「极端工况安全驾驶有了刚需方案」
目录
[01 行业两大原生痛点,倒逼事件智驾方案落地](#01 行业两大原生痛点,倒逼事件智驾方案落地)
[1. 传统RGB-VLM天生场景短板](#1. 传统RGB-VLM天生场景短板)
[2. 老旧事件视觉方案能力断层](#2. 老旧事件视觉方案能力断层)
[3. 行业长期缺少标准化事件智驾数据集](#3. 行业长期缺少标准化事件智驾数据集)
[02 复刻完整智驾链路的多模态基准](#02 复刻完整智驾链路的多模态基准)
[03 两大核心模块破解模态融合难题](#03 两大核心模块破解模态融合难题)
[04 指标客观解读:亮眼成绩与固有边界](#04 指标客观解读:亮眼成绩与固有边界)
[05 行业价值与现存短板](#05 行业价值与现存短板)
[06 写在最后](#06 写在最后)
过去的事件相机研究,几乎全部停留在检测、分割、光流和跟踪等低层视觉任务。它能告诉你"有东西在动",却回答不了"那个东西是什么、它要往哪去、我该怎么办",更不用说支撑车辆轨迹预判、行车路径规划等高阶驾驶决策了。
这种"底层感知强、高层决策弱"的断层,让事件相机长期游离于自动驾驶主流的感知-决策链路之外。
2026年6月,新加坡国立大学、香港科技大学(广州)、地平线等机构联合发布的EventDrive,第一次把这个问题推到了台面上。
它做了一件事:把事件视觉能力完整地嵌入了自动驾驶感知-理解-预测-规划的全决策链路。不再是"又多了一个传感器",而是让事件相机第一次拥有了参与驾驶决策的"语言能力"。
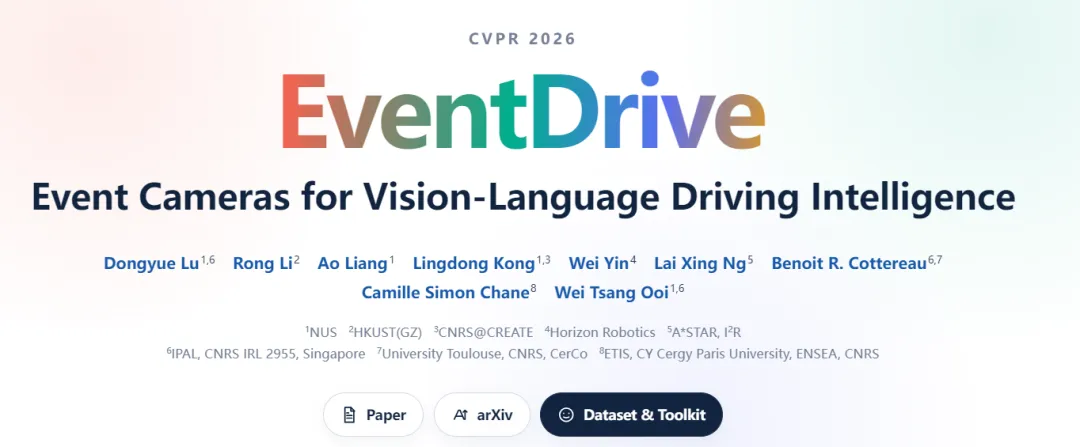
EventDrive带来了471,543个真实事件-RGB-语言配对样本,以及端到端融合模型EventDrive-VLM------这是业内首个贯穿智驾全闭环的事件视觉语言基准。
从感知层(天气/路况/能见度判断)到理解层(目标定位与状态识别),从预测层(周边车辆1秒内行为预判)到规划层(自车5秒行车轨迹输出),EventDrive用一套统一的数据集和模型范式,打通了从"看见"到"决策"的完整链条。
此前事件相机研究要么只做图像分割检测,要么仅做简单图文问答,从未支撑车辆轨迹预判、行车路径规划等高阶驾驶决策,EventDrive精准补上了行业长期技术空白。
01 行业两大原生痛点,倒逼事件智驾方案落地
