Hive 安装
Hive 是数据仓库和 SQL 查询入口,安装前最好先把 HDFS、YARN、MapReduce2、Tez 都准备好。这样 Hive 安装完成后,Metastore、HiveServer2、WebHCat 和客户端配置能够一次接上,不需要反复回头补依赖。
本篇使用外部 MySQL / MariaDB 作为 Hive Metastore 数据库,数据库放在 hadoop1.test.com,示例账号为 hive / hive。
::: warning
hive / hive 只是教程环境里为了方便演示使用的弱密码。生产环境请给 Hive 单独创建高复杂度密码,并限制授权范围,只授予 Hive Metastore 库的访问权限。
:::
本次角色分配如下:
| 主机 | Hive 角色 |
|---|---|
hadoop1.test.com |
WEBHCAT_SERVER、HCAT、HIVE_CLIENT |
hadoop2.test.com |
HIVE_METASTORE、HIVE_SERVER、HCAT、HIVE_CLIENT |
hadoop3.test.com |
HCAT、HIVE_CLIENT |
1. 先准备 Hive Metastore 数据库
在 hadoop1.test.com 上创建 Hive 使用的库和用户:
sql
CREATE DATABASE IF NOT EXISTS hive
DEFAULT CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;
CREATE USER IF NOT EXISTS 'hive'@'%' IDENTIFIED BY 'hive';
CREATE USER IF NOT EXISTS 'hive'@'localhost' IDENTIFIED BY 'hive';
GRANT ALL PRIVILEGES ON hive.* TO 'hive'@'%';
GRANT ALL PRIVILEGES ON hive.* TO 'hive'@'localhost';
