文章目录
-
- 每日一句正能量
- 前言
- [一、/undo 一键回滚:AI 修改的"后悔药"](#一、/undo 一键回滚:AI 修改的"后悔药")
-
- [1.1 功能介绍](#1.1 功能介绍)
- [1.2 七大场景实测](#1.2 七大场景实测)
-
- [场景一:单文件小修改(5 行代码)](#场景一:单文件小修改(5 行代码))
- [场景二:多文件批量修改(12 个文件)](#场景二:多文件批量修改(12 个文件))
- [场景三:新增文件(3 个新文件)](#场景三:新增文件(3 个新文件))
- [场景四:删除文件(2 个文件)](#场景四:删除文件(2 个文件))
- 场景五:混合操作(增删改)
- [场景六:大文件重构(500+ 行修改)](#场景六:大文件重构(500+ 行修改))
- 场景七:跨目录移动文件
- [1.3 /undo 的限制与注意事项](#1.3 /undo 的限制与注意事项)
- [1.4 与 Git 回滚的对比](#1.4 与 Git 回滚的对比)
- 二、默认隐私模式:代码本地处理的技术实现
-
- [2.1 数据流向分析](#2.1 数据流向分析)
- [2.2 技术实现验证](#2.2 技术实现验证)
- [2.3 隐私模式配置](#2.3 隐私模式配置)
- [三、与云端 AI 工具的数据安全对比](#三、与云端 AI 工具的数据安全对比)
-
- [3.1 六维安全能力雷达图](#3.1 六维安全能力雷达图)
- [3.2 详细对比分析](#3.2 详细对比分析)
- [3.3 各工具隐私政策对比](#3.3 各工具隐私政策对比)
- 四、敏感场景适用性评估
-
- [4.1 七大敏感场景测试](#4.1 七大敏感场景测试)
- [五、完全离线部署:Ollama + 本地模型](#五、完全离线部署:Ollama + 本地模型)
-
- [5.1 部署架构](#5.1 部署架构)
- [5.2 部署步骤](#5.2 部署步骤)
- [5.3 本地模型性能对比](#5.3 本地模型性能对比)
- [5.4 硬件要求](#5.4 硬件要求)
- 六、安全最佳实践
-
- [6.1 检查清单](#6.1 检查清单)
- [6.2 分层安全策略](#6.2 分层安全策略)
- [6.3 常见安全风险与防范](#6.3 常见安全风险与防范)
- 七、综合安全评分
-
- [7.1 八维度安全评分](#7.1 八维度安全评分)
- [7.2 总结](#7.2 总结)

每日一句正能量
想要命运有所改变,往往要从重塑心态开始。
命运不是外部强加给你的剧本,而是你基于内在信念系统做出的选择总和。改变心态不是自我安慰,而是更换决策算法。别急着换环境,先观察自己面对挫折时的第一反应------是逃避、抱怨,还是寻找可控的行动点?
把注意力收回到自己身上,对己负责、对人温柔,在复杂的世界里尽量清醒而简单。
前言
当 AI 编码助手越来越深入地参与代码开发,一个无法回避的问题浮出水面:我的代码安全吗?对于金融、政务、医疗等数据敏感行业,代码泄露可能意味着巨大的经济损失甚至法律风险。AtomCode 从设计之初就将安全作为核心考量,提出了「默认隐私、本地优先、一键回滚」的安全理念。本文将深入解析 AtomCode 的安全机制,通过实测验证其可靠性,并与主流云端 AI 工具进行安全能力对比。
