K-means 聚类算法详解:从原理到实战
- [什么是 K-means 聚类?](#什么是 K-means 聚类?)
- 算法实现流程
- [API 详解](#API 详解)
- 案例实战:鸢尾花数据聚类
- 效果评估方法
-
- [肘部法则(Elbow Method)](#肘部法则(Elbow Method))
- [轮廓系数(Silhouette Score)](#轮廓系数(Silhouette Score))
- [CH 指数(Calinski-Harabasz Index)](#CH 指数(Calinski-Harabasz Index))
- 特征降维
无监督学习中最经典、最常用的聚类算法之一,凭借思想简洁、实现高效,长期活跃在客户分群、图像压缩、异常检测等众多场景中。本文从直观理解出发,依次讲解算法原理、sklearn API 用法、完整实现流程、效果评估方法,以及如何借助 K-means 完成特征降维。
什么是 K-means 聚类?
含义概念
K-means 是一种无监督学习算法,它会在没有标签的数据集中,自动把相似的样本归到同一个簇,使得"同簇内样本尽可能相似,不同簇之间尽可能不同"。
这里有两个关键角色:
- K:你想把数据分成多少个簇,需要人为指定。
- means:每个簇用一个"均值点"(簇中心 / 质心,centroid)来代表,质心就是该簇内所有样本坐标的平均值。
其实K-means聚类算法和KNN算法思想很接近,详情可以跳转-- KNN算法详解:从原理到实践入门
举例说明:
假设你是一家连锁超市的店长,手里有 300 位会员的两项数据:年消费金额 和 到店频次。你希望把顾客分成几类,以便做精准营销。
一开始这些点散落在坐标图上,看不出明显规律。你猜测大概可以分成 3 类,于是启动 K-means:
- 算法随机放上 3 个"质心点"(可以理解为 3 面旗帜)。
- 每位顾客看看自己离哪面旗帜最近,就站到那面旗下------这一步叫分配。
- 每面旗下重新计算所有顾客的平均位置,把旗帜移到这个新位置------这一步叫更新。
- 旗帜移动后,可能有些顾客发现另一面旗更近,于是换队。重复"分配→更新",直到旗帜不再移动,算法收敛。
最终结果如下图所示,顾客被清晰地分成了三个群体:
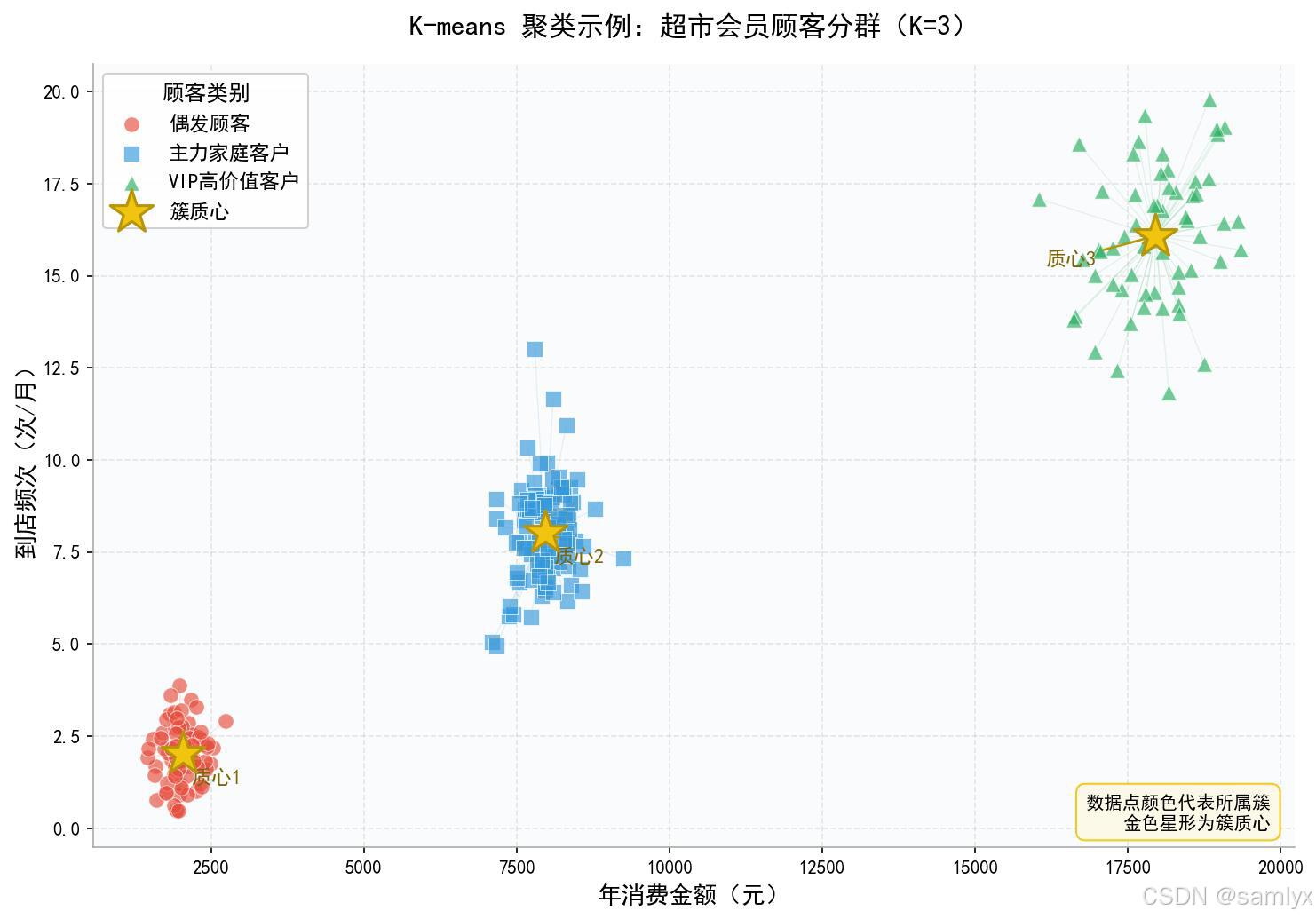
三个簇的现实含义非常直观:
- 红色簇:消费低、到店少------可能是偶发顾客或流失边缘,适合用优惠券唤醒。
- 蓝色簇:消费和频次中等------主力家庭客户,重点维护。
- 绿色簇:消费高、频次高------VIP 高价值客户,提供专属服务。
这就是 K-means 的威力:你不需要事先告诉算法"谁是 VIP",它仅凭数据本身的分布结构,就能帮你发现群体。
算法实现流程
K-means 的标准流程可以归纳为以下四步,循环执行直至收敛:
步骤 1:选择 K 值并初始化
由业务需求或数据探索决定簇的数量 K。这是 K-means 唯一的核心超参数,后文会介绍如何用肘部法则、轮廓系数辅助选 K。然后从数据中随机挑选 K 个点作为初始质心。
步骤 2:分配样本
对每个样本,计算它到 K 个质心的欧氏距离,把它分配给最近的那个质心所在的簇。
步骤 3:更新质心
对每个簇,重新计算簇内所有样本的均值,作为新的质心。
步骤 4:判断收敛
