么事情?
当我们的代码调用 pthread_create() 函数时,CPU 会首先跳转到已经映射到进程虚拟地址空间中的 pthread 动态库,开始执行线程库代码。
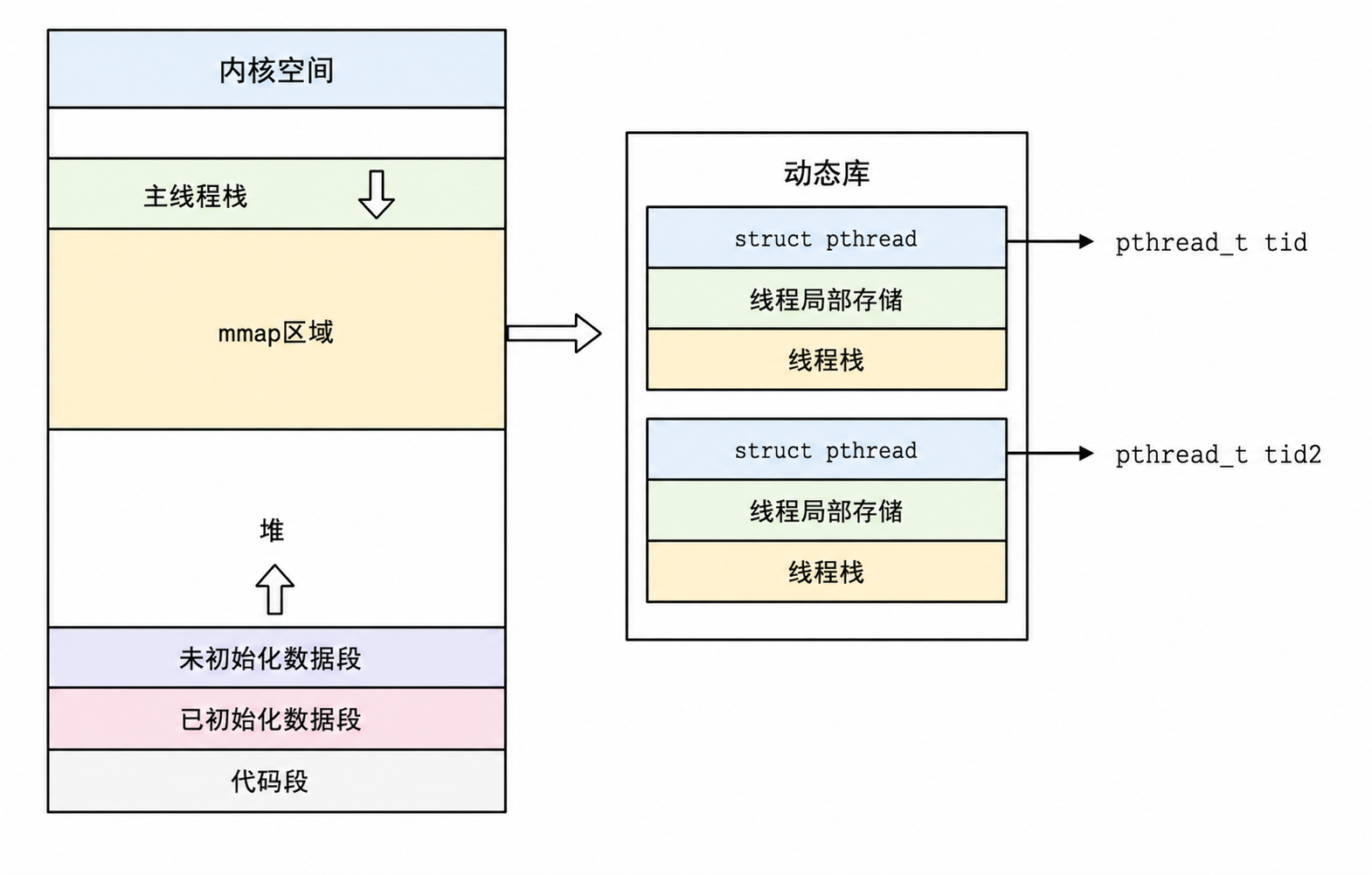
在线程真正创建之前,POSIX 线程库会先为新线程准备运行环境,包括:
- 创建线程描述符(struct pthread)
- 为线程申请独立的线程栈(Thread Stack);
- 为线程建立线程局部存储(TLS,Thread Local Storage);
- 初始化线程属性、线程 ID、同步信息等相关数据结构。
在 Linux 内核中,这些资源通常会通过一次
mmap系统调用 申请一整块匿名映射内存,再在这块内存中划分出 线程描述符 、线程局部存储 和 线程栈 等区域,因此这些数据一般位于进程虚拟地址空间的 mmap 动态映射区。完成这些准备工作之后,线程库会调用 clone 系统调用 创建新的轻量级进程。由于 clone 指定了共享地址空间、文件描述符、信号处理器等资源的共享标志,因此新创建的轻量级进程能够与创建它的线程共享同一个进程资源,从而共同组成一个 POSIX 线程。
总结:在库层面创建线程相关的数据结构,在内核层面创建轻量级进程
线程 ID 是什么?
cpptypedef unsigned long int pthread_t;在 Linux 的 glibc 实现中,线程ID的类型是一个无符号长整型,本质是 struct pthread 结构体的起始虚拟地址,而不是内核中的轻量级进程 ID。
线程返回值是怎么传递的?在线程控制块(struct pthread)中,存在着一个成员变量 void* ret。
在线程运行结束后,线程将返回值放在线程控制块的 ret 变量中,线程在被 join 的时候,将 ret 的值交给用户用来接收返回值的参数。
pthread_exit() 与线程函数 return 最终都会将返回值保存到 struct pthread 中,等待pthread_join()获取。
