这篇博客将介绍YOLO家族。包括对象检测、对象检测与图像分类的区别、检测中的挑战、什么是单级和两级对象检测器。
首先将简要介绍YOLOv1的单级探测器,YOLOv2、YOLOv3和YOLOv4。以及讨论Ultralytics开发的YOLOv5,这是继YOLOv4之后在PyTorch中实现的第一个YOLO模型。
然后介绍百度在飞浆框架中实现的PP-YOLO,它显示出优于YOLOv4和EfficientDet的有希望的结果。
然后将讨论一种称为Scaled-YOLOv4的YOLOv4扩展,该扩展基于跨阶段部分方法,可以上下缩放,在速度和精度上都优于以前的大小对象检测模型(如EfficientDet、YOLOv4和PP-YOLO)的基准。
紧接着继续讨论PP-YOLO的第二个版本,即PP-YOLOv2,它对PP-YOLO进行了各种改进,从而显著提高了MS COCO2017测试集的性能(即从45.9%mAP提高到49.5%mAP)。
最后将讨论YOLOX,它是继YOLOv1之后的一种无锚目标检测网络。YOLOX在CVPR研讨会的流媒体感知挑战赛中获得第一名,在准确性和速度上均优于YOLOv5大型和纳米机型。
YOLO家族简介
目标检测是计算机视觉中最重要的课题之一。大多数计算机视觉问题都涉及到检测视觉对象类别,如行人、汽车、公共汽车、人脸等。这不仅限于学术界,而且在视频监控、医疗保健、车内传感和自动驾驶等领域具有潜在的实际商业用例。许多用例尤其是自动驾驶,需要高精度和实时推理速度。
这篇博客将介绍一种速度和精度都符合要求的物体检测器------YOLO家族,涵盖所有YOLO变体(例如,YOLOv1、YOLOv2、...、YOLOX、YOLOR)。
YOLO是一种单级物体探测器,用于实现两个目标(即速度和精度)。
目标检测有三类算法:
- 基于传统计算机视觉
- 基于两阶段深度学习的算法
- 基于单阶段深度学习的算法
本课程是关于YOLO对象检测器的7部分系列的第一个教程:
- YOLO家族简介(今天的教程)
- 了解实时目标检测网络:你只看一次(YOLOv1)
- 更好、更快、更强的目标探测器(YOLOv2)
- 使用COCO评估器的平均精度(mAP)
- 使用Darknet-53和多尺度预测(YOLOv3)进行增量改进
- 实现目标检测的最佳速度和精度(YOLOv4)
- 在自定义数据集上训练YOLOv5对象检测器
要了解YOLO家族是如何进化的,每种变体在检测图像中的物体方面都不同于之前的版本,只需继续阅读即可。
2. 对象检测
图像分类的目标是回答"图像中存在什么?模型试图通过为图像指定特定标签来理解整个图像。
在单图像场景中,分类足以表达图像;但在多场景中,无法用单个标签表达图像中的内容,于是需要目标检测。
目标检测的另一个关键用例是自动车牌识别,要检测车牌号:首先需要用物体检测器识别车牌的位置,然后应用第二种算法来识别数字。
目标检测涉及分类和定位任务,用于分析图像中可能存在多个对象的更真实情况。
目标检测是一个两步过程;第一步是查找对象的位置。第二步是将这些边界框分类为不同的类,因此对象检测会遇到与图像分类相关的所有问题。此外,它还面临本地化和执行速度方面的挑战。
3. 挑战
-
拥挤或混乱的场景:图像中的对象太多使其非常拥挤。例如遮挡可能很大,对象可能很小,并且比例可能不一致。
-
