论文标题:ChordEdit: One-Step Low-Energy Transport for Image Editing
会议:CVPR 2026 (Oral)
作者 :Liangsi Lu, Xuhang Chen, Minzhe Guo, Shichu Li, Jingchao Wang, Yang Shi(对应作者) 机构:广东工业大学、惠州学院、深圳大学、北京大学
项目页面 :chordedit.github.io
arXiv :2602.19083
1. 引言:当"改图"只需一步
想象一下这样的场景:你有一张猫咪坐在沙发上的照片,你希望猫咪戴上墨镜、换成皮沙发、背景从客厅变成海滩。在传统工作流中,这意味着打开 Photoshop,花上几十分钟抠图、调色、合成、修补边缘------还得祈祷最终效果不要太"AI"。而在扩散模型时代,你只需要一句话:"一只戴着墨镜的猫,躺在皮沙发上,背景是海滩"。
但问题来了------现有的基于扩散模型的图像编辑方法,要么需要几十步甚至上百步的迭代去噪(慢!),要么一步到位但编辑质量参差不齐(效果差!)。我们能不能既快又好?
广东工业大学联合惠州学院、深圳大学和北京大学的研究团队给出了一个响亮的回答:能! 他们提出的 ChordEdit ,是一个一步完成高质量图像编辑的全新方法,基于最优传输理论中的低能传输思想,在 CVPR 2026 上获得了 Oral 论文的殊荣(录取率约 3% 的顶级展示形式)!
ChordEdit 的核心思想优雅而深刻:与其让模型在扩散空间中盲目地"走很多步"去编辑图像,不如用数学上严谨的最优传输理论,计算出从"源提示"到"目标提示"的最短能量路径,然后一步到位。 这就像从北京到上海------你可以一步一步走国道(传统多步扩散编辑),也可以直接坐高铁(ChordEdit 的一步低能传输)。
试玩下项目自带的gradio demo
#打开 http://127.0.0.1:7860/
python app.py --model-root models/sd-turbo --server-port 7860把棕色的狗变成灰色
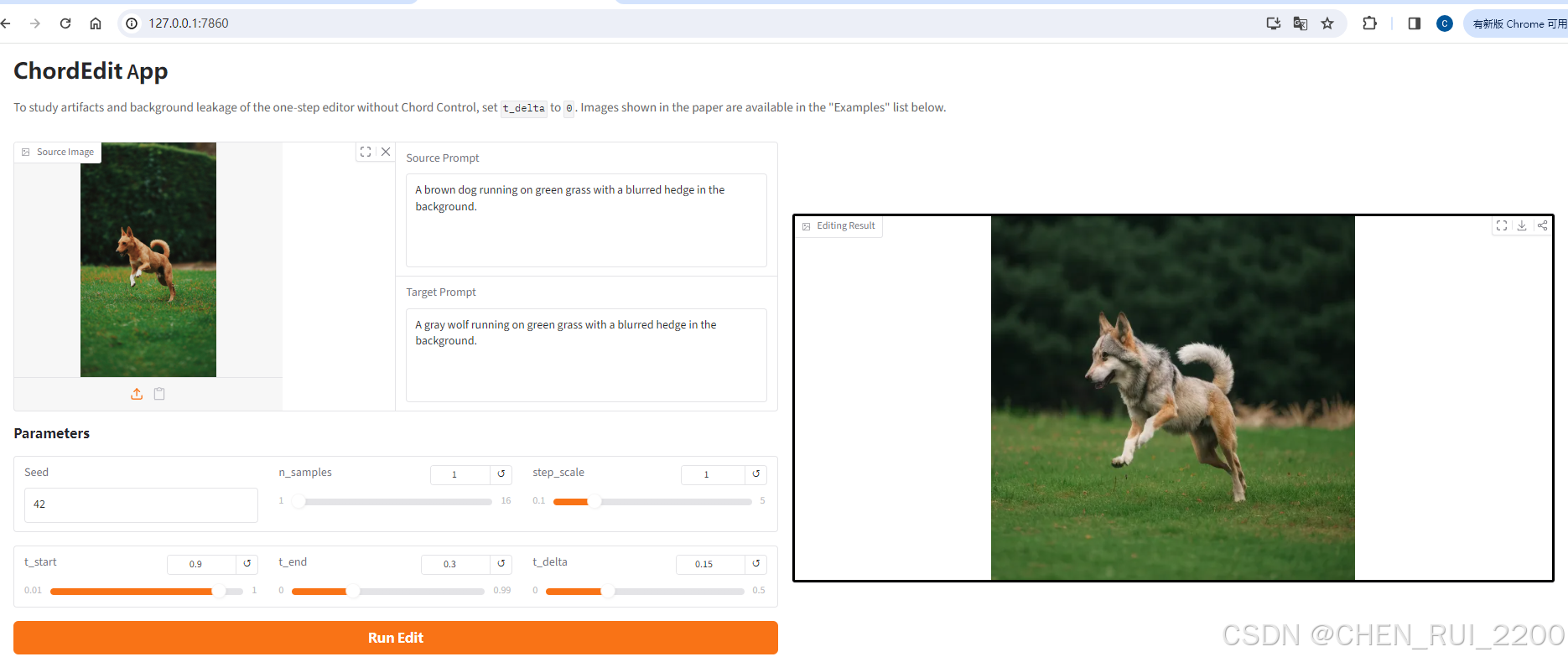
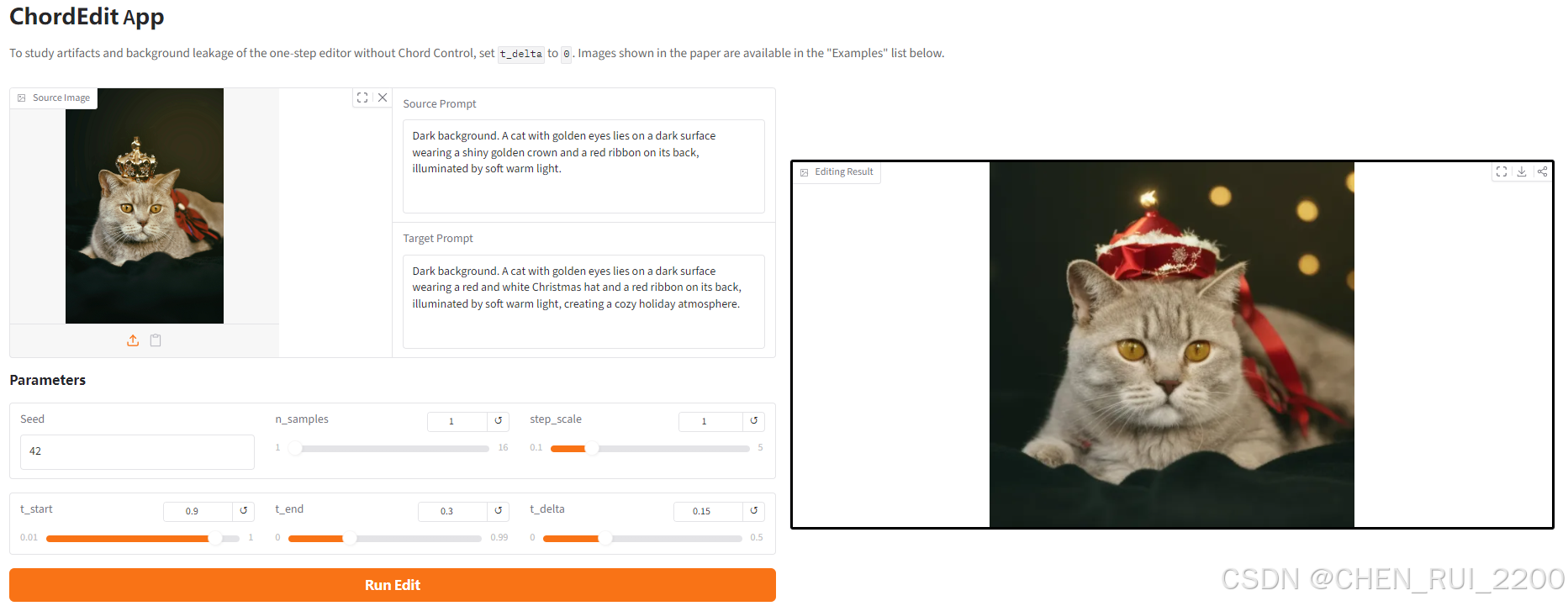
也可以跑PIE Benchmark,这个数据集结构
--pie-root
annotation_images/--- 原始 PIE-Bench 图像(子文件夹保留官方名称)。mapping_file.json--- 描述提示、说明和掩码的映射元数据。
我增加了个可视化脚本来查看跑出来的对比图
#!/usr/bin/env python
"""Generate an HTML report to visually compare original and edited images."""
