仔细想想,你其实每天都在跟哈希打交道------
HashMap里存键值对是哈希,HashSet里去重是哈希,重写equals()时 IDE 唠叨着让你一并重写hashCode()是哈希,下载文件后比对的 MD5 校验值是哈希,登录时密码不是明文存储而是"加密"成一串乱码也是哈希,Git 每一次 commit 那串看不懂的十六进制 ID 还是哈希,甚至你们公司 Redis 集群把数据均匀分到不同机器上------背后站着的依然是哈希。你熟练地使用着这些工具,但真要你解释一句"哈希到底是什么?它凭什么能让查找变得这么快?",你可能就卡壳了。
这篇文章就是来帮你捅破这层窗户纸------从最朴素的原理出发,一路讲到 HashMap 源码、一致性哈希和布隆过滤器,让你对这位"最熟悉的陌生人"真正知根知底。
一、先别急,让我们从一只"指纹"说起
在正式进入 Java 源码之前,我想先问你一个问题:如果让你在一本 1000 页的字典里快速找到某个单词,你会怎么做?
你肯定不会从第一页开始逐页翻------那得翻到地老天荒。更聪明的做法是:字典本身就有索引(比如侧面的 ABCD 标签),你先根据首字母定位到大致的页码区间,再在这个小区间里精确查找。
这个"根据首字母快速定位"的过程,本质上就是哈希(Hash)。
哈希,就是把一个任意长度的输入,通过某种算法,映射成一个固定长度的输出。这个输出就像数据的"指纹"------独一无二(理想情况下)、短小精悍,让你能通过它快速定位到原始数据。
用更生活化的例子来说:
- 图书馆索书号:每本书都有一个索书号,你不需要遍历整个图书馆,直接根据索书号就能找到书架位置。
- 身份证号:14 亿人,每人一个 18 位的身份证号,这就是一种"哈希编号"。
- 文件 MD5:你下载文件时经常看到的"MD5 校验值",就是一种哈希。下载完比对一下,就知道文件有没有被篡改。
好了,概念讲完了。下面我们上硬菜。
二、哈希函数:好的哈希函数长什么样?
上面的例子中,"取首字母""计算 MD5""生成索书号"这些操作,都是由哈希函数(Hash Function) 完成的。
2.1 哈希函数的"三好学生"标准
一个优秀的哈希函数,必须同时满足三个条件:
| 特性 | 含义 | 大白话 |
|---|---|---|
| 确定性 | 同样的输入,永远得到同样的输出 | "张三"算出来是 3 号柜子,不能下次算成 7 号 |
| 高效性 | 计算速度要快 | 如果算一次哈希要 1 秒钟,再好的算法也白搭 |
| 均匀性 | 输出尽可能均匀分布 | 不能让所有人都挤在 1 号柜子前面排队 |
2.2 一个最简单的哈希函数
java
// 最简单的哈希:取模
public int hash(String key, int tableSize) {
int sum = 0;
for (char c : key.toCharArray()) {
sum += c; // 把每个字符的 Unicode 值加起来
}
return sum % tableSize; // 取模,保证落在 [0, tableSize-1] 范围内
}这个函数能用吗?能用。但好吗?不好。比如 "abc" 和 "cba" 算出来的哈希值完全一样(因为字符和相同),这就叫哈希冲突。
哈希冲突不可避免。好的哈希函数不是"没有冲突",而是"让冲突尽可能少、尽可能均匀"。就像天底下没有不吵架的夫妻,但好的婚姻能让吵架次数少、伤感情程度低------哈希函数也是这个道理。
三、Java 世界里的哈希:hashCode() 与 equals() 的"结婚契约"
终于到了 Java 的主场。在 Java 中,一切哈希的起点是两个方法:hashCode() 和 equals()。它们是 Object 类自带的方法,所有 Java 对象都继承了它们。
3.1 每个对象都有"指纹"
java
public class Object {
public native int hashCode(); // 返回对象的哈希值(默认是内存地址的某种映射)
public boolean equals(Object obj) {
return (this == obj); // 默认比较内存地址
}
}3.2 改写命运的"结婚契约"
当你决定让自定义对象可以被放进 HashMap 的 Key 中时,你就必须遵守 hashCode() 和 equals() 之间的契约------我管它叫"结婚契约":
铁律一 :如果
a.equals(b) == true,那么a.hashCode()必须等于b.hashCode()。铁律二 :如果
a.equals(b) == false,a.hashCode()可以相等也可以不相等(相等的叫冲突,不相等的是理想情况)。铁律三 :同一个对象,多次调用
hashCode(),在equals()用到的字段没变的情况下,必须返回相同值。
违反契约的后果是什么?来看一段"车祸现场":
java
public class Student {
private String name;
public Student(String name) { this.name = name; }
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Student)) return false;
return Objects.equals(name, ((Student) o).name);
}
// 注意:重写了 equals(),但忘了重写 hashCode()!
