论文标题: Compute Only Once: UG-Separated TokenMixer for Efficient Large Recommendation Models
论文链接: arXiv 2602.10455
论文作者: Hui Lu、Zheng Chai、Shipeng Bai、Hao Zhang、Zhifang Fan、Kunmin Bai、Ke Sun、Yingwen Wu、Bingzheng Wei、Xiang Sun、Ziyan Gong、Tianyi Liu、Hua Chen、Deping Xie、Zhongkai Chen、Zhiliang Guo、Qiwei Chen、Yuchao Zheng
一句话总结: UG-Sep 把 TokenMixer 中可复用的用户侧 token 与候选侧 token 显式隔离,让用户侧 PertokenFFN 在同一请求内只算一次,并用信息补偿与 W8A16 量化把线上延迟降低到 11.5%--22.0%。
背景与动机
大规模推荐模型沿着更宽、更深、更长序列扩展后,密集特征交互模型的主要瓶颈变成线上推理成本。长序列模型可以用用户级聚合或 KV Cache 复用用户历史表示;TokenMixer、RankMixer、TokenMixer-Large 这类 dense interaction 架构在每一层都把 user-side 与 group/item-side 特征混在一起,候选 item 一变,用户侧计算也要跟着重算。
本文要解决的问题很直接:在不破坏 TokenMixer 表达能力的前提下,把用户侧计算从"每个候选都算一遍"改成"同一个用户只算一次"。UG-Sep 的做法是把 token 流拆成 U-token 与 G-token,强约束 U-token 不接收 G 信息,因此 U-token 对不同候选 item 不变,可以在请求内缓存复用。
整体架构
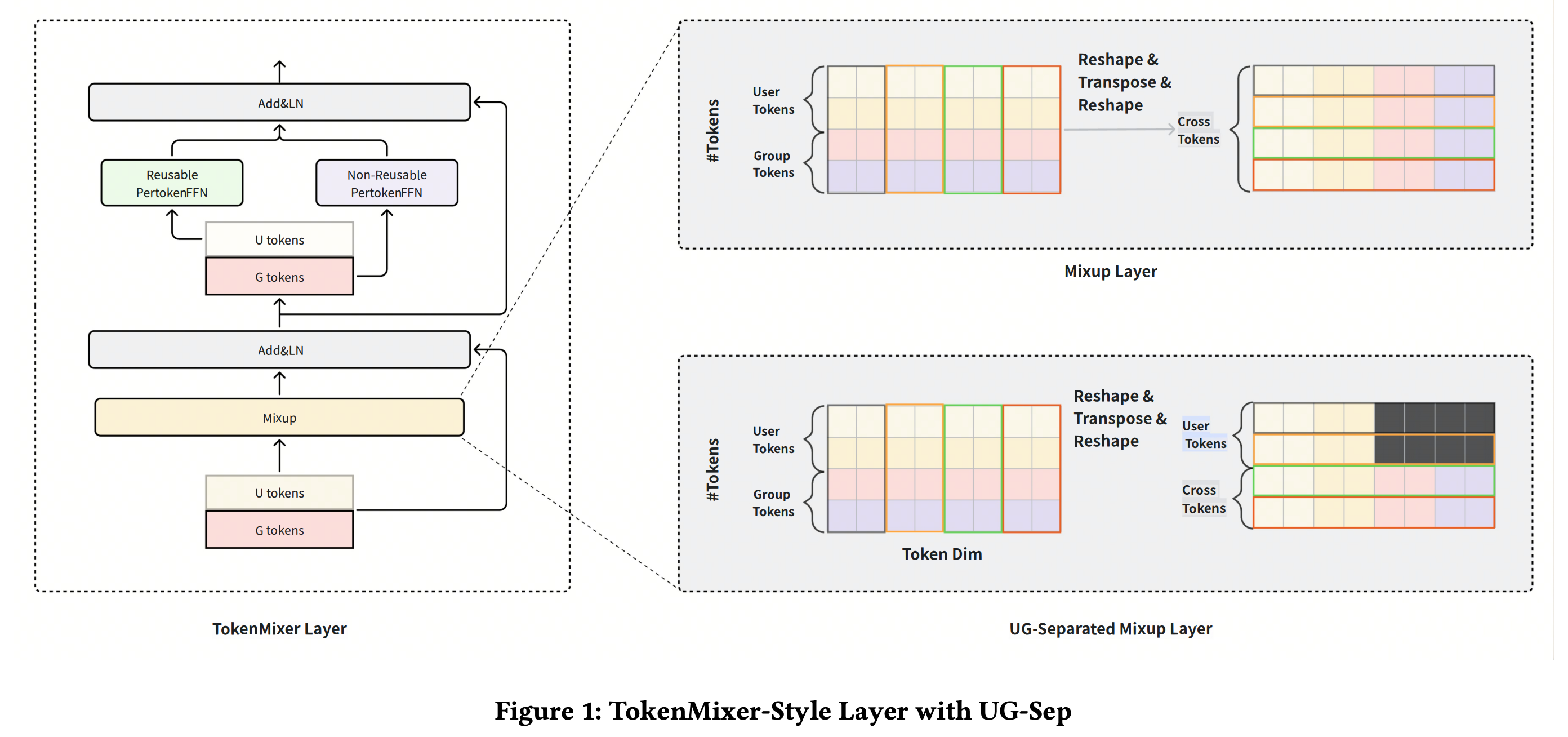
端到端数据流:底层特征抽取先把特征拆成 U-side 与 G-side 两支;TokenMixer 的 Mixup 层对 token 进行 reshape、transpose 与重组;UG-Sep 在 Mixup 后用 mask 去掉 U-token 中来自 G-token 的维度;PertokenFFN 被拆成 Reusable 与 Non-Reusable 两部分;线上 serving 时,Reusable PertokenFFN 的 U-token 输出按用户缓存,G-token 仍按候选 item 计算。
核心约束只有一条:U-token 可以影响 G-token,但 G-token 不能反向污染 U-token。这样 U-token 才能跨候选复用。
逐模块方案拆解
U/G token 底层分离
模块作用:在进入 TokenMixer 之前,把只含用户信息的 token 与含候选信息的 token 分开。
输入:原始用户特征、候选 item/group 特征、交叉特征;输出:X ∈ R^{B×T×D},其中 T=n+m。
