在大数据的环境当中,kafka是一个非常重要的组件,如果想要进行一些实时的处理,基本上都是离不开kafka的。
kafka对消息保存是根据主题topic进行归类的。JMS有两种消息模型,一种是队列,一种是主题。kafka采用的是主题,也就是发布订阅这种模式。

kafka集群当中是有多个broker的,zk会去记录所有的broker的信息,记录所有topic的信息,这样的元数据是保存在zk上面的。
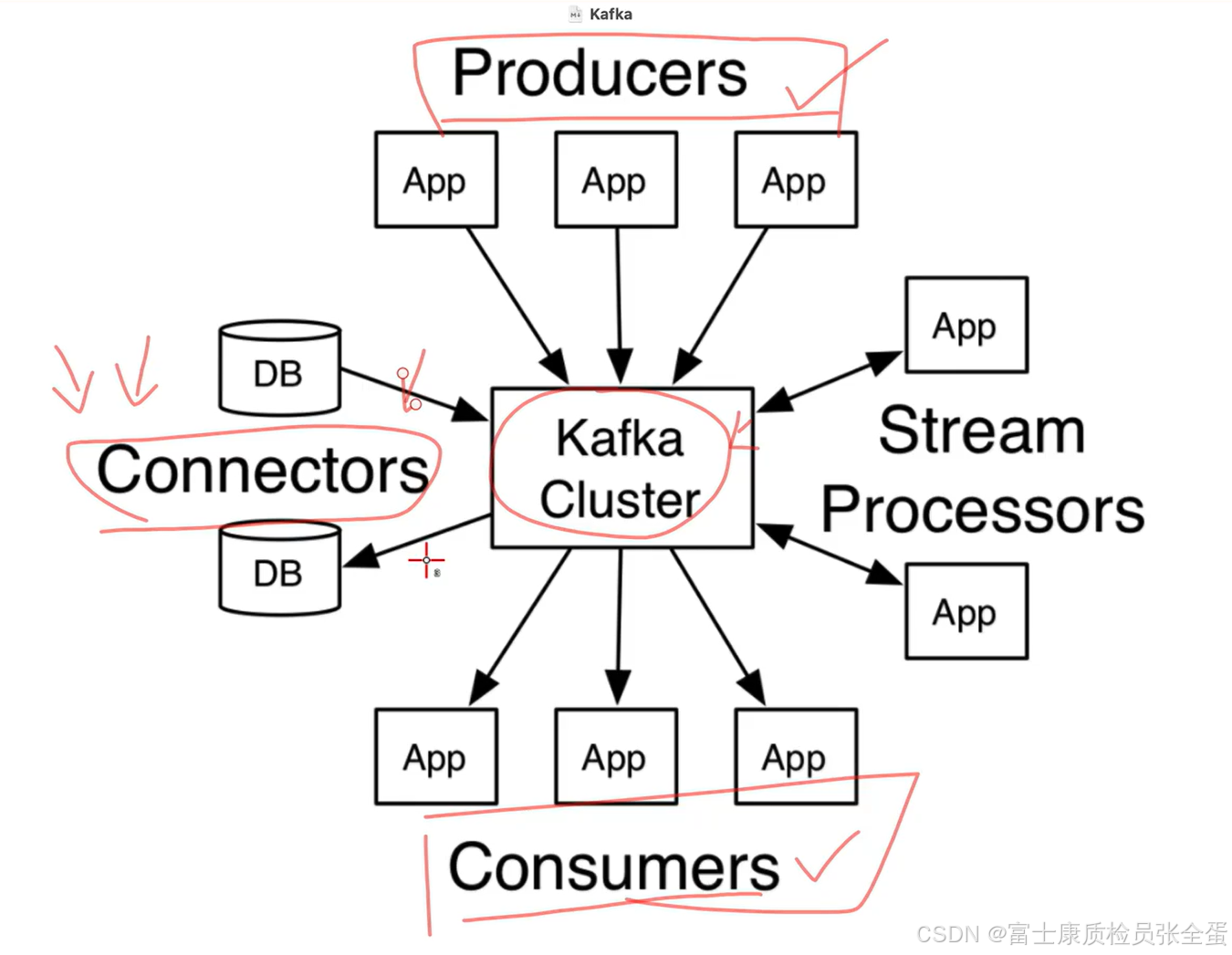
一个kafka的集群,生产者消费者是核心功能之一。对于读取文件和数据库中的数据,需要这些实时的加载到kafka的队列当中,connects提供了统一的消息导入和导出的解决方案。
可以将外部的数据导入到kafka当中,比如文件中的数据,数据库中的数据等等,这些数据直接读取到kafka指定的主题当中进行存储。当然也可以将kafka当中指定topic中的数据导出出来。比如导出到文件或者数据库当中。
