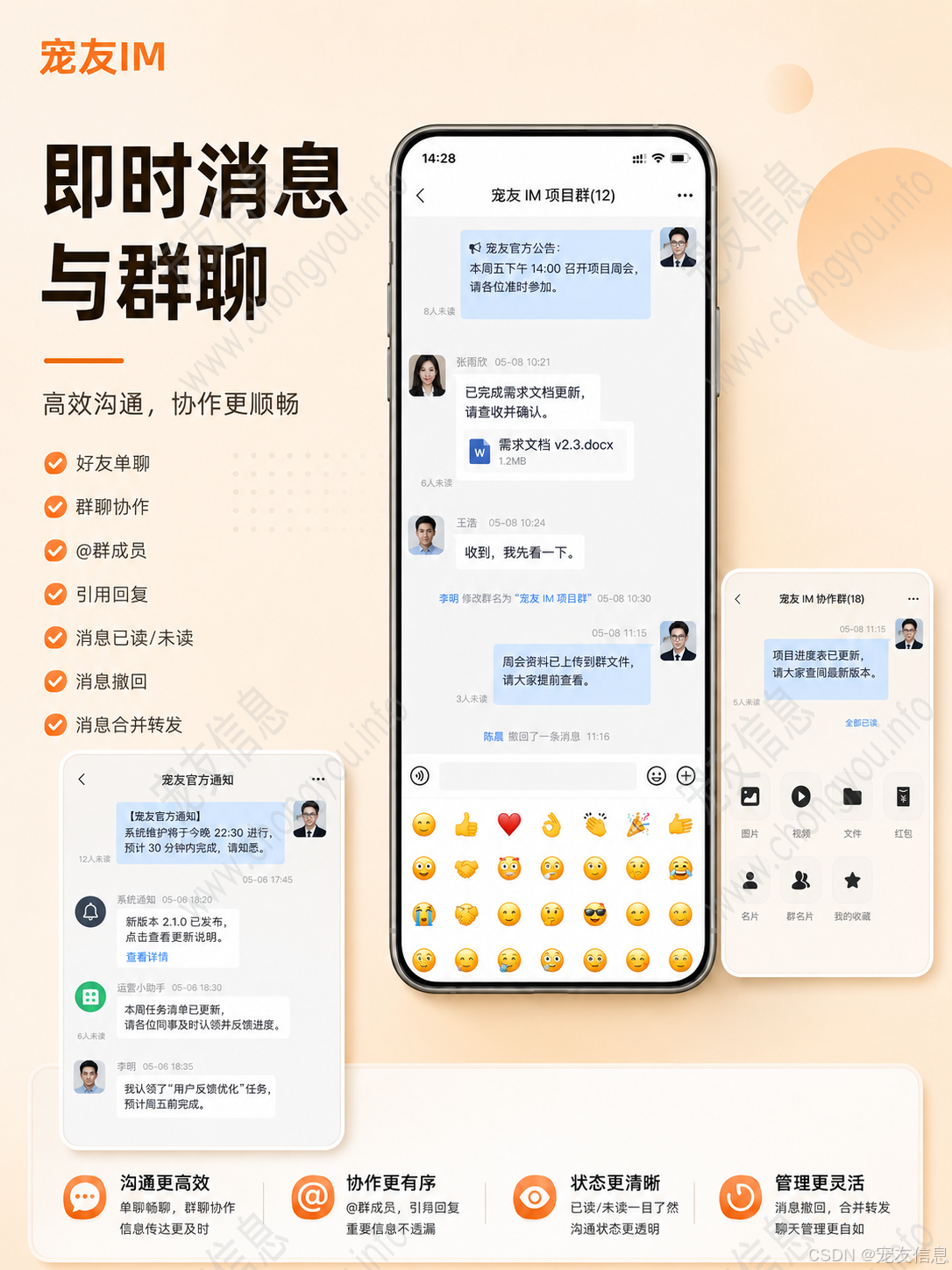
IM 即时通讯的系统技术复杂度并不来自"有多少聊天功能",而来自实时通信链路本身。
用户看到的是一条消息从输入框发出,服务端真正处理的是连接鉴权、协议解析、消息编号、幂等判断、消息落库、在线路由、跨节点转发、ACK 确认、离线同步、多端状态刷新等一整条链路。
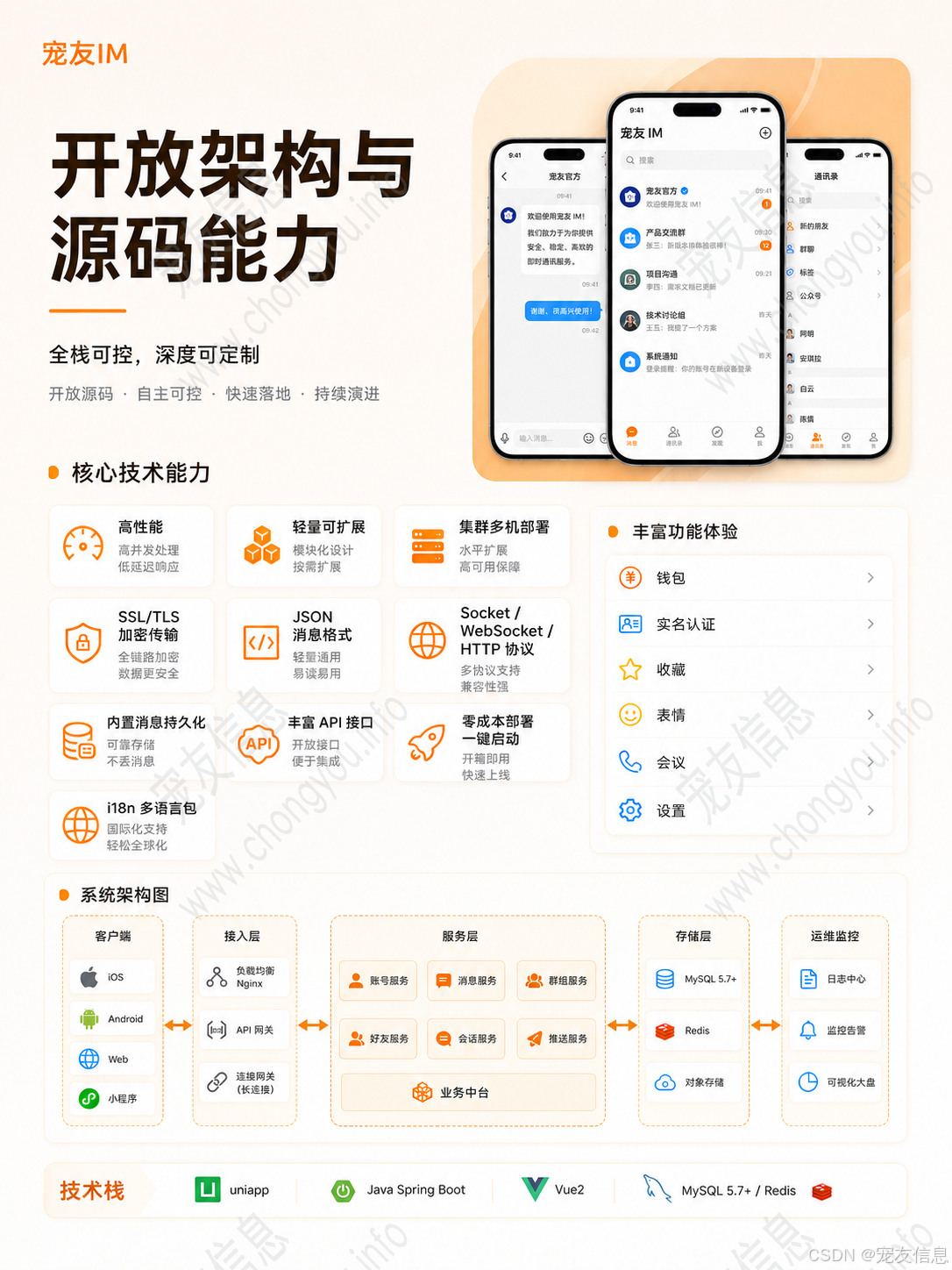
如果系统同时覆盖 Android、iOS、H5、PC,并且后端基于 SpringBoot + WebSocket + Socket + HTTP + Redis + MySQL 5.7+ 设计,那么架构重点就不能只停留在接口层,而要围绕"实时消息如何可靠流转"来建模。
本文从工程实现角度,分析一个 IM 即时通讯系统在消息链路、连接状态、存储索引、Redis 路由、多端一致性和集群部署中的技术设计思路。
从一次连接开始,而不是从一个接口开始
普通业务系统通常是"请求来了,接口处理,返回结果"。IM 系统不同,客户端和服务端之间需要长期保持连接。
一个客户端进入聊天系统后,第一步不是发送消息,而是建立实时通道。
这个通道可能来自 App 的 Socket 自定义协议,也可能来自 H5 或 PC 的 WebSocket。连接建立后,服务端需要完成几件事:
验证 token 是否有效。
识别当前用户 ID。
识别当前设备类型。
绑定当前连接所在节点。
记录连接最后活跃时间。
启动心跳检测。
这一步完成后,服务端才知道"某个用户的某个端,当前连接在哪台 IM 节点上"。
可以把这个过程理解成一张动态路由表:
javascript
userId=10001
android -> im-node-01 / channel-a81
h5 -> im-node-02 / channel-h19
pc -> im-node-03 / channel-p77这个结构比简单的 userId -> channelId 更适合多端在线。否则用户在 PC 登录后,可能覆盖 App 的连接,导致移动端收不到消息或状态不同步。
Redis 在 IM 系统里不是普通缓存
在很多业务系统里,Redis 只是缓存热点数据。但在 IM 系统中,Redis 更像实时状态中心。
它保存的不是"查库结果副本",而是系统当前运行状态,例如谁在线、在哪个节点、哪个会话有多少未读、哪个临时 token 还有效、哪个红包领取流程正在并发处理。
在线路由可以这样保存:
javascript
@Service
public class ImConnectionRegistry {
private final StringRedisTemplate redisTemplate;
public ImConnectionRegistry(StringRedisTemplate redisTemplate) {
