写在前面:
本文基于AI智能问答模块,实现回答结果导出为PDF的功能,对比优化前后的实现差异,重点介绍如何在不引入html2canvas、jsPDF、Puppeteer 的前提下,把"边画边分页"的实现升级为"先测量、后分页、再绘制"的前端排版引擎。
一、项目背景介绍
这个功能来自某AI智能助手中的"AI智能问答"模块。用户在面板里可以进行问答、问数等交互,系统会返回一段结构化程度较高的Markdown内容,例如分析结论、分级标题、列表、表格、代码样式字段、引用说明等。
在业务使用中,这类回答不只是临时展示在聊天窗口里,还需要被沉淀成可以流转、归档、汇报和打印的文档。因此,前端需要提供稳定的导出能力,把聊天回答转换成PDF或 Word。这里的重点不是"把屏幕截图保存下来",而是要让导出的文档具备正常报告的阅读体验:标题清楚、段落换行自然、表格不乱、代码块不被切断、分页位置可控。
最初的PDF导出已经完成了从Markdown到Canvas再到PDF的闭环,但随着回答内容越来越复杂,旧方案暴露出了一些排版问题,例如标题落在页尾、表格被拆开、代码块分页不稳定等。因此这次优化的目标很明确:不换技术栈,不引入额外截图或服务端打印方案,而是在当前前端Canvas导出架构内,把排版引擎做得更可靠。
二、技术方案介绍
1、Markdown:AI 回答的结构化文本格式
Markdown是一种轻量级标记语言。AI返回的回答通常天然适合用Markdown表达,比如用 # 表示标题,用 - 表示列表,用反引号表示行内代码或代码块,用管道符表示表格。它的优势是文本可读、结构清晰,也方便前端继续转换成HTML、AST、Word或PDF。
示例:
# 研判结论
- 起火点位于建筑二层
- 建议优先组织人员疏散
| 指标 | 内容 |
| --- | --- |
| 风险等级 | 高 |
| 处置建议 | 内攻搜救 + 外部控火 |2、AST:Markdown的语法树
AST是 Abstract Syntax Tree 的缩写,中文通常叫"抽象语法树"。如果说Markdown原文是一串字符,那么AST就是解析器理解这串字符后得到的结构化结果。
例如一段 Markdown 标题,在原文里只是 # 标题,但解析成AST后,它会变成类似"这是一个一级标题,标题内容是某段文本"的结构。相比直接处理字符串,AST更适合做严肃的文档生成,因为它已经把"这是什么内容"表达清楚了。

示例:
const tokens = md.parse(markdown, {})
// tokens 中会包含 heading_open、inline、heading_close、paragraph_open、table_open 等结构
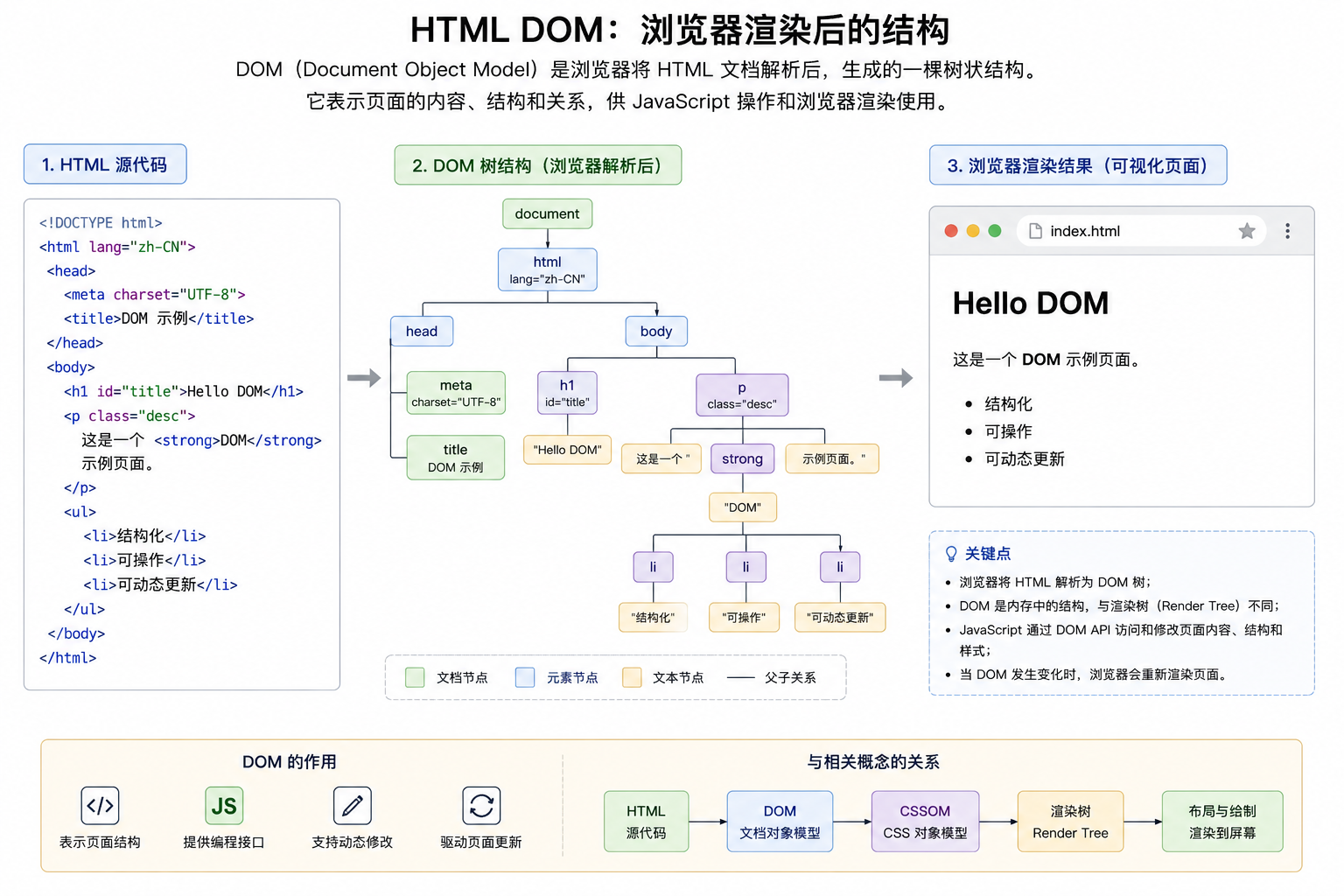
// 核心就是从这些token出发,不再依 HTML DOM。3、 HTML DOM:浏览器渲染后的结构
旧的优化方案仍然保留了Markdown 渲染流程:先把Markdown转成HTML,再让浏览器生成DOM 结构,然后遍历DOM节点判断标题、段落、列表和表格。这个方案直观,和页面展示逻辑接近,但DOM本身不等于文档排版模型,因此还需要额外的布局层来决定分页。
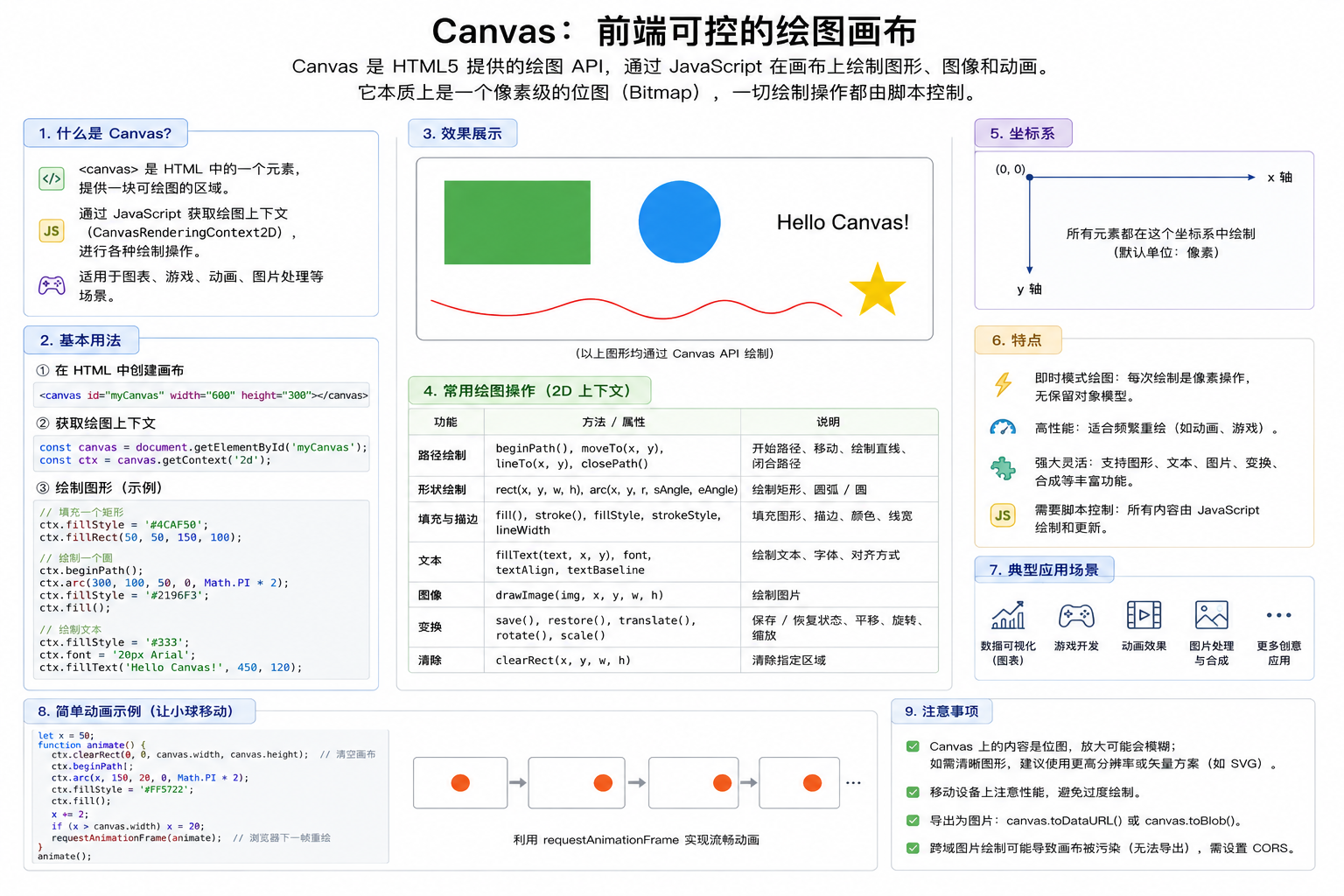
4、Canvas:前端可控的绘图画布
Canvas 是浏览器提供的一块可编程画布。我们可以在上面绘制文字、线条、矩形、图片和表格。PDF 导出里使用 Canvas 的好处是控制力强:文字画在哪里、表格边框怎么画、代码块背景多高、什么时候换页,都可以由前端逻辑决定。
示例:
ctx.fillStyle = '#111827'
