OpenTalking:开源实时数字人全栈管线,从 Mock 到生产级一键切换
datascale-ai 开源数字人编排框架------LLM + TTS + WebRTC + 可插拔模型后端,CPU 即可验证全链路,RTX 3090 本地实时对话,OmniRT 远端高清推理。
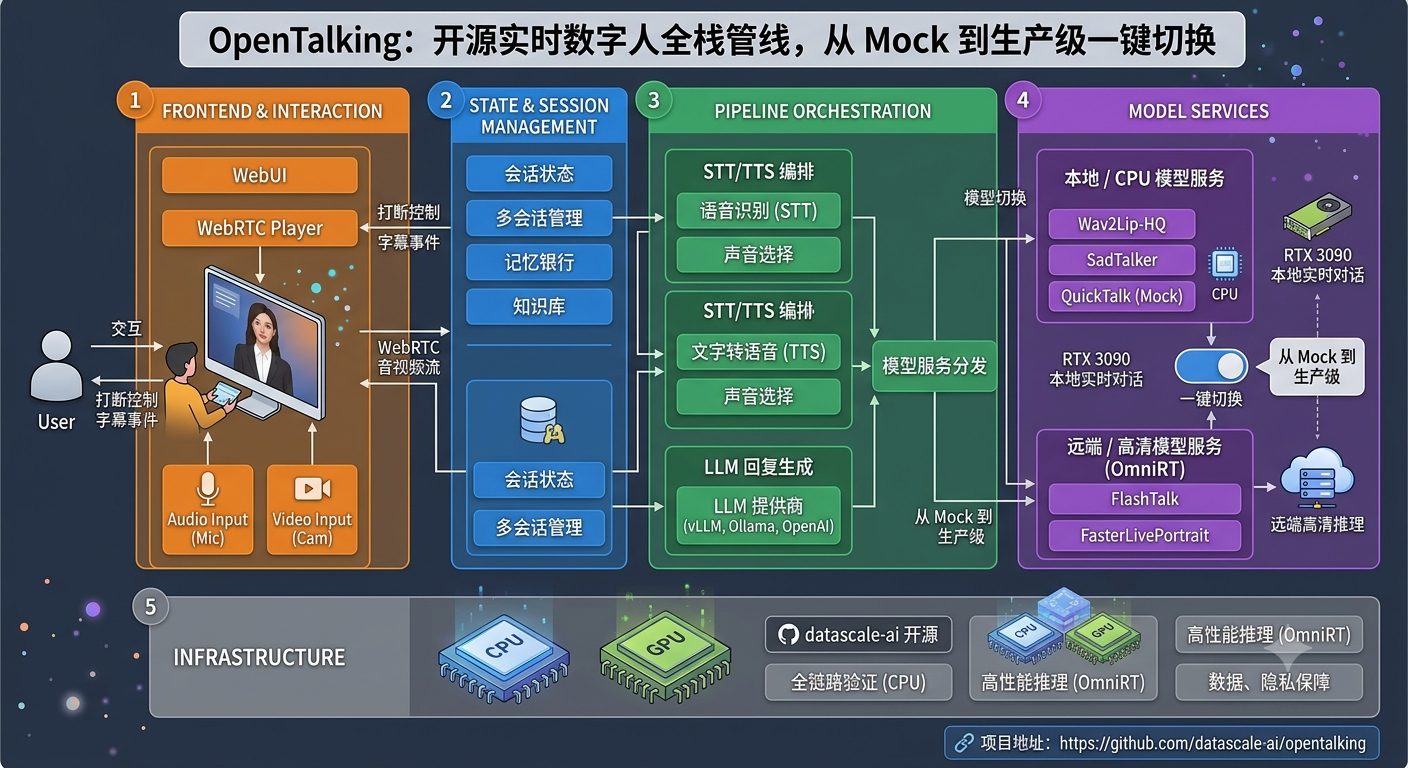
目录
- [1. 项目简介------它是什么?](#1. 项目简介——它是什么?)