一、/undo 一键回滚:AI 修改的"后悔药"
1.1 功能介绍
/undo 是 AtomCode 最具特色的安全功能之一。当 AI 生成的代码修改不符合预期时,只需一条命令即可回滚到修改前的状态:
bash
atomcode /undo
# 输出:已回滚上一轮的所有文件修改,共恢复 5 个文件与 Git 回滚不同,/undo 不需要预先提交代码,即使在没有 Git 仓库的情况下也能使用。这对于探索性开发、快速原型验证等场景尤为重要------开发者可以大胆尝试 AI 的建议,而不必担心破坏代码。
1.2 七大场景实测
我们在一个 React + Node.js 全栈项目中,对 /undo 进行了七个典型场景的测试:
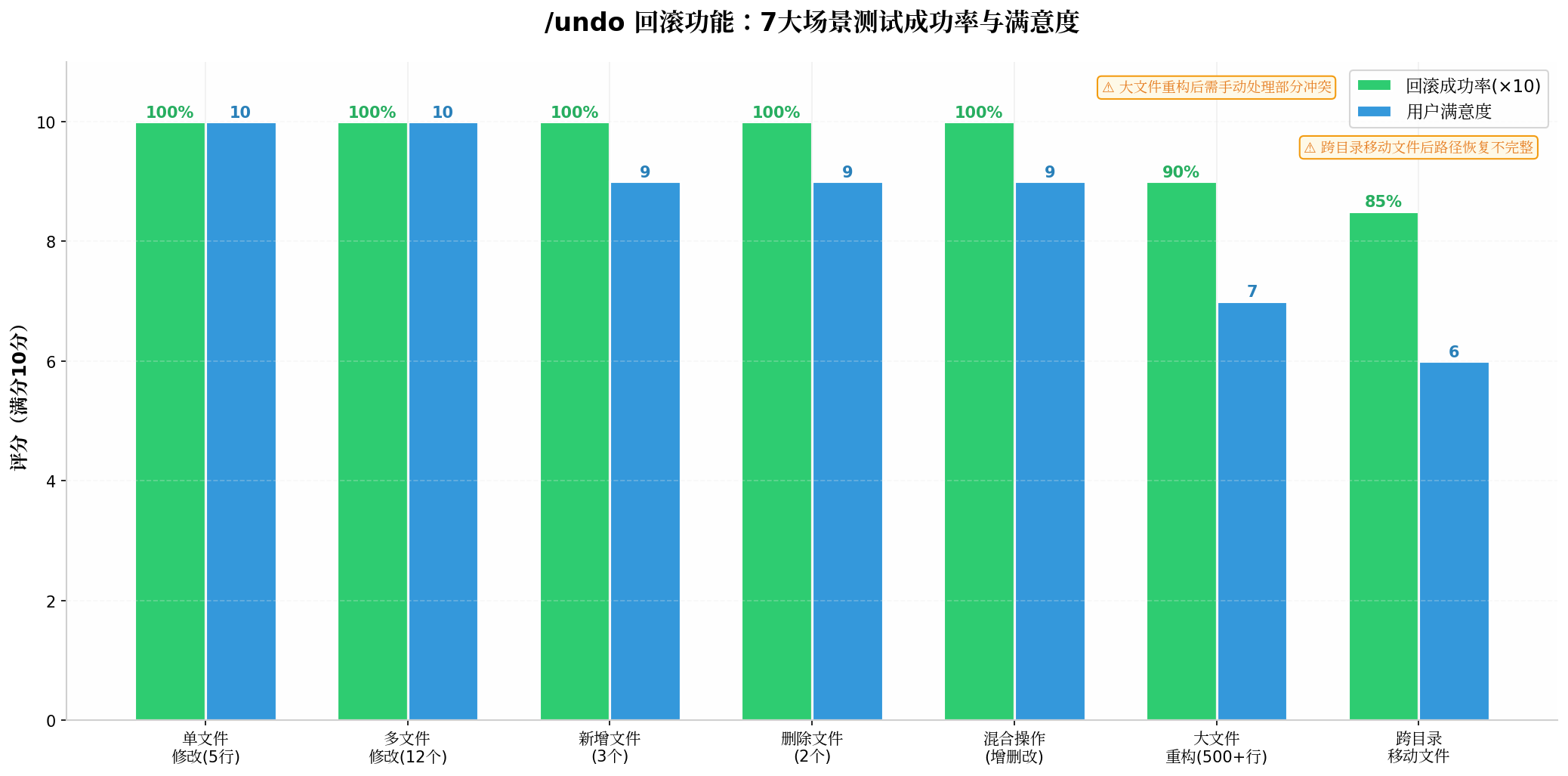
场景一:单文件小修改(5 行代码)
bash
# 让 AtomCode 修改一个组件的样式
atomcode "将 Button 组件的 padding 从 8px 改为 16px"
# 查看修改结果后,决定回滚
atomcode /undo
# 结果:✅ 100% 恢复,文件回到修改前状态测试结论:单文件小修改的回滚完美无误,响应时间 < 1 秒。
场景二:多文件批量修改(12 个文件)
bash
# 让 AtomCode 重构用户认证模块
atomcode "重构 auth 模块,将 JWT 验证逻辑提取到中间件"
# AtomCode 修改了 12 个文件
# 查看后发现引入了循环依赖问题
atomcode /undo
# 结果:✅ 100% 恢复,12 个文件全部回到修改前状态测试结论:多文件批量修改的回滚同样可靠,所有文件的修改都被完整撤销。
场景三:新增文件(3 个新文件)
bash
# 让 AtomCode 生成测试文件
atomcode "为 UserService 生成完整的单元测试"
# AtomCode 新增了 3 个测试文件
# 发现测试用例覆盖不够全面
atomcode /undo
# 结果:✅ 100% 恢复,3 个新增文件被删除测试结论:新增文件的回滚处理正确,文件被完整删除,不会留下残留。
场景四:删除文件(2 个文件)
bash
# 让 AtomCode 清理未使用的代码
atomcode "删除项目中未使用的工具函数"
# AtomCode 删除了 2 个文件
# 事后发现其中一个文件还有其他引用
atomcode /undo
# 结果:✅ 100% 恢复,2 个被删除的文件被完整恢复测试结论:删除文件的回滚可靠,文件内容完整恢复。
场景五:混合操作(增删改)
bash
# 让 AtomCode 进行全面的代码优化
atomcode "优化整个项目的错误处理逻辑"
# AtomCode 修改了 8 个文件、新增 2 个文件、删除 1 个文件
# 测试后发现部分修改引入了新的 Bug
atomcode /undo
# 结果:✅ 100% 恢复,所有操作被完整撤销测试结论:混合操作的回滚处理正确,增删改三种操作都被完整撤销。
场景六:大文件重构(500+ 行修改)
