在构建多租户 SaaS 平台或企业内部服务网关时,计费模块往往是最容易被低估复杂度的环节。很多团队在项目初期只关注功能实现,认为"先跑通业务逻辑,计费后面再加",结果到了商业化运营阶段,发现历史数据缺失、统计口径不一致、高并发下扣费不准等问题集中爆发,甚至需要重构整个架构。更棘手的是,不同的业务场景对计费的需求差异巨大:有的需要按调用量阶梯定价,有的要求实时防超刷,还有的必须满足严格的数据合规要求。
这篇文章将深入探讨如何从零开始构建一个灵活、安全且可扩展的计费系统。我们将覆盖从快速集成方案到自定义规则引擎的全流程,重点解决高并发下的实时扣费难题,并分享如何在全开源架构下确保数据安全与隐私合规。无论你是正在规划新平台的架构师,还是负责优化现有系统的后端开发者,文中的实战策略和配置示例都能帮助你避开常见的坑,实现从测试环境到生产环境的平滑迁移,最终建立起一套能够支撑商业化运营的自动化账单与对账体系。
① 多租户 SaaS 平台计费模块快速集成方案
对于大多数 SaaS 平台而言,自研计费核心不仅周期长,而且容易在精度和并发处理上出问题。快速集成的核心思路是"解耦":将计费逻辑从主业务代码中剥离,通过标准化的 API 或 SDK 进行交互。目前成熟的开源方案通常提供多租户隔离机制,允许为每个租户独立配置计费策略、货币单位和结算周期。
在集成初期,建议采用"旁路监听"模式。即业务系统正常处理请求,同时异步发送用量事件到计费服务。这样即使计费服务暂时不可用,也不会阻断主业务流程。例如,可以使用消息队列(如 Kafka 或 RabbitMQ)作为缓冲层:
python
# 伪代码:业务侧发送用量事件
def record_usage(tenant_id, feature_code, quantity):
event = {
"tenant_id": tenant_id,
"feature": feature_code,
"amount": quantity,
"timestamp": get_current_timestamp()
}
# 异步发送到消息队列,非阻塞
message_queue.publish("usage_events", event)这种架构不仅降低了耦合度,还为后续的流量削峰和数据重放提供了基础。集成时需注意租户标识的统一性,确保所有微服务传递的 tenant_id 格式一致,避免后续分摊统计出现偏差。
② 企业内部 API 网关用量统计与成本分摊
在大型企业内部,多个部门共享同一套 API 网关资源,如何公平地分摊成本是一个典型痛点。解决方案是在网关层植入计量插件,实时捕获每个请求的来源部门、接口路径及消耗资源(如 CPU 时间、带宽)。
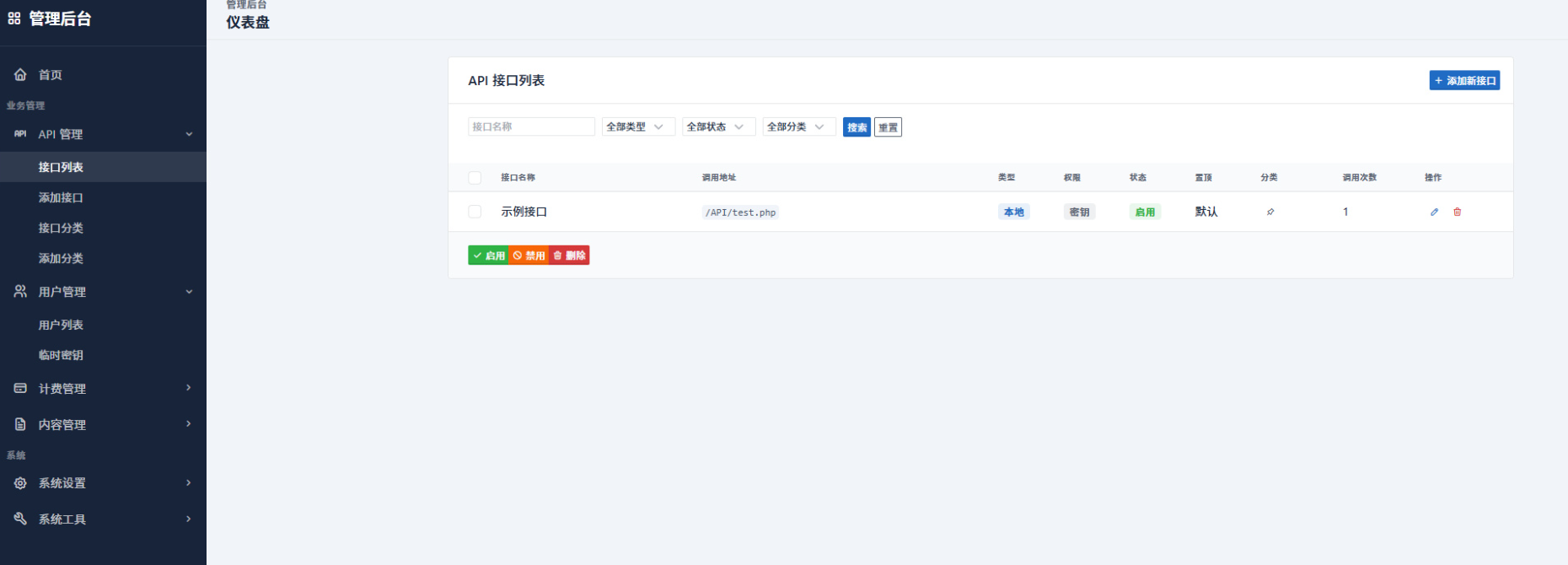