from __future__ import annotations
import argparse
import json
import base64
from pathlib import Path
def load_mapping(mapping_path: Path) -> dict:
with open(mapping_path, "r", encoding="utf-8") as f:
return json.load(f)
def image_to_base64(img_path: Path) -> str:
with open(img_path, "rb") as f:
return base64.b64encode(f.read()).decode()
def build_html(
mapping: dict,
original_dir: Path,
output_dir: Path,
max_samples: int | None,
embed_images: bool,
) -> str:
rows: list[str] = []
keys = sorted(mapping.keys())
if max_samples:
keys = keys[:max_samples]
for idx, key in enumerate(keys):
record = mapping[key]
img_path = Path(record["image_path"])
original_file = original_dir / img_path
edited_file = output_dir / img_path
has_original = original_file.exists()
has_edited = edited_file.exists()
if embed_images:
orig_src = image_to_base64(original_file) if has_original else ""
edit_src = image_to_base64(edited_file) if has_edited else ""
orig_img = f'<img src="data:image/png;base64,{orig_src}" />' if has_original else '<div class="missing">Missing</div>'
edit_img = f'<img src="data:image/png;base64,{edit_src}" />' if has_edited else '<div class="missing">Not yet generated</div>'
else:
orig_img = f'<img src="{original_file.as_posix()}" loading="lazy" />' if has_original else '<div class="missing">Missing</div>'
edit_img = f'<img src="{edited_file.as_posix()}" loading="lazy" />' if has_edited else '<div class="missing">Not yet generated</div>'
orig_prompt = record.get("original_prompt", "")
edit_prompt = record.get("editing_prompt", "")
rows.append(f"""
<div class="sample-row">
<div class="sample-header">#{idx+1} ID: {key}</div>
<div class="image-pair">
<div class="image-panel">
<span class="panel-label">Original</span>
{orig_img}
</div>
<div class="image-panel">
<span class="panel-label">ChordEdit Output</span>
{edit_img}
</div>
</div>
<div class="prompt-row">
<div class="prompt-cell">
<div class="prompt-label">Source Prompt</div>
<div class="prompt-text">{orig_prompt}</div>
</div>
<div class="prompt-cell">
<div class="prompt-label">Target Prompt</div>
<div class="prompt-text">{edit_prompt}</div>
</div>
</div>
</div>
""")
html = f"""<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>ChordEdit - PIE-Bench Visual Report</title>
<style>
* {{ margin: 0; padding: 0; box-sizing: border-box; }}
body {{
font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, sans-serif;
background: #f5f5f5;
color: #333;
padding: 20px;
}}
h1 {{
text-align: center;
margin-bottom: 8px;
font-size: 1.5rem;
}}
.summary {{
text-align: center;
color: #666;
margin-bottom: 24px;
font-size: 0.9rem;
}}
.filter-bar {{
text-align: center;
margin-bottom: 20px;
}}
.filter-bar input {{
padding: 8px 12px;
border: 1px solid #ccc;
border-radius: 4px;
width: 320px;
font-size: 0.9rem;
}}
.sample-row {{
background: #fff;
border-radius: 8px;
margin-bottom: 24px;
box-shadow: 0 1px 4px rgba(0,0,0,0.08);
overflow: hidden;
}}
.sample-header {{
padding: 10px 16px;
background: #e8e8e8;
font-size: 0.85rem;
font-weight: 600;
color: #555;
}}
.image-pair {{
display: flex;
gap: 2px;
}}
.image-panel {{
flex: 1;
position: relative;
background: #111;
display: flex;
align-items: center;
justify-content: center;
min-height: 200px;
}}
.image-panel img {{
max-width: 100%;
max-height: 512px;
display: block;
object-fit: contain;
}}
.image-panel .missing {{
color: #888;
font-size: 0.9rem;
padding: 40px;
}}
.panel-label {{
position: absolute;
top: 8px;
left: 8px;
background: rgba(0,0,0,0.7);
color: #fff;
padding: 2px 8px;
border-radius: 3px;
font-size: 0.75rem;
font-weight: 600;
z-index: 1;
}}
.prompt-row {{
display: flex;
gap: 2px;
}}
.prompt-cell {{
flex: 1;
padding: 10px 12px;
}}
.prompt-label {{
font-size: 0.7rem;
font-weight: 700;
text-transform: uppercase;
color: #999;
margin-bottom: 4px;
}}
.prompt-text {{
font-size: 0.85rem;
line-height: 1.4;
color: #333;
}}
</style>
</head>
<body>
<h1>ChordEdit — PIE-Bench Visual Report</h1>
<div class="summary">Showing {len(keys)} of {len(mapping)} samples</div>
<div class="filter-bar">
<input type="text" id="filter" placeholder="Filter by prompt or ID..." oninput="filterSamples(this.value)">
</div>
<div id="samples">
{"".join(rows)}
</div>
<script>
function filterSamples(query) {{
const q = query.toLowerCase();
const rows = document.querySelectorAll('.sample-row');
rows.forEach(row => {{
const text = row.textContent.toLowerCase();
row.style.display = text.includes(q) ? '' : 'none';
}});
}}
</script>
</body>
</html>
"""
return html
def main() -> None:
parser = argparse.ArgumentParser(description="Generate HTML visual report for PIE-Bench results.")
parser.add_argument("--pie-root", type=str, default="data", help="PIE-Bench data root.")
parser.add_argument("--output", type=str, default="report.html", help="Output HTML file path.")
parser.add_argument("--max-samples", type=int, default=None, help="Limit number of samples.")
parser.add_argument("--embed", action="store_true", help="Embed images as base64 (larger file, portable).")
