京东开源 JoyAI-Echo:5 分钟长视频一次生成,音画同步不崩脸!
京东 JoyAI-Echo:跨模态记忆银行 + DMD 蒸馏 7.5x 加速,分钟级多镜头故事一键生成。
目录
- [1. 项目简介------它是什么?](#1. 项目简介——它是什么?)
- [2. 长视频生成的三大痛点](#2. 长视频生成的三大痛点)
- [3. 核心突破------四大技术亮点](#3. 核心突破——四大技术亮点)
- [4. 评测结果------碾压级表现](#4. 评测结果——碾压级表现)
- [5. 快速上手------5 步跑起来](#5. 快速上手——5 步跑起来)
- [6. Prompt 写法指南------如何写出好故事](#6. Prompt 写法指南——如何写出好故事)
- [7. 核心原理------源码架构解析](#7. 核心原理——源码架构解析)
- [8. 适用场景与优缺点](#8. 适用场景与优缺点)
- [9. 总结](#9. 总结)
1. 项目简介------它是什么?
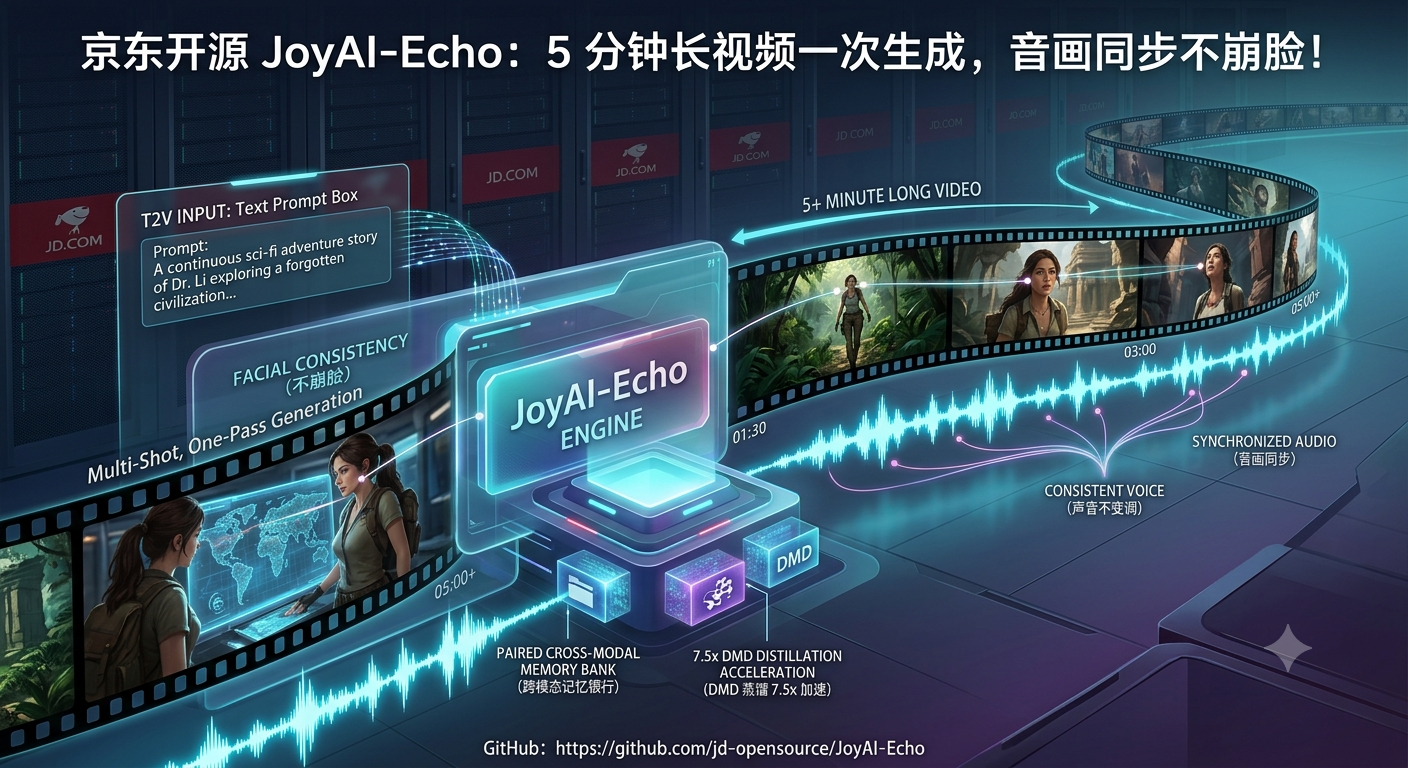
JoyAI-Echo 是京东开源的长视频生成框架,一句话概括:从文本提示生成分钟级多镜头音画同步视频,人物不崩脸、声音不变调。
它不是「一个镜头一个镜头分别生成再拼接」的传统方案------而是通过跨模态音视频记忆银行(Paired Cross-Modal Memory Bank) ,让每个新镜头都「记住」前面镜头中人物的外观和声线,实现跨镜头的一致性。再配合 DMD(Distribution Matching Distillation)蒸馏,推理速度比原始流程快 7.5 倍。
目前支持 T2V(文本到视频) 和多镜头长视频 + 音视频记忆生成,I2V(图到视频)暂不支持,后续版本将加入。
🔗 项目地址:https://github.com/jd-opensource/JoyAI-Echo
🔗 项目主页:https://echo-team-joy-future-academy-jd.github.io/Echo-LongVideo-Page/
🔗 Hugging Face:https://huggingface.co/jdopensource/JoyAI-Echo
🔗 ComfyUI 插件:https://github.com/zhuang2002/ComfyUI_JoyAI_Echo
⚠️ License:LTX-2 Community License Agreement(仅限学术研究和非商业用途)
2. 长视频生成的三大痛点
当前长视频生成面临三个核心难题:
| 痛点 | 具体表现 | 举个🌰 |
|---|---|---|
| ❌ 误差累积 | 长序列中误差逐帧叠加,越到后面越崩 | 第 1 镜头人物正常,第 5 镜头脸就变了 |
| ❌ 时间一致性差 | 跨镜头/跨场景的视觉和音频无法保持一致 | 主角说话声线前后不一致 |
| ❌ 推理延迟高 | 多步扩散模型推理极慢,分钟级视频生成成本高昂 | 生成 5 分钟视频可能要数小时 |
JoyAI-Echo 正是针对这三个痛点逐一攻克。
3. 核心突破------四大技术亮点
