https://arxiv.org/pdf/2503.10701
摘要
视频个体计数(Video Individual Counting,VIC)由于在智能视频监控中的重要性,正受到越来越多关注。现有工作在两个方面存在局限:数据集和方法。以往数据集通常由固定相机或很少移动的相机拍摄,且个体相对稀疏,这限制了它们对拥挤场景中高度变化视角和时间变化的评估能力。现有方法依赖先定位、再关联或分类的流程;但在密集和动态条件下,小目标定位不准确会使这些方法表现困难。
为解决这些问题,本文引入 MovingDroneCrowd 数据集。该数据集包含由高速移动无人机在拥挤场景中采集的视频,覆盖多种光照、拍摄高度和角度。本文进一步提出共享密度图引导网络(Shared Density map-guided Network,SDNet),该网络使用深度式跨帧注意力模块(Depth-wise Cross-Frame Attention,DCFA)直接估计连续帧之间的共享密度图。通过从全局密度图中减去共享密度图,可以得到流入和流出密度图。跨帧累加流入密度图即可获得一个视频中唯一行人的数量。本文在自建数据集和公开可用数据集上的实验表明,在高度动态且复杂的拥挤场景中,所提出方法优于当前最先进方法。数据集和代码已公开发布。
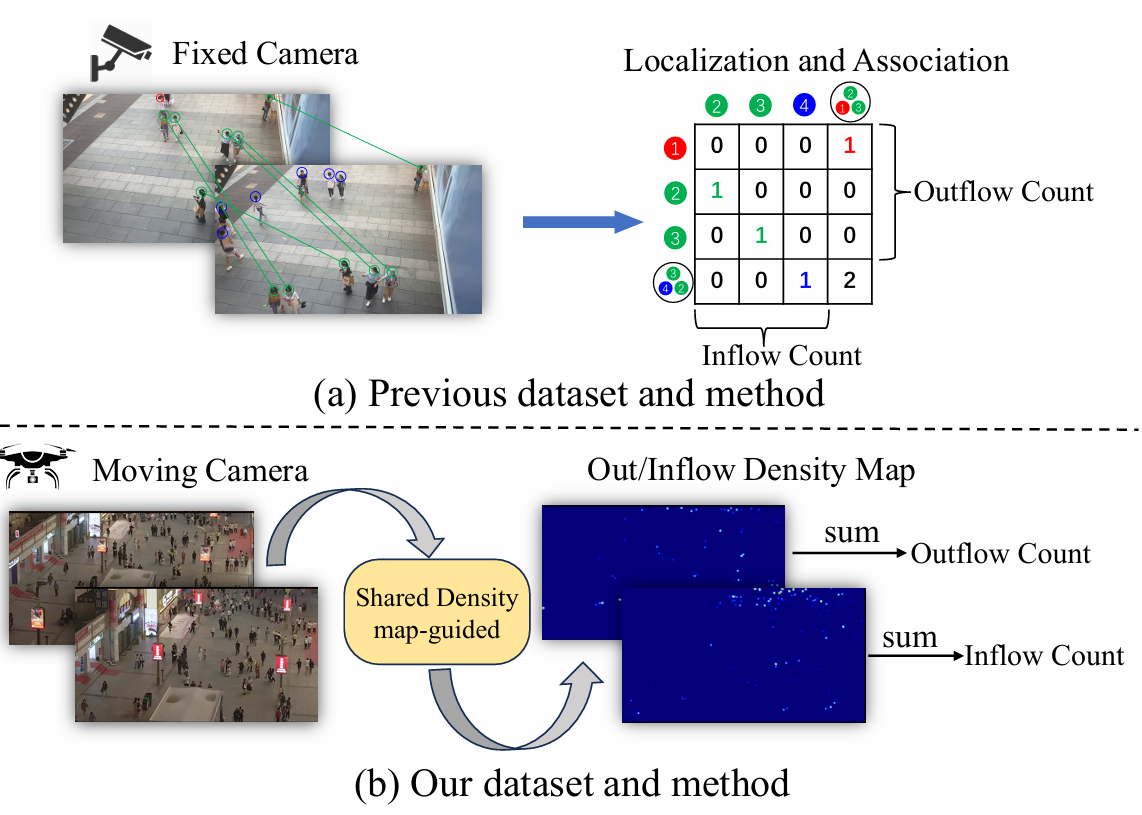
图 1:本文数据集/方法与已有数据集/方法的比较。
数据集方面,现有数据集通常由固定相机或几乎不移动的相机采集,目标稀疏;本文数据由高速移动无人机在拥挤场景中采集。方法方面,现有方法首先定位行人,再进行跨帧关联或分类。由于难以在拥挤复杂场景中准确定位行人,这些方法在本文这类具有挑战性的数据集上会失败。相比之下,本文的共享密度图引导方法采用更易学习和优化的方案:先通过跨帧注意力估计共享密度图,再推断流入和流出密度图,从而在挑战性场景中取得更好性能。
1. 引言
人群计数是人群分析中的基础任务,目标是估计图像或视频中的行人密度和数量。该任务在安全监控和踩踏事件早期预警中发挥重要作用,有助于预防由异常拥挤造成的人群灾害 44。
以往工作主要关注来自手持相机、智能手机和固定监控相机图像中的人群计数 9, 12, 17, 21, 23, 32, 45。尽管这些方法取得了显著进展,但它们逐渐难以满足复杂、动态真实场景的需求。一方面,这些图像通常在较低高度采集,覆盖区域有限。因此,透视效应会使远离相机区域中的头部相互遮挡,导致计数不准确。另一方面,图像计数只能给出特定位置、特定时刻的行人数量,无法满足现实中对大面积、长时间范围内行人数量和密度估计的需求,例如步行街或拥挤广场。
为解决地面相机带来的问题,已有工作 2, 26, 30, 40, 48 收集了一系列基于无人机的数据集。然而,它们大多是图像级数据集,或由固定无人机视角采集,因此只能在有限视野和时间内监测拥挤程度。尽管 25 引入了一个无人机视频数据集,但该数据集同时包含车辆和行人,导致行人密度相对较低。此外,由于其视频是在郊区由无人机以统一的拍摄高度、角度和光照条件采集的,它们可能无法代表复杂且拥挤的真实场景。
除数据集局限外,在视频中准确统计具有不同身份的行人,也就是视频个体计数 14,仍然具有挑战性。最直接的思路是应用多目标跟踪(Multi-Object Tracking,MOT)技术 3, 29, 33, 38, 46 并统计轨迹片段。然而,MOT 方法通常为目标较大的稀疏场景设计,在拥挤场景和低分辨率目标上会失败。近期已有若干方法 14, 20, 25 专门针对该任务提出,它们在每一帧中定位人,然后在两个连续帧之间进行关联或分类,以推断流入数量。尽管已有这些努力,所有方法仍高度依赖准确的行人定位,而这在密集人群中并不可靠。较差的定位会导致关联或分类退化,从而在视频级计数上产生显著偏差。
因此,在复杂的密集人群环境中,尤其是在由快速移动无人机拍摄的情况下,"先定位再关联"或"先定位再分类"的范式十分脆弱。与本文最相关的方法是 35,该方法直接预测流入和流出掩码,再将其与全局密度图相乘,以获得流入和流出密度图。然而,本文认为,直接从两帧中预测帧特定行人更困难。相比之下,本文方法先估计帧间共享密度图,再推断流入和流出密度图。
现有工作的数据集和方法局限如图 1 所示。为克服这些局限,本文收集了 MovingDroneCrowd 数据集,并提出一种共享密度图引导的视频个体计数方法。不同于现有数据集,本文数据集专门关注由移动无人机在多样且复杂条件下拍摄的拥挤场景,包括步行街、旅游景点和广场。该数据集具有复杂相机运动模式,以及更丰富的光照条件、拍摄角度和拍摄高度变化,使视频个体计数任务具有高度挑战性,并使现有方法效果受限。
在方法方面,本文方法受到两点启发:一是在图像级人群计数中,基于密度图的方法在拥挤场景中通常比基于定位的方法计数误差更低;二是在两个集合之间识别共享对象,比检测各集合中特有对象更容易且更易学习。
