🐟 项目简介
本项目是一个基于深度学习的鱼类图像分类识别系统,专注于解决鱼类物种自动识别问题。系统采用前后端分离的架构设计:
- 后端服务:基于 Django 框架,提供 Web 页面渲染、图片上传接口和模型推理服务
- 模型架构:集成多种经典 CNN 与 Transformer 模型,支持多种深度学习网络结构
- 核心功能:实现鱼类图片的自动分类识别,准确判别不同鱼类物种
系统首页集成了模型选择、图片上传、识别结果展示和数据集类别浏览等功能模块,适合作为:
- 🎓 课程设计:深度学习与计算机视觉课程的实践项目
- 🔬 实验展示:模型对比与性能评估的实验平台
- 💼 项目实践:完整的 AI 应用开发案例
🛠️ 技术栈
后端框架
- Web 框架:Django 4.x
深度学习框架
- 核心框架:PyTorch 2.0+
- 扩展库:Torchvision、TorchMetrics
支持的模型架构
本项目集成了多种经典和现代的深度学习模型:
经典 CNN 模型
- AlexNet、VGGNet、ResNet 系列
- GoogLeNet、DenseNet、MobileNet
- EfficientNet、RegNet、ShuffleNet
Transformer 模型
- Vision Transformer (ViT)
- Swin Transformer
- DeiT(Data-efficient Image Transformers)
数据处理与可视化
- 数据加载 :
torchvision.datasets.ImageFolder - 预处理:图像缩放、随机裁剪、水平翻转、归一化
- 可视化工具:Matplotlib、Seaborn、Plotly
- 数据分析:Pandas、NumPy
- 结果导出:Excel、CSV 格式训练日志
🖥️ 系统界面设计
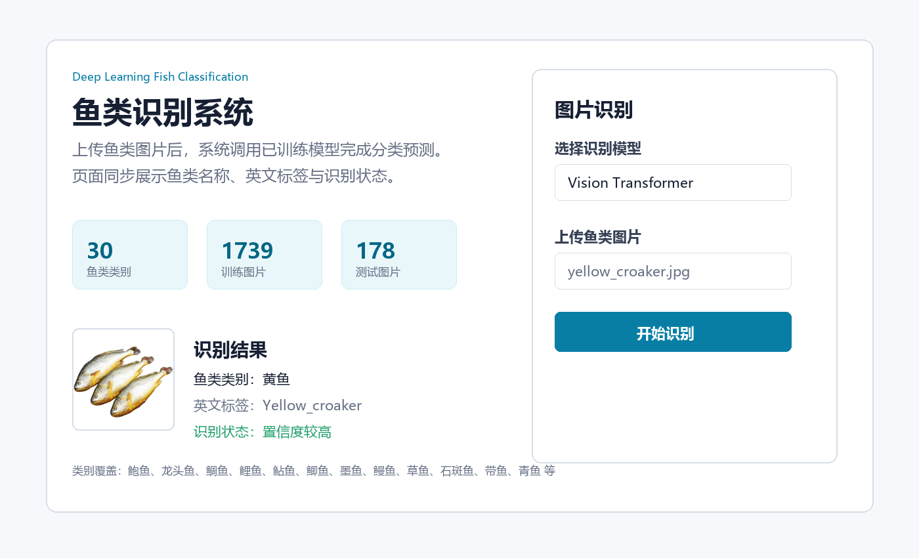
识别结果展示
识别完成后,系统以卡片形式展示详细结果:
📊 数据集介绍
数据集结构
数据集位于项目 djangoProject/data_set 目录下,采用标准组织格式:
data_set/
├── train/ # 训练集
│ ├── bass/ # 鲈鱼类别
│ │ ├── bass_001.jpg
│ │ ├── bass_002.jpg
│ │ └── ...
│ ├── carp/ # 鲤鱼类别
│ └── ...
├── test/ # 测试集
│ ├── bass/
│ ├── carp/
│ └── ...
