前言
3.1 什么是线性回归?
用 "预测奶茶销量" 来理解 🧋
假设你开了一家奶茶店,发现天气越热,卖的奶茶越多。你想预测明天能卖多少杯,好准备原料。
你收集了过去 7 天的数据:
提示:以下是本篇文章正文内容,下面案例可供参考
一、表格?
温度 (℃) 销量 (杯)
20 50
22 55
24 60
26 68
28 75
30 82
32 90
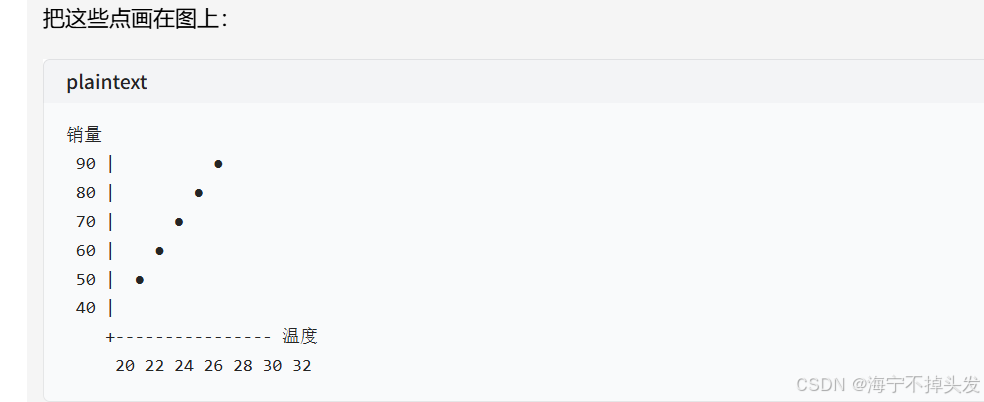
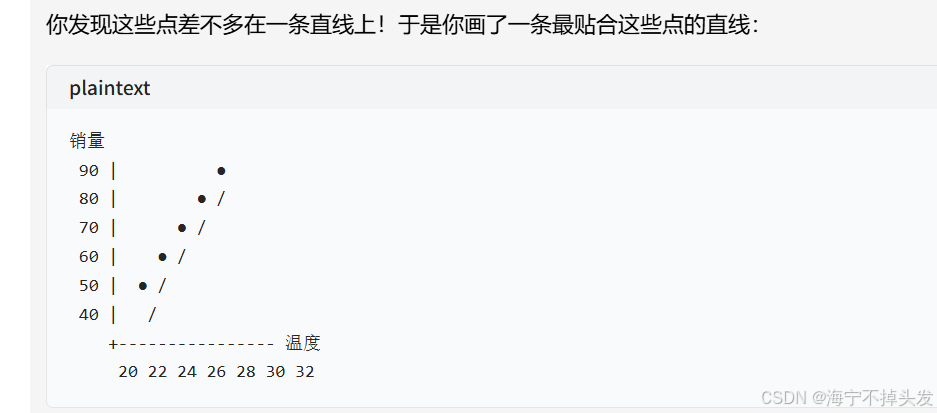
二、使用步骤
1.引入库
代码如下(示例):
c
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context这就是线性回归!
线性回归的本质:找一条直线(或者超平面),让它尽可能贴合所有数据点,然后用这条直线来预测新的数据。
3.2 线性回归的数学表达
代码如下(示例):
3.2.1 一元线性回归(一个特征)
还是奶茶的例子,只有 "温度" 这一个特征。
该处使用的url网络请求的数据。
y = w * x + b
y:预测值(预测销量)
x:特征值(温度)
w:权重 / 斜率(温度每升高 1 度,销量增加多少)
b:偏置 / 截距(温度为 0 时的销量,数学意义,实际可能没意义)
用奶茶例子来说:
假设我们算出 w = 3.2,b = -12
那么预测公式就是:销量 = 3.2 × 温度 - 12
验证一下:
20℃:3.2×20 - 12 = 64 - 12 = 52 杯(实际 50,差 2 杯)
30℃:3.2×30 - 12 = 96 - 12 = 84 杯(实际 82,差 2 杯)
还挺准的!
