🎯 集合框架源码通关总结(2026云版)
摘要 : 第45~50篇集合专题正式收官!一张学习路线图 + 六张速查表 + 14道高频面试题 + 11条云原生避坑清单,系统覆盖 ArrayList 1.5倍扩容、LinkedList 内存开销、HashMap 红黑树树化条件、JDK7死循环、ConcurrentHashMap 桶级锁与协助扩容、BlockingQueue 双锁设计。新增 JDK 8+ 原子方法(compute/merge)、容器化环境无界队列 OOM 防护、LongAdder 伪共享规避等 2026 实战加分项。从"调用API"到"吃透源码",从"八股文"到"K8s 线上坑",一篇打通集合全链路。
📌 系列导航 :《Java 100 天进阶之路》完整总目录
文章目录
-
- [🎯 集合框架源码通关总结(2026云版)](#🎯 集合框架源码通关总结(2026云版))
- [📌 本阶段完整学习路线图](#📌 本阶段完整学习路线图)
- [📚 分篇核心知识点速查表](#📚 分篇核心知识点速查表)
-
- [第45篇:ArrayList 源码解析](#第45篇:ArrayList 源码解析)
- [第46篇:LinkedList 源码与对比](#第46篇:LinkedList 源码与对比)
- [第47篇:HashMap 源码全解(上)](#第47篇:HashMap 源码全解(上))
- [第48篇:HashMap 源码全解(下)](#第48篇:HashMap 源码全解(下))
- [第49篇:ConcurrentHashMap 原理](#第49篇:ConcurrentHashMap 原理)
- 第50篇:阻塞队列与并发容器
- [🔥 分模块高频面试真题](#🔥 分模块高频面试真题)
-
- [List 模块(4道核心题)](#List 模块(4道核心题))
- [Map 模块(10道核心题)](#Map 模块(10道核心题))
- 并发容器模块(4道核心生产向考题)
- [🧨 2026云原生实战避坑清单](#🧨 2026云原生实战避坑清单)
- [🚀 下一阶段预告:第51~60篇 JUC并发编程全套详解](#🚀 下一阶段预告:第51~60篇 JUC并发编程全套详解)
- [🎁 配套资料福利](#🎁 配套资料福利)
- [📌 阅读行动指南](#📌 阅读行动指南)
很多开发能背集合基础API,面试深挖扩容、红黑树、并发锁就卡顿;线上开发队列、HashMap频繁踩并发脏数据、容器OOM等生产大坑。
本文是集合专题收官增强手册,结合2026云原生K8s实战视角 ,包含JDK 8+新特性、容器环境专属避坑点,一张学习路线图+六张速查表+高频面试汇总+生产避坑清单,覆盖Java集合90%面试考点,既是面试突击背诵材料,也是线上开发规范手册。
本系列第45~50篇完整完结,从基础List到并发容器层层递进,看完实现从"只会调用API"到"吃透底层源码、规避线上风险"的跨越,建议一键收藏长期复习。
📌 本阶段完整学习路线图
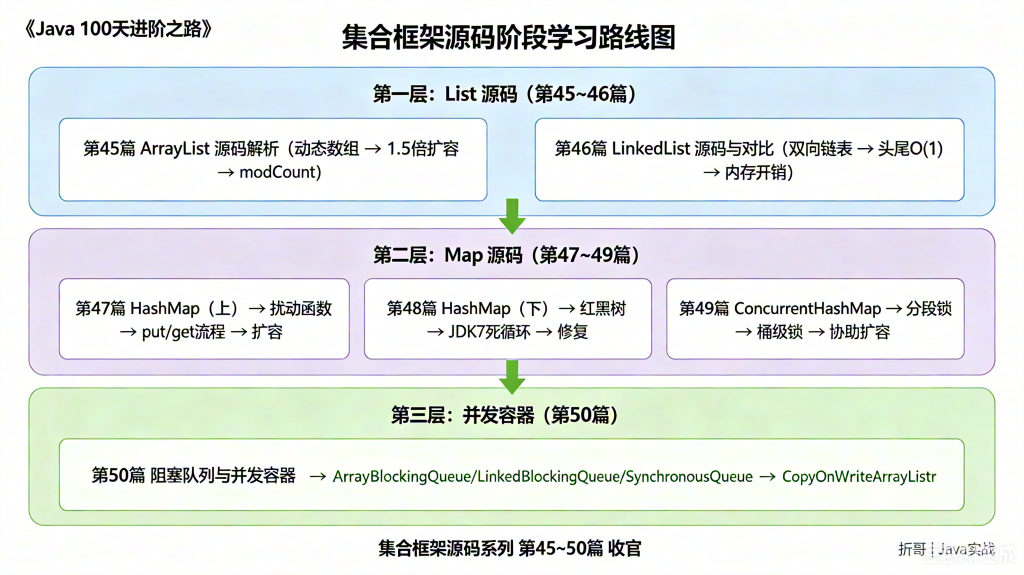
📚 分篇核心知识点速查表
第45篇:ArrayList 源码解析
📖 查看完整文章
| 核心概念 | 一句话总结 | 高频面试提问 |
|---|---|---|
| 底层结构 | 基于 Object[] 动态数组 |
ArrayList 底层存储结构? |
| 懒初始化 | JDK 8+ 无参构造为空数组,首次 add 扩容至 10 | 默认初始容量多少? |
| 1.5倍扩容 | oldCapacity + (oldCapacity >> 1) |
扩容倍数为何选 1.5 倍? |
| modCount | 记录结构性修改,实现 fail-fast | foreach 循环删除元素抛异常原因? |
| transient 序列化 | elementData 被 transient 修饰,自定义序列化逻辑 |
数组字段为什么加 transient? |
