设备分类
按用途:人机交互设备、存储设备、通讯设备、协处理设备
按速度:告诉设备、低速设备
按传输单位:块设备、字符设备、其他设备
按物理存在性:物理设备、虚拟设备
仅在概念上存在的设备。它有着和真实设备一样的接口,并对操作做出反应。
但找不到一个物理实体和它对应。又叫逻辑设备。
数据传输方式:直接传输设备、轮询设备、中断设备、DMA设备
共享类型:共享设备、假脱机设备、独占设备
问题一 什么样的设备适合作为直接传输设备?
随时准备好读写,且响应迅速的设备,如逻辑电平等。
问题二 什么设备适合作为直接内存访问传输设备?
数据量大或I/O操作频繁的设备。
SPOOLING
Spooling技术的本质,是把**"对设备的直接控制"** 替换为**"对磁盘文件的读写"**。只要满足以下两个条件,任何独占设备理论上都能被虚拟化:
-
数据是可存储的:设备处理的数据必须能被完整地写入磁盘(输入井/输出井),而不能是"即时交互"的。例如,打印机打印的内容可以存成文件,但鼠标的移动轨迹无法被"存起来"稍后执行。
-
操作是可排队的:设备的工作流程必须是"先来先服务"或"按顺序处理"的。如果设备需要随机、即时反馈,则无法排队。
结论: 从纯算法角度看,只要我们把设备的所有操作抽象为"数据流",就可以用磁盘缓存+后台进程来模拟。所以理论上,几乎所有独占设备(打印机、绘图仪、磁带机)都具备转换潜力。
1. 什么是假脱机技术(Spooling)?
Spooling 全称是 Simultaneous Peripheral Operations On-Line(同时外围设备联机操作)。
-
"假" 指的是:设备物理上只有一个,但系统通过软件手段,让每个用户都感觉自己"独占"了这台设备。
-
"脱机" 指的是:输入/输出操作不再直接由CPU控制,而是由磁盘作为中间缓冲,CPU只负责把数据"扔"到磁盘,然后继续做别的计算任务。
工作流程(以打印机为例):
当多个进程同时请求打印时,系统不会让打印机立刻打印,而是:
-
将每个进程的打印数据写入磁盘上的一个**"输出井"**(一个专门的文件区)。
-
系统给每个打印任务生成一个**"打印请求"**,排队等待。
-
打印机守护进程(后台进程)从队列中按顺序读取数据并打印。
关键点: CPU在处理打印任务时,不直接等待打印机,而是等待磁盘写操作(速度快得多),所以CPU效率大幅提高。