类内方差(Intra-Class Variance):对象检测的另一个主要挑战是正确检测具有高方差的同一类对象。例如有六种狗,它们都有不同的大小、颜色、毛发长度、耳朵等,因此检测同一类别的这些对象可能很有挑战性。
-
类不平衡(Class Imbalance):指前景-背景类不平衡。几乎影响到所有形式,无论是图像、文本、时间序列。例如考虑包含很少主要对象的图像。图像的其余部分由背景填充。因此,该模型将查看图像(数据集)中的许多区域,其中大多数区域将被视为负片。由于这些负面因素,模型无法学习到任何有用的信息,可能会淹没模型的整个训练。
-
许多其他挑战与对象检测相关,如遮挡、变形、视点变化、照明条件和实时检测的基本速度。
4. 目标检测历史
目标检测是计算机视觉中最关键和最具挑战性的问题之一,在过去的十年中,它的发展创造了历史,取得了重大进展;当然如果没有深层神经网络的强大功能和NVIDIA GPU的大规模计算,这一切都不可能实现。
在目标检测的历史上,有两个截然不同的时代:
- 传统的计算机视觉方法一直沿用到2010年;
- 从2012年开始,当AlexNet(一种图像分类网络)赢得ImageNet视觉识别挑战赛时,卷积神经网络的新时代开始了。
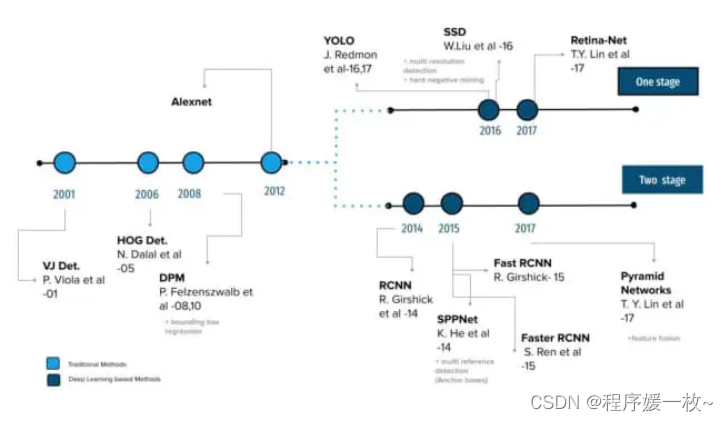
上图显示了目标检测的路线图,从2004年的Viola--Jones探测器到2019年的EfficientDet。
大多数传统的目标检测算法,如Viola--Jones、方向梯度直方图(Histogram of Oriented Gradients HOG)和可变形零件模型(Deformable Parts Model DPM),都依赖于从图像中提取手工特征,如边缘、角点、梯度和经典的机器学习算法。例如,第一款物体检测器Viola--Jones仅设计用于检测人类的正面,在侧面和上下脸上表现不佳。
然后,2012年迎来了一个新时代。当AlexNet(一种深度卷积神经网络(Deep Convolutional Neural Network CNN)架构)出于改进ImageNet挑战赛结果的需要而诞生时,这场彻底改变了计算机视觉游戏的革命在2012 ImageNet LSVRC-2012挑战赛上取得了相当高的准确率,准确率为84.7%,而第二好的准确率为73.8%。
然后,这些最先进的图像分类体系结构开始用作目标检测管道中的特征提取器只是时间问题。这两个问题都是相互关联的,它们依赖于学习健壮的高级特征。因此,Girschick et al.(2014)介绍了如何将卷积特征用于目标检测,引入了R-CNN(将CNN应用于区域建议)。从那时起,目标检测开始以前所未有的速度发展。
深度学习检测方法可以分为两个阶段;第一种称为两阶段检测算法,在多个阶段进行预测,包括RCNN、Fast RCNN和Faster RCNN等网络。
第二类探测器称为单级探测器,如SSD、YOLO、EfficientDet等。
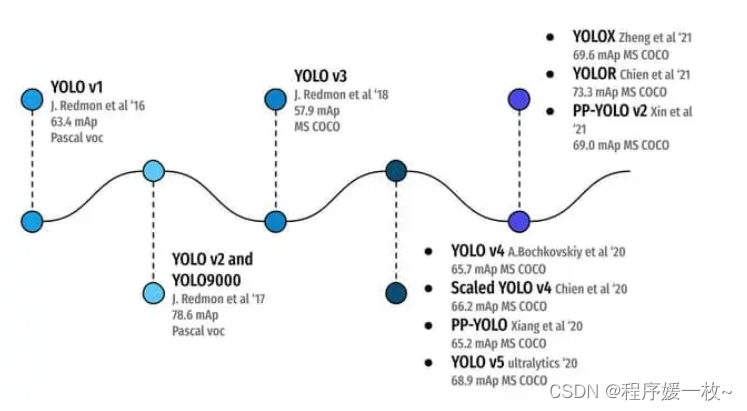
如上图,可以看到所有YOLO对象检测算法及其演变过程,从2016年的YOLOv1在Pascal VOC(20类)数据集上实现63.4mAP到2021的YOLOR,在更具挑战性的MS COCO数据集(80类)上实现73.3 mAP。这就是学术界的魅力所在。凭借不断的努力和弹性,YOLO目标检测已经取得了长足的进步!
