Model I/O - 模型调用(上)
1、Model I/O 介绍
1.1 什么是 Model I/O
Model I/O------LangChain 中与大语言模型交互的核心流程。
Model I/O 回答的是一个最基本的问题:"怎么把问题喂给模型,并拿到有用的结果?"
1.2 Model I/O 的三个环节
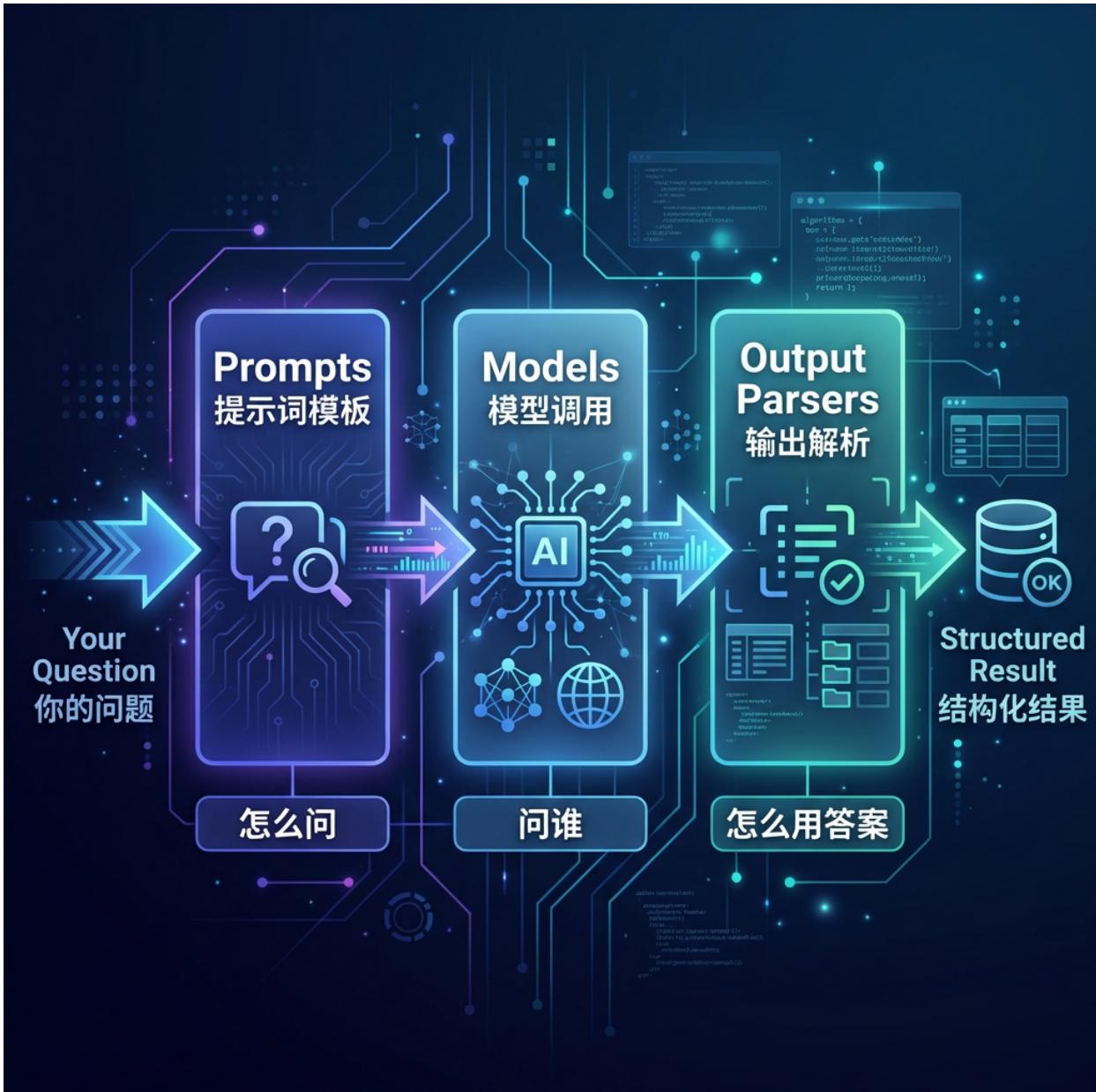
|----------------------|--------------------------------------|---|
| 环节 | 做什么 | |
| Prompts(提示词模板) | 把用户输入和系统指令格式化成模型能理解的消息 | |
| Models(模型调用) | 统一接口调用不同平台的模型(OpenAI、DeepSeek、本地模型等) | |
| Output Parsers(输出解析) | 把模型返回的文本转换为JSON、Pydantic对象等结构化数据 | |
1.3 LangChain 中的三类模型
LangChain 中有三类"模型",但它们的用途完全不同,不要混淆:
|------------------|--------------|-----------------|
| LangChain 模型类型 |||
| Chat Models"对话型" | LLMS"补全型" | Embeddings"向量型" |
| 输入:消息列表输出:AI消息 | 输入:字符串输出:字符串 | 输入:文本输出:数字向量 |
| ★主流,本课重点 | △已过时 | ★RAG |
|-------------|-----------|----------------------------------------|------------------------------------------------------------------------|
| 类型 | 输入→输出 | 代表类 | 说明 |
| Chat Models | 消息列表→AI消息 | ChatOpenAI、ChatAnthropic、ChatOllama | 当前主流,所有现代模型(GPT-4o、Claude、DeepSeek等)都是对话模型。本课程全程使用此类型 |
| LLMs | 字符串→字符串 | OpenAI(旧版) | 已基本淘汰。早期的文本补全模型(如GPT-3 text-davinci),不支持消息格式。LangChain v1.x仍保留接口但不推荐使用 |
| Embeddings | 文本→浮点数向量 | OpenAIEmbeddings、HuggingFaceEmbeddings | 用途不同。不生成文本,而是将文本转换为数字向量,用于语义搜索和RAG。 |
结论:本课程中提到的"模型调用",除非特别说明,都是指 Chat Models。
1.4 统一接口的价值
不管你用的是 OpenAI、DeepSeek、Claude 还是本地的 Ollama,LangChain 都提供了完全一致的调用方式:
python
# 不同平台,同一套代码
llm = ChatOpenAI(model="gpt-4o-mini") # OpenAI
llm = ChatOpenAI(model="deepseek-chat", ...) # DeepSeek
llm = ChatAnthropic(model="claude-sonnet-4-20250514") # Anthropic
llm = ChatOllama(model="qwen2.5:7b") # 本地模型