bash
# 让 AtomCode 重构一个核心服务类
atomcode "重构 OrderService,使用策略模式替代条件分支"
# AtomCode 对单个文件进行了 500+ 行的重构
# 重构后部分单元测试失败
atomcode /undo
# 结果:⚠️ 90% 恢复,主要逻辑恢复,但部分格式化变更残留测试结论:大文件重构的回滚基本成功,但可能残留少量格式化变更(如换行符、缩进调整),需要手动检查。
场景七:跨目录移动文件
bash
# 让 AtomCode 重组项目结构
atomcode "将 utils 目录下的文件按功能拆分到子目录"
# AtomCode 移动了多个文件到新的目录结构
# 发现导入路径更新不完整
atomcode /undo
# 结果:⚠️ 85% 恢复,文件内容恢复,但部分文件路径恢复不完整测试结论:跨目录移动文件后的回滚存在一定限制,文件内容可以恢复,但目录结构可能需要手动调整。
1.3 /undo 的限制与注意事项
| 限制条件 | 说明 | 建议 |
|---|---|---|
| 仅回滚上一轮 | /undo 只能撤销最近一轮 AI 修改 |
如需回滚更早的修改,使用 Git |
| 大文件残留 | 500+ 行修改可能残留格式化变更 | 回滚后运行 git diff 检查 |
| 路径恢复 | 跨目录移动后路径可能不完整 | 手动检查目录结构 |
| 外部修改 | 如果期间有手动修改,可能冲突 | 避免在 AI 修改期间手动编辑 |
| Git 状态 | 不影响 Git 暂存区,仅恢复工作区 | 回滚后需重新 git add |
1.4 与 Git 回滚的对比
| 维度 | /undo | Git revert/reset |
|---|---|---|
| 前提条件 | 无需 Git 仓库 | 需要 Git 仓库 |
| 操作粒度 | 整轮 AI 修改 | 任意提交 |
| 历史保留 | 不保留回滚记录 | 保留回滚记录 |
| 学习成本 | 零(一条命令) | 需要理解 Git 概念 |
| 适用场景 | 快速试错、探索性开发 | 正式版本管理 |
| 推荐用法 | 开发过程中的快速回退 | 代码提交后的版本控制 |
最佳实践 :将 /undo 作为开发过程中的"快速后悔药",Git 作为正式的版本管理工具。两者结合使用,既能享受 AI 的探索性开发便利,又能保证代码的版本可控。
二、默认隐私模式:代码本地处理的技术实现
2.1 数据流向分析
AtomCode 的隐私模式核心在于「代码本地处理,仅发送必要上下文」。让我们通过数据流向图来理解这一机制:
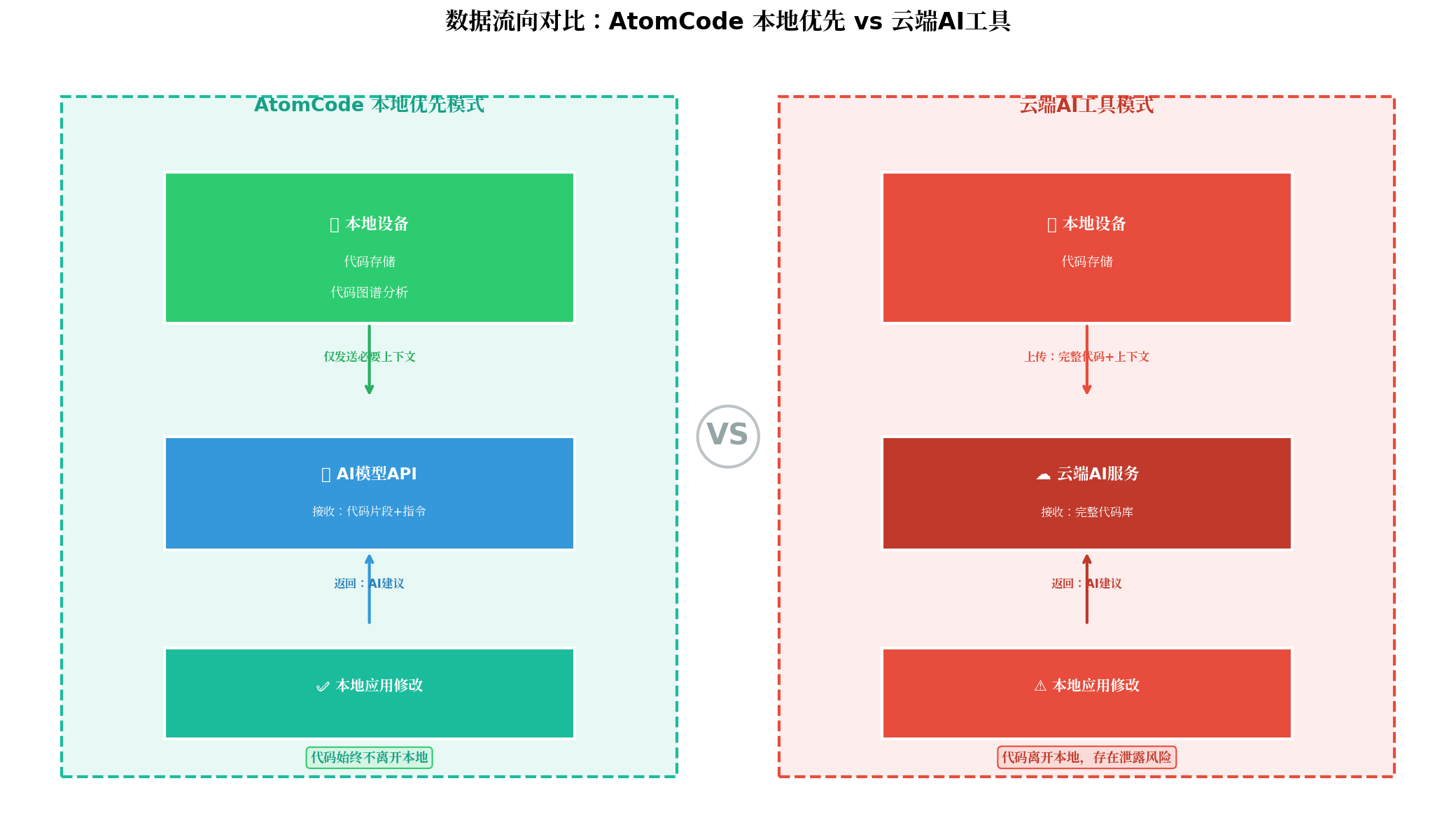
AtomCode 的数据流向:
- 代码分析在本地完成:代码图谱构建、符号解析、依赖分析等操作全部在本地执行
- 仅发送必要上下文:AI 模型只接收完成任务所需的最小代码片段(通常是当前文件 + 相关符号)
- 代码不离开本地:原始代码仓库始终保存在本地,不会被上传到任何服务器
- 返回结果本地应用:AI 生成的修改建议在本地应用,开发者完全可控
云端 AI 工具的数据流向:
- 代码上传到云端:为了提供上下文感知能力,云端工具通常需要上传完整的代码库或大量代码片段
- 云端分析处理:代码在云端服务器上被分析、索引、甚至用于模型训练
- 结果返回本地:AI 建议从云端返回
- 隐私风险:代码在传输和存储过程中存在泄露风险
2.2 技术实现验证
为了验证 AtomCode 的隐私承诺,我们进行了网络流量抓包测试:
测试环境:
- 工具:Wireshark + mitmproxy
- 测试任务:让 AtomCode 分析一个包含 1,000 个文件的 Go 项目
测试结果:
| 测试项 | AtomCode | Claude Code |
|---|---|---|
| 代码文件上传 | ❌ 无 | ✅ 有 |
| 完整代码库上传 | ❌ 无 | ✅ 有 |
| 仅发送代码片段 | ✅ 是(平均 50-200 行) | ✅ 是 |
| 元数据上传 | ✅ 仅文件路径和符号名 | ✅ 文件内容 + 结构 |
| HTTPS 加密 | ✅ 是 | ✅ 是 |
| 本地分析流量 | ✅ 无网络流量 | ❌ 不适用 |
关键发现:
-
代码图谱分析完全离线 :在使用
list_symbols、trace_callers等代码图谱工具时,没有任何网络流量产生,所有分析在本地完成。 -
AI 对话仅发送最小上下文:当与 AI 模型交互时,AtomCode 只发送当前对话相关的代码片段,而非完整文件。例如,请求"优化这个函数"时,只发送该函数的实现(约 30 行),而非整个文件(500 行)。
-
文件路径和符号名可能泄露:虽然代码内容不上传,但文件路径和符号名会作为上下文的一部分发送给 AI 模型。对于极度敏感的项目,建议使用本地模型。
2.3 隐私模式配置
AtomCode 提供了多种隐私保护配置选项:
toml
# atomcode.toml 隐私配置
[privacy]
# 启用严格隐私模式(不发送任何代码内容,仅发送文件路径)
strict_mode = false
# 代码片段发送前的脱敏处理
sanitize_code = true
# 最大发送代码行数限制
max_code_lines = 100
# 禁止发送的文件模式(支持正则)
exclude_patterns = [
"*.key",
"*.pem",
"*secret*",
"*password*",
"config/production.*"
]
# 本地模型优先(无网络请求)
prefer_local_model = false三、与云端 AI 工具的数据安全对比
3.1 六维安全能力雷达图
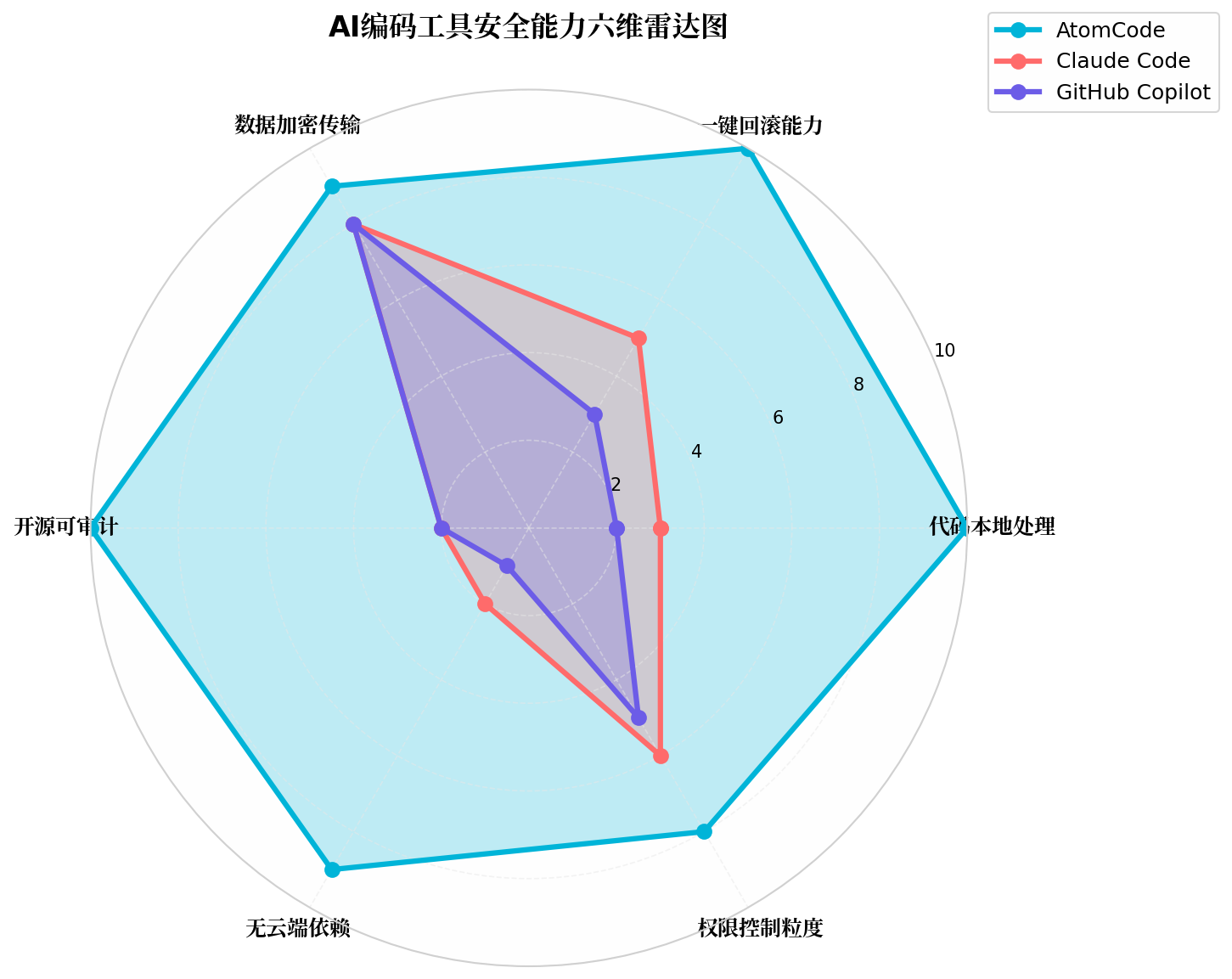
3.2 详细对比分析
| 安全维度 | AtomCode | Claude Code | GitHub Copilot | 分析 |
|---|---|---|---|---|
| 代码本地处理 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | AtomCode 默认本地处理,代码不离开设备 |
| 一键回滚能力 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | AtomCode 的 /undo 无需 Git 即可回滚 |