X = C o n c a t ( x u 0 , x u 1 , ... , x u , n − 1 , x g 0 , x g 1 , ... , x g , m − 1 ) X=\mathrm{Concat}(x_{u0}, x_{u1}, \ldots, x_{u,n-1}, x_{g0}, x_{g1}, \ldots, x_{g,m-1}) X=Concat(xu0,xu1,...,xu,n−1,xg0,xg1,...,xg,m−1)
变量说明:
-
B:batch size,论文公式中省略 batch 维;实际张量可写成X ∈ R^{B×T×D}。 -
T:token 总数,T=n+m。 -
D:每个 token 的 hidden dimension。 -
x_u ∈ R^{B×1×D}:U-side token,只包含用户侧信息。 -
x_g ∈ R^{B×1×D}:G-side token,包含候选 group/item 信息,论文中 group 与 item 可互换。 -
n:U-token 数量;m:G-token 数量。
实现上,SENet、DCN 等特征抽取模块被拆为 U 分支和 G 分支;无法干净拆分的复杂结构,其输出统一归到 G-side,避免污染 U-token。
TokenMixer 基础层
模块作用:用 Mixup 做跨 token 维度交互,再用 PertokenFFN 做逐 token 非线性变换。
输入:第 k-1 个 block 输出 X_{k-1} ∈ R^{B×T×D};输出:第 k 个 block 输出 X_k ∈ R^{B×T×D}。
P k − 1 = L N ( M i x u p ( X k − 1 ) ) P_{k-1}=\mathrm{LN}(\mathrm{Mixup}(X_{k-1})) Pk−1=LN(Mixup(Xk−1))
X k = L N ( P F F N ( P k − 1 ) + X k − 1 ) X_k=\mathrm{LN}(\mathrm{PFFN}(P_{k-1})+X_{k-1}) Xk=LN(PFFN(Pk−1)+Xk−1)
变量说明:
-
X_{k-1} ∈ R^{B×T×D}:输入 token 表示。 -
P_{k-1} ∈ R^{B×T×D}:Mixup 后并经过 LayerNorm 的中间表示。 -
Mixup(·):多头 token mixing 模块,对 token 维与 hidden 维进行重排和拼接。 -
PFFN(·):Pertoken FeedForward Network,对每个 token 独立做前馈变换。 -
LN(·):LayerNorm。 -
X_k ∈ R^{B×T×D}:当前 TokenMixer block 输出。
UG-Separated Mixup 与 mask
模块作用:在 Mixup 之后强制 U-token 不含 G-side 信息,使 U-token 可复用。
Mixup 先把每个 token 切成 H 个 head,每个 head 维度为 D'=D/H。