FLUSH PRIVILEGES;我会在安装前先用 Hive 用户试连一次:
sh
mysql -uhive -phive -h hadoop1.test.com -D hive能进入 hive 库,就说明数据库、用户、授权和网络访问都已经准备好。这里如果没有提前建库,安装向导里的数据库连接测试通常会报 Unknown database 'hive'。
2. 选择 Hive 服务
进入 服务与组件 ,点击 新增服务 ,勾选 Hive。
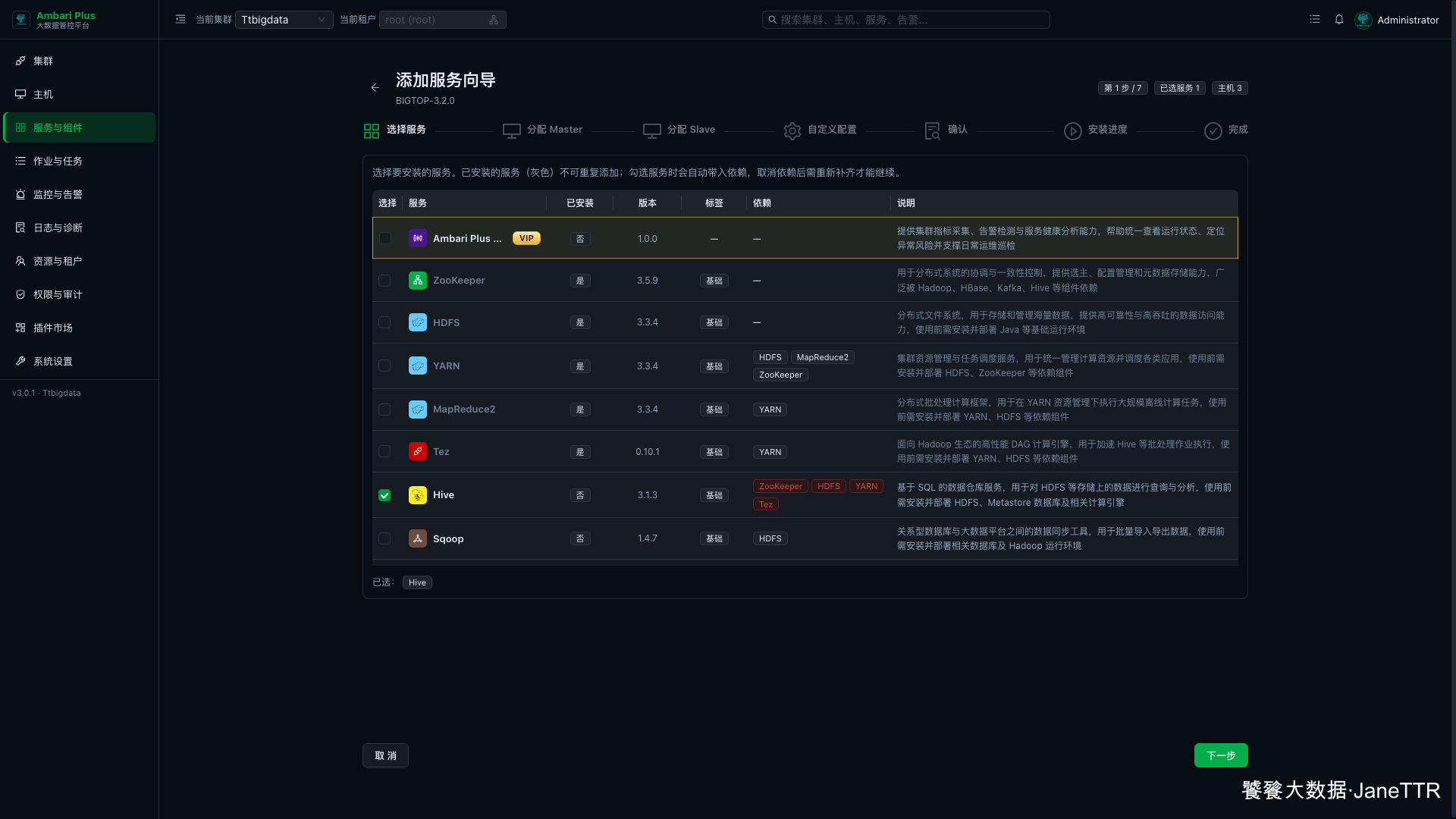
这里不要同时勾选太多服务。Hive 本身依赖关系比较多,单独安装更容易看清数据库、Kerberos 凭据和组件启动是否正常。
3. 分配 Hive Master
Master 分配页里,Hive 会出现三个核心服务端角色。
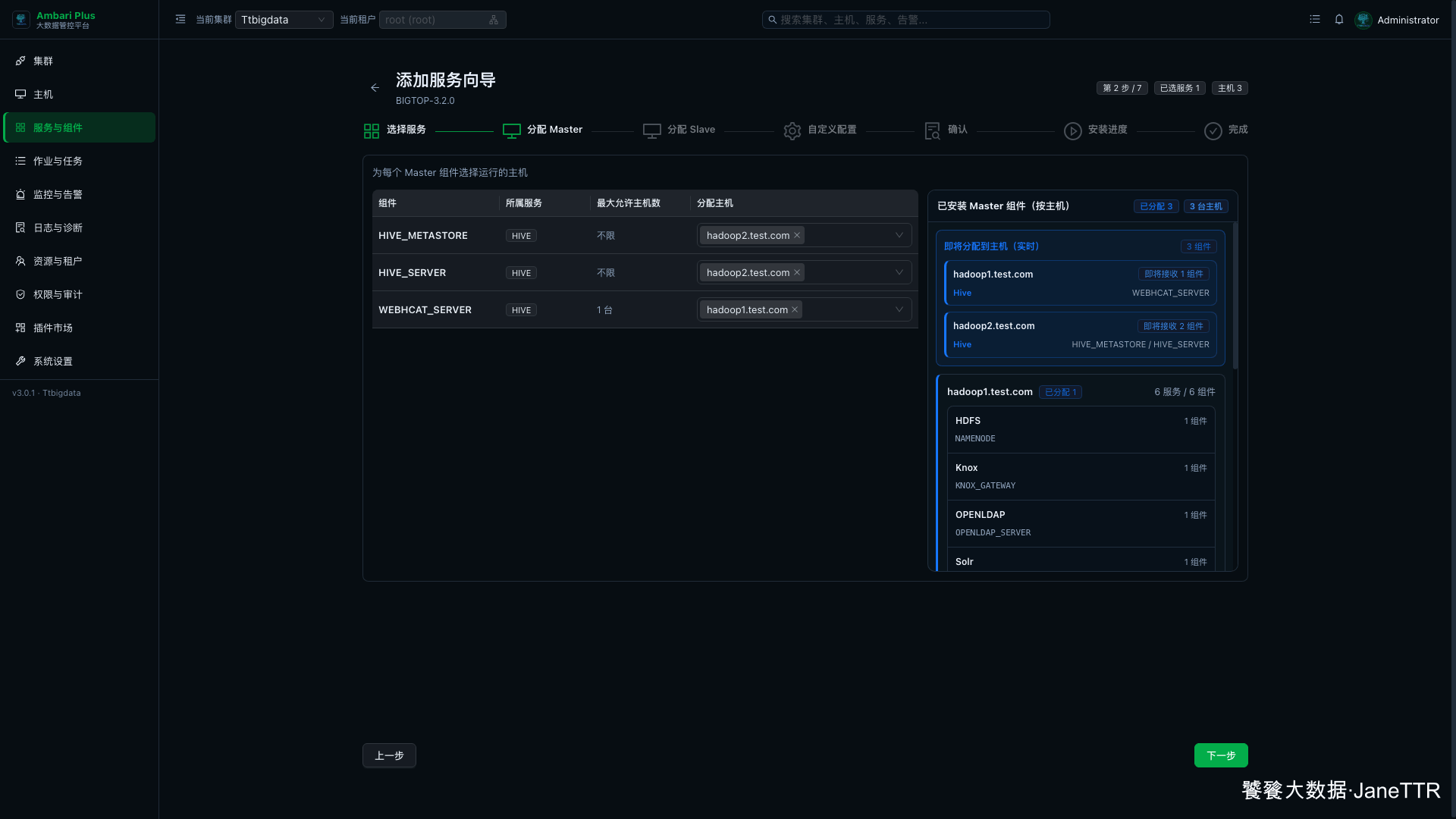
本次这样分配:
| 组件 | 主机 | 说明 |
