一.大数据以及hadoop相关概念
1.Hadoop将作业分成若干个task来执行其中包括___和___。
MapTask ReduceTask
2.Hadoop特点?
特点:高可靠性、高扩展性、高效性、高容错性
适合场景:大数据分析、离线分析
不适合场景:少量数据、复杂数据、在线分析
3.Hadoop的关键优势之一是它的可靠性。当某个计算元素或存储单元发生故障时,会发生什么情况?
A. 数据会丟失
B.任务会被重新分配
C. 系统会完全崩溃
D. 沒有任何影响
B.
Hadoop 的可靠性设计使其能够自动处理节点故障,核心机制包括数据副本冗余和任务重新分配。当计算元素(如 TaskTracker)或存储单元(如 DataNode)发生故障时:
- 数据不会丢失:因为 HDFS 默认存储 3 个数据副本,分布在不同节点或机架,单个节点故障不影响数据可用性。
- 任务会被重新调度:JobTracker(MapReduce 1)或 ResourceManager(YARN)会检测到任务失败,并将其重新分配到其他健康节点执行。
4.Google思想三篇论文?
The Google File System
MapReduce:Simplified Data Processing on Large Clusters
Bigtable:A distributed Storage System for Structured Data
二.Hadoop环境安装
1.格式化HDFS系统的命令是
hdfs namenode -format
2.HDFS实现机架感知的配置文件时
core-site.xml
3.一共三台虚拟机102、103、104,简述在Linux系统上安装Hadoop完全分布式模式的每台机器的主要组件及作用(可图表描述)
hdfs:namenode(1个) datanode(多个) secondaryNamenode(1个)
yarn:resource(1个) nomanode(多个)
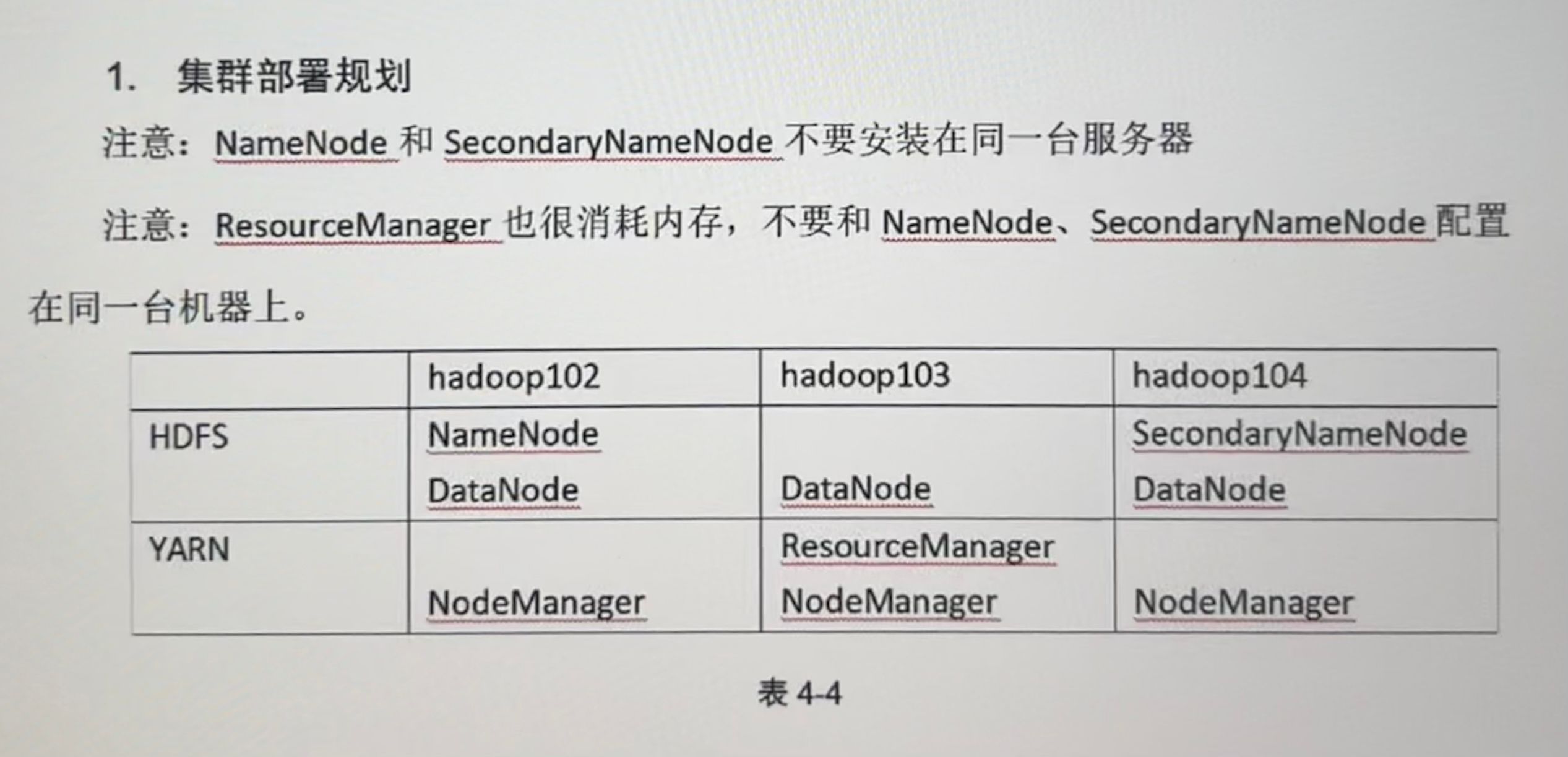
4.为保障Hadoop集群内部进行免密码通讯需要对___进行配置。
ssh
判断题:
5.每次启动Hadoop都要格式化文件系统。
× 格式化命令:hdfs namenode -format
6.在/etc/ssh文件映射ip和主机名称。
× 应该是在