如果质心几乎不再移动(变化量小于阈值 tol),或达到最大迭代次数 max_iter,算法停止;否则回到步骤 2 继续迭代。
整个过程的目标函数 是最小化所有样本到其所属质心的平方距离之和(称为 SSE,Sum of Squared Errors,也叫 inertia):
J = ∑ j = 1 K ∑ x ∈ C j ∥ x − μ j ∥ 2 J = \sum_{j=1}^{K} \sum_{x \in C_j} \left\| x - \mu_j \right\|^2 J=j=1∑Kx∈Cj∑∥x−μj∥2
需要说明的是,K-means 只能保证收敛到一个局部最优 ,而非全局最优。这也是为什么 sklearn 会用 n_init 参数多次运行取最优结果的原因。
API 详解
scikit-learn 提供了 sklearn.cluster.KMeans 类,是目前 Python 生态中最常用的实现。大数据集用 MiniBatchKMeans。 当样本量超过 1 万,标准 K-means 会明显变慢。sklearn.cluster.MiniBatchKMeans 用小批量样本更新质心,速度提升数倍,结果接近。
核心参数
python
class sklearn.cluster.KMeans(
n_clusters=8,
init='k-means++',
n_init='auto',
max_iter=300,
tol=1e-4,
verbose=0,
random_state=None,
copy_x=True,
algorithm='lloyd'
)| 参数 | 默认值 | 说明 |
|---|---|---|
n_clusters |
8 | 聚类簇数 K |
init |
'k-means++' |
质心初始化方式,可选 'k-means++'、'random'、数组或可调用对象 |
n_init |
'auto' |
用不同随机种子运行的次数,取 inertia 最小的结果。'auto' 时若 init='k-means++' 则跑 1 次,若 init='random' 则跑 10 次 |
max_iter |
300 | 单次运行的最大迭代次数 |
tol |
1e-4 | 质心变化的收敛阈值,Frobenius 范数小于该值即停止 |
random_state |
None | 随机种子,设为整数可复现结果 |
algorithm |
'lloyd' |
算法变体,'lloyd' 为经典 EM 风格,'elkan' 利用三角不等式在某些数据上更快但更耗内存 |
常用方法
fit(X):对数据 X 进行聚类。fit_predict(X):聚类并直接返回每个样本的簇标签,等价于fit(X).labels_。predict(X):用已拟合的模型预测新样本属于哪个簇。transform(X):将 X 转换到"到各质心距离"的空间,形状(n_samples, n_clusters),可用于特征降维。fit_transform(X):等价于fit(X).transform(X),但更高效。
案例实战:鸢尾花数据聚类
下面用经典的鸢尾花数据集演示完整流程。虽然鸢尾花本身有标签,但我们在聚类时假装不知道标签,纯粹用四个特征(花萼长宽、花瓣长宽)做无监督聚类,最后再和真实标签对比。
完整代码:
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1. 加载数据
