设输入空间为 X ⊆ R M \mathcal{X} \subseteq \mathbb{R}^M X⊆RM,每个样本 x i ∈ X x_i \in \mathcal{X} xi∈X 是一个 M M M 维向量。无监督学习的目标是发现数据内部的结构,输出空间 Z \mathcal{Z} Z 取决于具体任务:
对于聚类 : Z = { 1 , 2 , ... , K } \mathcal{Z} = \{1, 2, \dots, K\} Z={1,2,...,K},表示 K K K 个类别标签
对于降维 : Z ⊆ R d \mathcal{Z} \subseteq \mathbb{R}^d Z⊆Rd,其中 d < M d < M d<M
对于概率估计 : Z \mathcal{Z} Z 是概率分布的参数空间
无监督学习的假设空间 H \mathcal{H} H 可以表示为:
H = { h : X → Z } \mathcal{H} = \{h: \mathcal{X} \to \mathcal{Z}\} H={h:X→Z}
其中 h h h 是某个映射函数。与监督学习不同,这里的"正确"映射没有标准答案,模型需要在没有任何外部指导的情况下,从数据本身的结构中选择一个合理的映射。
1.2 模型的两种形式
无监督学习的模型通常有两种表达形式:
形式一:函数模型
直接用一个函数 z = g ( x ) z = g(x) z=g(x) 表示从输入到输出的映射。例如:
在 K K K-means 聚类中: g ( x ) = arg min k ∥ x − μ k ∥ 2 g(x) = \arg\min_{k} \|x - \mu_k\|^2 g(x)=argmink∥x−μk∥2,将样本分配到最近的簇中心
在 PCA 降维中: z = W T x z = W^T x z=WTx,其中 W W W 是投影矩阵, z z z 是低维表示
形式二:概率模型
用一个条件概率分布 P ( z ∣ x ) P(z|x) P(z∣x) 来描述给定输入 x x x 时输出 z z z 的分布。更一般地,还可以假设数据是由某个含隐变量的概率模型生成的:
P ( x ) = ∑ z P ( x ∣ z ) P ( z ) P(x) = \sum_{z} P(x|z)P(z) P(x)=z∑P(x∣z)P(z)
或者连续形式:
P ( x ) = ∫ P ( x ∣ z ) P ( z ) d z P(x) = \int P(x|z)P(z) dz P(x)=∫P(x∣z)P(z)dz
其中 z z z 是隐变量,代表数据中隐藏的结构(如类别、低维坐标等)。学习的目标是估计模型参数 θ \theta θ,使得观测数据 U U U 的出现概率最大:
θ ^ = arg max θ ∏ i = 1 N P ( x i ; θ ) \hat{\theta} = \arg\max_{\theta} \prod_{i=1}^{N} P(x_i; \theta) θ^=argθmaxi=1∏NP(xi;θ)
这也就是极大似然估计的思想。高斯混合模型(GMM)就是这类方法的典型代表。
1.3 数据矩阵表示
训练数据 U U U 通常表示为一个 M × N M \times N M×N 的矩阵( M M M 维特征, N N N 个样本):
X = x 11 x 12 ⋯ x 1 N x 21 x 22 ⋯ x 2 N ⋮ ⋮ ⋱ ⋮ x M 1 x M 2 ⋯ x M N X = \begin{bmatrix} x_{11} & x_{12} & \cdots & x_{1N} \\ x_{21} & x_{22} & \cdots & x_{2N} \\ \vdots & \vdots & \ddots & \vdots \\ x_{M1} & x_{M2} & \cdots & x_{MN} \end{bmatrix} X= x11x21⋮xM1x12x22⋮xM2⋯⋯⋱⋯x1Nx2N⋮xMN
其中 x i j x_{ij} xij 表示第 j j j 个样本的第 i i i 个特征值, i = 1 , ... , M i = 1,\dots,M i=1,...,M, j = 1 , ... , N j = 1,\dots,N j=1,...,N。每一列是一个样本,每一行是一个特征维度。