/etc/hosts文件里
7.修改~/.bashrc文件保存后,修改的内容能立即生效。
× source ~/.bashrc 命令使生效
8.优先级顺序
- 客户端代码中设置的值
- ClassPath下的用户自定义的配置文件 (project下的配置文件,例 如/root/IdeaProjects/hdfsClient/src/main/resources/hdfs-site.xml))
- 服务器的自定义配置文件(XXX-site.xml 路径为usr/local/hadoop/etc/hadoop)
- 服务器的默认配置(XXX-default.xml 路径为cd usr/local/hadoop/etc/hadoop)
9.在.ssh文件夹中,某些文件用于存放SSH密钥和授权信息。请选出存放生成的公钥的文件是:
A. known_host
B. id_rsa
C. id_rsa.pub
D. authorized_keys
C.id_rsa.pub
文件路径 用途 敏感等级 ~/.ssh/id_rsa私钥(RSA 算法) 高度敏感 ~/.ssh/id_rsa.pub公钥(RSA 算法) 可公开 ~/.ssh/authorized_keys存储允许登录的客户端公钥(服务器端) 敏感 ~/.ssh/known_hosts存储已访问服务器的公钥(客户端) 低敏感
- Hadoop环境搭建时,配置项fs.defaultFS在_____文件中进行配置,而副本数在______文件中进行配置
core-site.xml hdfs-site.xml
11.要启动Hadoop的两个核心组件,我们需要使用特定的命令。启动HDFS的命令是____,启动YARN的命令是_____。
13.HDFS NameNode对用户的查询端口是___,Yarn查看任务运行情况的端口是____。
9870 8088
三.HDFS
1.HDFS的NameNode主要负责什么?
A. 存储实际数据块
B. 管理文件系统的元数据(如文件目录结构)
C. 处理MapReduce任务
D. 监控DataNode状态
B
2.HDFS默认的副本数量是多少?
3
3.HDFS不适合以下哪种场景?
A. 存储大量小文件
B. 流式读取大文件
C. 高容錯需求
D. 离线批处理
A *见HDFS理论相关 (写文章-CSDN创作中心)
4.HDFS写操作的正确流程是?