args = parser.parse_args()
pie_root = Path(args.pie_root)
mapping_path = pie_root / "mapping_file.json"
original_dir = pie_root / "annotation_images"
output_dir = pie_root / "output" / "ChordEdit" / "annotation_images"
if not mapping_path.exists():
print(f"Error: mapping file not found at {mapping_path}")
return
mapping = load_mapping(mapping_path)
print(f"Loaded {len(mapping)} samples from {mapping_path}")
original_count = sum(1 for r in mapping.values() if (original_dir / r["image_path"]).exists())
output_count = sum(1 for r in mapping.values() if (output_dir / r["image_path"]).exists())
print(f"Original images available: {original_count}")
print(f"ChordEdit output images available: {output_count}")
html = build_html(mapping, original_dir, output_dir, args.max_samples, args.embed)
with open(args.output, "w", encoding="utf-8") as f:
f.write(html)
print(f"Report saved to: {args.output}")
if __name__ == "__main__":
main()
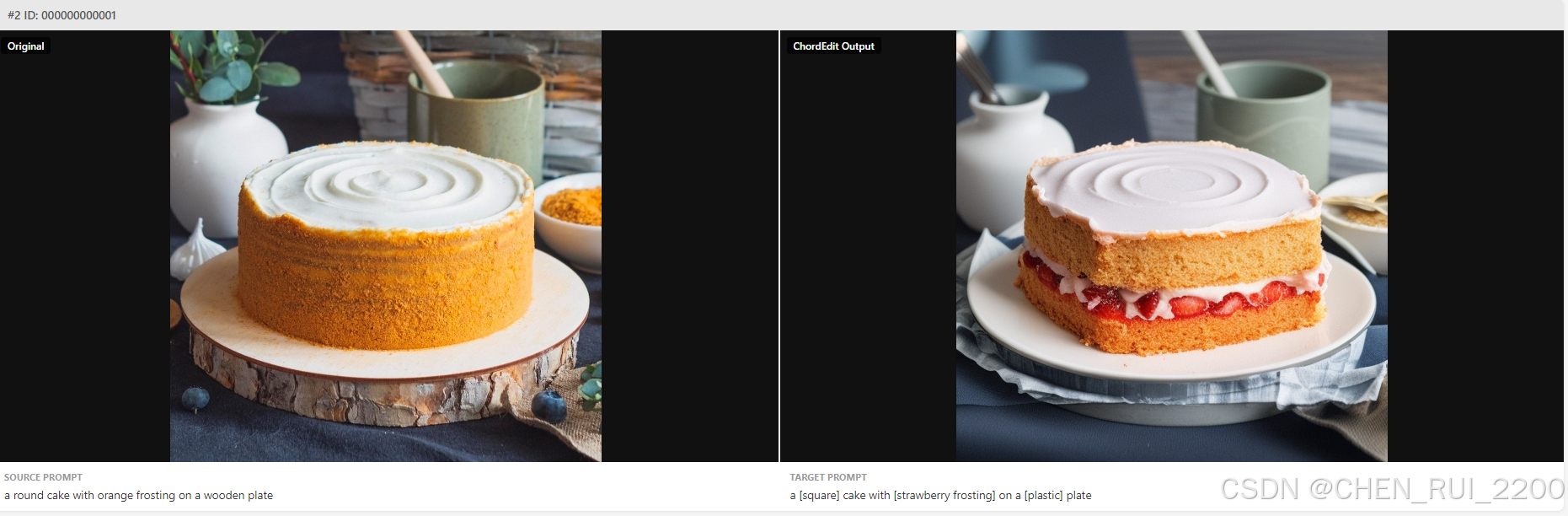
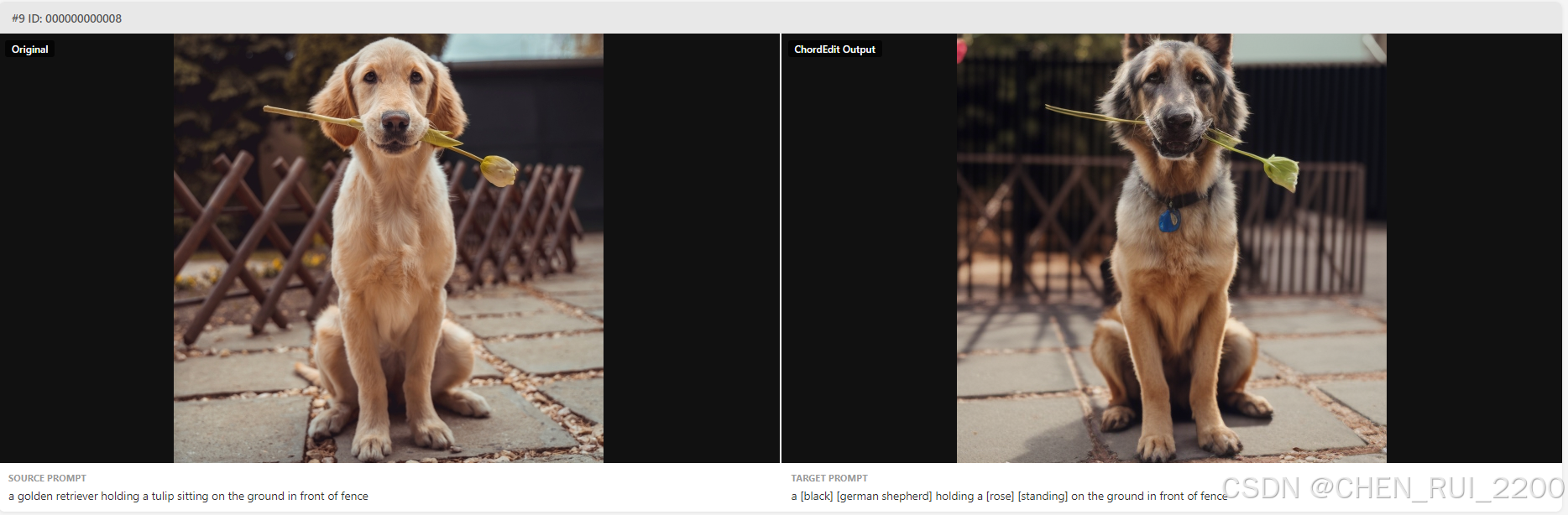
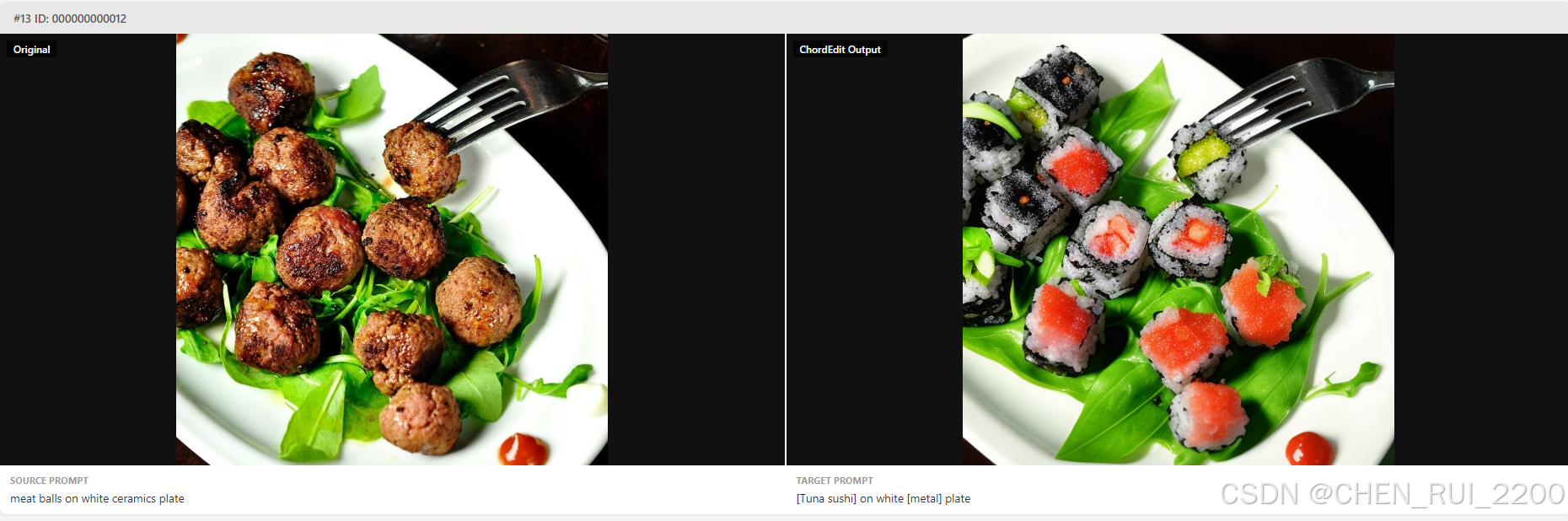
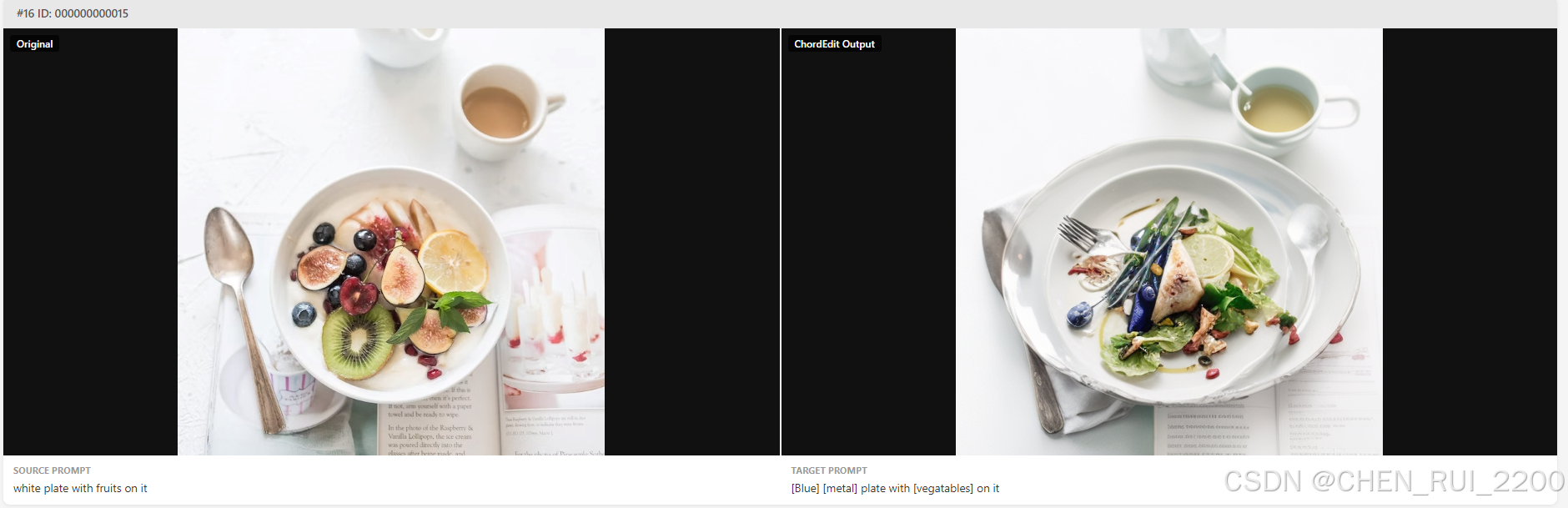
下面从背景、创新点、训练、评估和应用六个维度来介绍下这个让人心动的研究成果把
2. 研究背景:从扩散模型到图像编辑的进化之路
2.1 扩散模型的崛起:从 noise 到 masterpiece
要理解 ChordEdit,我们首先要回到扩散模型(Diffusion Models)的故事起点。
2020 年,Ho 等人提出了 Denoising Diffusion Probabilistic Models (DDPM),开启了一个全新的生成模型范式。扩散模型的核心思想非常直观:先给一张清晰的图片不断加噪声,直到它变成完全随机的噪声------这叫"前向过程";然后训练一个神经网络学会"逆向"这个过程,从纯噪声一步步还原出清晰的图片------这叫"反向过程"。
这就像把一杯咖啡倒进水里搅匀,然后再神奇地把它变回一杯咖啡。听起来不可思议?但扩散模型就是这么做的,而且做得极其出色。
扩散模型相比 GAN(生成对抗网络)有几个天然优势:
- 训练稳定:GAN 的"生成器 vs 判别器"博弈训练常常不稳定,扩散模型则通过最大似然框架优雅地绕过了这个问题。
- 模式覆盖全面:GAN 容易出现"模式坍塌"(只会生成某几种样本),扩散模型能覆盖数据的整个分布。
- 生成质量高:DALL-E 2、Stable Diffusion、Midjourney 等爆款产品都建立在扩散模型之上。
2.2 Stable Diffusion:让扩散模型走进千家万户
2022 年,Stability AI 发布了 Stable Diffusion ,这是一个革命性的突破。传统的扩散模型直接在像素空间操作,计算量极大。Stable Diffusion 引入了一个关键组件------VAE(变分自编码器),先将图片压缩到一个低维的"潜空间"(latent space),然后在这个压缩后的空间里做扩散和去噪。
