2.5 实战:构建问答智能体
接下来,将通过一个实战项目构建一个基于 LangChain 的多工具问答智能体,打造一个既能理解用户意图,又能自主选择调用工具,并具备良好可观测性的智能体。具体实现目标如下。
(1)自然语言问答交互。用户可通过自然语言直接提问,如今天上海的天气怎么样或请计算\((12+7)×3\)的值。系统能通过大模型准确解析用户意图,并自动规划、执行对应的任务流程。
(2)多工具集成与动态调用。集成多个基于 MCP 的工具,包括计算工具与实时查询天气服务。智能体具备运行时决策能力,能根据问题上下文自动选择并调用合适的工具。
(3)中间件增强与治理 。引入自定义中间件,实现包括请求日志记录、异常拦截与对话历史摘要等横切关注点逻辑。确保系统具备可观测性、鲁棒性与可控性。
(4)可视化交互页面。采用Streamlit 框架构建轻量级 Web 页面,实时展示智能体的完整工作流程。
2.5.1 项目环境搭建
1. 使用 conda 命令创建虚拟环境
推荐使用 conda 命令创建项目所需的独立虚拟环境。若对 conda 命令尚不熟悉,则请参考官方文档进行安装和学习。
(1)创建虚拟环境 agentQ2,使用 Python 3.13.7:
conda create -n agentQ2 python=3.13.7假如创建环境报错:
Collecting package metadata (current_repodata.json): done
Solving environment: failed with repodata from current_repodata.json, will retry with next repodata source.
Collecting package metadata (repodata.json): done
Solving environment: \
Found conflicts! Looking for incompatible packages.
This can take several minutes. Press CTRL-C to abort.
failed
UnsatisfiableError:
Note that strict channel priority may have removed packages required for satisfiability.可以进行如下方式修复:
先修改渠道优先级,关闭 strict
conda config --set channel_priority flexible
更新 base 环境 conda 本体(最关键,老 conda 解 3.13 必炸)
conda update -n base conda -y
更新完成后关闭当前终端,重新打开
清理损坏缓存
conda clean --all -y
还是想用 Python3.13(加指定 conda-forge 源创建)
conda create -n agentQ2 python=3.13 -c conda-forge(2)进入虚拟环境 agentQ:
conda activate agentQ2进入之后,命令行提示符前将显示环境标识(agentQ)
2. 构建项目目录
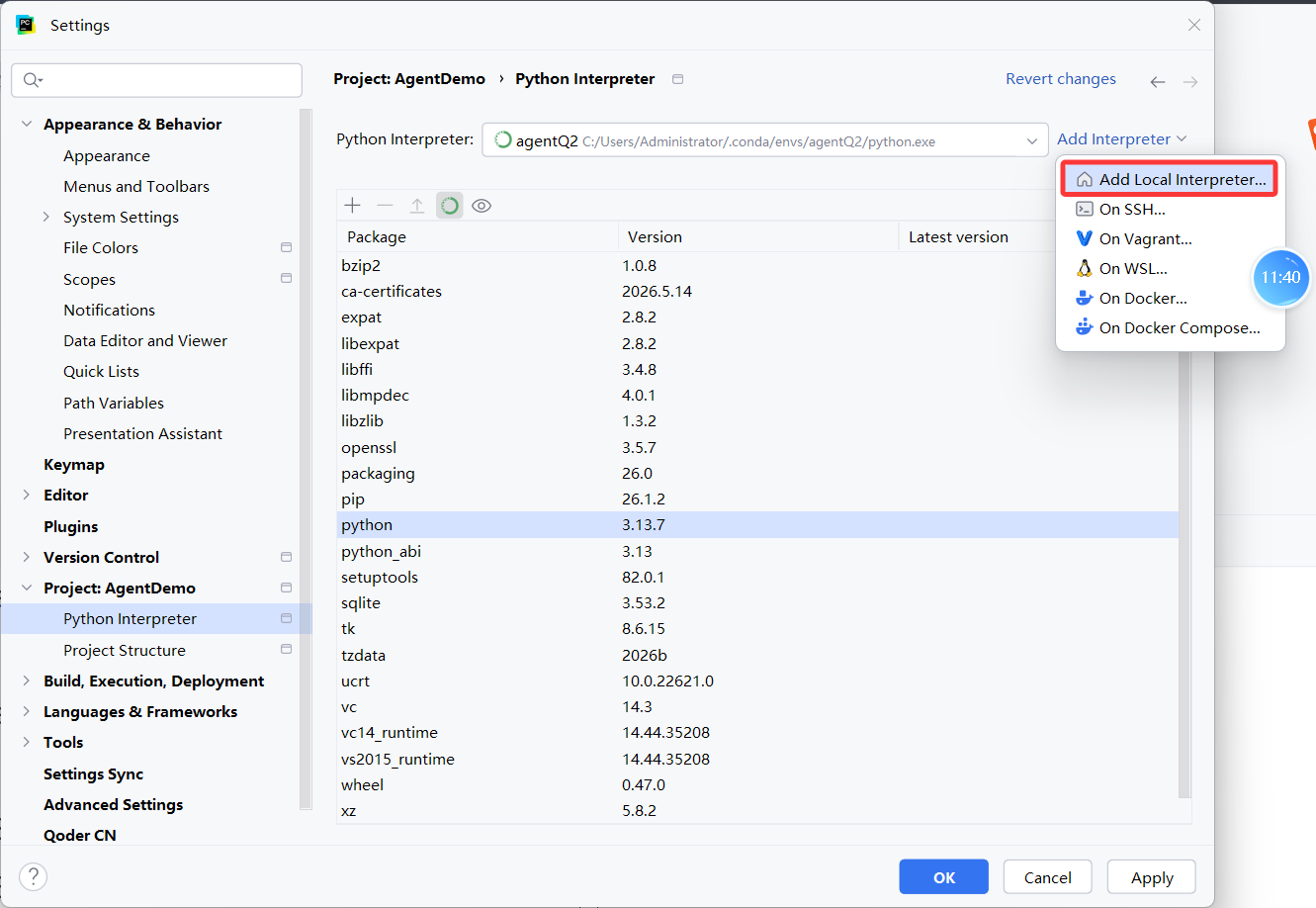
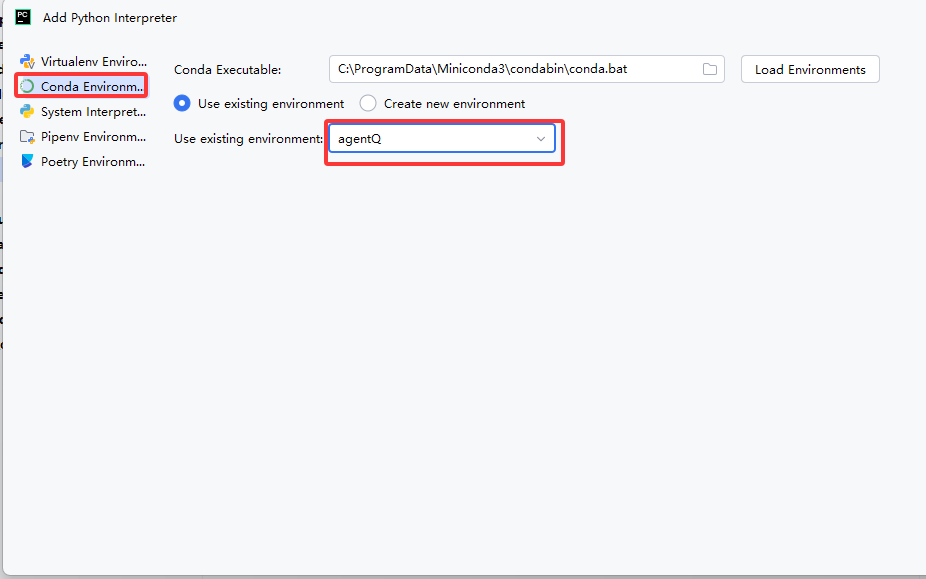
终端环境是 agentQ2,但 PyCharm 跑代码用了 base 或系统 Python
在根目录下创建名为 agentQ 的项目文件夹,并按照以下结构创建项目目录,所有文件内容为空:
agentQ2
├── agent
│ ├── mcp_tools.py
│ ├── memory.py
│ ├── middleware.py
| ___message_sanitize.py
│ ├── prompts.py
│ └── runner.py
├── app_streamlit.py
├── mcp_server
│ ├── math_server.py
│ └── weather_server.py
└── requirements.txt在目录构建完成后,请使用代码编辑器打开项目。
3. 安装项目依赖
1)编写 requirements.txt 文件中的代码
打开 requirements.txt 文件,加入以 LangChain 1.0 为核心的依赖库。 requirements.txt 文件的代码如下:
# LangChain 主包(需与 langgraph>=1.1.5 对齐,否则会出现
# ImportError: cannot import name 'ExecutionInfo' from 'langgraph.runtime')
langchain==1.2.15
# 与 langchain 1.2.x 的 Requires-Dist 一致,显式写出便于排查版本问题
langgraph>=1.1.5,<1.2.0
# 社区集成(与 1.0 匹配的 0.3 系列)
langchain-community==0.3.31
# OpenAI 适配 ------ 必须是 1.0 系列,否则与 core 1.0 不兼容
langchain-openai==1.0.2
# Ollama 适配
langchain-ollama>=0.1.0
# 辅助依赖,降低 3.13 解析回溯
pydantic>=2.12
typing-extensions>=4.15
python-dotenv>=1.0.0
# 数据库依赖(PostgreSQL)
psycopg2-binary>=2.9.0
sqlalchemy>=2.0.0
# MCP 依赖
mcp>=1.21.0
langchain-mcp-adapters>=0.1.12
# 其他依赖
dashscope>=1.24.9
streamlit==1.51.02)安装项目依赖
pip install -r requirements.txt2.5.2 项目目录的结构说明
下面对项目的目录结构进行详细说明。
(1)agent/:智能体的核心逻辑层。
① mcp_tools.py:定义基于 MCP 的多工具客户端接口,用于连接外部服务端(计算工具和实时查询天气工具)。通过 MultiServerMCPClient,系统可动态加载不同的工具,并支持 stdio 和 http 两种传输模式。
② memory.py:提供对话的记忆管理(短期记忆)功能,用于缓存历史输入与模型响应,使智能体能基于上下文进行推理或摘要。
③ middlewares.py:定义一系列中间件组件,如日志记录、异常拦截、夜间简报提示、对话摘要压缩等。中间件以可插拔方式实现横切逻辑,增强系统的可维护性与扩展性。
④ prompts.py:存放系统 Prompt,用于控制模型的行为风格与指令格式,保证不同的任务在调用时的统一性。
⑤ runner.py:智能体的主控制模块,负责调用模型、执行推理循环,并协调中间件与工具集,是智能体执行问答逻辑的核心入口。
(2)app_streamlit.py:基于 Streamlit 框架构建的可视化页面,提供简洁的网页问答。该文件是项目运行入口,集成了智能体初始化、用户输入,以及实时响应展示逻辑。
(3)mcp_server/:工具层,该目录包含可独立运行的外部工具,每个工具均实现了 MCP 接口,供智能体动态调用。
① math_server.py:计算工具,提供数学计算功能,可解析与执行自然语言中的算术表达式。
② weather_server.py:实时查询天气工具,提供天气查询接口,使用 streamable-http 模式。
(4)requirements.txt:列出了项目运行所需的依赖库。
2.5.3 集成 MCP 工具层
接下来开始编写核心代码。首先完成 MCP 工具层的集成,这一层的职责是将外部能力封装成 MCP 工具,并通过统一的多服务客户端提供给上层的 LangChain 智能体使用。从项目目录的结构中可以看出,需要构建 MCP Server 与 MCP Client。
(1)MCP Server:用 FastMCP 快速定义工具并发布(math_server.py 使用 stdio 传输协议启动,weather_server.py 使用 http 传输协议启动)。
(2)MCP Client:用 MultiServerMCPClient 同时连接多个 MCP 服务端,并把工具转换成 LangChain 可调用的 Tool 列表(mcp_tools.py)。
1. 封装 math_server.py 文件的代码
提供基础的计算能力,包括 add (a,b) 与 multiply (a,b) 功能,用于验证智能体从工具调用到结果返回的完整执行链路。 关键实现点如下。
(1)导入 FastMCP 类:通过 from mcp.server.fastmcp import FastMCP 引入简洁的 MCP 服务端 API。
(2)初始化服务实例:使用 mcp = FastMCP ("Math") 创建名为 Math 的 MCP 服务端
(3)工具注册机制:通过 @mcp.tool 装饰器将普通 Python 函数转换为 MCP 工具。
(4)传输方式配置:采用 mcp.run (transport="stdio") 启动服务端,使用标准输入 / 输出传输,便于客户端以子进程方式直接调用,无须额外管理网络端口或 HTTP 服务端。
"""
Math MCP 服务:
- 提供最基础的算术工具(加法、乘法)
- 通过 stdio 传输协议供 LangChain MCP 客户端调用
"""
import sys
from mcp.server.fastmcp import FastMCP
# 创建一个名为 "Math" 的 MCP 服务
mcp = FastMCP("Math")
# 定义第一个工具:加法
# 使用 @mcp.tool() 装饰器即可将函数注册为 MCP 工具。
@mcp.tool()