ctx.font = '13px Microsoft YaHei'
ctx.fillText('这是一行绘制到 Canvas 上的文字', 64, 120)但 Canvas 也有一个明显特点:它只负责"画",不会自动帮我们理解段落、标题、表格和分页。因此,如果直接边遍历边绘制,就很容易出现分页不可控的问题。优化后的关键,就是在 Canvas 绘制之前先完成 Measure 和 Pagination。
5、PDF Blob:浏览器里的可下载PDF 文件
当前项目的最后一步,是把每一页 Canvas 转成图片数据,再手动组装成PDF Blob。Blob可以理解为浏览器中的二进制文件对象,生成后通过临时URL触发下载。

示例:
const blob = buildImagePdf(pageImages)
const url = URL.createObjectURL(blob)
const anchor = document.createElement('a')
anchor.href = url
anchor.download = '智能辅助决策回答.pdf'
anchor.click()因此,整套技术方案的本质是:Markdown提供内容结构,HTML或AST提供可解析的中间表示,Layout Engine负责测量和分页,Canvas负责绘制页面,PDF Blob负责生成最终可下载文件。
三、初始方案:Markdown→HTML→ DOM→Canvas→PDF
最初的PDF导出方案采用的是一条非常直观的前端链路:先把AI返回的Markdown渲染成HTML,再创建一个临时DOM容器,遍历DOM节点并绘制到Canvas,最后把多页Canvas图片组装成PDF Blob下载。
1、整体流程
初始方案的流程可以概括为:Markdown负责表达内容结构,HTML DOM负责承载渲染后的节点结构,Canvas负责绘制页面,PDF Blob负责输出文件。

const drawRenderedMarkdown = (markdown: string) => {
const container = document.createElement('div')
container.innerHTML = md.render(markdown || '暂无回答内容')
Array.from(container.children).forEach(drawHtmlBlock)
}核心绘制逻辑集中在 drawHtmlBlock 中。它根据 DOM 标签判断当前内容类型,例如 h1、p、ul、pre、table,然后调用不同的绘制函数。
const drawHtmlBlock = (element: Element) => {
const tag = element.tagName.toLowerCase()
if (tag === 'h1' || tag === 'h2') {
drawInlineSegments(collectInlineSegments(element), headingStyle)
return
}
if (tag === 'p') {
drawInlineSegments(collectInlineSegments(element), paragraphStyle)
return
}
if (tag === 'pre') {
drawCodeBlock(element.textContent || '')
return
}
if (tag === 'table') {
drawHtmlTable(element as HTMLTableElement)
return
}
}2、Canvas为什么生成 PDF