5. 什么是单级物体检测器?
单级目标检测器是一类单级目标检测体系结构。将目标检测视为一个简单的回归问题。例如,输入到网络的图像直接输出标签类概率和边界框坐标。
这些模型跳过了区域建议网络(Region Proposal Network),它通常是两阶段对象检测器的一部分,两阶段对象检测器是图像中可能包含对象的区域。
在单阶段中,将检测头直接应用到特征地图上,而在两阶段中首先在特征地图上应用区域建议网络。
然后,将这些区域进一步传递到第二阶段,对每个区域进行预测。快速RCNN和掩码RCNN是一些最流行的两级对象检测器。
两级检测器比单级目标探测器更精确,但它们涉及多个阶段的推理速度较慢。单级检测器比两级检测器快得多。
6. YOLO
2016年,Joseph Redmon发布了第一个单级目标检测器:统一的实时目标检测。
YOLO是目标检测领域的一个突破,因为它是第一个将检测视为回归问题的单阶段目标检测方法。检测体系结构只需查看一次图像即可预测对象及其类标签的位置。
与两阶段检测器方法(Fast RCNN、Faster RCNN)不同,YOLOv1没有提案生成器和细化阶段;它使用一个单一的神经网络,可以在一次过程中从整个图像中预测类别概率和边界框坐标。由于检测管道本质上是一个网络,因此可以端到端进行优化;可以将其视为一个图像分类网络。
由于该网络旨在以类似于图像分类的端到端方式进行训练,因此该体系结构速度非常快,基本YOLO模型预测的图像速度为45 FPS(每秒帧数),作者还提出了一种更轻的YOLO版本,称为Fast YOLO,具有更少的以155 FPS处理图像的层。
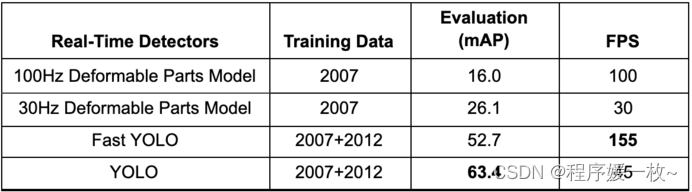
如上表所示,YOLO实现了63.4 mAP(平均精度),是其他实时探测器的两倍多。YOLO和Fast YOLO在平均精度(接近2倍)和FPS方面都比DPM的实时对象检测器变体有相当大的优势。
YOLO的可推广性在来自互联网的艺术品和自然图像上进行了测试。它的性能大大优于可变形零件模型(Deformable Parts Model DPM)和基于区域的卷积神经网络(Region-Based Convolutional Neural Networks RCNN)等检测方法。
7. YoLO2
Redmon和Farhadi(2017)发表了更好、更快、更强的YOLO9000:俩者在训练策略上有所不同。
YOLOv2接受了Pascal VOC和MS COCO等检测数据集的培训。同时,YOLO9000被设计为通过在MS COCO和ImageNet数据集上联合训练来预测9000多个不同的对象类别。
改进的YOLOv2模型在速度和精度上都优于最先进的方法,如更快的RCNN和SSD。其中一种技术是多尺度训练,它允许网络在不同的输入大小下进行预测,从而在速度和准确性之间进行权衡。
在416×416输入分辨率下,YOLOv2在VOC 2007数据集上实现了76.8 mAP,在544×544输入的同一数据集上,YOLOv2获得78.6 mAP和40 FPS。
几乎所有的YOLOv2变体都比其他检测框架在速度或准确性方面表现得更好,并且在YOLOv2中可以观察到精确度(mAP)和FPS之间的急剧权衡。
8. YoLO3
Redmon和Farhadi(2018)发表了YOLOv3的增量改进。作者对网络架构进行了许多设计更改,并采用了YOLOv1特别是YOLOv2的大部分其他技术。