3.2.2 多元线性回归(多个特征)
现实中,影响销量的不只是温度,还有星期几、有没有促销等等。
假设我们有 3 个特征:
x₁:温度
x₂:是不是周末(1 是 0 否)
x₃:有没有促销(1 是 0 否)
预测公式:
y = w₁x₁ + w₂x₂ + w₃*x₃ + b
每个特征前面都有一个权重 w,代表这个特征的重要程度:
w₁ 大 → 温度影响大
w₂ 大 → 是不是周末影响大
w₃ 大 → 促销影响大
用向量形式表示(更简洁)
y = w^T · x + b
其中 w = w₁, w₂, w₃ 是权重向量,x = x₁, x₂, x₃ 是特征向量。
再简化一点(把 b 也放进向量里):
给 x 加一个恒为 1 的特征,w 加一个偏置项:
x = 1, x₁, x₂, x₃
w = b, w₁, w₂, w₃
y = w^T · x
3.3 损失函数 ------ 怎么衡量 "拟合得好不好"?
问题来了:怎么判断哪条直线 "最贴合" 数据?
我们需要一个量化的标准,这就是损失函数(Loss Function)。
3.3.1 什么是损失?
损失 = 预测值和真实值的差距
对于每个数据点:
真实值:y
预测值:ŷ(读作 y hat)
误差:y - ŷ
但是误差有正有负,加起来可能抵消,所以我们用平方误差:
单个样本的损失 = (y - ŷ)²
为什么用平方? 🤔
消除正负号:平方后都是正的
放大误差:差得远的点惩罚更重(对异常点敏感)
数学好求导:平方函数求导很方便
3.3.2 均方误差(MSE)
把所有样本的损失加起来取平均,就是均方误差(Mean Squared Error):
MSE = (1/n) * Σ(yᵢ - ŷᵢ)²
n:样本数量
yᵢ:第 i 个样本的真实值
ŷᵢ:第 i 个样本的预测值
用奶茶例子算一下:
假设我们的直线是 y = 3x - 10
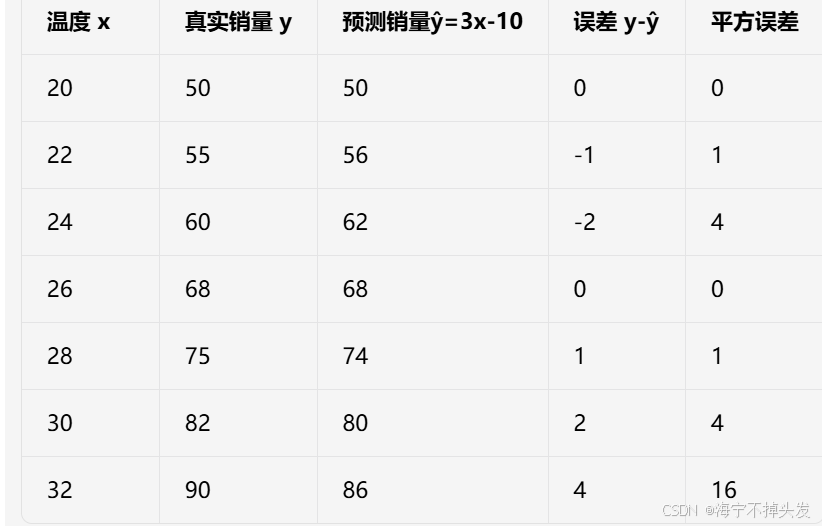
3.3.3 损失函数的几何意义
把损失函数想象成一个 "山谷":
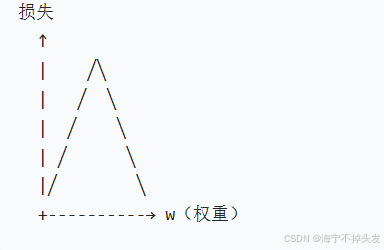 横轴:权重 w 的取值
横轴:权重 w 的取值
纵轴:损失函数的值(MSE)
形状:一个碗形(凸函数)
碗底:损失最小的地方,也就是最优解
3.4 求解方法一:最小二乘法(数学公式直接算)
线性回归有一个 "解析解",就是可以用数学公式直接算出最优解,不用迭代。
3.4.1 推导思路
我们的目标是最小化 MSE:
plaintext
J(w) = (1/n) * Σ(yᵢ - w^T xᵢ)²
对 w 求导,令导数等于 0,就能解出最优的 w。
3.4.2 最终公式
经过矩阵求导(过程比较复杂,记住结论就行),最优权重为:
plaintext
w* = (X^T X)⁻¹ X^T y
X:特征矩阵(n 行 d 列,n 个样本,d 个特征)
y:标签向量(n 个元素)
X^T:X 的转置
(X^T X)⁻¹:X^T X 的逆矩阵
用 "奶茶例子" 验证一下(简化版):