iris = load_iris()
X = iris.data # 四个特征
y_true = iris.target # 真实标签(仅用于最后对比,聚类时不使用)
# 2. 标准化(K-means 基于距离,对量纲敏感,务必标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 3. 用肘部法则选 K
sse = []
sil = []
K_range = range(2, 11)
for k in K_range:
km = KMeans(n_clusters=k, random_state=42, n_init=10)
km.fit(X_scaled)
sse.append(km.inertia_)
sil.append(silhouette_score(X_scaled, km.labels_))
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
ax[0].plot(K_range, sse, 'o-')
ax[0].set_xlabel('K')
ax[0].set_ylabel('SSE (inertia)')
ax[0].set_title('肘部法则')
ax[1].plot(K_range, sil, 'o-')
ax[1].set_xlabel('K')
ax[1].set_ylabel('轮廓系数')
ax[1].set_title('轮廓系数法')
plt.tight_layout()
plt.savefig('kmeans_eval.png', dpi=120)
plt.show()
# 4. 选定 K=3 进行聚类
km = KMeans(n_clusters=3, random_state=42, n_init=10)
labels = km.fit_predict(X_scaled)
centers = km.cluster_centers_
# 5. 可视化(取前两个特征画图)
plt.figure(figsize=(8, 6))
scatter = plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=labels, cmap='viridis', s=50, alpha=0.7)
plt.scatter(centers[:, 0], centers[:, 1], c='red', marker='*', s=300, label='质心')
plt.xlabel('花萼长度(标准化)')
plt.ylabel('花萼宽度(标准化)')
plt.title('K-means 鸢尾花聚类结果 (K=3)')
plt.legend()
plt.colorbar(scatter, label='簇编号')
plt.savefig('kmeans_result.png', dpi=120)
plt.show()
# 6. 输出评估指标
print(f'最终 SSE (inertia): {km.inertia_:.4f}')
print(f'轮廓系数: {silhouette_score(X_scaled, labels):.4f}')
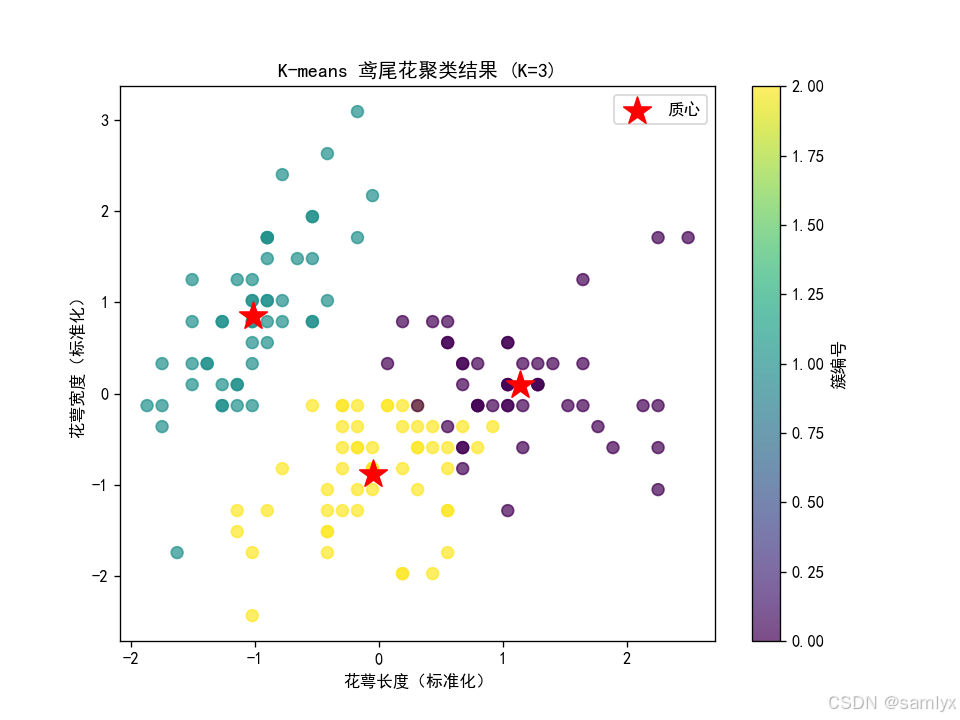