无监督学习的核心任务,就是对这个矩阵的"压缩":
纵向压缩(行方向):对样本(列)进行聚类,使相似的列归为一组
横向压缩(列方向) :对特征(行)进行降维,减少行数 M M M,保留主要信息
双向压缩:同时进行纵向和横向的压缩,寻找数据的低维结构
1.4 目标:最小化压缩损失
无监督学习可以被统一理解为:寻找一个压缩映射 h : X → Z h: \mathcal{X} \to \mathcal{Z} h:X→Z,使得压缩后的表示尽可能保留原始数据的信息。这等价于最小化某个损失函数 L L L:
min h ∈ H L ( X , h ( X ) ) \min_{h \in \mathcal{H}} L(X, h(X)) h∈HminL(X,h(X))
设两个样本 x i = ( x i 1 , x i 2 , ... , x i M ) ⊤ x_i = (x_{i1}, x_{i2}, \dots, x_{iM})^\top xi=(xi1,xi2,...,xiM)⊤ 和 x j = ( x j 1 , x j 2 , ... , x j M ) ⊤ x_j = (x_{j1}, x_{j2}, \dots, x_{jM})^\top xj=(xj1,xj2,...,xjM)⊤, M M M 为特征维度。
1. 闵可夫斯基距离(Minkowski Distance)
d i j = ( ∑ k = 1 M ∣ x i k − x j k ∣ p ) 1 p d_{ij} = \left( \sum_{k=1}^{M} |x_{ik} - x_{jk}|^p \right)^{\frac{1}{p}} dij=(k=1∑M∣xik−xjk∣p)p1
当 p = 1 p=1 p=1 时,为曼哈顿距离 (Manhattan Distance): d i j = ∑ k = 1 M ∣ x i k − x j k ∣ d_{ij} = \sum_{k=1}^{M} |x_{ik} - x_{jk}| dij=k=1∑M∣xik−xjk∣
当 p = 2 p=2 p=2 时,为欧氏距离 (Euclidean Distance): d i j = ∑ k = 1 M ( x i k − x j k ) 2 d_{ij} = \sqrt{\sum_{k=1}^{M} (x_{ik} - x_{jk})^2} dij=k=1∑M(xik−xjk)2
当 p = ∞ p=\infty p=∞ 时,为切比雪夫距离 (Chebyshev Distance): d i j = max k ∣ x i k − x j k ∣ d_{ij} = \max_k |x_{ik} - x_{jk}| dij=kmax∣xik−xjk∣
s i j = x i ⋅ x j ∥ x i ∥ ∥ x j ∥ = ∑ k = 1 M x i k x j k ∑ k = 1 M x i k 2 ∑ k = 1 M x j k 2 s_{ij} = \frac{x_i \cdot x_j}{\|x_i\| \|x_j\|} = \frac{\sum_{k=1}^{M} x_{ik} x_{jk}}{\sqrt{\sum_{k=1}^{M} x_{ik}^2} \sqrt{\sum_{k=1}^{M} x_{jk}^2}} sij=∥xi∥∥xj∥xi⋅xj=∑k=1Mxik2 ∑k=1Mxjk2 ∑k=1Mxikxjk
取值范围为 − 1 , 1 -1, 1−1,1,值越大表示越相似。对应的距离为 d i j = 1 − s i j d_{ij} = 1 - s_{ij} dij=1−sij。常用于文本数据(词频向量)。
ρ i j = ∑ k = 1 M ( x i k − x ˉ i ) ( x j k − x ˉ j ) ∑ k = 1 M ( x i k − x ˉ i ) 2 ∑ k = 1 M ( x j k − x ˉ j ) 2 \rho_{ij} = \frac{\sum_{k=1}^{M} (x_{ik} - \bar{x}i)(x{jk} - \bar{x}j)}{\sqrt{\sum{k=1}^{M} (x_{ik} - \bar{x}i)^2} \sqrt{\sum{k=1}^{M} (x_{jk} - \bar{x}_j)^2}} ρij=∑k=1M(xik−xˉi)2 ∑k=1M(xjk−xˉj)2 ∑k=1M(xik−xˉi)(xjk−xˉj)
