在工业智能化转型的浪潮中,将训练好的深度学习模型部署到算力受限的边缘设备上,正成为打通AI落地"最后一公里"的关键。然而,工业现场对推理延迟和系统可靠性的要求极为严苛,传统的云端部署往往因网络延迟而无法满足需求。本文将结合YOLO姿态检测模型的实战经验,深度解析如何通过ONNX与TensorRT的协同,在边缘端实现极致的推理加速。
NVIDIA® TensorRT™ 是由 NVIDIA 开发的一套专为高性能深度学习推理(Inference)打造的高性能优化器、编译器和运行时(Runtime)生态系统。它构建在 NVIDIA CUDA 并行编程模型之上,旨在帮助开发者将训练好的深度学习模型在 NVIDIA GPU 上实现低延迟、高吞吐量的生产级部署。
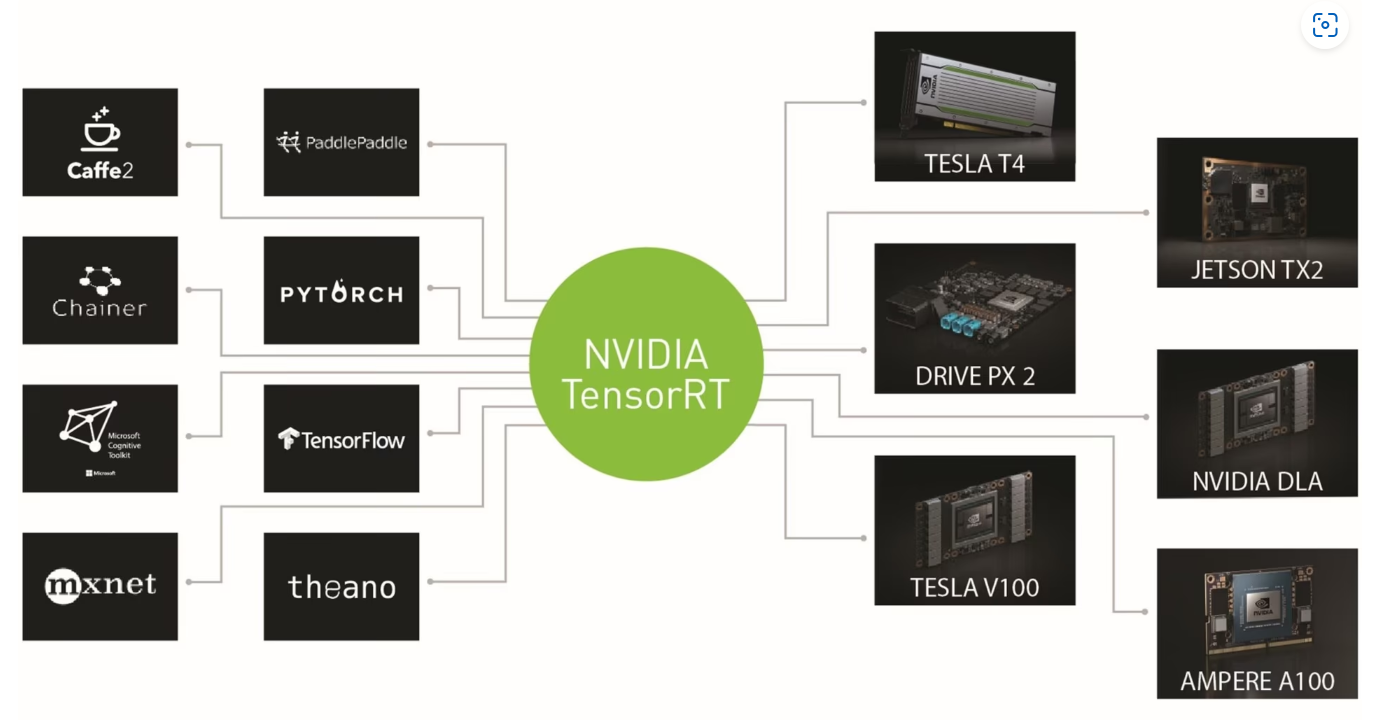
TensorRT环境安装
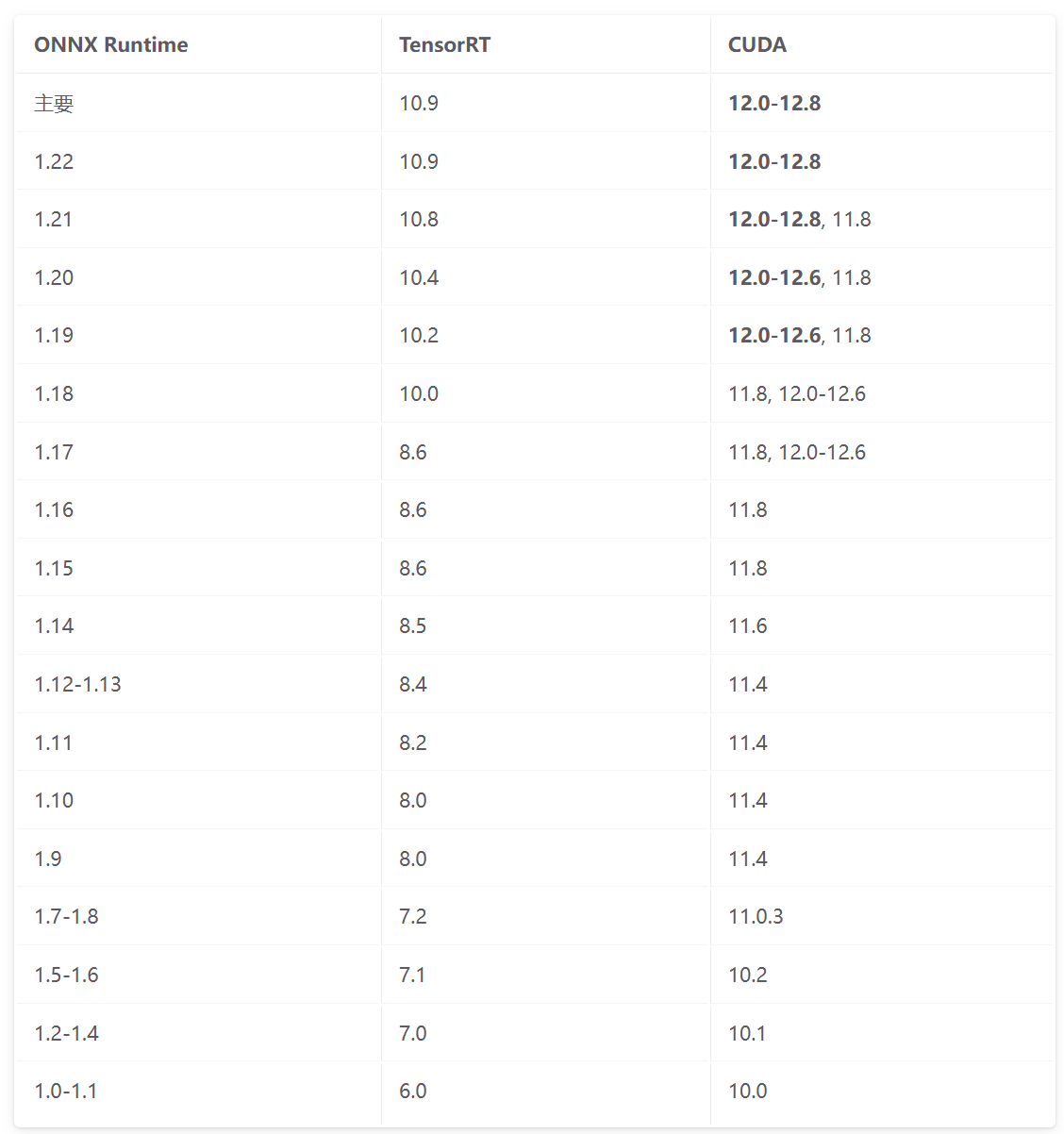
onnxruntime中自带了Tensort推理,可以根据下方的环境对照表去下载
php
https://runtime.onnx.org.cn/docs/execution-providers/TensorRT-ExecutionProvider.html关于CUDA ,OnnxRuntime,TensorRT的对应关系如下:
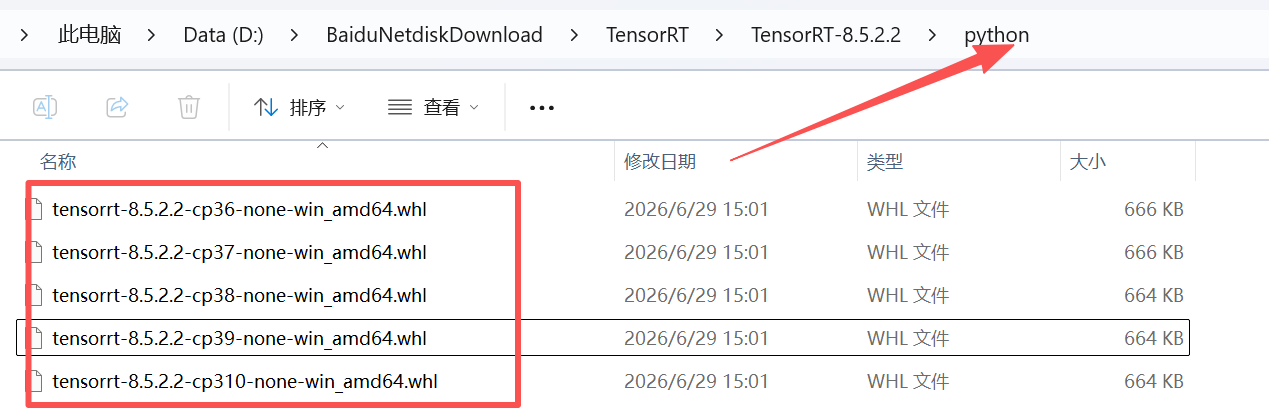
然后,博主在使用 pip 安装时却报错没有该依赖,因此我们需要去NVIDIA官网去下载:
python
https://developer.nvidia.com/nvidia-tensorrt-8x-download
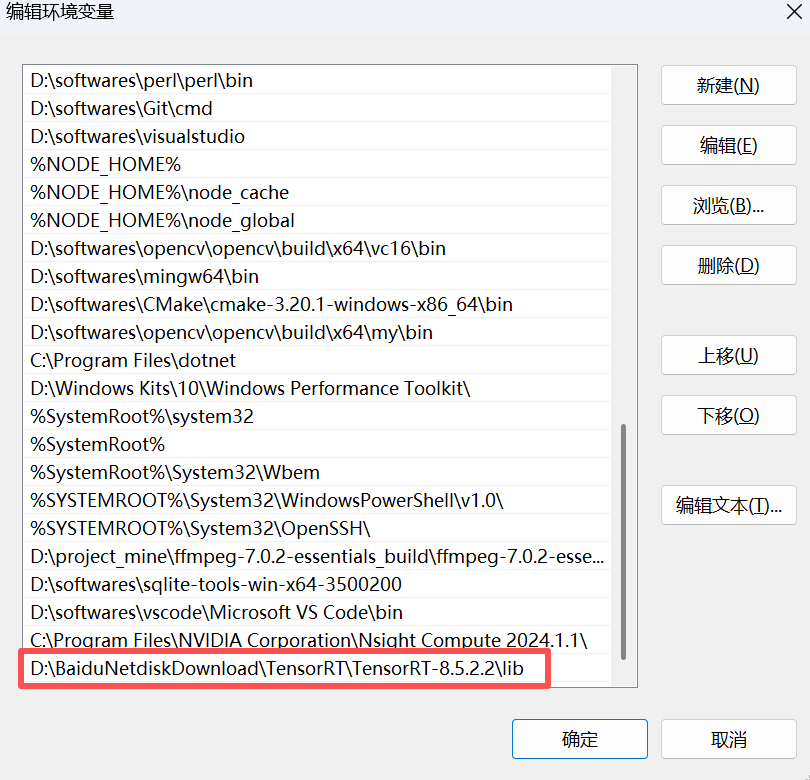
随后,需要配置环境变量,否则将调用不到:
直接pip install tensorrt-8.5.2.2-cp39-none-win amd64.whl即可
模型转换
python
from ultralytics import YOLO
# 加载一个模型,路径为 YOLO 模型的 .pt 文件
model = YOLO(r"yolo11n-pose.pt")
model.export(
format="engine", # 导出为 TensorRT 引擎
imgsz=640, # 固定输入尺寸
half=True, # 开启 FP16 加速
simplify=True, # 简化模型图
dynamic=False, # 【修改】固定尺寸,让 TRT 性能最大化
)或者我们可以使用onnx模型直接转换:
python
import tensorrt as trt
