文章目录
- HyGRAG:统一上下文感知与关系感知的图检索增强生成框架
-
- 一、基础信息
- 二、整体架构四大核心模块
- 三、实验设计与核心结果
-
- [1. 实验基准与数据集](#1. 实验基准与数据集)
- [2. 核心性能指标(Llama3.1-8B)](#2. 核心性能指标(Llama3.1-8B))
- [3. 效率实验](#3. 效率实验)
- [4. 消融实验(验证各模块必要性)](#4. 消融实验(验证各模块必要性))
- [5. 案例分析](#5. 案例分析)
- 四、补充分析与拓展实验
- [五、 结论](#五、 结论)
A Unified Framework for Context-Aware and Relation-Aware
Graph Retrieval-Augmented Generation
HyGRAG:统一上下文感知与关系感知的图检索增强生成框架
一、基础信息
- 核心定位 :提出HyGRAG分层混合图RAG,解决现有图RAG只能单一偏向实体关系/文本上下文、无法真正融合两类信息的痛点,统一上下文感知(Chunk)与关系感知(Entity)检索生成。
- 核心痛点
- 实体中心GraphR(GraphRAG、HippoRAG):擅长多跳推理,但抽取实体丢失原文上下文,易引入抽取误差,事实问答效果差;
- 分块中心RAG(RAPTOR、EraRAG):完整保留文本上下文,但无法建模跨片段实体关联,复杂多跳推理能力弱;
- 现有混合方案仅简单拼接实体与文本表征,未做知识融合,检索时上下文、关系信息独立匹配,无法产生融合后的高阶知识。
- 三大待解决技术难题
- 如何生成真正融合上下文+关系的社区摘要,而非简单拼接;
- 检索阶段如何利用融合摘要获取原文不存在的衍生知识;
- 动态新增语料时,避免全图重建,实现高效增量更新。
- 核心贡献
- 混合图分层索引:统一文本块、实体两类节点,构建多层社区抽象,支持多粒度检索;
- 双路协同检索:上下文检索+关系检索联动,利用社区结构挖掘单一路径遗漏信息;
- 性能大幅提升:多跳推理任务平均提升9.7%,事实准确率提升6.2%,HotpotQA最高提升12.2%,同时支持高效动态语料更新。
二、整体架构四大核心模块
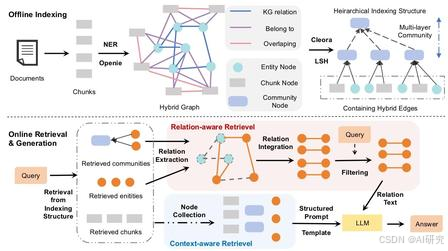
模块1:离线分层混合图索引构建(无在线耗时)
分为混合图搭建 +分层社区聚类摘要两步:
- 构建双基础子图
- 文本块图 G c G^c Gc:文档切重叠Chunk,共享≥3个实体的块之间建立边,用BGE-M3编码块向量;
- 实体知识图 G e G^e Ge:LLM抽取文本三元组(头,关系,尾),实体为节点、关系为边;
- 跨层连通得到混合图 G h y b r i d G_{hybrid} Ghybrid
新增「实体-所属文本块」跨层边,图包含两类节点(Chunk/Entity)、三类边(块间、实体间、实体-块); - 分层抽象索引树
- Cleora算法生成图结构感知嵌入(同时融合文本语义+图连接关系);
- LSH超平面哈希聚类,约束社区大小 S m i n = 5 、 S m a x = 50 S_{min}=5、S_{max}=50 Smin=5、Smax=50,过大拆分、过小合并;
- Llama3.1-8B为每个社区生成融合上下文与实体关系的结构化摘要,BGE-M3编码摘要向量;
- 将社区摘要作为上层节点,递归聚类生成4层分层索引(底层原始块/实体,顶层全局摘要)。
模块2:在线双路感知检索(上下文+关系协同)
给定查询,分两步联合检索,最终整合四类信息:社区摘要、原始文本块、实体、关系三元组
- 上下文感知检索
查询编码后,遍历分层索引所有层级,召回相似度Top-k:高层社区摘要、底层文本块、独立实体;覆盖从宏观概括到原文细节全粒度信息。 - 关系感知检索
- 合并上下文检索得到的实体 + 召回社区内全部实体,构建全局实体集合;
- 提取所有关联实体的三元组,拼接头/关系/尾做向量筛选,保留Top-k高相关关系;
- 检索复杂度: O ( l o g N ⋅ d + k e ⋅ d ˉ ⋅ d ) O(logN·d + k_e·\bar{d}·d) O(logN⋅d+ke⋅dˉ⋅d),次线性随图规模增长,对比单一Chunk检索仅增加轻量化开销。
模块3:分层信息融合生成
设计结构化Prompt,有序输入四类检索素材:
- 高层社区摘要(全局逻辑);
- 关键实体(核心概念);
- 筛选后的关系三元组(推理链路);
- 原始文本块(事实证据);
强制模型仅使用提供素材,信息不足时标注"Insufficient information",抑制幻觉。
模块4:动态增量更新机制(无需全量重建)
面向持续新增文档场景,采用依附式局部更新:
- 新文档切块、抽取实体三元组,生成整体摘要向量;
- 自底向上遍历分层索引,找到相似度超过阈值 τ a t t a c h = 0.65 \tau_{attach}=0.65 τattach=0.65的社区,将新节点依附至该层;
- 仅沿依附节点向上更新所有祖先社区的摘要与向量,无关分支完全不变;
- 新增块、实体按原图规则建立跨层/同层边,更新全流程离线执行,不影响线上检索速度。
三、实验设计与核心结果
1. 实验基准与数据集
- 基线分类
- 纯LLM:Zero-shot、CoT;
- 上下文类RAG:VanillaRAG、RAPTOR、EraRAG;
- 关系类GraphRAG:LightRAG三变体、HippoRAG/2、LGraphRAG、HiRAG、ArchRAG;
- 评测数据集
- 事实QA:PopQA;
- 多跳推理:MuSiQue、MultiHop-RAG、HotpotQA;
- 长文本阅读理解:QuALITY;
- 基础模型:Llama3.1-8B-Instruct、Qwen38B,嵌入统一使用BGE-M3。
2. 核心性能指标(Llama3.1-8B)
- 事实任务PopQA:准确率72.34%,召回43.51%,领先最优基线6.2%;
- 多跳推理:MultiHop-RAG准确率65.41%(提升6%),HotpotQA 70.79%,MuSiQue平均提升11.1%;
- 阅读理解QuALITY:59.49%,综合表现第二;
- 叠加推理增强Prompt后,多跳任务性能进一步小幅上涨。
3. 效率实验
- 在线查询开销
- Token消耗、单轮耗时显著优于所有关系类GraphRAG(LightRAG、HippoRAG等);略高于极简VanillaRAG,但推理收益远抵消微小开销;
- 离线索引效率
- 聚类仅31秒(RAPTOR的GMM聚类上万秒);总索引耗时比LightRAG快21%;内存占用可控(9.97GB内存+2.5GB显存);
- 动态语料鲁棒性
增量插入不同比例新数据,准确率仅下降1%-2%;对比传统全重建GraphRAG,增量索引Token、时间开销大幅降低。
4. 消融实验(验证各模块必要性)
- 移除Chunk块结构:性能暴跌,文本上下文是事实问答基础;
- 移除实体&关系:多跳推理明显下滑,仅长文本阅读小幅提升(实体关系易干扰小模型长文本理解);
- 移除社区分层:小幅稳定下降,高层摘要负责全局知识聚合;
- 单纯拼接HiRAG(关系)+RAPTOR(上下文):精度、Token消耗均弱于HyGRAG,证明框架不是简单融合,而是原生统一建模。
5. 案例分析
- MuSiQue多跳问题 :"Jan Klapáč出生地城市的城堡名称"
- 基线缺陷:LLightRAG仅找到出生地,无城堡关联;VanillaRAG检索完全无关实体;
- HyGRAG优势:通过实体三元组(Jan-born-in-Prague)+社区摘要(Prague Castle位于布拉格)串联完整推理链;
- PopQA消歧问题 :"Paul Walker出生城市"
- 基线缺陷:混淆多名同名人物,给出矛盾地点;
- HyGRAG优势:整合全部相关实体与关系,区分不同Paul Walker对应的证据,输出可信答案。
四、补充分析与拓展实验
- 嵌入模型鲁棒性:替换Qwen3-E、m-e5、text-embedding-v3等主流嵌入,HyGRAG始终优于对应Vanilla基线,适配各类向量化方案;
- 基座LLM鲁棒性:更换Qwen38B后,上下文类基线性能大幅衰减,HyGRAG仍稳定领跑,架构不依赖特定大模型;
- 幻觉分析:Llama生成社区摘要幻觉率17%,升级GPT-4o-mini后降至7%,框架可无缝替换摘要LLM缓解幻觉;
- 超参配置:最大分层4层、LSH哈希16维、社区摘要300词、实体共享阈值3等。
五、 结论
HyGRAG通过混合异构图+分层社区摘要实现上下文、关系信息原生融合,双路检索充分挖掘文本细节与实体逻辑;兼顾静态QA高精度与动态语料低成本更新,平衡推理能力、事实准确性与工程落地效率。