# 调用方式完全一致
response = llm.invoke("你好") # 同步调用
response = await llm差异化("你好") # 异步调用
for chunk in llm.stream("你好"): # 流式输出
print(chunk.content, end="")
responses = llm.batch(["问题1", "问题2"]) # 批量调用这就是 Model I/O 中 Models 层的核心价值:一次学会,到处能用。
2、调用在线模型
2.1 为什么不直接用原生 SDK?
刚接触 LangChain 的同学可能会问:"我直接用 OpenAI 的 SDK 不就行了,为什么要多学一层框架?"
在回答这个问题之前,先了解一下"原生 SDK"是什么、行业现状如何。
2.1.1 OpenAI SDK:行业事实标准
OpenAI 的 GPT 系列模型不仅推动了大模型技术的发展,还定义了整个行业的开发范式和接口标准。目前大部分模型(Qwen、ChatGLM、DeepSeek 等)的 API 都遵循 OpenAI 定义的规范,可以直接使用OpenAI SDK 来调用。
2.1.2 OpenAI 的 API 经历了两代演进:
|----------------------|--------|--------------------------------------|
| API | 发布时间 | 说明 |
| Chat Completions API | 2023年 | 经典 API,行业标准,几乎所有模型都兼容这套格式 |
| Responses API | 2025年中 | 新一代 API,支持服务端内置工具调用、服务端维护对话状态(短期记忆)等 |
txt
官方文档:Chat Completions API | Responses APIChat Completions API 调用示例(经典,也是 LangChain 底层使用的格式):
python
# uv add openai
from openai import OpenAI
import os
from dotenv import load_dotenv
load_dotenv()
python
client = OpenAI(
base_url=os.getenv("OPENAI_BASE_URL"),
api_key=os.getenv("OPENAI_API_KEY"),
)
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "将'你好'翻译成意大利语"}],
)
print(completion.choices[0].message.content)Responses API 调用示例(新一代,支持内置工具):
python
from openai import OpenAI
client = OpenAI()
response = client.results.create(
model="gpt-4o-mini",
input="中国国内今天发生了哪些大事儿?",
tools=[{"type": "web_search"}] # 服务端内置工具,无需自己实现
)
print(response.output_text)LangChain 目前底层使用的是 Chat Completions API 格式。Responses API 较新, LangChain的支持还在演进中。了解两者的区别即可,后续代码统一基于 Chat Completions API。
看起来原生 SDK 已经很好用了?那为什么还需要 LangChain?
2.1.3 原生 SDK 的痛点:切换模型
用一个真实场景来感受------"同一个任务,先用 GPT-4o-mini 跑,再换成 DeepSeek 跑,再换成Claude 跑,对比结果":
用原生 SDK:每换一个平台,改一堆代码
python
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
# ---- 调用 OpenAI ----
client_openai = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_BASE_URL"),
)
resp1 = client_openai.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "用一句话解释量子计算"}],
)
print(resp1.choices[0].message.content)
# ---- 换成 DeepSeek ----
python
# 要重新创建 client、改 api_key、改 base_url、改 model......
client_deepseek = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1",
)
resp2 = client_deepseek.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": "用一句话解释量子计算"}],
)
print(resp2.choices[0].message.content)
# ---- 换成 Anthropic? 不兼容 OpenAI 格式,整套代码重写..... ----
import anthropic
client_claude = anthropic.Anthropic(
api_key=os.getenv("ANTHROPIC_API_KEY"),
base_url=os.getenv("ANTHROPIC_BASE_URL"),
)
message = client_claude.messages.create(
model="claude-sonnet-4-20250514",
messages=[{"role": "user", "content": "用一句话解释量子计算"}],
)
print(message.content[0].text) # 注意:取值方式都不一样!三个平台,三套 client,三种取值方式。如果还要加流式输出、错误重试、对话记忆......代码量会爆炸式增长。
2.1.4 用 LangChain:只改一行初始化,其余代码不动
python
# uv add langchain-openai langchain-anthropic
from langchain_openai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
from dotenv import load_dotenv
import os
load_dotenv()
# ---- 调用 OpenAI ----
llm = ChatOpenAI(model="gpt-4o-mini")
print(llm.invoke("用一句话解释量子计算").content)
# ---- 换成 DeepSeek? 改一行 ----
llm = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1",
)
print(llm.invoke("用一句话解释量子计算").content) # 调用代码完全一样
# ---- 换成 Anthropic? 也是改一行初始化 ----
llm = ChatAnthropic(model="claude-sonnet-4-20250514")
print(llm.invoke("用一句话解释量子计算").content) # 调用代码还是一样2.1.5 差距在哪?
|----------------|----------------------------------------------------------------------------------------|----------------|
| 维度 | 原生 SDK | LangChain |
| 切换模型 | 改 client、改参数、可能改整套代码 | 只改一行初始化 |
| 调用方式 | 每个平台不一样 (OpenAI 用client.chat.completions.create(),Anthropic 用client.messages.create()) | 统一11m.invoke() |
| 取值方式 | OpenAI 用 .choices0.message.content,Anthropic 用 .content0.text | 统一 .content |
| 流式输出 | 每个平台的 stream 写法不同 | 统一11m.stream() |
| 批量调用 | 自己写循环或并发 | 内置11m.batch() |
| 加功能(记忆、工具、RAG) | 全部从零写 | 框架内置,直接组合 |
模型只有一两个时感觉差不多,但当你要对比 3-5 个模型、加上流式输出、再接上 RAG 管道时,原生 SDK 的代码量会呈指数增长,而 LangChain 始终保持简洁。
2.2 基础使用:ChatOpenAI
ChatOpenAI 是你在 LangChain 中最常用的类,日常开发 90% 的场景都用它。
python
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv()
# 最简写法:环境变量里已配好 OPENAI_API_KEY 和 OPENAI_BASE_URL
llm = ChatOpenAI(model="gpt-4o-mini")
response = llm.invoke("你好,介绍一下LangChain")
# response 是一个 AIMessage 对象,不是普通字符串
print(type(response)) # <class 'langchain_core.messages.ai.AIMessage'>
print(response.content) # 模型返回的文本内容
print(response.response_metadata) # 模型名称、token消耗等元信息注意: llm.invoke() 返回的是 AIMessage 对象,不是字符串。要拿文本内容需要 .content 。这个设计是为了保留消息的元信息(角色、token 用量等),在构建对话链时会用到。
2.3 核心参数详解
初始化 ChatOpenAI 时可以传入多个参数来控制模型行为:
python
11m = ChatOpenAI(
model="gpt-4o-mini", # 模型名称(必填)
temperature=0.7, # 随机性,0=确定性,1=有创意(默认因模型而异)
max_tokens=1000, # 最大输出长度
timeout=60, # 超时时间(秒)
max_retries=2, # 失败重试次数
)2.3.1 temperature 到底怎么选?
temperature 是最常调的参数,它控制模型输出的"创造力":
python
from langchain_openai import ChatOpenAI
question = "给我的咖啡店起个名字"
# temperature=0 -- 确定性输出,每次结果几乎一样
llm_precise = ChatOpenAI(model="gpt-4o-mini", temperature=0)
print(llm_precise.invoke(question).content)
# → "醇香时光咖啡馆"(每次运行结果固定)
# temperature=1 -- 有创意,每次结果不同
llm_creative = ChatOpenAI(model="gpt-4o-mini", temperature=1)
print(llm_creative.invoke(question).content)
# → "晨雾与豆语"(下次运行可能是另一个名字)选择建议:
|--------------|----------------|------------|
| 场景 | 推荐 temperature | 原因 |
| 代码生成、数据提取、翻译 | 0 ~ 0.3 | 需要准确、稳定的输出 |
| 问答、摘要、分析 | 0.3 ~ 0.7 | 兼顾准确性和流畅性 |
| 创意写作、头脑风暴、起名 | 0.7 ~ 1.0 | 需要多样性和创造力 |
2.3.2 Token 是什么?
讲 token,最容易误解的一点就是:它不是"字数",也不是"单词数"。
大模型真正处理的最小单位,是 token。你可以把它理解成:模型内部用来读写文本的"最小片段"。这个片段有时候是一个字,有时候是半个词,有时候是一个完整单词,甚至可能只是一个标点。
所以,同样一句话,人眼看起来长度差不多,token 数却可能差很多。
|----|-----------|----------------------------|
| 语言 | 1个Token≈ | 示例 |
| 中文 | 1~1.8个汉字 | "你好世界"可能被切成2~4个token |
| 英文 | 3~4个字母 | "Hello World"通常是2~3个token |
这里一定要注意:同一段文本,在不同模型、不同分词器下,token 数并不一定相同。
为什么?因为每家模型厂商背后的分词器(tokenizer)不一样。
分词器本质上就是:把一段文本切成 token 的规则和词表。不同分词器的词表不同、切分策略不同,所以最后统计出来的 token 数也会不同。
比如下面三种情况就很常见:
同样是 Hello world ,有的分词器可能切成 2 个 token,有的会更多
同样是 LangChain 很好用,中英混合文本常常比纯英文更容易出现 token 差异
同样一段 Python 代码,空格、换行、括号、变量名都会参与切分,所以代码的 token 数往往比肉眼估算更高
2.3.3 常见分词器例子
1. OpenAI 的 cl100k_base
GPT-4、GPT-4o 这一代模型常见的分词器,很多英文文本和代码场景都会用它来计数。
2. OpenAI 的 o200k_base
更新一代的分词器,词表更大,在部分多语言文本里会比 cl100k_base 更省 token。
3. Anthropic / Claude 自家的分词器
Claude 使用自己的 token 切分规则,所以同一句中文、同一段提示词,放到 Claude 里统计,结果通常不会和 OpenAI 完全一样。
一句话记忆:token 不是固定按"几个字"来算,而是按"当前模型使用的分词器怎么切"来算。
2.3.4 可以直接在线测试的工具
OpenAI Tokenizer:https://platform.openai.com/tokenizer
模型提供商通常按 token 数量计费, max_tokens 参数限制的是输出的最大 token 数。如果你发现模型的回答被截断了,通常是 max_tokens 设太小了。
补充理解:
输入 token:你发给模型的提示词、上下文、历史对话
输出 token:模型生成的回答
总消耗 token = 输入 token + 输出 token
所以,一次调用是否贵,不只取决于回答长不长,也取决于你喂给模型的上下文有多长。
2.4 进阶:init_chat_model(动态切换模型)
当你需要在运行时动态切换不同提供商的模型时,init_chat_model 比 ChatOpenAI 更方便------不需要 import 不同的类:
python
# uv add langchain-openai
# uv add langchain-anthropic
# uv add google-genai
from langchain.chat_models import init_chat_model
from dotenv import load_dotenv
import os
load_dotenv()
# 一个函数搞定所有提供商,通过 model_provider 参数区分
python
llm_openai = init_chat_model("gpt-5.4-nano-2026-03-17", model_provider="openai", api_key=os.getenv("OPENAI_API_KEY"), base_url=os.getenv("OPENAI_BASE_URL"))
llm_claude = init_chat_model("claude-opus-4-7", model_provider="anthropic", api_key=os.getenv("ANTHROPIC_API_KEY"), base_url=os.getenv("ANTHROPIC_BASE_URL"))
llm_gemini = init_chat_model("gemini-3.1-flash-lite-preview", model_provider="google_genai", api_key=os.getenv("GEMINI_API_KEY"), base_url=os.getenv("GEMINI_BASE_URL"))
# 调用方式完全一致
for name, llm in [("OpenAI", llm_openai), ("Claude", llm_claude), ("Gemini", llm_gemini)]: response = llm.invoke("用一句话介绍你自己")
print(f"{name}: {response.content}")2.5 什么时候用哪个?
|------------------------------------|---------------------------------|----------------------------|
| 场景 | 用什么 | 原因 |
| 日常开发,模型固定 | ChatOpenAI / ChatAnthropic 等具体类 | 代码提示好,参数明确 |
| 需要动态切换模型(A/B测试、用户选择模型) | init_chat_model | 一个函数搞定所有提供商 |
| 不兼容 OpenAI 格式的平台(Anthropic、Google) | init_chat_model 或对应的专用类 | ChatOpenAI 只能调OpenAI 兼容的接口 |