引言
rapidocr==3.9.0 仅支持 ONNXRuntime 和 OpenVINO 两个推理引擎,PaddlePaddle, PyTorch 和 MNN 打算在下个版本(v3.9.1)都支持了。
本篇文章就是用来记录 RapidOCR PP-OCRv6 Det 模型支持 PaddlePaddle, PyTorch, MNN 的过程,一是备忘,二是希望帮助需要的小伙伴们。
以下代码运行环境
- OS: macOS Tahoe 26.5.1
- Python: 3.10.14
- PaddlePaddle: 3.1.0
- paddle2onnx: 2.1.0
- paddlex: 3.7.1
- rapidocr: 3.9.0
- MNN: 3.2.5
- OpenVINO: 2026.2.1
- torch: 2.7.0
支持 PaddlePaddle
得益于原始模型就是 PaddlePaddle 格式,因此支持 PaddlePaddle 推理引擎较为容易,加上 @jaminmei 提的 PR #696。我这里做的工作少了许多,由衷地感谢。
需要做的:
- 将 Paddle 格式模型托管到魔搭仓库中,包括模型文件和字典文件。
- 更新
default_models.yaml文件中 Paddle 部分模型的路径和 SHA256,这个配置好后,可以直接通过参数指定EngineType为 Paddle 格式,程序会自动下载对应的模型。
测试代码如下:
python
from rapidocr import EngineType, RapidOCR
engine = RapidOCR(
params={
"Det.engine_type": EngineType.PADDLE,
"Rec.engine_type": EngineType.PADDLE,
}
)
img_url = "https://www.modelscope.cn/models/RapidAI/RapidOCR/resolve/master/resources/test_files/ch_en_num.jpg"
result = engine(img_url)
print(result)
result.vis("vis_result.jpg")以上代码可以正确打印出结果,说明程序跑通了。接下来跑一下在评测集上文字检测的指标,看看和之前跑的是否一致。
python
import cv2
import numpy as np
from rapidocr import EngineType, OCRVersion, RapidOCR
from tqdm import tqdm
from datasets import load_dataset
engine = RapidOCR(
params={
"Det.ocr_version": OCRVersion.PPOCRV6,
"Det.engine_type": EngineType.PADDLE,
"Det.model_type": ModelType.TINY,
}
)
dataset = load_dataset("SWHL/text_det_test_dataset")
test_data = dataset["test"]
content = []
for i, one_data in enumerate(tqdm(test_data)):
img = np.array(one_data.get("image"))
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
ocr_results = engine(img, use_det=True, use_cls=False, use_rec=False)
dt_boxes = ocr_results.boxes
dt_boxes = [] if dt_boxes is None else dt_boxes.tolist()
elapse = ocr_results.elapse
gt_boxes = [v["points"] for v in one_data["shapes"]]
content.append(f"{dt_boxes}\t{gt_boxes}\t{elapse}")
with open("pred.txt", "w", encoding="utf-8") as f:
for v in content:
f.write(f"{v}\n")
from text_det_metric import TextDetMetric
metric = TextDetMetric()
pred_path = "pred.txt"
metric = metric(pred_path)
print(metric)最终结果汇总到文章末尾了。
支持 PyTorch
PP-OCRv6 中,官方支持 safetensors 格式,支持用 transformers 库推理。经过我的调研,发现 safetensors 格式仅仅是权重,里面并没有具体网络结构。
因此想要直接使用 PyTorch 推理,就必须安装 transformers 库来推理。我翻看了 PaddleOCR, PaddleX 和 transformers 源码,试图找到 PP-OCRv6 检测和识别模型的网络结构定义。最终仅在 PaddleX 中找到了 PP-OCRv6_medium_det 的 PaddlePaddle 实现(source)。从源码中可以看到,当前版本所谓的支持 PyTorch 推理,也只是包装了一套 PaddlePaddle 实现的网路结构。如果想要不安装 PaddlePaddle,来使用 PyTorch 推理,那是不可能的。 因此,这条路算是走不通了。
但是 PaddleOCR2Pytorch 中已经支持 PP-OCRv6 文本检测和识别模型了。哈哈哈。RapidOCR 之前支持的 PyTorch 推理,其模型都是来自这个仓库。有了这个,剩下工作就是集成和测试一下指标就可以了。感谢大佬的工作。