def build_engine(onnx_path, engine_path):
# 1. 初始化 Logger 和 Builder
logger = trt.Logger(trt.Logger.INFO)
builder = trt.Builder(logger)
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
parser = trt.OnnxParser(network, logger)
# 2. 解析 ONNX 模型
with open(onnx_path, "rb") as f:
if not parser.parse(f.read()):
for error in range(parser.num_errors):
print(parser.get_error(error))
return None
# 3. 配置构建参数
config = builder.create_builder_config()
config.max_workspace_size = 1 << 30 # 设置 1GB 工作空间
# 启用 FP16
if builder.platform_has_fast_fp16:
config.set_flag(trt.BuilderFlag.FP16)
# 【关键】配置动态形状(如果你的模型支持动态 Batch 或变长序列)
profile = builder.create_optimization_profile()
profile.set_shape("input", min=(1,3,224,224), opt=(8,3,224,224), max=(32,3,224,224))
config.add_optimization_profile(profile)
# 4. 构建并序列化引擎
serialized_engine = builder.build_serialized_network(network, config)
with open(engine_path, "wb") as f:
f.write(serialized_engine)
print("TensorRT Engine 构建成功!")
if __name__ =="__main__":
build_engine(r"features.onnx", "feature.engine")运行时间会稍微较长,日志如下:
python
D:\softwares\Anconda\envs\yolo\python.exe D:\workspace\ultralytics-main\ultralytics-main\ultralytics\models\yolo\detect\导出.py