|---|---|---|
HIVE_METASTORE |
hadoop2.test.com |
Hive 元数据服务。 |
HIVE_SERVER |
hadoop2.test.com |
HiveServer2,对外提供 JDBC / Beeline 查询入口。 |
WEBHCAT_SERVER |
hadoop1.test.com |
WebHCat / Templeton 入口。 |
小集群可以把 Metastore 和 HiveServer2 放在同一台机器上。生产环境如果 Hive 压力比较大,可以再考虑拆开部署和高可用。
4. 分配 Hive Client
Slave 与 Client 分配页里,Hive 没有 Slave 组件,主要分配 HCAT 和 HIVE_CLIENT。
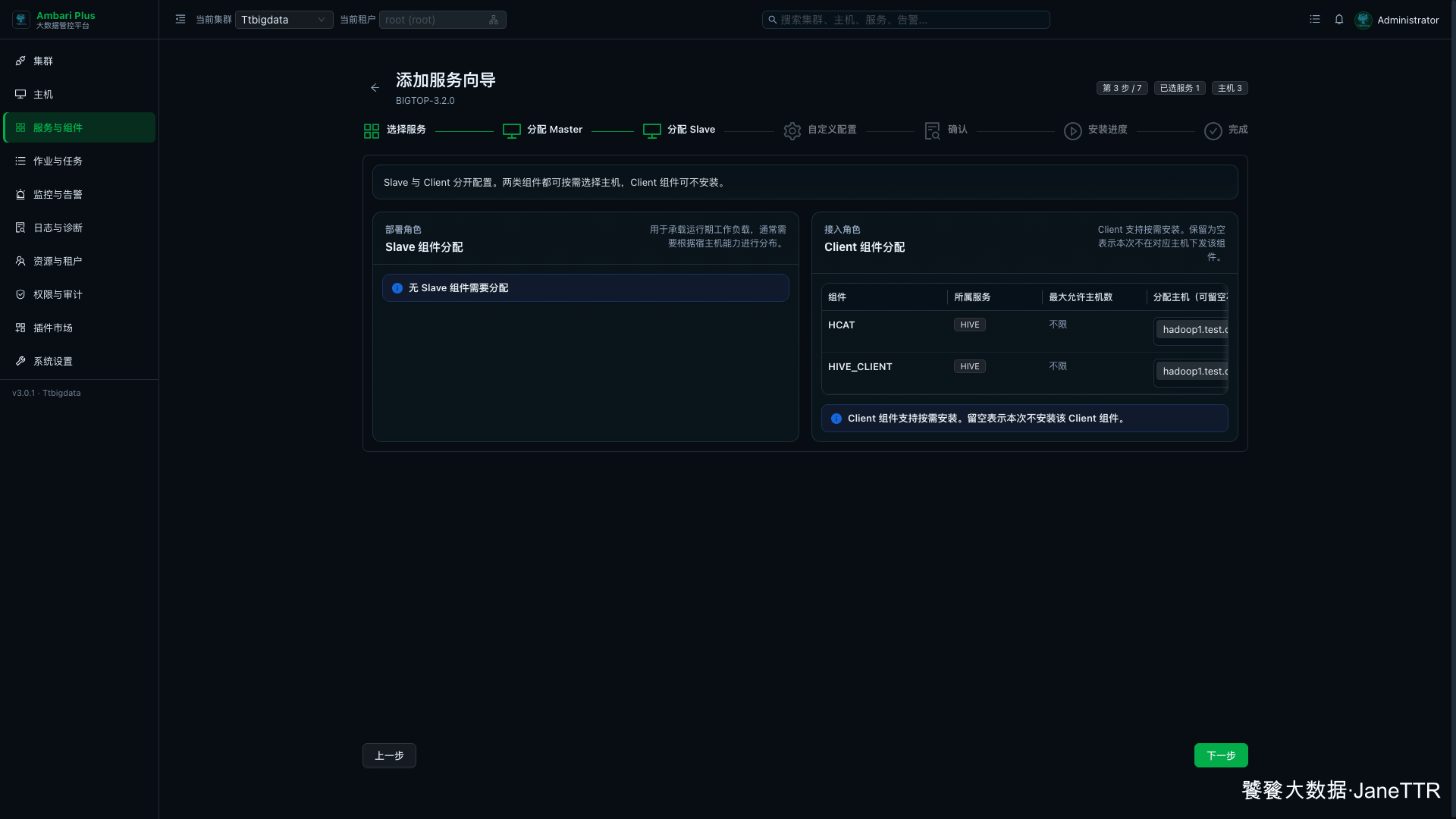
本次三台主机都安装客户端:
| 组件 | 分配主机 |
|---|---|
HCAT |