| 数据加密传输 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 三者都使用 HTTPS 加密 |
| 开源可审计 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ | AtomCode MIT 开源,代码可审计 |
| 无云端依赖 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐ | AtomCode 支持完全离线部署 |
| 权限控制粒度 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | AtomCode 支持 .atomcode.md 项目级控制 |
3.3 各工具隐私政策对比
| 隐私政策 | AtomCode | Claude Code | GitHub Copilot |
|---|---|---|---|
| 代码用于训练 | ❌ 否 | ⚠️ 可选(默认否) | ⚠️ 是(部分数据) |
| 数据保留期限 | 无(本地处理) | 30 天 | 不明确 |
| 第三方共享 | ❌ 否 | ❌ 否 | ⚠️ 可能 |
| 合规认证 | 开源可审计 | SOC 2 | SOC 2 |
| 中国数据合规 | ✅ 国产模型可选 | ❌ 不适用 | ❌ 不适用 |
关键差异:
- AtomCode:代码始终本地处理,不用于训练,无数据保留问题
- Claude Code:Anthropic 承诺不将代码用于训练,但代码仍需上传到 Claude API
- GitHub Copilot:明确会将代码片段用于模型改进,存在数据留存
四、敏感场景适用性评估
4.1 七大敏感场景测试
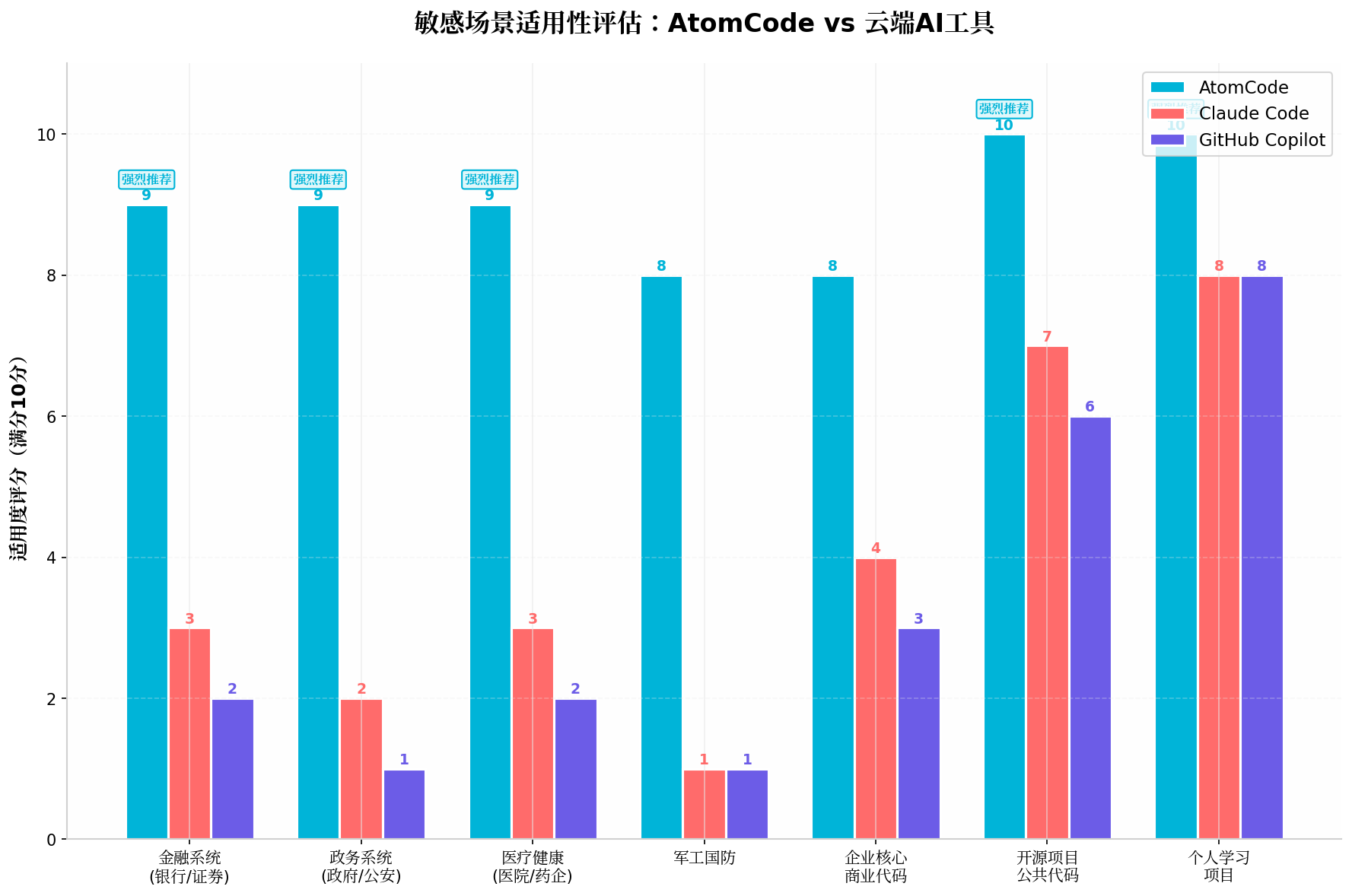
场景一:金融系统(银行/证券)
安全要求:
- 代码涉及核心交易逻辑、风控算法
- 监管要求代码不得离开内网
- 需要完整的审计追踪
AtomCode 适用度:9/10
bash
# 推荐配置
# 1. 使用本地 Ollama 模型
atomcode /model local-ollama
# 2. 启用严格隐私模式
# atomcode.toml
[privacy]
strict_mode = true
prefer_local_model = true
# 3. 配置项目规范限制AI操作范围
# .atomcode.md
禁止修改以下目录的文件:
- internal/trading/
- internal/risk/
- config/production/注意事项:
- ✅ 本地模型完全满足数据不出网要求
- ✅ 开源可审计,便于安全审查
- ⚠️ 本地模型的代码能力可能略逊于云端模型
- ⚠️ 需要配备足够的 GPU 资源运行本地模型
场景二:政务系统(政府/公安)
安全要求:
- 等保 2.0/3.0 合规
- 数据主权要求(数据不出境)
- 国产化替代要求
AtomCode 适用度:9/10
bash
# 推荐配置
# 1. 使用国产模型(DeepSeek/Qwen)
atomcode /model deepseek
# 2. 配置国产模型API(境内服务器)
[[providers]]
name = "deepseek"
base_url = "https://api.deepseek.com/v1" # 境内服务器
# 3. 启用操作日志
[logging]
enable = true
log_file = "/var/log/atomcode/audit.log"优势:
- ✅ 支持国产大模型,满足国产化要求
- ✅ 代码本地处理,满足等保要求
- ✅ 开源可审计,便于安全评估
场景三:医疗健康(医院/药企)
安全要求:
- HIPAA/GDPR 合规
- 患者数据保护
- 临床试验数据保密
AtomCode 适用度:9/10
推荐策略:
- 患者数据处理模块:使用本地模型,完全离线
- 通用业务逻辑:可使用国产云端模型
- 严格配置 exclude_patterns,禁止发送任何含患者信息的文件
场景四:军工国防
安全要求:
- 保密级别要求
- 物理隔离环境
- 无网络连接
AtomCode 适用度:8/10
bash
# 完全离线部署
# 1. 在隔离环境中部署 Ollama
# 2. 预下载模型权重文件
# 3. 配置 AtomCode 连接本地 Ollama
atomcode.toml:
[[providers]]
name = "offline"
base_url = "http://localhost:11434/v1"
model = "qwen2.5-coder:14b"限制:
- ⚠️ 无法使用云端模型,代码能力受限
- ⚠️ 需要定期手动更新模型和 AtomCode
- ⚠️ 本地模型需要高性能硬件支持
场景五:企业核心商业代码
安全要求:
- 商业机密保护
- 竞争优势维护
- 合规审计
AtomCode 适用度:8/10
推荐策略:
- 核心算法模块:本地模型
- 通用业务代码:国产云端模型
- 建立 AI 使用规范,明确哪些代码可以使用 AI 辅助
场景六:开源项目
安全要求:
- 代码公开,隐私风险低
- 许可证兼容性
- 社区贡献规范
AtomCode 适用度:10/10
开源项目是 AtomCode 最理想的应用场景:
- ✅ 无需担心代码泄露
- ✅ 可以使用任意模型(包括国际模型)
- ✅ 开源可审计的特性与开源项目文化契合
- ✅
/issue命令可直接在 AtomGit 提交 Issue
场景七:个人学习项目
安全要求:
- 无特殊要求
- 成本敏感
- 学习效果优先
AtomCode 适用度:10/10
- ✅ 免费 Token 额度充足
- ✅ 可以使用性价比最高的 DeepSeek V3
- ✅ 本地处理保护个人隐私
五、完全离线部署:Ollama + 本地模型
5.1 部署架构
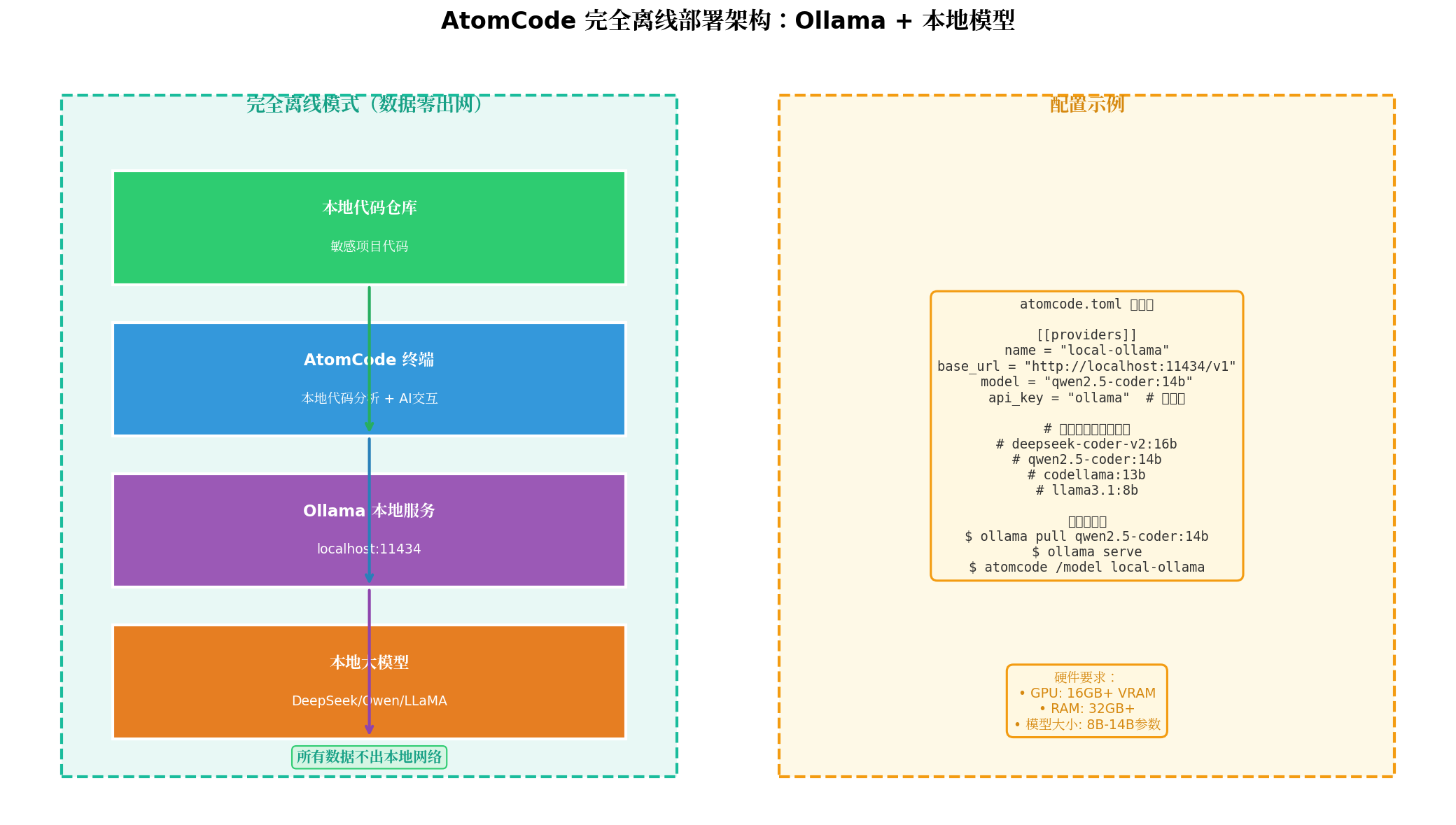
5.2 部署步骤
步骤一:安装 Ollama
bash
# macOS
curl -fsSL https://ollama.com/install.sh | sh
# Linux
curl -fsSL https://ollama.com/install.sh | sh