S p l i t ( x u 0 ) = ( x u 0 0 , x u 0 1 , ... , x u 0 H − 1 ) \mathrm{Split}(x_{u0})=(x^0_{u0},x^1_{u0},\ldots,x^{H-1}_{u0}) Split(xu0)=(xu00,xu01,...,xu0H−1)
L h = C o n c a t ( x u 0 h , x u 1 h , ... , x g , T − 1 h ) , h ∈ 0 , H − 1 L^h=\mathrm{Concat}(x^h_{u0},x^h_{u1},\ldots,x^h_{g,T-1}),\quad h∈0,H-1 Lh=Concat(xu0h,xu1h,...,xg,T−1h),h∈0,H−1
M i x u p ( X ) = C o n c a t ( L 0 , L 1 , ... , L H − 1 ) \mathrm{Mixup}(X)=\mathrm{Concat}(L^0,L^1,\ldots,L^{H-1}) Mixup(X)=Concat(L0,L1,...,LH−1)
变量说明:
-
H:head 数量。 -
D'=D/H:单个 head 的维度。 -
x^h_{ui} ∈ R^{B×1×D'}:第i个 U-token 在第h个 head 上的切片。 -
x^h_{gi} ∈ R^{B×1×D'}:第i个 G-token 在第h个 head 上的切片。 -
L^h ∈ R^{B×1×(T·D')}:第h个 head 拼接后的新 token,原始 TokenMixer 中会同时含 U/G 信息。
论文假设 Mixup 后前 c_u 个 token 是 U-token,剩余 c_g 个 token 是 G-token,且 c_u+c_g=H。mask 定义为:
m a s k i , j = { 0 , i < c u , j > n ⋅ D ′ 1 , o t h e r w i s e mask_{i,j}=\begin{cases} 0,& i<c_u,\ j>n\cdot D'\\ 1,& otherwise \end{cases} maski,j={0,1,i<cu, j>n⋅D′otherwise
X m a s k e d = M i x u p ( X ) ⊙ b r o a d c a s t ( m a s k ) X_{masked}=\mathrm{Mixup}(X)\odot \mathrm{broadcast}(mask) Xmasked=Mixup(X)⊙broadcast(mask)
变量说明:
-
i ∈ [0,H-1]:Mixup 后 token/head 索引。 -
j ∈ [0,T·D']:拼接后 hidden 维索引。 -
c_u:Mixup 输出中划为 U-token 的数量。 -
c_g:Mixup 输出中划为 G-token 的数量。 -
n·D':U-side 信息在拼接维度中的边界;超过该边界的维度来自 G-side。 -