└── en2ch.txt # 中英文类别映射文件类别覆盖
数据集共包含 30 种常见鱼类,涵盖:
| 中文名称 | 英文名称 | 样本数量 |
|---|---|---|
| 黄鱼 | Yellow Croaker | ~150 |
| 鲤鱼 | Carp | ~140 |
| 鲫鱼 | Crucian Carp | ~130 |
| 鲈鱼 | Perch | ~120 |
| 带鱼 | Hairtail | ~110 |
| 草鱼 | Grass Carp | ~100 |
| 鲑鱼 | Salmon | ~90 |
| 罗非鱼 | Tilapia | ~85 |
| 石斑鱼 | Grouper | ~80 |
| 多宝鱼 | Turbot | ~75 |
数据特点
- 多样性:包含不同角度、光照条件下的鱼类图片
- 标准化:所有图片统一调整为 224×224 分辨率
- 平衡性:各类别样本数量相对均衡
- 扩展性:支持轻松添加新鱼类类别
数据预处理流程
python
# 数据预处理示例代码
from torchvision import transforms
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
🔄 模型训练与识别流程
训练阶段
1. 数据准备
python
# main_train.py - 数据加载部分
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
# 加载训练集和测试集
train_dataset = ImageFolder('data_set/train', transform=train_transform)
test_dataset = ImageFolder('data_set/test', transform=test_transform)
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)2. 模型配置
项目提供统一的训练入口 main_train.py,支持通过命令行参数切换不同模型:
bash
# 训练 ResNet50
python main_train.py --model resnet50 --epochs 50 --lr 0.001
# 训练 Vision Transformer
python main_train.py --model vit --epochs 100 --lr 0.0001
# 训练 MobileNetV3
python main_train.py --model mobilenetv3 --epochs 30 --lr 0.013. 智能模型过滤
系统自动检测可用的模型权重文件,只向用户展示:
- ✅ 已完成训练的模型
- ✅ 权重文件完整的模型
- ✅ 通过基础测试的模型
避免用户选择未训练或损坏的模型,减少运行时错误。
📈 可视化分析与模型评估
数据分布分析
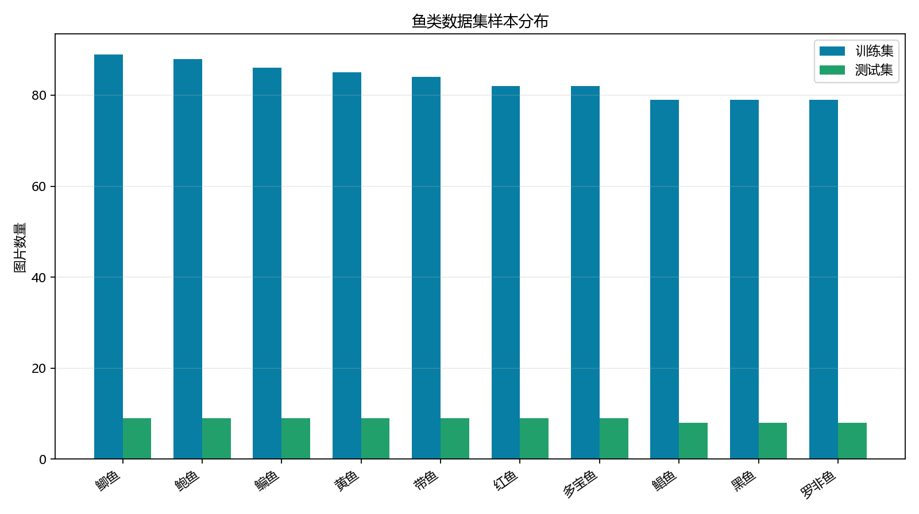
1. 类别样本分布
通过统计分析发现,不同鱼类类别的样本数量存在差异:
python
import pandas as pd
import matplotlib.pyplot as plt
# 统计各类别样本数量
class_counts = {}
for class_name in train_dataset.classes:
class_counts[class_name] = len(train_dataset.class_to_idx[class_name])
# 可视化展示
plt.figure(figsize=(12, 6))
plt.bar(range(len(class_counts)), list(class_counts.values()))
plt.xlabel('类别索引')
plt.ylabel('样本数量')
plt.title('训练集类别分布')
plt.show()2. 数据不平衡处理策略
针对样本不均衡问题,我们采用以下策略:
- 过采样:对少数类别进行数据增强
- 类别权重:在损失函数中为少数类别分配更高权重
- 分层采样:确保每个 batch 包含所有类别的样本
训练过程可视化
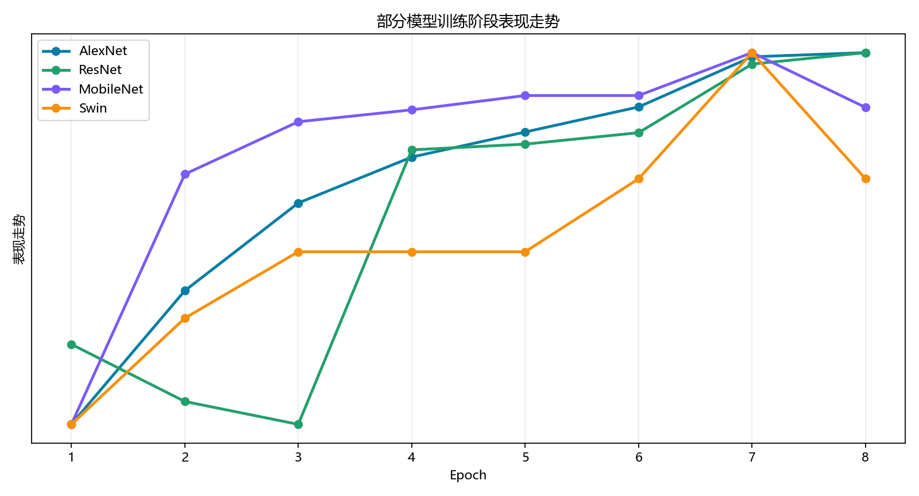
1. 训练趋势图
python
# 训练日志分析
import pandas as pd
# 读取训练日志
log_df = pd.read_csv('training_log.csv')
# 绘制训练曲线
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# 训练损失
axes[0, 0].plot(log_df['epoch'], log_df['train_loss'])
axes[0, 0].set_title('训练损失变化')
axes[0, 0].set_xlabel('Epoch')
axes[0, 0].set_ylabel('Loss')
# 验证准确率
axes[0, 1].plot(log_df['epoch'], log_df['val_accuracy'])
axes[0, 1].set_title('验证准确率')
axes[0, 1].set_xlabel('Epoch')
axes[0, 1].set_ylabel('Accuracy')
# 学习率变化
axes[1, 0].plot(log_df['epoch'], log_df['learning_rate'])
axes[1, 0].set_title('学习率调度')
axes[1, 0].set_xlabel('Epoch')
axes[1, 0].set_ylabel('Learning Rate')
# 模型对比
models = ['ResNet50', 'MobileNetV3', 'ViT']
accuracies = [0.92, 0.88, 0.94]
axes[1, 1].bar(models, accuracies)
axes[1, 1].set_title('不同模型准确率对比')
axes[1, 1].set_ylabel('Accuracy')
plt.tight_layout()
plt.show()2. 关键指标分析
- 收敛速度:ResNet 系列收敛最快,Transformer 需要更多 epoch
- 稳定性:CNN 模型训练更稳定,ViT 需要精细调参
- 过拟合:通过早停、Dropout、权重衰减控制
项目总结与优化方向
该系统完成了从数据集组织、模型训练、权重加载到 Web 端识别展示的完整闭环。后续可以继续从三个方向优化:一是补充更多复杂背景、不同角度和不同光照条件下的鱼类图片;二是加入更细致的错误样本分析和混淆类别对比;三是完善模型权重管理、历史识别记录和批量预测功能,让系统更适合实际部署和演示。