YOLO3介绍了一种新的网络体系结构Darknet-53------一个比以前大得多的网络,而且更精确、更快。它在320×320、416×416等各种图像分辨率下进行训练。在320×320分辨率下,YOLOv3以45 FPS的速度运行,达到28.2 mAP,与单次激发探测器(SSD321)一样精确,但速度快3倍。
9. YOLO4
2020年,Bochkovskiy等人发表了《YOLOv4:目标检测的最佳速度和精度》。YOLOv4是许多实验和研究的产物,结合了各种小型新技术,可以提高卷积神经网络的准确性和速度。对不同的GPU架构进行了广泛的实验,结果表明,YOLOv4在速度和准确性方面优于所有其他目标检测网络架构。
YOLOv4的运行速度是EfficientDet的两倍,性能相当棒,它将YOLOv3的mAP和FPS分别提高了10%和12%。
10. YOLO5
卷积神经网络(CNN)的性能在很大程度上取决于使用和组合的特征。例如,某些功能仅适用于特定的模型、问题陈述和数据集。但批量规范化和剩余连接等特性适用于大多数模型、任务和数据集。因此,这些特性可以称为通用特性。
Bochkovskiy等人利用这一想法并假设了一些通用特性,包括
- 加权剩余连接 Weighted-Residual-Connections (WRC)
- 跨级部分连接(Cross Stage Partial connections (CSP)
- 交叉小批量标准化 (Cross mini-Batch Normalization (CmBN)
- 自我对抗训练 (Self-adversarial training (SAT)
- Mish激活 (Mish activation)
- 马赛克数据扩充 (Mosaic data augmentation)
- DropBlock正则化(DropBlock regularization)
- CIoU损失( CIoU loss)
将上述功能结合起来,可获得最先进的结果:MS COCO数据集上43.5%的mAP(65.7%的mAP50)
YOLOv4模型结合了上述的更多功能,形成了"免费赠品袋",用于改进模型的培训,以及"特殊物品袋",用于提高目标探测器的精度。
11. YOLOv5
与YOLOv4相同,YOLO v5使用交叉级部分连接,主干和路径聚合网络中的Darknet-53作为颈部。主要改进包括新的马赛克数据增强(来自YOLOv3 PyTorch实现)和自动学习边界框锚。
YOLOv5是官方最先进的型号之一,拥有巨大的支持,更易于在生产中使用。最棒的是,YOLOv5是在PyTorch中本机实现的,消除了Darknet框架的限制(基于C编程语言,而不是从生产环境的角度构建)。Darknet框架随着时间的推移而发展,是一个很好的研究框架,可以使用TensorRT进行训练、微调和推理;
YOLOv5存储库提供了大量的资源,使其更容易在各种目标平台上进行培训、微调、测试和部署。
YOLOv5提供了比YOLOv4更好的性能和速度。
12. 马赛克增强的好处
mosaic数据增强的思想最初由Glenn Jocher在YOLOv3 PyTorch实现中使用,现在在YOLOv5中使用。马赛克增强将四幅训练图像按特定比例缝合成一幅图像,对于流行的COCO目标检测基准尤其有用,有助于模型学习解决众所周知的"小目标问题",即小目标检测不如大目标准确。