WARNING TensorRT requires GPU export, automatically assigning device=0
Ultralytics 8.4.7 Python-3.10.16 torch-2.4.1 CUDA:0 (NVIDIA GeForce RTX 4060 Laptop GPU, 8188MiB)
YOLO11n-pose summary (fused): 109 layers, 2,866,468 parameters, 0 gradients, 7.4 GFLOPs
PyTorch: starting from 'D:\workspace\ultralytics-main\ultralytics-main\ultralytics\models\yolo\pose\yolo11n-pose.pt' with input shape (1, 3, 640, 640) BCHW and output shape(s) (1, 56, 8400) (6.0 MB)
ONNX: starting export with onnx 1.16.1 opset 17...
ONNX: slimming with onnxslim 0.1.71...
ONNX: export success 1.3s, saved as 'D:\workspace\ultralytics-main\ultralytics-main\ultralytics\models\yolo\pose\yolo11n-pose.onnx' (11.3 MB)
TensorRT: starting export with TensorRT 8.5.2.2...
[06/29/2026-15:25:57] [TRT] [I] [MemUsageChange] Init CUDA: CPU +9, GPU +0, now: CPU 15479, GPU 1212 (MiB)
[06/29/2026-15:26:00] [TRT] [I] [MemUsageChange] Init builder kernel library: CPU +90, GPU +116, now: CPU 15701, GPU 1328 (MiB)
[06/29/2026-15:26:00] [TRT] [I] ----------------------------------------------------------------
[06/29/2026-15:26:00] [TRT] [I] Input filename: D:\workspace\ultralytics-main\ultralytics-main\ultralytics\models\yolo\pose\yolo11n-pose.onnx