mask_{i,j}:二值掩码;当输出 token 属于 U-token 且维度来自 G-side 时置 0。 -
⊙:逐元素乘法。 -
X_{masked} ∈ R^{B×H×(T·D')}:mask 后的 Mixup 表示,前c_u个 token 不再含 G 信息。
mask 之后,PertokenFFN 被拆成两条路:U-token 走 Reusable PertokenFFN,G-token 走 Non-Reusable PertokenFFN。线上同一用户面对 C 个候选时,U-token 部分从 O(C) 降为 O(1)。
分离残差连接
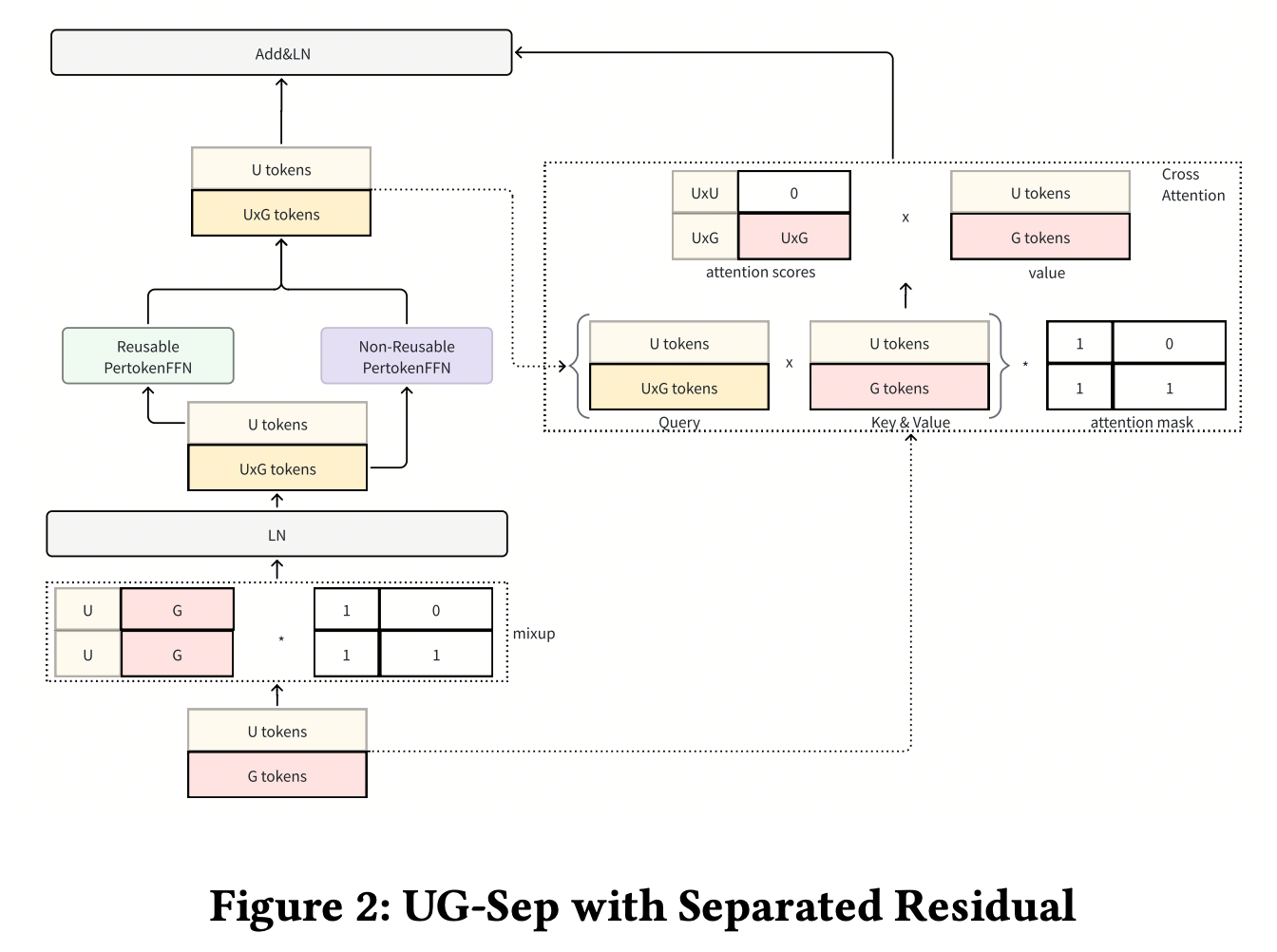
模块作用:在金字塔 TokenMixer 中保持 U/G 分离,同时允许输入 token 数与输出 token 数不一致。
问题点在于:金字塔结构会让输入 U-token 数 n 与 Mixup 输出 U-token 数 c_u 不相等,直接 residual add 可能把 G 信息带回 U-token。论文借鉴 cross-attention:Mixup+PFFN 的输出作为 Query,当前层输入 token 作为 Key/Value,并在 attention 中加入 UG mask。
Q = X m i x o u t , K = X i n , V = X i n Q = X^{out}_{mix},\quad K=X^{in},\quad V=X^{in} Q=Xmixout,K=Xin,V=Xin
R = A t t e n t i o n ( Q , K , V ; M U G ) R=\mathrm{Attention}(Q,K,V;M_{UG}) R=Attention(Q,K,V;MUG)
Y = X m i x o u t + R Y=X^{out}_{mix}+R Y=Xmixout+R
变量说明:
-
X^{in} ∈ R^{B×T_{in}×D}:当前 mixer 层输入 token。 -
X^{out}_{mix} ∈ R^{B×T_{out}×D}:Mixup 与 PFFN 后输出,T_out可小于T_in。 -
Q ∈ R^{B×T_{out}×D}:cross-attention query。 -
K,V ∈ R^{B×T_{in}×D}:cross-attention key/value。 -
M_{UG} ∈ {0,1}^{T_{out}×T_{in}}:UG attention mask;U 输出位置不能 attend 到 G 输入位置。 -
R ∈ R^{B×T_{out}×D}:受 mask 约束的 residual 信息。 -
Y ∈ R^{B×T_{out}×D}:分离残差后的输出。
信息补偿
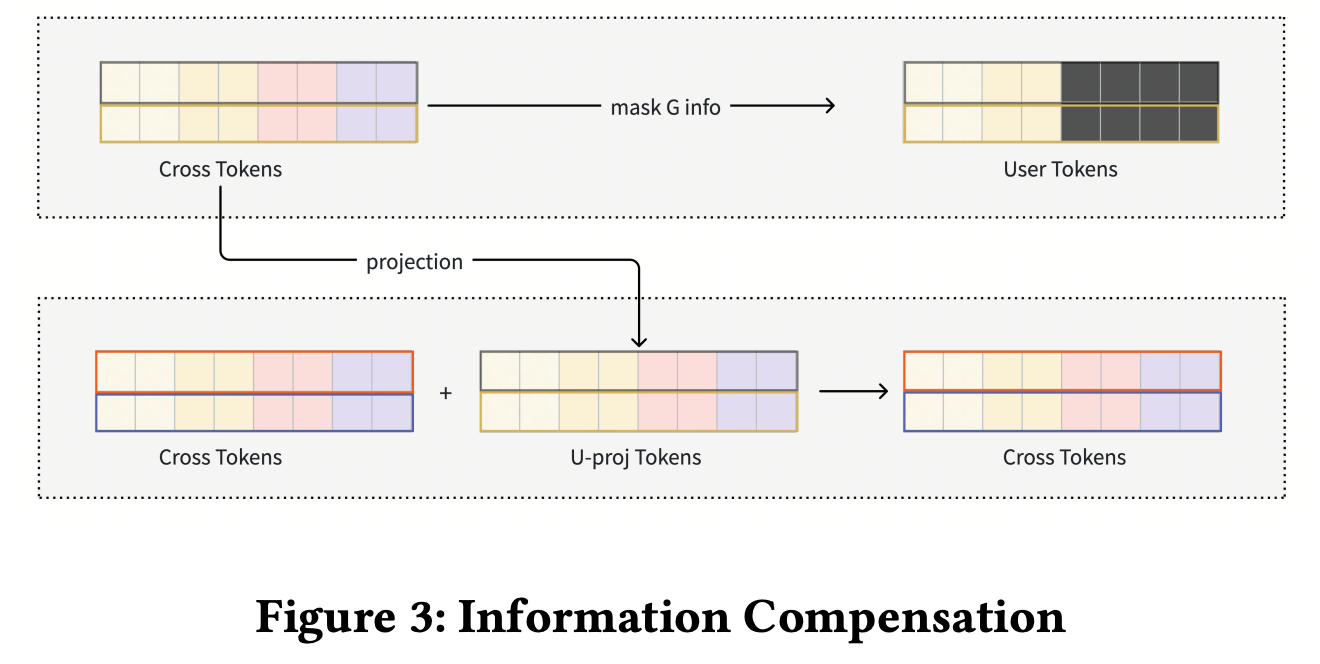