数据:
x = 20, 22, 24, 26, 28, 30, 32
y = 50, 55, 60, 68, 75, 82, 90
用最小二乘法算出来:
w ≈ 3.21
b ≈ -13.57
所以公式是:销量 = 3.21 × 温度 - 13.57
3.4.3 最小二乘法的优缺点
表格
优点 缺点
一步到位,直接算出结果 特征太多时,矩阵求逆计算量很大
不需要调参(没有学习率) 数据量太大时,内存可能不够
一定能找到全局最优解 必须满足 X^T X 可逆(有时不可逆)
什么时候用?
特征少(<1000)、数据量不大的时候
快速验证、快速出结果的时候
3.5 求解方法二:梯度下降法(迭代优化)
这是机器学习里最常用的优化方法,也是你之前学的 "皮卡丘下山"!
站在山坡上 → 找最陡的下坡方向 → 走一步 → 重复 → 直到山底
用损失函数的 "山谷" 来理解:
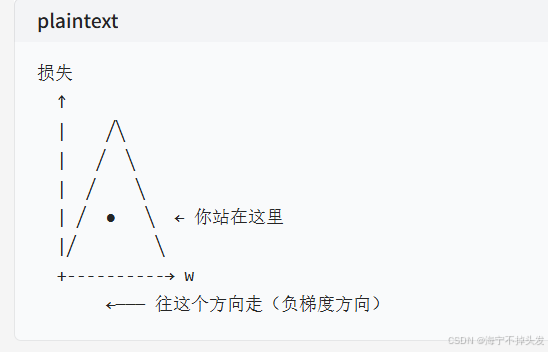
每一步做什么:
计算当前位置的梯度(损失函数对 w 的导数)
沿着负梯度方向走一步(更新 w)
重复,直到收敛
3.5.2 梯度下降的数学公式
权重更新公式:
plaintext
w = w - α * (∂J/∂w)
w:当前权重
α:学习率(learning rate)------ 步长多大
∂J/∂w:损失函数对 w 的梯度(导数)
减号:沿着负梯度方向
学习率 α 很重要! 🎯

3.5.3 线性回归的梯度推导
损失函数(MSE):
plaintext
J(w) = (1/n) * Σ(yᵢ - w^T xᵢ)²
对 w 求导(用链式法则):
plaintext
∂J/∂w = (1/n) * Σ 2*(yᵢ - w^T xᵢ) * (-xᵢ)
= (-2/n) * Σ (yᵢ - ŷᵢ) * xᵢ
直观理解:
(yᵢ - ŷᵢ) 是预测误差
误差越大,梯度越大,步子迈得越大
xᵢ 是特征值,特征值大的影响也大
简化一下(把 2/n 的常数吸收到学习率里):
梯度方向 = Σ (ŷᵢ - yᵢ) * xᵢ

3.5.5 用奶茶例子走一遍
数据:
x = 20, 22, 24, 26, 28, 30, 32(温度)
y = 50, 55, 60, 68, 75, 82, 90(销量)
初始化:
w = 0, b = 0
学习率 α = 0.001
第 1 次迭代:
计算预测值:ŷ = 0*x + 0 = 0(全是 0,很离谱)
计算误差:ŷ - y = -50, -55, -60, -68, -75, -82, -90
计算梯度:
∂J/∂w = (2/7) * Σ(误差 * x)
算出来大概是... 很大的一个负数
更新参数:
w = 0 - 0.001 * (很大的负数) → w 变大
b = 0 - 0.001 * (很大的负数) → b 变大
第 100 次迭代:
w ≈ 2.8, b ≈ -5
预测公式:y = 2.8x - 5
第 1000 次迭代:
w ≈ 3.2, b ≈ -13
越来越接近最优解了!