def add(a: int, b: int) -> int:
"""计算两数之和,同时输出调试信息便于排查。"""
# 注意:stdio 模式下,print 输出会被 MCP 协议吞掉
# 使用 stderr 输出调试信息,这样可以在主进程日志中看到
print(f"-----> [Math Server] Adding {a} and {b}", file=sys.stderr)
result = a + b
print(f"-----> [Math Server] Result: {result}", file=sys.stderr)
return result
# 定义第二个工具:乘法
# 使用 @mcp.tool() 装饰器即可将函数注册为 MCP 工具。
@mcp.tool()
def multiply(a: int, b: int) -> int:
"""计算两数之积,同时输出调试信息便于排查。"""
# 使用 stderr 输出调试信息
print(f"-----> [Math Server] Multiplying {a} and {b}", file=sys.stderr)
result = a * b
print(f"-----> [Math Server] Result: {result}", file=sys.stderr)
return result
# 运行 MCP 服务,使用 stdio 传输协议
# transport="stdio" 表示通过标准输入输出进行通信。
if __name__ == "__main__":
mcp.run(transport="stdio")2. 封装 weather_server.py 文件的代码
对 Open-Meteo(一个开源免费的天气 API)进行封闭,提供地理编码和实时查询天气两个功能,支持从城市名到经纬度的转换,以及根据经纬度获取实时天气数据。 关键实现点如下。
(1)服务初始化:使用 mcp = FastMCP ("Weather") 创建名为 Weather 的 MCP 服务端。
(2)HTTP 客户端:依赖 httpx 库访问 Open-Meteo 公有 API。
(3)工具注册:通过 @mcp.tool 装饰器将查询函数注册为 MCP 工具。
(4)传输协议:配置服务使用 streamable-http 传输协议,监听 http://localhost:8000/mcp 端点。
"""
Weather MCP 服务:
- 封装 Open-Meteo 的地理编码与天气查询 API
- 通过 streamable-http 传输协议提供城市天气检索工具
"""
import sys
from mcp.server.fastmcp import FastMCP
import httpx
from typing import Dict, Any, Optional
mcp = FastMCP("Weather")
# ---------------------------------------------------------------------
# 定义 Open-Meteo 公共 API 地址(无需 API Key)
# 1. WEATHER_URL ------ 根据经纬度查询当前天气
# 2. GEOCODE_URL ------ 根据城市名查询经纬度
# ---------------------------------------------------------------------
OPEN_METEO_WEATHER_URL = "https://api.open-meteo.com/v1/forecast"
OPEN_METEO_GEOCODE_URL = "https://geocoding-api.open-meteo.com/v1/search"
# 工具一:geocode_city()
# 将城市名解析为经纬度信息
@mcp.tool()
def geocode_city(name: str, country: Optional[str] = None, language: str = "zh") -> Dict[str, Any]:
"""将城市名解析为经纬度,返回首个匹配结果的基础信息。"""
params = {"name": name, "count": 1, "language": language, "format": "json"}
if country:
params["country"] = country
with httpx.Client(timeout=10) as client:
r = client.get(OPEN_METEO_GEOCODE_URL, params=params)
r.raise_for_status()
data = r.json()
results = data.get("results") or []
if not results:
return {"error": f"未找到城市:{name}"}
top = results[0]
# 使用 stderr 输出调试信息,避免干扰 HTTP 响应
print(f"-----> [Weather Server] Geocoding {name} to {top.get('latitude')}, {top.get('longitude')}", file=sys.stderr)
return {
"name": top.get("name"),
"lat": top.get("latitude"),
"lon": top.get("longitude"),
"country": top.get("country"),
}
# 工具二:get_current_weather()
# 根据经纬度查询当前天气
@mcp.tool()
def get_current_weather(lat: float, lon: float) -> Dict[str, Any]:
"""根据经纬度查询当前天气,返回温度、风速等核心指标。"""
params = {"latitude": lat, "longitude": lon, "current_weather": True}
with httpx.Client(timeout=10) as client:
r = client.get(OPEN_METEO_WEATHER_URL, params=params)
r.raise_for_status()
payload = r.json()
cw = payload.get("current_weather") or {}
print(f"-----> [Weather Server] Getting current weather for {lat}, {lon}: {cw}", file=sys.stderr)
return {
"latitude": lat,
"longitude": lon,
"temperature": cw.get("temperature"),
"windspeed": cw.get("windspeed"),
"weathercode": cw.get("weathercode"),
"time": cw.get("time"),
}
# 工具三:get_current_weather_by_city()
# 组合前两个工具,实现「城市名 → 当前天气」的完整流程
@mcp.tool()
def get_current_weather_by_city(name: str, country: Optional[str] = None, language: str = "zh") -> Dict[str, Any]:
"""城市名 -> 当前天气(内部先地理编码再查询天气)。"""
g = geocode_city(name=name, country=country, language=language)
if "error" in g:
return g
w = get_current_weather(lat=g["lat"], lon=g["lon"])
print(f"-----> [Weather Server] Getting current weather by city {name}: {w}", file=sys.stderr)
return {**g, **w}
# transport="streamable-http" 表示使用 HTTP 协议暴露服务
# 端点默认路径是 /mcp,端口通常为 8000
if __name__ == "__main__":
print("Starting Weather MCP Server (streamable-http) on http://localhost:8000/mcp ...")
mcp.run(transport="streamable-http")3、 封装 mcp_tools.py
文件的代码 整合多个 MCP 服务端的连接配置,通过 MultiServerMCPClient 统一管理服务连接,为上层 LangChain 智能体提供可直接调用的工具列表。
关键实现点如下。
(1)服务配置整合:在 build_tools 函数内配置 Math 与 Weather 服务端连接,Math 服务端以子进程方式启动,Weather 服务端通过 HTTP 直连。
(2)异步调用处理:使用 asyncio.run (...) 方法包装异步操作,确保在同步代码中安全获取工具列表。
"""
MCP 工具装配模块:
- 通过 MultiServerMCPClient 同时连接本地 math 与 weather 服务
- 返回 LangChain Agent 可直接使用的 Tool 列表
"""
import asyncio
from pathlib import Path
from langchain_mcp_adapters.client import MultiServerMCPClient
