
大模型部署介绍
大模型部署流程


大模型常用压缩方法




大模型常用部署工具


大模型推理加速技术


大模型应用开发




大模型本地部署展望


大模型商业模式





-
大模型部署流程
-
运行参数配置
-
超参数设置:运行参数配置需修改对应配置文件,如 TopK 是一个超参数,它决定预测出概率最高的词的数量,TopK 等于几就会预测出几个排名最高的词。
-
实际应用:在实际部署中,运行参数配置是必选环节,需要根据具体需求设置合适的超参数,以确保模型的正常运行。
-
工程编译与编程框架接入
- 编译类型:工程编译主要是 C++ 的推理编译,编程框架接入主要是连接数据库以处理模型不足问题。
- 可选性说明:工程编译和编程框架接入在整个部署流程中是可选的,可根据实际情况决定是否添加。
-
-
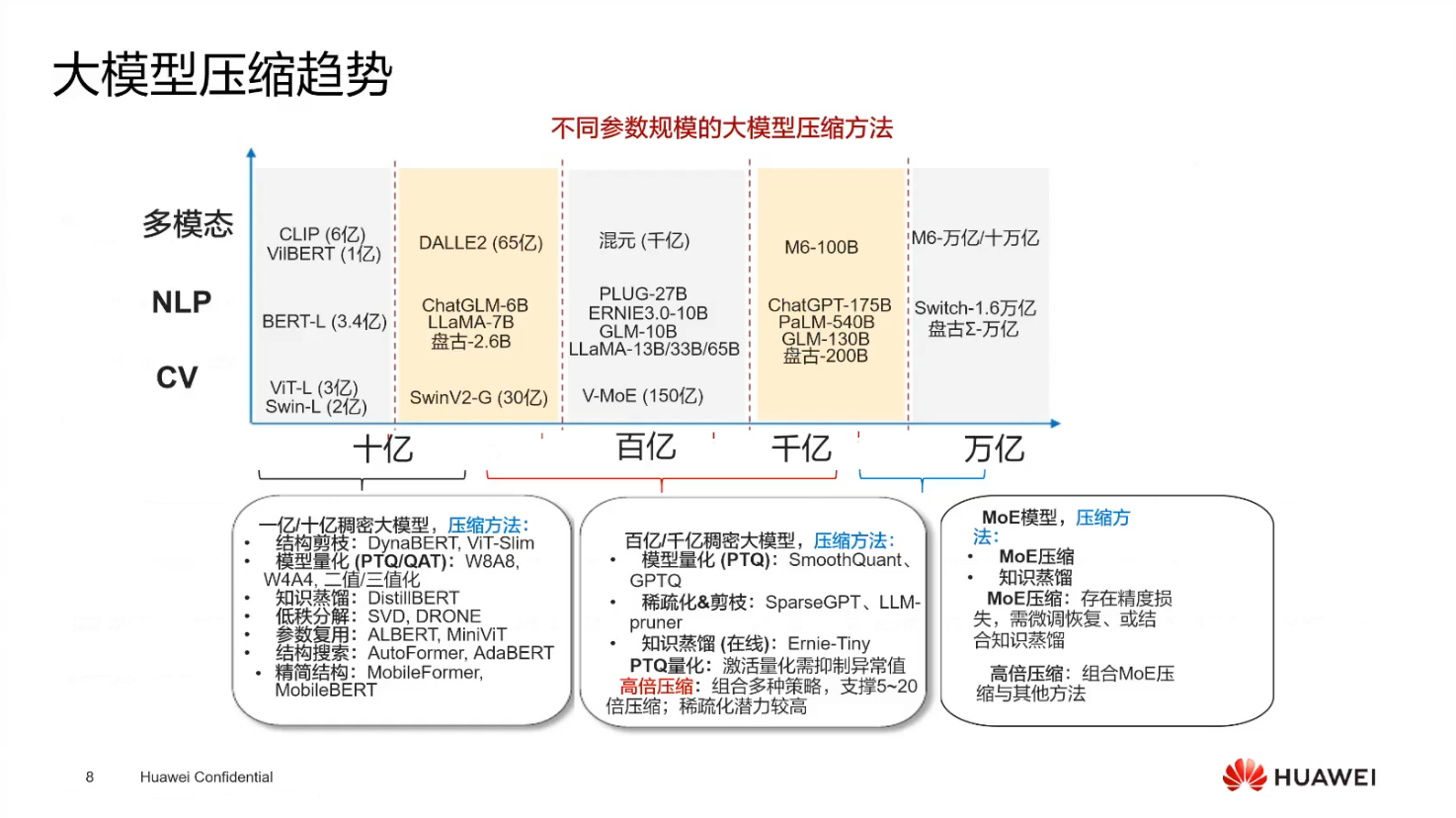