其中 x ˉ i = 1 M ∑ k = 1 M x i k \bar{x}i = \frac{1}{M} \sum{k=1}^{M} x_{ik} xˉi=M1∑k=1Mxik。相关距离为 d i j = 1 − ρ i j d_{ij} = 1 - \rho_{ij} dij=1−ρij。
在层次聚类等算法中,需要计算两个簇之间的距离。设 C p C_p Cp 和 C q C_q Cq 为两个簇, n p = ∣ C p ∣ n_p = |C_p| np=∣Cp∣, n q = ∣ C q ∣ n_q = |C_q| nq=∣Cq∣, d i j d_{ij} dij 为样本 x i x_i xi 与 x j x_j xj 之间的距离, μ p \mu_p μp 和 μ q \mu_q μq 分别为两个簇的质心(均值向量)。
1. 最短距离(Single Linkage)
D min ( C p , C q ) = min i ∈ C p , j ∈ C q d i j D_{\min}(C_p, C_q) = \min_{i \in C_p, j \in C_q} d_{ij} Dmin(Cp,Cq)=i∈Cp,j∈Cqmindij
计算方法 :遍历 C p C_p Cp 和 C q C_q Cq 中所有样本对,找到距离最小的那一对,以其距离作为簇间距离。
举例 : C p C_p Cp 中的点 { 0 , 10 } \{0, 10\} {0,10}, C q C_q Cq 中的点 { 9 , 20 } \{9, 20\} {9,20}。最近的一对是 10 10 10 和 9 9 9,距离为 1 1 1,所以 D min = 1 D_{\min}=1 Dmin=1。
特点:容易产生链状的簇,对噪声敏感(一个离群点就能把两个簇连起来)。
2. 最长距离(Complete Linkage)
D max ( C p , C q ) = max i ∈ C p , j ∈ C q d i j D_{\max}(C_p, C_q) = \max_{i \in C_p, j \in C_q} d_{ij} Dmax(Cp,Cq)=i∈Cp,j∈Cqmaxdij
计算方法 :遍历 C p C_p Cp 和 C q C_q Cq 中所有样本对,找到距离最大的那一对,以其距离作为簇间距离。
直观理解:两个簇之间的距离由它们"离得最远的两个点"决定。只有两个簇整体都靠近,才会被认为近。
举例 : C p C_p Cp 中的点 { 0 , 10 } \{0, 10\} {0,10}, C q C_q Cq 中的点 { 9 , 20 } \{9, 20\} {9,20}。最远的一对是 0 0 0 和 20 20 20,距离为 20 20 20,所以 D max = 20 D_{\max}=20 Dmax=20。
特点:倾向于产生紧凑的球状簇,对噪声不敏感(离群点只影响局部,不影响最远距离)。
3. 中心距离(Centroid Linkage)
D cent ( C p , C q ) = ∥ μ p − μ q ∥ D_{\text{cent}}(C_p, C_q) = \|\mu_p - \mu_q\| Dcent(Cp,Cq)=∥μp−μq∥
其中 μ p = 1 n p ∑ i ∈ C p x i \mu_p = \frac{1}{n_p} \sum_{i \in C_p} x_i μp=np1∑i∈Cpxi, μ q = 1 n q ∑ i ∈ C q x i \mu_q = \frac{1}{n_q} \sum_{i \in C_q} x_i μq=nq1∑i∈Cqxi。
特点 :计算速度快(只需 O ( d ) O(d) O(d) 时间),但可能出现"逆序"现象------合并后的新簇与另一个簇的距离反而比合并前更小,导致树状图出现交叉。
4. 平均距离(Average Linkage)