模块作用:UG mask 会切掉 U-token 中与 G-side 相关的维度;当 U:G 比例偏向 U-side 时,信息损失会明显放大。Information Compensation 把保留下来的 U 信息投影后加回 G-token,补偿 G-token 的上下文,同时不把 G 信息注入 U-token。
U ^ = P r o j ( U ) \hat U = \mathrm{Proj}(U) U^=Proj(U)
G c o m p = G + U ^ G_{comp}=G+\hat U Gcomp=G+U^
变量说明:
-
U ∈ R^{B×c_u×d}:Mixup 与 UG mask 后的 U-token 表示。 -
G ∈ R^{B×c_g×d}:对应的 G-token 表示。 -
Proj(·):可学习线性投影,把 U-side 表示映射到与 G-token 可相加的维度。 -
\hat U ∈ R^{B×c_g×d}:投影后的 U-side 补偿信息;若c_u与c_g不一致,投影需同时处理 token 数或通过实现中的映射对齐。 -
G_{comp} ∈ R^{B×c_g×d}:补偿后的 G-token。
这一路只做 U → G 的信息注入,不做 G → U 注入,因此不会破坏 U-token 的可复用性。
请求内 U-side 缓存
模块作用:在一次 ranking 请求里,把同一用户的 U-side 表示抽出来只跑一次 TokenMixer,再 repeat 回所有候选。
O f f s e t = C u m s u m ( c a n d i d a t e _ s i z e _ t e n s o r ) Offset=\mathrm{Cumsum}(candidate\_size\_tensor) Offset=Cumsum(candidate_size_tensor)
U n i q u e _ U = G a t h e r ( I N P U T _ U , O f f s e t ) Unique\_U=\mathrm{Gather}(INPUT\_U,Offset) Unique_U=Gather(INPUT_U,Offset)
U n i q u e _ U = T o k e n M i x e r ( U n i q u e _ U ) Unique\_U=\mathrm{TokenMixer}(Unique\_U) Unique_U=TokenMixer(Unique_U)
O U T P U T _ U = R e p e a t ( U n i q u e _ U , c a n d i d a t e _ s i z e _ t e n s o r ) OUTPUT\_U=\mathrm{Repeat}(Unique\_U,candidate\_size\_tensor) OUTPUT_U=Repeat(Unique_U,candidate_size_tensor)
变量说明:
-
candidate_size_tensor ∈ R^{M}:每个用户对应的候选 item 数,M为请求内用户数或聚合单元数。 -