想要读懂这项工作,先要认清纯帧VLM、传统事件算法各自无法突破的技术天花板,二者都无法支撑全域安全自动驾驶。
图| EventDrive 全自动化标注流水线示意图
1. 传统RGB-VLM天生场景短板
LLaVA、Qwen、InternVL等主流帧模型依赖固定曝光图片,存在致命缺陷:
- 高速行驶画面严重模糊,无法判断车辆转向、加减速趋势;
- 逆光隧道、夜间强光、雨雪天气极易出现画面过曝死黑,丢失路标、红绿灯、障碍物信息;
- 单帧静态画面缺失毫秒级连续动态信息,只能猜测交通参与者意图,行为预测误差极高。
这类模型晴天城市道路表现合格,但事故高发的夜间、高速、隧道场景,感知精度会断崖式下跌。
2. 老旧事件视觉方案能力断层
事件相机微秒级异步捕捉亮度变化,天生无运动模糊、超高动态范围、极低延迟,完美适配动态驾驶场景。但过往研究存在两大核心断层:
- 任务断层:绝大多数算法仅做光流、检测、分割底层感知,无法对接运动推理、行车规划等高阶决策,输出不了车辆可用控制指令;
- 模态断层:EventGPT等早期事件VLM只用单事件模态,丢失色彩、纹理、交通标识静态语义,路牌、车型识别准确率大幅下降,仅支持简单图文描述,无法完成轨迹预判、路径规划复杂推理。
简言之,RGB看得清静态画面却跟不上高速运动,事件抓得住动态变化却分不清物体语义,行业长期缺少二者深度融合、贯穿完整驾驶逻辑的统一框架。
3. 行业长期缺少标准化事件智驾数据集
DSEC、M3ED等现有事件数据集规模小、场景单一,只有底层视觉标注,没有驾驶问答、轨迹规划语言标签,无法训练高阶决策VLM。
EventDrive整合三大真实道路数据源,构建47万组三元配对样本,拆分感知、理解、预测、规划4大类17项驾驶任务,专门搭建低光模糊困难测试集,填补了事件智驾评测基准空白。
02 复刻完整智驾链路的多模态基准
整套数据集统一时序对齐、标注规范,所有样本同步留存事件流、RGB画面、文本监督三类数据,分层匹配自动驾驶全业务流程:

图| EventDrive 基准整体总览图
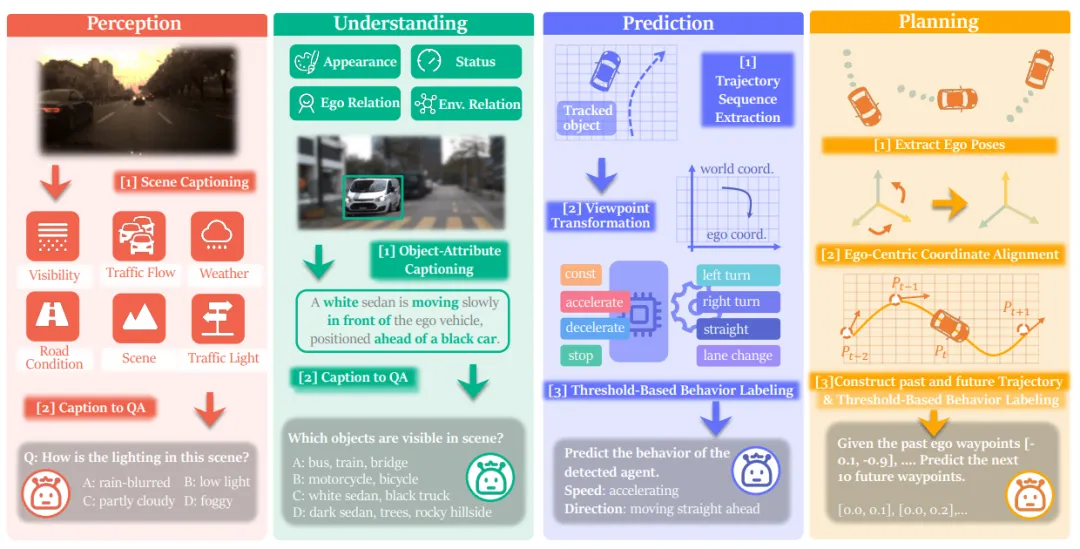
- 感知层:判断天气、路况、能见度、交通灯状态等全局环境信息,RGB模型低光场景准确率暴跌20%,融合模型可稳定保持性能。
- 理解层:识别车辆、行人外观、位置、运动状态,纯事件模型定位mIoU不足10,双模态融合方案直接提升至72.56。