this.redisTemplate = redisTemplate;
}
public void online(Long userId, String device, String nodeId, String channelId) {
String key = "im:conn:" + userId;
String value = nodeId + "|" + channelId;
redisTemplate.opsForHash().put(key, device, value);
redisTemplate.opsForHash().put(key, device + ":activeAt", String.valueOf(System.currentTimeMillis()));
redisTemplate.expire(key, Duration.ofMinutes(10));
}
public Map<Object, Object> routes(Long userId) {
return redisTemplate.opsForHash().entries("im:conn:" + userId);
}
public void heartbeat(Long userId) {
redisTemplate.expire("im:conn:" + userId, Duration.ofMinutes(10));
}
}这个结构的关键点不是代码本身,而是数据维度。
它不是只记录用户在线,而是记录用户在哪些设备在线、每个设备在哪个节点、对应哪个连接。
后续消息投递、多端同步、跨节点转发,都依赖这张路由表。
一条消息真正经历了哪些阶段
一条消息从客户端发出后,不应该直接写成"保存并推送"。更稳妥的方式是把它拆成状态流转。
javascript
客户端本地生成 clientMsgId
↓
进入本地发送队列
↓
通过 WebSocket / Socket 发送
↓
服务端解析协议
↓
校验用户与会话状态
↓
判断 clientMsgId 是否重复
↓
生成 serverMsgId 和 msgSeq
↓
写入消息存储
↓
返回 ACK 给发送端
↓
根据在线路由投递到接收端
↓
接收端确认或等待后续同步这里面有三个 ID 很重要。
clientMsgId 用于解决客户端弱网重发。客户端网络不稳定时,同一条消息可能被发送多次,服务端需要根据它做幂等判断。
serverMsgId 是服务端消息唯一 ID。消息撤回、引用回复、收藏、合并转发、历史查询都会用到它。
msgSeq 是会话内递增序号。它用于解决消息排序、分页查询、多端同步和断点续拉问题。
如果只依赖时间戳排序,在并发发送、跨节点投递或客户端本地临时消息存在时,容易出现顺序不稳定。
消息协议不要围绕页面设计