2. 假脱机技术的三个核心组件
为了实现上述功能,系统通常维护以下结构:
| 组件 | 作用 |
|---|---|
| 输入井/输出井 | 磁盘上预留的存储区域,用于暂存输入/输出数据。 |
| 输入缓冲区/输出缓冲区 | 内存中的缓冲区,用于暂存数据,减少磁盘I/O次数。 |
| 守护进程(Daemon) | 一个后台进程,负责从队列中取出请求,并实际控制物理设备工作。 |
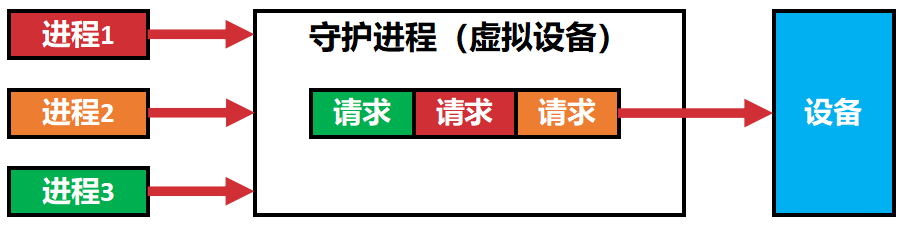
对于每个假脱机设备,我们都会启动守护进程来管理队列和操作I/O,而其他进程则把这个进程当成虚拟设备并操作它。
其他请求进程发起请求后立刻收到正在处理的回复,然后由守护进程维护队列处理,成功后主动通知调用进程。因此是阻塞的异步接口。
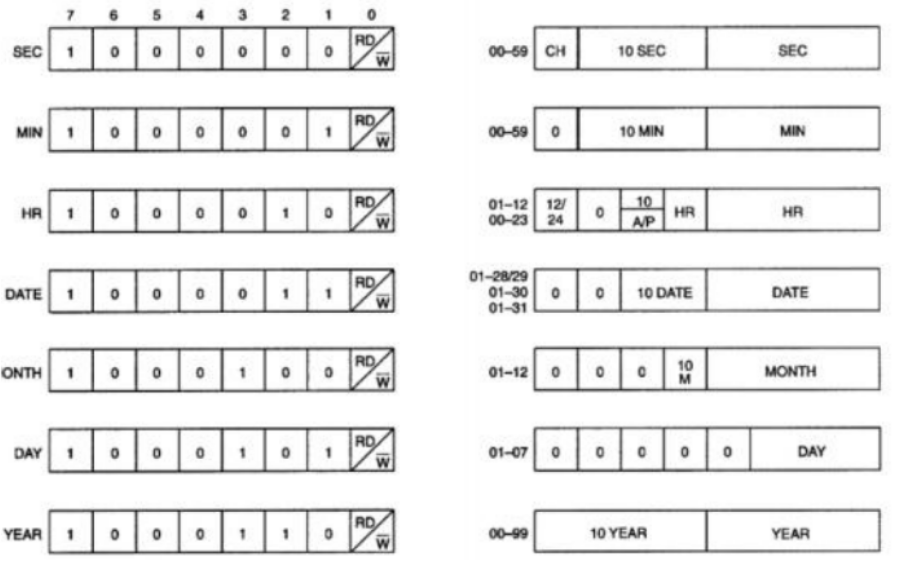
字符设备:实时时钟
定时器------带上限的计数器。
两组D触发器,一组用来计数,一组用来存上限,一个比较器持续比较二者,溢出置零
定时器中断------定时器置零的时候发送中断,让OS重启计时器
万年历------内部是一系列串联的定时器,上一级的溢出信号作为下一级定时器的输入。
能否找到一种方法,用一个定时器模拟出一批定时器?
软定时器------以系统定时器作为时基。每一个系统时刻检查所有软定时器看看有没有超时。
这样工作量很大。用红黑树存储定时器,只需检查最早到期的定时器即可。
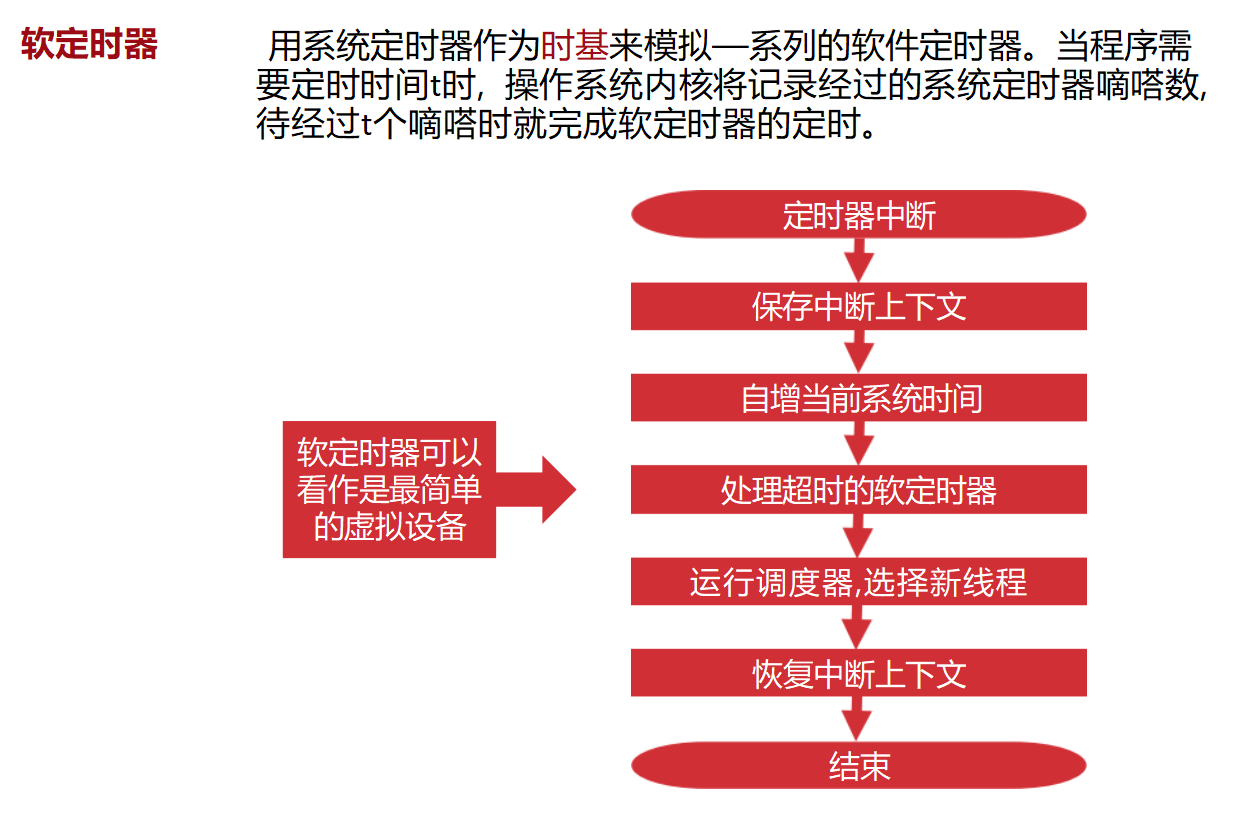
第一阶段:硬件"滴答"一声响了(触发中断)
系统定时器芯片 每震动一次,就会向CPU发送一个硬件中断信号。
第二阶段:内核"记账"与"检查闹钟"
-
保存中断上下文: CPU赶紧把当前正在运行的程序(线程)的状态(寄存器、程序计数器等)存起来。
-
**自增当前系统时间:**完成"时间流逝"的计数。
-
处理超时的软定时器(最关键的一步!):
-
假设你写了一个代码:
sleep(100),意思是要等100个"滴答"后才醒来。 -
操作系统内核里有一张"软定时器列表"(相当于一组闹钟)。系统现在会去查这张表,看看有没有哪个"闹钟"的时间到了。
-
如果发现时间到了,就把这个休眠的程序标记为"可以唤醒了",或者触发你写的定时器回调函数。