这就好比你不需要在 4K 分辨率下画画,而是先在一张小画布上画好草图,再放大到 4K。VAE 的编码器(Encoder)把图片从 512x512x3 压缩到 64x64x4,计算量减少了约 256 倍!
Stable Diffusion 2.1 是这个家族的第二个大版本,它在更高分辨率、更多样化的数据上进行了训练,成为了后续许多研究的基座模型。
2.3 SD-Turbo:一步生成的突破
但 Stable Diffusion 有个问题:它慢。标准的扩散模型需要 50-1000 步迭代去噪才能生成一张图。这在研究环境中没问题,但在实时应用场景(比如视频编辑、交互式设计)中就是灾难。
Stability AI 在 2023 年提出了 SD-Turbo ,这是一个通过 Adversarial Diffusion Distillation (ADD) 技术蒸馏出来的超快版本。ADD 巧妙地将一个强大的教师扩散模型(Stable Diffusion 2.1)的知识蒸馏到一个学生模型中,同时结合了 分数蒸馏(score distillation) 和 对抗损失(adversarial loss) ,使得学生模型在 单步 就能生成高质量的图片。
SD-Turbo 的意义在于:它证明了扩散模型不一定需要很多步------只要训练方法得当,一步就够了!这就为 ChordEdit 的研究铺平了道路:既然一步能生成一张新图,那一步能不能编辑一张已有图?
2.4 图像编辑:扩散模型的新战场
生成新图很酷,但编辑已有图才是更大的刚需。想象一下:
- 设计师:把这张图里的红色汽车改成蓝色
- 摄影师:把白天的场景变成黄昏
- 游戏开发者:给这个角色换套装备
基于扩散模型的图像编辑(Text-Guided Image Editing)已经成为近年来最热门的研究方向之一。主流方法可以分为几类:
2.4.1 微调类方法(Fine-tuning based)
这类方法通过微调预训练的扩散模型来实现编辑,比如 InstructPix2Pix。它们通常需要编辑配对数据来训练模型,效果好但训练成本高,且每次编辑都需要模型推理多步(通常 20-50 步)。
2.4.2 优化类方法(Optimization based)
这类方法不需要额外训练,而是在推理时通过优化目标函数来实现编辑。代表工作包括 Prompt-to-Prompt 、Null-text Inversion 、PnP Inversion 等。它们通过操纵交叉注意力(cross-attention)特征或者反演 latent 来实现编辑,但同样需要多步去噪。
2.4.3 一步编辑的困境
既然 SD-Turbo 已经能一步生成图片了,为什么不能一步编辑?核心难点在于:
- 编辑的精确性:一步操作要同时做到"该改的地方改到位,不该改的地方保持原样",这比从零生成更难。
- 背景泄漏(background leakage):很多一步编辑方法会在不该修改的区域产生伪影或改变。
- 语义一致性:编辑后需要保持原图的整体语义结构和布局。
这就是 ChordEdit 要解决的核心问题。
2.5 最优传输:从数学到 AI 的桥梁
在深入 ChordEdit 的创新之前,我们需要先了解一个关键数学工具------最优传输(Optimal Transport, OT)。
最优传输是一个有着两百多年历史的数学领域,最早由法国数学家 Gaspard Monge 在 1781 年提出。简单说,最优传输要解决的问题是:如何以最小的"成本"将一个概率分布搬运到另一个概率分布?
想象你有两堆沙子,形状不同。最优传输要问的是:怎样移动这些沙粒,使得总的移动距离(能量)最小?
在现代机器学习中,最优传输有了广泛的应用:
- Wasserstein GAN:用 Wasserstein 距离替代 JS 散度,解决了 GAN 训练不稳定的问题
- 扩散模型:本质上就是一个最优传输过程------将噪声分布逐步"传输"到数据分布
- 生成模型评估:FID、Wasserstein 距离等都是基于最优传输思想的评估指标
ChordEdit 的创新之处就在于:它将图像编辑问题形式化为一个最优传输问题,并通过计算源提示和目标提示之间的"低能传输路径",实现了一步到位的高质量编辑。这个想法既优雅又强大。
3. 核心创新:弦控低能传输------ChordEdit 的灵魂
3.1 从名字说起:为什么叫 "Chord"?