[06/29/2026-15:26:00] [TRT] [I] ONNX IR version: 0.0.8
[06/29/2026-15:26:00] [TRT] [I] Opset version: 17
[06/29/2026-15:26:00] [TRT] [I] Producer name: pytorch
[06/29/2026-15:26:00] [TRT] [I] Producer version: 2.4.1
[06/29/2026-15:26:00] [TRT] [I] Domain:
[06/29/2026-15:26:00] [TRT] [I] Model version: 0
[06/29/2026-15:26:00] [TRT] [I] Doc string:
[06/29/2026-15:26:00] [TRT] [I] ----------------------------------------------------------------
[06/29/2026-15:26:00] [TRT] [W] onnx2trt_utils.cpp:377: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
TensorRT: input "images" with shape(1, 3, 640, 640) DataType.FLOAT
TensorRT: output "output0" with shape(1, 56, 8400) DataType.FLOAT
TensorRT: building FP16 engine as D:\workspace\ultralytics-main\ultralytics-main\ultralytics\models\yolo\pose\yolo11n-pose.engine
[06/29/2026-15:26:00] [TRT] [I] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU -3, GPU +8, now: CPU 15159, GPU 1336 (MiB)
[06/29/2026-15:26:00] [TRT] [I] [MemUsageChange] Init cuDNN: CPU -12, GPU +10, now: CPU 15147, GPU 1346 (MiB)
[06/29/2026-15:26:00] [TRT] [I] Local timing cache in use. Profiling results in this builder pass will not be stored.