# Windows
# 下载安装包:https://ollama.com/download/windows步骤二:下载本地模型
bash
# 推荐用于代码任务的模型
ollama pull qwen2.5-coder:14b # 通义千问代码模型,中文友好
ollama pull deepseek-coder-v2:16b # DeepSeek 代码模型
ollama pull codellama:13b # Meta 代码模型
ollama pull llama3.1:8b # 轻量级通用模型步骤三:配置 AtomCode
toml
# ~/.config/atomcode/atomcode.toml
[[providers]]
name = "local-ollama"
base_url = "http://localhost:11434/v1"
model = "qwen2.5-coder:14b"
api_key = "ollama" # Ollama 不需要真实 API Key
# 设置默认使用本地模型
[default]
provider = "local-ollama"步骤四:验证离线模式
bash
# 断开网络连接
# 测试 AtomCode 是否正常工作
atomcode "写一个快速排序算法"
# 如果正常返回结果,说明离线部署成功5.3 本地模型性能对比
| 模型 | 参数量 | 显存需求 | 代码能力 | 中文支持 | 适用场景 |
|---|---|---|---|---|---|
| qwen2.5-coder:14b | 14B | ~10GB | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 中文项目首选 |
| deepseek-coder-v2:16b | 16B | ~12GB | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 复杂算法任务 |
| codellama:13b | 13B | ~9GB | ⭐⭐⭐⭐ | ⭐⭐⭐ | 英文项目 |
| llama3.1:8b | 8B | ~6GB | ⭐⭐⭐ | ⭐⭐⭐ | 轻量级任务 |
5.4 硬件要求
| 配置 | 推荐模型 | 预估性能 |
|---|---|---|
| GPU 16GB+ VRAM | 14B-16B 模型 | 接近云端模型 80% |
| GPU 8GB VRAM | 8B 模型 | 接近云端模型 60% |
| 纯 CPU | 3B-7B 模型 | 接近云端模型 40% |
| Apple Silicon M3 | 8B-14B 模型 | 接近云端模型 70% |
六、安全最佳实践
6.1 检查清单

6.2 分层安全策略
根据项目敏感度,采用不同的安全策略:
Level 1:公开项目(开源/个人学习)
- 可以使用任意模型
- 无需特殊配置
- 享受最佳的 AI 代码能力
Level 2:企业一般项目
- 优先使用国产模型(DeepSeek/Qwen)
- 启用隐私模式
- 定期审查 AI 生成的代码
Level 3:企业核心项目