-
第三阶段:既然到点了,该谁干活了?(调度)
-
运行调度器,选择新线程: 刚才如果唤醒了某个程序,或者刚才那个程序本来时间片就用完了。这时候,操作系统的"大管家"(调度器)就要出来决定:"既然刚才那个程序时间到了,接下来该把CPU给哪个程序运行呢?" 调度器会选出一个优先级最高、准备好的新线程。
-
恢复中断上下文: 既然决定了让新线程(或者刚才被打断的老线程)继续跑,CPU就把之前保存的现场重新恢复。
-
结束: 中断处理完毕,CPU继续执行刚刚选中的那个线程的代码。
块设备:机械硬盘
读写单位:簇------扇区的集合
磁盘的共享:
磁道:越靠近的磁道之间的访问延迟更低,同时从内圈往外圈读访问延迟比从外圈往内圈读低
同一个磁道,从前往后读快,从后往前读慢。一个簇内部的写则最好一次写完。
模块一:缓冲(Buffer)与 缓存(Cache)的区别
-
缓冲区(Buffer) - 速度不匹配
-
作用 :解决速度不匹配 (CPU极快,硬盘极慢)和数据单位不一致的问题。
-
核心特点 :先进先出(FIFO)。
-
磁盘优化 :系统不会一个请求来了就立刻移动磁头,而是把请求塞进"操作缓冲区"。同一个"簇"的读写请求合并 ,并按照磁道位置进行重新排序。这为后面的"磁盘调度算法"做好了准备。
-
-
缓存(Cache) -减少读盘
- 作用 :保存副本,重用。
缓存作为缓冲区的改进,增加了数据存留的功能。缓冲缓存就能解决速度不匹配和副本宠用的问题。
模块二:缓冲区的数据结构与组织方式
既然有这么多读写请求,内存里是怎么把它们组织起来的?
-
单缓冲 / 双缓冲:最基础的结构。双缓冲允许一边读,一边写,从而实现并行,效率更高。
-
环形多缓冲(重点):
-
这是最常用的结构,就像一个摩天轮,有多个"车厢"(缓冲区)。
-
队头指针(读,取走数据) 和队尾指针(写,放入数据)。
-
读快于写 (头追上尾) →→ 队列空;写快于读(尾追上头) →→ 队列满。
-
-
缓冲池(Buffer Pool):
-
操作系统不只为硬盘设置专属缓冲,而是提供一个全局共享的缓冲池。
-
谁要用,就在池子里"划一块"缓冲区,用完归还。这极大地节约了内存,提高了整体利用率。
-
模块三:磁盘调度算法 - 物理上的"谁先动"
1. 先来先服务(FCFS)
-
做法:谁先来,就先去哪个磁道,不管远近。