使用马赛克数据增强的好处是:
- 网络可以在一个图像中看到更多的上下文信息,甚至在其正常上下文之外。
- 允许模型学习如何以比通常更小的比例识别对象。
- 批量标准化将减少4倍,因为它将计算每层四个不同图像的激活统计信息。这将减少培训期间对大型小型批量的需求。
13. PP-YOLO
2021 10月,YOLOv5-v6.0发布,包含了许多新功能和错误修复带来了架构调整,并重点介绍了新的P5和P6纳米模型:YOLOv5n和YOLOv5n6。Nano模型的参数比以前的模型少约75%,从7.5M到1.9M,小到可以在移动设备和CPU上运行。
YOLOv5明显优于EfficientDet变体。即使是最小的YOLOv5变体(即YOLOv5n6)也比EfficientDet更快地达到可比精度。
就训练时间和准确性而言,YOLOv5 nano变体比YOLOv4 Tiny好得多。
有三个实现了YOLO的框架,即Darknet和PyTorch,以及飞浆框架,因此命名为PP-YOLO。飞浆是百度编写的一个深度学习框架,百度拥有大量的计算机视觉和自然语言处理模型库。
飞浆模型------一种高效的目标检测器。与YOLOv4类似,PP-YOLO目标检测器也是基于YOLOv3体系结构构建的。
PP-YOLO是PaddleDetection的一部分,是一个基于飞浆框架的端到端对象检测开发工具包。它提供了大量的目标检测体系结构、主干、数据增强技术、组件(如损耗、特征金字塔网络等),可以在不同的配置中进行组合,以设计最佳的目标检测网络。
简而言之,它提供了诸如对象检测、实例分割、多对象跟踪、关键点检测等图像处理功能,从而以更快更好的方式简化了这些模型的构建、训练、优化和部署中的对象检测过程。
PP-YOLO论文的目标不是发布一种新的对象检测模型,而是一种有效性和效率相对平衡的对象检测器,可以直接应用于实际应用场景。
单级检测模型一般由主干、检测颈和检测头组成。PP-YOLO的体系结构与YOLOv3和YOLO4检测模型非常相似。
PP-YOLO探测器分为三部分:
-
主干:一个完全卷积的网络,有助于从图像中提取特征地图。它在本质上类似于预训练的图像分类模型。该模型没有使用Darknet-53体系结构(在YOLOv3和YOLOv4中),而是使用ResNet50 vd dcn作为主干。
-
检测颈部:特征金字塔网络(FPN)通过特征地图之间的横向连接创建特征金字塔。
-
检测头:检测头是目标检测管道的最后一部分,用于预测对象的边界框(定位)和分类。PP-YOLO的头部与YOLOv3的头部相同。预测最终输出使用3×3卷积层,然后是1×1卷积层。
最终输出的输出通道为3(K+5),其中K是类数(对于MS COCO数据集为80),3是每个网格的锚数量。对于每个锚,前K个通道是预测类概率,四个通道是边界框坐标预测,一个通道是对象性得分预测。
14. 缩放-YOLOv4
Wang等人(2021)提出了"Scaled-YOLOv4:缩放跨阶段部分网络",可以有效地扩展网络的设计和规模,
所提出的基于跨阶段部分方法的检测网络可以上下扩展,在速度和精度上都优于以前的小型和大型目标检测模型的基准。此外,网络缩放方法修改网络的深度、宽度、分辨率和结构。
与其他最先进的探测器相比,Scaled-YOLOv4获得了最好的结果。
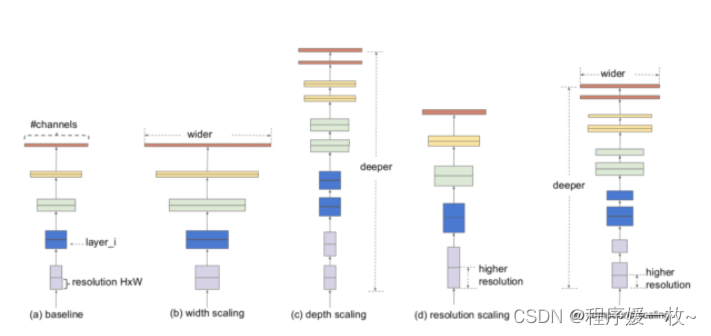
什么是模型缩放?
