一、一个几乎无法复现的现网故障
某运营商数据中心部署了一套基于DPDK开发的100G高性能交换机。
系统采用:
- 每Queue绑定一个PMD Worker;
- 无锁数据平面;
- Session采用DPDK Hash管理;
- 控制面负责动态下发转发表。
系统已经稳定运行半年。
累计转发数据包超过数千亿。
就在所有人都认为系统已经足够稳定时。
现场开始反馈:极偶尔:某些新建立的业务流第一个数据包会被错误丢弃。
第二个包:立即恢复正常。
整个异常持续时间不到1毫秒。
概率低到一天可能只发生一两次。
查看所有监控。
全部正常。
| 指标 | 状态 |
|---|---|
| PMD CPU | 100% |
| RSS | 正常 |
| RX Queue | 正常 |
| TX Queue | 正常 |
| NIC Error | 0 |
| Session数量 | 正常 |
控制面日志:
显示:Session已经创建成功。
数据面日志却偶尔打印:
Session Not Found几百微秒以后再次查询Session:又能够正常找到。
整个现象像极了:"Session凭空消失。"
核心知识点一
真正困难的故障往往不是100%复现。
而是:百万分之一概率。
因为概率越低。越说明问题不是业务逻辑。
而更可能来自底层硬件行为。
二、第一轮排查:怀疑Hash
由于日志显示:Session查询失败。
团队第一反应:Hash出了问题。
于是增加统计。
记录:
rte_hash_lookup_data()所有返回值。
连续运行48小时。
结果:Hash没有任何异常。
Bucket没有冲突。
Hash Miss始终为0。
说明:
Hash没有问题。
三、第二轮排查:怀疑RCU
继续分析。
控制面:负责创建Session。
数据面:负责查询Session。
因此:又怀疑是不是RCU同步存在问题。
继续检查版本API。
Grace Period全部正常。
RCU没有异常。
核心知识点二
当Hash RCU 锁。
全部排除以后。
真正应该怀疑的是:数据什么时候真正对其它CPU可见?
注意:
这里讨论的:已经不是:数据有没有写。
而是:什么时候能够被另一个CPU看到。
四、第三轮排查:代码没有问题
继续阅读控制面:更新流程。
代码非常简单。
例如:
session->action = action;
session->counter = counter;
session->flags = READY;
publish(session);逻辑完全正确。
没有空指针。
没有竞争。
没有锁。
没有异常。
但是数据面偶尔却看到:
flags = READY
action = NULL这意味着:
CPU居然先看到了READY。
却没有看到真正的数据。
这几乎违背所有人的直觉。
核心知识点三
很多开发者默认认为:
代码按照书写顺序执行。
实际上现代CPU并不保证这一点。
五、重新认识CPU
很多教材都会画出:
这样的执行过程:
Store A
↓
Store B
↓
Store C于是:大家自然认为:CPU一定也是这样执行。
实际上现代CPU为了提高吞吐。
采用:Out-of-Order Execution(乱序执行)。
真正发生的事情可能是:
Store B
↓
Store A
↓
Store C甚至:
CPU已经完成Store。
另一个核心仍然看不到最新数据。
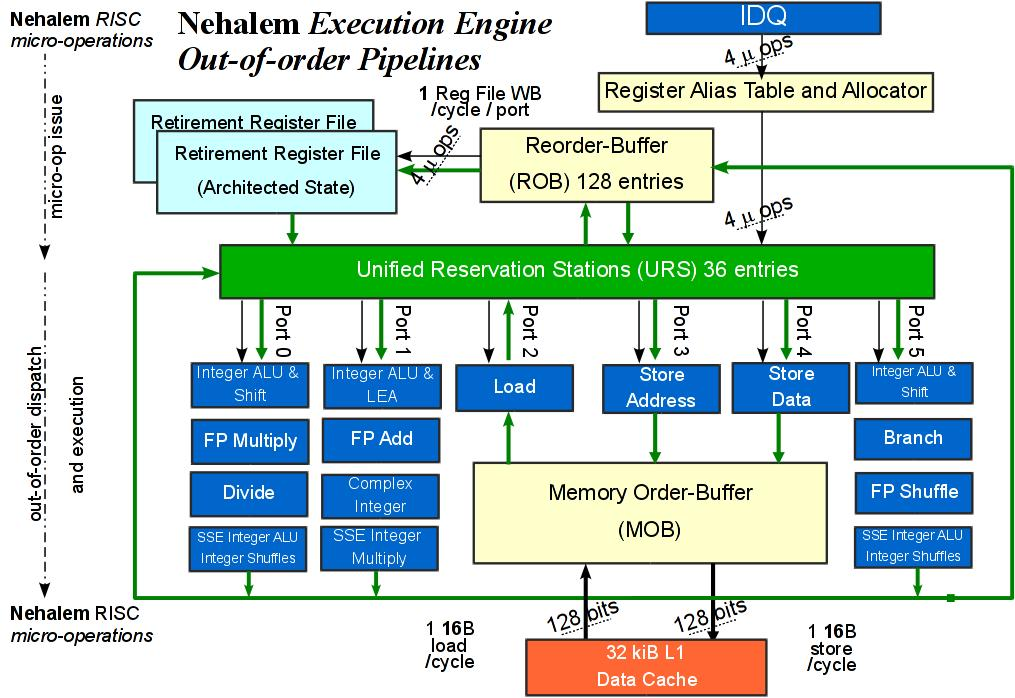
六、为什么CPU要乱序?
如果:
CPU严格按照程序顺序执行。
很多流水线都会空闲。
例如:
Load
↓
等待内存
↓
继续执行CPU大量时间浪费等待。
于是:
现代处理器开始提前执行后面的无关指令。
例如:
Store A
Store B
Load CCPU可能先完成Load C。
再回来执行Store A。
整个过程:
对于单线程结果完全正确。
但是:
对于多核心另一个CPU:观察到的顺序就可能发生变化。
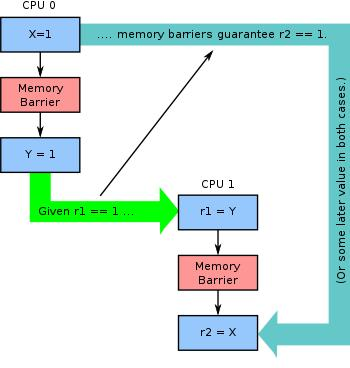
核心知识点四
程序执行顺序 ≠ CPU执行顺序 ≠ 其它CPU观察到的顺序。
这是理解:Memory Ordering最重要的一句话。
七、问题开始指向Memory Ordering
继续检查:Session发布流程。
发现最后一步:
只是:
publish(session);整个过程没有任何Barrier。
也没有Memory Fence。
控制面认为数据已经全部写完。
于是通知Worker:可以开始使用。
但是:
CPU真的保证其它核心一定已经看到这些写操作了吗?
真正的问题开始指向:Memory Ordering......
(未完待续)