| 中间插入逻辑 | System.arraycopy 批量移位,时间复杂度 O(n) |
随机位置插入性能差的根源? |
| RandomAccess 标记接口 | 区分可快速随机访问集合 | LinkedList 禁止普通 for 循环遍历原因 |
第46篇:LinkedList 源码与对比
📖 查看完整文章
| 核心概念 | 一句话总结 | 高频面试提问 |
|---|---|---|
| 底层结构 | 双向链表 Node 节点存储 | LinkedList 底层实现? |
| 首尾操作 | linkFirst/linkLast 仅修改指针,O(1)效率 |
哪些场景适合用 LinkedList? |
| 中间插入 | 先 node(index) 定位节点 O(n),整体插入 O(n) |
LinkedList 插入一定 O(1)? |
| 内存开销 | 单个节点含对象头+前后指针,占用 24~32 字节 | ArrayList 与 LinkedList 内存差异? |
| ArrayDeque 优先方案 | 队列、栈场景优先选用 ArrayDeque | 不推荐 LinkedList 做队列的原因? |
| 遍历短板 | 无连续内存,CPU 缓存局部性差,GC 压力更高 | 高并发高性能遍历推荐集合? |
第47篇:HashMap 源码全解(上)
📖 查看完整文章
| 核心概念 | 一句话总结 | 高频面试提问 |
|---|---|---|
| 底层结构 | JDK 8+ 数组+链表+红黑树 | HashMap 完整数据结构? |
| 扰动函数 | h ^ (h >>> 16),高位哈希参与低位运算,降低碰撞概率 |
为什么设计扰动函数? |
| 索引计算 | (n - 1) & hash,位运算替代取模,运算效率更高 |
容量必须是 2 的整数次幂原因? |
| put 完整流程 | 哈希计算→桶定位→新增/覆盖→判断树化与扩容 | 简述 HashMap put 执行流程 |
| 两倍扩容机制 | 扩容后通过 (e.hash & oldCap) 区分高低位链表 |
resize 扩容如何优化数据迁移? |
| 负载因子 0.75 | 平衡存储空间与查询耗时 | 负载因子固定 0.75 的设计考量? |
| computeIfAbsent 原子方法 | 简化 Map 缓存初始化逻辑 | 如何安全实现 Map 缓存自动创建? |
第48篇:HashMap 源码全解(下)
📖 查看完整文章
| 核心概念 | 一句话总结 | 高频面试提问 |
|---|---|---|
| 树化双条件 | 链表长度 ≥ 8 且数组容量 ≥ 64 才转红黑树 | 链表长度到 8 一定会树化吗? |
| 退链阈值 6 | 节点少于 6 恢复链表,平衡树维护开销 | 退链表阈值设为 6 而非 7 的原因? |
| JDK 7 并发死循环 | 头插法扩容+多线程并发产生环形链表 | JDK 7 HashMap 并发死循环成因? |
| JDK 8 修复方案 | 尾插法迁移,高低位链表拆分规避环链 | JDK 8 如何解决并发扩容死循环? |
| 哈希冲突极端场景 | 所有 key 哈希值一致,集合退化为链表 O(n) | 业务中如何规避大量哈希碰撞? |
| 红黑树平衡机制 | 插入删除执行左旋、右旋、变色维持平衡 | 红黑树查询效率稳定 O(log n) 原理? |
第49篇:ConcurrentHashMap 原理
📖 查看完整文章
| 核心概念 | 一句话总结 | 高频面试提问 |
|---|---|---|
| JDK 7 分段锁 | Segment 数组,默认并发度 16,分段加锁 | JDK 7 CHM 锁设计思路? |
| JDK 8 桶级锁 | CAS + 桶头 synchronized,取消分段锁 | 新版本废弃 Segment 分段锁原因? |
| 多线程协助扩容 | ForwardingNode 标记,多线程分担迁移任务 | 扩容过程其他线程可正常读写? |