卷积神经网络结构可以在三个维度上进行缩放:深度、宽度和分辨率。网络的深度对应于网络中的层数。宽度与卷积层中滤波器或信道的数量相关。最后,分辨率就是输入图像的高度和宽度。
图21更直观地理解了这三个维度的模型缩放,其中(a)是一个基线网络示例;(b)
-(d)是仅增加网络宽度、深度或分辨率的一维的常规缩放;和(e)是一种拟议的(在EfficientDet中)复合缩放方法,该方法以固定比率均匀缩放所有三维。
Scaled-YOLOv4使用最佳网络缩放技术来实现YOLOv4 CSP->P5->P6->P7网络。
修改了宽度和高度的激活,从而可以更快地进行网络培训。
改进的网络体系结构:主干优化和颈部(路径聚合网络)使用CSP连接和Mish激活。
在训练过程中使用指数移动平均(EMA)。
对于网络的每个分辨率,都会训练一个单独的网络,而在YOLOv4中,单个网络会训练多个分辨率。
YOLOv4、YOLOv5、PP-YOLO和Scaled-YOLOv4相继达到了目标检测的最新水平。
15. CSP化YOLOv4
为了在大型图像中检测大型对象,作者发现增加CNN主干和颈部的深度和阶段数至关重要(据报道增加宽度几乎没有效果)。这允许他们首先扩大输入大小和阶段数量,并根据实时推理速度要求动态调整宽度和深度。
YOLOv4设计用于通用GPU上的实时目标检测。在Scaled-YOLOv4中,YOLOv4被重新设计为YOLOv4 CSP,以获得最佳的速度/精度权衡。
YOLOv4微型模型与Scaled-YOLOv4模型有不同的考虑,因为在边缘上各种限制因素发挥作用,如内存带宽和内存访问。对于YOLOv4 tiny的浅层CNN,作者希望OSANet在小深度上具有良好的计算复杂性。与其他tiny车型相比,YOLOv4 tiny实现了实时性能。
YOLOv4 large是为云GPU设计的;其主要目的是实现高精度的目标检测。此外,开发了一个完全CSP化的模型YOLOv4-P5,当宽度比例因子等于1时,YOLOv4-P6可以在视频上以每秒30帧的速度达到实时性能。
YOLOv4中的数据扩充是YOLOv4令人印象深刻的性能的关键贡献之一。在Scaled-YOLOv4中,作者首先在一个扩充较少的数据集上进行训练,然后在训练结束时打开扩充进行微调。他们还使用"测试时间扩充",其中对测试集应用了多个扩充。然后对这些测试增强进行平均预测,以进一步提高其非实时结果。
基于CSP方法的YOLOv4目标检测神经网络可上下扩展,适用于小型和大型网络;因此称为Scaled-YOLOv4,达到了最佳的速度和精度。
YOLOv4、YOLOv5、PP-YOLO和Scaled-YOLOv4相继达到了目标检测的最新水平。
2021,百度发布了PP-YOLO的第二个版本名为PP-YOLOv2:Xing Huang等人的实用目标检测器。发布在arXiv上,在目标检测领域达到了新的高度。目的是开发一种实用的目标检测器,该检测器能够获得良好的精度并以更快的速度执行推理。
如果KPI要以更快的速度实现良好的性能,选择PP-YOLOv2!
PP-YOLO是YOLOv3的增强版,其中主干被Darknet-53的ResNet50 vd取代。通过严格的消融研究,利用总共10个技巧,取得了许多其他改进,例如
- DropBlock正则化(DropBlock regularization)
- 可变形卷积(Deformable Convolutions)
- CoordConv
- 空间金字塔池(Spatial Pyramid Pooling)
- 借据损失和分行(IoU loss and branch)
- 电网灵敏度(Grid Sensitivity)
- 矩阵NMS(Matrix NMS)
- 更好的ImageNet预训练模型(Better ImageNet pretraining model)
16. 改进的选择
-
路径聚合网络(Path Aggregation Network PAN):为了检测不同尺度的目标,作者将PAN应用于目标检测网络的颈部。在PP-YOLO中,利用特征金字塔网络组成自下而上的路径。与YOLOv4类似,在PP-YOLOv2中,作者遵循PAN的设计来聚合自上而下的信息。
-
Mish激活功能:检测网络颈部采用Mish激活功能;由于PP-YOLOv2在ImageNet分类数据集上具有82.4%的top-1精度,因此使用了预先训练的参数。它被证明在各种实际物体探测器(如YOLOv4和YOLOv5)的主干中是有效的。
-