- [2. 为什么 OpenTalking 是数字人生产级方案?](#2. 为什么 OpenTalking 是数字人生产级方案?)
- [3. 三大前端工作流](#3. 三大前端工作流)
- [4. 6 种部署路径------从 CPU 到分布式集群](#4. 6 种部署路径——从 CPU 到分布式集群)
- [5. 支持的 7 种数字人模型](#5. 支持的 7 种数字人模型)
- [6. 快速上手------两种方式跑起来](#6. 快速上手——两种方式跑起来)
- [7. 核心架构------编排层 + 合成后端](#7. 核心架构——编排层 + 合成后端)
- [8. 功能生态------不只是对话](#8. 功能生态——不只是对话)
- [9. 近期更新一览](#9. 近期更新一览)
- [10. 适用场景与优缺点](#10. 适用场景与优缺点)
- [11. 总结](#11. 总结)
1. 项目简介------它是什么?
OpenTalking 是 datascale-ai 开源的实时数字人对话编排框架 ,一句话概括:覆盖数字人产品全链路------前端交互、会话状态、LLM 回复、STT/TTS/声音选择、打断控制、字幕事件、WebRTC 音视频播放,以及可插拔的本地/远端模型服务。
它不是「只能跑一个模型」的实验项目------而是一个生产级数字人全栈方案:WebUI、角色/声音资产库、知识库、记忆、多会话状态、LLM/STT/TTS 提供商、WebRTC 播放、模型后端,全在一个项目里组织好。你可以从轻量 Mock 模式起步,接本地 QuickTalk/Wav2Lip,或用 OmniRT 跑 FlashTalk、FasterLivePortrait 等更高质量或更复杂的模型工作流。
🔗 项目地址:https://github.com/datascale-ai/opentalking
🔗 官网:https://www.opentalking.net
🔗 文档站:https://datascale-ai.github.io/opentalking/latest/en/
🔗 OmniRT:https://github.com/datascale-ai/omnirt
📜 License:Apache 2.0
2. 为什么 OpenTalking 是数字人生产级方案?
当前数字人开源项目大多是「单模型实验」------能跑 Wav2Lip 但没有完整产品链路,能做实时对话但没有知识库和记忆。OpenTalking 把整个数字人产品的全链路做成了开源:
| 能力 | OpenTalking | 典型开源数字人项目 |
|---|---|---|
| 🎬 实时对话全链路 | ✅ STT→LLM→TTS→数字人驱动→WebRTC | ❌ 通常只覆盖部分 |
| 🔌 可插拔模型后端 | ✅ mock/local/omnirt 3种后端 | ❌ 通常只绑一种模型 |
| 🧑 角色资产库 | ✅ 创建/选择角色、声音、场景 | ❌ 通常硬编码 |
| 📚 知识库 + 记忆 | ✅ LightRAG + mem0 + BM25 | ❌ 通常没有 |
| 🎤 语音克隆 | ✅ IndexTTS/CosyVoice/MiMo | ❌ 通常只支持一种 TTS |
| 📹 视频创作 + 克隆 | ✅ 音频/文本驱动创作 + 摄像头/上传视频克隆 | ❌ 通常只有对话 |
| 🌐 WebRTC 实时传输 | ✅ 流式音频/视频推送 | ❌ 通常用 WebSocket |
| 🐳 生产级部署 | ✅ Docker Compose + 分布式 | ❌ 通常只适合本地测试 |
3. 三大前端工作流
OpenTalking 支持三种核心前端场景:
A. 实时对话