- 预测层:预判周边参与者1秒内加减速、变道意图,纯帧模型速度预测准确率不足20%,融合模型突破42%。
- 规划层:输出自车5秒行车路点轨迹,融合模型轨迹L2误差仅3.66米,远优于纯帧模型8米以上误差,大幅降低高危场景行车风险。
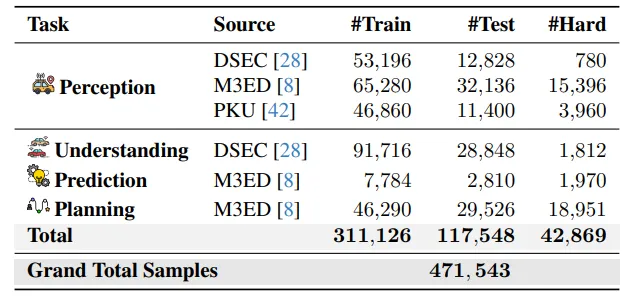
图| Event 数据集各任务训练 / 测试 / 困难集样本统计表
数据集包含31万训练样本、11万测试样本,额外4.2万夜间、模糊极端困难样本,采用半自动化高精度标注流水线,是全球首个打通感知到规划全链路的大规模事件驾驶基准,可统一全行业模型评测标准。
03 两大核心模块破解模态融合难题
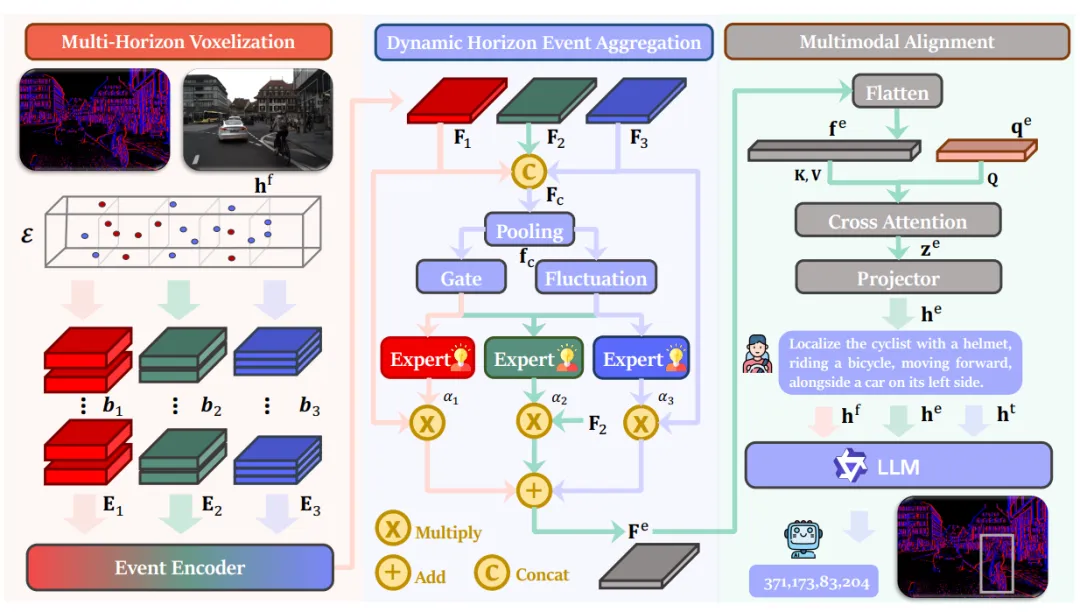
模型基于Qwen2.5-VL-7B主干搭建,新增两大专属模块,不改动原有RGB编码器,极低成本即可完成工程迁移,完美解决事件时序杂乱、跨模态语义错位两大行业难题。
图| EventDrive-VLM 完整模型架构图
1. 多尺度MoE动态事件编码器
事件流疏密随车速剧烈变化,固定切片处理要么丢失高速细节,要么冗余算力浪费。模型用20/50/100三档时间分桶提取特征,通过混合专家网络自适应匹配场景:高速场景优先短时高精度时序信息,平稳路况选用长时序粗粒度特征,像自带自适应快门,兼顾速度与算力平衡。
2. Event Q-Former跨模态对齐模块
异步稀疏事件与稠密图像、文本嵌入天然割裂,直接拼接会让模型偏向RGB静态特征,浪费事件动态优势。该模块用可学习查询向量筛选驾驶关键事件特征,过滤噪声后统一嵌入维度,和图像、文本token无缝对接LLM,定位与预测精度提升近5%,同时加快推理速度。
3. 两阶段渐进训练
先冻结大模型与RGB主干,完成事件-语义初步对齐;再解冻底层Transformer,全量多任务指令微调,平稳解决事件模态难以适配通用大模型权重的行业痛点。
04 指标客观解读:亮眼成绩与固有边界
横向性能对比
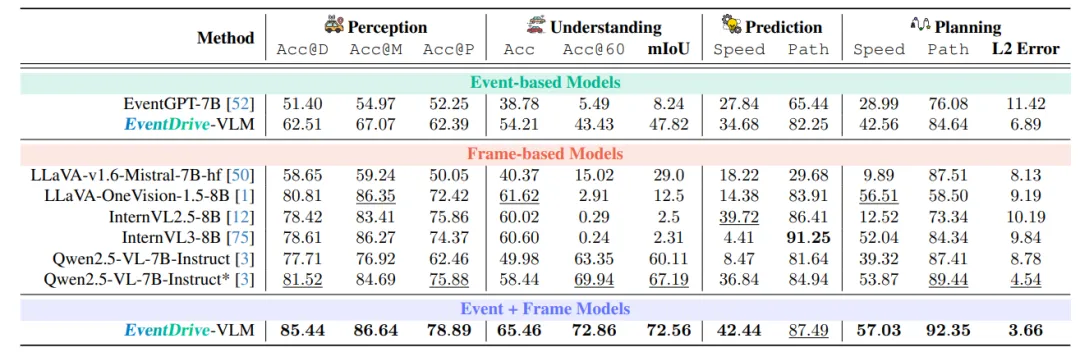
图| 全任务综合评测对比总表(纯事件 / 纯帧 / 事件 + 帧三类模型)
- 纯事件模型:动态预测尚可,但色彩、标识、物体定位精度极差,无法适配日常日间道路;
- 纯帧VLM:晴天表现优异,极端困难场景性能暴跌,动态行为预判能力严重不足;