第 10000 次迭代:
w ≈ 3.21, b ≈ -13.57
基本收敛了,和最小二乘法结果一样!
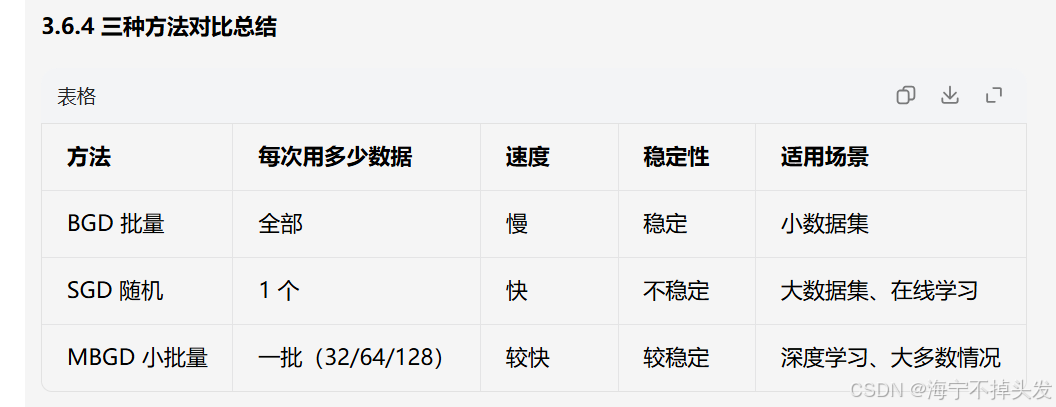
3.6 三种梯度下降的对比
梯度下降有三种常见变体,各有优缺点:
3.6.1 批量梯度下降(BGD)
Batch Gradient Descent
每次迭代用全部训练数据计算梯度
优点:稳定,一定往最优方向走
缺点:数据量大时,每次迭代很慢
类比:考试前把所有题都做完一遍,才知道自己哪里错了,然后改进。
3.6.2 随机梯度下降(SGD)
Stochastic Gradient Descent
每次迭代随机选一个样本计算梯度
优点:速度快,数据量大也不怕
缺点:不稳定,路线弯弯绕绕,可能震荡
类比:做一道题就改一下,做一道改一道,方向忽左忽右,但总体还是往对的方向走。

3.6.3 小批量梯度下降(MBGD)
Mini-Batch Gradient Descent
每次迭代用一小批样本(比如 32 个、64 个)
是 BGD 和 SGD 的折中方案
优点:既快又相对稳定
深度学习里最常用!
类比:做 10 道题就改一次,既不会太慢,也不会太不稳定。
3.7 代码实现:手动实现线性回归
现在我们用 NumPy 手动实现一个线性回归,彻底搞懂每一步!
3.7.1 准备数据
python
import numpy as np
奶茶店数据:温度、销量
X = np.array(20, 22, 24, 26, 28, 30, 32, dtype=np.float32)
y = np.array(50, 55, 60, 68, 75, 82, 90, dtype=np.float32)
注意:X要变成二维矩阵(n行1列),因为机器学习的输入都是二维的
X = X.reshape(-1, 1) # 变成 (7, 1) 的形状
print("X shape:", X.shape) # (7, 1)
print("y shape:", y.shape) # (7,)
3.7.2 数据归一化(很重要!)
为什么要归一化?
温度是 20-30,销量是 50-90,数值范围不一样
如果不归一化,梯度下降会走得很别扭("马克波过河" 的比喻)
归一化方法:Min-Max 归一化
把数据缩放到 0, 1 区间:
plaintext
x_norm = (x - min) / (max - min)
python
特征归一化
X_min = X.min()
X_max = X.max()
X_norm = (X - X_min) / (X_max - X_min)
标签也可以归一化(可选)
y_min = y.min()
y_max = y.max()
y_norm = (y - y_min) / (y_max - y_min)
print("归一化后的X:", X_norm.flatten())
0. 0.16666667 0.33333334 0.5 0.66666669 0.83333331 1.