| 场景 | 说明 |
|---|---|
| 🛒 电商直播 | 数字人主播带货,实时回答观众问题 |
| 💬 陪伴角色 | 数字人陪伴聊天,支持记忆和个性化 |
| 📰 新闻播报 | 数字人主播播报新闻,字幕同步 |
B. 视频创作
| 驱动方式 | 说明 |
|---|---|
| 🎵 音频驱动 | 上传一段音频,数字人跟着说话 |
| ✍️ 文本驱动 | 输入文本,自动生成 TTS + 数字人视频 |
| 🗣️ 克隆声音驱动 | 用克隆的声音驱动数字人说话 |
C. 视频克隆
| 方式 | 说明 |
|---|---|
| 📷 实时摄像头模仿 | 摄像头捕捉动作,数字人实时模仿 |
| 📁 上传视频模仿 | 上传一段视频,数字人模仿视频中的动作表情 |
4. 6 种部署路径------从 CPU 到分布式集群
| 路径 | 模型/后端 | 设备 | 适用场景 |
|---|---|---|---|
| 快速验证 | mock |
CPU / 无 GPU | 不下载模型权重,验证 API、LLM、TTS、WebRTC 全链路 |
| 入门验证 | quicktalk / wav2lip |
RTX 3050/3060/4060 | 真实视频渲染,演示和部署验证 |
| 消费级单机 | quicktalk / wav2lip / musetalk |
RTX 3090/4090 | 接近实时本地演示,轻量预生产 |
| 全本地私有 | sensevoice + local_cosyvoice + quicktalk |
RTX 3090/4090 | STT+TTS+数字人全部本地跑,零云端依赖 |
| 高清远端推理 | flashtalk / flashhead / fasterliveportrait + OmniRT |
多 GPU / 昇腾 910B2 / 远端 GPU | 多卡、GPU/NPU、生产隔离、更高视觉质量 |
| Docker/生产部署 | API + Web + Worker + 外部模型服务 | 单 GPU / 远端 GPU / 分布式集群 | 服务部署、远端 GPU、生产验证 |
💡 关键设计 :编排层(API/Worker/前端)和数字人合成后端(mock/local/omnirt)可以独立部署------前端和后端分离!
5. 支持的 7 种数字人模型
| 模型 | 输入 | 推荐后端 | 显存要求 |
|---|---|---|---|
mock |
参考图/静态帧 | mock |
无 GPU |
quicktalk |
模板视频 + 音频 | local |
RTX 3090/4090,约 3.8 GiB |
wav2lip |
参考图/帧 + 音频 | local / omnirt |
≥ 8 GB |
musetalk |
全帧 + 音频 | omnirt / local |
≥ 12 GB |
soulx-flashtalk-14b |
人像 + 音频 | omnirt |
多 GPU / NPU |
soulx-flashhead-1.3b |
人像 + 音频 | omnirt |
多 GPU / NPU |
fasterliveportrait |
人像/驱动视频/音频 | omnirt |
单 GPU 实时 |
QuickTalk 性能参考
| 模型 | 硬件 | 输入 | 输出 | 显存 | 帧率 |
|---|---|---|---|---|---|
quicktalk |
RTX 3090 | 模板视频+音频 | 720×900 / 25fps | ~3.8 GiB | ~35 fps |
📌 35fps 实时驱动------在消费级 GPU 上已经达到流畅对话的标准!