hadoop1.test.com、hadoop2.test.com、hadoop3.test.com |
HIVE_CLIENT |
hadoop1.test.com、hadoop2.test.com、hadoop3.test.com |
后面如果要在不同节点上跑 beeline、hive 命令,三台都有客户端会方便很多。
5. 填写数据库密码
进入自定义配置页后,页面会提示 Hive 有一个必填项:数据库密码。
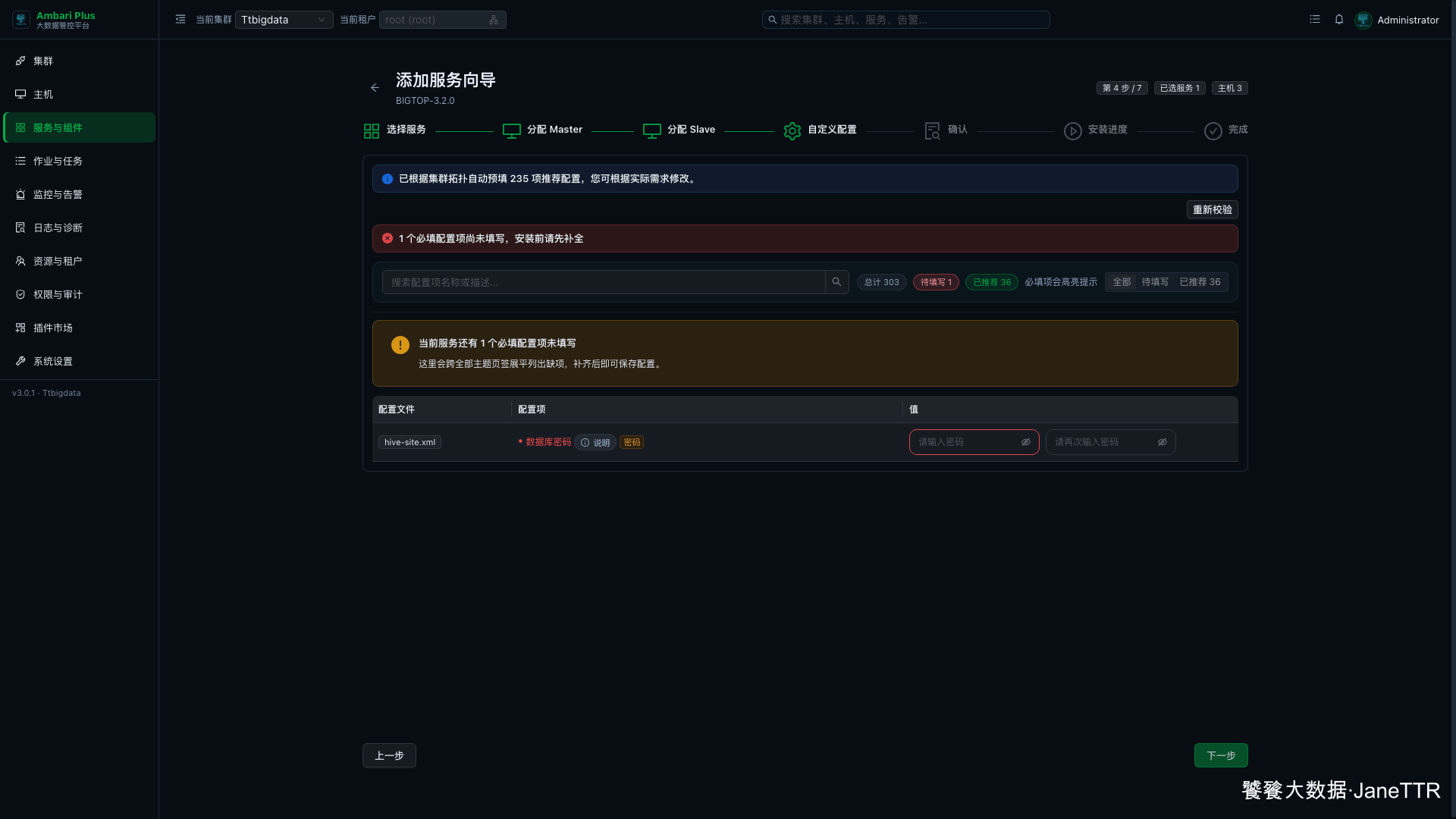
这里两次输入 hive。前面已经创建了 hive 用户,所以页面里的数据库配置保持下面这组值:
| 配置项 | 示例值 |
|---|---|
| 数据库类型 | Existing MySQL / MariaDB Database |
| 数据库名 | hive |
| 数据库用户 | hive |
| 数据库密码 | hive |
| JDBC URL | jdbc:mysql://hadoop1.test.com/hive |