关键在于建立准确的映射关系。可以通过 HTTP Header 中的自定义字段(如 X-Dept-ID)或 API Key 的前缀来识别归属部门。网关层收集数据后,定期聚合生成部门维度的用量报表。为了体现资源的真实成本,可以引入权重系数,例如将耗时较长的数据库查询操作赋予更高的计费权重。
yaml
# 网关配置示例:定义不同接口的资源权重
rate_limiting:
rules:
- path: "/api/v1/heavy-query"
weight: 5.0 # 高消耗接口
- path: "/api/v1/light-check"
weight: 0.5 # 低消耗接口通过这种方式,财务部门可以依据报表向各业务线出具内部结算单,促使各部门优化调用策略,减少无效请求,从而降低整体基础设施成本。
③ 开发者社区按调用量阶梯定价策略实现
面向开发者社区的 API 服务,通常采用阶梯定价来鼓励使用并保障收益。实现这一策略的核心在于动态匹配当前用量所在的区间,并应用对应的单价。
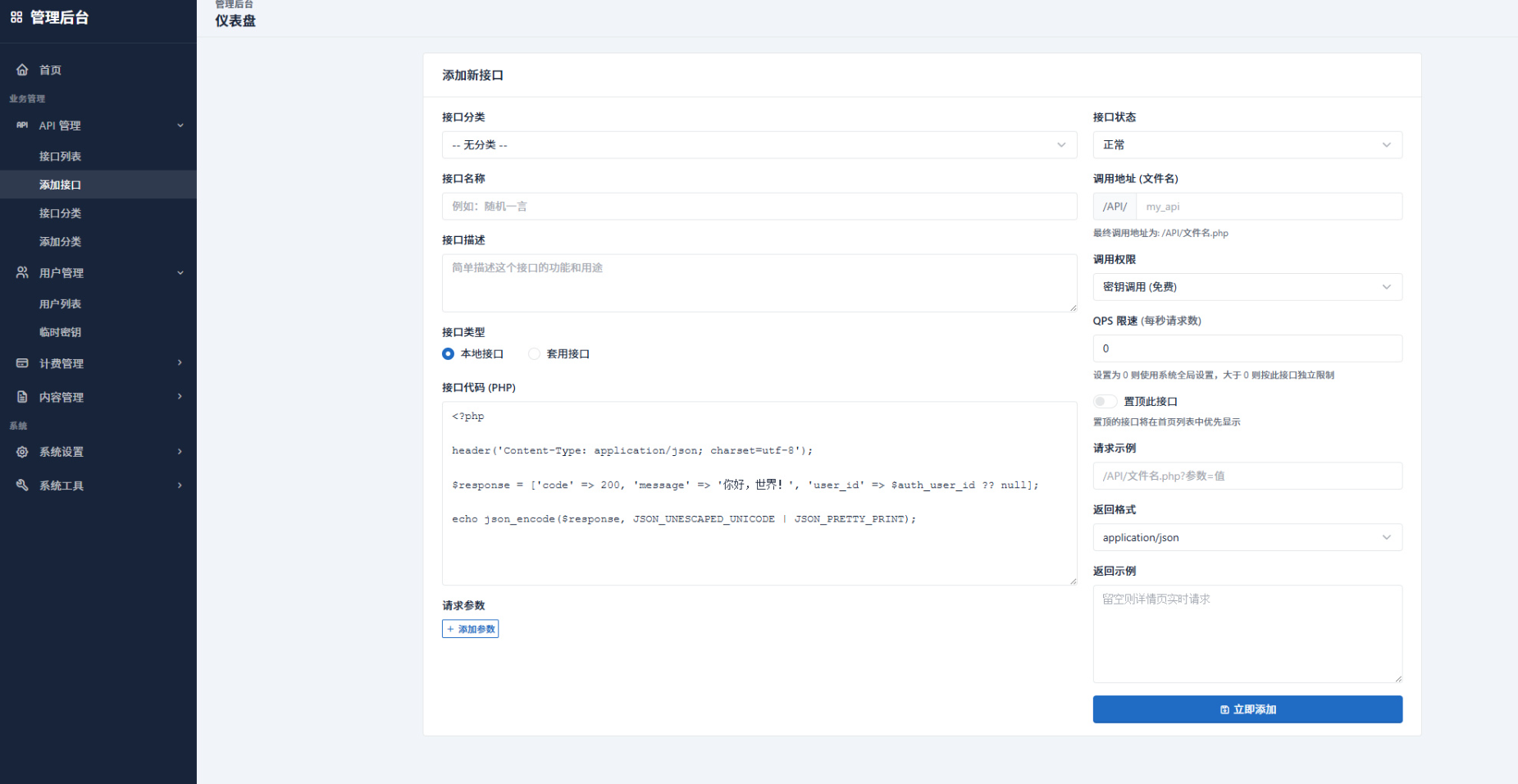
逻辑上,我们需要维护一个有序的阶梯配置表。当用户发起计费请求时,系统累加其当前周期的总用量,判断落入哪个区间。值得注意的是,阶梯可以是"超额累进"(类似个税,不同段不同价)或"全额累进"(达到阈值后全部用量按新价格)。大多数场景推荐超额累进,体验更平滑。
javascript
// 阶梯定价计算逻辑示例
function calculateFee(totalUsage, tiers) {
let fee = 0;
let remaining = totalUsage;
for (let i = 0; i < tiers.length; i++) {
const tier = tiers[i];
const limit = tier.limit === Infinity ? remaining : Math.min(remaining, tier.limit - (i > 0 ? tiers[i-1].limit : 0));
if (remaining <= 0) break;
fee += limit * tier.pricePerUnit;
remaining -= limit;
}
return fee;
}配置表中应包含 limit(上限)和 pricePerUnit(单价)。这种结构支持运营人员随时调整价格策略而无需修改代码,只需更新配置即可生效。
④ 高并发场景下实时扣费与防超刷机制
在高并发场景下,实时扣费面临两大挑战:性能瓶颈和并发竞争导致的超卖(超刷)。传统的数据库行锁在每秒数万次的请求面前会成为严重瓶颈。
解决思路是引入"预扣费"机制结合本地缓存。用户发起请求前,先在 Redis 中尝试扣除额度。利用 Redis 的原子操作(如 DECRBY 或 Lua 脚本)保证并发安全。如果扣减成功,则执行业务逻辑;若余额不足,直接拦截请求。