connectors就是这样一个组件来实现消息在kafka集群中的导入和导出的操作,stream流可以对kafka中的数据做一些流式的处理。

如果kafka中的消息被消费过了,那么还想再读取一遍,重新消费一次,也是ok的。
扩展性提高生产和消费能力。

broker翻译过来叫代理,它其实是kafka的一个节点,kafka也是一个分布式的集群,在集群中的每个角色称作为一个broker。
**每一个主题的每一个分区它都是有多个副本文件的,**一个topic做了3个分区,3个分区发布在3个节点上进行存储,结果有个节点挂了,那么这个节点上的消息就丢了。通过副本机制来进行容错,可以将分区多做几个副本,在其他节点上也放一份。如果这个节点挂了,那么可以从其他节点去恢复数据。
一个分区多个副本之间也存在leader和follower这样的角色组成一个集群。
segement是分区再往下的一个存储单元。
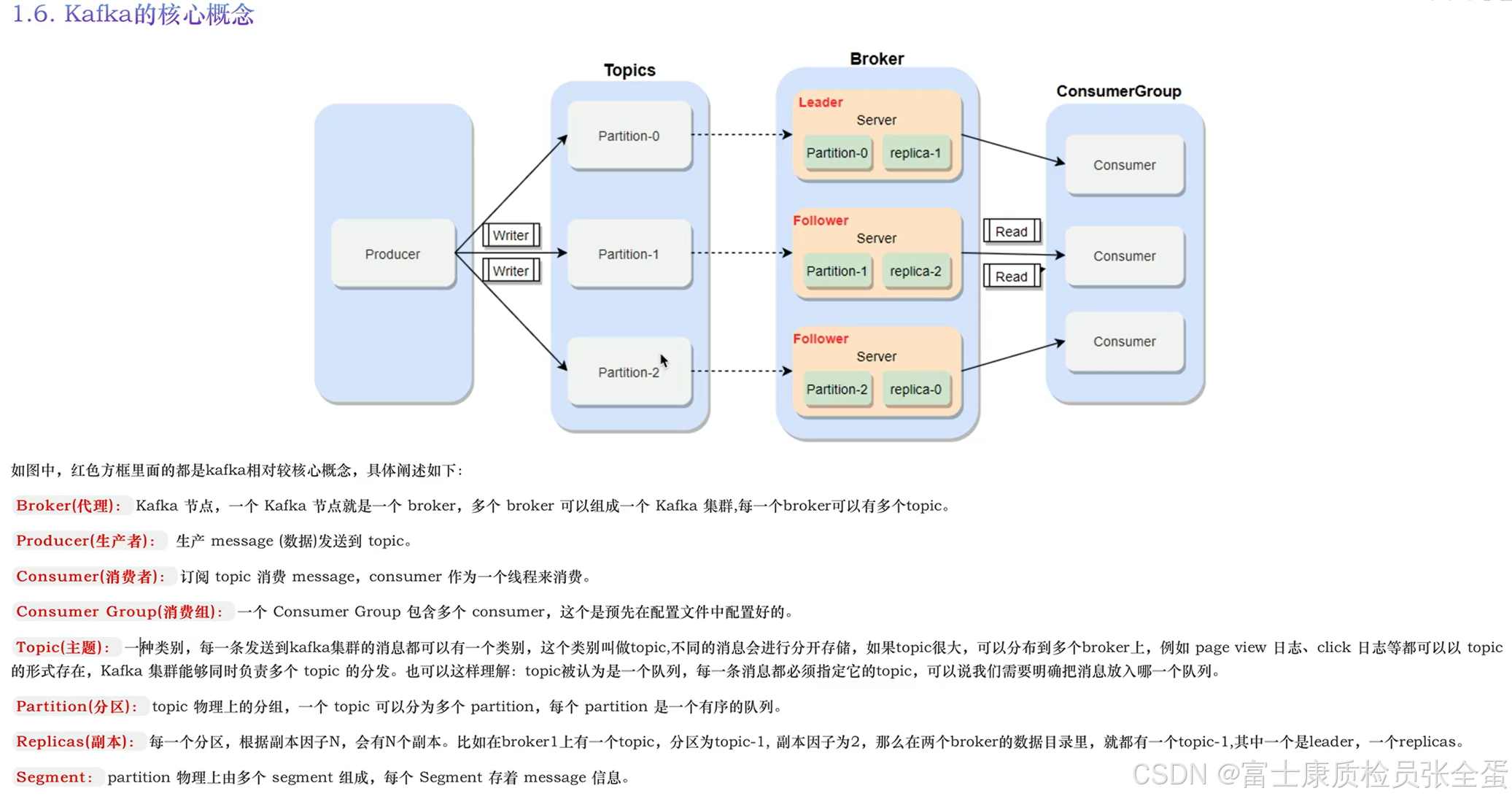
生产者将消息写入到了指定topic的分区里面,一条消息只能写到一个分区里面。至于消息存放在哪个分区里面这就是由分区器来决定的。
分区也会存在broker节点上面,同时他会有多个副本文件,在其他的broker上会进行副本订单拷贝。
最后由consumer从这些comsumer上面进行数据的拉取,在去消费指定topic中的数据,在消费的时候找到的是leader角色的partition,然后对其进行数据的读取操作。这是简单的流程。
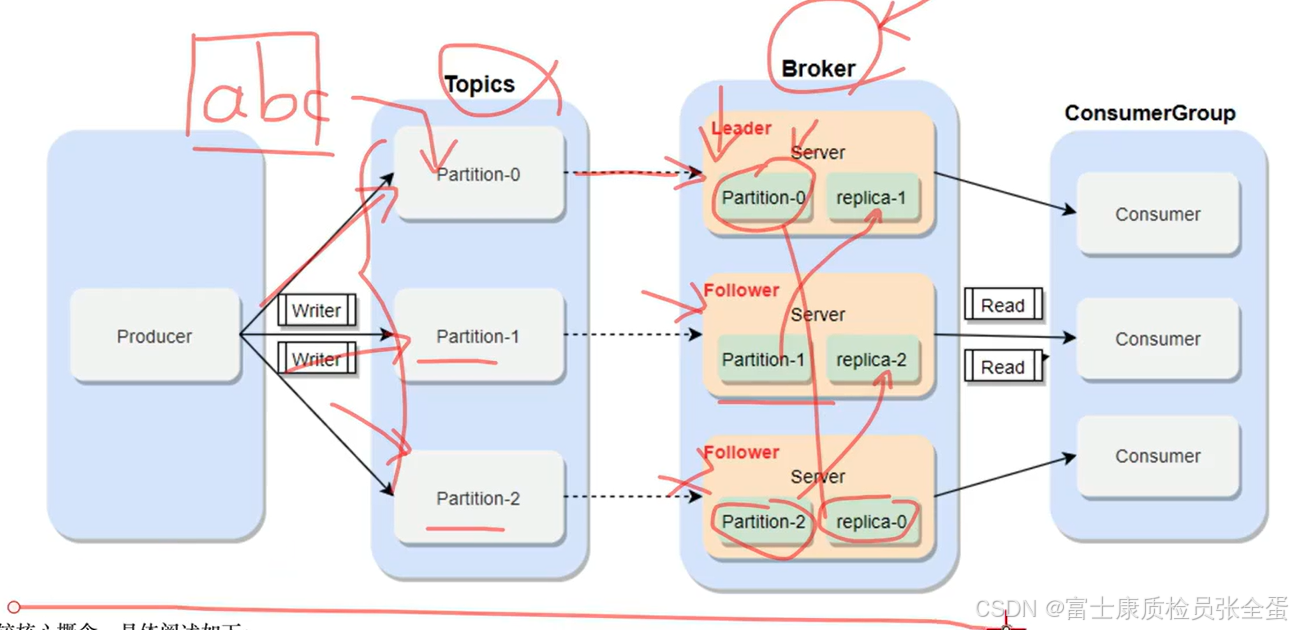

kafka有很多原生的connector。