参考:
- Gravitino Spark 连接器总览:https://gravitino.apache.org/docs/1.3.0/spark-connector/spark-connector/
- Spark 访问 Hive catalog:https://gravitino.apache.org/docs/1.3.0/spark-connector/spark-catalog-hive/
- 创建 Catalog(REST):https://gravitino.apache.org/docs/1.3.0/api/rest/create-catalog/
- Hive catalog 属性:https://gravitino.apache.org/docs/1.3.0/hive-catalog/
0. 目标与一句话原理
目标:把已有的 Hive 数据(Hive Metastore + HDFS 上的表)接入 Gravitino 统一管理,再用 Spark SQL 通过 Gravitino 查询。
一句话原理 :Spark 不直连 Hive Metastore ,而是通过 Gravitino Spark 连接器 向 Gravitino 拿到 catalog 定义(含 metastore.uris),再**委托 Spark **去访问 HMS / HDFS。
┌──────────────────────────┐
spark-sql ──────────▶│ Gravitino Spark 连接器 │ (DataSourceV2 插件)
(USE hive_cat) │ 拿 catalog 定义 + 鉴权 │
└─────────────┬────────────┘
│ 取 catalog 元数据
▼
┌──────────────────────────┐
│ Apache Gravitino :8090 │
│ metalake / catalog │
└─────────────┬────────────┘
│ metastore.uris
▼
┌──────────────────────────┐
│ Hive Metastore :9083 │──▶ HDFS 上的表数据
└──────────────────────────┘分工:Gravitino 管「有哪些 catalog / 表 + 权限」 ;Spark 连接器负责把 Gravitino 的 catalog 翻译成 Spark 能用的 Hive catalog;真正读写数据的是 Spark 的 Hive 支持层。
1. 前提条件
| 依赖 | 要求 | 说明 |