lua
-- Redis Lua 脚本:原子性预扣费
local key = KEYS[1]
local cost = tonumber(ARGV[1])
local balance = tonumber(redis.call('GET', key) or "0")
if balance >= cost then
redis.call('DECRBY', key, cost)
return 1 -- 成功
else
return 0 -- 失败,余额不足
end为了防止缓存数据与持久化数据不一致,需要有一个异步任务定期将 Redis 中的扣费记录同步到数据库,并进行最终一致性校验。此外,针对恶意刷量,还应设置单位时间内的最大请求频次限制,一旦触发阈值立即熔断该用户的访问权限。
⑤ 自定义计费规则引擎的配置与动态生效
业务形态千变万化,硬编码计费规则显然无法适应。我们需要一个轻量级的规则引擎,支持通过配置文件或管理后台动态定义计费逻辑。
规则引擎的核心是"条件 - 动作"模型。条件可以基于用户属性(如等级、地区)、时间窗口(如工作日、高峰期)或用量指标。动作则是具体的计费公式或折扣率。推荐使用表达式语言(如 SpEL、Aviator 或 JSONata)来描述这些规则。
例如,配置一条规则:"如果是 VIP 用户且在周末调用,享受 8 折优惠"。系统加载配置后,将其编译为可执行对象。当请求到来时,引擎根据上下文环境评估规则,动态计算出最终费用。这种设计使得产品运营可以在不发布新版本的情况下,即时上线促销活动或调整 pricing 策略,极大提升了业务响应速度。
⑥ 全开源架构下的数据安全与隐私合规部署
在涉及金钱交易和用户用量的系统中,数据安全是底线。采用全开源架构意味着我们需要自行把控每一个环节的安全加固。首先,所有敏感数据(如用户 ID、计费金额)在传输过程中必须强制使用 TLS 加密,存储时则需进行字段级加密。
隐私合规方面,要遵循"最小化采集"原则。计费系统只保留必要的用量元数据,避免存储完整的请求 Payload。对于需要长期保存的账单数据,应实施脱敏处理。此外,必须建立完善的审计日志,记录每一次计费规则的变更、每一笔人工调整操作,确保所有行为可追溯。
在部署架构上,建议将计费数据库部署在独立的私有子网中,禁止公网直接访问。通过堡垒机进行运维操作,并开启数据库的慢查询监控和异常登录报警。定期开展漏洞扫描和渗透测试,及时修补开源组件的已知安全风险。
⑦ 从测试环境到生产环境的平滑迁移路径
计费系统的迁移风险极高,任何数据错漏都可能导致资损。平滑迁移的关键在于"双轨运行"和"数据比对"。
第一阶段,在新旧系统并行期间,所有流量同时打入两套系统,但仅以旧系统结果为准进行实际扣费,新系统只做"影子计算"。第二阶段,启动自动化比对脚本,逐条核对两套系统的计算结果。重点关注边界条件(如刚好达到阶梯阈值)和异常场景。
