****论文题目:****DIFFWAVE: A VERSATILE DIFFUSION MODEL FOR AUDIO SYNTHESIS(一种通用的音频合成扩散模型)
会议:ICLR2021
****摘要:****在这项工作中,我们提出了DiffWave,一个通用的扩散概率模型,用于有条件和无条件的波形生成。该模型是非自回归的,在合成时通过具有恒定步数的马尔可夫链将白噪声信号转换为结构化波形。通过优化数据似然度的变分界的一个变量来有效地训练该算法。DiffWave在不同的波形生成任务中生成高保真音频,包括以MEL谱图为条件的神经声码、类别条件生成和无条件生成。我们证明,DiffWave在语音质量方面与强大的WaveNet声码器相匹配(MOS:4.44比4.43),同时合成数量级更快。特别是,在各种自动和人工评估的音频质量和样本多样性方面,它在具有挑战性的无条件生成任务中的性能显著优于自回归和基于GAN的波形模型。
DiffWave:一个用于音频合成的通用扩散概率模型
一、背景与问题
深度生成模型在语音合成与音乐生成领域已经取得了令人瞩目的成果,但现有方法均存在各自难以克服的局限。
1.1 自回归模型:质量高,速度慢
WaveNet、WaveRNN 等自回归模型通过逐样本顺序生成的方式,能够捕捉波形中极为精细的细节,音质出众。然而,其本质上的串行结构导致推理速度极慢------以 WaveNet 为例,在没有专门工程优化内核的情况下,其合成速度比实时慢约 500 倍,根本无法在生产环境中直接部署。
1.2 并行模型:快了,但有代价
为了解决速度问题,研究者尝试了多种并行化方案:
- Flow-based 模型(WaveGlow、WaveFlow):可并行生成,但要求网络在潜变量和数据之间维持严格的双射(bijection)结构,带来强烈的架构约束,参数量庞大(WaveGlow 高达 87.88M 参数)。
- 蒸馏模型(Parallel WaveNet、ClariNet):需要额外的教师模型辅助训练,增加了系统复杂度。
- GAN/VAE 类模型:存在训练不稳定、模式崩溃(mode collapse)或后验崩溃(posterior collapse)等问题,且往往依赖额外的辅助损失函数(如频谱损失)才能保证音频质量。
1.3 无条件生成:一个被忽视的难题
更棘手的挑战来自无条件波形生成 。在没有任何条件信息(如 mel 谱图)的情况下,模型需要独立地生成完整的语音------例如,1 秒的 16kHz 音频意味着需要自主生成 16,000 个连续时间步。