具体而言,本文设计了深度式跨帧注意力(DCFA)模块,以学习两相邻帧各自的共享密度图。每个共享密度图包含同时出现在当前帧和相邻帧中的行人密度。所提出的 DCFA 将两连续帧的多尺度特征作为输入,并在不同尺度特征之间计算跨帧注意力。DCFA 模块输出的每帧特征经共享密度图解码器解码,得到各自的共享密度图。最后,通过从全局密度图中减去共享密度图,估计流出和流入密度图。在测试阶段,跨帧累加流入密度图,即可统计视频片段中的唯一行人数量。本文方法是弱监督的,仅需要指示行人进入或离开视野的流入和流出标签。
本文贡献总结如下:
- 收集了一个视频级个体计数数据集,该数据集由快速移动无人机在多种拥挤场景中采集。相比以往数据集,本文数据集人群密度更高、相机运动更复杂,光照、拍摄角度和高度变化更大。
- 提出一种共享密度图引导的 VIC 方法,绕过困难的定位步骤,转而先学习连续帧之间的共享行人密度图,从而采用更易学习的方式。
- 设计 DCFA 模块提取共享密度图,再从全局密度图中减去共享密度图以获得准确的流入密度。
- 在本文数据集和公开可用数据集上的实验表明,所提出方法在高度动态、密集和复杂场景中优于现有最先进方法。
2. 相关工作
2.1 图像级人群计数
在人群计数早期工作 5, 16, 27 中,研究者使用手工特征回归图像中的人数。18 通过学习图像特征到密度图的映射,利用空间信息提升性能。如今,CNN 或 Transformer 被用于将图像特征映射为密度图。这些工作处理了透视效应 31, 42, 43、域差异 7, 11, 13, 24, 37, 41 或尺度变化 8, 15, 36 等挑战。虽然基于密度图的方法能够提供更准确的计数,但它们无法确定个体的精确坐标,尤其是在远离相机的区域。为此,人群定位方法被提出,用神经网络直接回归每个人的坐标 22, 32。6, 10, 19 利用相邻帧增强目标帧中的计数和定位性能。由于这些方法仍会在不同帧中多次统计同一个人,因此它们仍属于图像级人群计数。传统图像级方法只能在固定区域、单一时间点计数,而本文方法支持在动态变化视野中进行计数。
2.2 视频级人群计数
在一段时间内统计不同身份的行人更有意义。本文将该任务归类为视频级人群计数,在 14 中也被定义为视频个体计数。直观来看,MOT 技术 1, 34, 46 提供了一种潜在解决方案。然而,这些方法在具有大量遮挡的高度拥挤场景中表现困难,也无法有效处理快速相机运动。Han 等人 14 将该任务分解为两个连续帧之间的行人关联问题。Liu 等人 25 进一步提出一种弱监督的组级匹配方法。20 回归人的坐标,并将其分类为共享、流入或流出行人。然而,这些方法都需要先在每一帧中定位个体,再进行关联或分类,而定位误差会严重影响精度。
Wan 等人 35 提出一种基于密度图的方法,预测流入和流出掩码,再将掩码与全局密度图相乘,以获得流入和流出密度图;但这一过程难以学习和优化。相比之下,本文方法以更易学习的方式构造该任务:先估计共享密度图,再推断流入和流出密度图。
2.3 基于无人机的人群计数数据集
目前,从无人机视角进行人群计数的数据集仍相对稀缺。Bahmanyar 等人 2 使用搭载在直升机上的 DSLR 相机采集了一个航拍人群数据集。26, 30 提出的数据集由无人机采集的 RGB 和热成像图像对构成。然而,这些数据集都是图像级的,只能在固定视野中的特定时刻统计人数。面向无人机视角的多目标跟踪数据集 48 包含密集人群的视频片段,但在标注时,这些拥挤区域被完全忽略。Luo 等人 39, 40 发布了一个视频级无人机人群数据集,但视频片段由悬停无人机拍摄,每个片段仅覆盖固定视野,类似图像级数据集。
UAVVIC 25 数据集收集了由无人机在相对简单且统一条件下拍摄的视频片段。它不仅包含行人,也包含大量车辆,因此行人密度较低。相比之下,本文数据集由快速移动无人机在更复杂条件下拍摄,包括更密集的人群、更具挑战性的光照,以及更多样的飞行高度和相机角度。

图 2:本文数据集中的两个示例片段。
每一帧展示了头部边界框和 ID 标注。多样光照条件、拍摄角度、高度以及密集行人使其成为高度挑战性数据集。为节省空间并更清晰展示,每个片段只展示两帧。可放大查看细节。
3. MovingDroneCrowd 数据集
为促进实用人群计数研究,本文引入 MovingDroneCrowd:一个视频级数据集,专门面向复杂条件下由移动无人机拍摄的密集行人场景。值得注意的是,本文数据集为跨帧的每个人提供精确边界框和 ID 标签,因此也适用于复杂场景中无人机视角下的多行人跟踪。下面详细介绍该数据集并与现有数据集比较。