评测代码:
python
import cv2
import numpy as np
from datasets import load_dataset
from tqdm import tqdm
from rapidocr import EngineType, ModelType, OCRVersion, RapidOCR
model_path = "models/PP-OCRv6_det_tiny.pth"
engine = RapidOCR(
params={
"Det.ocr_version": OCRVersion.PPOCRV6,
"Det.model_path": model_path,
"Det.engine_type": EngineType.TORCH,
}
)
dataset = load_dataset("SWHL/text_det_test_dataset")
test_data = dataset["test"]
content = []
for i, one_data in enumerate(tqdm(test_data)):
img = np.array(one_data.get("image"))
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
ocr_results = engine(img, use_det=True, use_cls=False, use_rec=False)
dt_boxes = ocr_results.boxes
dt_boxes = [] if dt_boxes is None else dt_boxes.tolist()
elapse = ocr_results.elapse
gt_boxes = [v["points"] for v in one_data["shapes"]]
content.append(f"{dt_boxes}\t{gt_boxes}\t{elapse}")
with open("pred.txt", "w", encoding="utf-8") as f:
for v in content:
f.write(f"{v}\n")
from text_det_metric import TextDetMetric
metric = TextDetMetric()
pred_path = "pred.txt"
metric = metric(pred_path)
print(metric)支持 MNN
bash
# 安装
pip install MNN==3.2.5
# 转换
MNNConvert -f ONNX --modelFile rapidocr/models/PP-OCRv6_det_medium.onnx --MNNModel mnn/PP-OCRv6_det_medium.mnn --bizCode MNN测试转换后的模型指标
python
import cv2
import numpy as np
from datasets import load_dataset
from tqdm import tqdm
from rapidocr import EngineType, ModelType, OCRVersion, RapidOCR
# 依次跑 Tiny, small 和 Medium 三个模型
model_path = "mnn/PP-OCRv6_det_tiny.mnn"
engine = RapidOCR(
params={
"Det.ocr_version": OCRVersion.PPOCRV6,
"Det.model_path": model_path,
"Det.engine_type": EngineType.MNN,
}
)
dataset = load_dataset("SWHL/text_det_test_dataset")
test_data = dataset["test"]
content = []
for i, one_data in enumerate(tqdm(test_data)):
img = np.array(one_data.get("image"))
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
ocr_results = engine(img, use_det=True, use_cls=False, use_rec=False)
dt_boxes = ocr_results.boxes
dt_boxes = [] if dt_boxes is None else dt_boxes.tolist()
elapse = ocr_results.elapse
gt_boxes = [v["points"] for v in one_data["shapes"]]
content.append(f"{dt_boxes}\t{gt_boxes}\t{elapse}")
with open("pred.txt", "w", encoding="utf-8") as f:
for v in content:
f.write(f"{v}\n")
from text_det_metric import TextDetMetric
metric = TextDetMetric()
pred_path = "pred.txt"
metric = metric(pred_path)
print(metric)最终结果汇总到文章末尾了。
不同推理引擎指标汇总
在这里将 ONNXRuntime, OpenVINO, PaddlePaddle, MNN 和 PyTorch 在 PP-OCRv6 Det 模型上指标和速度都汇总起来了,便于大家选用最合适的。
TensorRT 的指标等有时间再补哈!