聊天页面上看到的是文本、图片、文件、表情、红包、名片、语音、视频等不同形态,但服务端不应该为每种形态设计一套协议。
更合理的协议是命令 + 消息体 + 扩展字段。
javascript
{
"cmd": "MSG_SEND",
"clientMsgId": "c_10001_202607010001",
"serverMsgId": null,
"conversationId": "c2c_10001_20001",
"fromUserId": 10001,
"targetId": 20001,
"scene": "single",
"bodyType": "text",
"body": {
"text": "这是一条即时消息"
},
"extra": {
"quoteMsgId": null,
"atUserIds": [],
"forwardId": null
},
"sendAt": 1782864000000
}这个结构里,cmd 描述操作,bodyType 描述内容类型,extra 描述消息之间的关系。
例如消息撤回不是一种正文内容,而是一种命令。
已读回执不是聊天气泡,而是状态事件。
音视频邀请也不是普通文本,而是信令消息。
这样设计后,消息类型增加时,协议主结构不需要频繁变化。服务端只需要根据 cmd 和 bodyType 分发到不同处理器。
写入消息表前先确定查询方式
IM 消息表的设计不能只看"要存哪些字段",还要先看"未来怎么查"。
聊天窗口向上翻页,需要按会话查询历史消息。
客户端断线重连,需要按上次同步位置补消息。
引用回复,需要按消息 ID 查原消息摘要。
消息撤回,需要按消息 ID 更新状态。
合并转发,需要按一组消息 ID 查询上下文。
因此,消息存储至少要支持三种查询路径:
javascript
conversationId + msgSeq 用于会话分页
serverMsgId 用于单条消息定位
senderId + clientMsgId 用于发送幂等表结构可以围绕这些路径设计:
javascript
CREATE TABLE im_message_store (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
server_msg_id VARCHAR(64) NOT NULL,
client_msg_id VARCHAR(64) DEFAULT NULL,
conversation_id VARCHAR(64) NOT NULL,
sender_id BIGINT NOT NULL,
msg_seq BIGINT NOT NULL,
scene VARCHAR(20) NOT NULL,
body_type VARCHAR(30) NOT NULL,
body JSON NOT NULL,
msg_status TINYINT DEFAULT 0,
send_at BIGINT NOT NULL,