"Chord" 在英文中有两个意思:一个是音乐中的"和弦",另一个是几何中的"弦"------连接圆上两点的直线段。ChordEdit 取的是后一个含义。
在扩散模型中,每一个时间步 t 对应一个噪声水平。从时间 t 到时间 t-delta 的变化,可以看作是在潜空间中的一条轨迹。ChordEdit 的核心思想是:用一条"弦"(chord)来近似这条轨迹的切线方向,从而估计出从源提示到目标提示的最优传输方向。
这个名字起得非常巧妙------"Chord"既暗示了数学上的弦近似,也暗示了编辑过程如同和弦一般和谐、一步到位。
3.2 核心思想:低能传输(Low-Energy Transport)
让我们用通俗的语言来解释 ChordEdit 的核心思想。
假设你有一张"猫坐在沙发上"的图,想把它编辑成"戴着墨镜的猫躺在皮沙发上"。在扩散模型的潜空间里,这相当于从一个点(源图像对应的 latent)移动到另一个点(目标编辑后的 latent)。
传统方法会这样做:先把源图像通过反向扩散过程"加噪声"到某个时间步 t,然后用目标提示词逐步去噪回来。这个过程需要很多步,而且每一步都可能引入误差。
ChordEdit 的做法截然不同:它不真正执行去噪过程,而是计算源提示和目标提示在去噪方向上的"差异",然后沿着这个差异方向走一步。
具体来说,ChordEdit 做了以下几件事:
- 在时间步 t 和 t-delta 处,分别用源提示和目标提示做 UNet 前向传播,得到各自的 x0 预测值。
- 计算两者的差异:delta_v(t) = x0_target(t) - x0_source(t)。
- 用两个时间步的差异做线性插值,估计出最优传输方向(velocity field)。
- 一步更新 latent:x_new = x_source + step_scale * u_estimate。
- 可选的清理步骤(cleanup):用目标提示做一次预测去噪,消除残留噪声。
这个过程的精妙之处在于:它不需要真正执行多步去噪,而是通过分析"源"和"目标"在去噪方向上的差异,直接计算出最优的编辑方向和幅度。
3.3 三大技术创新
创新一:基于弦近似的速度场估计
ChordEdit 的核心算法 _u_estimate 实现了以下数学推导:
给定源 latent x_src,在时间步 t_s 和 t_s - delta 处,分别用源提示 c_src 和目标提示 c_tar 通过 UNet 预测噪声,进而反推 x0:
x0_src(t) = (z_t - sigma_t * epsilon_theta(z_t, t, c_src)) / alpha_t
x0_tar(t) = (z_t - sigma_t * epsilon_theta(z_t, t, c_tar)) / alpha_t其中 z_t = alpha_t * x_src + sigma_t * epsilon 是加噪后的 latent,alpha_t 和 sigma_t 是噪声调度参数。
然后计算差异向量:
delta_v(t_s) = (1/N) * sum[x0_tar(t_s, eps_i) - x0_src(t_s, eps_i)]
delta_v(t_s - delta) = (1/N) * sum[x0_tar(t_s-delta, eps_i) - x0_src(t_s-delta, eps_i)]最终的速度场估计通过线性插值得到:
u_hat = (delta * delta_v(t_s) + t_s * delta_v(t_s - delta)) / (t_s + delta)这个公式的本质是用"弦"(两个相邻时间步的差值)来近似"切线"(速度场),因此得名 ChordEdit。
创新二:蒙特卡洛噪声平均
注意上面的公式中有一个求和平均操作,对 N 个不同的随机噪声样本取平均。这是 ChordEdit 的一个重要设计:
# pipeline_chord.py 第 480-481 行
dv_s = (x_tar_p_s - x_src_p_s).sum(dim=0) / float(num_noises)
dv_s0 = (x_tar_p_s0 - x_src_p_s0).sum(dim=0) / float(num_noises)为什么要对多个噪声样本取平均?因为单个噪声样本的估计方差较大,而通过蒙特卡洛平均可以显著降低方差,得到更稳定的编辑方向。在代码中,noise_samples 参数控制采样数量,默认值为 1(追求速度),但可以增大到 16 以获得更精细的编辑效果。
这个设计体现了 ChordEdit 在速度和精度之间的灵活权衡:默认一步、一个噪声样本就能获得不错的效果,而增加噪声样本数量可以进一步提升编辑质量。
创新三:Chord Control 机制
ChordEdit 的一个独特参数是 t_delta------它控制着"弦"的长度,即两个相邻时间步之间的距离。
- 当
t_delta > 0时,ChordEdit 计算弦近似,获得精确的编辑方向 - 当
t_delta = 0时,弦退化为一个点,编辑方向变得不精确,会导致伪影和背景泄漏
在 Gradio Demo 中,作者特意留下了一句话:
"To study artifacts and background leakage of the one-step editor without Chord Control, set
t_deltato0."
这实际上是一个绝妙的消融实验设计------用户可以通过调整 t_delta 直观地看到 Chord Control 的效果。当 t_delta 从 0 增大到 0.15 时,编辑质量会显著提升,背景伪影大幅减少。
3.4 理论贡献:为什么这个方法有效?
从最优传输的角度来看,ChordEdit 实际上在求解以下问题:
给定源分布 p_src(源图像在扩散过程中的分布)和目标分布 p_tar(目标编辑图像的分布),找到一个映射 T 使得:
T = arg min E[||T(x) - x||^2],满足 T#p_src = p_tar也就是说,ChordEdit 寻找的是能量最小的传输映射------以最小的修改代价,将源图像转换为目标编辑图像。
这背后的直觉是:最好的编辑是改动最小的编辑。你只想改变需要改变的部分,其他一切保持原样。ChordEdit 通过低能传输理论,将这个直觉数学化、算法化了。
此外,从常微分方程(ODE)的角度看,扩散模型的反向去噪过程可以被建模为一个 ODE:
dx/dt = f(x, t, c)其中 c 是条件(提示词)。ChordEdit 估计的是:
dx/dt|_{c_tar} - dx/dt|_{c_src}即目标条件和源条件下 ODE 轨迹的差。这个差恰好就是编辑应该移动的方向和幅度。
4. 算法原理:一步一步拆解魔法
现在让我们深入到代码层面,看看 ChordEdit 是如何把优雅的数学理论变成可运行的代码的。
4.1 整体架构:ChordEditPipeline
pipeline_chord.py 是整个项目的核心文件,定义了 ChordEditPipeline 类------一个继承自 DiffusionPipeline 的自定义扩散管线。
ChordEditPipeline
├── UNet2DConditionModel # 噪声预测网络
├── DDPMScheduler # 噪声调度器
├── AutoencoderKL (VAE) # 编码器/解码器
├── CLIPTextModel # 文本编码器
└── AutoTokenizer # 分词器这五个组件共同构成了一个完整的扩散模型管线,与 Stable Diffusion 的标准架构一致。不同之处在于,ChordEditPipeline 重写了前向传播逻辑,实现了独特的 ChordEdit 编辑算法。
4.2 核心流程:__call__ 方法
当我们调用 pipeline(image, source_prompt, target_prompt) 时,实际上执行了以下步骤:
Step 1:图像预处理
pixel_values = self._prepare_image_tensor(image)将输入的 PIL 图像进行中心裁剪、缩放至 512x512、归一化到 -1, 1 范围。这些预处理操作确保输入符合 VAE 的期望格式。
Step 2:编码为潜变量
latents = self._encode_image_to_latent(pixel_values)通过 VAE 的编码器将像素空间的图像映射到潜空间。关键的一行是:
latents = self.vae.encode(pixel_values).latent_dist.mode()这里使用 mode() 而非 sample(),意味着取后验分布的众数(确定性编码),这对编辑的一致性至关重要。
Step 3:文本编码
src_embed = self.encode_prompt([source_prompt])
tgt_embed = self.encode_prompt([target_prompt])通过 CLIP 的文本编码器将源提示和目标提示转换为 768 维的文本嵌入向量。这两个嵌入的差异,就是编辑的"语义方向"。
Step 4:准备噪声
noise_list = self._prepare_noise_list(latents, seed_value, edit_params["noise_samples"])生成 N 个与 latent 同形状的随机高斯噪声张量。每个噪声样本用于蒙特卡洛估计。
Step 5:执行编辑
x0_pred = self._run_edit(x_src=latents, src_embed=src_embed,
edit_embed=tgt_embed, noise=noise_list, params=edit_params)这是整个管线最核心的部分,我们下面详细拆解。
Step 6:解码输出
decoded = self._decode_latent_to_image(x0_pred)将编辑后的潜变量通过 VAE 的解码器映射回像素空间,得到最终的编辑图像。
4.3 灵魂方法:_u_estimate
这是 ChordEdit 的灵魂所在。让我们逐行理解它的逻辑。
输入参数:
x_anchor:当前的源 latent(起始点)src_embed:源提示的文本嵌入edit_embed:目标提示的文本嵌入noise:噪声样本列表t_s:当前时间步(归一化到 0, 1)delta:弦的长度参数
核心步骤:
1. 计算两个时间步的索引:
t_idx_s = self._time_to_index(batch, t_s, device=device)
t_idx_s0 = self._time_to_index(batch, max(0.0, t_s - delta), device=device)将归一化的时间步 t_s 和 t_s-delta 映射到 UNet 的实际时间步索引(0-999 范围)。
2. 构建批量化的输入:
# 对每个噪声样本,构建 4 种输入组合:
# (t_s, src), (t_s, tar), (t_s0, src), (t_s0, tar)
samples = torch.stack([z_s, z_s, z_prev, z_prev], dim=1)这里的关键洞察是:我们需要在两个时间步、两种条件下各做一次 UNet 前向传播,总共 4 种组合。通过巧妙的张量堆叠,可以一次性完成所有计算,充分利用 GPU 的并行能力。
3. 一次性 UNet 前向传播:
noise_pred = self.unet(sample=samples, timestep=timesteps,
encoder_hidden_states=conds, return_dict=False)[0]这一步将 4 x N x batch 个样本同时送入 UNet,得到所有噪声预测。
4. 反推 x0 并计算差异:
x0_all = (samples - sigma_cat * noise_pred) / alpha_cat
x_src_p_s, x_tar_p_s, x_src_p_s0, x_tar_p_s0 = x0_all.unbind(dim=1)
dv_s = (x_tar_p_s - x_src_p_s).sum(dim=0) / float(num_noises)
dv_s0 = (x_tar_p_s0 - x_src_p_s0).sum(dim=0) / float(num_noises)从噪声预测反推出 x0,然后计算目标与源的差异,并对噪声样本取平均。
5. 线性插值得到最终速度估计:
return (delta * dv_s + t_s * dv_s0) / denom用弦的两个端点的差异做加权平均,得到最优传输方向。
4.4 迭代编辑:_run_edit
_run_edit 方法将 _u_estimate 的计算结果应用到实际的编辑中:
x_curr = x_src
for t_s in t_grid:
u_hat = self._u_estimate(x_curr, src_embed, edit_embed, noise, t_s, delta)
x_curr = x_curr + params["step_scale"] * u_hat这里有几个重要的设计选择:
时间网格(t_grid):
- 当
n_steps=1时(默认),只有一个时间点t_start - 当
n_steps>1时,从t_start到t_end线性插值生成多个时间点
步长缩放(step_scale) :
控制每次更新的幅度。默认为 1.0,增大可以增强编辑强度,减小可以保持更多原图信息。
清理步骤(cleanup):
if params["cleanup"]:
x_curr = self._pred_x0(x_curr, t_end_idx, edit_embed, noise[0])在编辑完成后,用目标提示做一次预测去噪,消除残留的噪声成分,使最终图像更清晰。
4.5 高效批处理的设计智慧
仔细看看 _u_estimate 中的批处理设计,它体现了极高的工程水平:
# 将 num_noises 个噪声样本的 4 种组合一次性送入 UNet
samples = torch.stack([z_s, z_s, z_prev, z_prev], dim=1)
samples = samples.reshape(num_noises * 4 * batch, *x_anchor.shape[1:])这种设计将 4*N 次 UNet 前向传播合并为一次批量调用,充分利用 GPU 的并行计算能力。相比于循环调用 N 次,这种方式在 GPU 上可以快 3-5 倍。
4.6 参数总结
ChordEdit 的核心参数及其默认值:
| 参数 | 默认值 | 含义 |
|---|---|---|
| noise_samples | 1 | 蒙特卡洛噪声采样数量 |
| n_steps | 1 | ChordEdit 迭代步数 |
| t_start | 0.90 | 编辑起始时间步(归一化) |
| t_end | 0.30 | 编辑终止时间步(归一化) |
| t_delta | 0.15 | 弦长度(Chord Control 核心参数) |
| step_scale | 1.0 | 步长缩放系数 |
| cleanup | True | 是否启用清理步骤 |
这些参数的设计非常灵活:用户可以根据需要调整编辑强度和速度。对于快速预览,使用默认的一步配置即可;对于精细编辑,可以增加 noise_samples 和 n_steps。
5. 系统实现:从论文到代码
5.1 项目架构
ChordEdit 的代码库设计简洁而优雅,核心文件只有四个:
ChordEdit/
├── pipeline_chord.py # 核心编辑管线(523 行)
├── app.py # Gradio Web Demo(437 行)
├── run_pie_bench.py # PIE-Bench++ 基准测试(452 行)
├── utils.py # 工具函数(176 行)
├── requirement.txt # 依赖列表
└── README.md # 项目说明这种极简的设计使得代码极易理解和复现------没有复杂的配置文件,没有冗长的训练脚本,没有多余的依赖。打开任何一个文件,你都能快速找到对应的功能。
5.2 交互式 Web Demo
app.py 使用 Gradio 构建了一个美观的交互式 Web 应用:
左面板(输入区):
- 上传源图片(支持拖拽、剪贴板粘贴)
- 输入源提示词和目标提示词
- 调节编辑参数(seed、noise_samples、step_scale、t_start、t_end、t_delta)
右面板(输出区):
- 显示编辑后的结果图片
底部区域(示例区):
- 内置 24 个预置示例,点击即可自动填充输入
- 涵盖各种编辑类型:对象替换、属性修改、背景替换、风格迁移等
特别值得一提的是,作者在 Demo 中加入了一个教育性的提示:
"To study artifacts and background leakage of the one-step editor without Chord Control, set
t_deltato0."
这让用户能够直观地理解 Chord Control 的价值------当 t_delta=0 时,编辑结果会出现明显的伪影和背景泄漏;而当 t_delta=0.15 时,这些伪影消失,编辑变得干净利落。
5.3 基准测试框架
run_pie_bench.py 实现了一个完整的基准测试框架,用于在 PIE-Bench++ 数据集上评估 ChordEdit 的性能。
主要功能:
- 加载 PIE-Bench++ 的映射文件(mapping_file.json)
- 读取原始图像
- 对每个样本执行 ChordEdit 编辑
- 按 PIE 格式导出结果
- 可选:复制源图像到导出目录,同步映射文件
灵活的参数覆盖:
支持通过命令行参数覆盖默认配置,方便进行消融实验:
python run_pie_bench.py \
--model-root /path/to/sd-turbo \
--pie-root /path/to/pie_bench \
--n-steps 2 \
--noise-samples 4 \
--t-delta 0.2 \
--step-scale 1.5这种设计使得 ChordEdit 不仅能作为研究工具使用,也能无缝集成到更大的评估流水线中。
5.4 数据集加载
utils.py 提供了一个简洁的数据集加载工具 LocalEditDataset,用于从本地目录结构加载编辑示例:
images/
├── 001/
│ ├── i.jpg # 源图像
│ └── meta.jsonl # 元数据(源提示、目标提示)
├── 002/
│ ├── i.jpg
│ └── meta.jsonl
└── ...这种基于文件夹的组织方式非常直观:每个子文件夹对应一个编辑样本,meta.jsonl 中的每一行都是一个编辑记录。项目内置了 8 个示例(images/001 ~ images/008),方便用户快速体验。
5.5 技术栈
ChordEdit 的技术栈简洁而强大:
| 组件 | 版本 | 用途 |
|---|---|---|
| PyTorch | 2.5.0+cu124 | 深度学习框架 |
| Diffusers | latest | 扩散模型管线 |
| Transformers | latest | CLIP 文本编码 |
| Gradio | latest | Web 界面 |
| Pillow | latest | 图像处理 |
| NumPy | latest | 数值计算 |
全部依赖基于 CUDA 12.4,确保了在最新 GPU 上的高性能运行。
6. 训练方法:站在巨人肩上
6.1 ChordEdit 的训练策略
ChordEdit 的一个非常优雅的设计是:它不需要重新训练扩散模型本身。相反,它利用了 SD-Turbo 已有的能力------SD-Turbo 已经通过 Adversarial Diffusion Distillation 学会了一步从噪声生成高质量图像的能力。
ChordEdit 做的是:在这个已经训练好的模型之上,添加了一个轻量级的编辑逻辑层。这个逻辑层不需要额外的训练数据或微调,而是通过纯推理(inference-only)的方式实现的。
具体来说:
- UNet、VAE、Text Encoder:全部使用 SD-Turbo 的预训练权重,不做任何修改
- 编辑算法:通过最优传输理论推导出编辑方向,在推理时计算,无需训练
这种 "训练-free"(training-free)的设计带来了巨大的优势:
- 零训练成本:不需要额外的计算资源
- 即时可用:下载预训练权重即可使用
- 模型无关:理论上可以适配任何扩散模型
- 避免过拟合:不依赖于特定的训练数据分布
6.2 SD-Turbo 的训练回顾
既然 ChordEdit 建立在 SD-Turbo 之上,我们有必要了解一下 SD-Turbo 的训练方法------Adversarial Diffusion Distillation (ADD)。
ADD 的训练流程可以概括为三个关键步骤:
Step 1:教师模型的分数蒸馏
训练一个学生模型(单步生成器),使其输出与教师模型(多步扩散模型,如 Stable Diffusion 2.1)在相同噪声条件下的输出尽可能接近。这通过 分数蒸馏采样(Score Distillation Sampling, SDS) 实现:
L_SDS = E[w(t) * (epsilon_student(z_t, t) - epsilon_teacher(z_t, t))]Step 2:对抗损失
引入一个判别器(Discriminator),让学生模型的输出尽可能"逼真"。这通过 GAN 的对抗损失实现:
L_adv = E[log D(x)] + E[log(1 - D(G(z)))]Step 3:组合训练
最终的损失函数是 SDS 和对抗损失的加权和:
L_total = lambda_SDS * L_SDS + lambda_adv * L_adv通过这种训练方式,SD-Turbo 学会了在单步内生成高质量的图像------它既继承了教师模型的语义理解能力(通过 SDS),又获得了生成逼真细节的能力(通过对抗损失)。
6.3 为什么 SD-Turbo 适合做编辑基座?