各个推理引擎对应不同的模型,最终指标效果如下:
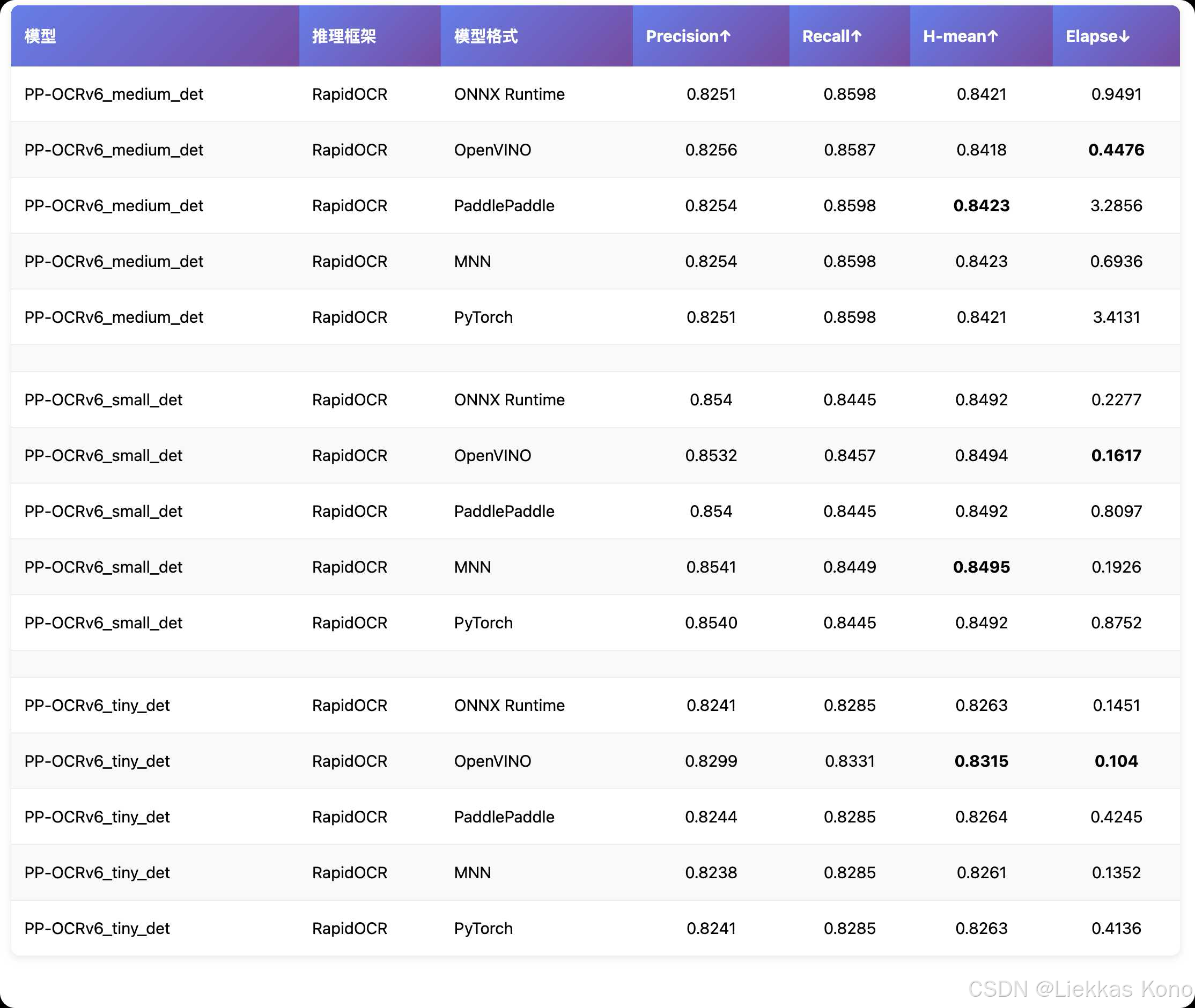
从以上推理速度来看,OpenVINO 竟然是最快的了。这个有点出乎我的意料。
上述推理引擎的支持,将会随 rapidocr==3.9.1 发布,敬请期待!