现有模型在这一任务上表现不佳:WaveNet 倾向于生成"伪单词"般含混的声音,WaveGAN 的生成质量和多样性也十分有限。根本原因在于,缺少条件信息时模型很难管控如此长序列中的全局一致性。
二、DiffWave:核心思路
针对上述问题,论文提出了 DiffWave------一个基于扩散概率模型(Diffusion Probabilistic Model, DDPM)的通用音频波形生成框架。
2.1 扩散模型基础
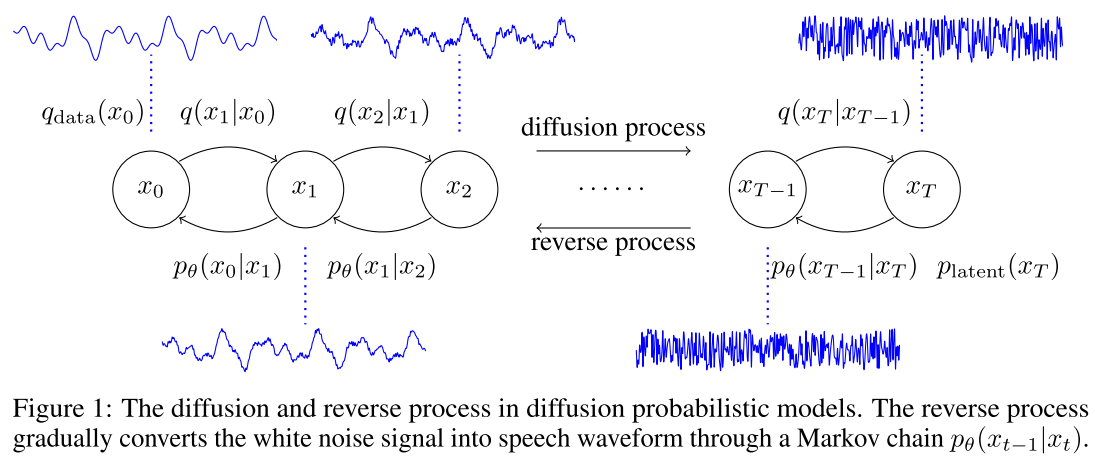
扩散模型由前向扩散过程 和反向去噪过程 两部分组成(见图 1:论文 Figure 1,扩散与反向过程示意图)。
前向扩散过程 是一条固定的马尔可夫链,逐步向真实音频数据 中添加高斯噪声,最终得到近似标准正态分布的白噪声
:
其中 是预先设定的噪声方差调度(variance schedule),整个过程无需学习参数。
反向去噪过程 则是由神经网络参数化的马尔可夫链,从白噪声 出发,逐步"去噪",最终恢复出结构化的波形
:
训练目标 借助 Ho et al.(2020)提出的参数化方案,将变分下界(ELBO)转化为封闭形式,最终简化为训练一个噪声预测网络 ,使其在任意扩散步 t 都能准确预测被添加的高斯噪声:
这一目标函数形式简洁,不需要任何辅助损失,避免了 GAN/VAE 的联合训练难题。
2.2 DiffWave 网络架构
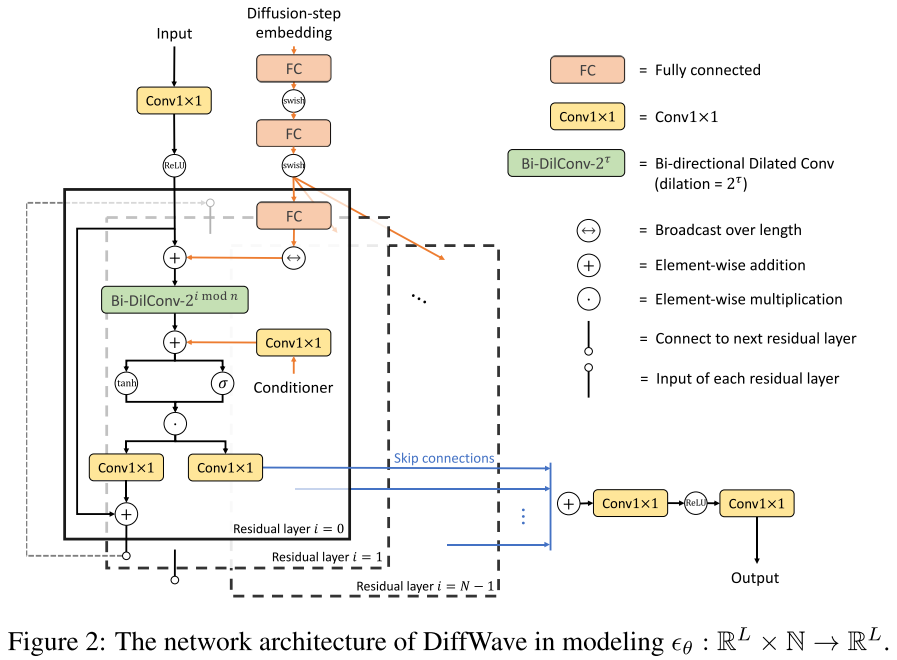
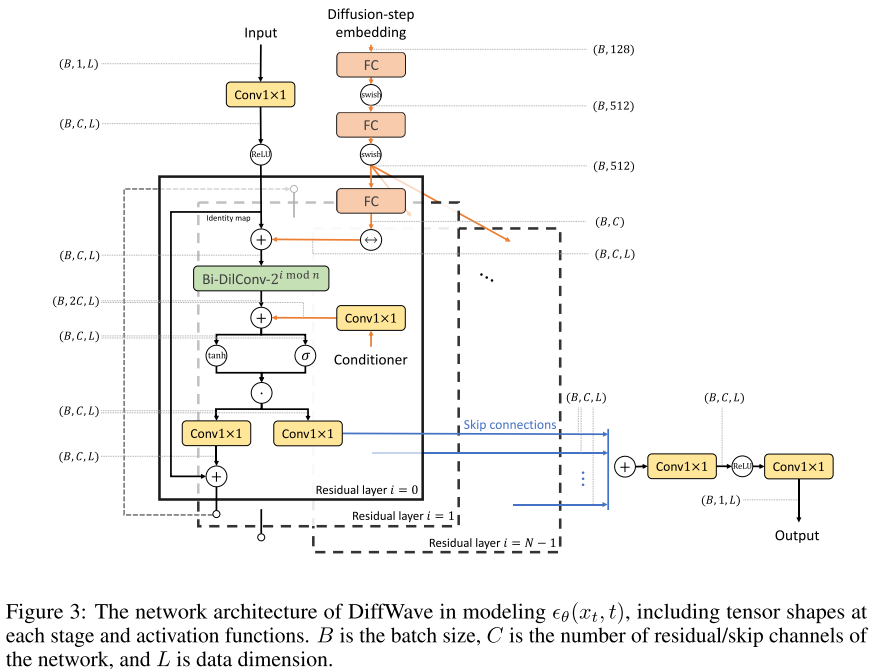
DiffWave 的网络架构如图 2所示(论文 Figure 2 / Figure 3,网络结构图)。整体是一个由 N 个残差层堆叠而成的前馈网络,其设计要点如下:
(1)双向膨胀卷积(Bi-DilConv)
由于没有自回归生成约束,DiffWave 采用双向 膨胀卷积(而非 WaveNet 使用的因果卷积),卷积核大小为 3,每个 block 内膨胀率按 递增。实验也证实,使用因果卷积会明显降低音频质量。
(2)扩散步嵌入(Diffusion-step Embedding)
模型需要知道当前处于哪个扩散步 t,从而输出对应的噪声预测。DiffWave 使用 128 维的正弦/余弦位置编码,并通过三层全连接(FC)层将其映射为每个残差层的偏置向量,广播后逐层注入。
(3)条件注入机制
- 局部条件(mel 谱图):通过转置 2D 卷积对齐到波形长度,再通过逐层 Conv1×1 映射为 2C 通道,作为偏置加入每个残差层的膨胀卷积之中。
- 全局条件(类别标签/说话人 ID):使用 128 维共享嵌入,通过逐层 Conv1×1 注入各残差层。