A. 客户端切分文件--- NameNode分DataNode 一管道写入一确认队列
B. NameNode分配DataNode 一客户端切分文件一管道写入一确认队列
C. 管道写入一客户端切分文件一 NameNode分配DataNode 一 确认队列
D. 客户端切分文件一管道写入一 NameNode分配DataNode 一确认队列
A *见HDFS读写流程/NN/DN(写文章-CSDN创作中心)
5.Secondary NameNode的作用是?
A. 实时备份NameNode数据
B. 合井Fslmage和EditLog以減小NameNode重启时间
C. 替代故障的NameNode
D. 存储数据块的校验和
B
6.多选(重要)
HDFS的高可用性(HA)实现依赖以下哪些组件?
A. JournalNode
B. ZooKeeper
C. Active NameNode 和 Standby NameNode
D. Secondary NameNode
答案:A, B,C
解析:
HDFS HA通过Active/Standby双NameNode架构实现,依赖JournalNode共享编辑日志,ZooKeeper管理故障切换。Secondary NameNode不参与HA。
7.以下哪些是DataNode的职责?
A. 存储实际数据块
B. 定期向NameNode发送心跳和块报告
C. 执行MapReduce任务 yarn
D. 管理文件系统命名空间 namlenode
A,B
8.HDFS默认的块大小?(Block size)
在Hadoop 2.x版本中是128MB
9.HDFS进入安全模式的命令是____。
hadoop disadmin -safemode enter
10.HDFS默认的副本存储策略中,第一个副本存放在____所在节点。
客户端
11.HDFS中负责管理元数据的守护进程是_____。
NameNode
12.HDFS支持存储单个文件的大小超过PB级别。
√
13.HDFS的写入操作需要客户端直接与DataNode通信完成数据块传输。
现本地的/zhangsan目录下有data.txt文件,请使用shell命令完成以下要求:
1) 在hdfs的根目录下创建test目录。
2) 将本地/zhanjian/data.txt文件拷贝到hdfs的/test目录下。
3) 在hdfs的/test目录下创建test.xml文件。
4)将hdfs 的/test/test.xml 下载到Linux本地的当前目录。
5) 查看hdfs的 /test/test.xml文件内容。
hadoop fs -mkdir /test hdfs dfs -mkdir -p /test
hadoop fs -put /zhanjian/data.txt /test (copyFromLocal
hadoop fs -touchz /test/test.xml
hadoop fs -get /test/test.xml (copyToLocal
hadoop fs-cat /test/test.xml
14.查看Hadoop集群各台服务器节点进程启动状况的命令是
jps
15.HDFS的edits文件和fsimage文件中,_edits_体现了HDFS最新状态。
fsimage secondarynamenode namenode将两者合并起来
- 数据节点(DataNode)负责存储数据,一个数据块会在多个DataNode中进行冗余备份
HDFS默认存储__3_份
17.格式化HDFS系统的命令是
hdfs namenode -format
20.在Maven项目中pom.xml作用是记录项目的日志信息。(判断)
错误
pom.xml是依赖版本,自己通过maven去下载 pom.xml是给一个需要下载的清单,maven根据这个清单去下载工程需要的依赖。
21 编程:
下面是JAVA将HDFS上sunwukong.txt文件下载到用户电脑D盘,用户名为atguigu,请在横线上填写出缺失的代码。
@Test
public void testCopyToLocalFile() throws IOException, InterruptedException, URISyntaxException(
// 1 获取文件系统
configuration configuration = new Configuration();
Filesystem fs = Filesystem.get (new URI ("//172.18.0.2:9000"),
((1)___________),"((2)__________)");
// 2 执行下载操作
// boolean delSre 指是香将原文件删除
// path sre 指要下裁的文件路径
// Path dst 指将文件下載到的路径
// boolean useRawlocalFilesystem 是否开启文件校验
fs.copyToLocalFile(false, new Path ("/xiyou/huaguoshan/sunwukong. txt"), new Path(((3)______)), true);
//3 关闭贷源
fs. ((4)_______)();Filesystem fs = Filesystem.get (new URI ("//172.18.0.2:9000"),configuration, "atguigu");
fs.close();
编程
编程
23.在Hadoop的HDFS系统中,哪种角色负责维护和管理数据块的存储位置信息?