🎞️ 亮点一:分钟级多镜头故事生成
一个 JSON 文件定义一组镜头提示词,模型按顺序生成每个镜头,并通过记忆银行在镜头之间传递人物外观和声音信息,输出连贯的 5 分钟级长视频。
默认配置:25 fps × 241 帧 × 1280×736 分辨率,单镜头约 9.6 秒
⚡ 亮点二:DMD 蒸馏 7.5x 加速
通过 Distribution Matching Distillation(分布匹配蒸馏),将原始多步扩散模型蒸馏为少步推理版本 ,速度提升约 7.5 倍,同时视觉质量反而提升。
从 configs/inference.yaml 可以看到,蒸馏后仅需 9 步降噪:
yaml
denoising:
steps: [1000, 994, 988, 981, 975, 909, 725, 422, 0]
sigmas: [1.0, 0.99375, 0.9875, 0.98125, 0.975, 0.909375, 0.725, 0.421875, 0.0]🔊 亮点三:音画联合生成
一条管线同时生成同步的视频和音频------不是先生成视频再配音,而是视频画面和声音同步输出,人物说话口型与声线自然匹配。
🧠 亮点四:跨模态记忆银行
这是 JoyAI-Echo 最核心的创新。Paired Audio-Video Memory Bank 像一个「角色档案柜」:
镜头 1 → 生成视频 + 音频
↓ 提取人物外观帧 + 声音特征 → 存入记忆银行
镜头 2 → 读取记忆银行中的人物外观 + 声音 → 作为条件输入
↓ 生成保持一致的新镜头
镜头 3 → 读取记忆银行 → 继续保持一致...记忆银行配置(来自 inference.yaml):
yaml
memory:
max_size: 7 # 最多记住 7 个记忆条目
num_fix_frames: 3 # 每条记忆固定 3 帧
position_mode: reference # 位置编码模式
lora_strength: 1.0 # LoRA 记忆适配强度
audio_memory:
enable: true
window_size: 96 # 音频记忆窗口大小
window_selection_mode: max_response
sample_rate: 16000
mel_bins: 128 # 梅尔频谱 bins 数视觉记忆存的是人物的「外观帧」,音频记忆存的是声音的「梅尔频谱窗口」------两者配对存储,确保声画一致。
4. 评测结果------碾压级表现
长视频对比:JoyAI-Echo vs HappyOyster(Directing 模式)
GSB 用户偏好百分比------数字越大说明越受欢迎:
| 评估维度 | JoyAI-Echo | 平局 | HappyOyster |
|---|---|---|---|
| 🎨 视觉美学 | 63.6% | 8.8% | 27.6% |
| 🔊 音频质量 | 81.7% | 6.5% | 11.8% |
| 📝 提示词遵循 | 80.6% | 13.5% | 5.9% |
| 🧑 IP 一致性 | 59.4% | 12.9% | 27.7% |
📌 在音频质量和提示词遵循上,JoyAI-Echo 以碾压级优势领先!