Canvas本身并不是PDF,但它可以作为PDF页面图像的来源。项目中每一页PDF先绘制成一张 Canvas,然后通过**canvas.toDataURL('image/jpeg')**转成图片数据,再写入PDF文件结构中。
const commitPage = () => {
pageImages.push({
dataUrl: canvas.toDataURL('image/jpeg', 0.94),
width: canvas.width,
height: canvas.height,
})
}
const blob = buildImagePdf(pageImages)这种方式的好处是可控:页面尺寸、字体、颜色、表格边框、代码块背景都由前端绘制逻辑决定。它不依赖浏览器打印,也不需要后端服务生成PDF,适合当前AI智能助手这种"前端本地导出"的场景。
3、存在的问题
初始方案的问题不在于链路不通,而在于分页不可预测。旧实现中Canvas一边绘制,一边通过ensureSpace 判断是否换页。
const ensureSpace = (height: number) => {
if (y + height <= pageHeight - margin) return
commitPage()
createPage()
}这种方式适合短文本,但面对复杂Markdown内容时会出现明显问题:
| 问题 | 具体表现 | 原因 |
|---|---|---|
| 标题孤立 | 标题可能单独出现在页尾,正文被挤到下一页。 | 标题和紧随正文没有作为一个整体排版。 |
| 代码块被拆 | 代码块逐行绘制,容易在页面底部被切开。 | 绘制前不知道整个代码块总高度。 |
| 表格分页不稳 | 表格行可能被拆到两页,阅读体验差。 | 缺少表格整体高度计算。 |
| Canvas 职责过重 | 绘制函数既要画内容,又要决定分页。 | 没有独立的布局阶段。 |
四、保持HTML架构下的排版优化
优化后的当前方案没有推翻原来的Markdown → HTML → DOM → Canvas → PDF架构,而是在 DOM 和 Canvas 之间增加了一层Layout Engine。也就是说,HTML DOM仍然作为内容解析入口,但Canvas不再直接负责分页判断。
1、引入Layout Engine
Layout Engine的核心是把DOM节点转换成统一的 LayoutNode。每个块级元素都先变成一个可测量、可分页、可绘制的布局节点。
type LayoutNode = {
type: string
height: number
marginTop: number
marginBottom: number
padding: PdfPadding
keepTogether: boolean
children: LayoutNode[]
segments?: PdfInlineSegment[]
style?: AiDecisionPdfStyle
lines?: PdfTextLine[]
level?: number
rawRows?: PdfTableCell[][]
tableRows?: PdfTableRowLayout[]
image?: HTMLImageElement
}这样,DOM 遍历阶段只负责识别结构,不再立即绘制。标题、段落、表格、引用、列表、代码块都会先进入 LayoutNode Tree。
const buildMarkdownLayout = async (markdown: string) => {
const container = document.createElement('div')