6. 快速上手------两种方式跑起来
方式一:Compshare 云镜像(最快体验)
不想配置环境?用 Compshare 预构建镜像一键体验:
- 镜像地址:https://www.compshare.cn/images/TdDwmKZUZebI
- 开放端口:
5173(WebUI) - 包含:OpenTalking + OmniRT + QuickTalk 运行环境 + 模型文件
部署实例后打开 5173 端口即可访问 WebUI。
方式二:自部署(从源码开始)
Step 1:克隆 + 环境
bash
git clone https://github.com/datascale-ai/opentalking.git
cd opentalking
uv sync --extra dev --python 3.11
source .venv/bin/activate
cp .env.example .envStep 2:配置 .env
至少配置一个 LLM。默认 TTS 可用免密钥的 edge 语音。LLM、STT、TTS 是独立提供商------参考 配置文档。
Step 3:Mock 模式启动
bash
bash scripts/start_unified.sh --mock默认前端 http://localhost:5173。自定义端口:
bash
bash scripts/start_unified.sh --mock --api-port 8210 --web-port 5280Step 4:切换真实模型
Mock 验证通过后,按你的硬件选路径:
bash
# 本地 QuickTalk:消费级 GPU 单机路径
export OPENTALKING_TORCH_DEVICE=cuda:0
export OPENTALKING_QUICKTALK_ASSET_ROOT="$PWD/models/quicktalk"
export OPENTALKING_QUICKTALK_WORKER_CACHE=1
bash scripts/start_unified.sh --backend local --model quicktalk --api-port 8210 --web-port 5280
# 远端 OmniRT / FlashTalk:高清或多卡路径
bash scripts/start_unified.sh \
--backend omnirt \
--model flashtalk \
--api-port 8210 \
--web-port 5280 \
--omnirt http://<gpu-server>:9000停止服务:
bash
bash scripts/quickstart/stop_all.sh7. 核心架构------编排层 + 合成后端
OpenTalking 的架构分为两大独立层:
┌──────────────── 编排层 ────────────────┐
│ React 18 前端(WebUI) │
│ FastAPI API 服务 │
│ Worker 进程(会话管理/消息路由) │
│ 知识库 / 记忆 / 资产库 │
└────────────────────────────────────────┘
↕
┌──────────────── 合成后端 ──────────────┐
│ mock → 静态帧,无 GPU │
│ local → 本地模型(QuickTalk等) │
│ omnirt → 远端推理服务 │
│ direct_ws → 直接 WebSocket 连接 │
└────────────────────────────────────────┘关键设计:
- 前后端分离:编排层和合成后端可以部署在不同机器上
- 可插拔后端 :
mock→local→omnirt三种后端无缝切换,不需要改前端代码 - 流式链路:LLM 回复 → TTS 流式合成 → 字幕事件 → WebRTC 音视频推送,全链路实时
- 打断控制:用户可以随时打断数字人说话,立刻切换到新的回复
- 多会话状态:支持同时运行多个数字人对话会话
8. 功能生态------不只是对话
OpenTalking 不仅是实时对话,还有完整的数字人产品功能矩阵:
🧑 角色与声音
| 功能 | 说明 |
|---|---|
| 角色资产库 | 创建/选择数字人角色,模板视频管理 |
| 声音库 | 多种 TTS 提供商,声音预览,声音标签 |
| 语音克隆 | IndexTTS / CosyVoice / MiMo 声音克隆 |
| 系统语音 | 免密钥 Edge 语音开箱即用 |
📚 知识与记忆
| 功能 | 说明 |
|---|---|
| LightRAG 知识库 | 文档检索,会话级知识选择 |
| Persona Package | 可复用的角色设定/知识素材/Prompt 包 |
| 角色记忆面板 | mem0 + BM25 + SQLite 三种记忆提供商 |
| 微信记忆导入 | 导入微信聊天记录构建角色人设 |
🎬 视频创作与克隆
| 功能 | 说明 |
|---|---|
| 音频驱动创作 | 上传音频 → 数字人视频 |
| 文本驱动创作 | 输入文本 → TTS + 数字人视频 |
| 克隆声音驱动 | 克隆的声音 + 数字人视频 |
| 摄像头实时模仿 | 实时驱动的数字人视频克隆 |
| 上传视频模仿 | 视频驱动的数字人克隆 |
| 沉浸式场景 | 场景资产 + 透明背景 + 视角切换 |
🔌 LLM / STT / TTS 提供商
| 类别 | 支持的提供商 |
|---|---|
| LLM | OpenAI 兼容接口 / DashScope / Atlas Cloud(300+模型) |
| STT | SenseVoice / 小米 MiMo / OpenAI 兼容 |
| TTS | Edge(免密钥)/ CosyVoice(本地 TRT)/ IndexTTS / MiMo / OpenAI 兼容 |
9. 近期更新一览
OpenTalking 迭代非常快,近一个月的更新密度令人印象深刻:
| 时间 | 更新 |
|---|---|
| 06-25 | ✅ 微信记忆导入 + 人设工作流;前端人设选择与驱动模型不再互斥 |
| 06-23 | ✅ 本地 CosyVoice TRT sidecar 部署(TensorRT/FP16 加速) |
| 06-22 | ✅ 运行时配置页面;mem0 运行时刷新;沉浸式场景资产管线 |
| 06-18/19 | ✅ 快速入门拆分(云镜像 + 自部署);LightRAG 运行时配置 |
| 06-12 | ✅ QuickTalk 本地资产修复 + Apple Silicon 支持 |
| 06-12 | ✅ IndexTTS 本地/OmniRT 提供商;系统语音 + 声音预览 |
| 06-02/10 | ✅ Persona Package API/CLI/WebUI;LightRAG 知识检索;角色记忆面板 |
| 06-05 | ✅ 资产库连接角色/知识/会话/Agent 上下文;音视频导出 |
| 06-05/06 | ✅ OpenAI 兼容 STT/TTS 适配器;小米 MiMo STT/TTS/声音克隆 |
10. 适用场景与优缺点
✅ 最适合谁?