|---|---|---|
| Gravitino | 已运行(见 Apache Gravitino 新一代元数据开源框架解析及Docker部署操作手册 / 07-verify-and-quickstart.md) | curl http://localhost:8090/api/version 能返回 |
| Hive Metastore (HMS) | 2.x,可访问 thrift://<host>:9083 |
Gravitino 通过它读取 Hive 元数据 |
| HDFS | 2.x / 3.x | Hive 表数据实际存储 |
| Spark | 3.3 / 3.4 / 3.5,Scala 2.12/2.13,JDK 8/11/17 | 连接器版本要与 Spark 小版本对应 |
没有 HMS / HDFS? 用官方 Playground 一键起 Hive/HDFS/Trino/Spark 完整栈,见 。Playground 里 HMS 容器名通常是
hive-metastore(端口 9083),HDFS 为hdfs://namenode:9000。
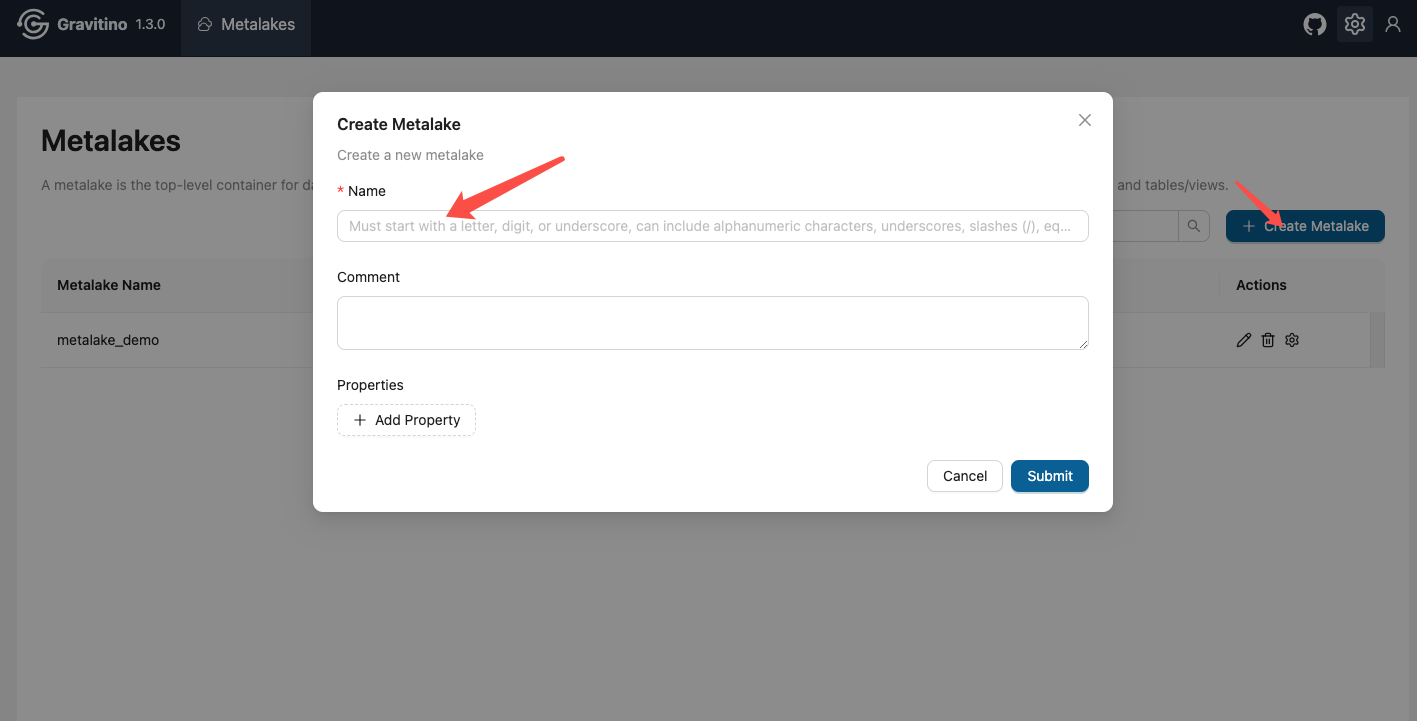
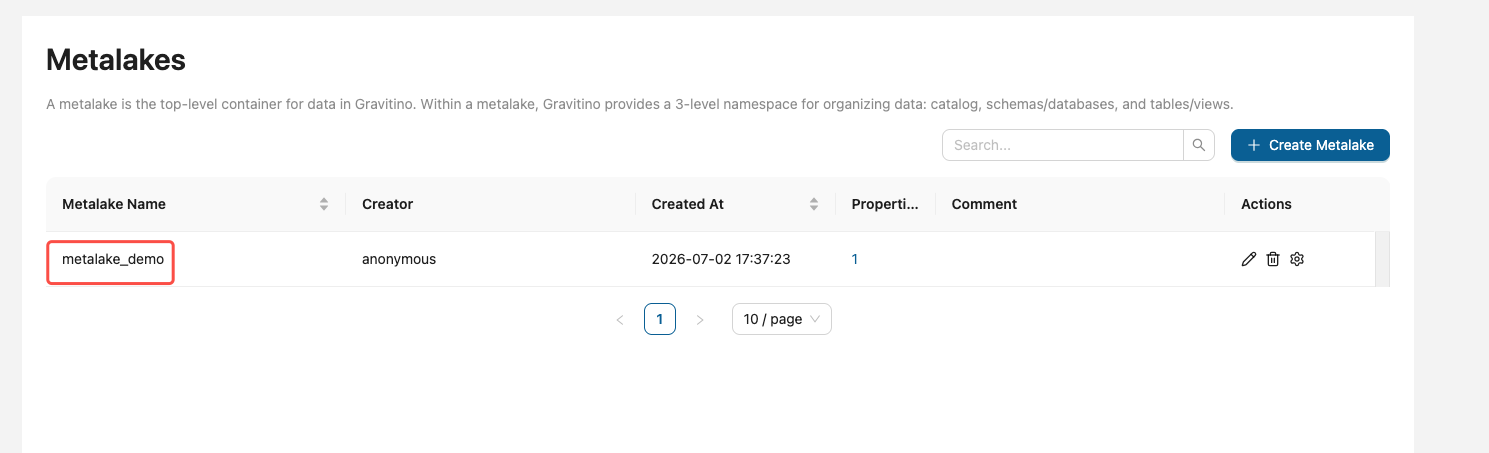
2. 第一步:准备 Metalake(若尚未创建)
Catalog 必须挂在 Metalake 下。下面统一用 metalake 名 test、Gravitino 地址 http://localhost:8090。
bash
# 创建 metalake(已存在则跳过)
curl -X POST -H "Content-Type: application/json" -d '{
"name": "test",
"comment": "dev metalake"
}' http://localhost:8090/api/metalakes
curl http://localhost:8090/api/metalakes # 验证或者在页面
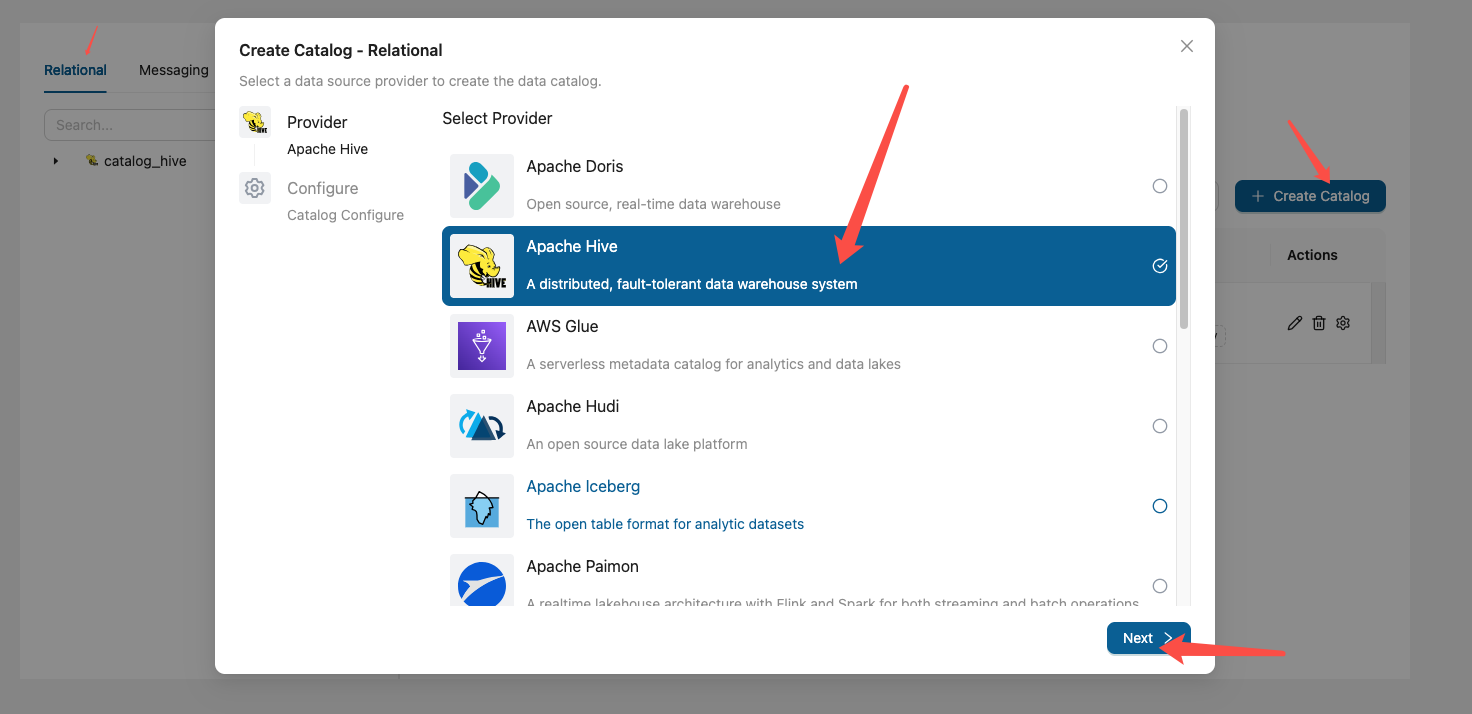
3. 第二步:在 Gravitino 创建 Hive Catalog
向 Gravitino 注册一个指向 HMS 的 Hive catalog。provider=hive、type=relational。
bash
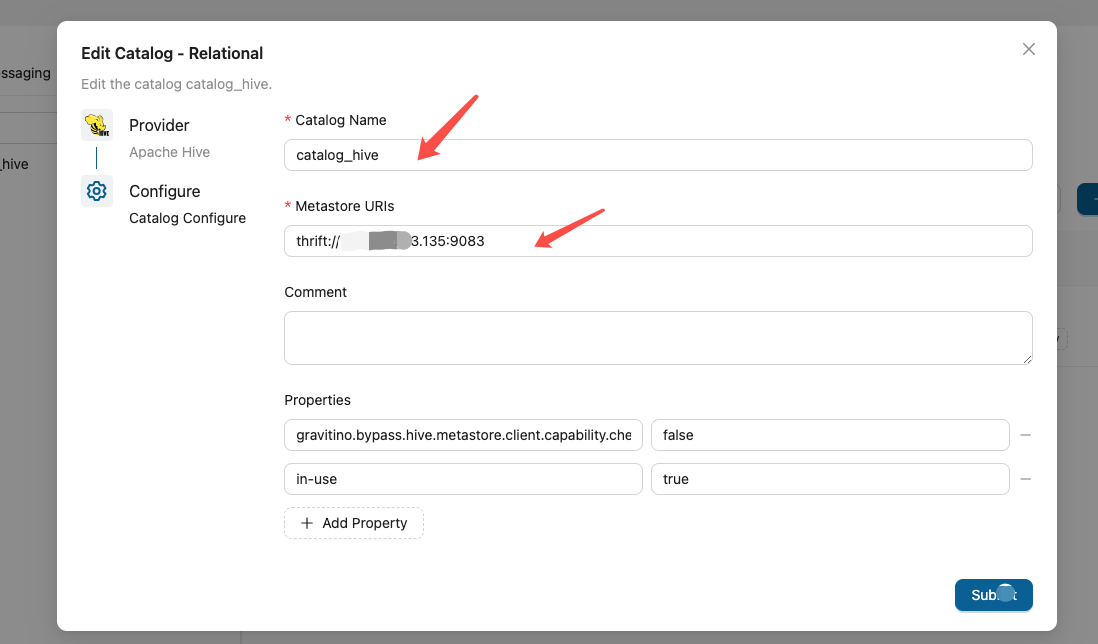
curl -X POST -H "Content-Type: application/json" -d '{