def build_tools():
"""
封装 math 与 weather 两个 MCP 服务:
- math:通过 stdio 启动本地 math_server.py
- weather:通过 streamable-http 连接到固定端口(http://localhost:8000/mcp)
"""
# 获取项目根目录(agent/mcp_tools.py 的父目录的父目录)
project_root = Path(__file__).parent.parent
math_server_path = project_root / "mcp_server" / "math_server.py"
client = MultiServerMCPClient({
"math": {
"transport": "stdio",
"command": "python",
"args": [str(math_server_path)],
},
"weather": {
"transport": "streamable_http",
"url": "http://localhost:8000/mcp", # Weather MCP Server 固定地址
},
})
# asyncio.run 会自动创建/关闭事件循环,确保在同步上下文中安全获取工具
return asyncio.run(client.get_tools())2.5.4 集成 Prompt 与短期记忆
主要解决以下两个核心问题。
(1)集中管理 Prompt:将系统 Prompt 模板、工具使用规范及异常处理策略统一维护,避免在代码中分散定义。
(2)管理上下文记忆:采用基于滑动窗口的短期记忆机制,保留最近对话消息,为模型提供必要的上下文。
当前的短期记忆通过上下文拼接实现,完整的记忆管理应使用 LangGraph 记忆机制,我们将在后续章节详细探讨。
1. 封装 prompts.py 文件的代码
集中管理系统 Prompt 模板,通过 SYSTEM_PROMPT 明确定义工具调用规范:包括何时使用 Weather 工具、何时使用 Math 工具的参数判断逻辑,在参数缺失时引导用户补充信息而非直接调用,同时统一设定异常处理机制与输出风格规范。
"""
系统提示语模块:
- 统一维护 Agent 的 System Prompt,强调工具使用策略与输出约束
"""
SYSTEM_PROMPT = """你是一个可靠的中文问答助手,具备调用外部工具的能力。
当前可用工具(通过 MCP 提供):
- weather:查询城市天气(如 get_current_weather_by_city)
- math:进行数学计算,包含以下工具:
* add(a, b):计算两数之和
* multiply(a, b):计算两数之积
【决策规则】
1)若问题涉及天气/温度/降雨/风/空气质量等 → 使用 weather。
- 若缺少城市名,先礼貌澄清"请告知要查询的城市?"再调用工具。
2)若问题涉及计算/公式/比例/单位换算等 → 必须使用 math 工具进行计算。
- 对于加法运算,使用 add 工具;对于乘法运算,使用 multiply 工具。
- 即使是很简单的计算(如 6+6),也必须调用工具,不要直接回答。
- 若缺少必要数值或表达式,先澄清再调用工具。
3)若问题不涉及天气或计算,则直接回答。
4)若同一轮既涉及天气又涉及计算,按需要分别调用相应工具;整合结果后给出一个自然语言答案。
5)工具调用失败时,简要说明原因,并给出下一步可操作建议(例如更换城市或稍后再试)。
【输出风格】
- 先给结论,再给关键依据;必要时用列表分点说明。
- 不输出你的思考过程;不要编造工具未返回的数据。
- 内容使用简体中文。
当前日期:{today}
"""2. 封装 memory.py 文件的代码
实现基于滑动窗口的短期记忆机制,通过对话窗口仅保留最近 N 轮对话消息,避免长对话场景下将全部历史记录输入模型,有效控制 Token 消耗成本。
关键实现点如下。
(1)add(msg: List[BaseMessage]):向窗口追加消息,当消息数量超出 window_size 时自动移除最早的消息。
(2)get() -> List[BaseMessage]:获取当前窗口内所有消息的副本。
(3)clear():清空窗口中的所有消息记录。
"""
对话记忆模块:
- 提供轻量级滑动窗口记忆,用于保存最近若干轮会话
"""
from typing import List
from langchain_core.messages import BaseMessage
class ConversationWindow:
"""
对话短期记忆窗口。
- 基于 InMemorySaver 封装(仅进程内存储,不落库)
- 按 window_size 控制保留最近若干轮对话消息
"""
def __init__(self, window_size: int = 5):
# 控制窗口长度,例如保留最近 5 轮会话
self.window_size = window_size
self.buffer: List[BaseMessage] = []
def add(self, msgs: List[BaseMessage]):
"""新增消息并自动裁剪窗口"""
self.buffer.extend(msgs)
print(f"-----> Memory: Adding messages: {self.buffer}")
if len(self.buffer) > self.window_size * 2:
self.buffer = self.buffer[-self.window_size * 2 :]
def get(self) -> List[BaseMessage]:
"""返回当前会话窗口中的消息"""
print(f"-----> Memory: Getting messages: {self.buffer}")
return list(self.buffer)
def clear(self):
"""清空对话缓存"""
print(f"-----> Memory: Clearing messages: {self.buffer}")
self.buffer = []
print(f"-----> Memory: Cleared messages: {self.buffer}")
def build_memory(window_size: int = 5) -> ConversationWindow:
"""工厂方法:创建对话记忆对象"""
return ConversationWindow(window_size=window_size)2.5.5 集成中间件
中间件层用于承载横切关注点,把与业务无关但又需要的能力从智能体主流程里剥离出来,形成一条可插拔、可编排的处理链。
(1)可观察性与可调试:记录每轮对话与工具调用的结构化日志、耗时与状态,当出现异常时给出可读的诊断信息,便于本地调试与线上排查故障。
(2)对话长度控制与成本优化:当上下文过长时触发对话摘要,把早期多轮对话压缩为一段小结,从而在不丢失关键语义的前提下降低 Token 成本。
(3)用户体验策略:在特定场景下注入附加提示(如夜间提示和礼貌提醒)、统一输出语气与格式,保证交互体验稳定一致。
关键实现点如下。
(1)预置中间件 封装在 install_builtin_middlewares 函数中,其中用到 SummarizationMiddleware 中间件,作为项目中的对话压缩器 ,在对话过长时(超过 3000 Token)自动生成摘要,替换早期消息,防止上下文膨胀。
(2)基于装饰器的中间件@before_agent(name="rate_guard")在智能体执行前统一实施请求限额策略 ,两次请求间隔小于 1s 时拒绝并返回提示,大于 1s 时放行。
(3)基于装饰器的中间件@before_model(name="clarify_missing_params")在模型调用前检查参数。
(4)基于装饰器的中间件@after_model(name="post_format_checker")在模型调用后会在 state 标记输出已检查。
(5)基于装饰器的中间件@after_agent(name="post_agent_logger")在智能体执行完成后会记录完成时间。
(6)基于装饰器的中间件@dynamic_prompt() night_briefing 会动态提示,在 23:00---7:00 时间段内返回 "夜间模式"。
(7)基于类的中间件 TimingAndRetryMiddleware 会记录模型调用耗时与异常时重试。其中,wrap_model_call 函数同步包装模型调用,awrap_model_call 函数异步包装模型调用。
(8)基于类的中间件 ConversationGuardMiddleware 会限制输入长度,对历史过长时提示总结,限制输出长度。其中,before_agent 校验输入长度,before_model 检查历史消息,after_model 输出长度截断。
(9)install_default_middlewares 函数统一装配所有中间件。
"""
中间件总装配(覆盖三类形态):
1) 预置(Built-in)中间件:直接复用官方提供的能力(示例:SummarizationMiddleware)
2) 基于"装饰器"的中间件:使用 before_agent / after_agent / before_model / after_model /
wrap_model_call / dynamic_prompt 六种钩子组合,轻量、函数式、低侵入
3) 基于"类"的中间件:继承 AgentMiddleware,集中实现多个阶段的治理逻辑,适合复杂策略
参考文档:
- Built-in middleware: https://docs.langchain.com/oss/python/langchain/middleware#built-in-middleware