-
缺点:磁头会疯狂左右乱跑,效率极低。
2. 最短寻道时间优先(SSTF)
-
做法 :磁头当前位置在哪,就选择距离当前位置最近的那个请求去服务。
-
缺点 :如果一直有离当前位置很近的新请求到来,那么离得远的磁道(比如最外圈或最内圈)就永远得不到服务 。这就叫**"饥饿现象"**。
3. 电梯扫描算法(SCAN 及其变种)
将队列中的请求排序,从头扫描到尾,然后再从头开始
基于回程时是否响应 ,以及是否扫描到底,有以下四个变种。
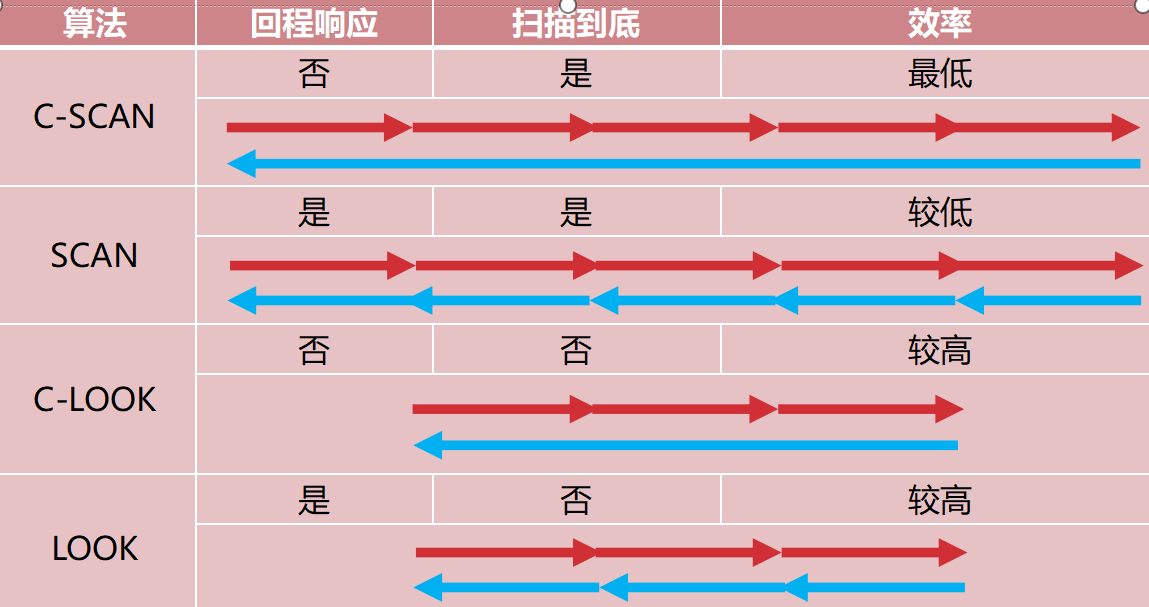
1. 为什么叫"循环"(Circular)?
-
普通 SCAN(电梯算法) :就像一部正常的电梯。它从一楼到顶楼,然后原路返回 (下降),下降途中继续响应请求。来回都干活。
-
C-SCAN(循环扫描) :它不原路返回 。它只朝一个方向(比如从外向里)扫描。一旦扫到了最内侧,它**"啪"的一下瞬移(或者说是绕一圈)**回到最外侧的起点,重新开始从头往里扫。
也就是说,它的运动轨迹是一个"从起点到终点,然后瞬移回起点"的无限循环,所以叫 Circular(循环)。
驱动程序(Driver)------ 操作系统的"万能翻译官"
一般运行在内核态。驱动程序是设备依赖的。这是由于它们直接控制设备,与设备特性紧密相关。一旦更换设备,就需要更换驱动程序。驱动程序一般由设备厂商提供。
设备号:主设备号(厂商号)用来标记厂商,次设备号(设备号)用来标记具体产品
驱动程序根据设备的属性来查找设备。
驱动程序的功能
查找设备
扫描并检测硬件改动,识别应当识别的设备。
初始化设备
初始化并对设备进行必要设置 ,注册中断ISR。
响应设备请求
响应设备的中断等,在设备运行中与设备交互。
响应软件请求
执行操作系统和应用程序下发的设备操作指示。
USB如何识别设备------描述符 考点 ☆
USB设备的一切识别和配置操作都是基于描述符。描述符包括设备描述符、配置描述符、接口描述符和端点描述符四个层次,抽象程度依次递减。
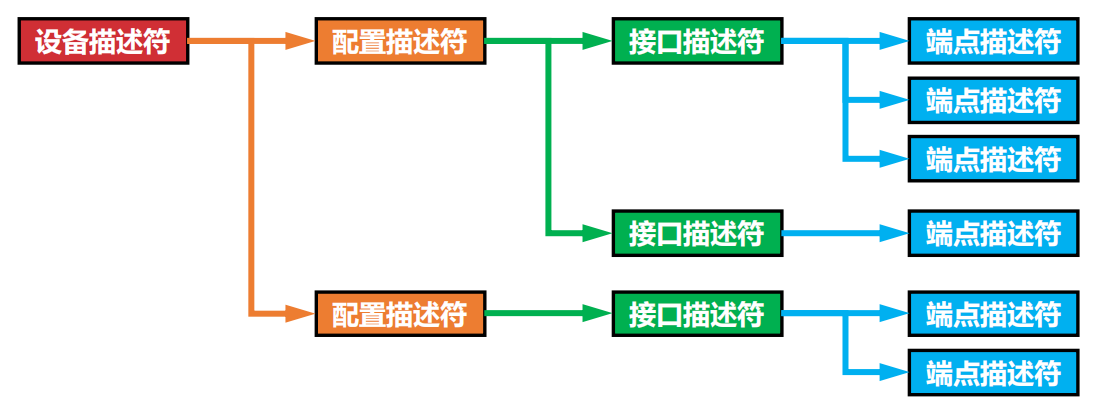
上述设备包括两种工作模式(配置)第一种配置包括两个接口(子功能),其中第一个子功能由三个通信端点(单向数据管道)组成。(输入输出就需要两个端点)
主机是如何识别设备的?