"name": "hive_cat",
"type": "relational",
"provider": "hive",
"comment": "生产 Hive 集群",
"properties": {
"metastore.uris": "thrift://hive-metastore:9083",
"gravitino.bypass.hive.metastore.client.capability.check": "false"
}
}' http://localhost:8090/api/metalakes/test/catalogs
metastore.uris(必填 ):HMS 的 thrift 地址。Spark 侧会被翻译成hive.metastore.uris。gravitino.bypass.*前缀的属性会原样透传 给 Spark 的 Hive 连接器(去掉前缀)。例:gravitino.bypass.hive.exec.dynamic.partition.mode→hive.exec.dynamic.partition.mode。- 若 Spark 用的是 spark-sql shell ,还要在此处加一条(见第 5 节的坑):
"spark.bypass.spark.sql.hive.metastore.jars": "maven"
验证 catalog 已创建并列出其下的 schema(库):
bash
curl http://localhost:8090/api/metalakes/test/catalogs # 列出 catalog
curl http://localhost:8090/api/metalakes/test/catalogs/hive_cat # 详情
curl http://localhost:8090/api/metalakes/test/catalogs/hive_cat/schemas # 列出 Hive 库也可在 Web UI(:8090) 里图形化创建:Metalake → Create Catalog → 选 Hive,填
metastore.uris。
4. 第三步:安装 Spark Gravitino 连接器
4.1 放置连接器 runtime jar
按 Spark 小版本下载对应的 runtime jar,放入 Spark 的 classpath(jars/ 目录或用 --jars):
| Spark 版本 | 连接器包 |
|---|---|
| 3.3 | gravitino-spark-connector-runtime-3.3 |