[06/29/2026-15:34:05] [TRT] [I] Total Activation Memory: 8685487616
[06/29/2026-15:34:05] [TRT] [I] Detected 1 inputs and 4 output network tensors.
[06/29/2026-15:34:06] [TRT] [I] Total Host Persistent Memory: 281472
[06/29/2026-15:34:06] [TRT] [I] Total Device Persistent Memory: 696832
[06/29/2026-15:34:06] [TRT] [I] Total Scratch Memory: 4194304
[06/29/2026-15:34:06] [TRT] [I] [MemUsageStats] Peak memory usage of TRT CPU/GPU memory allocators: CPU 7 MiB, GPU 2122 MiB
[06/29/2026-15:34:06] [TRT] [I] [BlockAssignment] Started assigning block shifts. This will take 210 steps to complete.
[06/29/2026-15:34:06] [TRT] [I] [BlockAssignment] Algorithm ShiftNTopDown took 24.7974ms to assign 11 blocks to 210 nodes requiring 17705472 bytes.
[06/29/2026-15:34:06] [TRT] [I] Total Activation Memory: 17705472
[06/29/2026-15:34:07] [TRT] [I] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +8, now: CPU 13577, GPU 1414 (MiB)
[06/29/2026-15:34:07] [TRT] [I] [MemUsageChange] Init cuDNN: CPU +0, GPU +8, now: CPU 13577, GPU 1422 (MiB)
[06/29/2026-15:34:07] [TRT] [W] TensorRT encountered issues when converting weights between types and that could affect accuracy.
[06/29/2026-15:34:07] [TRT] [W] If this is not the desired behavior, please modify the weights or retrain with regularization to adjust the magnitude of the weights.
[06/29/2026-15:34:07] [TRT] [W] Check verbose logs for the list of affected weights.
[06/29/2026-15:34:07] [TRT] [W] - 74 weights are affected by this issue: Detected subnormal FP16 values.
[06/29/2026-15:34:07] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in building engine: CPU +5, GPU +7, now: CPU 5, GPU 7 (MiB)
TensorRT: export success 491.9s, saved as 'D:\workspace\ultralytics-main\ultralytics-main\ultralytics\models\yolo\pose\yolo11n-pose.engine' (9.2 MB)
Export complete (492.7s)
Results saved to D:\workspace\ultralytics-main\ultralytics-main\ultralytics\models\yolo\pose
Predict: yolo predict task=pose model=D:\workspace\ultralytics-main\ultralytics-main\ultralytics\models\yolo\pose\yolo11n-pose.engine imgsz=640 half
Validate: yolo val task=pose model=D:\workspace\ultralytics-main\ultralytics-main\ultralytics\models\yolo\pose\yolo11n-pose.engine imgsz=640 data=/ultralytics/ultralytics/cfg/datasets/coco-pose.yaml half
Visualize: https://netron.app
Process finished with exit code 0模型测试
在使用TensorRT进行推理时,首次会较为耗时,需要进行缓存处理
python
import time
import numpy as np
import onnxruntime as ort
# 1. 加载模型(确保开启了 TensorRT 缓存)
model_path = "pose.onnx"
trt_options = {
'device_id': 0,
'trt_max_workspace_size': int(1.5 * 1024 * 1024 * 1024),
'trt_engine_cache_enable': True,
'trt_engine_cache_path': r'trt_cache',
'trt_fp16_enable': True
}
session = ort.InferenceSession(model_path,
providers=[('TensorrtExecutionProvider', trt_options), 'CUDAExecutionProvider'])
# 2. 构造假数据(模拟真实的输入形状,避免数据加载干扰)
dummy_blob = np.zeros((1, 3, 640, 640), dtype=np.float32)
input_name = session.get_inputs()[0].name
# 3. 【关键】预热阶段(Warm-up)
print("正在进行 Warm-up...")