- Decorator-based: https://docs.langchain.com/oss/python/langchain/middleware#decorator-based-middleware
- Class-based: https://docs.langchain.com/oss/python/langchain/middleware#class-based-middleware
"""
from __future__ import annotations
import time
from typing import Optional, Awaitable, Callable
from langchain_core.messages import AIMessage, HumanMessage
from langchain_openai import ChatOpenAI
from langchain.agents.middleware import (
before_agent,
after_agent,
before_model,
after_model,
dynamic_prompt,
AgentMiddleware,
AgentState,
ModelRequest,
ModelResponse,
SummarizationMiddleware,
)
from agent.message_sanitize import stringify_dialog, stringify_message
# =========================================================
# 1) 预置(Built-in)中间件
# =========================================================
def install_builtin_middlewares():
"""
官方内置中间件:自动摘要对话上下文
使用独立的 summarization 模型,并设置触发/保留策略。
"""
print("[中间件] 开始安装官方内置 SummarizationMiddleware。")
summ_llm = ChatOpenAI(
model="deepseek-chat",
api_key="你的API",
base_url="https://api.deepseek.com",
temperature=0.0,
)
summarizer = SummarizationMiddleware(
model=summ_llm,
max_tokens_before_summary=3000,
messages_to_keep=20,
)
print("[中间件] 官方内置 SummarizationMiddleware 装载完成。")
return [summarizer]
# =========================================================
# 2) 装饰器(Decorator-based)中间件
# =========================================================
# 2.1 限频(在 Agent 入场前)
def _rate_limit_guard(state: AgentState) -> Optional[dict]:
now = time.time()
last = state.get("_last_ts", 0.0)
print(f"[中间件] rate_guard 触发检查:now={now}, last={last}")
if now - last < 1.0:
msg = AIMessage(content="请求太快啦,请 1 秒后再试。")
print("[中间件] rate_guard 生效:拒绝请求并终止流程。")
return {"messages": state.get("messages", []) + [msg], "jump_to": "end"}
state["_last_ts"] = now
print("[中间件] rate_guard 放行:更新最近访问时间。")
return None
@before_agent(name="rate_guard")
def rate_guard(state: AgentState, *_args, **_kw) -> Optional[dict]:
return _rate_limit_guard(state)
# 2.2 在模型前做参数澄清引导(天气缺城市 / 数学缺表达式)
def _clarify_intent_guard(state: AgentState) -> Optional[dict]:
msgs = state.get("messages", [])
last = msgs[-1] if msgs else None
if not isinstance(last, HumanMessage):
print("[中间件] clarify_missing_params 略过:最后一条消息不是用户。")
return None
text = (last.content or "").strip()
print(f"[中间件] clarify_missing_params 检查文本:{text}")
need_weather = any(k in text for k in ["天气", "温度", "weather"])
has_city = any(k in text for k in ["北京", "上海", "广州", "深圳", "杭州", "新加坡", "Singapore"])
if need_weather and not has_city:
print("[中间件] clarify_missing_params 提醒:天气查询缺少城市。")
return {"system_prompt": "若用户查询天气但未提供城市,请先礼貌询问城市名称,仅提出一个澄清问题。"}
need_math = any(k in text for k in ["计算", "结果", "乘", "加", "减", "除", "表达式"])
has_expr = any(ch in text for ch in ["+", "-", "*", "/", "(", ")"])
if need_math and not has_expr:
print("[中间件] clarify_missing_params 提醒:数学计算缺少表达式。")
return {"system_prompt": "若用户需要计算但缺少表达式,请先让其提供明确的表达式,然后再调用计算工具。"}
print("[中间件] clarify_missing_params 未发现澄清需求。")
return None
@before_model(name="clarify_missing_params")
def clarify_missing_params(state: AgentState, *_args, **_kw) -> Optional[dict]:
return _clarify_intent_guard(state)
# 2.3 模型后:轻度标注
def _post_model_annotate(state: AgentState) -> None:
#_metrics 是状态里预留的自定义指标字典,用来记录流程标记、耗时、校验标记等;
metrics = state.setdefault("_metrics", {})
#给指标打上布尔标记:post_checked = True
#业务含义:代表当前流程已经走完「模型后置校验 / 后置标注」逻辑。
metrics["post_checked"] = True
print("[中间件] post_format_checker 已执行:标记模型输出已检查。")
@after_model(name="post_format_checker")
def post_format_checker(state: AgentState, *_args, **_kw) -> None:
_post_model_annotate(state)
# 2.4 Agent 后:打点
def _log_after_agent(state: AgentState) -> None:
state["_last_done"] = time.time()
print(f"[中间件] post_agent_logger 已执行:记录完成时间 {state['_last_done']}")
@after_agent(name="post_agent_logger")
def post_agent_logger(state: AgentState, *_args, **_kw) -> None:
_log_after_agent(state)
# 2.5 动态提示(示例:夜间更简洁)
# 注意:@dynamic_prompt 会把返回值包成 SystemMessage(content=prompt)。
# 若返回 None,在 LangChain 1.2.x 会得到 SystemMessage(content=None),触发 Pydantic 校验错误。
# 白天必须返回「当前系统提示」字符串(见 ModelRequest.system_prompt),以保留 create_agent 的 system_prompt。
def _night_briefing_rule(request: ModelRequest) -> str:
hour = time.localtime().tm_hour
print(f"[中间件] night_briefing 检查当前小时:{hour}")
base = request.system_prompt or ""