3.7.3 初始化参数
python
初始化权重和偏置
w = np.zeros(1) # 一个特征,所以一个权重
b = 0.0
学习率
learning_rate = 0.01
迭代次数
epochs = 1000
n = len(X_norm) # 样本数量
3.7.4 梯度下降训练
python
loss_history = \[\] # 记录每次的损失,方便画图
for epoch in range(epochs):
1. 前向传播:计算预测值
y_pred = np.dot(X_norm, w) + b # shape: (7,)
# 2. 计算损失(MSE)
loss = np.mean((y_pred - y_norm) ** 2)
loss_history.append(loss)
# 3. 计算梯度
# dw = (2/n) * Σ (ŷ - y) * x
dw = (2/n) * np.dot(X_norm.T, (y_pred - y_norm))
# db = (2/n) * Σ (ŷ - y)
db = (2/n) * np.sum(y_pred - y_norm)
# 4. 更新参数
w = w - learning_rate * dw
b = b - learning_rate * db
# 每100次打印一下
if (epoch + 1) % 100 == 0:
print(f"Epoch {epoch+1}/{epochs}, Loss: {loss:.6f}")print(f"\n训练完成!")
print(f"w = {w0:.4f}")
print(f"b = {b:.4f}")
输出大概是这样:
plaintext
Epoch 100/1000, Loss: 0.012345
Epoch 200/1000, Loss: 0.008765
...
Epoch 1000/1000, Loss: 0.000123
训练完成!
w = 0.9623
b = 0.0189
3.7.5 预测新数据
python
预测:明天35度,能卖多少杯?
new_temp = 35
先归一化
new_temp_norm = (new_temp - X_min) / (X_max - X_min)
预测
pred_norm = np.dot(new_temp_norm, w) + b
反归一化,还原成真实销量
pred = pred_norm * (y_max - y_min) + y_min
print(f"预测:明天{new_temp}度,能卖 {pred:.1f} 杯奶茶!")
预测:明天35度,能卖 98.5 杯奶茶!
3.7.6 完整代码封装成类
python
class LinearRegression:
def init (self, learning_rate=0.01, epochs=1000):
self.learning_rate = learning_rate
self.epochs = epochs
self.w = None
self.b = None
self.loss_history = \[\]
def fit(self, X, y):
"""训练模型"""
n_samples, n_features = X.shape
# 初始化参数
self.w = np.zeros(n_features)
self.b = 0
# 梯度下降
for _ in range(self.epochs):
# 前向传播
y_pred = np.dot(X, self.w) + self.b
# 计算损失
loss = np.mean((y_pred - y) ** 2)
self.loss_history.append(loss)
# 计算梯度
dw = (2/n_samples) * np.dot(X.T, (y_pred - y))
db = (2/n_samples) * np.sum(y_pred - y)
# 更新参数
self.w -= self.learning_rate * dw
self.b -= self.learning_rate * db
def predict(self, X):
"""预测"""
return np.dot(X, self.w) + self.b使用示例
model = LinearRegression(learning_rate=0.01, epochs=1000)
model.fit(X_norm, y_norm)
predictions = model.predict(X_norm)
3.8 模型评估:怎么判断模型好不好?
训练完了,怎么知道模型好不好?
