第3.5篇: 图像识别------儿童绘画内容理解
系列 :HarmonyOS 从入门到实践 · 画伴梦工厂实战
难度 :⭐⭐⭐ 高级
前置知识 :3.1 HTTP 网络请求、3.4 图片压缩与 Base64 编解码
涉及源文件 :
products/default/src/main/ets/services/ImageRecognitionService.ets
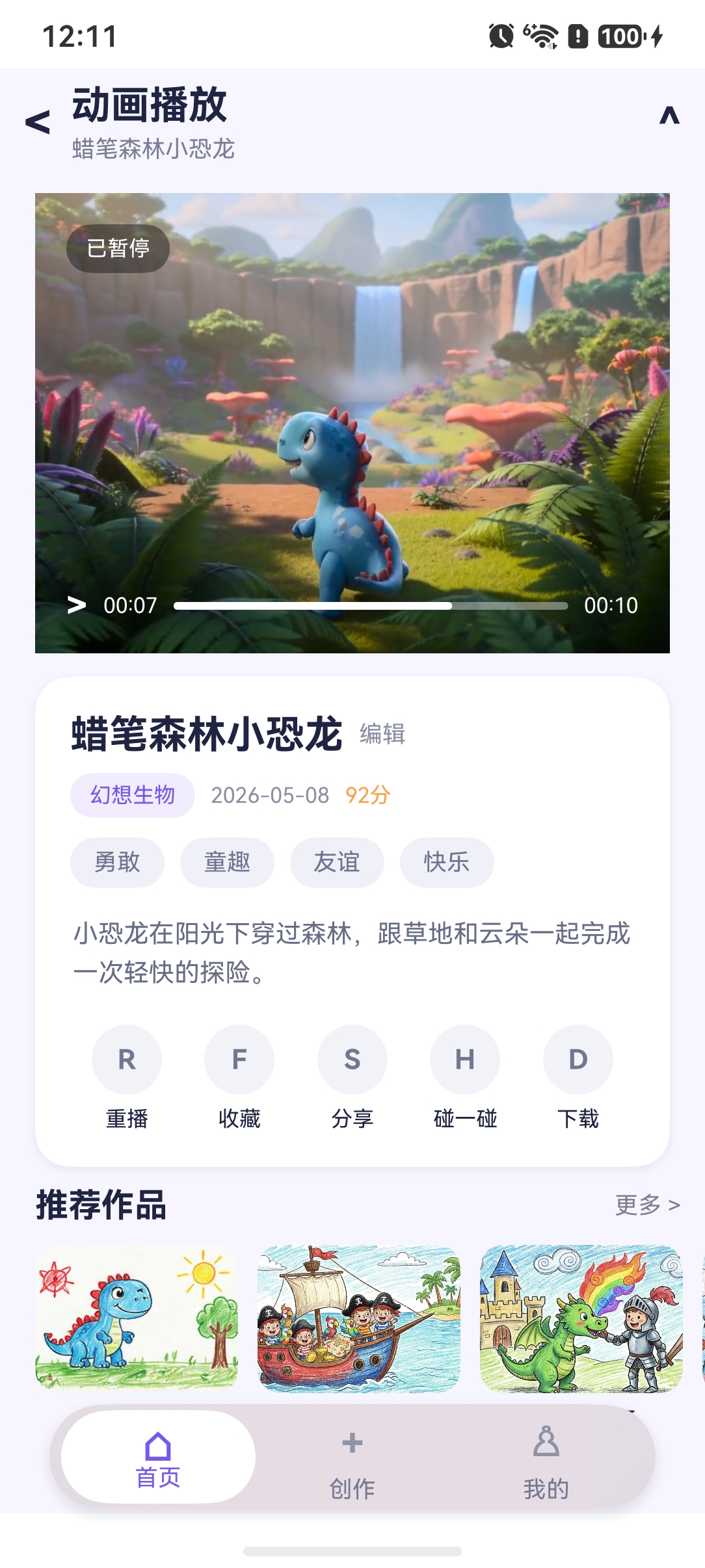
在"画伴梦工厂"中,识别一幅儿童手绘的内容(画了什么角色、在哪里、什么情绪)是生成动画的关键前提。传统图像标签服务只能输出"恐龙"、"草地"这样的通用标签,无法提取角色身份、场景氛围、情绪色彩这些对动画生成至关重要的结构化信息。
这里我们使用市场上常见的多模态模型,支持同时接收文本和图像输入,在图像识别任务上表现出色且推理成本极低。本文将详细拆解如何通过它实现专为儿童绘画设计的智能识别管线。
一、多模态模型
| 考量维度 | 多模态模型 | 传统图像分类 API |
|---|---|---|
| 输入形式 | 文本 + 图像多模态 | 仅图像 |
| 结构化输出 | JSON 格式,自由定义字段 | 固定标签 + 置信度 |
| 推理能力 | 理解绘画主题、情绪、建议 | 仅识别物体名称 |
| 每千张成本 | ~$0.15 | 通常 1 \~ 3 |
核心优势在于:多模态模型 不仅能识别"这是一只恐龙",还能理解"这是一只快乐的小恐龙在草地上晒太阳,适合做跳跃和摇尾巴的动画"。这种开放域理解能力正是儿童画创作场景所需要的。
二、数据模型:以类型安全定义识别结果
首先定义识别结果的结构。这是整个服务的"契约",决定了 AI 返回什么、页面消费什么:
typescript
export interface RecognizedElement {
name: string; // 元素名称,如"小恐龙"
confidence: number; // 置信度 0-100
color: string; // UI 展示用的主题色
}
export interface DrawingRecognitionResult {
protagonist: string; // 主角描述
scene: string; // 场景描述
emotion: string; // 情绪描述
animationSuggestion: string; // 动画动作建议
summary: string; // 综合摘要
elements: RecognizedElement[]; // 识别出的元素列表
}DrawingRecognitionResult 是面向动画生成流程设计的------protagonist 决定动画主体,scene 决定背景风格,emotion 决定色调和配乐倾向,animationSuggestion 直接输入到后续的 3.3 图生视频服务作为 prompt 增强。
三、多模态请求体构建
3.1 OpenAI 兼容格式
多模态请求遵循 OpenAI Chat Completions 格式,核心是允许 content 字段为数组,同时包含文本片段和图片片段:
typescript
interface ModelContentPart {
type: string; // 'text' 或 'image_url'
text?: string; // type 为 'text' 时使用
image_url?: ModelImageUrl; // type 为 'image_url' 时使用
}
interface ModelMessage {
role: string; // 'system' 或 'user'
content: string | ModelContentPart[]; // 字符串或多模态数组
}
interface ModelRequestBody {
model: string;
temperature: number;
messages: ModelMessage[];
}3.2 buildRequestBody:组装结构化 Prompt
buildRequestBody 方法负责将 Base64 图片和结构化 Prompt 组装成请求体:
typescript
private static buildRequestBody(imageBase64: string, mimeType: string): ModelRequestBody {
const schemaPrompt: string =
'请识别这张儿童手绘图片中的主要角色、场景、情绪和适合生成动画的动作建议。' +
'只返回 JSON,不要 Markdown。字段必须为:protagonist、scene、emotion、animationSuggestion、summary、elements。' +
'elements 是数组,最多 6 项,每项包含 name 和 0-100 的 confidence。中文作答。';
const systemMessage: ModelMessage = {
role: 'system',
content: '你是儿童绘画智能识别助手,结果要适合在儿童创作应用里展示,表达温和、简洁。'
};
const textPart: ModelContentPart = {
type: 'text',
text: schemaPrompt
};
const imageUrl: ModelImageUrl = {
url: 'data:' + mimeType + ';base64,' + imageBase64
};
const imagePart: ModelContentPart = {
type: 'image_url',
image_url: imageUrl
};
const userMessage: ModelMessage = {
role: 'user',
content: [textPart, imagePart]
};
return {
model: MODEL_NAME, // 多模态模型
temperature: 0.2, // 低温度确保输出稳定
messages: [systemMessage, userMessage]
};
}3.3 Prompt 工程设计要点
Prompt 是整个识别服务的灵魂。设计时有几个关键决策:
① system message 设定角色:
"你是儿童绘画智能识别助手,结果要适合在儿童创作应用里展示,表达温和、简洁。"这告诉模型:用儿童友好的语气输出,不要用冷冰冰的技术术语。
② 明确的 JSON Schema 约束:
"只返回 JSON,不要 Markdown。字段必须为:protagonist、scene、emotion......"直接指定字段名和类型,避免模型输出多余的 Markdown 包裹或无关字段。
③ 置信度范围限定:
"每项包含 name 和 0-100 的 confidence"明确数值范围,降低模型输出异常值的概率。
④ temperature = 0.2:低温度值让模型输出更确定、更可重复,适合结构化提取任务。如果是创意生成任务(如文案创作),通常会设到 0.7~0.9。
四、图片预处理:压缩与 Base64
在 3.4 图片压缩篇中已经详细介绍了压缩技术,这里重点关注几个与识别服务直接相关的常量:
typescript
const MAX_IMAGE_BYTES: number = 12 * 1024 * 1024; // 最大原始大小 12MB
const RECOGNITION_IMAGE_TARGET_BYTES: number = 520 * 1024; // 压缩目标 520KB
const RECOGNITION_IMAGE_MAX_EDGE: number = 1024; // 最大边长 1024pxprepareRecognitionImage 方法是压缩链路的入口:
typescript
private static async prepareRecognitionImage(imageUri: string): Promise<PreparedImagePayload> {
const sourceBuffer = ImageRecognitionService.readImageAsArrayBuffer(imageUri);
try {
const compressedBuffer = await ImageRecognitionService.compressImageBuffer(sourceBuffer);
return {
base64: ImageRecognitionService.arrayBufferToBase64(compressedBuffer),
mimeType: 'image/jpeg'
};
} catch (error) {
// 压缩失败时回退到原图
return {
base64: ImageRecognitionService.arrayBufferToBase64(sourceBuffer),
mimeType: ImageRecognitionService.getMimeType(imageUri)
};
}
}注意这里的兜底策略:如果图片压缩失败(比如图片太小无需压缩),不会让整个识别流程崩溃,而是直接使用原图。这个模式在后续的降级处理中还会反复出现。
五、网络请求与异常处理
recognizeDrawing 是服务的核心入口方法:
typescript
static async recognizeDrawing(imageUri: string): Promise<DrawingRecognitionResult> {
if (imageUri === '') {
return ImageRecognitionService.getFallbackResult();
}
// Step 1: 准备图片(压缩 + Base64)
let payload: PreparedImagePayload = { base64: '', mimeType: 'image/jpeg' };
try {
payload = await ImageRecognitionService.prepareRecognitionImage(imageUri);
} catch (error) {
throw new Error('图片读取失败:' + ImageRecognitionService.getErrorMessage(error as Error));
}
// Step 2: 创建 HTTP 请求
const request = http.createHttp();
try {
const headers: ModelHeaders = {
'Content-Type': 'application/json',
'Authorization': 'Bearer ' + MODEL_API_KEY
};
const options: http.HttpRequestOptions = {
method: http.RequestMethod.POST,
expectDataType: http.HttpDataType.STRING,
connectTimeout: 30000,
readTimeout: 60000,
header: headers,
extraData: JSON.stringify(ImageRecognitionService.buildRequestBody(payload.base64, payload.mimeType))
};
const response = await request.request(MODEL_API_URL, options);
const responseText = response.result.toString();
if (response.responseCode < 200 || response.responseCode >= 300) {
throw new Error('模型接口返回异常:' + response.responseCode.toString());
}
const responseBody = JSON.parse(responseText) as ModelResponseBody;
if (responseBody.error && responseBody.error.message) {
throw new Error(responseBody.error.message);
}
// Step 3: 解析并规范化结果
return ImageRecognitionService.normalizeModelResult(responseBody.choices[0].message.content);
} finally {
request.destroy();
}
}三重异常防护
| 层级 | 异常类型 | 处理方式 |
|---|---|---|
| 图片读取 | 文件不存在、权限不足、大小超限 | 抛出明确错误信息 |
| HTTP 请求 | 网络超时、非 2xx 状态码 | 抛出带状态码的错误 |
| 响应解析 | JSON 格式错误、字段缺失 | 抛出解析失败信息 |
每一层都确保错误信息足够具体,方便上层调用方决定是提示用户重试、降级展示默认结果,还是跳转到备用流程。
六、结果规范化与降级处理
这是整个服务中最见"工程功底"的部分------AI 模型返回的内容永远不可信,必须做严格的校验和兜底。
6.1 stripJsonFence:清理 Markdown 包裹
虽然 Prompt 要求"只返回 JSON,不要 Markdown",但模型有时还是会输出代码块。stripJsonFence 负责清理:
typescript
private static stripJsonFence(content: string): string {
const trimmed = content.trim();
if (!trimmed.startsWith('```')) {
return trimmed;
}
const firstLineEnd = trimmed.indexOf('\n');
const lastFenceStart = trimmed.lastIndexOf('```');
if (firstLineEnd >= 0 && lastFenceStart > firstLineEnd) {
return trimmed.substring(firstLineEnd + 1, lastFenceStart).trim();
}
return trimmed;
}逻辑很简单:如果字符串以 ```````````开头,找到第一个换行(去掉第一行的语言标记)和最后一个`````` `````,提取中间内容。这段代码处理了类似这样的输入:
```json
{"protagonist": "小恐龙", ...}
```6.2 clampConfidence:置信度边界限定
typescript
private static clampConfidence(value: number | undefined): number {
if (value === undefined || Number.isNaN(value)) {
return 86; // 默认置信度
}
return Math.max(0, Math.min(100, Math.round(value)));
}既防止了模型返回负值或超过 100 的异常值,也为缺失值提供了合理的默认值(86)。
6.3 pickText:字段级兜底
typescript
private static pickText(value: string | undefined, fallback: string): string {
if (value && value.trim() !== '') {
return value.trim();
}
return fallback;
}对每个文本字段独立做空值检查。如果 AI 没有返回某个字段(比如 emotion 缺失),就用默认值替代,而不是显示空字符串。
6.4 normalizeModelResult:全量规范化
typescript
private static normalizeModelResult(content: string): DrawingRecognitionResult {
const jsonText = ImageRecognitionService.stripJsonFence(content);
const parsed = JSON.parse(jsonText) as ModelResultBody;
const fallback = ImageRecognitionService.getFallbackResult();
const elements: RecognizedElement[] = [];
if (parsed.elements) {
for (let i = 0; i < parsed.elements.length && i < 6; i++) {
const item = parsed.elements[i];
if (!item.name || item.name.trim() === '') {
continue; // 跳过无名称的元素
}
elements.push({
name: item.name,
confidence: ImageRecognitionService.clampConfidence(item.confidence),
color: ELEMENT_COLORS[i % ELEMENT_COLORS.length] // 轮换颜色
});
}
}
return {
protagonist: ImageRecognitionService.pickText(parsed.protagonist, fallback.protagonist),
scene: ImageRecognitionService.pickText(parsed.scene, fallback.scene),
emotion: ImageRecognitionService.pickText(parsed.emotion, fallback.emotion),
animationSuggestion: ImageRecognitionService.pickText(parsed.animationSuggestion, fallback.animationSuggestion),
summary: ImageRecognitionService.pickText(parsed.summary, fallback.summary),
elements: elements.length > 0 ? elements : fallback.elements
};
}关键设计原则:
- 每字段独立兜底:不因为一个字段异常就丢弃全部结果
- 元素白名单 :跳过
name为空的元素项,而不是直接报错 - 颜色轮换 :
ELEMENT_COLORS提供 6 种预设色,确保 UI 展示有视觉区分度 - 整体降级 :如果
elements数组最终为空,使用默认元素列表
6.5 getFallbackResult:有温度的默认值
typescript
const DEFAULT_RESULT: DrawingRecognitionResult = {
protagonist: '小恐龙',
scene: '草地和太阳',
emotion: '快乐探险',
animationSuggestion: '跳跃、摇尾、看向太阳',
summary: '识别到儿童手绘中的主角、自然场景和明亮情绪,适合生成轻快的探险动画草稿。',
elements: [
{ name: '小恐龙', confidence: 96, color: '#D8F7EA' },
{ name: '太阳', confidence: 91, color: '#FFF0DD' },
{ name: '草地', confidence: 88, color: '#EAF8F0' },
{ name: '树木', confidence: 84, color: '#F1EDFF' }
]
};默认值不是随便填的。它们构成了一个完整的、可用的动画场景------一只小恐龙在草地上晒太阳。即使用户的网络完全不可用,或者 AI 服务宕机,应用也可以直接用这些默认值启动动画生成流程,用户甚至可能察觉不到异常。
七、完整调用链路
7.1 业务层调用
在 PhotoRecognitionComponent 中,识别服务被调用的典型场景是用户拍照/选择图片后点击"生成动画":
用户拍照/选图
│
▼
capturedImageUri 保存成功
│
▼
generateFromPhoto()
│
▼
navigateToGeneration()
│
▼
RecognitionWaitingPage(等待页)
│
├── startGeneration() → AIGenerationService.generateVideo()
│ (内部可先调用 ImageRecognitionService.recognizeDrawing)
│
└── 完成后 pushUrl → RecognitionResultPage7.2 结果展示
在 RecognitionResultPage.ets 中,识别结果通过路由参数传递并展示:
typescript
// aboutToAppear 中解析识别结果
if (params && params.recognitionResult) {
try {
this.recognitionResult = JSON.parse(params.recognitionResult) as DrawingRecognitionResult;
} catch (error) {
this.recognitionResult = ImageRecognitionService.getFallbackResult();
}
}在 UI 层,通过 buildResultItems 方法将结构化数据转换为展示项:
typescript
private buildResultItems(): ResultItem[] {
const firstConfidence = this.recognitionResult.elements.length > 0
? this.recognitionResult.elements[0].confidence : 96;
const secondConfidence = this.recognitionResult.elements.length > 1
? this.recognitionResult.elements[1].confidence : 91;
// ...
return [
{ name: '主角:' + this.recognitionResult.protagonist, confidence: firstConfidence },
{ name: '场景:' + this.recognitionResult.scene, confidence: secondConfidence },
{ name: '情绪:' + this.recognitionResult.emotion, confidence: thirdConfidence },
{ name: '动画建议:' + this.recognitionResult.animationSuggestion, confidence: fourthConfidence }
];
}每个识别维度都展示为一个卡片行,包含名称和置信度百分比,用品牌紫色突出显示。ResultPage 根据 videoUri 是否为空决定展示视频播放视图还是识别结果视图。
┌──────────────────────────────┐
│ 识别结果 │
│ 画作识别已完成 │
├──────────────────────────────┤
│ │
│ [ 画作预览图 ] │
│ │
│ ┌────────────────────────┐ │
│ │ 动画草稿已准备 │ │
│ │ 识别到儿童手绘中的... │ │
│ ├────────────────────────┤ │
│ │ 主角:小恐龙 96% │ │
│ │ 场景:草地和太阳 91% │ │
│ │ 情绪:快乐探险 88% │ │
│ │ 动画建议:跳跃... 86% │ │
│ └────────────────────────┘ │
│ │
│ [ 查看动画视频 ] │
└──────────────────────────────┘八、服务层架构设计要点
ImageRecognitionService 采用纯静态方法 设计模式,所有方法都是 static,这么做有几个好处:
| 特性 | 说明 |
|---|---|
| 无需实例化 | 直接 ImageRecognitionService.recognizeDrawing() 调用 |
| 无状态 | 每次调用独立,天然线程安全 |
| 易于测试 | 可以 mock HTTP 层单独测试解析逻辑 |
| 轻量 | 不依赖 Context,不与组件生命周期耦合 |
接口模型(ModelRequestBody、ModelResponseBody 等)全部声明为私有 interface,对外只暴露 DrawingRecognitionResult 和 RecognizedElement。这遵循了信息隐藏原则------调用方不需要知道 GPT-4o-mini 的请求格式细节。
九、与 3.4 图片压缩的协作关系
本文假设读者已经掌握了 3.4 篇的内容。这里梳理一下两个服务之间的协作点:
ImageRecognitionService.recognizeDrawing(imageUri)
│
├── readImageAsArrayBuffer() ← fileIo 读取文件
│
├── compressImageBuffer() ← image.Packer 压缩(520KB 目标)
│ │ image.PixelMap 缩放(1024px 最大边长)
│ │ JPEG quality 68 / 52 两级策略
│
├── arrayBufferToBase64() ← util.Base64Helper 编码
│
├── buildRequestBody() ← 组装多模态请求
│
├── http POST → GPT-4o-mini API ← @kit.NetworkKit 网络请求
│
└── normalizeModelResult() ← 解析、校验、降级图片压缩将原始图片(可能 10MB+)压缩到约 520KB 的 JPEG,既满足 GPT-4o-mini 的输入限制,又大幅缩短传输时间。Base64 编码将二进制图片转为字符串,嵌入 JSON 请求体中。
十、异常场景覆盖检查
| 场景 | 触发条件 | 行为 |
|---|---|---|
| 空 URI | imageUri === '' |
直接返回 fallback 结果 |
| 图片读取失败 | fileIo 异常 | 抛出"图片读取失败" |
| 图片超 12MB | stat.size 超限 | 抛出明确提示 |
| 压缩失败 | image.Packer 异常 | 使用未压缩原图 |
| HTTP 超时 | 30s 连接 / 60s 读取 | 抛网络异常 |
| 非 2xx 响应 | responseCode 异常 | 抛出状态码 + 响应片段 |
| AI 返回错误 | responseBody.error | 抛出 error.message |
| JSON 解析失败 | JSON.parse 异常 | 抛出"不是约定 JSON" |
| 字段缺失 | protagonist 等为空 | pickText 使用默认值 |
| elements 为空 | 无有效元素 | 使用默认元素列表 |
这张表展示了工业级 AI 集成服务应有的防御深度。上线前可以对每个场景编写测试用例,确保降级行为符合预期。
总结
GPT-4o-mini 图像识别是"画伴梦工厂"AI 服务链中承上启下的一环。本文从多模态请求构建、Prompt 工程设计、结果规范化到降级策略,完整拆解了这个服务:
| 知识点 | 实现 |
|---|---|
| 多模态请求 | text + image_url 双 part 结构,含 Base64 图片 |
| Prompt 工程 | system/user 双消息,显式 JSON Schema 约束 |
| 结果解析 | stripJsonFence → JSON.parse → normalizeModelResult |
| 字段级兜底 | pickText / clampConfidence 独立处理每个字段 |
| 整体降级 | getFallbackResult 返回有意义的默认场景 |
| 防御式编程 | 图片读取失败 → 原图回退;AI 异常 → 默认结果 |
下一篇预告: 第 3.6 篇 JSON 序列化与反序列化------我们将深入对比 AIGenerationService 与 ImageRecognitionService 中不同的 JSON 处理策略,学习如何定义健壮的 interface 数据模型。
参考源码
本文所有代码均来自项目文件:
products/default/src/main/ets/services/ImageRecognitionService.ets--- 完整的 GPT-4o-mini 图像识别服务实现products/default/src/main/ets/pages/RecognitionResultPage.ets--- 识别结果展示页面products/default/src/main/ets/components/CreationComponents.ets--- PhotoRecognitionComponent 中触发识别的业务逻辑