| JDBC Driver | com.mysql.jdbc.Driver |
::: tip
如果数据库连接测试失败,先不要急着点下一步。优先检查 hive 库是否存在、hive 用户是否能从 Hive 所在节点访问 hadoop1.test.com:3306,以及 MySQL JDBC 驱动是否已经在前面的本地仓库和 JDK 准备阶段放好。
:::
6. 确认安装清单
确认页会把新增服务、Master 分配、Client 分配和配置校验集中列出来。
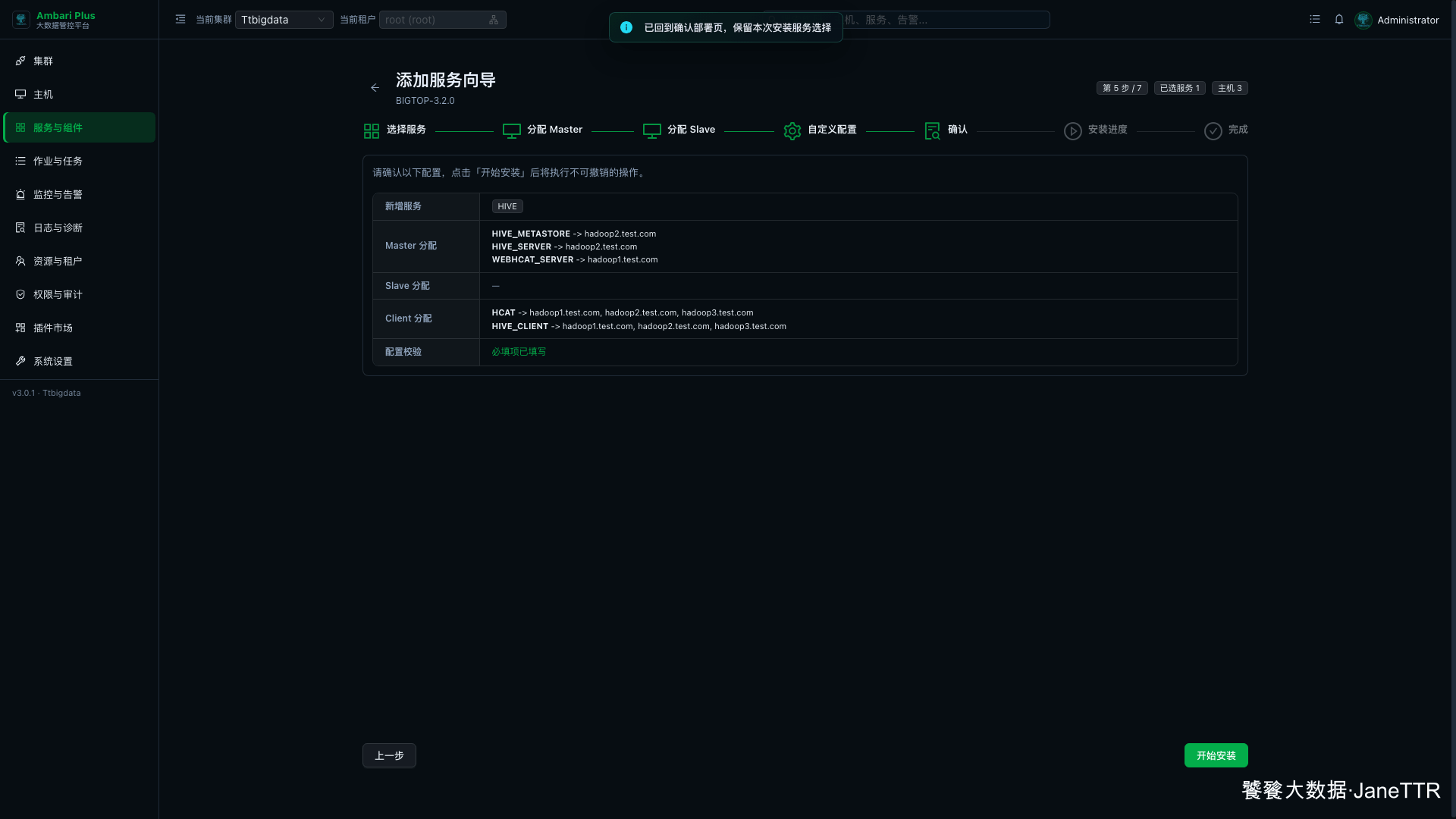
我会重点看这几项:
| 检查项 | 本次结果 |
|---|---|
| 新增服务 | HIVE |
| Master 分配 | HIVE_METASTORE、HIVE_SERVER、WEBHCAT_SERVER |
| Slave 分配 | 无 |
| Client 分配 | 三台主机都有 HCAT 和 HIVE_CLIENT |