3.8.1 均方误差(MSE)
plaintext
MSE = (1/n) * Σ(yᵢ - ŷᵢ)²
越小越好
缺点:数值大小和标签的量纲有关,不好直观判断
3.8.2 均方根误差(RMSE)
plaintext
RMSE = √MSE
和标签同一个量纲,更好理解
比如 RMSE=5,说明平均差 5 杯
3.8.3 平均绝对误差(MAE)
plaintext
MAE = (1/n) * Σ|yᵢ - ŷᵢ|
用绝对值,对异常点不那么敏感
3.8.4 R² 分数(最重要!)⭐
R² 分数:决定系数,衡量模型解释了多少数据的变化。
plaintext
R² = 1 - (SS_res / SS_tot)
SS_res = Σ(yᵢ - ŷᵢ)² (残差平方和,模型没解释的部分)
SS_tot = Σ(yᵢ - ȳ)² (总平方和,数据本身的变化)
直观理解:
R² = 1:模型完美预测,所有点都在直线上
R² = 0:模型和直接预测平均值一样烂
R² < 0:模型还不如直接预测平均值
一般来说:
R² > 0.8:模型很不错
R² 在 0.5-0.8:模型还可以
R² < 0.3:模型比较差
3.9 线性回归的常见问题
3.9.1 线性回归的假设(使用前提)
线性回归不是万能的,它有几个假设:
线性关系:特征和标签之间是线性关系
如果不是线性的,线性回归就拟合不好
误差独立:样本之间的误差互不影响
比如时间序列数据,今天的误差和昨天有关,就不满足
误差同方差:误差的方差是恒定的
不能有的地方误差大,有的地方误差小
误差正态分布:误差服从正态分布
特征不相关:特征之间不能高度相关(多重共线性)
比如同时用 "身高厘米" 和 "身高米" 作为特征,就完全相关了
3.9.2 多重共线性问题
什么是多重共线性?
特征之间高度相关,比如:
特征 1:身高(厘米)
特征 2:身高(米)
这两个特征完全线性相关!
有什么问题?
权重不稳定:数据稍微变一点,权重变化很大
权重解释性差:不知道到底是哪个特征在起作用
但预测结果可能还不错
怎么解决?
删除相关的特征(留一个就行)
用 PCA 降维
用岭回归(加 L2 正则化)
3.9.3 异常值的影响
线性回归对异常值很敏感!因为用的是平方误差,异常点的误差会被放大。
例子:
本来数据点都在直线附近,突然来了一个离群点,直线就被 "拉歪" 了。
怎么解决?
检查并删除异常值(如果是数据错误)
用更鲁棒的模型(比如决策树)
用 L1 损失(MAE)代替 L2 损失(MSE)
3.10 多项式回归
线性回归只能拟合直线,那如果数据不是线性的怎么办?
答案:多项式回归!
3.10.1 什么是多项式回归?
给原始特征添加高次项,然后还是用线性回归来拟合。
例子:
原始特征只有 x,我们添加 x²、x³...
plaintext
原始:y = w₁x + b
多项式:y = w₁x + w₂x² + w₃x³ + b
虽然特征是高次的,但对权重 w 来说还是线性的,所以还是叫 "线性" 回归。
直观理解:
一次项(x):直线
二次项(x²):抛物线
三次项(x³):S 形曲线
次数越高,曲线越灵活,能拟合更复杂的数据
3.10.2 过拟合问题 ⚠️
多项式次数不是越高越好!
plaintext
次数太低(欠拟合):直线拟合曲线,误差大
●
● /
●/
/●
/ ●
次数适中:刚好拟合
●●
● ●
● ●
● ●
次数太高(过拟合):把每个点都精准穿过,但弯弯绕绕,新数据预测不准
●●
╱ ╲
● ●
╱ ╲
● ●
过拟合:模型在训练集上表现很好,但在测试集上表现很差。
模型把训练数据的 "噪音" 也学进去了
就像学生背答案,考试遇到原题考满分,换个题就不会了
怎么解决过拟合?
增加数据量
减少特征(降低多项式次数)
正则化(后面讲)
✅ 第三部分小结
线性回归核心知识点:
表格
知识点 核心内容 关键词
什么是线性回归 找一条直线拟合数据,用来预测 直线、拟合、预测
数学表达 y = w·x + b 权重 w、偏置 b
损失函数 均方误差 MSE = (1/n)Σ(y-ŷ)² 平方误差、最小化
最小二乘法 直接用公式算最优解 解析解、矩阵求逆
梯度下降 迭代优化,一步步下山 学习率、负梯度、收敛
三种梯度下降 BGD/SGD/MBGD 批量、随机、小批量
评估指标 MSE、RMSE、MAE、R² R² 最重要,越接近 1 越好
常见问题 多重共线性、异常值、过拟合 假设、前提条件
多项式回归 添加高次项,拟合曲线 过拟合、欠拟合