数据处理与规模。 由于无人机飞行受到严格监管,本文使用 "aerial""drone""pedestrian flow""pedestrian street"等关键词从互联网获取原始无人机视频。原始视频首先被分割为覆盖完整地点的片段。为减少冗余,根据无人机速度,每个片段被下采样到 1 fps、3 fps 或 6 fps。一些无人机视频拍摄角度很窄,使远离相机的行人非常模糊。为降低标注难度,这些片段被裁剪到拍摄范围内行人能够被标注者识别为止。最终获得 89 个片段(4940 帧),分辨率包括 720p、1080p、2K 和 4K。
标注。 标注过程由 10 名训练良好的标注者使用 DarkLabel 标注工具完成,耗时一个月。每位标注者被要求标注紧密包围行人头部的边界框,并在整个视频中为不同个体分配唯一 ID。标注完成后,片段被重新分配给不同标注者进行错误检查和修订。最终获得 325,542 个头部边界框和 16,154 条轨迹。图 2 展示了本文数据集中的两个视频片段,以及头部边界框和 ID 标签,说明其具有多样光照条件、拍摄角度和高度,以及更高的人群密度。这些属性使本文数据集更具挑战性,并区别于以往数据集。
数据集划分。 数据集按场景级别划分为训练集(70%)、测试集(20%)和验证集(10%),确保场景不重叠。这种设置对算法的泛化能力提出更高要求。此外,数据划分过程确保每个集合都包含多样数据。
比较。 如表 1 所示,本文将 MovingDroneCrowd 与近期视频数据集比较。与以往无人机数据集 25 相比,本文数据集专门关注密集行人,并具有多样光照条件、拍摄角度和拍摄高度,以及更复杂的运动模式。图 3 展示了本文数据集与 UAVVIC 中移动数据的逐帧行人数量分布。由于 UAVVIC 的测试集不可用,本文仅包含其训练集比较结果。统计结果显示,UAVVIC 中大多数移动帧包含少于 50 名行人,而本文数据集在 50-99 和 100-149 区间具有更高比例,这些区间对应典型拥挤场景。此外,本文训练集中存在分布在 250-349 更拥挤区间的帧,测试集中还包含行人数量在 350-549 区间的极端拥挤移动帧,而 UAVVIC 中没有这些情况。总之,本文数据集提供了更多样、更具挑战性的行人数量分布。
表 1:近期视频数据集比较。
MFR 表示移动帧占所有帧的比例,MPR 表示移动帧中的行人占全部行人的比例,MPPF 表示移动帧中每帧平均行人数。本文数据集采集于高度动态且复杂的场景,是最具挑战性的数据集。
| 数据集 | 视角 | 相机移动 | MFR | MPR | MPPF | 光照 | 高度 | 角度 | ID |
|---|---|---|---|---|---|---|---|---|---|
| CroHD | 监控 | 否 | 0 | 0 | 0 | 白天/夜晚 | 固定 | 固定 | 是 |
| VSCrowd | 监控 | 否 | 0 | 0 | 0 | 白天/夜晚 | 固定 | 固定 | 是 |
| DroneCrowd | 无人机 | 否 | 0 | 0 | 0 | 白天/夜晚 | 固定 | 固定 | 是 |
| UAVVIC | 无人机 | 是 | 51% | 39% | 32 | 白天 | 约 20 m | 约 90° | 是 |
| MovingDroneCrowd | 无人机 | 是 | 100% | 100% | 66 | 白天/夜晚 | 约 3-20 m | 约 45°-90° | 是 |
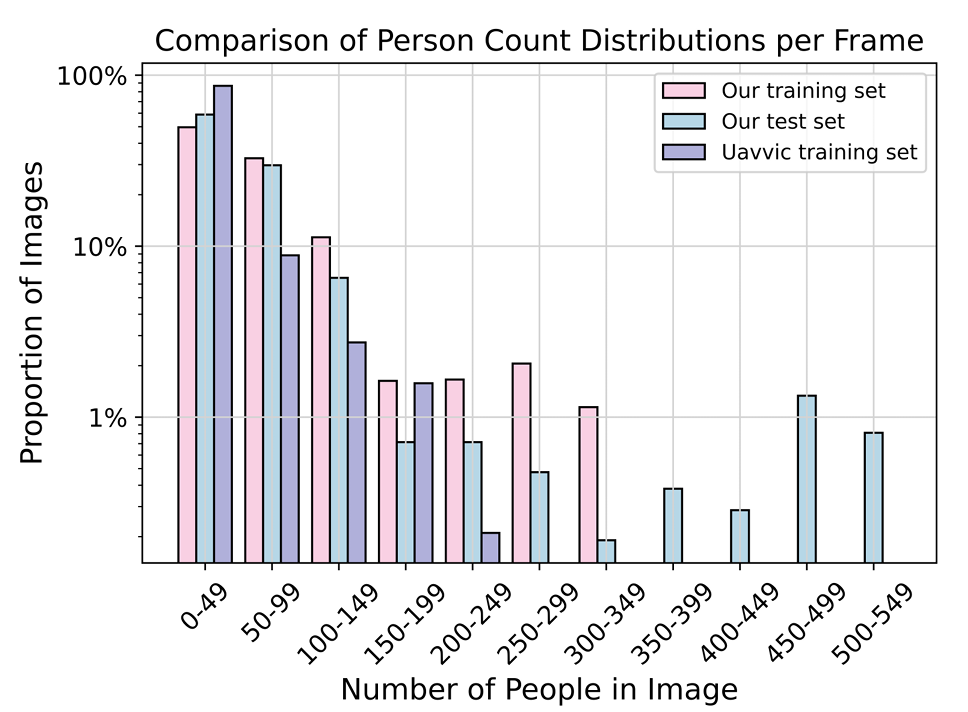
图 3:本文数据集与 UAVVIC 的逐帧行人数量分布比较。
4. 方法
4.1 问题形式化
形式上,训练集 Vt={Vi,Li}i=1NtV_t=\{V_i,L_i\}{i=1}^{N_t}Vt={Vi,Li}i=1Nt 由 NtN_tNt 个视频片段及其标注组成,其中第 iii 个视频 Vi={Vj}j=1niV_i=\{V_j\}{j=1}^{n_i}Vi={Vj}j=1ni 包含 nin_ini 帧,Li={Pj,IDj}j=1niL_i=\{P_j,ID_j\}_{j=1}^{n_i}Li={Pj,IDj}j=1ni 提供视频 ViV_iVi 中每一帧的人员坐标和身份。值得注意的是,本文方法是弱监督的,不需要 ID 标签。因此,即使只提供表示行人进入或离开视野的流入标签 IjI_jIj 和流出标签 OjO_jOj,本文方法也适用。
对于连续帧 VjV_jVj 和 Vj+δV_{j+\delta}Vj+δ(固定间隔为 δ\deltaδ),本文方法估计 VjV_jVj 的流出密度图 D^jout\hat{D}^{out}jD^jout 和 Vj+δV{j+\delta}Vj+δ 的流入密度图 D^j+δin\hat{D}^{in}{j+\delta}D^j+δin。D^jout\hat{D}^{out}jD^jout 的和给出在 VjV_jVj 中出现、但离开了 Vj+δV{j+\delta}Vj+δ 视野的行人数;D^j+δin\hat{D}^{in}{j+\delta}D^j+δin 的和表示进入 Vj+δV_{j+\delta}Vj+δ 视野的行人数。因此,视频 ViV_iVi 中唯一行人的总数可计算为:
M(Vi)≈M(V1)+∑k=1(ni/δ)−1sum(D^1+k×δin), M(V_i) \approx M(V_1) + \sum_{k=1}^{(n_i/\delta)-1} \operatorname{sum}\left(\hat{D}^{in}_{1+k\times\delta}\right), M(Vi)≈M(V1)+k=1∑(ni/δ)−1sum(D^1+k×δin),
其中,M(V1)M(V_1)M(V1) 表示第一帧中的人数,D^1+k×δin\hat{D}^{in}{1+k\times\delta}D^1+k×δin 是帧 V1+k×δV{1+k\times\delta}V1+k×δ 相对于帧 V1+(k−1)×δV_{1+(k-1)\times\delta}V1+(k−1)×δ 的流入密度图。
4.2 整体框架
为实现上述目标,即估计每一帧的流入密度图,本文首先估计共享密度图,如图 4 所示。具体而言,给定两连续帧 VjV_jVj 和 Vj+δV_{j+\delta}Vj+δ,首先提取它们的多尺度特征 FjF_jFj 和 Fj+δF_{j+\delta}Fj+δ。随后,提取出的多尺度特征经过本文提出的 DCFA 模块,得到每帧的共享特征 FjsF^s_jFjs 和 Fj+δsF^s_{j+\delta}Fj+δs。共享密度图解码器 DsD_sDs 将共享特征映射为共享密度图 D^js\hat{D}^s_jD^js 和 D^j+δs\hat{D}^s_{j+\delta}D^j+δs。同时,每一帧的多尺度特征被融合,并通过全局密度图解码器 DgD_gDg 映射为全局密度图 D^jg\hat{D}^g_jD^jg 和 D^j+δg\hat{D}^g_{j+\delta}D^j+δg。最后,全局密度图与共享密度图之间的差异被用于导出 VjV_jVj 的流出密度图 D^jout\hat{D}^{out}jD^jout 和 Vj+δV{j+\delta}Vj+δ 的流入密度图 D^j+δin\hat{D}^{in}_{j+\delta}D^j+δin。
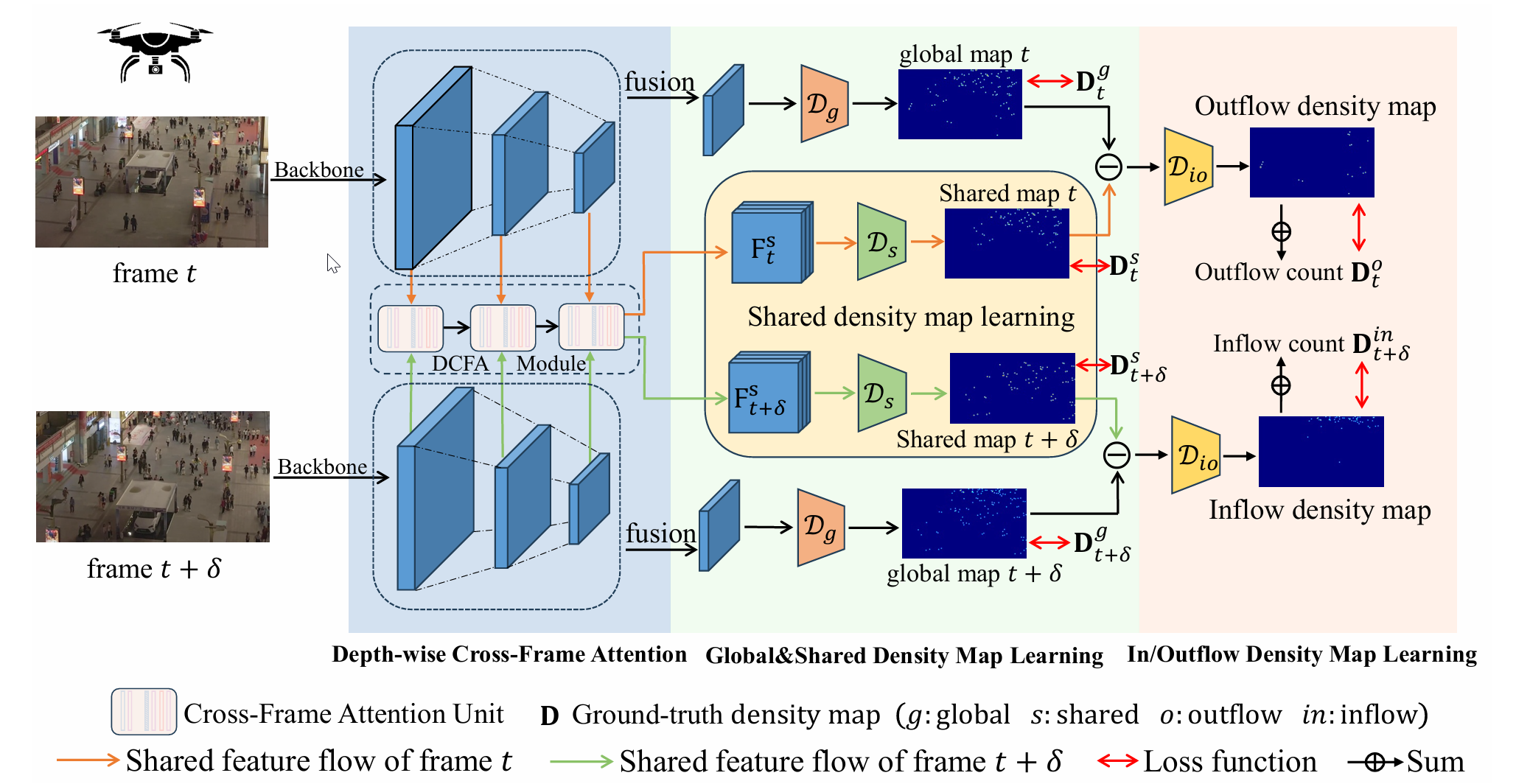
图 4:共享密度图引导的 VIC 方法流程。
首先,使用共享权重 CNN 和 FPN 提取多尺度特征。DCFA 模块在所有尺度的特征之间计算跨帧注意力,以获得共享特征;全局特征则通过融合多尺度特征获得。随后,全局解码器和共享解码器为每一帧生成全局密度图和共享密度图。最后,流入/流出解码器处理全局与共享密度图之间的差异,生成第一帧的流出密度图和第二帧的流入密度图。在测试时,只需累加所有帧流入密度图的和,即可得到整个视频中唯一行人的总数。
4.3 深度式跨帧注意力
为学习共享特征和全局特征,我们首先提取多尺度特征。给定采样的连续帧 VjV_jVj 和 Vj+δV_{j+\delta}Vj+δ,共享权重骨干网络和特征金字塔网络提取多尺度特征 FjF_jFj 和 Fj+δF_{j+\delta}Fj+δ,其中 Fj={Fji}i=1NfF_j=\{F^i_j\}_{i=1}^{N_f}Fj={Fji}i=1Nf,NfN_fNf 是多尺度特征层级数量。第 iii 个尺度特征 FjiF^i_jFji 的维度为 C×H/2i+1×W/2i+1C \times H/2^{i+1} \times W/2^{i+1}C×H/2i+1×W/2i+1。其中 HHH 和 WWW 分别是输入图像的高度和宽度,CCC 是特征通道数。
在提取多尺度特征后,本文设计的 DCFA 模块被用于为每一帧学习共享特征。DCFA 细节如图 5 所示。DCFA 由 NuN_uNu 个跨帧注意力单元组成,每个单元包含 NbN_bNb 个跨帧注意力块。DCFA 中单元数量对应于多尺度特征中的尺度层级数量。当计算帧 VjV_jVj 的共享特征时,第一个跨帧注意力单元直接以 Fj1F^1_jFj1 作为输入;对于第 iii 个单元(i>1i>1i>1),帧 VjV_jVj 的第 iii 个尺度特征 FjiF^i_jFji 首先与第 (i−1)(i-1)(i−1) 个单元的输出 F^ji−1\hat{F}^{i-1}_jF^ji−1 融合:
F~ji=Fusion(F^ji−1,Fji). \tilde{F}^i_j = \operatorname{Fusion}(\hat{F}^{i-1}_j, F^i_j). F~ji=Fusion(F^ji−1,Fji).