INPUT_U ∈ R^{N×T_u×D}:展开到候选粒度后的 U-side 输入,N=Σ candidate_size_tensor。 -
Offset ∈ R^{M}:每个用户在展开样本中的代表位置。 -
Unique_U ∈ R^{M×T_u×D}:去重后的用户侧 token。 -
OUTPUT_U ∈ R^{N×T_u×D}:repeat 回候选粒度后的 U-side 输出。
W8A16 量化
模块作用:UG-Sep 降低 U-side FLOPs 后,部分算子从 compute-bound 转为 memory-bound;W8A16 通过 8-bit 权重、16-bit activation 降低权重加载带宽。
理论 FLOPs 降幅可近似写为:
r a t i o = c u c u + c g ratio=\frac{c_u}{c_u+c_g} ratio=cu+cgcu
变量说明:
-
ratio:U-side 可复用部分带来的 FLOPs 减少比例。 -
c_u:Mixup 输出中 U-token 数量。 -
c_g:Mixup 输出中 G-token 数量。 -
当
c_u=c_g时,理论 FLOPs 减少约 50%。
W8A16 是 weight-only quantization:权重以 FP8 存储,计算时片上反量化;activation 保持 16-bit。论文给出的内存流量收益是相对 FP32 最高 4×,相对 BF16 约 2×。
训练目标 / 损失函数
论文没有提出新的监督损失,也没有引入额外蒸馏或辅助目标。训练沿用各业务 baseline 的训练协议,UG-Sep 只改 TokenMixer 结构与 serving 复用方式。
可抽象为:
L = L t a s k ( y ^ , y ) \mathcal{L}=\mathcal{L}_{task}(\hat y,y) L=Ltask(y^,y)
变量说明:
-
\mathcal{L}_{task}:业务原始任务损失;论文评估覆盖 CTR/CVR/推荐排序等场景,但未展开各业务的具体 loss 形式。 -
\hat y ∈ R^{B×K}:模型预测,K为任务输出维度;二分类 CTR/CVR 场景可取K=1。 -
y ∈ R^{B×K}:监督标签。 -
B:训练 batch size。
训练变化主要来自样本组织与可复用计算:Douyin Feed Rec 使用 user-level sample aggregation,因此可评估训练加速;Hongguo、Chuanshanjia、Qianchuan 使用标准 instance-level 样本,论文只报告推理加速。
实验与分析
实验覆盖 4 个字节真实工业场景:Douyin Feed Recommendation、Hongguo Feed Recommendation、Chuanshanjia Ads、Qianchuan Ads。评价指标包括相对 AUC 变化、serving latency、Douyin 训练 speedup、W8A16 GEMM latency,以及线上 A/B 指标。
离线效果与推理延迟