短视频对比:JoyAI-Echo vs Wan 2.6(短视频专精模型)
| 评估维度 | JoyAI-Echo | 平局 | Wan 2.6 |
|---|---|---|---|
| 🎨 视觉美学 | 58.8% | 14.7% | 26.5% |
| 🔊 音频质量 | 32.3% | 30.9% | 36.8% |
| 📝 提示词遵循 | 33.8% | 36.8% | 29.4% |
📌 长视频专精模型在短视频场景的视觉美学上居然也赢了 Wan 2.6!音频方面稍逊,但差距不大。
规模数据
| 项目 | 数值 |
|---|---|
| 🎬 长视频连贯故事长度 | 5 分钟 |
| ⚡ 推理加速倍数 | 7.5x |
| 📚 评测故事数 | 100 |
| 🎞️ 评测镜头数 | 3,000 |
| 🕒 每镜头帧数 | 241 @ 25fps |
5. 快速上手------5 步跑起来
Step 1:克隆仓库
bash
git clone https://github.com/jd-opensource/JoyAI-Echo.git
cd JoyAI-EchoStep 2:创建环境
推荐环境:Python 3.11 + PyTorch 2.8 + CUDA 12.8
使用 conda(推荐,自带 ffmpeg):
bash
conda env create -f environment.yml
conda activate echo-long使用 uv(手动安装 ffmpeg):
bash
uv venv --python 3.11 .venv
source .venv/bin/activate
uv pip install --extra-index-url https://download.pytorch.org/whl/cu128 -r requirements.txt
# macOS
brew install ffmpeg
# Linux
sudo apt install ffmpegStep 3:下载模型权重
需要下载两个模型:
| 文件 | 说明 | 大小 | 下载链接 |
|---|---|---|---|
echo-longvideo-release.safetensors |
主模型(transformer + VAE + vocoder) | ~46 GB | HuggingFace |
gemma-3-12b/ |
文本编码器(指令微调版) | ~24 GB | Gemma-3-12b-it |
放置到 checkpoints/ 目录:
text
checkpoints/
+-- echo-longvideo-release.safetensors
`-- gemma-3-12b/Step 4:编写故事 Prompt
在 prompts/ 目录下创建 JSON 文件,每个文件包含一个 prompts 数组,每个字符串代表一个镜头:
json
{
"prompts": [
"镜头1描述...",
"镜头2描述...",
"镜头3描述..."
]
}Step 5:运行推理
bash
python inference.py模型加载一次,处理 prompts/ 目录下所有 JSON 文件。输出保存到:
text
inference_result/outputs/<prompt-name>/inference_<timestamp>/💡 显存要求 :默认配置峰值约 46--50 GB ,建议使用 H100/A100(80GB)或 48GB 级 GPU。显存不足可减少帧数:
python inference.py --num-frames 121
CLI 参数可覆盖所有 YAML 配置:
bash
python inference.py --seed 42 --num-frames 121
python inference.py --config configs/my_experiment.yaml
python inference.py --help6. Prompt 写法指南------如何写出好故事
JoyAI-Echo 强烈建议先使用 Prompt Enhancer 增强提示词:
- 长视频用:
prompts/long_story_writer_system_prompt.md - 短视频用:
prompts/short_story_writer_system_prompt.md
⚠️ 不增强的 Prompt 效果明显较弱!
每个镜头的描述应包含以下 6 个部分(按顺序写):
| 部分 | 写什么 | 示例 |
|---|---|---|
| 人物与角色 | 人物外貌:年龄、体型、发型、脸型、衣着、声线特征 | "一位 30 岁女性,棕色短发,穿深蓝西装..." |
| 动作与对话 | 人物做什么、说什么 | "她站在讲台上,说:'我们开始吧。'" |
| 视觉风格 | 整体美学和情感基调 | "写实电影语言,冷调日光,克制紧张的镜头感" |
| 镜头运动 | 镜头类型和运动 | "稳定近景,面部特写" 或 "中景,腰部以上" |
| 背景场景 | 环境和场景细节 | "现代会议室,白色墙壁,投影屏幕" |
| 音效与配乐 | 场景声音和背景音乐 | "室内氛围音,脚步声和衣物摩擦声,对话下方轻柔低音音乐铺垫" |
7. 核心原理------源码架构解析
🏗️ 仓库结构
text
.