create_time DATETIME DEFAULT CURRENT_TIMESTAMP,
UNIQUE KEY uk_server_msg_id (server_msg_id),
UNIQUE KEY uk_conversation_seq (conversation_id, msg_seq),
KEY idx_sender_client (sender_id, client_msg_id),
KEY idx_conversation_time (conversation_id, send_at)
);uk_conversation_seq 可以保证同一个会话内消息序号不重复。
idx_sender_client 可以防止客户端重发造成重复消息。
msg_status 用于表达正常、已撤回、已删除、异常等状态。撤回消息时,通常不物理删除,而是更新状态并推送撤回事件。
当消息量变大后,还需要考虑冷热数据拆分。近期消息用于高频查询,历史消息可以进入归档表或独立存储,避免单表持续膨胀影响分页性能。
ACK 不是提示,而是可靠性边界
很多聊天系统的问题都出在 ACK 设计不清楚。
客户端点击发送后,可以先把消息展示在本地,但此时只能算"发送中"。只有服务端完成协议解析、幂等判断、消息编号和落库后,返回 ACK,客户端才能把状态改成"已发送"。
如果服务端没有返回 ACK,客户端需要决定是重试、标记失败,还是等待网络恢复。
这也是 clientMsgId 必须存在的原因。重试时服务端看到相同 clientMsgId,应该返回同一条消息的处理结果,而不是重新生成一条新消息。
ACK 的意义不是"告诉用户发出去了",而是划定客户端状态和服务端状态的分界线。
群聊高并发的核心不是消息内容,而是扩散策略
群聊最容易出性能问题的地方,不是消息表存一条内容,而是这条消息要影响多少用户。
一个群有 500 个成员时,一条消息可能带来:
500 个成员的未读状态变化。
若干在线成员的实时推送。
若干离线成员的后续同步。
被 @ 成员的特殊提醒。
多端在线用户的状态刷新。
如果每发一条群消息都给每个成员复制一份完整消息,写入量会快速放大。
更常见的方式是:
消息正文只存一份。
会话内生成递增 msgSeq。
每个成员维护自己的 lastReadSeq。
未读数可以由读取位置计算,也可以在 Redis 中做高频计数。
在线成员实时推送,离线成员通过同步机制补齐。
这种设计可以把"消息内容存储"和"成员读取状态"拆开,避免群成员数量直接放大消息表写入压力。
已读未读本质是读取位置,不是布尔值
在 IM 系统中,已读未读不能简单设计成 read = true / false。
对于单聊,用户只需要知道对方读到哪里。
对于群聊,每个成员都可能读到不同位置。
因此,已读状态更适合用读取位置表达:
javascript
conversationId = group_90001