container.innerHTML = md.render(markdown || '暂无回答内容')
const nodes: LayoutNode[] = []
for (const child of Array.from(container.children)) {
nodes.push(...await elementToLayoutNodes(child))
}
return nodes
}2、Measure:先测量后绘制
优化后的关键原则是:每个块级元素必须先计算真实渲染高度,再决定是否分页,最后才绘制。
const measureTextNode = (node: LayoutNode, width = contentWidth) => {
const style = node.style || { fontSize: 13, lineHeight: 22 }
const availableWidth = width - node.padding.left - node.padding.right
node.lines = layoutInlineSegments(
node.segments || [{ text: node.text || '' }],
style,
availableWidth,
)
node.height =
node.padding.top
+ node.lines.length * aiDecisionPdfLineHeight(style)
+ node.padding.bottom
}表格、图片和代码块也走同样思路:先测量整体高度,再参与分页。
const measureTable = (node: LayoutNode) => {
const rows = node.rawRows || []
const columnCount = Math.max(...rows.map((row) => row.length), 1)
const cellWidth = contentWidth / columnCount
node.tableRows = rows.map((row) => {
const cells = row.map((cell) => ({
...cell,
lines: wrapPdfText(ctx, cell.text, cellWidth - 16, cellStyle),
}))
return {
cells,
height: calculateRowHeight(cells),
}
})
node.height = node.tableRows.reduce((sum, row) => sum + row.height, 0)
}3、Pagination:智能分页
分页逻辑从"绘制过程中检查"改成了"绘制前根据块高度计算"。新的判断条件是:
if (currentY + blockHeight > pageBottom) {
pages.push(page)
page = []
currentY = pageTop
}这比旧方案的if (currentY > pageBottom) 更可靠,因为它判断的是"当前块完整放下以后是否会超页"。如果会超页,就先换页,再绘制。
const paginateBlocks = (nodes: LayoutNode[]) => {
const pages: LayoutNode[][] = []
let page: LayoutNode[] = []
let currentY = pageTop
nodes.forEach((node) => {
const blockHeight = outerHeight(node)