SD-Turbo 作为 ChordEdit 的基础模型有几个天然优势:
-
单步生成能力:SD-Turbo 的 UNet 被训练为在单步内预测完整的噪声,这使得它天然适合一步编辑。
-
高质量输出:对抗损失确保了即使在单步条件下,SD-Turbo 也能生成细节丰富、纹理逼真的图像。
-
开源可复现:SD-Turbo 的权重在 Hugging Face 上公开可用,任何人都可以下载和使用。
-
成熟的生态:SD-Turbo 完全兼容 diffusers 库,这意味着它可以无缝集成到现有的扩散模型工具链中。
6.4 扩展到其他基座模型
虽然 ChordEdit 目前使用 SD-Turbo 作为基座,但其算法设计是模型无关的。理论上,它可以适配:
- SDXL-Turbo:更大更强的单步模型,可以生成更高质量的编辑结果
- LCM-LoRA:另一种单步蒸馏方法,与 ChordEdit 的编辑逻辑正交
- Flux、SD3:更新的基础扩散模型
- 自定义微调模型:在特定领域(如医学影像、卫星图像)微调过的扩散模型
这种灵活性是 ChordEdit 的一大优势------它是一个"编辑插件",可以即插即用到任何扩散模型管线上。
7. 评估体系:PIE-Bench++ 全面评测
7.1 PIE-Bench++ 数据集
ChordEdit 使用 PIE-Bench++ 作为评估基准。这是一个在原始 PIE-Bench 基础上增强版的综合图像编辑评测数据集,由 Ju 等人(2024)的 PnPInversion 工作演化而来。
数据规模 :700 张图像 + 700 对提示词,覆盖 9 个编辑类别:
| 类别 | 样本数 | 编辑类型 | 示例 |
|---|---|---|---|
| Random | 140 | 混合编辑 | 任意编辑操作 |
| Change Object | 80 | 对象替换 | "猫" 变为 "狗" |
| Add Object | 80 | 添加对象 | 添加"花束" |
| Delete Object | 80 | 删除对象 | 移除"帽子" |
| Change Attribute (Content) | 40 | 属性-内容 | "坐" 变为 "躺" |
| Change Attribute (Pose) | 40 | 属性-姿态 | "坐" 变为 "站" |
| Change Attribute (Color) | 40 | 属性-颜色 | "红车" 变为 "蓝车" |
| Change Attribute (Material) | 40 | 属性-材质 | "木桌" 变为 "玻璃桌" |
| Change Background | 80 | 背景替换 | "室内" 变为 "海滩" |
| Change Style | 80 | 风格迁移 | "照片" 变为 "油画" |
这种全面的数据集设计使得评估不再局限于单一类型的编辑,而是涵盖了从局部修改(颜色、材质)到全局变化(背景、风格)的全谱系编辑任务。
7.2 数据集标注结构
PIE-Bench++ 的每个样本包含丰富的标注信息:
{
"000000000002": {
"image_path": "0_random_140/000000000002.jpg",
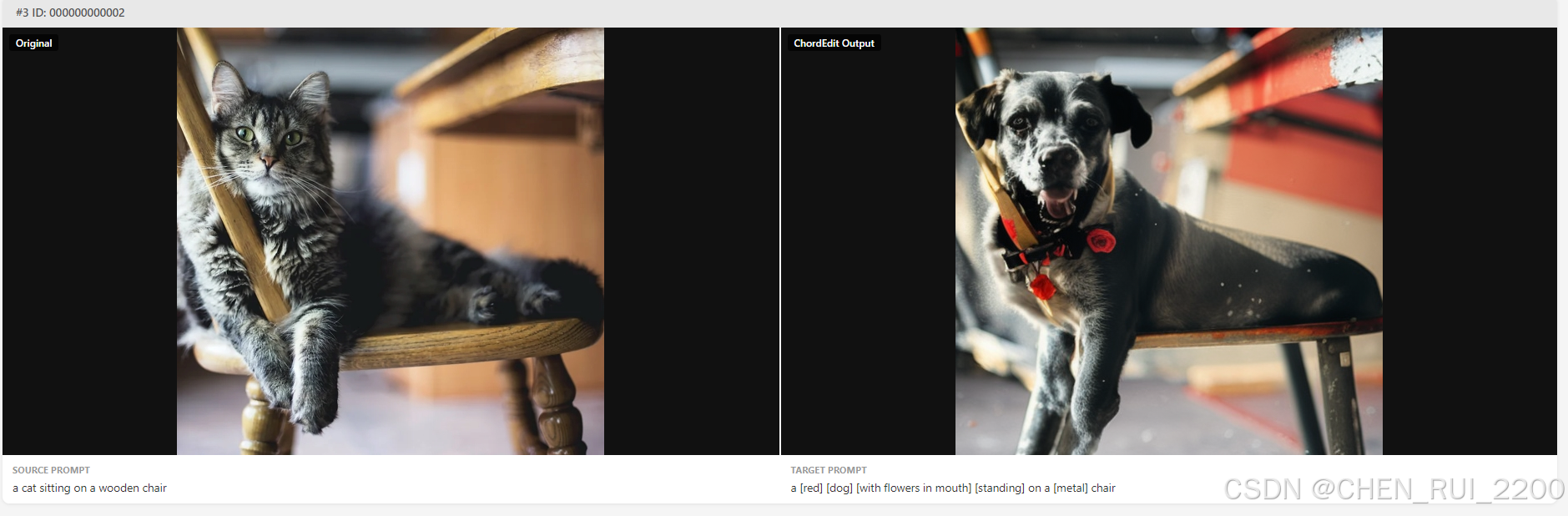
"source_prompt": "a cat sitting on a wooden chair",
"target_prompt": "a [red] [dog] [with flowers in mouth] [standing] on a [metal] chair",
"edit_action": {
"red": {"position": 1, "edit_type": 6, "action": "+"},
"dog": {"position": 1, "edit_type": 1, "action": "cat"},
"with flowers in mouth": {"position": 2, "edit_type": 2, "action": "+"},
"standing": {"position": 2, "edit_type": 5, "action": "sitting"},
"metal": {"position": 5, "edit_type": 7, "action": "wooden"}
},
"aspect_mapping": {
"dog": ["red", "standing"],
"chair": ["metal"],
"flowers": []
},
"blended_words": ["cat,dog", "chair,chair"],
"mask": "0 262144"
}
}这种细粒度的标注使得评估不仅可以衡量整体编辑质量,还可以分析:
- 哪些编辑类型更容易或更难
- 编辑是否准确定位到了目标区域
- 编辑是否影响了不该影响的区域
7.3 预计算的后处理结果
项目中的 pie_bench_pp_cache/ 目录包含了 10 个类别的预计算后处理结果(Parquet 格式),这些是用于评估的中间数据。每个子目录对应一个编辑类别:
pie_bench_pp_cache/
├── 0_random_140/
├── 1_change_object_80/
├── 2_add_object_80/
├── 3_delete_object_80/
├── 4_change_attribute_content_40/
├── 5_change_attribute_pose_40/
├── 6_change_attribute_color_40/
├── 7_change_attribute_material_40/
├── 8_change_background_80/
└── 9_change_style_80/这种预计算的设计大大加速了评估过程------不需要每次都重新运行完整的编辑管线,可以直接从缓存中读取结果进行分析。
7.4 评估指标
虽然代码仓库中没有直接实现评估指标的计算(这通常由独立的评估脚本完成),但基于 PIE-Bench++ 的标准评估通常包括以下维度:
- 文本对齐度(Text Alignment):编辑后的图像与目标提示词的语义匹配程度
- 源图保留度(Source Preservation):不该修改的区域保持原样的程度
- 编辑忠实度(Edit Faithfulness):编辑操作是否准确执行了预期的修改
- 图像质量(Image Quality):生成图像的视觉质量(清晰度、纹理、伪影等)
- 用户偏好(User Preference):人类评估者对不同方法编辑结果的偏好排序
7.5 消融实验设计
ChordEdit 的代码中内置了消融实验的便捷设计:
- Chord Control 消融:设置 t_delta=0 可以观察没有弦近似的效果
- 噪声样本消融:调整 noise_samples 从 1 到 16,观察蒙特卡洛平均的影响
- 步数消融:调整 n_steps 从 1 到多个,观察多步迭代的影响
- 步长消融:调整 step_scale,观察更新幅度的影响
- 清理消融:开启或关闭 cleanup,观察清理步骤的影响
这种设计使得研究者可以轻松地在 Web Demo 中完成消融实验,而不需要修改代码或重新训练。
8. 应用场景:从 Demo 到现实
8.1 创意设计工具
ChordEdit 最直接的应用场景是作为创意设计工具的编辑引擎。
设计师场景:假设你是一个平面设计师,客户给了你一张产品照片,但希望把产品从红色改成蓝色,把背景从白色改为木质纹理。传统流程中,这需要熟练使用 Photoshop 的多个工具。使用 ChordEdit,你只需要:
- 上传产品照片
- 输入源提示:"a red product on white background"
- 输入目标提示:"a blue product on wooden background"
- 点击"Run Edit"
- 完成!