| 场景 | U:G | ΔAUC | ΔLatency |
|---|---|---|---|
| Douyin Feed Rec | 1:2 | +0.002% | -- |
| Douyin Feed Rec | 1:1 | -0.004% | -20.0% |
| Douyin Feed Rec | 3:1 | -0.013% | -- |
| Hongguo Feed Rec | 1:1 | -0.018% | -11.5% |
| Hongguo Feed Rec | 5:3 | -0.015% | -- |
| Hongguo Feed Rec | 2:1 | -0.033% | -- |
| Chuanshanjia Ads | 1:1 | -0.016% | -12.7% |
| Chuanshanjia Ads | 5:3 | -0.026% | -- |
| Qianchuan Ads | 1:1 | -0.024% | -22.0% |
论文说明 0.01%--0.03% 的 AUC 下降已通过严格 A/B 验证,对线上表现几乎无影响。核心读法是:1:1 附近通常是稳定折中点,延迟收益明确,AUC 波动很小;U-token 比例过大时,AUC 可能下降更多,需要信息补偿兜底。
训练加速
| 模型 | U:G | Training Speedup |
|---|---|---|
| TokenMixer | -- | 0.0% |
| TokenMixer with UG-Sep | 1:2 | +5.50% |
| TokenMixer with UG-Sep | 1:1 | +8.60% |
| TokenMixer with UG-Sep | 3:1 | +14.8% |
Douyin 场景采用用户级样本聚合,U-side 计算复用能直接转化为训练吞吐收益。U-token 占比越高,训练加速越强;但 3:1 的 AUC 已出现更明显下降,因此不能只按吞吐选比例。
信息补偿消融
| U:G Ratio | Info Compensation | ΔAUC |
|---|---|---|
| 1:2 | N | +0.00% |
| 1:1 | N | -0.01% |
| 2:1 | N | -0.04% |
| 3:1 | N | -0.06% |
| 3:1 | Y | -0.02% |
| 5:1 | Y | -0.04% |
信息补偿的价值在高 U-token 比例时最明显:3:1 下 ΔAUC 从 -0.06% 恢复到 -0.02%。这说明 mask 切掉的 G 相关维度在 U 比例升高后不能只靠 residual 恢复,必须通过 U → G 的投影补偿把上下文加回 G-token。
W8A16 GEMM 延迟
| BS M N K | UG-Sep | UG-Sep + W8A16 |
|---|---|---|
| (1,16,1280,2560) | -- | -50.2% |
| (1,16,1280,640) | -- | -40.0% |