if hour >= 23 or hour < 7:
print("[中间件] night_briefing 生效:进入夜间简洁模式。")
suffix = "夜间模式:请尽量简洁作答,不要过度展开。"
return f"{base}\n\n{suffix}" if base else suffix
return base
@dynamic_prompt()
def night_briefing(request: ModelRequest) -> str:
return _night_briefing_rule(request)
def install_decorator_middlewares():
"""组合装饰器型中间件(顺序会影响效果)"""
print("[中间件] 开始安装装饰器型中间件。")
return [
rate_guard,
night_briefing,
clarify_missing_params,
post_format_checker,
post_agent_logger,
]
# =========================================================
# 3) 类(Class-based)中间件
# =========================================================
def _record_latency(req: ModelRequest, latency_ms: float) -> None:
metrics = req.state.setdefault("_metrics", {})
metrics["last_model_latency_ms"] = latency_ms
print(f"[中间件] timing_and_retry 记录模型耗时:{latency_ms} ms")
def _timed_retry_wrapper_sync(
req: ModelRequest,
call: Callable[[ModelRequest], ModelResponse | AIMessage],
retries: int = 1,
) -> ModelResponse | AIMessage:
print("[中间件] timing_and_retry 同步封装开始。")
t0 = time.time()
try:
resp = call(req)
except Exception:
print("[中间件] timing_and_retry 捕获异常,尝试重试。")
if retries > 0:
resp = call(req)
else:
raise
latency_ms = round((time.time() - t0) * 1000, 2)
_record_latency(req, latency_ms)
print("[中间件] timing_and_retry 同步封装结束。")
return resp
async def _timed_retry_wrapper_async(
req: ModelRequest,
call: Callable[[ModelRequest], Awaitable[ModelResponse | AIMessage]],
retries: int = 1,
) -> ModelResponse | AIMessage:
print("[中间件] timing_and_retry 异步封装开始。")
t0 = time.time()
try:
resp = await call(req)
except Exception:
print("[中间件] timing_and_retry 捕获异步异常,尝试重试。")
if retries > 0:
resp = await call(req)
else:
raise
latency_ms = round((time.time() - t0) * 1000, 2)
_record_latency(req, latency_ms)
print("[中间件] timing_and_retry 异步封装结束。")
return resp
class TimingAndRetryMiddleware(AgentMiddleware):
"""
wrap_model_call 风格示例:
- 计算模型调用耗时
- 捕获异常并简单重试一次
"""
@property
def name(self) -> str:
return "timing_and_retry"
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse | AIMessage],
) -> ModelResponse | AIMessage:
return _timed_retry_wrapper_sync(request, handler)
async def awrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], Awaitable[ModelResponse | AIMessage]],
) -> ModelResponse | AIMessage:
return await _timed_retry_wrapper_async(request, handler)
class ConversationGuardMiddleware(AgentMiddleware):
"""
会话治理中间件(示例):
- before_agent:输入长度校验
- before_model:历史过多时先总结
- after_model:输出过长时截断
"""
def __init__(self, max_input_chars: int = 3000, max_output_chars: int = 4000):
self.max_input_chars = max_input_chars
self.max_output_chars = max_output_chars
@property
def name(self) -> str:
return "conversation_guard"
def before_agent(self, state: AgentState, runtime=None, **kwargs) -> dict | None: # noqa: ARG002
print("[中间件] ConversationGuard.before_agent 检查输入长度。")
last = state.get("messages", [])[-1] if state.get("messages") else None
if isinstance(last, HumanMessage) and len(last.content or "") > self.max_input_chars:
msg = AIMessage(content="输入过长,已拒绝处理。请缩短后重试。")
print("[中间件] ConversationGuard.before_agent 拒绝:输入过长。")
return {"messages": state["messages"] + [msg], "jump_to": "end"}
return None
def before_model(self, state: AgentState, runtime=None, **kwargs) -> dict | None: # noqa: ARG002
print("[中间件] ConversationGuard.before_model 检查消息数量。")
if len(state.get("messages", [])) > 20:
print("[中间件] ConversationGuard.before_model 生效:历史消息过多,提示先总结。")
return {"system_prompt": "历史较多,请先简要总结要点,再给出答案。"}
return None
def after_model(self, state: AgentState, runtime=None, **kwargs) -> None: # noqa: ARG002
print("[中间件] ConversationGuard.after_model 检查输出长度。")
messages = state.get("messages", [])
if not messages:
return
last = messages[-1]
if isinstance(last, AIMessage) and len(last.content or "") > self.max_output_chars:
last.content = last.content[: self.max_output_chars] + "\n...(已自动截断过长输出)"
print("[中间件] ConversationGuard.after_model 生效:输出过长已截断。")
class DeepSeekStrictContentMiddleware(AgentMiddleware):
"""
在每次真正调用聊天模型前,把 ModelRequest 里所有消息的 content 压成字符串。
仅处理 runner 记忆不够覆盖的路径:ReAct 过程中模型返回的块列表会再次进入下一轮请求,
DeepSeek 会报 messages[n]: expected string, got sequence。
放在中间件列表末尾,使 wrap_model_call 处于最内层、紧邻模型调用。
"""
@property
def name(self) -> str:
return "deepseek_strict_content"
def _sanitize_request(self, request: ModelRequest) -> ModelRequest:
overrides: dict = {"messages": stringify_dialog(request.messages)}
sys_m = request.system_message
if sys_m is not None and not isinstance(sys_m.content, str):
overrides["system_message"] = stringify_message(sys_m)
return request.override(**overrides)
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse | AIMessage],
) -> ModelResponse | AIMessage:
return handler(self._sanitize_request(request))
async def awrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], Awaitable[ModelResponse | AIMessage]],
) -> ModelResponse | AIMessage:
return await handler(self._sanitize_request(request))
# =========================================================
# 4) 统一装配出口
# =========================================================
def install_default_middlewares():
"""
统一给 runner 调用的装配函数:
- 先挂上装饰器型"轻治理"
- 再挂上类中间件"重治理"(含 wrap_model_call)
- 追加官方"预置中间件"
返回:可直接传入 create_agent(..., middleware=[...]) 的列表
"""
print("[中间件] 开始安装默认中间件栈。")
middlewares = []
middlewares.extend(install_decorator_middlewares())
print("[中间件] 装饰器型中间件安装完成。")
middlewares.append(TimingAndRetryMiddleware())
print("[中间件] 计时重试中间件添加完成。")
middlewares.append(ConversationGuardMiddleware())
print("[中间件] 会话治理中间件添加完成。")
middlewares.extend(install_builtin_middlewares())
print("[中间件] 官方内置中间件添加完成。")
middlewares.append(DeepSeekStrictContentMiddleware())
print("[中间件] DeepSeek 消息 content 规范化(wrap_model_call 最内层)已添加。")
print(f"[中间件] 中间件列表就绪:{[mw.name if hasattr(mw, 'name') else type(mw).__name__ for mw in middlewares]}")
return middlewares这段代码专门统一格式化 LangChain 消息里的 content,解决多模型接口兼容问题: 部分厂商(DeepSeek、部分国产大模型)不支持新版 OpenAI 格式的多模态块列表 (content=[{type:"text",text:"xxx"},...]),只接受纯字符串 content: "文本"。
stringify_content(content: Any) -> str
核心转换函数,把任意类型 content 强制转为纯文本字符串,兼容 4 种常见格式
"""将消息 content 规范为字符串,兼容 DeepSeek 等要求 content 不能为块列表的接口。"""
from __future__ import annotations
import json
from typing import Any, List, Sequence
from langchain_core.messages import BaseMessage
def stringify_content(content: Any) -> str:
if content is None:
return ""
if isinstance(content, str):
return content
if isinstance(content, list):
parts: list[str] = []
for block in content:
if isinstance(block, str):
parts.append(block)
elif isinstance(block, dict):
if "text" in block:
parts.append(str(block["text"]))
elif block.get("type") == "text":
parts.append(str(block.get("text", "")))
else:
parts.append(json.dumps(block, ensure_ascii=False))
else:
text = getattr(block, "text", None)
parts.append(str(text) if text is not None else str(block))
return "\n".join(parts)
return str(content)
def stringify_message(msg: BaseMessage) -> BaseMessage:
if isinstance(msg.content, str):
return msg
return msg.model_copy(update={"content": stringify_content(msg.content)})
def stringify_dialog(messages: Sequence[BaseMessage]) -> List[BaseMessage]:
return [stringify_message(m) for m in messages]2.5.6 集成智能体调度器
智能体调度器是整个智能体的调度核心,负责将 LLM、Prompt、工具集、中间件、记忆等组件编排成一个可运行的智能体管线(Agent Runner),并定义问答流程的完整生命周期。
关键实现点如下。
(1)invoke定义了单轮调用流程。
① 拼接历史与当前输入:从 memory 中获取历史消息,将用户输入转为 HumanMessage,拼接到历史消息后形成 state。
② 调用智能体:使用 asyncio.run 函数同步调用异步 agent.ainvoke(state)函数,智能体内部处理 ReAct、工具、中间件等。
③ 回写记忆:清空旧记忆,将完整消息列表(含历史 + 新增)整体写入 memory,实现滑动窗口更新。
④ 返回 AI 文本:获取最后一条消息,若为 AIMessage,则返回 content,否则转为字符串。
(2)build_runner()->AgentRunner:定义使用 DeepSeek Chat 模型;调用 build_tools函数获取了 MCP 工具;调用 install_default_middlewares 函数获取所有中间件;使用create_agent函数组装模型、工具、系统 Prompt、中间件;调用 build_memory(window_size=5) 函数创建滑动窗口(保留最近 5 条消息)。
runner.py 文件的代码如下:
from __future__ import annotations
"""
Agent runner 模块:
- 对 LangChain create_agent 进行最小封装,结合 MCP 工具与中间件
- 提供同步调用入口,方便在 Streamlit 等传统 Web 环境中复用
- 暴露 build_runner() 供应用层按需构建预配置的 AgentRunner
"""
import asyncio
from typing import List
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
from langchain_core.messages import AIMessage, HumanMessage
from agent.prompts import SYSTEM_PROMPT
from agent.mcp_tools import build_tools
from agent.memory import build_memory, ConversationWindow
from agent.message_sanitize import stringify_dialog
from agent.middlewares import install_default_middlewares
class AgentRunner:
"""
一个最小可用的 Agent 调用器:
- 使用 create_agent(model, tools, middlewares, system_prompt)
- 通过 ConversationWindow 维护短期对话记忆(不落库)
- 输入输出均走 Messages 机制(HumanMessage / AIMessage)
"""
def __init__(self, *, agent, memory: ConversationWindow):
self.agent = agent