因此,线程返回值并不是直接返回给创建者,而是先保存在 struct pthread 中,再由pthread_join()取出并返回给等待线程。
为什么未分离线程需要 join?当一个未分离的线程运行结束后,内核会立即回收与轻量级进程(LWP)相关的资源,例如task_struct 、内核栈等;但是线程库仍然保留该线程对应的 struct pthread、线程栈、TLS 以及等资源,等待其他线程调用 pthread_join() 获取返回值并完成资源回收。
如果线程始终没有被 pthread_join(),且进程一直没有退出,那么这些用户态资源将一直无法释放,从而造成线程库层面的内存泄漏。因此,对于未分离线程,通常都需要调用 pthread_join() 来完成资源回收。
因此,pthread_join() 的作用不仅是等待线程结束,更重要的是回收线程在用户态申请的各种资源。
线程栈是什么,作用是是什么?线程栈是线程拥有的一段独立且固定(它的大小与申请内存的大小有关)的虚拟地址空间,通常由线程库通过 mmap 在进程虚拟地址空间的 mmap 映射区申请。每个线程都拥有自己独立的线程栈,用于保存函数调用过程中产生的栈帧,包括局部变量、函数参数、返回地址以及寄存器现场等信息。
当 CPU 执行线程时,栈指针(SP/RSP)始终指向当前线程的线程栈,线程调用函数、压栈、出栈等操作都发生在线程栈上。因此,不同线程之间互不共享线程栈,从而保证了函数调用过程彼此独立。
线程切换时,CPU 只需切换栈指针寄存器,即可切换到另一线程的执行现场。
线程局部存储是什么?线程局部存储是一块线程私有的存储区域,用于保存线程独享的数据。对于使用 pthread 库声明的变量,以及线程运行过程中需要维护的 error等线程私有数据,都会存放在 TLS 中。
TLS 的本质就是为每个线程维护一份独立的数据副本,使多个线程能够同时访问同一个全局变量名,而互不影响,从而避免线程安全问题。