| 3.4 | gravitino-spark-connector-runtime-3.4 |
| 3.5 | gravitino-spark-connector-runtime-3.5 |
bash
# 示例:Spark 3.5 + Gravitino 1.3.0
curl -L -o gravitino-spark-connector-runtime-3.5_2.12-1.3.0.jar \
https://repo1.maven.org/maven2/org/apache/gravitino/gravitino-spark-connector-runtime-3.5/1.3.0/gravitino-spark-connector-runtime-3.5_2.12-1.3.0.jar
# 放到 Spark classpath
cp gravitino-spark-connector-runtime-3.5_2.12-1.3.0.jar $SPARK_HOME/jars/
4.2 让 Spark 能访问 HDFS
Spark 需要能连上 Hive 表所在的 HDFS。把 Hadoop 配置放到 Spark 能读到的地方,二选一:
- 把
core-site.xml、hdfs-site.xml、hive-site.xml复制到$SPARK_HOME/conf/;或 - 在 Spark conf 里通过
hive.config.resources指定它们的路径。
网络:Spark 所在主机/容器必须能路由到 HMS(9083) 与 HDFS(9000)。若 Spark 也跑在 Docker,建议和 Gravitino、HMS 放同一网络。
5. 第四步:用 spark-sql 查询 Hive 数据
5.1 启动 spark-sql
bash
$SPARK_HOME/bin/spark-sql -v \
--conf spark.plugins="org.apache.gravitino.spark.connector.plugin.GravitinoSparkPlugin" \
--conf spark.sql.gravitino.uri=http://localhost:8090 \
--conf spark.sql.gravitino.metalake=metalake_demo | 配置 | 含义 |
|---|---|
spark.plugins |
启用 Gravitino Spark 插件(固定值) |
spark.sql.gravitino.uri |
Gravitino 服务地址 |
spark.sql.gravitino.metalake |