A. NameNode
B. DataNode
C. Secondary NameNode
D. Client
A. NameNode
24.在hadoop3.x版本的HDFS系统中,NameNode为用户提供查询服务的端口号是多少?
A. 8020
B. 9000
C. 9870
D. 50070
C. 9870
25.在Hadoop的分布式文件系统HDFS中,Secondary NameNode的主要职责是什么?
A. 存储最新的fsimage和edits日志
B. 监控NameNode的状态
C. 台并fsimage和edits日志生成新的镜像文件
D. 执行数据块的分配和管理
BC
26.(多选)HDFS上的文件数据块会保存多个副本,以提供容错和效率。以下哪些是HDFS默认的副本存放策略?
A. 副本一放在上传文件的数据节点或随机选择磁盘不太满、CPU不太忙的节点
B.副本二放在与副本一所在机架不同的节点上
C.副本二放在与副本二相同机架的不同节点上
D. 所有副本均匀分布在不同机架上的节点
ABC
- 在HDFS的edits文件和fsimage文件中,__edits文件__保存了HDFS的更新操作。
___fsimage文件___又件保存HDFS的元信息。
四.Mapreduce
1.如果一个Map任务失败,MapReducs柜架会如何处理?
A. 终止整个作业
B. 自动在其他节点重新执行该任务
C. 仅记录错误日志
D. 由用户手动启动
答案:B
解析:MapPeduce框架具有容错机制,会自动将失败的Map任务重新调度到其他可用节点执行。
2.以下哪个阶段不晨于MapReduce任务流程?
A, Split
B. Merge
C. Shuffle
D. Reduce
答案:B
解析:MapReduce核心流程包括Split(分片)、Map、Shuffle、Reduce,Merge不属于标准阶段(Merge是Shuffle中溢写文件的合并操作)。
3.Combiner的作用是?
A. 合并多个Map任务的输出
B. 在Map端本地聚合数据以减少网络传输
C. 替代Reduce阶段
D.排序Map输出的键值对
答案:B
解析:Combiner在Map端对相同键的值进行局部聚合,减少Shuffle阶段的数据传输量,提升性能。
4.MapReduce的默认输入格式是?
A. TextlnputFommat
B. Key ValuelnputFormat
C. SequenceFilelnputFormat
D. NLinelnputFormat
TextlnputFommat
5.MapReduce的Shufile阶段发生在?
A. Map任务输出到Reduce任务输入之间
B. Map任务开始之前
C. Reduce任务输出之后
D. 仅限Combiner阶段
答案:A
解析:Shuffle阶段是Map任务输出到Reduce任务输入之间的关键步骤,包括分区、排序、传输数据等操作
6.MapReduce作业中,以下哪些阶段由框架自动处理?
A. 数据分片(Split)
B. Map任务的输出排序
C. Shuffle和Sort
D. Reduce任务的最终输出写入
AC
Map任务的输出持序,Reduce任务的最终输出写入 在driver类里面有代码控制
7.以下哪些技术可以优化MapReduce性能?(多选)
A. 使用Combiner减少网络传输
B. 启用数据压缩(如Snappy)
C. 增加Reduce任务数量
D. 避免使用Writable类型
答案:A,B,C
解折:Combiner和压缩减少数据传输,合理增加Reduce任务数提升并行度,Writable是Hadoop序列化必需组件,无法避免。
8.哪些操作可能导致MapReduce任务失败?