userId = 10001
lastReadSeq = 3688
lastReadAt = 1782867600000当会话最大消息序号是 3700,而用户最后已读序号是 3688,就可以计算出未读区间。
这种方式也更适合多端同步。用户在 PC 端打开会话后,服务端更新 lastReadSeq,然后向 Android、iOS、H5 推送已读事件,各端再更新本地未读数。
如果未读数只在客户端本地维护,换设备、断线重连、清理缓存后很容易出现不一致。
多端同步不要伪装成普通消息
Android、iOS、H5、PC 同时在线时,长连接里传输的不只有聊天消息,还有大量状态事件。
例如:
PC 端已读,会影响移动端未读数。
App 端撤回消息,会影响 H5 和 PC 的消息展示。
用户修改资料,会影响会话列表展示。
群信息变更,会影响所有在线成员的群资料缓存。
这些数据不应该都伪装成普通聊天气泡,而应该以事件方式处理。
可以把长连接下发数据分成两类:
javascript
聊天消息:需要进入消息列表
状态事件:只更新本地状态或页面缓存例如 MSG_REVOKE 是状态事件,客户端收到后查找本地对应消息并更新为已撤回。
READ_RECEIPT 也是状态事件,客户端收到后更新未读数或消息已读状态。
GROUP_PROFILE_UPDATE 不进入聊天记录,只刷新群资料缓存。
这样客户端处理逻辑会更清晰,也能减少大量无意义的系统气泡。

文件和音视频都不应该压在消息通道里
实时消息通道适合传输轻量数据,不适合传输大文件和音视频媒体流。
文件发送更合理的方式是先走 HTTP 上传,拿到文件元数据后,再发送一条文件类型消息。消息里保存文件 ID、文件名、大小、类型、下载地址等信息。
语音通话、视频通话、多人音视频会议也类似。IM 负责发送信令,例如邀请、接听、拒绝、挂断、加入会议、离开会议。真正的媒体流应该交给 RTC 通道处理。
这种拆分有两个好处。
第一,长连接不会被大文件或媒体流阻塞。
第二,文件存储、下载鉴权、音视频房间、媒体传输都可以独立扩展,不会和聊天消息强耦合。
跨节点投递要依赖路由,而不是广播
单机部署时,用户连接都在当前进程内,服务端可以直接找到连接并推送。
集群部署后,情况会变成:
javascript
用户 A 连接在 im-node-01
用户 B 连接在 im-node-03
用户 C 连接在 im-node-02用户 A 给用户 B 发消息时,im-node-01 不能盲目广播给所有节点,而应该先查 Redis 路由,确认用户 B 在 im-node-03,然后把消息转发到目标节点。
跨节点转发可以通过内部 RPC、消息队列或 Redis Pub/Sub 实现。无论采用哪种方式,都要保证两点:
同一条消息不会重复投递。
目标节点异常时,消息仍然可以通过历史同步兜底。
这里的关键仍然是 serverMsgId 和幂等处理。只要每条消息有稳定的全局 ID,接收节点就可以判断自己是否已经处理过。