要使用的 metalake,也就是在 gravitino 中已有的,这里是 metalake_demo |
spark.sql.gravitino.enableIcebergSupport=true |
仅当要同时用 Iceberg catalog 时才加 |
5.2 SQL 示例(查询已有 Hive 表)
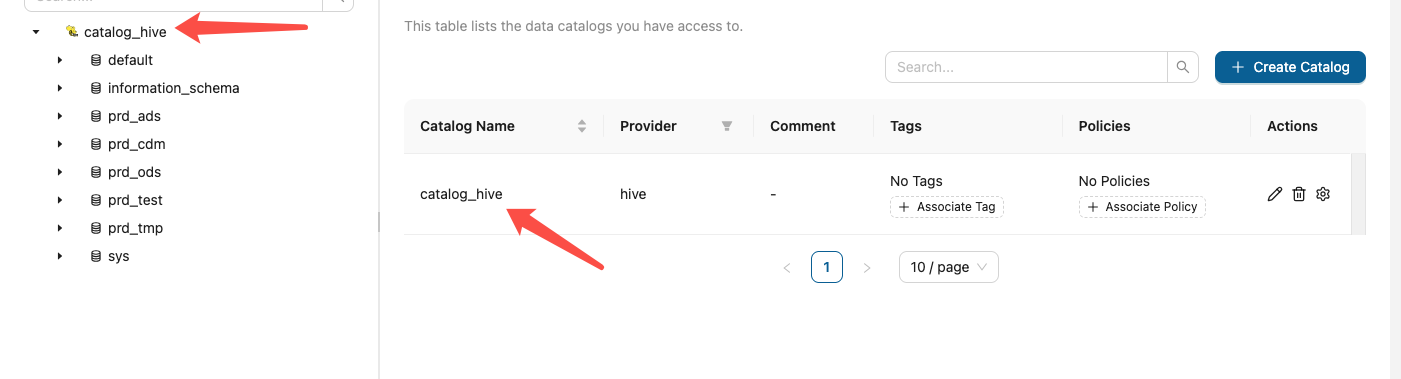
注意⚠️:在此处使用 show catalogs 时仅会展示 spark_catalog ,而不会展示 gravitino 中创建的 catalog_hive

附官方说明:

但是可以直接使用 use xxx 进行 catalog 切换,这里在 Gravitino 中创建的是catalog_hive
sql
USE catalog_hive; -- 切到 Gravitino 里的 Hive catalog执行成功后的差别:

查询 : 使用 gravitino 的 catalog

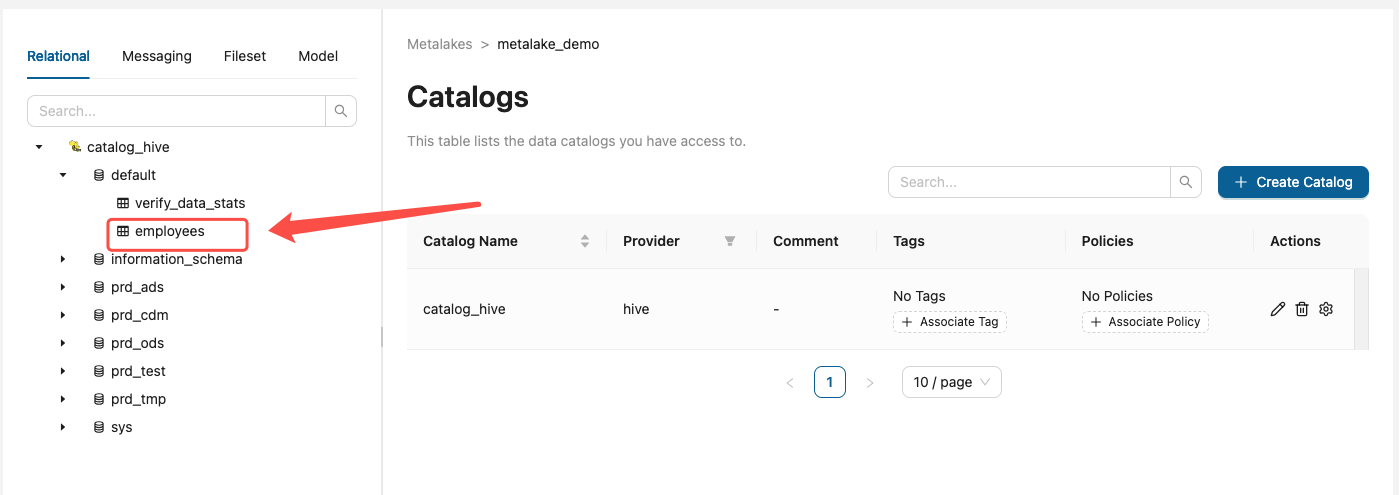
5.3 建表 / 写入 / 分区查询(端到端)
sql
CREATE TABLE IF NOT EXISTS employees (
id INT,
name STRING,
age INT
) PARTITIONED BY (department STRING)
STORED AS PARQUET;
INSERT OVERWRITE TABLE employees PARTITION (department='Engineering')
VALUES (1, 'John Doe', 30), (2, 'Jane Smith', 28);
INSERT OVERWRITE TABLE employees PARTITION (department='Marketing')
VALUES (3, 'Mike Brown', 32);
SELECT * FROM employees WHERE department = 'Engineering';gravitino 同步元数据
6. ⚠️ spark-sql shell 必须修的一个坑
用 spark-sql 命令行 访问 Hive catalog 时,默认 spark.sql.hive.metastore.jars=builtin,会导致 metastore 客户端加载异常。解决方法 :在 Gravitino 建 Hive catalog 时 加一条透传属性(spark.bypass.* 会传给 Spark):
bash