设备描述符
USB设备的识别和驱动匹配采取结构化的设备描述符。主机会定期扫描USB端口,一旦它发现有设备被插入,就发出控制传输请求,要求读取设备的设备描述符。
靠设备和厂商编号匹配设备
之后,主机就可以对设备的基本属性尽在掌握了,也知道匹配何驱动
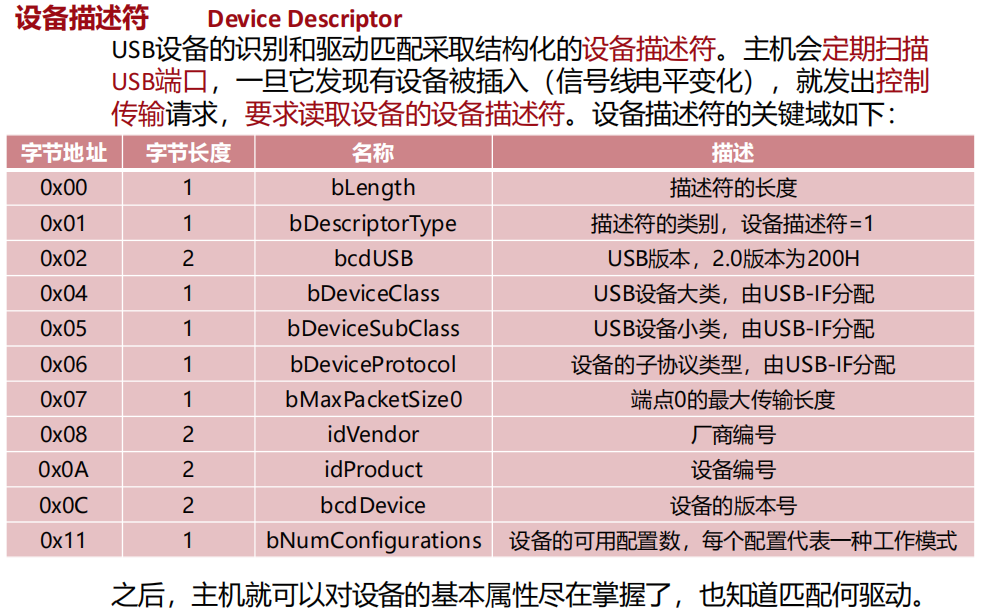
配置描述符
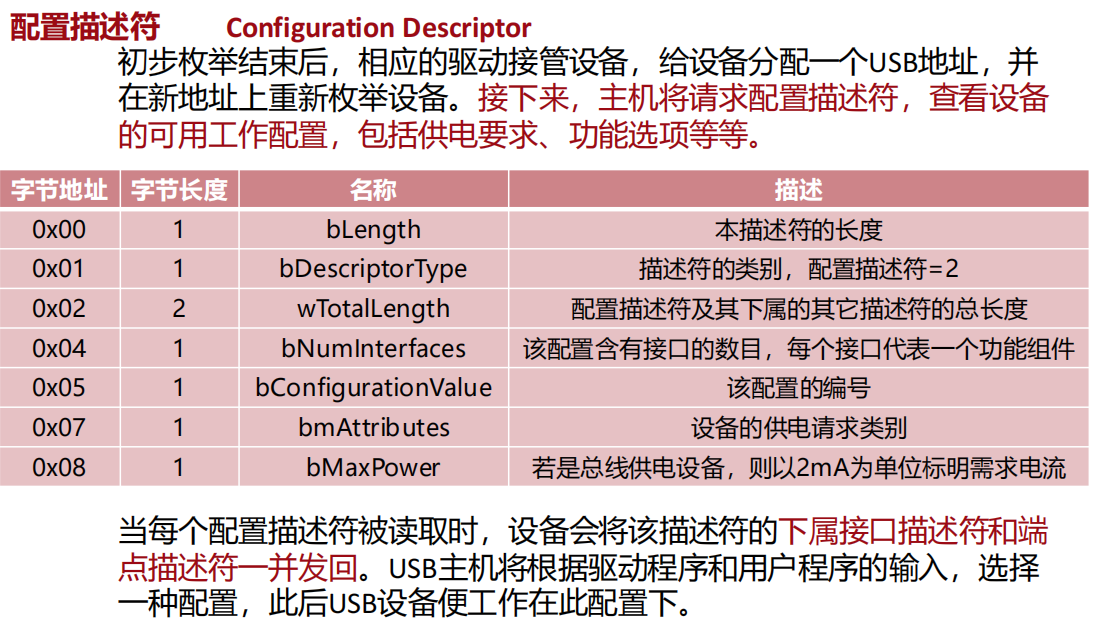
接口描述符
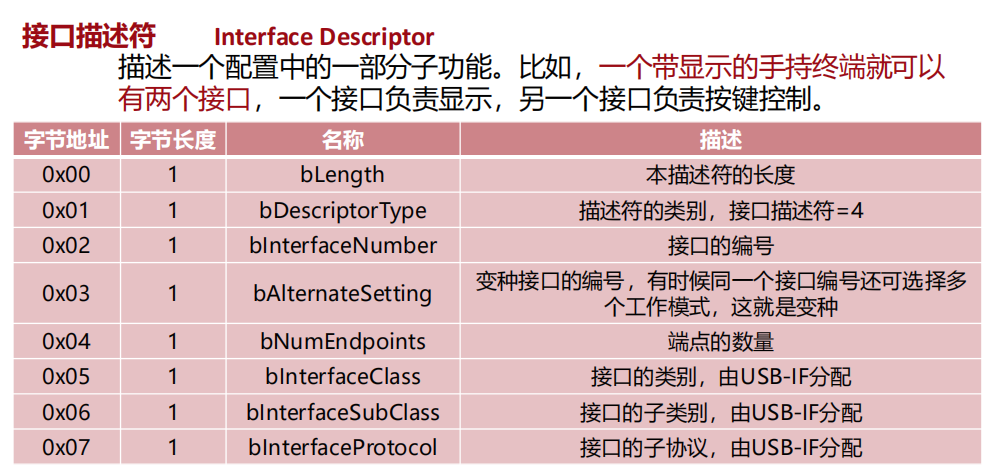
端点描述符
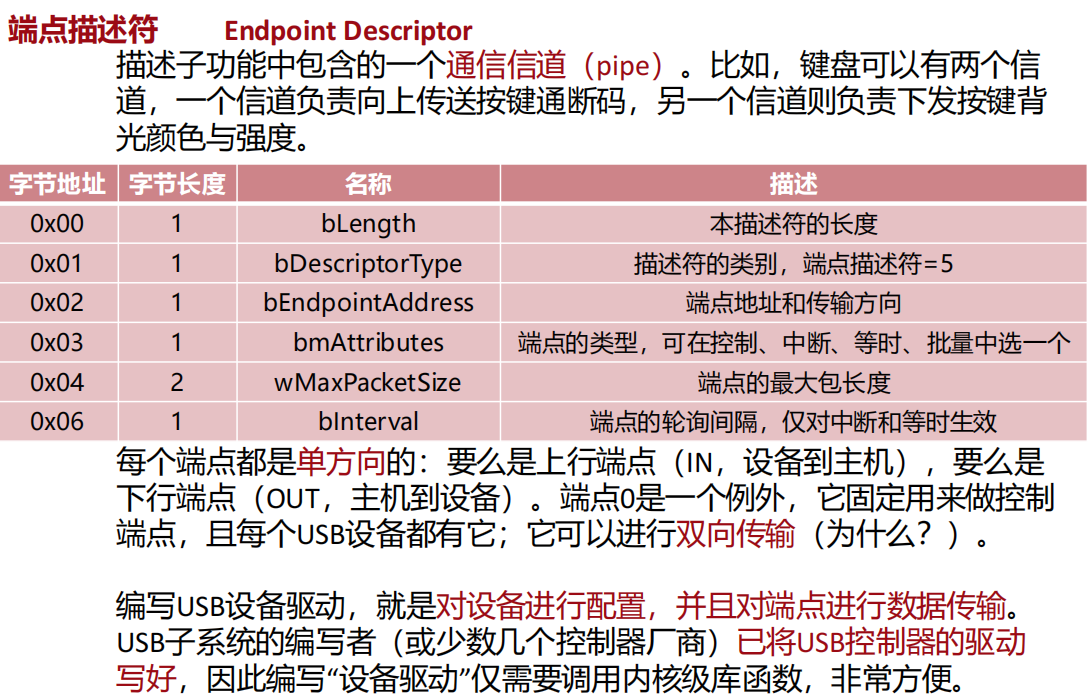
设备操作的全景 ------ 一次完整的 I/O 脱胎换骨的过程
第一步:正常流程(从左到右,再到左)
-
用户进程(红色块) :你的程序(比如Word文档)发起了
fwrite()或read()请求。这只是一条简单的指令。 -
运行库(橙色块) :系统将你的请求包装成**"系统调用(System Call)"** 。注意,这里有一条红色的虚线 ,这是用户态和内核态的边界。跨越这条线,程序就从"普通权限"变成了"系统特权"。
-
系统内核(绿色块 - I/O子系统) :内核收到了请求。它会先查一下缓存(Cache)。如果数据正好在内存里,直接返回,不走下面。如果不在,就会交给驱动程序去办。
-
驱动程序(蓝色块):驱动程序收到内核的指令,去真正读写硬件控制器的寄存器,发起物理操作。
-
数据返回(箭头向右再向左) :硬件把数据给驱动,驱动给内核,内核再通过系统调用**"返回"**给用户进程,结束。
第二步:图下方的"阻塞"问题 ------ 为什么会导致假脱机?