self.memory = memory
def invoke(self, user_input: str) -> str:
"""单轮调用:拼接历史 + 本轮输入 -> 调用 Agent -> 回写记忆 -> 返回文本"""
# 1) 拼接历史与当前输入(Messages 机制)
history: List = stringify_dialog(self.memory.get())
print(f"-----> Runner: History: {history}")
state = {"messages": history + [HumanMessage(content=user_input)]}
print(f"-----> Runner: State: {state}")
# 2) 调用 Agent(内部自动处理ReAct、工具、中间件)
new_state = asyncio.run(self.agent.ainvoke(state))
print("--------------------------------")
print(f"-----> Runner: New state: {new_state}")
print("--------------------------------")
# 3) 回写记忆为最新窗口
# 因为 messages 本身已经包含了之前的历史 + 这次的新增消息,所以这里是"整体替换"而不是"在旧列表末尾 append"。
messages = stringify_dialog(new_state.get("messages", []))
self.memory.clear()
self.memory.add(messages)
# 4) 返回本轮 AI 文本
last = messages[-1] if messages else None
return last.content if isinstance(last, AIMessage) else (str(last) if last is not None else "")
def build_runner() -> AgentRunner:
"""
组装一个最简洁的 Runner:
- DeepSeek 模型
- MCP 工具(math + weather)
- 中间件(预置 + 装饰器 + 类中间件,详见 middlewares.install_default_middlewares)
- 短期记忆(InMemorySaver 封装的滑窗)
"""
# app_streamlit.py 在页面初始化时会调用此方法,确保界面加载后即可复用同一套配置。
model = ChatOpenAI(
model="deepseek-chat",
api_key="你的API",
base_url="https://api.deepseek.com",
temperature=0.3,
)
tools = build_tools()
middlewares = install_default_middlewares()
agent = create_agent(
model=model,
tools=tools,
system_prompt=SYSTEM_PROMPT,
middleware=middlewares,
)
memory = build_memory(window_size=5)
return AgentRunner(agent=agent, memory=memory)2.5.7 集成问答页面
基于 Streamlit 框架构建可视化页面,用于展示智能体的问答能力,集成快捷示例面板、对话历史显示、用户输入表单和对话重置功能。 因为我们的重点不是介绍前端代码的编写,所以不对代码进行展示,你可以参考app_streamlit.py 文件。
from __future__ import annotations
"""
Streamlit 前端入口:
- 提供一个最小聊天界面,用于演示 AgentRunner 的问答能力
- 包含快捷示例、对话历史、输入表单与侧边栏重置逻辑
"""
import streamlit as st
from agent.runner import build_runner
st.set_page_config(
page_title="AgentQ --- 问答智能体",
page_icon="🤖",
layout="centered",
)
# --- 初始化 ---
if "runner" not in st.session_state:
# AgentRunner:封装模型+工具+中间件(复用同一个实例)
st.session_state.runner = build_runner()
if "history" not in st.session_state:
# history:前端展示的聊天记录(列表保存角色和文本)
st.session_state.history = []
if "_prefill" not in st.session_state:
# _prefill:输入框的预填内容,示例按钮会写入它
st.session_state._prefill = ""
st.title("AgentQ --- 问答智能体")
# 快捷示例(不改后端,仅便于输入)
with st.expander("示例问题(点一下即可带入输入框)", expanded=False):
c1, c2, c3 = st.columns(3)
if c1.button("今天上海天气怎样?"):
st.session_state._prefill = "今天上海天气怎样?"
st.rerun()
if c2.button("计算 (3+5)*12"):
st.session_state._prefill = "计算 (3+5)*12"
st.rerun()
if c3.button("帮我总结:LangChain 作用是什么?"):
st.session_state._prefill = "帮我总结:LangChain 作用是什么?"
st.rerun()
# 展示历史
for role, content in st.session_state.history:
with st.chat_message("user" if role == "user" else "assistant"):
st.markdown(content)
# 输入区域:使用 form + text_input,支持预填
with st.form(key="chat_form", clear_on_submit=True):
user_text = st.text_input(
"输入",
value=st.session_state._prefill,
placeholder="例如:今天上海天气怎样? 或 计算 (3+5)*12",
label_visibility="collapsed",
)
sent = st.form_submit_button("发送")
# 发送
if sent:
st.session_state._prefill = ""
prompt = (user_text or "").strip()
if prompt:
st.session_state.history.append(("user", prompt))
with st.chat_message("user"):
st.markdown(prompt)
try:
# 调用 AgentRunner(runner.py中)的 invoke 方法,传入用户输入的 prompt
reply = st.session_state.runner.invoke(prompt)
except Exception as e:
reply = f"抱歉,发生错误:{e}"
st.session_state.history.append(("assistant", reply))
with st.chat_message("assistant"):
st.markdown(reply)
# 侧边栏:重置
with st.sidebar:
st.subheader("会话控制")
if st.button("清空会话 / 重置记忆", use_container_width=True):
# 重建 runner(清空短期记忆),清空历史
st.session_state.runner = build_runner()
st.session_state.history = []
st.session_state._prefill = ""
st.rerun()2.5.8 运行测试
为了更直观地查看项目的运行过程,在代码中打印了很多日志,可以在控制台中查看。
1. 启动项目
进入 mcp_server 文件夹后,通过以下命令启动 Weather MCP 服务端:
python weather_server.py启动成功后,会出现日志,如图 2-23 所示。
Starting MCP Server (streamable-http) on http://localhost:8000/mcp ...
INFO: Started server process [28628]
INFO: Waiting for application startup.
StreamableHTTP session manager started
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)图 2-23
在项目根目录下,通过以下命令打开项目页面:
streamlit run app_streamlit.py --server.port 7860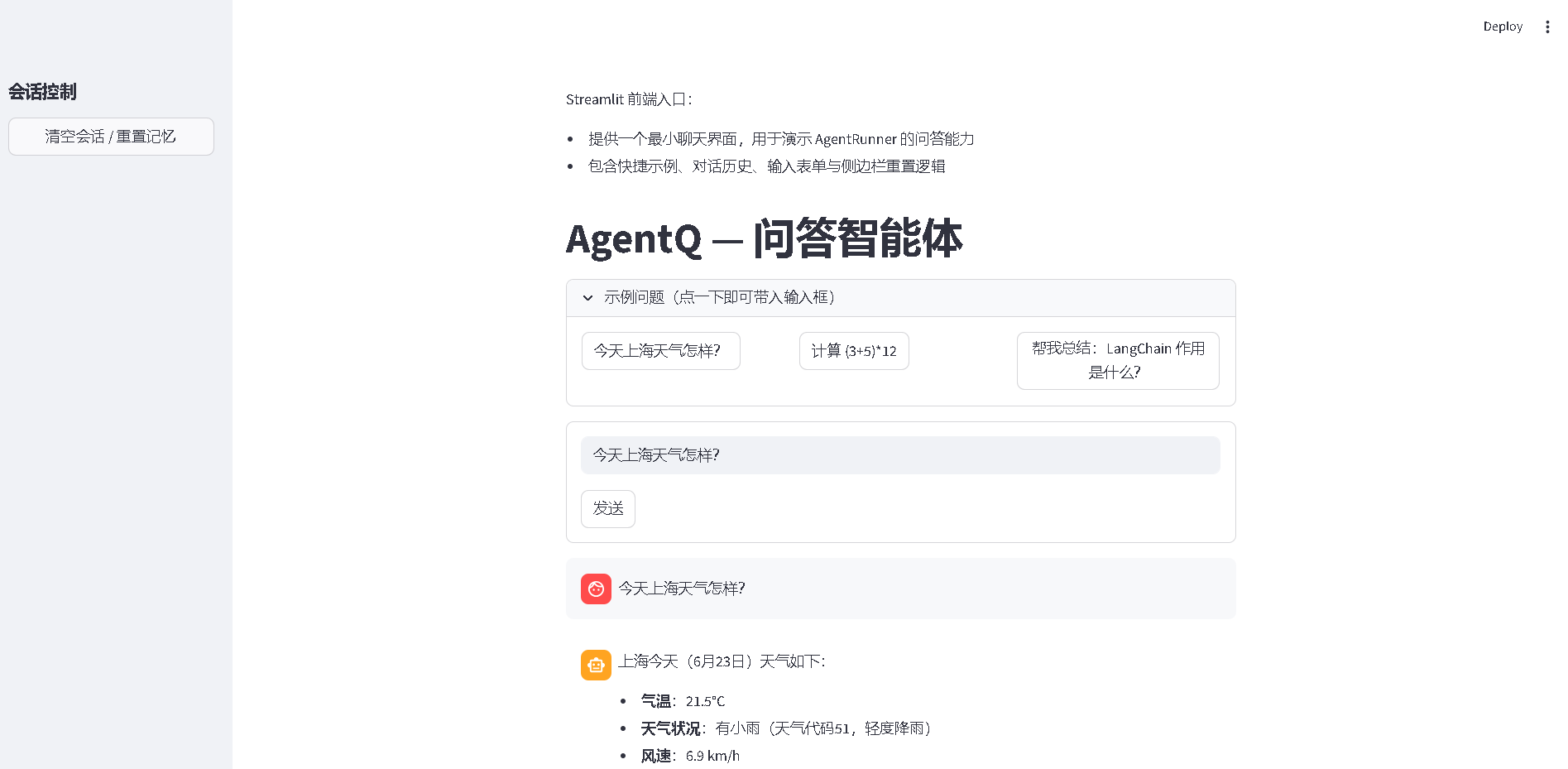
启动成功后,会出现日志,如图 2-24 所示。
You can now view your Streamlit app in your browser.