- EventDrive-VLM:全任务均衡最优,标准集感知准确率85.44%,低光困难集仍保持82.43%,兼顾静态识别与动态时序推理,泛化能力远超同类事件模型。

图| 真实路况定性效果对比图(纯帧 VLM vs EventDrive-VLM)
数据天然局限
所有结果均来自公开城市道路数据集,缺少暴雪、浓雾等极限天气场景;评测以2D分类、轨迹误差为主,未覆盖3D空间感知、碰撞安全、行车平顺性等车规指标;7B小参数量模型,难以应对复杂多车博弈长时序规划;同时依赖事件相机硬件,受车载硬件普及进度限制落地节奏。
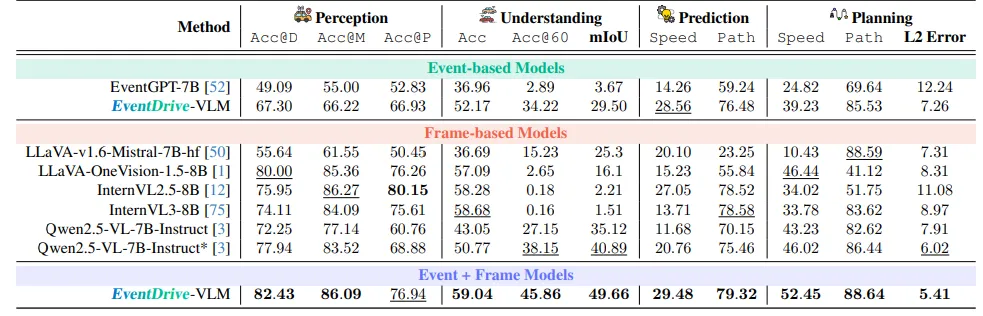
图| 低光 / 运动模糊困难集评测结果表
和小米世界模型路线区分
二者是智驾系统互补搭档:

图| Xiaomi Auto World Model 效果展示
小米世界模型主打3D重建+视频生成,负责后台仿真、长尾数据扩充;
EventDrive-VLM主打事件+RGB实时融合,负责前台在线感知、短期行车决策。
未来量产智驾,必然是二者协同部署。
05 行业价值与现存短板
核心行业贡献
- 把事件视觉从底层检测,拓展至完整智驾决策闭环,统一全行业事件VLM评测体系,大幅降低领域研发门槛;
- 通用融合架构可无缝适配所有开源视觉大模型,车企算法团队零门槛复用;
- 用量化数据证实事件模态不可替代性,为整车多传感器硬件选型提供硬核依据;
- 单模型打通感知、预测、规划全任务,精简车载软件栈,降低算力消耗。
现阶段短板
极端长尾场景数据不足;未融合激光雷达实现3D空间感知;缺少车载芯片轻量化部署优化;仅支持短期轨迹规划,无法适配长距离复杂路口行车;未融合毫米波、雷达等全车传感器,距离整车融合系统仍有差距。
06 写在最后
当下绝大多数智驾大模型都围绕RGB画面优化,普遍忽视夜间、高速模糊等高事故场景感知缺陷,EventDrive精准击中行业核心痛点,证实事件相机不是实验室小众技术,而是极端工况安全驾驶的刚需硬件。
自动驾驶未来一定会双线并行:世界模型负责后台仿真迭代数据,事件VLM负责前台实时安全决策。
二者深度配合,才是高阶自动驾驶落地的完整解法。
Ref
论文标题:EventDrive: Event Cameras for Vision-Language Driving Intelligence,