# 在第 3 步创建 catalog 的 properties 里增加:
"spark.bypass.spark.sql.hive.metastore.jars": "maven"maven:运行时从 Maven 下载合适的 hive metastore jars(最省事,需要外网)。- 也可指定本地 hive jars 路径或
builtin之外的自定义值,按环境调整。
该属性建议放在 catalog properties(而非 Spark conf),这样所有用此 catalog 的 Spark 会话都生效。
7. 配置速查表
7.1 Gravitino Hive catalog 关键属性
| 属性 | 必填 | 说明 |
|---|---|---|
metastore.uris |
✅ | HMS thrift 地址,如 thrift://hive-metastore:9083 |
gravitino.bypass.<key> |
--- | 透传给 Spark Hive 连接器(去前缀),如 hive.exec.dynamic.partition.mode |
spark.bypass.<key> |
--- | 透传给 Spark 自身配置,如 spark.sql.hive.metastore.jars |
warehouse |
--- | Hive warehouse 目录(一般由 HMS 决定,可不填) |
7.2 Spark 端关键配置
| 配置 | 必填 | 说明 |
|---|---|---|
spark.plugins |
✅ | org.apache.gravitino.spark.connector.plugin.GravitinoSparkPlugin |
spark.sql.gravitino.uri |
✅ | Gravitino 地址 |
spark.sql.gravitino.metalake |
✅ | metalake 名 |
spark.sql.gravitino.enableIcebergSupport |
--- | 用 Iceberg 时设 true |
spark.sql.gravitino.enablePaimonSupport |
--- | 用 Paimon 时设 true |
spark.sql.gravitino.client.* |
--- | Gravitino Java client 配置(如 socketTimeoutMs) |
8. 常见问题
| 现象 | 原因 / 解决 |
|---|---|
USE hive_cat 报找不到 catalog |
metalake 名 / Gravitino 地址填错;或 catalog 没建成功。先 curl .../catalogs 确认。 |
连不上 HMS(Connection refused 9083) |
metastore.uris 指向错;Spark 所在主机/容器到 HMS 网络不通。Docker 下放同一 network。 |
读不到 HDFS 数据(FileNotFoundException) |
Spark 没拿到 HDFS 配置:放 core-site.xml/hdfs-site.xml 到 $SPARK_HOME/conf,或设 hive.config.resources。 |
| spark-sql 下 metastore 客户端异常 | 默认 builtin jars 问题,按第 6 节在 catalog 加 spark.bypass.spark.sql.hive.metastore.jars=maven。 |
SHOW CATALOGS 看不到 hive_cat |
属正常(Spark 限制),用 USE hive_cat 成功即可。 |
连接器类找不到(ClassNotFoundException: ...GravitinoSparkPlugin) |
runtime jar 没进 classpath;确认 Spark 小版本与 jar(3.3/3.4/3.5)匹配。 |
| View 相关 DDL 失败 | 连接器不支持 CREATE/DROP/ALTER VIEW;但可 SELECT 读 HMS 里已有的视图(大视图有 OOM 风险)。 |
不支持 OpenCSVSerde 的表 |
已知限制,改用其它 serde。 |
下一步看看数据治理能力 - 权限控制
信息来源
- Spark 连接器总览:https://gravitino.apache.org/docs/1.3.0/spark-connector/spark-connector/
- Spark 访问 Hive catalog:https://gravitino.apache.org/docs/1.3.0/spark-connector/spark-catalog-hive/
- 创建 Catalog REST:https://gravitino.apache.org/docs/1.3.0/api/rest/create-catalog/
- Hive catalog 属性:https://gravitino.apache.org/docs/1.3.0/hive-catalog/
- Maven 包:https://repo1.maven.org/maven2/org/apache/gravitino/