}
// 车祸现场
Map<Student, Integer> scores = new HashMap<>();
scores.put(new Student("小明"), 90);
// 你期望拿到 90,实际拿到的却是 null!
Integer score = scores.get(new Student("小明"));
System.out.println(score); // null !!为什么呢? 因为虽然两个 Student 对象 equals 返回 true,但它们的 hashCode() 不同(默认用内存地址),所以 HashMap 去不同的"桶"里找,当然找不到。
记住:重写
equals()就必须重写hashCode()。这俩就像筷子------少一只你能吃饭吗?能用,但你得用手,而面试官会因为这个把你挂掉。
3.3 标准写法
java
public class Student {
private String name;
private int age;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Student)) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age); // Java 7+ 一行搞定
}
}现代 Java 项目中,直接用 Lombok 的
@EqualsAndHashCode注解,或者用 IDEA 自动生成,一般不需要手写。但面试时,你得能手写出来。
四、哈希冲突------当两个不同的人拿到了同一个储物柜号码
前面我们说了,哈希冲突是不可避免的。那么冲突发生了怎么办?业界主要有两种方案。
4.1 链地址法(Separate Chaining)
核心思想:每个"桶"不只放一个元素,而是放一个链表(或红黑树)。冲突的元素串在同一个桶后面。
数组索引: [0] -> 张三 -> 李四 -> null ← 桶0里挂了两个元素(冲突了)
[1] -> null ← 这个桶空的
[2] -> 王五 -> null ← 这个桶只有一个元素这就是 Java HashMap 采用的方式。
4.2 开放地址法(Open Addressing)
核心思想:每个桶只放一个元素。如果目标桶被占了,就按某种规则去找下一个空桶。
- 线性探测:往后走一步,看看下一个桶空不空
- 二次探测:往后走 1²、2²、3²... 步
- 双重哈希:用第二个哈希函数计算步长
Java 的 ThreadLocal 中的 ThreadLocalMap 用的就是开放地址法(线性探测)。
4.3 两种方案对比
| 维度 | 链地址法 | 开放地址法 |
|---|---|---|
| 实现 | 数组+链表/红黑树 | 纯数组 |
| 内存 | 需要额外存储指针 | 全部在数组内,缓存友好 |
| 删除 | 简单(从链表移除) | 复杂(不能直接置空) |
| 扩容阈值 | 可以超过 100% | 通常 ≤ 70% |
| 代表 | HashMap |
ThreadLocalMap |
五、HashMap 源码深度拆解------Java 面试的"必考题"
如果说数据结构面试有一道"必考题",那一定是 HashMap。下面的内容建议你收藏,面试前拿出来温习。
5.1 数据结构全景图
java
┌─────────────────────────────────────────────────────────┐
│ HashMap │
│ │
│ table (Node<K,V>[]) │
│ ┌───┬───┬───┬───┬───┬───┬───┬───┐ │
│ │ 0 │ 1 │ 2 │ 3 │ 4 │ 5 │...│n-1│ │
│ └─┬─┴───┴─┬─┴───┴───┴───┴───┴───┘ │
│ │ │ │
│ │ └──→ Node → Node (链表,长度≤8) │
│ │ ↓(树化) │
│ │ TreeNode ↔ TreeNode (红黑树,长度>8) │
│ │ │
│ └──→ null (空桶) │
└─────────────────────────────────────────────────────────┘5.2 核心常量:为什么是 8 和 0.75?