| (1,8,1280,2560) | -- | -46.8% |
| (1,8,1280,640) | -- | -55.0% |
W8A16 在 UG-Sep 后更有效,因为 UG-Sep 已经削掉大量计算,剩余瓶颈更偏向权重读取。表 4 中 GEMM 级延迟下降为 40.0%--55.0%。
线上 A/B
| Douyin 指标 | Change | p-value |
|---|---|---|
| Active Days | -0.0020% | 0.46 |
| Duration | +0.0056% | 0.45 |
| Like | -0.0511% | 0.34 |
| HLT | -0.0003% | 0.95 |
| Comment | -0.0923% | 0.18 |
| Latency | -20.0% | -- |
| Chuanshanjia 指标 | Change | p-value |
|---|---|---|
| Cost | -0.1143% | 0.45 |
| Rank Advv | -0.1322% | 0.42 |
| Advv Overall | -0.2042% | 0.32 |
| Latency | -12.7% | -- |
线上结果的核心是"指标无显著变化 + 延迟下降":Douyin 用户行为指标 p-value 均较高,Chuanshanjia 广告指标变化也低于 0.25%,论文将这些解释为统计不显著波动。
优势与局限
优势
-
首次把 TokenMixer 密集交互里的用户侧计算变成可复用计算: 原本 user 与 item 在每层深度混合,无法像长序列模型一样缓存;UG-Sep 通过 U/G token 隔离和 mask 让 U-token 跨候选稳定。
-
工程收益直接: Douyin、Hongguo、Chuanshanjia、Qianchuan 四个生产场景均有 serving latency 下降,范围为
11.5%--22.0%。 -
结构兼容性较强: 论文强调 UG-Sep 可集成到 TokenMixer 变体、Transformer-based 结构等交互架构,不要求重写主干设计。
-
补偿机制针对真实损失点: 当 U:G 倾斜时,信息补偿能显著缓解 AUC 下降。
-
量化与结构优化互补: UG-Sep 降 FLOPs 后暴露 memory-bound,W8A16 继续降低 GEMM 级延迟。
局限
-
依赖 U/G 可分性: 底层特征抽取需要拆分 U 分支与 G 分支;无法干净拆分的模块只能归为 G-side,可复用空间会受限。
-
U:G 比例需要业务调参: 高 U-token 比例能带来更大训练加速,但 AUC 下降风险同步增加;论文实验显示 1:1 或 1:2 更稳。
-
论文未公开绝对 AUC 与完整业务 loss: 出于商业保密,只报告相对 AUC 与线上指标变化,复现实验只能验证趋势,不能对齐绝对效果。
-
实验图形化结果较少: 论文核心证据主要是表格,缺少曲线型图表展示 latency、AUC 与 U:G ratio 的连续变化。