print(f'迭代次数: {km.n_iter_}')运行后你会观察到:
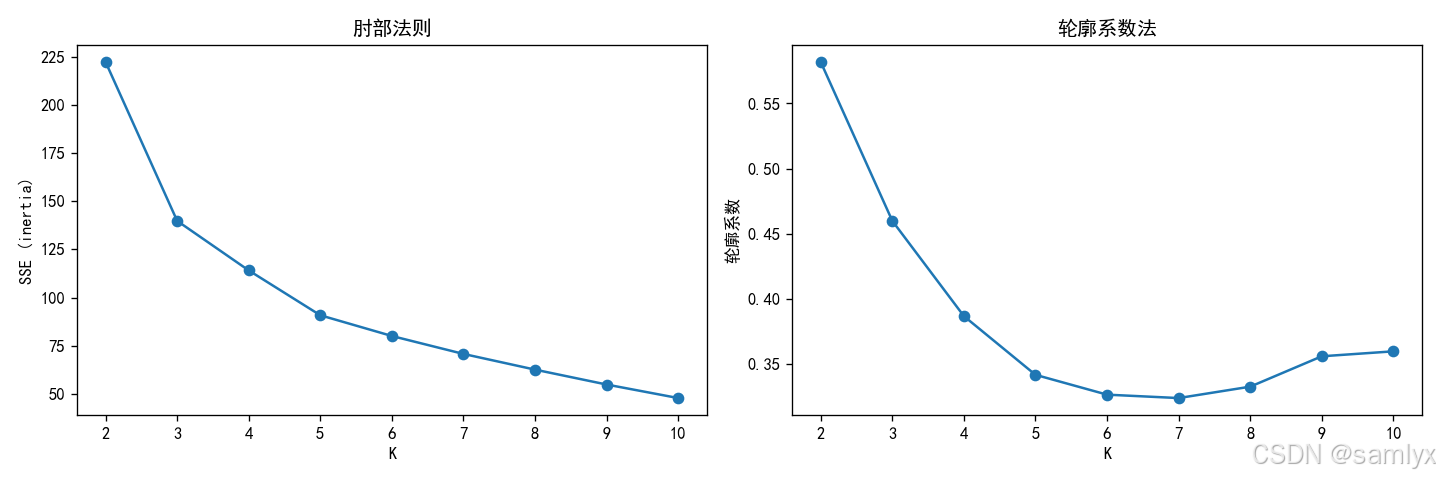
- 肘部法则图在 K=3 处出现明显拐点,SSE 下降速度骤减。
- 轮廓系数在 K=2 或 K=3 时达到峰值。
- 聚类结果中,三类鸢尾花被较好地分开,其中一类(Setosa)几乎完全正确,另外两类(Versicolor 与 Virginica)有少量样本重叠------这与它们在特征空间中的真实分布一致。
这个案例体现了 K-means 的典型工作流:标准化 → 选 K → 聚类 → 评估 → 可视化。
效果评估方法
聚类没有真实标签可用,评估比监督学习更依赖内部指标。以下是三种常用方法。
肘部法则(Elbow Method)
绘制不同 K 值对应的 SSE 曲线,寻找"肘部"拐点。SSE 随 K 增大单调下降,当 K 超过真实簇数后,下降幅度会明显变缓,这个转折点就是较优的 K。
肘部法则简单直观,但拐点有时不明显,需要结合其他方法交叉验证。
轮廓系数(Silhouette Score)
轮廓系数同时考虑簇内紧密度和簇间分离度,取值范围 − 1 , 1 -1, 1 −1,1:
s ( i ) = b ( i ) − a ( i ) max { a ( i ) , b ( i ) } s(i) = \frac{b(i) - a(i)}{\max\{a(i), b(i)\}} s(i)=max{a(i),b(i)}b(i)−a(i)
- a ( i ) a(i) a(i):样本 i i i 到同簇其他样本的平均距离(越小越好)。
- b ( i ) b(i) b(i):样本 i i i 到最近的其他簇中样本的平均距离(越大越好)。
解读标准:
- 接近 1:聚类效果好,样本分到了正确的簇。
- 接近 0:样本处于两个簇的边界。
- 接近 -1:样本可能被分错了簇。
sklearn 中调用方式:
python
from sklearn.metrics import silhouette_score
score = silhouette_score(X, labels)CH 指数(Calinski-Harabasz Index)
又称方差比准则,计算簇间离散度与簇内离散度之比,值越大说明簇间越分散、簇内越紧凑,聚类效果越好。
python
from sklearn.metrics import calinski_harabasz_score
score = calinski_harabasz_score(X, labels)CH 指数计算速度快,适合在大数据集上做快速评估。
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 肘部法则 | 直观易懂 | 拐点可能不明显,主观性强 | 初步探索 K |
| 轮廓系数 | 同时考虑紧密度和分离度,有明确取值范围 | 计算复杂度高 O ( n 2 ) O(n^2) O(n2) | 中小数据集精细评估 |
| CH 指数 | 计算快,值越大越好 | 无固定取值范围,仅适合横向比较 | 大数据集快速评估 |
特征降维
K-means 除了聚类,还有一个常被忽略的用途------特征降维 ,在信号处理领域称为向量量化(Vector Quantization)。
基本思想