D avg ( C p , C q ) = 1 n p n q ∑ i ∈ C p ∑ j ∈ C q d i j D_{\text{avg}}(C_p, C_q) = \frac{1}{n_p n_q} \sum_{i \in C_p} \sum_{j \in C_q} d_{ij} Davg(Cp,Cq)=npnq1i∈Cp∑j∈Cq∑dij
计算方法 :计算 C p C_p Cp 和 C q C_q Cq 之间所有样本对的距离,然后取平均值。
矩阵的读法:第 i i i 行第 j j j 列的值 d i j d_{ij} dij 就是 x i x_i xi 与 x j x_j xj 的距离。例如 d 13 = 2 d_{13}=2 d13=2 表示 x 1 x_1 x1 与 x 3 x_3 x3 的距离为 2, d 35 = 1 d_{35}=1 d35=1 表示 x 3 x_3 x3 与 x 5 x_5 x5 的距离为 1。
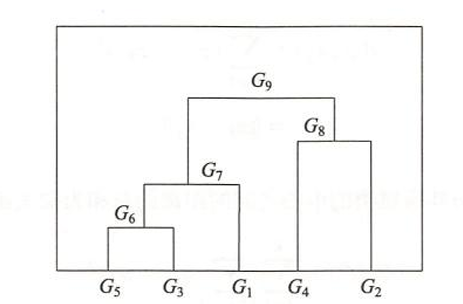
用最短距离(单链接)做聚合聚类。
最短距离的定义:两个类 A A A 和 B B B 的距离等于它们笛卡尔积 A × B A \times B A×B 中所有点对距离的最小值。
第 1 步:初始状态
5 个类: G 1 = { x 1 } , G 2 = { x 2 } , G 3 = { x 3 } , G 4 = { x 4 } , G 5 = { x 5 } G_1=\{x_1\}, G_2=\{x_2\}, G_3=\{x_3\}, G_4=\{x_4\}, G_5=\{x_5\} G1={x1},G2={x2},G3={x3},G4={x4},G5={x5}
找最小距离: min = 2 \min = 2 min=2,位于 G 1 G_1 G1 与 G 6 G_6 G6。
合并 G 1 G_1 G1 和 G 6 G_6 G6 为新类 G 7 = { x 1 , x 3 , x 5 } G_7 = \{x_1, x_3, x_5\} G7={x1,x3,x5}。
第 3 步:再次更新
计算 G 7 G_7 G7 与其他类的距离。
G 7 G_7 G7 与 G 2 G_2 G2 的笛卡尔积: G 7 × G 2 = { ( x 1 , x 2 ) , ( x 3 , x 2 ) , ( x 5 , x 2 ) } G_7 \times G_2 = \{(x_1, x_2), (x_3, x_2), (x_5, x_2)\} G7×G2={(x1,x2),(x3,x2),(x5,x2)}
D ( G 7 , G 2 ) = min ( d 12 , d 32 , d 52 ) = min ( 7 , 5 , 6 ) = 5 D(G_7, G_2) = \min(d_{12}, d_{32}, d_{52}) = \min(7, 5, 6) = 5 D(G7,G2)=min(d12,d32,d52)=min(7,5,6)=5
G 7 G_7 G7 与 G 4 G_4 G4 的笛卡尔积: G 7 × G 4 = { ( x 1 , x 4 ) , ( x 3 , x 4 ) , ( x 5 , x 4 ) } G_7 \times G_4 = \{(x_1, x_4), (x_3, x_4), (x_5, x_4)\} G7×G4={(x1,x4),(x3,x4),(x5,x4)}
D ( G 7 , G 4 ) = min ( d 14 , d 34 , d 54 ) = min ( 9 , 8 , 5 ) = 5 D(G_7, G_4) = \min(d_{14}, d_{34}, d_{54}) = \min(9, 8, 5) = 5 D(G7,G4)=min(d14,d34,d54)=min(9,8,5)=5
D ( G 2 , G 4 ) = 4 D(G_2, G_4)=4 D(G2,G4)=4 不变。
更新后的距离矩阵(顺序: G 2 , G 4 , G 7 G_2, G_4, G_7 G2,G4,G7):
G 2 G 4 G 7 G 2 0 4 5 G 4 4 0 5 G 7 5 5 0 \begin{array}{c|ccc} & G_2 & G_4 & G_7 \\ \hline G_2 & 0 & 4 & 5 \\ G_4 & 4 & 0 & 5 \\ G_7 & 5 & 5 & 0 \end{array} G2G4G7G2045G4405G7550