| 配置校验 | 必填项已填写 |
确认无误后点击 开始安装 。如果集群已经开启 Kerberos,向导会要求提交 KDC 管理员凭据。本次继续使用 admin/admin@TEST.COM 和对应管理员密码,让系统为 Hive 生成并分发服务凭据。
7. 等待 Hive 安装与启动
安装进度页会按主机展示任务。Hive 的任务比 Tez 多一些,会看到 HCAT、HIVE_CLIENT、HIVE_METASTORE、HIVE_SERVER、WEBHCAT_SERVER 和 HIVE_SERVICE_CHECK。
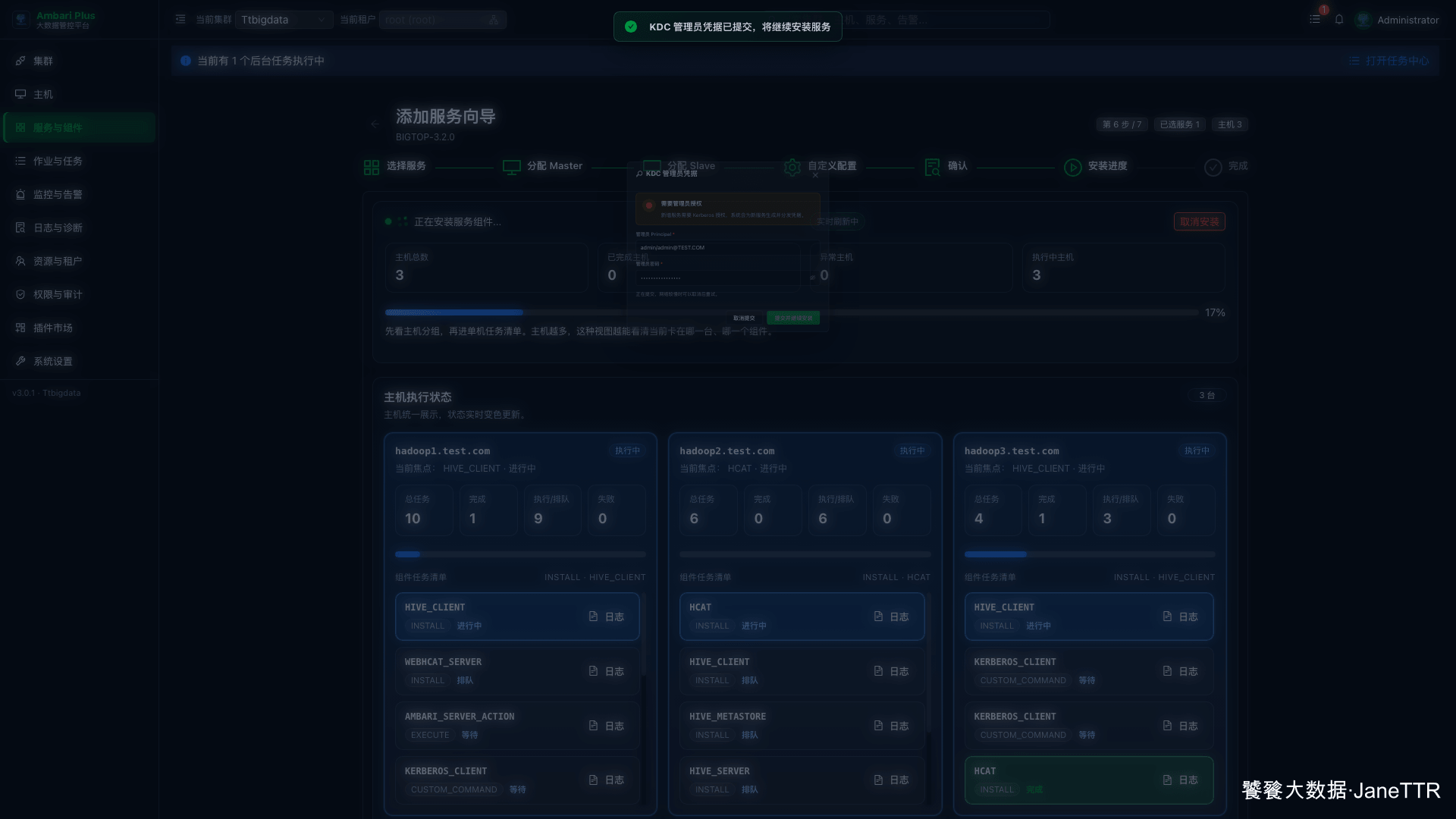
这个阶段我主要看三件事:
| 检查项 | 期望结果 |
|---|---|
| 安装任务 | 三台主机的 Client 安装完成。 |
| 服务启动 | HIVE_METASTORE、HIVE_SERVER、WEBHCAT_SERVER 启动完成。 |