A. Map任务抛出未捕获异常
B. DataNode磁盘故牌
C. Reduce任务等待Map任务输出超时 D. 用户代码中调用System.exit()
答案:A, C.D
解折:Map任务异常、Reduce超时或用户代码强制退出会导致任务失败,DataNode故障田HDFS副本机制处理,不直接影响任务(除非副本丢失)。
9.Hadoop在Mapper和Redueer之间的过程叫做
shuffle
10.MapReduce中可以通过Counter类来创建自定义计数器。
11.MapReduce默认的输入格式是。
TextInputFormat
12.MapReduce中负责将Map输出进行分组排序的阶段是Shuffle阶段。
- Combiner仅在Map端进行局部聚合,无法处理跨Map任务的全局聚合,最终仍需Reaucesh段完成最终结果处理。
14.MapReduce默认会对Map任务的输出按键进行排序
解析:Shufle阶段会自动对Map输出的键值对按键进行排序,确保相同键的数据发送到同一Reduce 任务。
15.MapReduceSReduce任务数量必须由用户显式指定。
解析:Reduce任务数默认值为1,用户需通过1ob.setNumReduceTasks()显式设置,香则仅运行一个Reduce任务。
16.Map的主要工作是将多个任务的计算结果进行汇总。
错误
17.下列哪种业务场暴中,可以直接使用Reducer充当Combiner使用?( )
A. sum求和 B.max求最大值
C.count求计数 D. avg求平均
ABC
18.Partition的数量决定Reducer的数量。
19.WordCount案例在MapReduce中的流程是什么?
Wordcount案例:在给定的文本文件中统计输出每一个单词出现的总次数。请概述WordCoun 例在遵循MapReduce编程模型下的主要执行步骤。
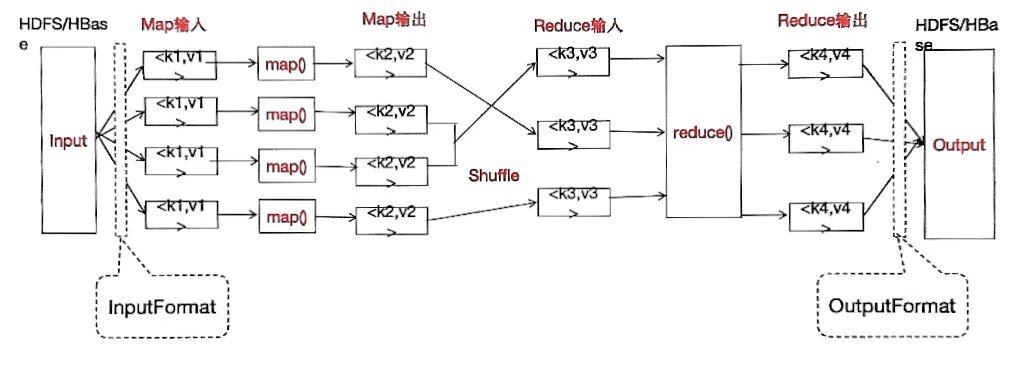
21.在大数据处理中,combiner和reducer都是用来聚合数据的组件。它们的主要区别在于运行位置,请问它们的区别具体是什么?
A. 执行阶段不同
B. 功能不同
C. 输入格式不同
D. 输出格式不同
A
22.(多选题 )Hadoop MapReduce中,我们可能会遇到分区相关的问题。请根据你的理解选择正确的描述:
A.Parttioner是一个负责实现数据分配的类
B.默认的分区方式是Hash分区
C.Partition的作用之一是平衡Reduce阶段的负载
D.Reducer的数量由Map任务的数量决定
ABC
23.Hadoop官方示例源码Wordcount程序,从结构上可以分为3个部分。请问,下列选项中哪些属于该程序的核心模块?
A. Driver模块
B. Марреr模块
C. Reducer模块
D. Main模块
ABC
24.在MapReduce中,使用____Partitioner____组件实现数据的分区,使用____Combiner____组件实现数据的合并。
五.Maven项目相关
在 Maven 项目中 pom.xml作用是记录项目的日志信息。(判断)
六.Yarn
1.YARN的三种调度器及其主要功能?(见另一篇文章)
- Fifo;
- 容量调度器;
3.公平调度器。
2.在计算机系统中,某个组件负责资源的分配和任务的执行,这个组件通常被称为调度器。那么,在分布式系统中,下面哪个选项可能是它的调度器?
A. YARN
B. Spark
C. HDFS
D. Kafka
A
3.在分布式运算时,有一个角色负责整个程序的过程调度以及状态协调。它是?
A. MapTask
B. ReduceTask
C. MrAppMaster
D. DataNode
C