if (page.length && currentY + blockHeight > pageBottom) {
pages.push(page)
page = []
currentY = pageTop
}
page.push(node)
currentY += blockHeight
})
if (page.length) pages.push(page)
return pages
}4、Keep Together:块级元素整体分页
对于图片、表格、引用块、代码块、列表等内容,优化方案默认不拆开。如果当前页剩余空间不足,就把整个块移动到下一页。
一级标题和二级标题还会和紧随其后的正文组成一个group,避免标题单独落在页尾。
const applyHeadingKeepTogether = (nodes: LayoutNode[]) => {
const grouped: LayoutNode[] = []
for (let index = 0; index < nodes.length; index += 1) {
const current = nodes[index]
const next = nodes[index + 1]
if (
current?.type === 'heading'
&& (current.level === 1 || current.level === 2)
&& next
&& !['heading', 'divider'].includes(next.type)
) {
grouped.push(createNode({
type: 'group',
children: [current, next],
keepTogether: true,
}))
index += 1
} else if (current) {
grouped.push(current)
}
}
return grouped
}5、优化效果对比
| 维度 | 初始方案 | 当前优化方案 |
|---|---|---|
| 分页时机 | 绘制过程中临时判断。 | 绘制前完成块级分页。 |
| Canvas 职责 | 同时负责绘制和分页。 | 只负责绘制,不决定分页。 |
| 标题处理 | 可能孤立在页尾。 | 一级/二级标题和正文 Keep Together。 |
| 表格处理 | 逐行绘制,整体不可控。 | 先测量所有行高,再整体分页。 |
| 代码块处理 | 可能跨页断开。 | 整体测量,默认不拆页。 |
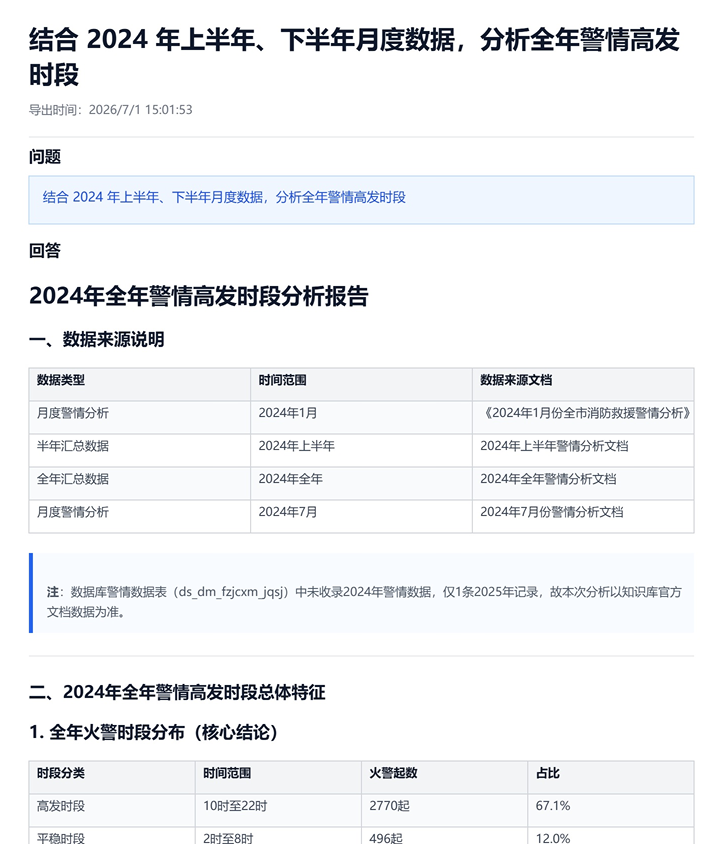
优化前:

优化后:
五、下一步优化:Markdown AST 渲染方案
在当前 HTML + Layout 方案稳定之后,下一步可以考虑进一步减少中间层:从 Markdown 直接进入 AST,再从 AST 构建布局块,最后绘制到 Canvas。
1、AST是什么
AST 是 Abstract Syntax Tree 的缩写,中文叫抽象语法树。在 Markdown 场景中,它表示 Markdown 被解析后的语法结构。比如 # 标题 不再只是一行字符串,而是一个 heading token;代码块、列表、表格也都会变成对应的结构化 token。
2、为什么引入AST
HTML 方案需要先把 Markdown 变成 HTML,再从 DOM 标签中反推出文档结构。AST 方案则直接读取 Markdown 的语义结构,路径更短,也更适合做文档生成。
例如标题在 DOM 方案里是 h1 标签,在 AST 方案里是 heading_open token。两者都能表达标题,但 AST 更接近 Markdown 原始语义。