假设你有 n n n 个样本,每个样本 d d d 维。K-means 聚类后得到 K 个质心,我们可以把每个样本替换成"它到这 K 个质心的距离",于是样本维度从 d d d 变成了 K K K。
当 K ≪ d K \ll d K≪d 时,就实现了降维。这正是 sklearn 中 transform 方法的用途:
python
km = KMeans(n_clusters=50, random_state=42)
X_dist = km.fit_transform(X) # 形状从 (n, d) 变为 (n, 50)X_dist[i][j] 表示样本 i i i 到第 j j j 个质心的距离。这种距离特征往往比原始特征更具判别力,常作为下游分类器的输入。
经典应用
图像压缩是 K-means 降维最直观的案例。一张彩色图片每个像素由 RGB 三个值(0-255)表示,共有 1600 万种可能颜色。如果用 K-means 把所有像素颜色聚成 16 类,每个像素只需记录它属于 16 个质心中的哪一个(4 bit),颜色种类从 1600 万压缩到 16,文件体积大幅缩小,而肉眼几乎看不出差别。
python
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from matplotlib.image import imread
# 1. 读取图片,把像素拉平成 (n_pixels, 3)
img = imread('photo.jpg')
h, w, c = img.shape
pixels = img.reshape(-1, 3)
# 2. 用 K-means 把颜色聚成 16 类
kmeans = KMeans(n_clusters=16, random_state=42, n_init=10)
labels = kmeans.fit_predict(pixels)
compressed_palette = kmeans.cluster_centers_
# 3. 用质心颜色重建图片
compressed_img = compressed_palette[labels].reshape(h, w, c)
# 4. 对比展示
fig, ax = plt.subplots(1, 2, figsize=(12, 6))
ax[0].imshow(img)
ax[0].set_title('原始图片')
ax[0].axis('off')
ax[1].imshow(compressed_img / 255)
ax[1].set_title('压缩后(16 色)')
ax[1].axis('off')
plt.tight_layout()
plt.savefig('image_compression.png', dpi=120)
plt.show()| 维度 | K-means 降维 | PCA 降维 |
|---|---|---|
| 原理 | 用到质心的距离替换原特征 | 用主成分投影保留最大方差方向 |
| 类型 | 非线性(基于聚类) | 线性 |
| 输出 | 到 K 个质心的距离(K 维) | 投影到前 K 个主成分(K 维) |
| 适用场景 | 簇结构明显、想做特征工程 | 一般降维、去噪、可视化 |
实际工程中,两者经常组合使用:先用 PCA 把高维数据降到几十维,再用 K-means 聚类,既能提升速度,又能改善效果。