大模型压缩方法
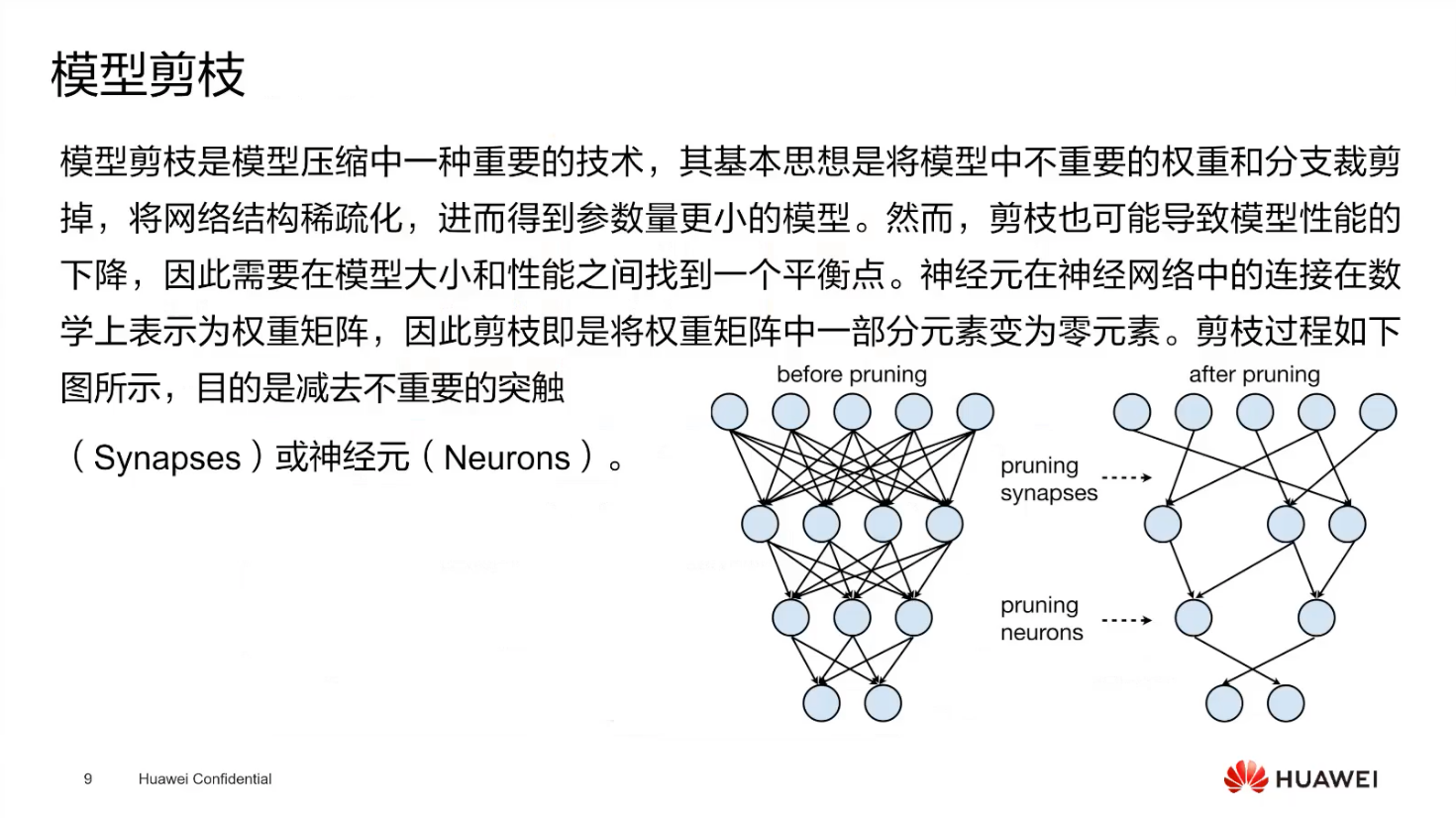
- 剪枝
- 原理:剪枝是去掉不重要的权重,将网络稀疏化,本质是把权重矩阵中不重要的部分置 0,从而减少存储权重,提高运行速度。
- 效果:通过剪枝可以有效降低模型的复杂度,减少计算量,提升模型的运行效率。
- 知识蒸馏
- 本质:知识蒸馏需要一个大模型(teacher 模型)和一个小模型(student 模型),将大模型的问题和输出结果交给小模型学习,使小模型的回答效果接近大模型,节省计算资源。
- 类比理解:类似于武侠小说中的传功,大模型走过很多弯路学会功法,直接传给小模型,小模型学习速度快且效果相近。
- 量化
- 训练后量化(PTQ):专门压缩量化预训练的浮点模型,无需数据集,直接翻转优化权重,如使用 libra file 算法,可快速将浮点转换成 int 8,减少计算量。