找最小距离: min = 4 \min = 4 min=4,位于 G 2 G_2 G2 与 G 4 G_4 G4。
合并 G 2 G_2 G2 和 G 4 G_4 G4 为新类 G 8 = { x 2 , x 4 } G_8 = \{x_2, x_4\} G8={x2,x4}。
第 4 步:最后合并
计算 G 7 G_7 G7 与 G 8 G_8 G8 的距离。
G 7 G_7 G7 与 G 8 G_8 G8 的笛卡尔积: G 7 × G 8 = { ( x 1 , x 2 ) , ( x 1 , x 4 ) , ( x 3 , x 2 ) , ( x 3 , x 4 ) , ( x 5 , x 2 ) , ( x 5 , x 4 ) } G_7 \times G_8 = \{(x_1, x_2), (x_1, x_4), (x_3, x_2), (x_3, x_4), (x_5, x_2), (x_5, x_4)\} G7×G8={(x1,x2),(x1,x4),(x3,x2),(x3,x4),(x5,x2),(x5,x4)},共 3 × 2 = 6 3 \times 2 = 6 3×2=6 个点对。
点对
距离
( x 1 , x 2 ) (x_1, x_2) (x1,x2)
7
( x 1 , x 4 ) (x_1, x_4) (x1,x4)
9
( x 3 , x 2 ) (x_3, x_2) (x3,x2)
5
( x 3 , x 4 ) (x_3, x_4) (x3,x4)
8
( x 5 , x 2 ) (x_5, x_2) (x5,x2)
6
( x 5 , x 4 ) (x_5, x_4) (x5,x4)
5
D ( G 7 , G 8 ) = min ( 7 , 9 , 5 , 8 , 6 , 5 ) = 5 D(G_7, G_8) = \min(7, 9, 5, 8, 6, 5) = 5 D(G7,G8)=min(7,9,5,8,6,5)=5
合并 G 7 G_7 G7 和 G 8 G_8 G8 为 G 9 = { x 1 , x 2 , x 3 , x 4 , x 5 } G_9 = \{x_1, x_2, x_3, x_4, x_5\} G9={x1,x2,x3,x4,x5},结束。
合并过程汇总
步骤
合并的类
距离
新类
包含的样本
1
G 3 G_3 G3 与 G 5 G_5 G5
1
G 6 G_6 G6
{ x 3 , x 5 } \{x_3, x_5\} {x3,x5}
2
G 1 G_1 G1 与 G 6 G_6 G6
2
G 7 G_7 G7
{ x 1 , x 3 , x 5 } \{x_1, x_3, x_5\} {x1,x3,x5}
3
G 2 G_2 G2 与 G 4 G_4 G4
4
G 8 G_8 G8
{ x 2 , x 4 } \{x_2, x_4\} {x2,x4}
4
G 7 G_7 G7 与 G 8 G_8 G8
5
G 9 G_9 G9
{ x 1 , x 2 , x 3 , x 4 , x 5 } \{x_1, x_2, x_3, x_4, x_5\} {x1,x2,x3,x4,x5}
关键点
笛卡尔积 :两个类 A A A 和 B B B 的所有点对 = A × B = { ( a , b ) ∣ a ∈ A , b ∈ B } A \times B = \{(a, b) \mid a \in A, b \in B\} A×B={(a,b)∣a∈A,b∈B},共 ∣ A ∣ × ∣ B ∣ |A| \times |B| ∣A∣×∣B∣ 个
最短距离 = 笛卡尔积中所有点对距离的最小值
每次合并最小的:每一步都找当前距离矩阵中的最小值
矩阵不断缩小:每合并一次,类数减 1
2.3 K均值聚类
K均值聚类(K-Means Clustering)是一种基于中心的聚类算法。它将样本划分为 K K K 个簇,每个簇由其质心(均值)代表,样本被分配到离它最近的质心所在的簇。
2.3.1 算法思想
K均值聚类的目标:将 n n n 个样本划分到 K K K 个簇中,使得每个样本到其所属簇质心的距离平方和最小。