随后,第 iii 个单元输出的计算过程如下:
Fji′=MSA(LN(F~ji))+F~ji, F^i_j{}' = \operatorname{MSA}(\operatorname{LN}(\tilde{F}^i_j)) + \tilde{F}^i_j, Fji′=MSA(LN(F~ji))+F~ji,
Fji′′=MCA(LN(Fji′),Fj+δi)+Fji′, F^i_j{}'' = \operatorname{MCA}(\operatorname{LN}(F^i_j{}'), F^i_{j+\delta}) + F^i_j{}', Fji′′=MCA(LN(Fji′),Fj+δi)+Fji′,
F^ji=MLP(LN(Fji′′))+Fji′′. \hat{F}^i_j = \operatorname{MLP}(\operatorname{LN}(F^i_j{}'')) + F^i_j{}''. F^ji=MLP(LN(Fji′′))+Fji′′.
其中,LN 表示层归一化,MSA 表示多头自注意力层,MCA 表示多头交叉注意力层。公式中的 MCA 计算表示,来自帧 VjV_jVj 和 Vj+δV_{j+\delta}Vj+δ 的多尺度特征分别被设为 query 和 key。该过程可表示为:
Qh=Fji′WhQ,Kh=Fj+δiWhK,Vh=Fj+δiWhV, Q_h = F^i_j{}' W^Q_h,\quad K_h = F^i_{j+\delta} W^K_h,\quad V_h = F^i_{j+\delta} W^V_h, Qh=Fji′WhQ,Kh=Fj+δiWhK,Vh=Fj+δiWhV,
Headh=Softmax(QhKhTD)Vh, \operatorname{Head}_h = \operatorname{Softmax}\left(\frac{Q_h K_h^T}{\sqrt{D}}\right)V_h, Headh=Softmax(D QhKhT)Vh,
Fji′′=Concat(Head1,...,HeadH). F^i_j{}''=\operatorname{Concat}(\operatorname{Head}_1,\ldots,\operatorname{Head}_H). Fji′′=Concat(Head1,...,HeadH).
其中,WhQW^Q_hWhQ、WhKW^K_hWhK 和 WhVW^V_hWhV 是可学习投影矩阵。hhh 表示第 hhh 个独立头,最终输出由所有头的输出拼接得到。该过程迭代重复,直到最后一个跨帧注意力单元输出 F^jNu\hat{F}^{N_u}jF^jNu,作为 VjV_jVj 的共享特征 FjsF^s_jFjs。类似地,交换 FjiF^i_jFji 和 Fj+δiF^i{j+\delta}Fj+δi 的角色,即将 Fj+δiF^i_{j+\delta}Fj+δi 设为 query,将 FjiF^i_jFji 设为 key 和 value,即可得到帧 Vj+δV_{j+\delta}Vj+δ 的共享特征 Fj+δsF^s_{j+\delta}Fj+δs。DCFA 模块能够有效整合多尺度特征并捕获丰富跨帧信息,从而学习仅保留两连续帧之间共享行人信息的特征。
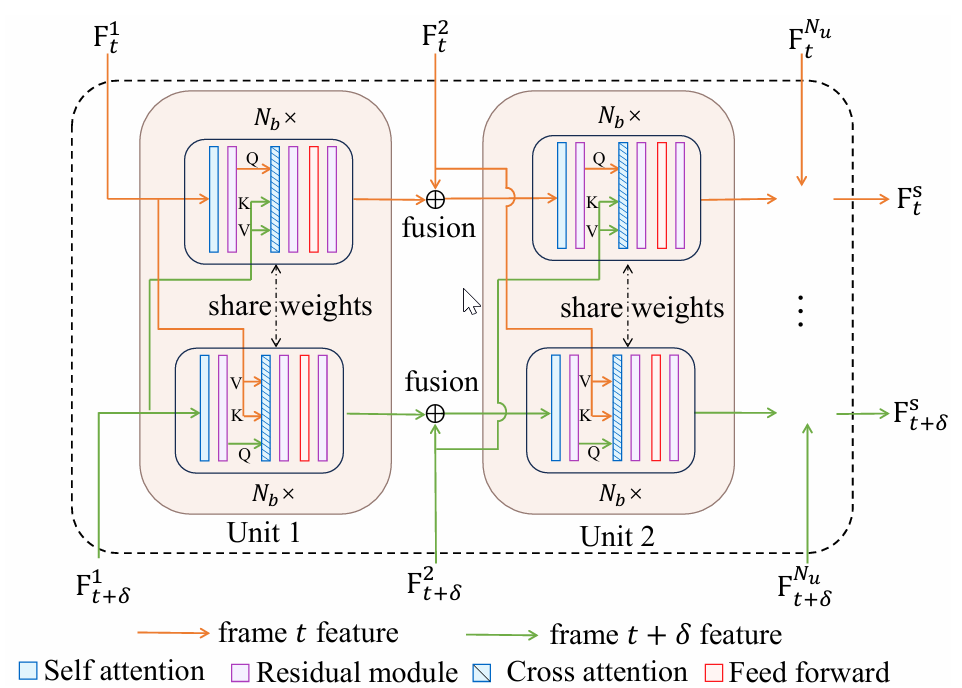
图 5:本文 DCFA 模块细节。
该模块包含 NuN_uNu 个跨帧注意力单元,每个单元包含 NbN_bNb 个跨帧块。单元数量与多尺度特征层级匹配。对于第 iii 个单元,使用第一帧第 iii 个尺度特征与第 (i−1)(i-1)(i−1) 个单元输出融合后的特征作为 query,使用第二帧第 iii 个尺度特征作为 key 和 value 来计算跨帧注意力。最终单元输出为第一帧的共享特征。交换两帧角色后,可得到第二帧的共享特征。
4.4 流入/流出密度图学习
为得到流入和流出密度图,首先解码帧 VjV_jVj 和 Vj+δV_{j+\delta}Vj+δ 的共享密度图和全局密度图:
D^jg=Dg(Fjg),D^js=Ds(Fjs), \hat{D}^{g}{j}=D_g(F^g_j),\quad \hat{D}^{s}{j}=D_s(F^s_j), D^jg=Dg(Fjg),D^js=Ds(Fjs),
其中,DgD_gDg 和 DsD_sDs 分别表示全局密度图解码器和共享密度图解码器。它们具有相同架构,由交替的卷积层和上采样操作组成,以逐步恢复分辨率至输入图像大小。这里,FjgF^g_jFjg 是 VjV_jVj 的全局特征,由 FjF_jFj 中多尺度特征直接融合得到。
全局密度图包含每一帧中所有行人的密度,而共享密度图只包含同时出现在两帧中的行人密度。因此,流出和流入密度图可以由全局密度图与共享密度图之间的差异得到:
D^jo=Dio(D^jg−D^js), \hat{D}^{o}{j}=D{io}(\hat{D}^{g}{j}-\hat{D}^{s}{j}), D^jo=Dio(D^jg−D^js),
D^j+δin=Dio(D^j+δg−D^j+δs), \hat{D}^{in}{j+\delta}=D{io}(\hat{D}^{g}{j+\delta}-\hat{D}^{s}{j+\delta}), D^j+δin=Dio(D^j+δg−D^j+δs),
其中,DioD_{io}Dio 是由卷积层组成的流入/流出解码器。显然,流出密度图包含只出现在帧 VjV_jVj 中的行人密度,而流入密度图包含只出现在帧 Vj+δV_{j+\delta}Vj+δ 中的行人密度。在测试阶段,对所有帧的流入密度图求和即可得到视频中的总行人数。