看源码前,先记住这几个"魔法数字":
java
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认容量 16
static final float DEFAULT_LOAD_FACTOR = 0.75f; // 负载因子
static final int TREEIFY_THRESHOLD = 8; // 链表转红黑树阈值
static final int UNTREEIFY_THRESHOLD = 6; // 红黑树退化为链表阈值
static final int MIN_TREEIFY_CAPACITY = 64; // 最小树化容量面试高频问题来了:
为什么负载因子是 0.75?
这是时间和空间的折中:
- 设太大(如 0.9):空间利用率高,但哈希冲突概率飙升,查找效率下降。
- 设太小(如 0.5):冲突少、查找快,但一半空间浪费了。
- 0.75 是经过大量实验验证的"甜点值",在时空之间取得了最佳平衡。
为什么树化阈值是 8?
根据泊松分布,在负载因子为 0.75 的情况下,一个桶中元素个数达到 8 的概率约为 0.00000006 (亿分之六)。也就是说,正常情况下几乎不可能出现需要树化的场景------如果真的出现了,说明你的 hashCode() 写得有问题,或者有人在故意构造哈希碰撞攻击。树化本质上是一种防御机制。
为什么退化阈值是 6 而不是 8?
如果退化阈值也设为 8,当元素个数在 7→8→7 之间反复横跳时,链表和红黑树会频繁转换,开销巨大。设成 6 相当于加了一个"缓冲区",避免震荡。
5.3 哈希扰动函数:不是简单取模那么简单
java
// JDK 1.8 HashMap 的 hash() 方法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}为什么要做 h ^ (h >>> 16) 这个"扰动"?
因为计算桶下标用的是 (n - 1) & hash(等同于取模运算,但只对 2 的幂次有效)。当 n 比较小(比如初始容量 16)时,n - 1 的二进制只有低 4 位是 1:
java
n = 16: n - 1 = 15 = 0000 0000 0000 1111如果不做扰动,只有 hashCode 的低 4 位参与运算,高位完全被忽略------冲突率会高得离谱。扰动函数把高 16 位和低 16 位异或,让高位也参与进来,哈希更均匀。
5.4 put() 方法全流程
java
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 1. 如果 table 为空,先扩容(懒初始化)
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 2. 计算桶下标,如果桶为空,直接放
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
// 3. 桶不为空,分三种情况处理
Node<K,V> e; K k;
// 3a. 第一个节点就是目标,直接命中
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 3b. 桶里是红黑树,走树的插入逻辑
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 3c. 桶里是链表,遍历链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) { // 走到末尾,插入新节点
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // 长度≥8,转红黑树
treeifyBin(tab, hash);
break;
}
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
break; // 找到了相同key
p = e;
}
}
// 4. 如果找到了相同的 key,覆盖旧值
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
return oldValue;
}
}
// 5. 检查是否需要扩容
if (++size > threshold)
resize();
return null;
}用一张流程图总结 put 的全过程:
put(key, value)
│
▼
计算 hash(key),确定桶下标 index
│
▼
桶为空?──是──▶ 直接放入新节点
│
否
│
▼
桶内第一个节点就是要找的 key?──是──▶ 覆盖 value
│
否
│
▼
桶内是红黑树?──是──▶ 走树的插入逻辑
│
否(是链表)
│
▼
遍历链表:
- 找到相同 key → 覆盖 value
- 走到末尾 → 插入新节点 → 检查是否需要树化
│
▼
size > threshold?──是──▶ 扩容5.5 扩容机制:为什么容量总是 2 的幂?
JDK 1.8 的扩容是一次优雅的重哈希过程:
java
final Node<K,V>[] resize() {
// ... 省略部分代码
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int newCap = oldCap << 1; // 新容量 = 旧容量 × 2
// 遍历旧数组
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null) // 只有一个元素,直接放新位置
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode) // 红黑树,走 split 逻辑
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // 链表,拆成两条
// 核心技巧:用 hash & oldCap 判断元素在新数组中的位置
// 结果为 0:位置不变 (j)
// 结果为 1:位置变成 j + oldCap
// ...拆分逻辑
}
}
}
}为什么容量始终保持 2 的幂?三个好处:
- 位运算替代取模 :
hash & (n-1)等价于hash % n,但快得多。 - 扩容时元素位置规律:扩容后,元素要么在原位置,要么在原位置 + 旧容量处。不需要重新计算哈希。
- 配合扰动函数:让哈希分布更均匀。
5.6 JDK 1.7 vs JDK 1.8 的演进
| 特性 | JDK 1.7 | JDK 1.8 |
|---|---|---|
| 数据结构 | 数组 + 链表 | 数组 + 链表 + 红黑树 |
| 插入方式 | 头插法(新节点插在链表头部) | 尾插法(新节点插在链表尾部) |
| 扩容死链 | ⚠️ 多线程扩容可能形成环形链表,CPU 100% | ✅ 修复,不会成环 |
| 哈希扰动 | 4 次扰动 | 1 次扰动(高16位异或低16位) |
面试时主动提 JDK 1.7 头插法导致的死循环问题,绝对是加分项。
六、一致性哈希------当哈希遇上分布式
到目前为止我们聊的都是单机环境。现在把视角拉远:如果你的数据量大到一台机器装不下,需要用多台机器组成集群,哈希还能用吗?