(4)无条件生成中的感受野扩增
DiffWave 在无条件生成中有一个天然优势:通过 T 次反向过程迭代,网络对 的有效感受野最大可达
(其中 r 为单次前向传播的感受野大小),从而轻松覆盖整条语音序列,避免了 WaveNet 在长序列上的全局一致性问题。
2.3 快速采样算法
训练时通常使用 步扩散,但推理时大部分有效去噪发生在 t 接近 0 的阶段。受此启发,论文提出了快速采样算法(Algorithm 3):

在推理时使用一个独立的、步数更少的方差调度(),通过噪声水平对齐公式将训练步骤与推理步骤对应起来,从而将 200 步的反向过程"折叠"为仅 6 步,无需重新训练模型,只需复用训练好的检查点即可。
三、实验与结果
3.1 神经声码器任务
数据集:LJ Speech(约 24 小时,22.05 kHz,单说话人,13,100 条语音)
对比基线:WaveNet(4.57M)、ClariNet(2.17M)、WaveGlow(87.88M)、WaveFlow(5.91M / 22.25M)
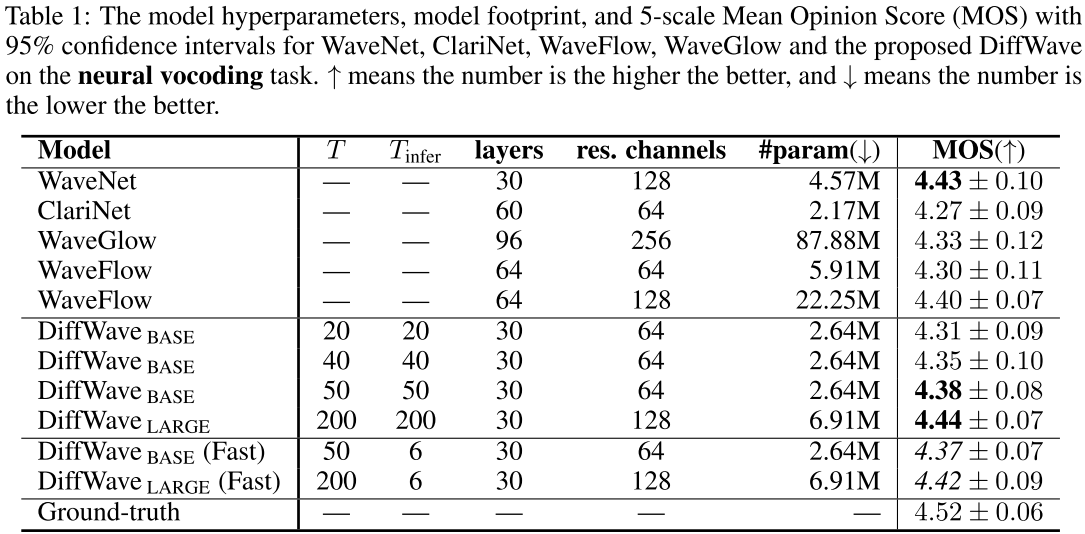
📊 此处配表 :论文 Table 1(模型超参数、参数量与 MOS 评分对比)
主要结论如下:
- DiffWave LARGE (6.91M 参数,T=200)MOS 达到 4.44 ,与 WaveNet(MOS 4.43)持平,但合成速度快数个数量级;WaveNet 无优化内核时比实时慢约 500 倍,而 DiffWave BASE(T=20)在 FP32 下已达实时速度的 2.1 倍。
- DiffWave BASE (2.64M 参数)是 WaveGlow 参数量的 1/33,MOS(4.31~4.38)仍优于 WaveGlow(4.33)。
- DiffWave BASE(Fast,
) MOS 为 4.37 ,合成速度比实时快 5.6 倍(V100 GPU,FP32,无专用内核),在极低延迟下仍保持高保真音质。
- DiffWave LARGE(Fast)比实时快 3.5 倍,MOS 4.42,与全步推理几乎无差别(4.44)。
- 当前 DiffWave 仍慢于 Flow-based 模型(如 5.91M WaveFlow 在 FP16 下比实时快 40 倍以上),但参数量更小、音质更好,作者预计未来通过推理优化可进一步提速。
3.2 无条件生成任务
数据集:SC09(Speech Commands 数据集中的说话数字 0~9 子集,31,158 条训练语音,2,032 位说话人,每条 1 秒,16kHz)
评估指标:
- FID(Fréchet Inception Distance):越低越好,综合衡量质量与多样性
- IS(Inception Score):越高越好,衡量质量与多样性
- mIS(Modified Inception Score):越高越好,额外衡量类内多样性
- AM Score:越低越好,考虑真实数据标签分布
- NDB/K(Number of Statistically-Different Bins):越低越好,衡量生成分布覆盖度
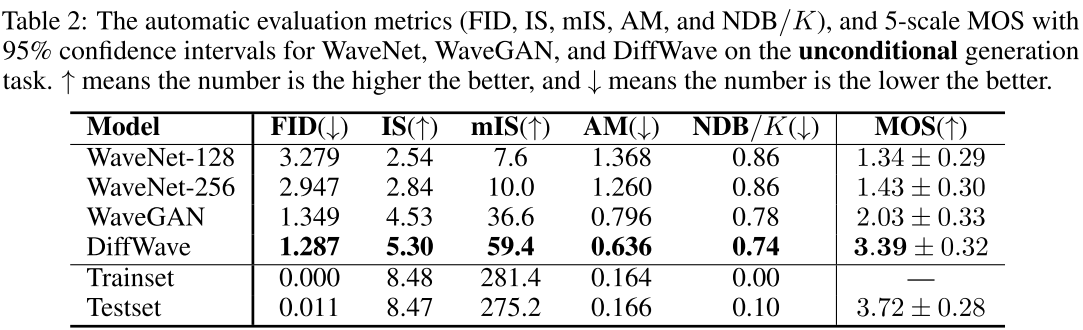
📊 此处配表 :论文 Table 2(无条件生成任务自动评估与 MOS 对比)
主要结论如下:
- MOS :DiffWave 3.39,远超 WaveGAN(2.03)和 WaveNet-256(1.43);测试集 ground truth 为 3.72。
- FID :DiffWave 1.287,优于 WaveGAN(1.349)和 WaveNet-256(2.947)。
- IS / mIS :DiffWave 5.30 / 59.4,均为最优;WaveGAN 为 4.53 / 36.6,WaveNet-256 仅 2.84 / 10.0。
- 所有自动评估指标上,DiffWave 均排名第一,在质量、多样性和分布覆盖三个维度全面领先。
3.3 类别条件生成任务
任务设定:在 3.2 相同的 SC09 数据集上,向模型提供数字类别标签(0~9)作为全局条件。
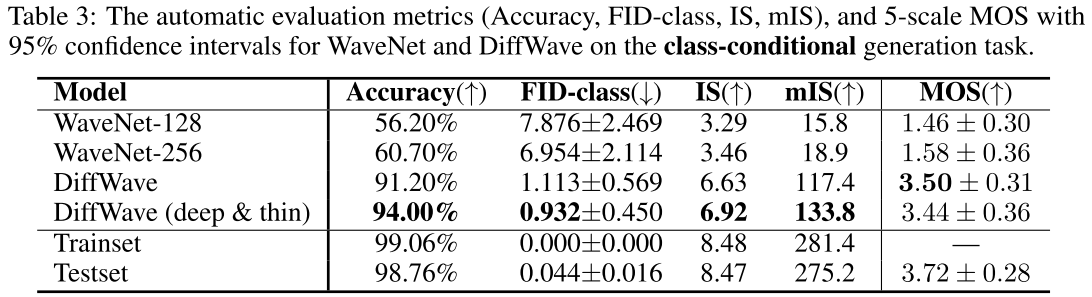
📊 此处配表 :论文 Table 3(类别条件生成自动评估与 MOS 对比)
主要结论如下:
- 分类准确率 :DiffWave 91.2% ,WaveNet-256 仅 60.7%,差距悬殊;DiffWave(深而细)版本(C=128,48层)进一步达到 94.0%。
- FID-class :DiffWave 1.113 ,WaveNet-256 为 6.954,约为后者的 1/6。
- MOS :DiffWave 3.50 ,WaveNet-256 仅 1.58;DiffWave 与真实数据(3.72)的 MOS 差距,仅为 WaveNet 与真实数据差距的约 10%。
- 与无条件生成相比,加入类别标签后,WaveNet 和 DiffWave 的 IS 均提升超过 20%,mIS 几乎翻倍,MOS 至少提升 0.11,说明条件信息确实有效降低了生成任务的难度。
3.4 其他能力展示
零样本语音去噪:直接使用无条件 DiffWave 对加入了白噪声、粉噪声、流水声等六种噪声(噪声比例 10%)的测试语音进行去噪,模型在训练时从未接触过任何真实噪声类型,但仍能有效恢复原始语音,说明 DiffWave 习得了扎实的语音先验。