本文框架使用四个 MAE 损失进行训练:全局密度图损失 LgL_gLg、共享密度图损失 LsL_sLs、流出密度图损失 LoL_oLo 和流入密度图损失 LinL_{in}Lin。这些损失计算如下:
Lg=12N∑i=12N∥D^ig−Dig∥,Ls=12N∑i=12N∥D^is−Dis∥, L_g=\frac{1}{2N}\sum_{i=1}^{2N}\|\hat{D}^g_i-D^g_i\|, \quad L_s=\frac{1}{2N}\sum_{i=1}^{2N}\|\hat{D}^s_i-D^s_i\|, Lg=2N1i=1∑2N∥D^ig−Dig∥,Ls=2N1i=1∑2N∥D^is−Dis∥,
Lo=1N∑i=1N∥D^2i−1o−D2i−1o∥,Lin=1N∑i=1N∥D^2iin−D2iin∥. L_o=\frac{1}{N}\sum_{i=1}^{N}\|\hat{D}^{o}{2i-1}-D^{o}{2i-1}\|, \quad L_{in}=\frac{1}{N}\sum_{i=1}^{N}\|\hat{D}^{in}{2i}-D^{in}{2i}\|. Lo=N1i=1∑N∥D^2i−1o−D2i−1o∥,Lin=N1i=1∑N∥D^2iin−D2iin∥.
其中,NNN 是训练 batch 中图像对数量。DgD^gDg、DsD^sDs、DoD^oDo 和 DinD^{in}Din 分别为真实全局、共享、流出和流入密度图。需要注意的是,真实密度图可以由全监督标签(ID)或弱监督标签(流入和流出标注)生成。
5. 实验
受篇幅限制,更多实现细节见补充材料。
5.1 数据集
本文使用 UAVVIC 和 MovingDroneCrowd 两个数据集进行评估。上文已对这两个数据集进行详细描述和比较。
5.2 评估指标
与图像级人群计数类似,本文使用 MAE 和 RMSE 进行评估,但它们在视频级别计算。此外,本文也采用 14 中定义的 WRAE、MIAE 和 MOAE。WRAE(Weighted Relative Absolute Errors,加权相对绝对误差)在计算相对误差时考虑不同视频帧数的影响。MIAE 和 MIOE 分别衡量流入和流出预测质量。详细定义见 14 及其补充材料。
5.3 与最先进方法比较
比较方法。 为展示本文方法的优越性,我们将其与多种相关工作进行比较。除专门为 VIC 设计的算法外,还包含其他相关方法,例如多目标跟踪和越线人群计数。
MovingDroneCrowd 上的结果。 表 2 比较了本文方法与其他方法在 MovingDroneCrowd 数据集上的表现。相比最新方法 CGNet,本文方法分别将 MAE 和 RMSE 降低了 37% 和 47%,显著优于其他方法。为进行更深入细致的分析,本文按行人密度划分测试场景,并在不同密度水平下评估 MAE。随着行人密度增加,其他方法性能急剧下降,而本文方法始终保持合理性能。基于 MOT 的方法由于依赖个体检测和全局身份关联,在高密度场景中完全失败;而本文数据集包含严重遮挡和快速相机运动等复杂场景,使这种关联不可行。VIC 方法缓解了部分问题,但仍依赖定位和跨帧关联,因此在高度拥挤场景中表现不理想。基于密度的方法 FMDC 35 虽然避免了定位和关联,但由于直接预测流入和流出掩码非常困难,因此性能较差。相比之下,本文方法先推断更易学习的共享密度图,再导出流入和流出图,因此即使在复杂拥挤场景中也能取得令人满意的结果。
表 2:MovingDroneCrowd 数据集上的性能比较。
D0-D3 分别表示四个行人密度范围:[0, 150)、[150, 300)、[300, 450)、≥450。原文中加粗表示最佳结果,下划线表示次优结果,红色表示本文方法相对次优方法的提升。随着人群密度增加,本文方法的性能优势更加明显。
| 方法 | Venue | ID | MAE↓ | RMSE↓ | WRAE↓ | MIAE↓ | MIOE↓ | D0 | D1 | D2 | D3 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ByteTrack 46 | ECCV'22 | 是 | 153.17 | 227.62 | 63.82 | 13.25 | 11.22 | 83.38 | 24.00 | 325.00 | 441.33 |
| BoT-SORT 1 | arXiv'22 | 是 | 150.61 | 223.46 | 62.53 | 13.11 | 11.22 | 82.46 | 22.00 | 327.00 | 430.00 |
| OC-SORT 4 | CVPR'23 | 是 | 203.56 | 276.84 | 87.75 | 10.90 | 13.63 | 101.46 | 232.00 | 405.00 | 569.33 |
| DiffMOT 28 | CVPR'24 | 是 | 229.17 | 450.86 | 71.27 | 23.01 | 21.41 | 45.85 | 292.00 | 952.00 | 761.67 |
| DRNet 14 | CVPR'22 | 是 | 81.14 | 126.34 | 33.36 | 5.64 | 5.09 | 28.73 | 129.88 | 217.13 | 246.69 |
| CGNet 25 | CVPR'24 | 是 | 66.06 | 110.36 | 29.16 | - | - | 25.92 | 111.00 | 144.00 | 199.00 |