| 分段计数 | baseCount + CounterCell,仿 LongAdder 分散计数 |
size() 获取总数为何存在误差? |
| 弱一致性迭代器 | 迭代器不抛快速失败,无法实时感知最新数据 | CHM 迭代器是 fail-fast 还是 fail-safe? |
| 禁止 null 键值 | 无法区分 key 不存在与 value=null 两种场景 | ConcurrentHashMap 不允许 null 的原因? |
| merge/compute 原子复合操作 | 保证查询、修改、写入整套逻辑原子性 | 高并发计数器如何基于 CHM 实现? |
👉 阅读完整:第49篇 ConcurrentHashMap原理
第50篇:阻塞队列与并发容器
📖 查看完整文章
| 核心概念 | 一句话总结 | 高频面试提问 |
|---|---|---|
| BlockingQueue 特性 | 队列满 put 阻塞、队列空 take 阻塞 |
阻塞队列核心适用场景? |
| ArrayBlockingQueue | 数组存储,单锁双条件,必须指定容量 | 与 LinkedBlockingQueue 核心差异? |
| LinkedBlockingQueue | 链表存储,读写分离双锁,默认无界 | 无界队列线上会引发什么问题? |
| SynchronousQueue | 零容量,生产者消费者手递手,线程池默认队列 | SynchronousQueue 业务价值? |
| CopyOnWriteArrayList | 写时复制数组,读无锁、写加锁拷贝 | 适合读多写少场景的底层逻辑? |
| ConcurrentLinkedQueue | 纯 CAS 无锁非阻塞队列 | 和阻塞队列本质使用区别? |
| TransferQueue 拓展 | transfer 方法生产者阻塞等待消费者接收 |
除 SynchronousQueue 外的递达队列? |
🔥 分模块高频面试真题
List 模块(4道核心题)
1. ArrayList 与 LinkedList 核心差异
存储:连续数组 vs 离散双向链表;查询:O(1)随机访问 vs O(n)遍历定位;缓存:数组具备缓存行局部性,链表内存分散;内存开销:数组无额外对象开销,链表每个节点存储前后指针。
2. ArrayList 初始容量与扩容规则
JDK 8 懒加载空数组,首次 add 扩容至 10,后续按 1.5 倍容量持续扩容;批量插入建议提前指定预估容量减少拷贝。
3. LinkedList 中间插入效率误区
插入指针操作是 O(1),但定位指定下标节点需要遍历链表 O(n),整体复杂度 O(n),不适合频繁随机位置增删。
4. 队列/栈结构选型建议
优先 ArrayDeque,内存紧凑无链表节点开销,性能远优于 LinkedList。
Map 模块(10道核心题)
- HashMap JDK 7 / JDK 8 底层结构区别
- 扰动函数、2次幂容量、负载因子 0.75 各自作用
- HashMap 完整 put 流程与扩容逻辑
- 链表转红黑树两大硬性条件
- JDK 7 并发扩容死循环成因与 JDK 8 修复方案
- ConcurrentHashMap 新旧版本锁机制差异
- ConcurrentHashMap 不支持 null 键值的底层原因
- CHM
size()统计数值不准确的原理 - 自定义实体类做 HashMap key 必须重写
hashCode+equals - 哈希碰撞极端场景性能退化解决方案
并发容器模块(4道核心生产向考题)
ArrayBlockingQueue与LinkedBlockingQueue对比,容器环境禁用无界队列SynchronousQueue适用场景,CachedThreadPool 底层原理CopyOnWriteArrayList优缺点与适用场景边界ConcurrentLinkedQueue无锁 CAS 与阻塞队列使用场景区分