-
图里特别解释了一个概念:阻塞(Blocking)。
-
问题所在 :驱动告诉硬件"去读磁盘"。但是,机械硬盘读数据需要好几毫秒 (机械臂要移动、盘片要旋转),这对于CPU来说极其漫长。
-
后果 :如果程序在这里**"死等"** ,CPU就被浪费了。这就是为什么需要假脱机(Spooling) 。假脱机把用户进程的打印请求直接写到磁盘缓冲区,用户进程立刻返回(不阻塞),而真正的慢速打印操作,交给后台的"守护进程"去排队慢慢做。
第三步:图下方最恐怖的"问题"------ 死锁/永久阻塞
-
现实场景 :你让打印机打印,但打印机没纸了。驱动程序发出了操作,但一直没有**"中断信号(ISR)"**说"我干完了"。
-
操作系统如何解决?
- 设置一个**"超时计时器(Timeout)"**。
中断
第一层:核心概念------为什么要把中断分成"两半"?
问题根源: 中断处理必须极其迅速。如果在处理中断时,CPU一直"关中断"(不响应新中断),那么系统就会错过其他更紧急的信号。
解决策略(分而治之):
既然不能在一个函数里把所有事做完,那就把工作拆成两半:
-
上半部(Top-half / ISR) :"紧急抢救" 。只做必须立刻做的事(比如把数据从硬件寄存器拷贝到内存),做完立刻结束,恢复中断。要求:越快越好。
-
下半部(Bottom-half / kworker) :"善后工作" 。处理复杂、耗时的事情(比如把刚才拷贝进内存的数据,解析、分发,或者唤醒等待数据的进程)。要求:可以被打断,慢慢排队处理即可。
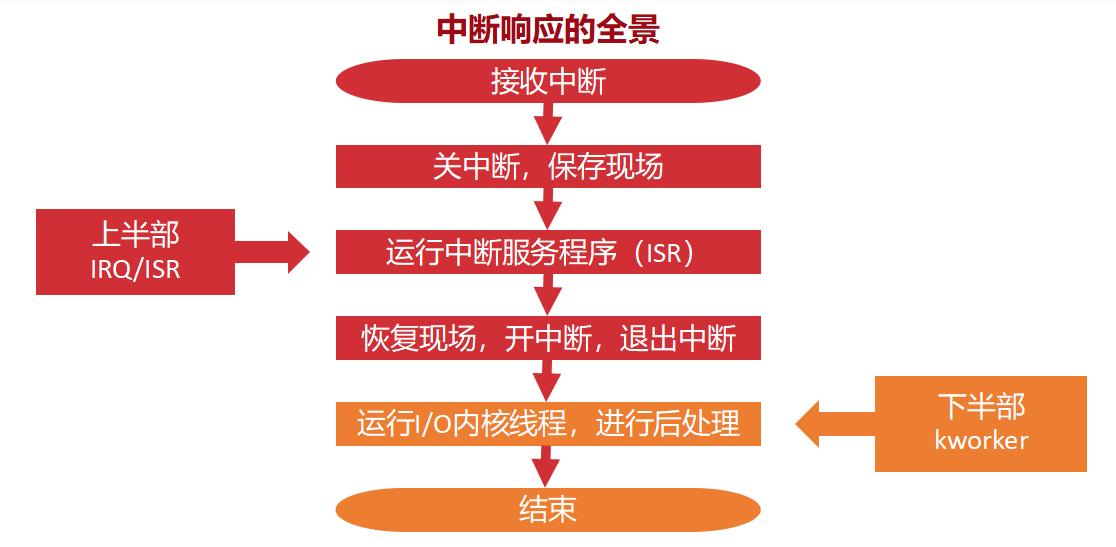
-
接收中断(触发):网卡收到了一个数据包,向CPU发信号。
-
关中断,保存现场:CPU立刻暂停当前运行的程序,关闭响应新中断的能力,把当前的寄存器和执行状态存起来。
-
运行中断服务程序(ISR / 上半部 - 红色块):
-
这就是上半部。
-
核心动作 :网卡驱动读取网卡寄存器,把数据包拷贝到内核内存的缓冲区中。
-
结束 :拷贝完毕后,立刻恢复现场、开中断,退出。整个过程可能只要几十微秒,极其高效。
-
-
运行I/O内核线程(下半部 - 橙色块):
-
这就是下半部 。图中右侧写的
kworker是内核专门用来干杂活的工作线程。 -
刚才的上半部(ISR)在退出前,会给这个
kworker发一个信号(解除其阻塞),让它开始干活。 -
核心动作 :这个内核线程开始慢悠悠地分析刚才拷进来的数据包,进行协议栈解析(比如判断是TCP还是UDP),并最终把数据交给用户程序(比如你的浏览器)。这个解析可能耗时好几毫秒甚至更长,但完全没关系,因为CPU在中断刚结束时就已经恢复运行其他程序了,下半部是在后台并行执行的。
-
换算单位
"M"到底代表 1024×1024还是 106 ,主要取决于你是在处理存储/内存 ,还是网络/传输速率。
只有存储用二进制,因为需要通过地址线寻址。