| LOI 47 | ECCV'16 | 是 | 241.77 | 337.90 | 99.63 | - | - | 110.13 | 294.46 | 467.57 | 719.33 |
| FMDC 35 | WACV'24 | 是 | 120.31 | 183.57 | 48.82 | 8.21 | 6.40 | 61.66 | 75.71 | 54.92 | 411.09 |
| Ours | - | 是 | 41.00 | 58.34 | 19.32 | 5.50 | 6.39 | 23.71 | 79.77 | 41.21 | 102.88 |
相对次优结果,本文方法在 MAE、RMSE、WRAE、MIAE 和 MIOE 上分别提升 37.8%、47.1%、33.7%、24.9% 和 48.3%。
UAVVIC 上的结果。 本文也在无人机视频数据集 UAVVIC 上进行了比较实验。由于其测试集尚未发布,比较在验证集上进行。表 3 结果表明,本文方法取得最佳总体性能,说明本文方法不仅能有效处理密集场景,也能在稀疏场景中表现良好。UAVVIC 包含静态和动态无人机视频,因此本文分别在两类场景中测试,以保证分析更加全面。如表 3 所示,其他方法在动态场景中的性能相较静态场景显著下降,而本文方法在两种设置中都保持稳定强性能。这说明其他方法难以处理具有复杂运动模式的动态场景,而本文方法能够有效应对。
表 3:UAVVIC 验证集上的性能比较。
结果显示,本文方法在总体、静态和动态场景中均取得最佳结果,证明其在动态和稀疏场景中的有效性。
| 方法 | Venue | Overall MAE↓ | Overall RMSE↓ | Overall WRAE↓ | MIAE↓ | MOAE↓ | Static MAE↓ | Static RMSE↓ | Dynamic MAE↓ | Dynamic RMSE↓ |
|---|---|---|---|---|---|---|---|---|---|---|
| ByteTrack 46 | ECCV'22 | 14.19 | 21.51 | 68.92 | 1.77 | 2.09 | 9.40 | 10.21 | 15.69 | 23.98 |
| OC-SORT 4 | CVPR'23 | 18.81 | 35.42 | 71.01 | 2.42 | 3.06 | 7.20 | 7.77 | 22.44 | 40.34 |
| LOI 47 | ECCV'16 | 21.70 | 38.21 | 99.00 | - | - | 11.12 | 11.59 | 25.01 | 43.29 |
| CGNet 25 | CVPR'24 | 24.95 | 52.57 | 83.82 | - | - | 6.80 | 8.22 | 30.62 | 60.05 |
| Ours | - | 6.37 | 11.01 | 46.01 | 1.81 | 2.18 | 3.30 | 4.12 | 7.33 | 12.40 |
相对次优结果,本文方法在 Overall MAE、Overall RMSE、Overall WRAE、Static MAE、Static RMSE、Dynamic MAE 和 Dynamic RMSE 上分别提升 55%、48.8%、33.2%、51.5%、47%、53.3% 和 48.3%。
5.4 消融研究
骨干网络影响。 在本文方法中,图像特征可以由 CNN 或 Transformer 提取。因此,本文首先研究骨干网络的影响。如表 4 第一部分所示,使用 VGG-16 骨干网络获得最佳性能。这表明 CNN 可以为计数等像素级任务提供更丰富的局部细节。
深度式跨帧注意力的影响。 为验证本文 DCFA 模块的有效性,我们直接使用全局特征 FjgF^g_jFjg 和 Fj+δgF^g_{j+\delta}Fj+δg 计算跨帧注意力,并将其称为浅层式跨帧注意力(Shallow-wise Cross-Frame Attention,SCFA)。为保证公平比较,我们调整 SCFA 中的超参数,使其参数量与 DCFA 相同。表 4 结果显示,DCFA 取得更优性能,因为它在学习相邻帧之间共享行人信息的同时,能够有效整合多尺度特征。
DCFA 中位置编码的影响。 表 4 中的实验结果显示,在使用不同骨干网络时,位置编码具有不同影响。具体而言,当使用 CNN 作为骨干时,在 DCFA 中加入位置编码会导致最终性能下降。这是因为 CNN 本身已经编码了位置信息,额外加入位置编码可能破坏 CNN 特征的语义完整性。相比之下,Transformer 特征依赖位置编码来指定每个像素的位置。
学习策略影响。 本文方法先预测共享密度图,再通过从全局密度图中相减得到流出和流入图。为验证这一策略的有效性,我们进行消融研究:将 DCFA 输出解码后直接用真实流出和流入密度图监督,即直接学习它们,而不是先预测共享密度图。如表 4 第七行所示,直接学习流入密度图会导致最终性能显著下降。这表明学习两帧之间的共享信息比学习每一帧的私有信息更容易,也进一步验证了本文方法设计的合理性。
表 4:本文方法消融研究。
"Direct" 表示直接学习流入密度图,而不是先学习共享密度图。
| 消融设置 | 配置 | MAE↓ | RMSE↓ | WRAE↓ | MIAE↓ | MIOE↓ |
|---|---|---|---|---|---|---|
| Backbone | VGG w/o PE | 41.00 | 58.34 | 19.32 | 5.50 | 6.39 |
| Backbone | VGG w/ PE | 66.64 | 102.66 | 37.73 | 7.80 | 9.37 |