Local URL: http://localhost:7860
Network URL: http://192.168.12.177:7860
For better performance, install the Watchdog module:
$ xcode-select --install
$ pip install watchdog
Processing request of type ListToolsRequest
【中间件】开始安装默认中间件。
【中间件】请求限流中间件装载完成。
【中间件】耗时统计中间件装载完成。
【中间件】对消息做摘要中间件加载完成。
【中间件】开始配置内置 SummarizationMiddleware。
【中间件】摘要内置中间加载完成。
【中间件】官方内置中间加载完成。
【中间件】中间列表装载:['rate_guard', 'night_briefing', 'clarify_missing_params', 'post_format_checker', 'post_agent_logger', 'timing_and_retry', 'conversation_guard', 'SummarizationMiddleware']图 2-24
服务端启动成功后,系统将在浏览器中自动打开应用页面,如图 2-25 所示。若页面未自动打开,则可通过手动输入 http://localhost:7860 打开页面。
图 2-25:AgentQ--- 问答智能体页面
2. 测试
1)测试计算逻辑
在页面中输入问题:计算(3+5)*12。运行结果如图 2-26 所示,正确输出了计算结果。
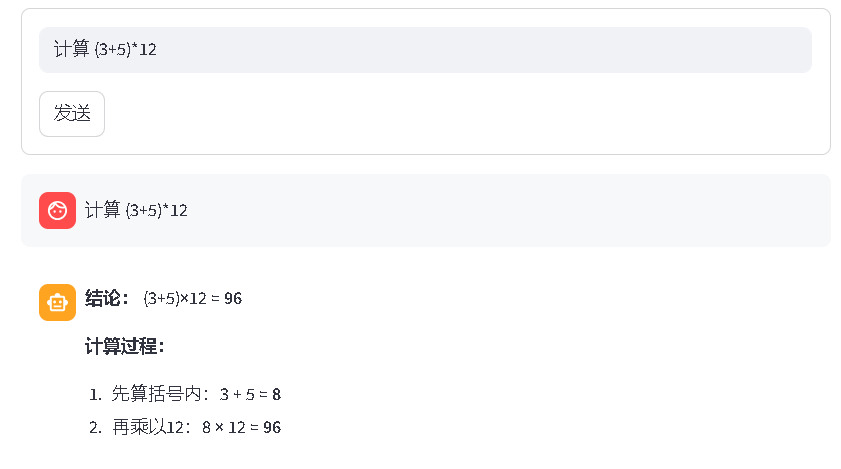
图 2-26:计算交互页面
从控制台日志(如图 2-27 所示)中可见,计算工具 Math 被调用了两次:首次被调用执行加法运算,随后被调用执行乘法运算。同时,日志还完整展示了中间件的执行流程。
2)测试获取实时天气逻辑
我们在页面中输入问题:"今天上海的天气怎么样?",运行结果如图 2-28 所示,正确输出了当前上海的天气情况。
图 2-28 AgentQ--- 问答智能体页面 页面示例输出:

根据查询结果,今天上海的天气情况如下:
• 城市:上海
• 温度:17.1℃
• 风速:11.3km/h
• 天气状况:多云(天气代码3表示多云)
• 更新时间:2025年11月12日06:45
今天上海多云,温度17.1℃,风力适中,是比较舒适的天气。查看 Weather MCP 服务端启动对应的控制台日志,可以观察到具体的 API 调用情况,如图 2-29 所示。
图 2-29 Weather 服务端调用日志
3)测试计算 + 获取实时天气逻辑
如果将这两种问题混合在一起,那么系统可以正确调用工具并返回结果吗?例如,在页面中输入问题 "(3+3)*3=?,并且告诉我现在大连的天气",运行结果如图 2-30 所示,毫无疑问,也正确输出了结果。
图 2-30 AgentQ--- 问答智能体交互页面 页面输出内容:

计算结果:
• (3+3)*3 = 18
大连当前天气:
• 温度:23.1℃
• 风速:13.4km/h
• 天气状况代码:3(多云)
• 更新时间:2025-11-12 06:45通过控制台日志可见,Math 与 Weather 工具均被成功调用,如图 2-31 所示。其中 Math 工具执行了两次运算:先进行加法运算,随后执行乘法运算。
图 2-31 混合调用控制台日志
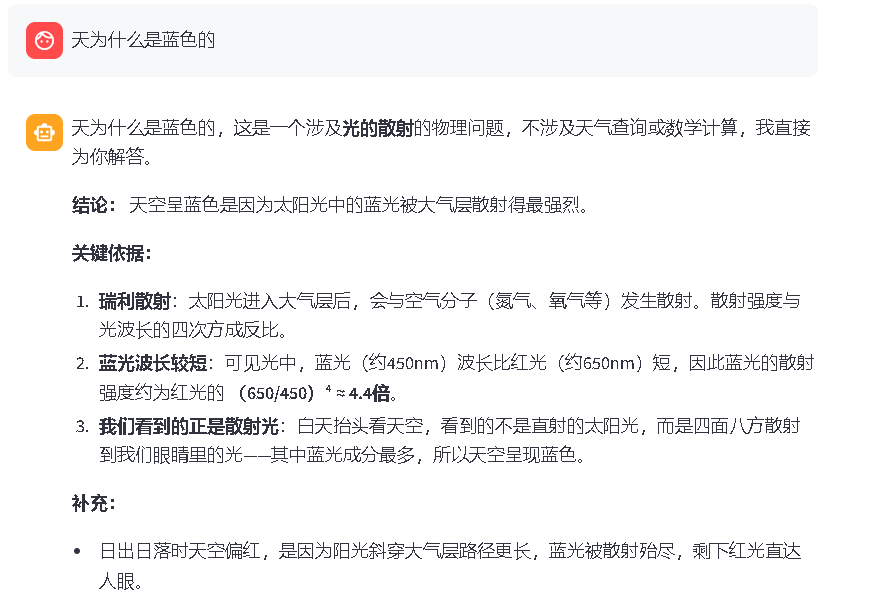
4)常规问答测试
当提出与计算和天气查询之外的问题时(例如,为什么天是蓝色的),系统不会调用任何工具,会通过调用大模型直接给出结果,运行结果如图 2-32 所示。
图 2-32 AgentQ--- 问答智能体页面
用户提问:为什么天是蓝色的 模型直接输出相关科普解答,无工具调用。