| Service Check | HIVE_SERVICE_CHECK 执行成功。 |
如果 WebHCat 启动时提示 HBase 相关 jar 缺失,通常是安装顺序或本地包依赖还没补齐。把 HBase 组件装好以后,再回到 Hive 服务页单独启动 WebHCat 即可。
8. 回到服务列表确认状态
安装完成后回到 服务与组件 页面,Hive 会出现在 查询数据 分类下。
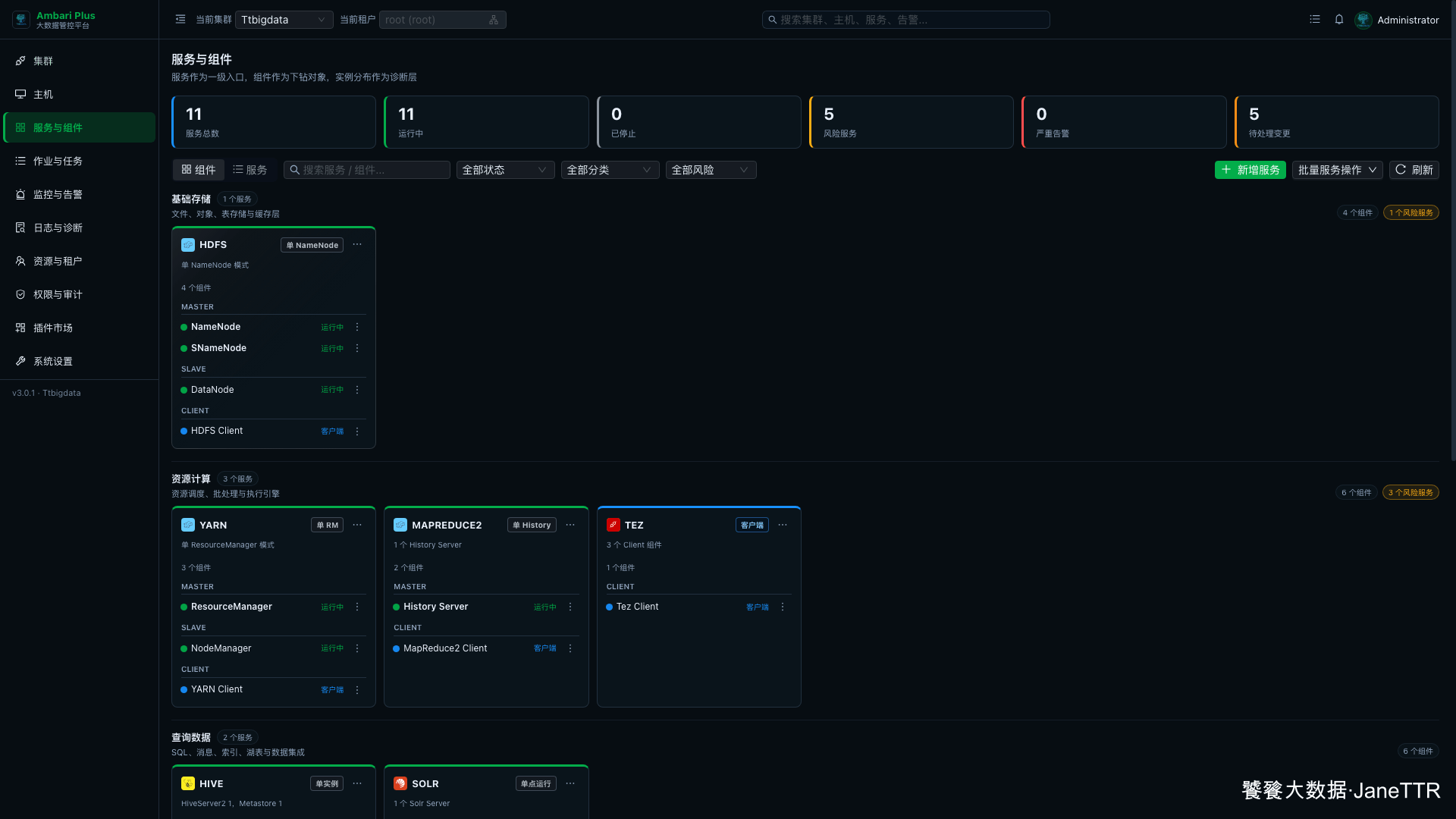
页面里可以看到:
| 组件 | 状态 |
|---|---|
Hive Metastore |
运行中 |
HiveServer2 |
运行中 |
WebHCat Server |
运行中 |
HCat Client |
客户端 |
Hive Client |
客户端 |
到这里,Hive 的基础安装就完成了。下一步可以继续安装 Sqoop;等 HBase、Kafka、Spark 等组件陆续接入后,再回头补 Hive 与 Ranger、Knox、Hue 的联动配置。