用数学语言表达:给定样本集 { x 1 , x 2 , ... , x n } \{x_1, x_2, \dots, x_n\} {x1,x2,...,xn},将其划分为 K K K 个簇 C 1 , C 2 , ... , C K C_1, C_2, \dots, C_K C1,C2,...,CK,最小化如下目标函数:
J = ∑ k = 1 K ∑ x ∈ C k ∥ x − μ k ∥ 2 J = \sum_{k=1}^{K} \sum_{x \in C_k} \|x - \mu_k\|^2 J=k=1∑Kx∈Ck∑∥x−μk∥2
其中 μ k = 1 ∣ C k ∣ ∑ x ∈ C k x \mu_k = \frac{1}{|C_k|} \sum_{x \in C_k} x μk=∣Ck∣1∑x∈Ckx, 是簇 C k C_k Ck 的质心(均值向量)。
SSE ( K + 1 ) ≤ SSE ( K ) , ∀ K \operatorname{SSE}(K+1) \le \operatorname{SSE}(K), \quad \forall K SSE(K+1)≤SSE(K),∀K
定义 边际下降量:
Δ ( K ) = SSE ( K − 1 ) − SSE ( K ) ( K ≥ 2 ) \Delta(K) = \operatorname{SSE}(K-1) - \operatorname{SSE}(K) \quad (K\ge 2) Δ(K)=SSE(K−1)−SSE(K)(K≥2)
Δ ( K ) \Delta(K) Δ(K) 表示从 K − 1 K-1 K−1 个簇增加到 K K K 个簇时,SSE 减少了多少。
肘部法则要找的就是 Δ ( K ) \Delta(K) Δ(K) 从大变小 的那个 K K K。
假设我们有一个簇 C C C,包含 m m m 个点,质心为 μ \mu μ,簇内离差平方和为
S ( C ) = ∑ x ∈ C ∥ x − μ ∥ 2 . S(C) = \sum_{x\in C}\|x-\mu\|^2. S(C)=x∈C∑∥x−μ∥2.
若将 C C C 分裂为两个子簇 C 1 C_1 C1 和 C 2 C_2 C2(大小分别为 m 1 , m 2 m_1,m_2 m1,m2,质心分别为 μ 1 , μ 2 \mu_1,\mu_2 μ1,μ2,且 m 1 + m 2 = m m_1+m_2=m m1+m2=m),则分裂后的 SSE 减少量有一个精确的闭式表达式。
Δ = m 1 ⋅ m 2 2 m 2 ∥ μ 1 − μ 2 ∥ 2 + m 2 ⋅ m 1 2 m 2 ∥ μ 1 − μ 2 ∥ 2 = m 1 m 2 2 + m 2 m 1 2 m 2 ∥ μ 1 − μ 2 ∥ 2 = m 1 m 2 ( m 1 + m 2 ) m 2 ∥ μ 1 − μ 2 ∥ 2 = m 1 m 2 m ∥ μ 1 − μ 2 ∥ 2 . \begin{aligned} \Delta &= m_1\cdot\frac{m_2^2}{m^2}\|\mu_1-\mu_2\|^2 \;+\; m_2\cdot\frac{m_1^2}{m^2}\|\mu_1-\mu_2\|^2 \\4pt &= \frac{m_1m_2^2 + m_2m_1^2}{m^2}\,\|\mu_1-\mu_2\|^2 \\4pt &= \frac{m_1m_2(m_1+m_2)}{m^2}\,\|\mu_1-\mu_2\|^2 \\4pt &= \frac{m_1m_2}{m}\,\|\mu_1-\mu_2\|^2. \end{aligned} Δ=m1⋅m2m22∥μ1−μ2∥2+m2⋅m2m12∥μ1−μ2∥2=m2m1m22+m2m12∥μ1−μ2∥2=m2m1m2(m1+m2)∥μ1−μ2∥2=mm1m2∥μ1−μ2∥2.
因此最终公式为
S ( C ) − ( S ( C 1 ) + S ( C 2 ) ) = m 1 m 2 m ∥ μ 1 − μ 2 ∥ 2 . S(C) - \bigl(S(C_1)+S(C_2)\bigr) = \frac{m_1 m_2}{m}\,\|\mu_1 - \mu_2\|^2. S(C)−(S(C1)+S(C2))=mm1m2∥μ1−μ2∥2.