for _ in range(20):
session.run(None, {input_name: dummy_blob})
# 4. 正式压测(无锁、无打印、纯计算)
print("开始正式计时...")
times = []
for _ in range(100):
start = time.perf_counter()
session.run(None, {input_name: dummy_blob})
times.append(time.perf_counter() - start)
avg_time = sum(times) / len(times) * 1000
print(f"TensorRT 100帧平均纯推理耗时: {avg_time:.2f} ms")针对深度学习模型的推理部署,本研究对 ONNX-CPU、ONNX-GPU、PyTorch-GPU 与 TensorRT 进行了多维度的性能评估与对比。
| 执行提供程序 (Provider) | 纯推理耗时 | 性能表现 |
|---|---|---|
| TensorRT (FP16) | 3.25 ms | 极限性能,完美榨干显卡算力 |
| PyTorch (CUDA) | 10.4 ms | 优秀,原生框架,动态图开销适中 |
| ONNX Runtime (CUDA) | 7.48 ms | 优秀,比原生 PyTorch 略快,图优化生效 |
| CPU (ONNX-CPU) | 23.95 ms | 正常水平,受限于 CPU 算力 |
总结
一、 PyTorch-GPU:训练与调试的"原生基座"
PyTorch-GPU 作为深度学习领域最主流的训练框架,其原生推理能力主要服务于模型验证与早期调试。
- 核心优势:开发体验极佳,与训练代码无缝衔接,模型兼容性100%(不存在算子不支持的问题)。支持动态图特性,调试极其方便,可直接查看中间结果,非常适合处理变长输入和复杂逻辑。
- 性能局限:推理性能在四者中垫底。由于采用动态图"解释执行"机制,每次前向传播都需要重新解析计算图、启动大量小Kernel,并在显存中反复读写中间结果,调度开销极大。
- 适用场景:算法研发、模型训练、快速原型验证及小规模测试。
二、 ONNX-CPU:跨平台与轻量级部署的"通用桥梁"
ONNX 本身是开放神经网络交换格式(中间表示),配合 ONNX Runtime 的 CPU 执行提供者,构成了轻量级部署方案。
- 核心优势:跨平台、跨框架兼容性最好,生态极其丰富。在 CPU 环境下,通过图优化(如常量折叠、层融合)、多线程配置调优(合理设置 intra/inter 线程数)以及 INT8 量化,对于中小型模型(如 MobileNetV2、BERT-Base 等)可实现显著加速,且无 GPU 依赖,部署极其简单。