bash
# 简单的数据比对脚本逻辑示意
if [ "$old_fee" != "$new_fee" ]; then
log_error "Mismatch found for tenant $tenant_id: Old=$old_fee, New=$new_fee"
alert_team
fi只有当连续运行一段时间(如一个完整结算周期)且差异率为零时,才考虑切换流量。切换过程应采用灰度发布策略,先切分少量非核心租户到新系统,观察稳定后再逐步扩大范围,直至完全替代。
⑧ 商业化运营中的账单生成与自动化对账
账单生成不仅仅是数据的罗列,更是用户体验的重要组成部分。系统应支持定时任务(如每月 1 号)自动触发账单生成流程,汇总当期所有用量明细,应用优惠券后,生成 PDF 或 HTML 格式的账单推送给用户。
自动化对账则是财务闭环的关键。系统需对接银行流水或第三方支付渠道的对账单,通过算法自动匹配内部的收款记录。对于金额一致的交易自动核销;对于存在差异的记录(如手续费扣除、退款延迟),自动生成异常报告供财务人员人工介入。
为了提高效率,可以引入机器学习模型辅助识别常见的对账差异模式,减少人工重复劳动。同时,提供自助门户让企业用户随时下载历史账单和税务发票,降低客服压力。
⑨ 基于历史数据的用量预测与资源弹性扩容
精准的用量预测不仅能指导计费策略,还能优化底层资源成本。通过分析历史用量数据的时间序列特征(如周期性波动、增长趋势),可以构建预测模型。
例如,发现某类 API 在工作日上午 10 点会出现峰值,系统可提前 30 分钟自动触发扩容策略,增加计算节点以应对流量洪峰;而在深夜低谷期自动缩容,节省云资源开支。这种基于预测的弹性伸缩比单纯的阈值报警更加前瞻和平滑,能有效避免突发流量导致的服務降级。
预测数据还可以反哺销售团队,帮助识别高潜力客户或预警可能流失的客户(如用量突然大幅下降),从而制定针对性的运营动作。
⑩ 二次开发扩展:对接第三方支付与通知系统
计费系统的最后一步是资金流转与信息触达。为了适应不同地区的支付习惯,系统架构必须具备良好的扩展性,支持插件化对接支付宝、微信支付、Stripe 等第三方渠道。
对接时,重点处理回调通知的幂等性。第三方支付渠道可能会重复发送支付成功通知,计费系统必须通过唯一的订单号去重,防止重复入账。同时,建立状态机管理订单生命周期(待支付、支付中、已完成、已退款),确保状态流转的严谨性。
通知系统则应支持多渠道分发。除了站内信和邮件,还可集成短信、钉钉、企业微信等即时通讯工具。当余额低于阈值或账单生成时,自动触发模板消息提醒用户充值或查看账单,形成完整的业务闭环。通过标准化的 Webhook 接口,用户甚至可以自定义接收通知的地址,将计费事件集成到他们自己的运维监控体系中。