设数据集 D = { x 1 , ... , x n } D = \{x_1, \dots, x_n\} D={x1,...,xn}。第一个中心 c 1 c_1 c1 从 D D D 中均匀随机选取:
P ( c 1 = x i ) = 1 n , i = 1 , ... , n . P(c_1 = x_i) = \frac{1}{n}, \quad i = 1,\dots,n. P(c1=xi)=n1,i=1,...,n.
假设已选出 j − 1 j-1 j−1 个中心 c 1 , ... , c j − 1 c_1,\dots,c_{j-1} c1,...,cj−1。对于任意点 x ∈ D x \in D x∈D,定义它到已有中心的最短距离:
D ( x ) = min k = 1 , ... , j − 1 ∥ x − c k ∥ . D(x) = \min_{k=1,\dots,j-1} \|x - c_k\|. D(x)=k=1,...,j−1min∥x−ck∥.
解释: D ( x ) D(x) D(x) 是点 x x x 到最近已有中心 的距离。因为我们要找的是当前最不被覆盖的点------如果 x x x 离它最近的中心都很远,那它离所有中心都远,应该优先选为下一个中心。所以用 最短距离 来衡量"被忽略的程度"。
下一个中心 c j c_j cj 按以下概率分布抽取:
P ( c j = x ) = D ( x ) 2 ∑ y ∈ D D ( y ) 2 . P(c_j = x) = \frac{D(x)^2}{\sum_{y \in D} D(y)^2}. P(cj=x)=∑y∈DD(y)2D(x)2.
重复此步骤直到选出 K K K 个中心。
解释: D ( x ) 2 D(x)^2 D(x)2 越大,表示 x x x 离已有中心越远,被选为下一个中心的概率就越大。这保证了新中心倾向于落在当前尚未被充分覆盖的区域,从而使初始中心整体分散。
数学动机:最小化势能
定义 势能函数
Φ ( 中心集 ) = ∑ x ∈ D min c ∈ 中心 ∥ x − c ∥ 2 . \Phi(\text{中心集}) = \sum_{x \in D} \min_{c \in \text{中心}} \|x - c\|^2. Φ(中心集)=x∈D∑c∈中心min∥x−c∥2.
这正是 K‑均值目标函数在给定中心下的值(未进行分配优化)。K‑Means++ 的采样过程实际上是在 近似最小化这个势能 :每步以概率与当前势能贡献成正比的规则添加新中心,可以证明这相当于对最优势能的 O ( log K ) O(\log K) O(logK) 近似。
理论保证(Arthur & Vassilvitskii 2007)
令 ϕ opt \phi_{\text{opt}} ϕopt 表示用 K K K 个中心能达到的最小势能(即最优聚类的 SSE)。经过 K‑Means++ 初始化后,所得初始中心集的势能 ϕ \phi ϕ 满足:
E ϕ ≤ 8 ( ln K + 2 ) ⋅ ϕ opt . \mathbb{E}\\phi \le 8 (\ln K + 2) \cdot \phi_{\text{opt}}. Eϕ≤8(lnK+2)⋅ϕopt.
期望的初始化误差被限制在最优值的 O ( log K ) O(\log K) O(logK) 倍以内。随后运行标准 K‑均值算法只会进一步降低 SSE,因此最终聚类结果的误差同样有界。相比之下,随机初始化在最坏情况下可以产生任意大的 ϕ \phi ϕ。
证明思路(简略)
设已选中心集为 C C C,当前势能为
ϕ C = ∑ x min c ∈ C ∥ x − c ∥ 2 . \phi_C = \sum_x \min_{c\in C} \|x-c\|^2. ϕC=x∑c∈Cmin∥x−c∥2.
选择下一个中心时,每个点 x x x 被选的概率为 D ( x ) 2 / ϕ C D(x)^2 / \phi_C D(x)2/ϕC。可以证明,新中心加入后期望势能的减少量至少为某个比例。通过递推,经过 K K K 步后总势能相对于最优解的倍数被控制在 O ( log K ) O(\log K) O(logK) 内。