| Backbone | ViT w/o PE | 98.56 | 142.83 | 48.50 | 7.84 | 8.07 |
| Backbone | ViT w/ PE | 51.76 | 66.99 | 24.90 | 9.21 | 8.10 |
| Cross-Frame | DCFA | 41.00 | 58.34 | 19.32 | 5.50 | 6.39 |
| Cross-Frame | SCFA | 70.42 | 90.13 | 44.71 | 5.80 | 6.02 |
| Inflow Learning | Direct | 65.64 | 99.34 | 47.12 | 6.41 | 7.63 |
| Inflow Learning | SDNet | 41.00 | 58.34 | 19.32 | 5.50 | 6.39 |
5.5 定性结果
图 6 展示了本文方法在 MovingDroneCrowd 示例上的可视化结果。流入和流出密度图反映了视野内的行人进入和离开情况。虽然存在一些错误响应,但其数值被有效抑制。图 7 展示了 CGNet 在相同图像对上的可视化结果。可以观察到定位和关联都存在显著错误,其中关联几乎完全错误。这说明以往基于定位和关联的方法难以有效处理动态且密集的场景。

图 6:本文方法在 MovingDroneCrowd 上的可视化结果。
图中展示了两连续帧的结果。除每一帧的全局密度图外,第一帧还包含其相对于第二帧的共享密度图和流出密度图;第二帧包含其相对于第一帧的共享密度图和流入密度图。

图 7:CGNet 在 MovingDroneCrowd 上的可视化结果。
在密集场景中存在大量定位错误,跨帧关联几乎全部错误。
6. 结论
本文探索了一种灵活方法,用于在一段时间内、较大区域中统计唯一个体,具体场景为由移动无人机拍摄的视频。由于缺少相关数据集和有效算法,本文引入 MovingDroneCrowd,这是一个具有挑战性的视频级数据集,采集自移动无人机在拥挤场景中拍摄的视频,包含多样光照、高度、角度和复杂运动模式。这些因素使以往基于定位的方法失效。
因此,本文提出一种基于密度图的视频个体计数算法,绕过定位和关联。相反,本文直接估计流入密度图,该密度图反映新进入人群的数量。在本文基准和以往基准上的实验表明,本文方法能够有效处理高密度和动态场景,同时在静态和稀疏场景中也取得优秀结果。
致谢
本工作部分受到国家自然科学基金(U22A2095、62276281、62406090)以及中国广东省基础与应用基础研究基金(2024A1515011882)支持。
A. 训练和测试细节
训练细节。 由于 MovingDroneCrowd 视频已经被充分下采样以消除冗余,本文在 3-8 的范围内随机选择帧间隔 δ\deltaδ,以保证训练图像对包含多样的流入和流出行人变化。对于数据增强,训练图像被下采样,使长边不超过 2560 像素,短边不超过 1440 像素,从而确保裁剪图像包含足够行人。裁剪、翻转和缩放策略遵循 14。初始学习率设为 1e-5,权重衰减为 1e-6,并使用幂为 0.9 的多项式衰减。本文使用以 ImageNet 预训练权重初始化的 VGG16 作为特征提取骨干网络。模型使用 PyTorch 实现,并在 A800 GPU 上训练。
测试细节。 本文模型在测试时可以接收不规则分辨率图像。为降低计算成本,输入图像的长边和短边分别限制为不超过 1920 和 1080 像素。图 11 显示,本文方法在较宽帧间隔范围内都保持合理性能,证明其对间隔变化具有鲁棒性。当 δ=4\delta=4δ=4 时取得最佳性能,因此在 MovingDroneCrowd 上测试时,将帧间隔 δ\deltaδ 设为 4。
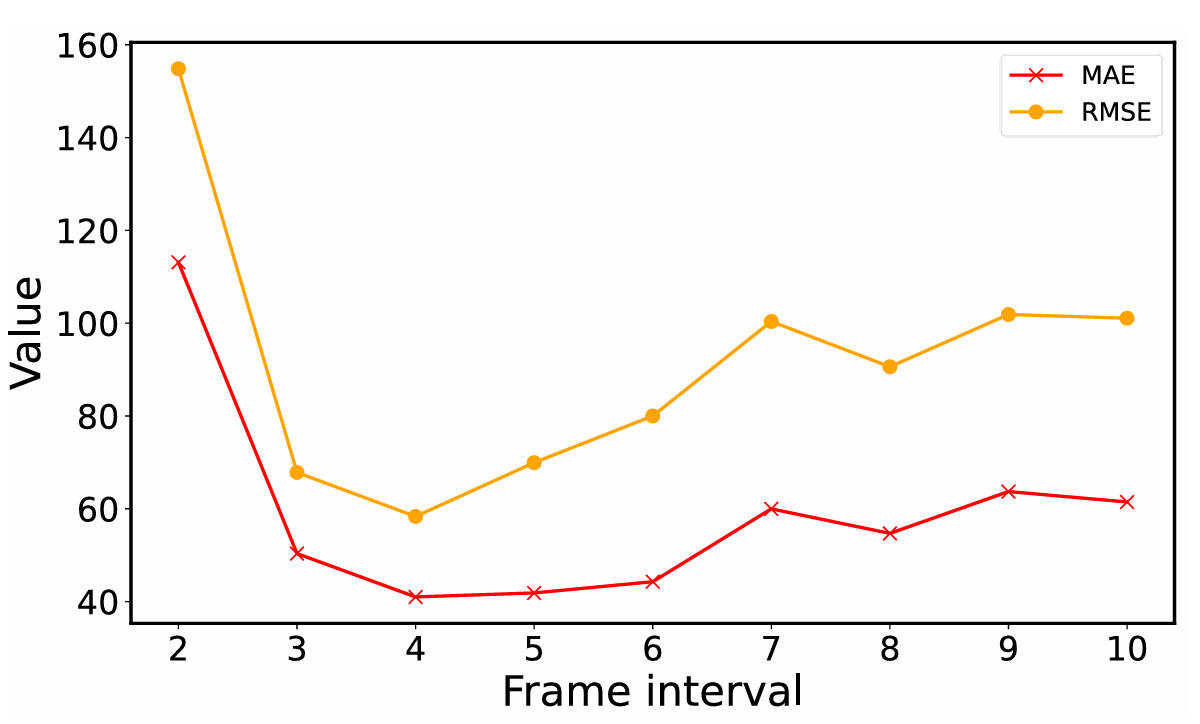
图 11:MovingDroneCrowd 上测试帧间隔 δ\deltaδ 的消融研究。
B. 更多 MovingDroneCrowd 示例
图 8 展示了本文数据集 MovingDroneCrowd 中更多视频样例,每一帧都标注了头部边界框和身份 ID。这些示例突出了本文数据集的关键特征:密集人群、复杂运动模式、变化光照条件,以及多样相机高度和角度。

图 8:MovingDroneCrowd 数据集的额外样例。
受篇幅限制,每个视频只展示三帧,每一帧均标注头部边界框和 ID 标签。
C. 更多可视化结果
图 9 展示了本文方法在 MovingDroneCrowd 上的更多可视化结果。第一个场景是具有显著无人机运动的密集拥挤场景,第二个场景是在低空无人机飞行期间拍摄的稀疏区域。两个场景均在弱光条件下录制。这些结果表明,本文方法能够准确预测每一帧相对于前一帧的流入密度图。这说明本文方法具有足够鲁棒性,能够在密集、稀疏和弱光等复杂环境中取得强性能。
图 10 展示了本文方法在以往数据集 UAVVIC 上的可视化结果。该场景由几乎没有相机运动的悬停无人机拍摄,说明本文方法在静态场景中仍然表现良好。

图 9:本文方法在 MovingDroneCrowd 数据集上的额外可视化结果。
结果表明,本文方法在弱光、密集和稀疏场景中都表现良好。

图 10:本文方法在 UAVVIC 数据集上的额外可视化结果。
结果表明,本文方法在静态场景中也取得令人满意的性能。
D. 局限性
测试集上的可视化结果显示,共享密度图并未被完美学习,仍包含许多错误响应,这也会导致流入和流出密度图中出现一些误差。由于行人外观相似,直接学习两帧之间的共享行人特征仍然是一项具有挑战性的任务。在两帧之间计算交叉注意力计算开销较大,且耗时较长。这些问题将在未来工作中解决。