6.1 普通哈希取模的"翻车现场"
假设你有 3 台 Redis 服务器,用最简单的策略路由数据:
java
int serverIndex = hash(key) % 3; // 3台机器,取模决定去哪台看起来没问题。直到有一天,你加了一台新机器------
原来:hash("user:1001") % 3 = 2 → 去 2 号机器
现在:hash("user:1001") % 4 = 1 → 去 1 号机器 ← 找不到了!几乎所有 Key 的路由都变了 。这意味着什么?缓存全部失效,所有请求直接打到数据库------俗称缓存雪崩。这是个能让运维半夜起来加班的问题。
6.2 一致性哈希的"环形魔法"
一致性哈希用一个 Hash 环 (0 ~ 2³²-1)来解决这个问题: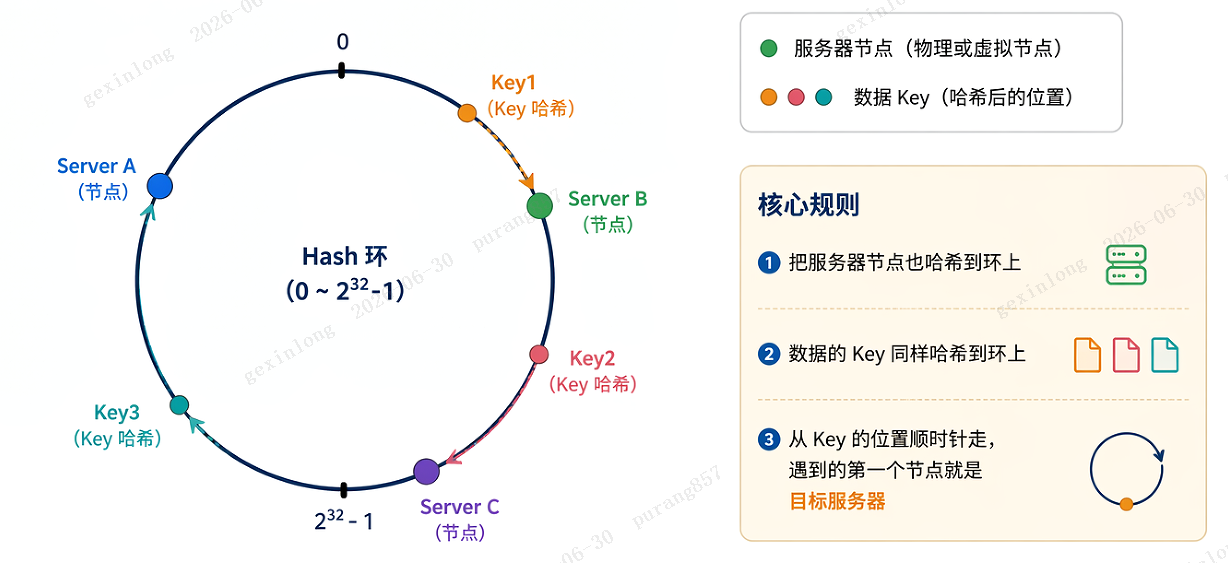
核心规则:
- 把服务器节点也哈希到环上
- 数据的 Key 同样哈希到环上
- 从 Key 的位置顺时针走,遇到的第一个节点就是目标服务器
6.3 增加/删除节点的影响
增加节点前:Key1、Key2、Key3 都路由到 Server B
增加节点后:只有 Key2 切换到了新节点 Server C,Key1 和 Key3 不受影响只影响环上相邻的一小段数据,而不是全部。这就是一致性哈希的核心优势。
6.4 虚拟节点------让"雨露均沾"成为现实
一致性哈希有一个隐患:如果节点太少,哈希环上的分布可能极不均匀(有的节点分到海量数据,有的节点"闲出屁")。
解决方案是虚拟节点(Virtual Node):每个物理节点在环上映射为多个虚拟节点。
物理节点 Server A → 虚拟节点 A#1, A#2, A#3 ... A#150
物理节点 Server B → 虚拟节点 B#1, B#2, B#3 ... B#150虚拟节点越多,分布越均匀。这也是 Dubbo、Nginx、Memcached 等中间件中一致性哈希的通用做法。
java
// 带虚拟节点的一致性哈希示意
public class ConsistentHash {
private final TreeMap<Integer, String> ring = new TreeMap<>(); // 用TreeMap实现环
private final int virtualNodes; // 每个物理节点的虚拟节点数
public ConsistentHash(int virtualNodes, List<String> servers) {
this.virtualNodes = virtualNodes;
for (String server : servers) {
addNode(server);
}
}
private void addNode(String server) {
for (int i = 0; i < virtualNodes; i++) {
String virtualNodeName = server + "#" + i;
int hash = getHash(virtualNodeName);
ring.put(hash, server);
}
}
public String getServer(String key) {
int hash = getHash(key);
// 顺时针找最近的节点
Map.Entry<Integer, String> entry = ring.ceilingEntry(hash);
if (entry == null) {
entry = ring.firstEntry(); // 超过最大值,回到环的起点
}
return entry.getValue();
}
}七、布隆过滤器------用空间换时间的极致艺术
7.1 一个真实场景