+-- configs/inference.yaml # 全部推理参数(YAML)
+-- checkpoints/ # 模型权重(单独下载)
+-- prompts/ # 多镜头 Prompt JSON 文件
+-- ltx-core/src/ltx_core/ # transformer、VAE、文本编码器基础模块
+-- ltx-pipelines/src/ltx_pipelines/ # 采样器和管线工具
+-- ltx-distillation/
| +-- src/ltx_distillation/ # DMD 包装、音视频管线、记忆银行、工具
| `-- scripts/multishot_inference_dmd.py
+-- inference.py # 主入口(加载一次,推理全部)🔧 两阶段推理引擎
inference.py 中的 InferenceEngine 采用了两阶段 GPU 显存热换策略:
- Stage 1:文本编码 --- 加载 Gemma-3-12b 文本编码器(~24GB),编码所有 Prompt,然后完全释放文本编码器
- Stage 2:视频生成 --- 加载视频生成器 + VAE + 记忆银行管线,用 Stage 1 的缓存 Prompt 进行推理
python
class InferenceEngine:
"""Two-stage inference engine: encode all prompts first, then load generator.
This avoids holding the text encoder (~24GB) and the video generator
in memory at the same time.
"""
def encode_all_prompts(self, prompt_files):
# 加载文本编码器 → 编码 → 释放
text_encoder = create_text_encoder_wrapper(...)
# ... 编码所有 prompt ...
del text_encoder
torch.cuda.empty_cache()
def load_generator(self):
# 加载生成器 + VAE + 记忆管线
self.generator = create_ltx2_wrapper(...)
self.video_vae, self.audio_vae = create_vae_wrappers(...)这个设计非常巧妙------在同一块 GPU 上交替加载不同模块,峰值显存只需 46-50GB 而不是 70GB+!
🔧 记忆银行管线
两种管线对应不同场景:
BidirectionalAVInferencePipeline:单镜头音视频推理BidirectionalMemoryAVInferencePipeline:多镜头记忆推理(核心管线)
记忆银行核心组件 PairedAudioVideoMemoryBank:
- 视觉记忆:从已生成镜头中提取人物关键帧,编码为条件输入
- 音频记忆:从已生成镜头中提取声音梅尔频谱窗口
- 两者配对存储,确保新镜头中人物外观和声线与之前一致
8. 适用场景与优缺点
✅ 最佳适用场景
| 场景 | 说明 |
|---|---|
| 🎬 短片/广告视频生成 | 多镜头叙事视频一键生成 |
| 📱 社交媒体内容创作 | 快速生产高质量视频内容 |
| 🎮 游戏/动画预可视化 | 快速生成故事板级视频 |
| 🎙️ 视频配音/音效生成 | 音画同步联合生成 |
| 🤖 交互式视频创作 | 对话式 Agent 实时编辑视频(规划中) |
⚖️ 优缺点对比
| 优点 | 缺点 |
|---|---|
| 🟢 5 分钟级长视频一次生成 | 🔴 仅限学术/非商业用途(LTX-2 License) |
| 🟢 跨镜头人物外观+声线一致 | 🔴 I2V(图到视频)暂不支持 |
| 🟢 音画同步联合输出 | 🔴 模型权重总大小约 70GB(46+24) |
| 🟢 DMD 蒸馏 7.5x 加速 | 🔴 最低需要 48GB 显存 GPU |
| 🟢 两阶段显存热换,48GB 可跑 | 🔴 短视频音频质量略逊 Wan 2.6 |
| 🟢 已有 ComfyUI 插件支持 | 🔴 Prompt 需先增强,裸写效果较弱 |
| 🟢 YAML + CLI 全参数可调 | 🔴 Director Agent 和超分模块尚未发布 |
9. 总结
JoyAI-Echo 是京东在长视频生成领域的一次重磅出击,用两个核心创新解决了行业痛点:
- 跨模态记忆银行------让每个新镜头「记住」前面镜头的人物外观和声线,5 分钟视频全程不崩脸不变调
- DMD 蒸馏------9 步降噪实现 7.5 倍加速,分钟级视频推理不再是奢侈品
再加上两阶段 GPU 显存热换设计,48GB 显存就能跑完整管线,以及已有 ComfyUI 插件生态,实用性相当不错。
当然也有遗憾------非商业 License 限制了商用场景,I2V 和 Director Agent 还在路上,70GB 模型权重下载门槛不低。但作为长视频生成的前沿探索,JoyAI-Echo 确实开创了长程跨模态一致性 + 实时推理 + 对话交互 + 高分辨率输出四者兼得的新范式。
推荐指数:⭐⭐⭐⭐ (4/5)
技术创新扎实、评测碾压、生态初成,但非商业 License 和高硬件门槛是实打实的门槛。
原文链接 :https://github.com/jd-opensource/JoyAI-Echo
项目主页 :https://echo-team-joy-future-academy-jd.github.io/Echo-LongVideo-Page/
License:LTX-2 Community License Agreement(学术研究和非商业用途)
标签:#京东 #JoyAI-Echo #长视频生成 #AIGC #跨模态记忆 #DMD蒸馏 #开源项目 #视频生成
分类:原创文章