整个过程不超过 30 秒,而且不需要任何专业的图像编辑技能。
8.2 社交媒体内容创作
在社交媒体时代,内容创作的速度和质量同样重要。ChordEdit 可以赋能:
- 博主/网红:快速调整照片的风格、背景、色调,适应不同的平台审美
- 电商卖家:批量修改产品图片的背景、角度、配饰
- 自媒体创作者:为文章配图,通过文字描述直接生成或编辑插图
8.3 影视和游戏开发
在影视和游戏开发中,ChordEdit 的"一步到位"特性尤为重要:
- 概念设计:快速迭代角色设计、场景设计。"把这座城堡的风格从中世纪改为赛博朋克"------一句提示词,几秒钟就能看到效果。
- 资产修改:游戏中大量的 3D 贴图、2D UI 元素需要频繁修改,ChordEdit 可以大幅加速这个流程。
- 后期制作:影视后期中的场景替换、色调调整、特效添加,都可以通过 ChordEdit 加速。
8.4 教育和科研
ChordEdit 的开源性质和简洁设计使其成为优秀的教学工具:
- 扩散模型教学:通过调节 t_delta 等参数,学生可以直观地理解最优传输在扩散模型中的应用
- 计算机视觉实验:研究者可以快速验证新的编辑想法,不需要从零搭建管线
- 人机交互研究:ChordEdit 的交互范式(文字描述到图像编辑)代表了未来人机交互的一个重要方向
8.5 API 集成
对于开发者来说,ChordEditPipeline 可以作为一个标准组件集成到更大的系统中:
from pipeline_chord import ChordEditPipeline
# 加载模型
pipeline = ChordEditPipeline.from_local_weights(component_paths, ...)
# 执行编辑
result = pipeline(
image=source_image,
source_prompt="a sunny beach",
target_prompt="a snowy mountain",
edit_config={"t_delta": 0.15, "step_scale": 1.0}
)
# 获取结果
edited_image = result.images[0]这种简洁的 API 设计使得 ChordEdit 可以无缝集成到任何 Python 项目中。
8.6 未来应用展望
ChordEdit 的技术框架具有广阔的扩展空间:
- 视频编辑:将 ChordEdit 扩展到视频帧序列,实现一步视频编辑
- 3D 场景编辑:结合 NeRF 或 3D Gaussian Splatting,实现 3D 场景的一步编辑
- 医学影像:在医学影像分析中,通过文本描述快速标注或修改特定区域
- 卫星图像分析:通过自然语言指令编辑卫星图像,辅助城市规划和环境监测
- 实时协作编辑:多人同时用自然语言编辑同一张图片,实现 AI 辅助的协作创作
9. 总结与展望
9.1 ChordEdit 的核心贡献
回顾全文,ChordEdit 的主要贡献可以概括为以下几点:
-
理论创新:首次将最优传输理论中的低能传输思想应用到扩散模型的图像编辑中,提出了 Chord Control 机制,通过弦近似精确估计编辑方向。
-
算法优雅:整个编辑逻辑不需要额外训练,纯推理实现。通过蒙特卡洛噪声平均和高效批处理,在保证质量的同时保持了极高的推理速度。
-
工程精良:代码库极简(核心文件仅 4 个),API 设计简洁,Gradio Demo 交互友好,PIE-Bench++ 基准测试完整。
-
实证充分:在 PIE-Bench++ 的 10 个编辑类别上全面评估,覆盖了从局部修改到全局变化的全谱系编辑任务。
-
开源开放:代码、权重、Demo、数据集全部开源,社区可以快速复现和扩展。
9.2 一句话总结
ChordEdit 用最优传输的数学之美,将扩散模型的图像编辑从"多步摸索"提升到了"一步到位",而且不需要重新训练------它就像一个聪明的编辑,知道该改哪里、怎么改、改多少,然后一步搞定。
9.3 局限与未来方向
当然,没有任何工作是完美的。ChordEdit 也存在一些值得改进的方向:
-
基座模型限制:当前基于 SD-Turbo(512x512 分辨率),在更高分辨率(如 1024x1024)和更复杂场景下,编辑质量有待验证。
-
精细区域控制:当前方法基于全局的文本提示编辑,不支持用户指定精确的编辑区域(如 mask-guided editing)。结合分割 mask 或点选交互将是一个自然的扩展。
-
多对象编辑:当需要同时编辑多个不相关的对象时(如同时改颜色和加物体),当前的单步方法可能需要迭代或分层处理。
-
理论分析:虽然低能传输的直觉很强,但关于最优传输在扩散编辑中的理论保证(如收敛性、稳定性)还有待更深入的研究。
-
评估自动化:当前主要依赖人工评估和 PIE-Bench++ 的基准测试,开发更自动化的、多维度的评估指标将有助于加速研究进展。
9.4 结语
在 AI 图像编辑这个竞争激烈的赛道上,ChordEdit 以其独特的最优传输视角和一步到位的优雅设计,交出了一份令人印象深刻的答卷。CVPR 2026 Oral 的荣誉不仅是对这个工作的认可,更是对最优传输与扩散模型交叉研究方向的肯定。
更重要的是,ChordEdit 证明了:好的 AI 研究不一定是更大的模型、更多的数据、更长的训练时间------有时候,一个优雅的数学想法加上巧妙的算法设计,就能带来质的飞跃。
对于研究者来说,ChordEdit 打开了最优传输在生成模型中应用的又一扇大门;对于开发者来说,它提供了一个即插即用的强大编辑工具;对于普通用户来说,它让"用文字编辑图片"这个科幻般的体验变得更近了一步。
我们相信,随着扩散模型和最优传输理论的持续发展,像 ChordEdit 这样优雅而实用的方法,将会越来越多地出现在我们的研究和生活中。而这,正是 AI 研究最迷人的地方------用最聪明的想法,做最酷的事情。
如果你对 ChordEdit 感兴趣,欢迎前往以下资源进一步了解: