文章目录
- 如何解决过拟合
-
- 正则化
-
- [**💡 补充:L1 和 L2 的区别**](#💡 补充:L1 和 L2 的区别)
- **为什么加了惩罚项,权重就会变低?**
- 线性回归
-
- [线性 ≠ 直线](#线性 ≠ 直线)
- 损失函数(线性回归):衡量模型准不准
- [从一个 x 到多个 x](#从一个 x 到多个 x)
- 用向量简化表达
- 梯度下降
- 逻辑回归
- 总结
如何解决过拟合
过拟合意味着模型太复杂,模型记住了训练数据的噪声,常用的解决方案有几种:
| 技术 | 核心思想 | 适用场景 |
|---|---|---|
| 增加训练数据 | 更多数据让噪声被稀释 | 数据获取成本低时 |
正则化 |
给模型复杂度加惩罚 |
最通用的方法 |
| 降低模型复杂度 | 用更简单的模型 | 模型明显过于复杂时 |
| 特征选择 | 去掉无关或冗余特征 | 特征多而样本少时 |
| 交叉验证 | 更可靠地评估泛化能力 | 所有场景 |
| 早停 | 训练到验证误差开始上升时停下 | 迭代式模型(神经网络/GBDT) |
| Dropout | 随机丢弃神经元 | 深度学习 |
| 数据增强 | 通过变换扩充训练集 | 图像/文本/音频 |
可能很多同学第一直觉是降低其复杂度就可以了,但现实训练模型我们很难判断该怎么调整,正则化技术可以帮我们自动惩罚不相关的特征,让模型自动降低复杂度。
正则化
正则化 Regularization 本意是使之变得规则、整齐、正常,在机器学习中没正则化时,模型会疯狂拟合造成,变得很不正常。使用加正则化,让模型别太极端、别太复杂,回归正常的简单形态
在前面的多项式演示中,我们用 15 次多项式去拟合  ,结果模型为了穿过每一个带有噪声的训练点,把某些系数
,结果模型为了穿过每一个带有噪声的训练点,把某些系数  推到了极端的值:
推到了极端的值:

一旦出现  、
、 这样的极端系数,曲线就会剧烈震荡------这就是过拟合。
这样的极端系数,曲线就会剧烈震荡------这就是过拟合。
回顾普通线性回归的损失函数:

它只关心一件事:拟合得准不准,完全不管系数有多大,这就是问题所在。
正则化的核心思想是在损失函数中额外加一个惩罚项,系数越大、罚得越重,从而逼迫模型用尽可能小的系数来完成拟合。根据惩罚方式的不同,正则化分为两种:
L2 正则化(Ridge) 在 MSE 后面加上所有权重的平方和作为惩罚:

L1 正则化(Lasso) 则加上所有权重的绝对值之和作为惩罚:

两者唯一的区别就在于惩罚的计算方式------平方还是绝对值。但正是这个看似微小的差异,导致了截然不同的优化效果:
- L2 会将所有权重均匀地压缩到接近 0 的小值,但不会恰好等于 0。当所有特征都对预测有一定贡献,或者特征之间存在多重共线性时,L2 表现最为稳定。
- L1 则会将不重要特征的权重直接压缩到 0,相当于自动进行特征选择。当数据集有大量特征、但真正起作用的只是少数几个时,L1 就非常有价值了。
💡 补充:L1 和 L2 的区别
- L2 正则化 :惩罚的是权重的平方。它会让所有权重都均匀地变小,但很少会绝对变成 0。
- L1 正则化 :惩罚的是权重的绝对值 。它的惩罚更"粗暴",会直接把很多不重要的权重变成 0,从而实现特征选择(让模型变得更稀疏)。
为什么加了惩罚项,权重就会变低?
你可以想象模型现在面临一个两难的抉择:
- 如果它把权重调大,虽然"原始误差"变小了,但后面的"惩罚项"会急剧变大,导致"总损失"变大。
- 如果它把权重调小,"惩罚项"就变小了,虽然"原始误差"可能会稍微变大一点,但"总损失"反而可能更小。
线性回归
参考链接:https://www.yuque.com/qx2io/blz6hd/ae9tduy1ixmry3yl
线性 ≠ 直线
很多同学看到 线性 两个字会以为新型回归仅仅是指直线,其实在数学上,线性描述的是输入与输出之间按比例变化、可叠加的关系。一个映射 如果满足以下两个性质:
如果满足以下两个性质:
- 齐次性

- 可加性 :

就被称为线性映射。几何解释在一维空间中,线性关系表现为一条直线,在高维空间中,表现为平面或超平面。
损失函数(线性回归):衡量模型准不准
模型要找到最好的参数,首先得回答一个问题:当前这组参数到底好不好?
我们需要一种方法来度量预测值与真实值之间的偏差------这就是损失函数(Loss Function) 。在线性回归中,最常用的损失函数是均方误差(Mean Squared Error, MSE),思路非常直白:
- 对每个样本,计算 预测值 − 真实值(即误差);
- 将误差取平方(消除正负号、放大较大误差);
- 对所有样本求平均。

一句话概括:预测值离真实值越远,损失越大。 模型训练的目标,就是让损失函数的值尽可能小。
使用 MSE 有两个好处
- 消除正负号的影响,让误差 绝对值化,防止求和之后正负误差互相抵消;
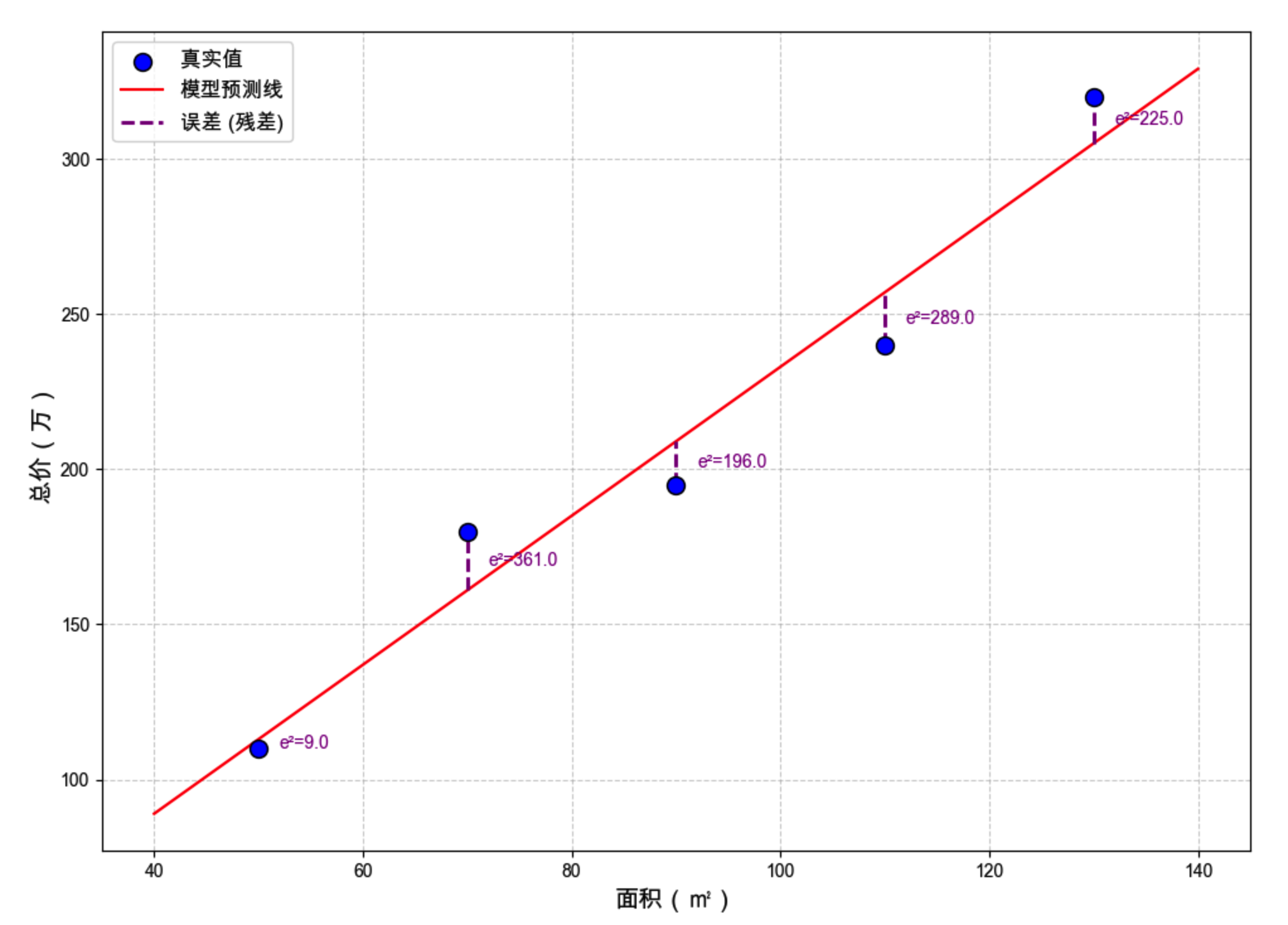
- 放大误差便于模型优化,例如误差为 3 和 0.4,平方后变为 9 和 0.16,差异更明显。
从一个 x 到多个 x
之前单特征的模型是:
现在有  个特征(面积、楼层、距地铁、房龄......),模型自然地扩展为:
个特征(面积、楼层、距地铁、房龄......),模型自然地扩展为:

以房价为例:

每个特征都有自己的权重  ,权重的大小和正负代表了该特征对房价的影响方向和强度:
,权重的大小和正负代表了该特征对房价的影响方向和强度:
| 权重 | 期望符号 | 含义 |
|---|---|---|
 (面积) (面积) |
➕ 正 | 面积越大,房价越高 |
 (楼层) (楼层) |
➕ 正 | 中高楼层通常更贵(简化假设) |
 (距地铁) (距地铁) |
➖ 负 | 离地铁越远,房价越低 |
 (房龄) (房龄) |
➖ 负 | 房子越老,房价越低 |
模型训练结束后,我们甚至可以通过观察各个权重的大小,来判断哪个因素对房价的影响最大。因为线性回归的结果具有很强的可解释性,因此也被广泛用于数据分析。
用向量简化表达
当特征很多时,把公式全部展开写会非常冗长。借助向量的记号,可以将其写得更简洁:

其中:


就是向量的点积 (内积),展开后恰好等于  。
。
会发现,不管是 1 个特征还是 100 个特征,模型的本质结构完全一样------都是特征的加权求和再加偏置,损失函数依然用 MSE,优化方法依然用梯度下降,只不过需要同时更新更多的参数。
py
import numpy as np
from sklearn.linear_model import LinearRegression
# 4 个特征:面积、楼层、距地铁(km)、房龄(年)
X = np.array([
[50, 3, 0.5, 5],
[70, 15, 1.2, 10],
[90, 8, 0.3, 2],
[110, 20, 2.0, 15],
[130, 12, 0.8, 8],
])
y = np.array([180, 210, 320, 280, 380]) # 总价(万元)
# 训练模型
model = LinearRegression()
model.fit(X, y)
# 查看学到的权重
feature_names = ['面积', '楼层', '距地铁', '房龄']
print("各特征权重:")
for name, w in zip(feature_names, model.coef_):
print(f" {name}: {w:+.2f}")
print(f" 偏置 b: {model.intercept_:.2f}")
# 预测:100㎡、10楼、距地铁0.6km、房龄5年
new_house = np.array([[100, 10, 0.6, 5]])
pred = model.predict(new_house)
print(f"\n预测房价:{pred[0]:.1f} 万元")
bash
各特征权重:
面积: +2.42
楼层: +1.30
距地铁: -38.07
房龄: -4.28
偏置 b: 49.53
预测房价:289.0 万元从权重可以看出:距地铁每远 1km,房价大约下降 38 万,这与我们的生活直觉一致。而如果只用面积来预测,100㎡ 大约是 230 万------多了距地铁、楼层、房龄的信息后,预测结果明显更合理。
真实世界的预测任务几乎都涉及多个特征。从单特征到多特征,公式只是从一个乘法变成了一组乘法的加和,但模型的学习逻辑------定义损失、计算梯度、更新参数------没有任何变化,这正是线性回归优雅的地方。
梯度下降
参考文章:https://www.yuque.com/qx2io/blz6hd/drrieqsqls94gz6n
核心思想是:沿着损失函数下降最快的方向,逐步调整参数,直至找到最优解。

-
二维的情况下求导成为导数
我们要求得cost的最小值,就要沿着导数减小的方向移动,所以要加
"负号"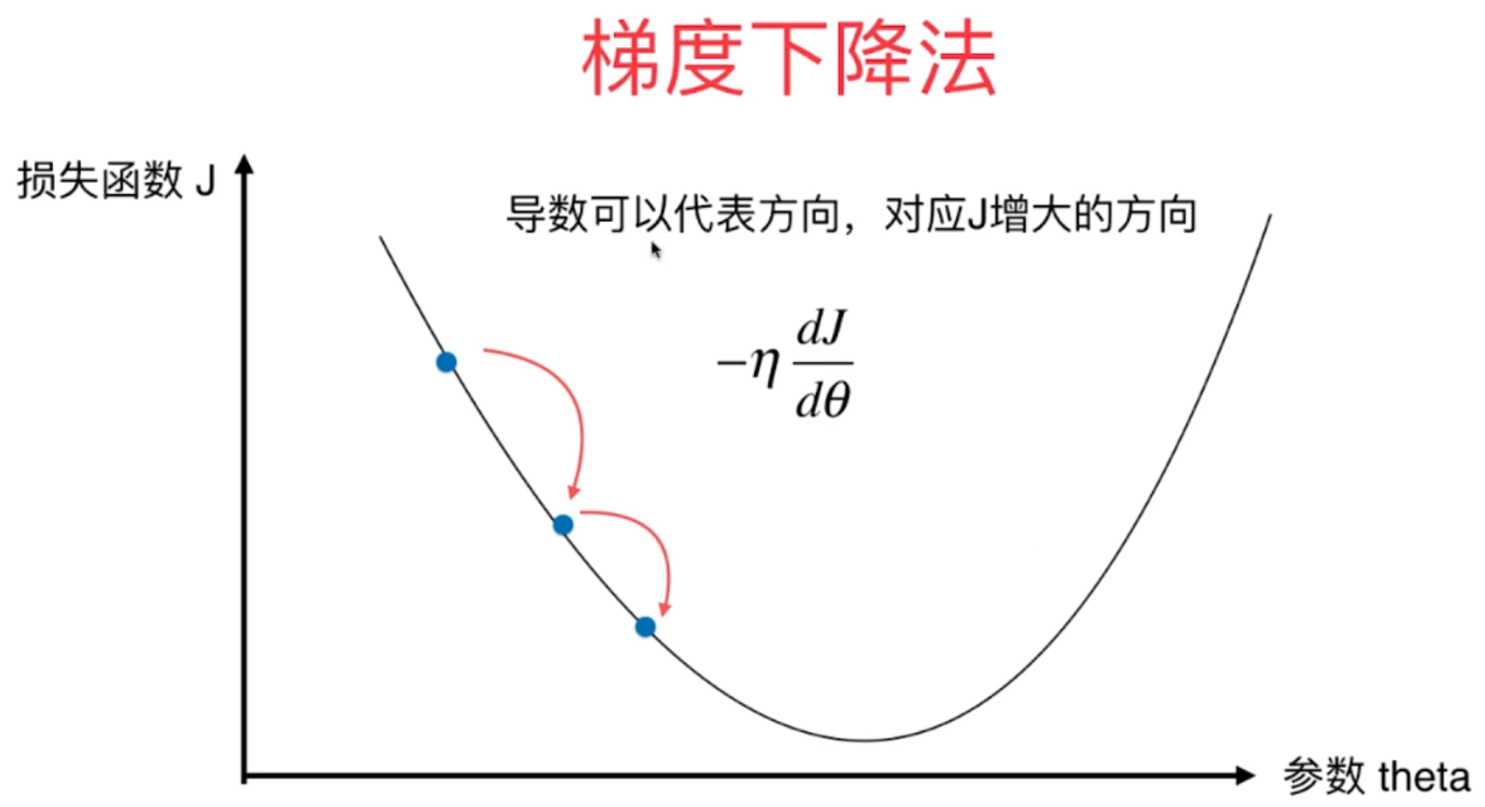
梯度的方向,是函数值增长最快的方向 。反过来说,梯度的反方向,就是函数值下降最快的方向。
-
多维求导则称之为梯度
训练过程可以总结为一个不断循环的流程:输入数据 → 计算预测 → 计算损失 → 计算梯度 → 更新参数 。每完成一轮循环参数就更接近一点,经过多轮迭代模型逐渐收敛到最优解,这整个过程就是模型训练。
梯度:指向最陡上坡的方向
把所有变量的偏导数组合成一个向量,我们就得到了梯度(Gradient)

如果有更多参数  ,梯度就是:
,梯度就是:

梯度下降的迭代公式
基于以上理解,梯度下降的参数更新公式为:

让我们逐项拆解这个公式:
| 符号 | 含义 | 类比 |
|---|---|---|
 |
当前的参数值 | 你现在站的位置 |
 |
在当前参数处的梯度 | 脚下最陡的上坡方向 |
 |
学习率(Learning Rate) | 每一步迈多大 |
 |
沿梯度反方向移动一步 | 朝下坡方向迈一步 |
 |
更新后的参数值 | 你走到的新位置 |
对于线性回归的具体场景,参数更新公式展开为:


py
import numpy as np
import matplotlib.pyplot as plt
# 配置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
np.random.seed(42)
# 房屋数量
n_samples = 100
# 生成随机面积(90-150平米)
areas_m2 = np.random.uniform(90, 150, n_samples)
# 转换为百平米,减少因为两个参数差距过大对学习率的影响
areas = areas_m2 / 100
# 生成房价
prices = 250 * areas + 30 + np.random.randn(n_samples) * 15
print(f"房屋数量: {len(areas)} 套")
print(f"面积范围: {areas_m2.min():.1f} - {areas_m2.max():.1f} 平米 ({areas.min():.2f} - {areas.max():.2f} 百平米)")
print(f"价格范围: {prices.min():.1f} - {prices.max():.1f} 万")
print(f"真实规律: 房价 = 2.5 × 面积(平米) + 30")
bash
房屋数量: 100 套
面积范围: 90.3 - 149.2 平米 (0.90 - 1.49 百平米)
价格范围: 248.0 - 414.8 万
真实规律: 房价 = 2.5 × 面积(平米) + 30推导梯度公式
损失函数(MSE):

对  求偏导:
求偏导:

对  求偏导:
求偏导:

这两个公式的推导过程只需要用到链式求导法则,即先对外层的平方求导,再乘以内层对 或
或  的导数。
的导数。
数据预处理参考文章:https://www.yuque.com/qx2io/blz6hd/qiiexxntlhcdklt2
模型评估参考文章:https://www.yuque.com/qx2io/blz6hd/vcqzedxf0slg89sq
欠拟合与过拟合:https://www.yuque.com/qx2io/blz6hd/xi3329io7sg1zor1
逻辑回归
参考文章:https://www.yuque.com/qx2io/blz6hd/ewwg2w1drdc460i5
逻辑回归损失函数

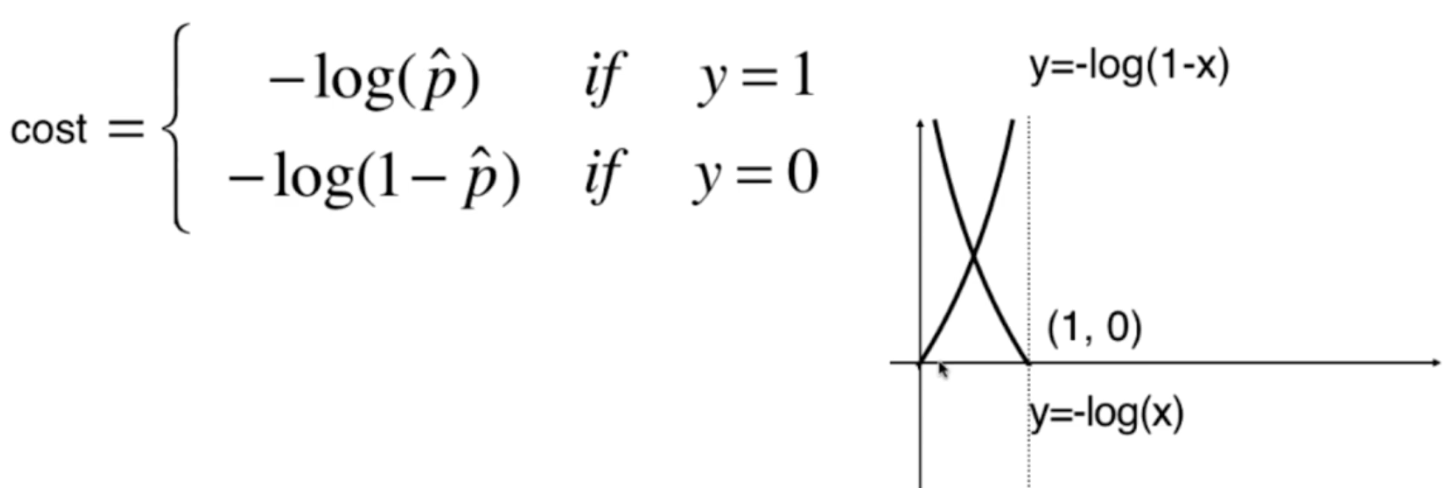
我们只看 x 属于 (0,1) 区间,映射为模型预测的概率 p,对 y 轴 l o g ( p ˆ ) log(\^p) log(pˆ)取负
● 当预测概率 p 趋近于 1 时, − l o g ( p ˆ ) → 0 -log(\^p) \to 0 −log(pˆ)→0
● 当预测概率 p 趋近于 0 时, − l o g ( p ˆ ) → ∞ -log(\^p) \to \infty −log(pˆ)→∞
这正好符合我们对损失函数的期待:
● 概率越接近真实标签,损失越小
● 概率越偏离真实标签,损失越大
● 如果模型非常自信但完全错了,损失会被放大得非常厉害
所以 − l o g ( p ) -log(p) −log(p)是一个非常适合拿来构造分类损失的函数。
最终结果式:
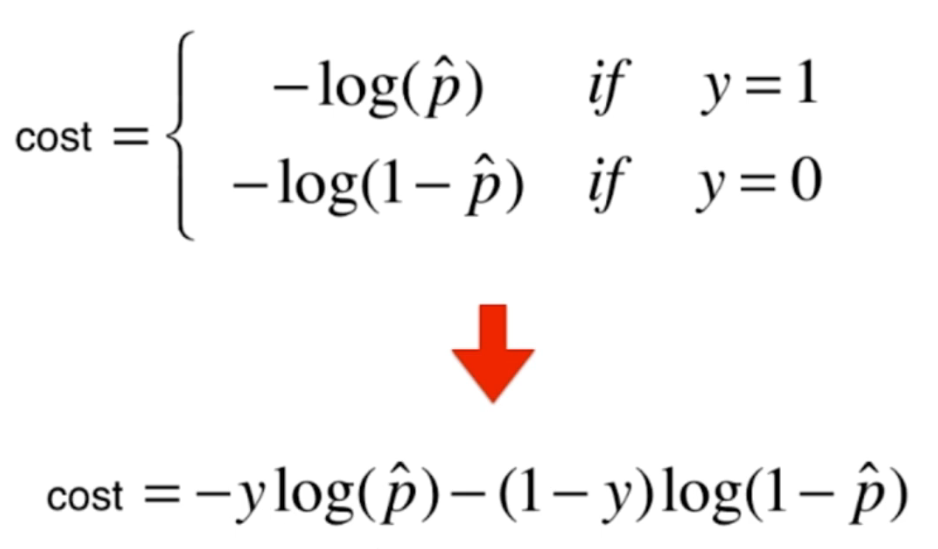
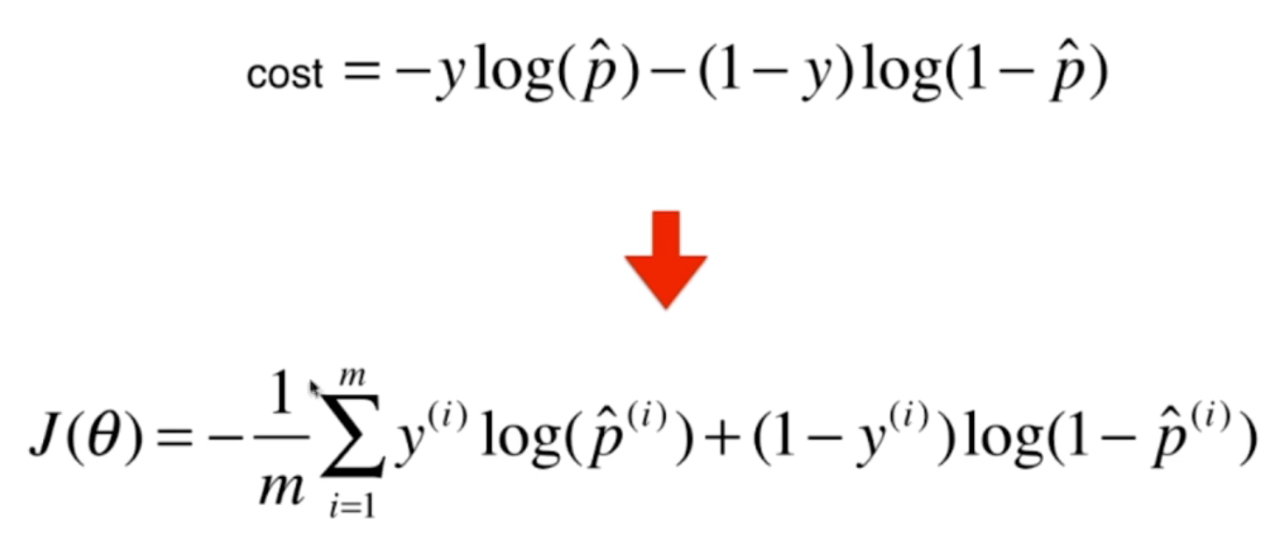

这就是逻辑回归的损失函数------交叉熵损失,整体公式看着长,但如果拆解开看,逻辑很简单:因为对于任何一个样本,真实标签 y y y 要么是 0 要么是 1,所以公式中永远只有一项在起作用,另一项会被自动乘以 0 消掉。
| 真实标签 | 损失项 | 含义 |
|---|---|---|
 |
 |
预测概率越接近 1,损失越小;接近 0 时损失  |
 |
 |
预测概率越接近 0,损失越小;接近 1 时损失 |
使用交叉熵作为损失函数时,它是一个严格的凸函数,无论初始权重在哪里,梯度都不会消失,在远离最优解的地方,梯度反而很大,能够引导模型快速且稳定地收敛到全局最优点。
梯度下降
逻辑回归的梯度推导过程中,Sigmoid 的导数和交叉熵的导数恰好大量约分抵消,最终结果和线性回归的形式一模一样(推导过程过于复杂,建议大家直接记住就行),唯一的区别在于 的含义不同
的含义不同
| 线性回归 | 逻辑回归 | |
|---|---|---|
| 权重梯度 |  |
|
| 偏置梯度 |  |
|
 含义 含义 |
 |
 |
精确率、召回率、F1
从混淆矩阵推导出三个核心指标:



- 精确率 :预测为正类的样本中,真正是正类的比例(
预测质量) - 召回率 :所有真正的正类中,被成功预测出来的比例(
覆盖能力) - F1 :精确率和召回率的调和平均,
综合衡量两者------两者都高,F1 才高
精确率 vs 召回率:二者往往存在权衡。降低决策阈值可以提高召回率(漏报更少),但会降低精确率(误报更多)。根据业务场景决定侧重哪个。
多分类问题
逻辑回归天生是二分类器,但可以扩展到多分类。从二分类扩展到多分类时,最自然的形式就是 Softmax Regression(也叫多项逻辑回归,Multinomial Logistic Regression),一次性输出所有类别的概率。
多分类逻辑回归中,每个类别都有一个线性打分函数,模型先为每个类别计算分数,再通过 Softmax 把这些分数转成一组概率,最后选择概率最大的类别作为预测结果。

如果只有 2 个类别,Softmax 就退化成了 Sigmoid,所以 Sigmoid 是 Softmax 的特例。
逻辑回归就是最简单的神经网络,Softmax 多分类逻辑回归就是神经网络中最常见的输出层形式之一。
总结
| 维度 | 线性回归 | 逻辑回归 |
|---|---|---|
| 解决什么问题 | 回归(预测数值) | 分类(预测类别) |
| 输出 | 任意实数 | 0~1 的概率 |
| 模型 |  |
 |
| 损失函数 | MSE | 交叉熵 |
| 梯度公式 |  |
|
| 评估指标 | MSE / RMSE / R² | Accuracy / F1 / AUC |
| 正则化 | Ridge(L2) / Lasso(L1) | 同样适用,参数叫 C=1/λ |
- 逻辑回归本质上是在线性回归的基础上加了一个 Sigmoid,把输出压缩到 0~1
- 损失函数必须换成交叉熵,否则优化会出问题
- 梯度公式和线性回归形式完全一样,只是 y^的计算方式不同
- 分类问题不能只看准确率,要根据业务场景选择 Precision / Recall / F1
- 逻辑回归虽然简单,但可解释性强、训练快、不容易过拟合,工业界依然大量使用