潜空间插值:在类别条件模型中,可以在两个说话人的潜变量(t=50 步对应的 x_t)之间做线性插值,生成声音在两种风格之间平滑过渡的语音,展现了模型对说话人特征的连续建模能力。
四、为什么 DiffWave 在无条件生成上表现更好?
这是本文最重要的洞察之一。
传统精确似然模型(如 WaveNet)在训练时被迫对数据分布的每一个细节建模,当缺少条件信息时,模型容量被大量"浪费"在模拟各种细节变化上,容易出现偏差较大的样本。
DiffWave 最大化的是似然的变分下界(ELBO),而非精确似然。这使其能够集中精力捕捉数据分布中最主要的变化模式,对次要细节有一定"容忍度",从而在有限模型容量下反而能生成更自然、更多样的样本。
相较于 GAN 和 VAE 类模型,扩散模型的训练只涉及单一网络,彻底避免了两网络联合训练带来的模式崩溃和后验崩溃问题,训练更加稳定。
五、DiffWave 的局限与未来方向
作者在结论中坦承,DiffWave 目前仍慢于 Flow-based 模型(尽管参数量更小),这是在生产 TTS 系统中部署的主要障碍。论文指出了若干未来方向:
- 更长语音生成:DiffWave 的有效感受野理论上可以随 T 线性增长,有潜力生成更长的语音片段。
- 进一步提速:最有效的去噪步发生在 t 接近 0 的区域,暗示可以将 T_\\text{infer} 压缩得更小;此外,网络参数 \\theta 在各反向步之间共享,适合使用 GPU 上的"持久内核"(persistent kernels)大幅加速推理。
- 架构优化:与 Flow-based 模型不同,DiffWave 不受双射约束,架构设计空间更自由,后续优化潜力大。
六、总结
DiffWave 的贡献可以概括为以下几点:
- 首次将扩散概率模型成功应用于原始音频波形的通用生成,兼顾有条件(声码器)与无条件生成。
- 非自回归架构,并行合成,以极少的参数量(2.64M)实现超实时合成,且音质逼近 WaveNet。
- 单一 ELBO 训练目标,训练简洁稳定,无需辅助损失或对抗训练。
- 在无条件和类别条件生成任务上全面超越 WaveNet 和 WaveGAN,MOS 从 1.43/2.03 大幅提升至 3.39。
- 快速采样算法将推理步数从 200 压缩至 6,音质几乎无损。
DiffWave 证明了扩散模型不仅适用于图像生成,同样是音频领域强有力的生成框架,为后续大量语音扩散模型(如 WaveGrad、Grad-TTS、DiffSinger 等)奠定了重要基础。