较大的输入大小:检测较小的对象通常是一个挑战,当图像穿过网络时,小规模对象的信息就会丢失。因此,在PP-YOLOv2中,输入大小增加,从而扩大了对象的面积。因此性能将得到提高。最大输入大小608增加到768。由于较大的输入分辨率占用更多内存,因此,批大小从每个GPU 24个图像减少到每个GPU 12个图像,在不同的输入大小之间均匀绘制【320、352、384、416、448、480、512、544、576、608、640、672、704、736、768】。
-
欠条感知分支(IoU Aware Branch):在PP-YOLO中,欠条感知损失是以与原始意图不一致的软权重格式计算的。因此,在PP-YOLOv2中,软标签格式可以更好地调整PP-YOLO的损失函数,并使其更加了解边界框之间的重叠。
17. YOLOX
YOLOX: 目前为止学习的唯一无锚YOLO对象检测器是YOLOv1,但YOLOX也以无锚方式检测对象。此外它还执行其他高级检测技术,如解耦头、利用鲁棒数据增强技术和领先的标签分配策略SimOTA,以实现最先进的结果。
YOLOX是在PyTorch框架中实现的,其设计考虑到了开发人员和研究人员的实际使用。因此,在ONNX、TensorRT和OpenVino框架中也提供了YOLOX部署版本。
在过去两年中,目标检测学术界的重大进展集中在无锚检测器、高级标签分配策略和端到端(无NMS)检测器上。然而,这些技术还没有应用于YOLO对象检测体系结构,包括最新的模型:YOLOv4、YOLOv5和PP-YOLO。其中大多数仍然是基于锚的探测器,带有手工编制的培训分配规则。这就是出版YOLOX的动机!
18. YOLOX-Darknet53
选择具有Darknet-53骨架的YOLOv3作为基线。然后,对基础模型进行了一系列改进。
从基线到最终的YOLOX模型,训练设置基本相似。所有模型都在MS COCO train2017数据集上进行了300个纪元的训练,批量大小为128。输入大小从448到832均匀绘制,步幅为32。FPS和延迟在单个特斯拉Volta 100 GPU上以FP16精度(半精度)和批量大小=1进行测量。
19. YOLOv3基线
它使用DarkNet-53主干网和一个被称为YOLOv3-SPP的SPP层。与原始实现相比,一些训练策略进行了修改,例如
- 指数移动平均权重更新(Exponential Moving Average weights update)
- 余弦学习速率表(Cosine learning rate schedule)
- BCE分类和目标分支损失(BCE Loss for classification and objectness branch)
- 回归分支的IoU损失(IoU Loss for regression branch)
20. YOLOX
在YOLOX中使用了用于分类和定位的解耦头部。
强大的数据扩充:添加了类似于YOLOv4的马赛克和混合数据增强技术,以提高YOLOX的性能。Mosaic是ultralytics-YOLOv3提出的一种有效的增强策略。
为了开发高速目标探测器,YOLOX采用了无锚机制,减少了设计参数的数量,因为现在不再需要处理锚箱,这大大增加了预测的数量。因此,对于预测头中的每个位置或网格,现在只有一个预测,而不是预测三个不同锚箱的输出。每个对象的中心位置都被视为正采样,并且有一个预定义的缩放范围。
简单地说,在无锚检测中,每个网格的预测从3减少到1,它直接预测四个值,即网格左上角的两个偏移量以及预测框的高度和宽度。
使用这种方法,可以减少检测器的网络参数和GFLOP,并使检测器更快,而不仅仅是性能提高到42.9%AP
21. YOLOv5中改进的CSPNet
为了进行公平比较,YOLOX用YOLOv5改进的CSP v5主干以及SiLU激活和盘头取代了Darknet-53主干。通过利用其缩放规则,可以生成YOLOX-S、YOLOX-M、YOLOX-L和YOLOX-X模型。
所有YOLOX变体都显示出持续的改善∼3.0%至∼1.0%AP,使用去耦压头只增加了少量时间。
22. 微型和纳米探测器
将YOLOX模型与YOLOv5进行了比较,YOLOv5是小型、中型、大型和特大型(更多参数) 。作者进一步缩小了YOLOX模型,使其参数低于YOLOX-S变体,从而生产出YOLOX Tiny和YOLOX Nano。YOLOX Nano是专为移动设备设计的。为了构建该模型,采用了深度方向的卷积,得到了一个只有0.91M参数和1.08G触发器的模型。
YOLOX Tiny与YOLOv4 Tiny和PPYOLO Tiny进行了比较。同样,与同类产品相比,YOLOX的车型尺寸更小,性能也更好。