| 人群 | 场景 |
|---|---|
| 🛒 电商运营 | 数字人直播带货,实时回答观众 |
| 🎮 游戏公司 | 数字人 NPC、游戏角色对话 |
| 📰 媒体/新闻 | 数字人新闻播报、字幕同步 |
| 🎓 教育/培训 | 数字人教师、培训场景 |
| 🏢 企业客服 | 数字人客服、知识库问答 |
| 🧪 AI 研究者 | 数字人模型验证、对比评测 |
| 🎬 内容创作者 | 音频/文本驱动视频创作、视频克隆 |
⚖️ 优缺点对比
| 优点 | 缺点 |
|---|---|
| 🟢 覆盖数字人产品全链路 | 🔴 项目较复杂,初学者上手门槛不低 |
| 🟢 mock 模式无 GPU 即可验证 | 🔴 mock 只用静态帧,体验不直观 |
| 🟢 7 种数字人模型可插拔切换 | 🔴 高质量模型(FlashTalk)需多 GPU |
| 🟢 知识库 + 记忆 + 人设体系完整 | 🔴 Agent 和工具调用仍在开发中 |
| 🟢 前后端分离,编排层和合成层独立部署 | 🔴 Windows/WSL2 一键部署尚未完成 |
| 🟢 Docker Compose + 分布式生产部署 | 🔴 消费级 GPU 多模型路径还在优化 |
| 🟢 Apple Silicon 支持(MPS/CPU) | 🔴 Apple Silicon 性能远低于 CUDA |
| 🟢 迭代速度极快(月内十余次更新) | 🔴 部分文档分散,需频繁查文档站 |
11. 总结
OpenTalking 是目前开源数字人领域最完整的生产级全栈方案。它不是一个模型实验------而是覆盖了数字人产品从 STT 到 WebRTC 的全链路,从角色资产库到知识库到记忆到多会话状态的全功能矩阵,从 Mock 到本地到远端 OmniRT 的全部署路径。
7 种数字人模型可插拔切换、3 种合成后端独立部署、6 种部署路径覆盖从 CPU 到分布式集群------这种灵活性在开源数字人项目中独一无二。加上 LightRAG 知识库、mem0 记忆、Persona Package 人设包、微信记忆导入这些产品级功能,OpenTalking 已经超越了「能跑模型」的阶段,进入了「能做产品」的阶段。
迭代速度也令人印象深刻------一个月内十余次功能更新,每次都是实际可用的功能而非概念。如果你要做数字人产品而非实验,OpenTalking 是当前开源领域最值得深入的项目。
推荐指数:⭐⭐⭐⭐⭐ (5/5)
数字人全链路 + 7 模型可插拔 + 知识库记忆 + 前后端分离 + 生产级部署------开源数字人领域的全能生产栈。
原文链接 :https://github.com/datascale-ai/opentalking
官网 :https://www.opentalking.net
文档站 :https://datascale-ai.github.io/opentalking/latest/en/
License:Apache 2.0
标签:#数字人 #OpenTalking #实时对话 #WebRTC #TTS #开源项目 #生产级部署 #知识库
分类:原创文章