接口分类
按功能分类:人机交互设备接口(wxWidgets、MFC、WPF)、存储设备接口(文件系统提供的文件操作)、网络设备接口(socket)、显示设备接口(OpenGL、DirectX等图形学库)
按阻塞性分类:阻塞接口、非阻塞接口
当设备无法即时完成操作或返回消息时,线程将阻塞,直到设备返回数据。一定需要操作系统介入
当设备无法即时完成I/O操作或返回消息时,该接口将立即返回,并将当前设备状态报告给调用线程。线程可以以合适的间隔轮询此接口,直到获取到数据。不一定需要操作系统介入。
问题(1):为什么需要非阻塞接口?一切接口都阻塞不好吗?
- 答案:如果一切接口都阻塞,一旦遇到慢速设备,线程卡死在那里。
问题(2):阻塞接口和非阻塞接口,哪个效率高?
- 答案 :"数据量小的设备,阻塞效率高;数据量大则反之。"
按同步性分类:同步接口、异步接口
第一层:核心概念------什么是"同步"与"异步"?
判断标准很简单: "发起请求后,你是自己亲自等结果 ,还是让别人(系统)结果出来时通知你?"
1. 同步接口(Synchronous)------ "亲自去等结果"
- 用同一个接口操作来发起I/O请求和接收I/O结果;当接口返回时,I/O结果必定已知,要么完成,要么失败。
2. 异步接口(Asynchronous)------ "我先走,结果出来了你叫我"
- 用一个接口操作来发起I/O请求,并用回调函数来接收I/O结果;发起请求的I/O接口操作返回时,请求可能还在处理中,I/O结果要等到回调函数被调用时才知道。
回调函数
(1)定义该回调函数
(2)将回调函数的函数指针 和触发它的条件注册给系统
(3)系统将在满足条件时调用它,提醒应用程序某事件发生。
"同步/异步" 与 "阻塞/非阻塞" 到底什么关系?
核心本质:
-
阻塞/非阻塞 讲的是:"我在等数据的时候,CPU能不能去干别的事?" (关注线程的状态)。
-
同步/异步 讲的是:"数据准备好了,是谁来通知我?" (关注消息的通知机制)。
为了让你彻底记住,我们看四个组合(经典的I/O模型):
| 组合 | 通俗例子 | 效率 |
|---|---|---|
| 同步 + 阻塞 | 你网购后,一直守在门口盯着快递,什么都不做,直到快递员把包裹递到你手里。 | 最低(卡死CPU) |
| 同步 + 非阻塞 | 你网购后,每隔5分钟去门口看一眼,没到就回去继续打游戏,到了就拿包裹。 | 中等(浪费CPU轮询) |
| 异步 + 阻塞 | 你网购后,一直守在门口,盯着手机。手机响了你拿包裹(极端少见)。 | 比较少见 |
| 异步 + 非阻塞 | (最完美的境界) 你网购后,正常打游戏、玩手机 。快递员到了给你按门铃(回调),你再下楼拿包裹。 | 最高(高效并发) |
一张图帮你记:
阻塞 = 我的人(线程)在等;
非阻塞 = 我的人(线程)在干别的;
同步 = 我亲自拿结果;
异步 = 系统通过回调把结果塞给我。