- 性能局限:受限于 CPU 算力,面对超大规模模型(如 7B 以上大语言模型)时性能瓶颈明显。此外,某些特殊算子可能在导出时不被支持或转换出错,动态轴处理也会带来额外开销。
- 适用场景:边缘设备、无 GPU 的云服务器、对成本敏感的通用推理场景。
三、 ONNX-GPU:兼顾性能与灵活性的"折中之选"
ONNX Runtime 的 GPU 执行提供者(CUDA EP)将 NVIDIA 硬件加速引入 ONNX 生态。
- 核心优势:在保持跨平台可移植性的同时,大幅提升了推理速度。实测数据显示,相比 PyTorch 原生 GPU 推理,ONNX-GPU 通常可获得 3 倍左右的加速。它支持动态形状和复杂控制流,对模型导出的宽容度较高,迁移成本低。
- 性能局限:虽然利用了 GPU,但其底层优化深度不及 TensorRT。性能表现高度依赖于 ONNX 导出的质量以及算子覆盖的保真度。
- 适用场景:云端通用推理、多云/异构硬件环境、需要快速上线且对极致延迟要求不苛刻的业务。
四、 TensorRT:NVIDIA 硬件上的"性能王者"
TensorRT 是 NVIDIA 专为自家 GPU 打造的高性能推理优化器和运行时库,代表了 NVIDIA 生态下的极致性能。
- 核心优势:将"解释执行"转化为"编译执行",深度集成 CUDA 与 cuDNN。通过激进的图优化(层融合、内核自动调优)、内存优化以及 FP16/INT8/FP8 混合精度计算,在 NVIDIA GPU 上实现绝对领先的性能。实测表明,在相同硬件下,TensorRT 的推理延迟通常比 PyTorch 降低 3-10 倍,吞吐量提升可达 6 倍以上。对于大语言模型(TensorRT-LLM),更能实现毫秒级首 Token 延迟。
- 性能局限:生态封闭,仅支持 NVIDIA 硬件。学习曲线陡峭,API 复杂,模型编译时间长;遇到不支持的特殊算子时,需要开发者自行编写插件。
- 适用场景:对延迟极其敏感的实时交互应用(如自动驾驶、Agent 智能体)、高并发高吞吐的数据中心生产环境。
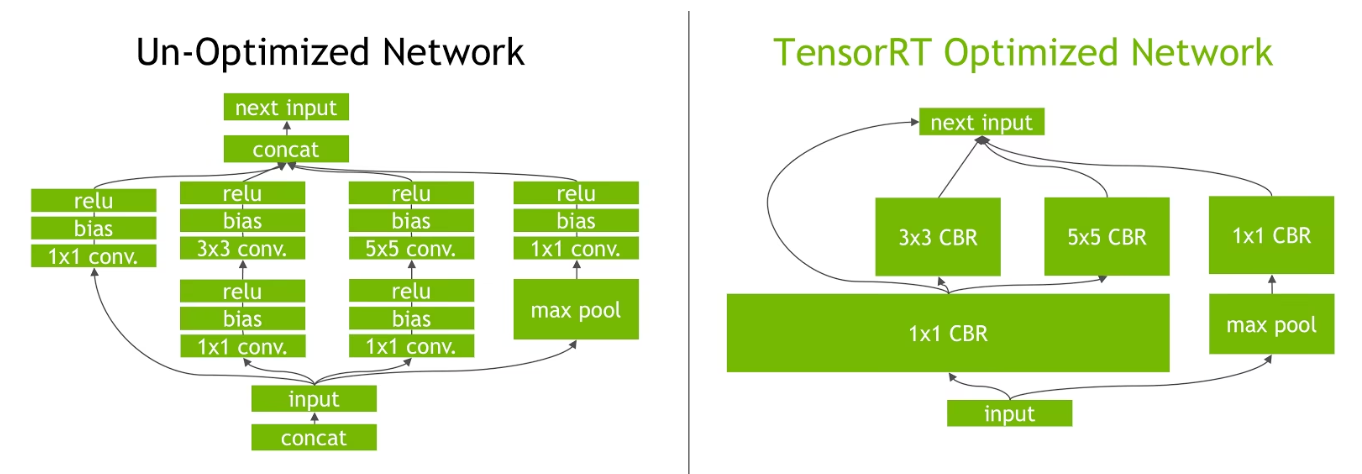
TensorRT的层融合效果如下:
总结与选型建议
这四种方案并非绝对互斥,而是构成了从研发到生产的完整阶梯:
- 研发与调试 :首选 PyTorch-GPU。
- 轻量级/无卡部署 :首选 ONNX-CPU。
- 通用云端部署 :首选 ONNX-GPU(也可作为 TensorRT 的降级备选)。
- 极致性能生产环境 :在拥有 NVIDIA GPU 的前提下,TensorRT 是最终极的加速方案。在实际工程中,也可采用混合策略,将模型中最耗时的核心子图交由 TensorRT 加速,其余部分由 ONNX Runtime 处理,以兼顾性能与灵活性。