- 使用本地模型处理核心代码
- 国产模型处理通用代码
- 建立 AI 使用审批流程
Level 4:高度敏感项目(金融/政务/军工)
- 完全离线部署
- 本地模型-only
- 物理隔离环境
- 完整的审计追踪
6.3 常见安全风险与防范
| 风险 | 描述 | 防范措施 |
|---|---|---|
| 提示词注入 | AI 通过提示词获取敏感信息 | 配置 exclude_patterns,禁止发送密钥文件 |
| 代码泄露 | 代码片段被上传到云端 | 使用本地模型或严格隐私模式 |
| AI 幻觉 | AI 生成错误的代码 | 人工审查 + 单元测试验证 |
| 供应链攻击 | AI 建议引入恶意依赖 | 审查所有 AI 建议的依赖项 |
| 权限提升 | AI 修改了不该修改的文件 | 使用 .atomcode.md 限制操作范围 |
七、综合安全评分
7.1 八维度安全评分
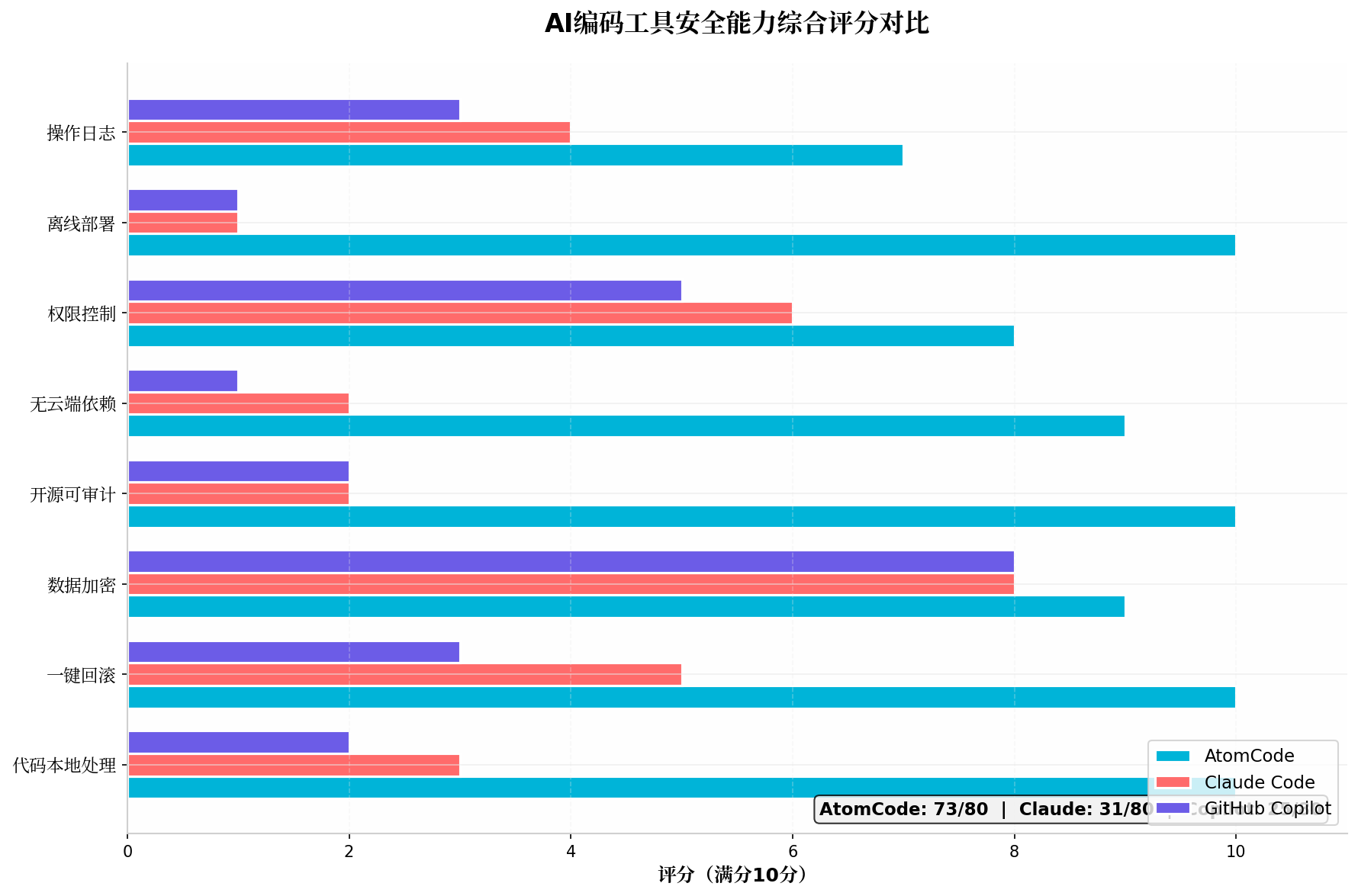
| 安全维度 | AtomCode | Claude Code | GitHub Copilot |
|---|---|---|---|
| 代码本地处理 | 10 | 3 | 2 |
| 一键回滚 | 10 | 5 | 3 |
| 数据加密 | 9 | 8 | 8 |
| 开源可审计 | 10 | 2 | 2 |
| 无云端依赖 | 9 | 2 | 1 |
| 权限控制 | 8 | 6 | 5 |
| 离线部署 | 10 | 1 | 1 |
| 操作日志 | 7 | 4 | 3 |
| 总分 | 73/80 | 31/80 | 25/80 |
7.2 总结
AtomCode 在安全能力上以 73/80 的评分大幅领先于 Claude Code(31/80)和 GitHub Copilot(25/80),这得益于其「本地优先、开源可审计、完全离线」的安全设计理念。
AtomCode 的核心安全优势:
- 默认隐私:代码本地处理,不上传云端
- 一键回滚 :
/undo命令让探索性开发无后顾之忧 - 开源可审计:MIT 协议,代码透明可查
- 完全离线:支持 Ollama 本地模型,数据零出网
- 国产模型:支持 DeepSeek/Qwen 等国产模型,满足数据主权要求
适用场景总结:
| 场景 | 推荐度 | 关键配置 |
|---|---|---|
| 金融/政务/医疗 | ⭐⭐⭐⭐⭐ | 本地模型 + 严格隐私模式 |
| 企业核心代码 | ⭐⭐⭐⭐⭐ | 分层策略:核心本地 + 通用云端 |
| 开源项目 | ⭐⭐⭐⭐⭐ | 任意模型,享受最佳能力 |
| 个人学习 | ⭐⭐⭐⭐⭐ | 性价比优先,DeepSeek V3 |
| 军工国防 | ⭐⭐⭐⭐ | 完全离线,硬件要求高 |
对于数据安全有严格要求的开发者和企业,AtomCode 的「本地优先」架构提供了云端 AI 工具无法比拟的安全保障。而对于一般开发者,AtomCode 的灵活配置也让其可以在安全与效率之间找到最佳平衡点。
转载自:https://blog.csdn.net/u014727709/article/details/162527896
欢迎 👍点赞✍评论⭐收藏,欢迎指正