你的公司做了一个新闻 App。为了不让用户看到重复的新闻,每次推荐前你都要判断"这篇文章用户看过没"。你不可能每次都去数据库查------那会让数据库直接歇菜。你也不可能把所有"已读文章ID"存到内存------用户量大了之后内存分分钟爆炸。
这时候,布隆过滤器(Bloom Filter)就登场了。
7.2 核心原理
布隆过滤器是一个概率型数据结构,它告诉你两件事:
-
"这个元素一定不存在" → 100% 确定
-
"这个元素可能存在" → 有一定误判概率
布隆过滤器的结构:
┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┐
│ 0 │ 0 │ 0 │ 0 │ 0 │ 0 │ 0 │ 0 │ 0 │ 0 │ 初始化:全部为0
└───┴───┴───┴───┴───┴───┴───┴───┴───┴───┘添加元素 "Java":
hash1("Java") = 2 ──▶ 第2位置1
hash2("Java") = 5 ──▶ 第5位置1
hash3("Java") = 7 ──▶ 第7位置1┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┐
│ 0 │ 0 │ 1 │ 0 │ 0 │ 1 │ 0 │ 1 │ 0 │ 0 │
└───┴───┴───┴───┴───┴───┴───┴───┴───┴───┘查询 "Java":
检查第2、5、7位 → 都是1 → "可能存在" ✅查询 "Python":
检查第1、4、6位 → 第4位是0 → "一定不存在" ❌
7.3 Java 实现(基于 Redis)
java
// 使用 Guava 的布隆过滤器
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
BloomFilter<String> filter = BloomFilter.create(
Funnels.stringFunnel(Charset.defaultCharset()),
1000000, // 预计插入数量
0.01 // 期望误判率 1%
);
filter.put("user:1001:article:5001"); // 标记为"已读"
if (filter.mightContain("user:1001:article:5002")) {
// 可能存在(有 ≤1% 概率误判),去数据库二次确认
} else {
// 一定不存在,放心推荐给用户
}布隆过滤器的妙处在于:用极小的空间(远小于存储全部 ID 所需的内存),换取了 "一定不存在" 这个确定性的答案。在缓存穿透防护、垃圾邮件过滤、网页去重等场景中堪称神器。
八、哈希应用全景图------不止是 HashMap
哈希的应用远比大多数人想象的要广泛。来快速过一遍:
| 应用场景 | 哈希的作用 | 代表技术 |
|---|---|---|
| 快速查找 | O(1) 时间复杂度 | HashMap、HashSet |
| 数据校验 | 检测数据是否被篡改 | MD5、SHA-256 |
| 负载均衡 | 将请求均匀分配到服务器 | 一致性哈希(Nginx、Dubbo) |
| 去重判断 | 用极小内存判断"是否存在过" | 布隆过滤器 |
| 数据分片 | 数据库/缓存水平拆分 | 分库分表路由 |
| 密码存储 | 不可逆加密 | BCrypt、Argon2 |
| 防篡改 | 区块链、Git commit ID | SHA-1(Git)、SHA-256(区块链) |
| 秒杀去重 | 防止用户重复下单 | Redis + Lua 脚本 |
九、面试高频题------手写与实践
9.1 你能手写一个简单的 HashMap 吗?
面试中可能被问到,这里给出一个简化版:
java
public class SimpleHashMap<K, V> {
static class Node<K, V> {
final K key;
V value;
Node<K, V> next;
Node(K key, V value) {
this.key = key;
this.value = value;
}
}
private Node<K, V>[] table;
private int size;
private static final int DEFAULT_CAPACITY = 16;
private static final float LOAD_FACTOR = 0.75f;
@SuppressWarnings("unchecked")
public SimpleHashMap() {
table = (Node<K, V>[]) new Node[DEFAULT_CAPACITY];
}
public void put(K key, V value) {
int index = indexFor(key);
Node<K, V> head = table[index];
// 查找是否已存在
for (Node<K, V> e = head; e != null; e = e.next) {
if (e.key.equals(key)) {
e.value = value; // 覆盖
return;
}
}
// 头插法插入新节点
Node<K, V> newNode = new Node<>(key, value);
newNode.next = head;
table[index] = newNode;
if (++size > table.length * LOAD_FACTOR) {
resize();
}
}
public V get(K key) {
int index = indexFor(key);
for (Node<K, V> e = table[index]; e != null; e = e.next) {
if (e.key.equals(key)) {
return e.value;
}
}
return null;
}
private int indexFor(K key) {
return (key.hashCode() & 0x7fffffff) % table.length; // 取正再取模
}
@SuppressWarnings("unchecked")
private void resize() {
Node<K, V>[] oldTable = table;
table = (Node<K, V>[]) new Node[oldTable.length << 1];
size = 0;
for (Node<K, V> head : oldTable) {
for (Node<K, V> e = head; e != null; e = e.next) {
put(e.key, e.value); // 简单做法:rehash reinsert
}
}
}
}9.2 面试必问题清单
以下问题建议你在面试前都能对答如流:
- HashMap 的底层数据结构是什么? → 数组 + 链表 + 红黑树
- 为什么用红黑树而不是 AVL 树? → 红黑树插入删除的旋转次数更少,适合频繁修改的场景;AVL 树查找略快但旋转开销大,适合读多写少
- HashMap 的扩容机制? → 容量翻倍、rehash、链表拆分(高位/低位两条链)
- 为什么 HashMap 线程不安全? → 数据覆盖、1.7 死循环、size 不准确
hashCode()和equals()的关系? → 对象相等则 hashCode 必相等,反之不必然- 什么是哈希冲突?如何解决? → 链地址法、开放地址法
- 一致性哈希的原理和优势? → Hash 环 + 顺时针查找,增减节点只影响相邻数据
- 布隆过滤器的原理和应用场景? → 多哈希 + 位数组,用于缓存穿透防护、去重
十、总结:从哈希看计算机科学的"权衡之美"
回顾整篇文章,你会发现一个反复出现的主题:权衡(Trade-off)。
- 负载因子 0.75:时间 vs 空间的权衡
- 树化阈值 8:正常场景性能 vs 极端场景防御的权衡
- 链地址法 vs 开放地址法:灵活性 vs 缓存友好的权衡
- 布隆过滤器:准确性 vs 内存占用的权衡
- 一致性哈希:数据均匀性 vs 扩缩容成本的权衡
哈希之所以成为计算机科学中最广泛应用的技术之一,正是因为它完美体现了"没有银弹,只有权衡"的工程哲学。
学技术,既要学"是什么"(概念),也要学"怎么用"(API),更要学"为什么"(设计原理)。三者缺一不可。希望这篇文章能帮你打通哈希的"任督二脉",在面试和工作中游刃有余。