3、AST + Layout + Canvas架构
AST 方案不是替代 Canvas,也不是替代 PDF Blob。它替代的是 Markdown → HTML → DOM 这段中间解析路径。

const astBlocks = markdownAstToBlocks(answer)
for (const block of astBlocks) {
await measureAstBlock(block)
}
const pages = paginateAstBlocks(astBlocks)
pages.forEach((page) => {
createPage()
let currentY = pageTop
page.forEach((block) => {
drawAstBlock(block, currentY)
currentY += outerHeight(block)
})
commitPage()
})4、与HTML方案对比
| 维度 | HTML + Layout 方案 | AST + Layout 方案 |
|---|---|---|
| 输入结构 | Markdown 渲染后的 DOM。 | Markdown 解析后的 token AST。 |
| 语义来源 | 依赖 HTML 标签。 | 依赖 Markdown token。 |
| 兼容性 | 更适合兼容 HTML 内容。 | 更适合纯 Markdown 文档生成。 |
| 维护重点 | DOM 标签到 LayoutNode 的映射。 | Markdown token 到 LayoutBlock 的映射。 |
六、三种方案对比
从演进角度看,这个导出功能可以拆成三种方案:初始 HTML → Canvas、改进一 HTML + Layout → Canvas、改进二 AST → Canvas。
1、HTML → Canvas
这是最初的方案,优点是实现直接、理解成本低。Markdown 渲染成 HTML 后,前端按 DOM 标签逐个绘制即可。
它适合内容较短、结构较简单的回答。但当内容变成长文档,包含表格、代码块、引用和多级标题时,就容易出现分页不可控的问题。
2、HTML + Layout → Canvas(改进方案一)
当前方案保留 HTML DOM 作为入口,但在 Canvas 前增加 Layout Engine。它的核心价值是稳定:先测量、再分页、后绘制。
这是目前最适合作为主线的方案,因为它既能兼容现有 Markdown 渲染结果,又解决了分页和块级元素整体性问题。
3、AST → Canvas(改进方案二)
AST 方案更适合后续演进。它直接从 Markdown 语义结构出发,减少 HTML DOM 中间层,更像一个真正的文档生成器。
不过 AST 方案需要覆盖更多 Markdown token 类型,也要额外考虑混入 HTML 的情况。因此它适合作为未来优化方向,而不是立刻完全替换当前 HTML + Layout 方案。
| 方案 | 核心链路 | 优点 | 不足 |
|---|---|---|---|
| 初始方案 | Markdown → HTML → DOM → Canvas → PDF | 实现简单,能快速完成导出。 | 分页和复杂块处理不稳定。 |
| 当前方案 | Markdown → HTML → DOM → Layout → Canvas → PDF | 分页可控,表格、代码块、标题处理更稳。 | 仍然依赖 DOM 作为中间结构。 |
| 未来方案 | Markdown → AST → Layout → Canvas → PDF | 语义直接,更适合文档生成。 | 需要补齐更多 token 兼容逻辑。 |
欢迎交流!!🌹🌹