- 量化感知训练(QAT):在训练中插入尾量化模块,与浮点计算需求做适配以提升精度,训练完后再做 int 8 的转换。
- 剪枝
-
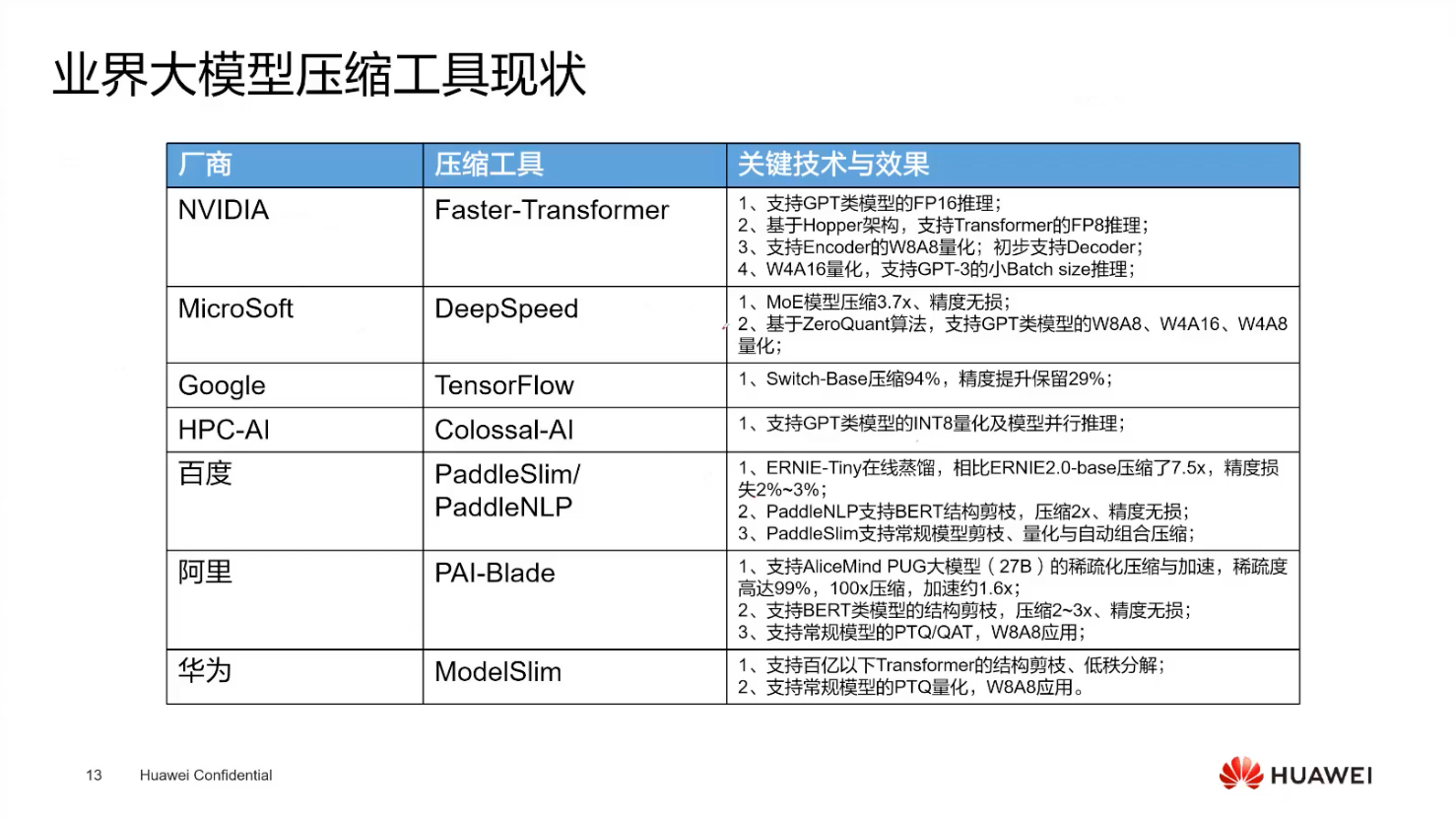
常用部署工具
- 主流工具
- Transformers:预训练模型部署时使用最多的工具。
- VLLM:企业级应用较多的开源推理引擎,采用帕特的 attention 算法,速度比 Transformers 快约 24 倍。
- 华为相关工具
- atformers:华为的套件,在主流模型应用下流任务云端部署时使用较多。
- modelink:可与 atformers 配合使用,是端到端应用较多的部署工具之一。
- 主流工具
-
加速技术
- 通用优化
- Moe 稀疏接口:华为在推理上采用 Moe 稀疏接口,即专家模型,实现快速加速。
- KV cache 加速:与芯片绑定,在芯片底层对 KV cache 的缓存矩阵进行优化,避免重复计算。
- 华为专用优化:华为专用的芯片级优化,直接在硬件上进行本地优化。
- 通用优化
-
应用开发
- Langchain 框架
- 解决问题:用于解决大模型开发中的幻觉问题,在 IP 课程中会详细学习。
- 官网介绍:官网实时更新快,考试以 PPT 内容为准,其核心组件包括 tools 工具链等,可按数据链形式将模型、提示词、RAG 等链到一起。
- 其他开发工具
- Gladio:Python 工具,通过 web 页面快速连接知识库和 LLM 进行开发,有 webUI 页面可直接调用 Python 函数进行交互。
- FastAPI:可采用前后端分离方式搭建大模型开发环境。
- Langchain 框架
-
本地部署趋势
- 模型选择:建议部署参数量 10B 以上的模型,如 13B 模型,因为 7B 模型未达到涌现标准,效果不佳。
- 部署方式:可在云服务器、PC 端等进行部署,如 AIPC 部署、混合 AI 部署等,可根据不同情况调节硬件。
-
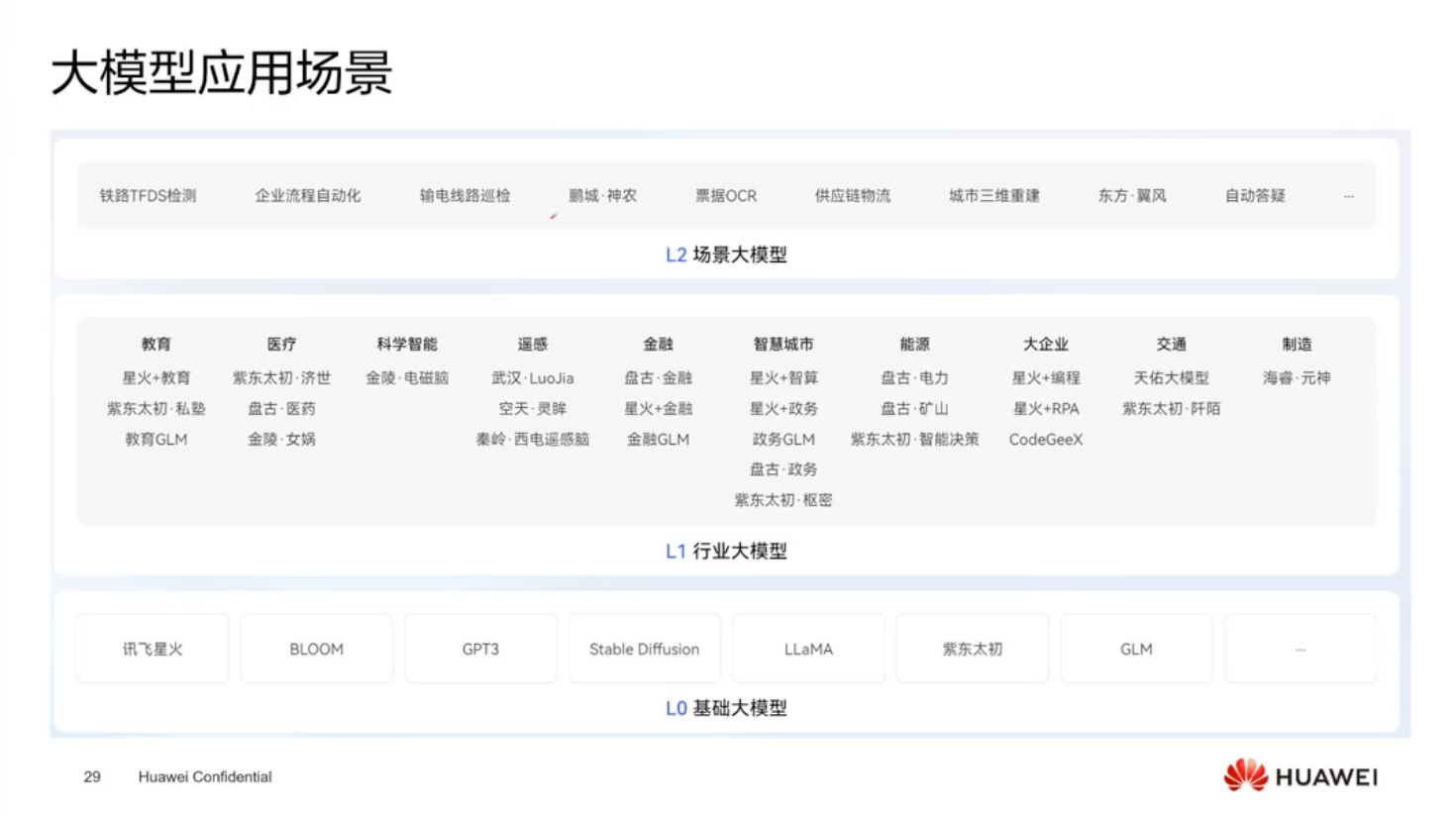
商业模式
- 行业模型:华为盘古大模型主要做行业模型,市场上还有讯飞星火、BLOOM、GPT 等多种模型,都在向行业模型和场景大模型发展。
- 变现方式:商业化变现方式多样,如租赁服务、提供算力服务、打造大模型等,部分厂商通过水印、分辨率限制等方式促使付费,国内模型也有先开源后收费的情况。
-
问答环节
- 大模型部署是否必须压缩:大模型部署不是必须进行压缩,压缩是为了节省资源,在有限资源上提高推理速度,若资源充足则无需压缩。
- bytepoliter 对大模型部署的重要性:可从 PPT 中提取相关内容,如配节 attention 可提高推理速度,meta performance 可在训练方面做优化等。