朋友圈、红包、钱包这类数据不要挤进消息主表
IM 系统经常会扩展社交和交易相关能力,但技术上不应该把所有业务都放进消息表。
朋友圈更接近内容流,核心是动态、评论、点赞、可见范围。
红包和钱包更接近资金状态,核心是余额、冻结、领取记录、流水。
聊天消息可以展示一个入口或状态摘要,但数据主状态应该由独立模型维护。
例如红包消息里可以保存红包 ID 和展示摘要,但领取状态、金额变化、退款状态、钱包流水不能依赖聊天消息表。
这样做的原因很简单:消息表主要服务会话查询,高频读写已经足够复杂。如果把内容流、资金流水、评论点赞都塞进去,索引会变得混乱,后续归档和排查也会变困难。
i18n 多语言也要走统一事件和 key
四端系统很容易出现文案不一致的问题。Android、iOS、H5、PC 如果各自维护一套语言 key,后期同一个功能可能出现不同翻译。
更稳定的方式是统一 key 命名。
例如:
javascript
chat.send
chat.revoke
message.unread
group.notice
wallet.balance
file.upload
call.invite
meeting.join前端根据语言环境加载不同语言包。后端发送系统通知时,也可以根据用户语言偏好选择对应文案。
i18n 看起来是前端问题,但在 IM 系统中,系统通知、群事件、钱包提醒、会议邀请都可能由后端生成,所以语言 key 最好从全局统一设计。
排查 IM 问题要顺着链路走
IM 系统出问题时,不能只看某一个接口是否返回成功。
如果用户反馈"消息发出去了,对方没收到",可以按链路排查:
客户端是否生成了 clientMsgId。
服务端是否返回 ACK。
消息是否写入消息表。
接收方 Redis 路由是否存在。
目标连接是否还有效。
跨节点转发是否成功。
接收端是否做了消息去重。
如果用户反馈"未读数不准",可以检查:
会话最大 msgSeq 是否正确。
用户 lastReadSeq 是否更新。
多端已读事件是否下发。
Redis 未读计数是否重复累加。
客户端本地状态是否覆盖服务端状态。
如果用户反馈"群消息顺序错乱",可以检查:
同一会话内 msgSeq 是否连续。
客户端是否按服务端序号排序。
本地临时消息是否正确替换为服务端消息。
跨节点投递是否导致重复推送。
如果用户反馈"PC 有消息,手机没有消息",可以检查:
Redis 是否按设备维度保存路由。
移动端连接是否被后登录设备覆盖。
服务端是否只推送到单端。
移动端断线重连后是否主动补拉消息。
这类排查方式比单纯查看 Controller 日志更有效。IM 系统的稳定性来自连接、协议、消息编号、存储索引、Redis 路由、状态事件和客户端本地队列之间的协作。任何一个环节状态不一致,最终都会表现为延迟、重复、丢失、顺序异常或多端不同步。