🧨 2026云原生实战避坑清单
| 坑点场景 | 错误写法 | 生产标准方案 |
|---|---|---|
| ArrayList 遍历删除 | for-each 循环直接 list.remove() |
Iterator.remove() / JDK 8 removeIf() |
| ArrayList 大批量新增 | 无参构造后循环 add |
new ArrayList<>(预估容量),减少数组拷贝 |
| LinkedList 随机遍历 | for 循环 get(i) 逐一遍历 |
增强 for / 迭代器遍历,规避 O(n²) 复杂度 |
| 队列选用 LinkedList | 业务队列、本地缓存队列使用 LinkedList | 统一替换为 ArrayDeque,降低内存占用 |
| 🔴 容器化无界队列 | new LinkedBlockingQueue() 无参构造 |
强制指定有界容量,必须搭配拒绝策略 (如 CallerRunsPolicy),防止 Pod OOM 被杀 |
| 多线程共用 HashMap | 并发读写直接使用 HashMap |
统一使用 ConcurrentHashMap |
| 自定义对象做 Map 键 | 未重写 hashCode/equals |
必须重写双方法,遵循哈希契约 |
| CHM 复合读写操作 | containsKey + get + put 分段执行 |
使用 compute/merge 原子方法保证线程安全 |
| CopyOnWrite 高频写入 | 大量新增、删除场景使用 | 仅用于配置、白名单等读多写极少场景 |
| ConcurrentLinkedQueue 频繁获取总数 | 循环调用 size() |
size() 全量遍历 O(n),高并发业务尽量少调用 |
| 🟡 并发计数伪共享 | 多线程高频计数用普通 long 变量 | 使用 LongAdder 分散计数(底层自动分段),无需手动 @Contended;如需更极致优化可参考 @Contended 注解原理 |
🚀 下一阶段预告:第51~60篇 JUC并发编程全套详解
集合源码专题正式收官,下一个核心进阶板块**「多线程与JUC」**即将更新,完整覆盖:
- 线程完整生命周期、4种创建方式与6种状态
synchronized深度拆解:锁膨胀、对象头 MarkWordvolatile、JMM 内存模型与happens-before规则- AQS 同步器:
ReentrantLock、Semaphore、CountDownLatch底层 ThreadPoolExecutor线程池七大参数、拒绝策略、动态调优- 线上死锁定位工具
jstack、死锁四大必要条件 CompletableFuture异步编程、原子类、ThreadLocal实战
👉 订阅专栏,第一时间获取完整连载内容
🎁 配套资料福利
我将本阶段 6 篇源码知识点、面试题、线上避坑规范整理成**《集合源码速查PDF手册》**,方便线下打印、面试突击背诵。
领取方式:
- 关注 CSDN 主页:折哥|智能物流与Java实战
- 文章评论区留言关键词:集合通关
- 私信我即可获取 PDF 完整下载链接
📌 阅读行动指南
- 一键收藏:面试前快速翻阅速查表,节省复习时间
- 转发分享:发给正在备战面试、做后端老系统重构的同行,一起避开线上容器大坑
- 评论交流:有集合线上踩坑、面试疑难问题可留言,统一回复解答
- 订阅专栏:锁定 JUC 并发系列持续更新,完整走完《Java 100天进阶之路》
不焦虑、不躺平,吃透底层源码才能借力AI工具提升开发效率。集合专题到此完结,并发章节我们继续深耕。
👉 回到系列总目录 | 订阅Java进阶专栏
适用人群 :Java后端进阶开发者、校招/社招面试突击、物流/ERP/WMS系统开发、云原生线上问题排查工程师
系列归属 :《Java 100天进阶之路》|上一篇:阻塞队列与并发容器|下一篇:线程生命周期与创建方式