图 1:本文数据集与模型和已有工作之间的比较。
(a) 现有机器人导航数据集与本文数据集在环境面积上的比较。本文数据集包含大规模室外人群场景。
(b) 现有人群计数数据集与本文数据集在镜头交互性上的比较。本文数据集为每个场景提供 3D 结构环境,使智能体能够与环境交互。
© 传统人群计数模型与本文方法之间的比较。本文提出利用智能体导航,对此前未探索的远处区域进行精细检测。
https://arxiv.org/pdf/2503.08367v1
摘要
遮挡是人群计数中的根本挑战之一。研究界已经提出了多种数据驱动方法来处理这一问题,但效果仍然有限。主要原因在于,大多数现有人群计数数据集基于被动相机采集,训练在这些数据集上的方法难以充分感知环境。近年来,具身导航方法在交互式场景中的精确目标检测方面展现出显著潜力。这些方法采用主动相机设置,有望解决人群计数中的根本问题。然而,现有大多数方法是为室内导航设计的,在大规模场景中分析复杂目标分布(例如人群)的性能仍不明确。此外,现有大多数具身导航数据集都是规模和目标数量都有限的室内场景,无法直接引入密集人群分析。
基于这些观察,本文提出一个新的任务:具身人群计数(Embodied Crowd Counting,ECC)。我们首先构建了一个交互式模拟器,即具身人群计数数据集(Embodied Crowd Counting Dataset,ECCD),它支持大规模场景和大量目标。我们引入一种近似真实人群分布的先验概率分布来生成人群。随后,本文提出一种零样本导航方法 ZECC。该方法包含由多模态大语言模型(MLLM)驱动的粗到细导航机制,支持主动 Z 轴探索;同时包含一种基于法线的人群分布分析方法,用于精细计数。与基线方法的实验结果表明,所提出方法在计数精度和导航成本之间取得了最佳折中。
1. 引言
人群计数对于公共安全和城市规划至关重要 21。该领域的一个主要挑战是遮挡。遮挡可以分为两个方面:重叠和不可见。重叠指人群密度较高、个体相互堆叠,使得从某些视角难以区分每个人;不可见则表示当前相机位置受到阻挡,例如被建筑物遮挡,或距离人群过远以至于无法清晰检测目标。概括来说,这些情况都源于较差的观察点。
现有方法尝试从多个角度解决这些挑战,例如使用多尺度特征提取 20、身体部位检测 26 或多相机融合 49, 50。也有研究通过扩展数据集来提升方法性能 19, 36, 43, 51。总体而言,这些方法或数据集要么试图增强学习模型的表征能力,要么通过引入多视角设置来扩展相机感知范围。然而,它们的被动相机设置并不能从根本上解决人群计数中的遮挡挑战,尤其是当人群超出感知范围,或没有相机能够检测到完全被遮挡的人群时。这些问题限制了基于被动相机的方法在实际中的应用。
具身 AI 的最新发展为解决人群计数中的遮挡挑战提供了新的视角。具身方法已经被证明在增强场景探索和目标检测方面具有显著潜力。视觉-语言导航(Vision-Language-Navigation,VLN)等方向致力于赋予移动机器人类人感知能力,并在开放环境中的场景探索和目标检测任务上取得了显著效果 4, 7, 9, 52。VLN 中的主动相机设置有望解决人群计数中的根本挑战,因为它能够优化观察点,从而缓解由相机位置较差引起的重叠和不可见问题。然而,大多数 VLN 基准 1, 3, 40, 44 都是室内环境,探索空间有限(例如没有 Z 轴动作选项),目标数量也相对较少。此类方法在大规模场景中检测数量庞大、分布复杂的人群时性能仍不明确。这导致 VLN 与人群计数之间存在显著差距,因为在实际中,人群通常出现在大空间中,并具有不同的分布形态。
为解决上述问题,我们首先定义了一个新任务:具身人群计数(ECC)。该任务将人群计数整合到 VLN 中的零样本目标导航任务(Zero-shot Object-Goal Navigation,ZSON)28 中,面向具有大量目标的大规模场景。随后,我们为该任务开发了测试环境 ECCD。与现有人群计数和 VLN 数据集相比,该测试环境具有以下特征:
- 支持 60 个彼此不同且多样的大规模室外场景。每个场景面积最高可达 40,000 m2m^2m2,目标数量最高可达 15,000。
- 使用先验分布,即泊松点过程(Poisson Point Process)11,对人群数量分布建模,从而近似真实人群情况。
基于这一平台,我们提出了用于在 ECCD 中进行人群计数的方法:零样本具身人群计数(Zero-shot Embodied Crowd Counting,ZECC)。与现有人群计数方法和 VLN 方法相比,ZECC 具有以下特征:
- 它使用主动相机设置解决人群计数中的根本挑战,将检测任务转化为探索任务。
- 它包含一个粗到细导航机制,利用多模态大语言模型(MLLM)的常识分析周围环境并规划 Z 轴探索,借助六自由度(6-DoF)的优势避开低空障碍并获得边界视野,从而实现高效探索。
- 它包含一个人群分布分析机制,将复杂人群分布转化为简单表面。该方法利用表面的法线生成精细观察点,从而缓解重叠和不可见的影响,实现准确人群计数。
本文贡献可概括如下:
- 提出一种名为 ECC 的创新任务,专门用于处理传统人群计数方法中普遍存在的遮挡和多尺度复杂性挑战。
- 构建新的数据集 ECCD,用以重新定义人群分析的研究场景。不同于传统人群计数和 VLN 数据集,ECCD 具有可交互的大规模室外人群场景。
- 提出 ZECC,使用 MLLM 进行 Z 轴探索,在保证检测性能的同时降低成本。该方法通过法线计算导航点,消除人群中的重叠并增强可见性。
- 实验表明,所提出方法在多种测试环境中优于基线方法。
2. 相关工作
2.1 人群计数
人群计数算法显著受益于 UCF-CC50 18 和 UCF-QNRF 19 等大规模高质量数据集。这些基础数据集促进了后续聚焦密集人群图像的数据集构建,例如 ShanghaiTech 51、JHU-CROWD++ 36 和 NWPU-Crowd 43。然而,这些数据集中的图像由固定相机生成。相比之下,ECCD 在保持多样人群分布的同时提供交互能力。
一些方法 5, 20, 24, 24, 51 利用图像中的人群分布先验,或使用注意力图学习依赖关系。近期的多模态方法 10, 29, 42, 47 利用视觉-语言模型将图文知识迁移到密集人群预测中。虽然这些模型提升了长距离和重叠小目标的检测能力,但当重叠达到极端程度时,它们在实际中的性能仍受到限制。
近期工作也在扩展空间覆盖范围。例如,多视角系统 17, 32 使用多相机从更大规模的场景中捕获图像;其他工作 14, 15 使用录制视频进行人群分析。相对于单幅固定图像方法,这些研究在解决人群计数根本挑战方面具有重要意义,但其相机设置仍由数据集预先定义,并且在推理时无法调整。这无法保证在大环境中的充分探索。ZECC 支持主动探索,这与现有方法有根本区别。
2.2 具身导航
许多传统机器人导航方法基于 KITTI 12 和 SUN RGB-D 38 等常规导航数据集开发。除这些基础数据集外,33, 44 为导航与交互任务提供了 3D 室内环境。这些数据集受限于较小的场景规模和较少的目标数量。近期也出现了面向室外导航的数据集,例如 AerialVLN 25 和 CityNav 23。然而,它们是为 VLN 任务设计的,并未考虑目标数量。相比之下,ECCD 同时支持大规模室外场景、大量目标以及多样分布。
使用移动机器人进行高效探索仍然是视觉和机器人领域的重要挑战。13, 16, 30, 38 提出了类人认知地图,使机器人能够在未知环境中自主学习路径。其他方法 2, 6, 31 使用强化学习开发探索策略。近期,48 使用基于视频的视觉-语言模型来规划 VLN 中的连续动作;27, 53 则提出了零样本模型,使用自然语言指令引导智能体穿越环境,无需针对特定环境的预训练。然而,上述方法都面向室内导航,并且不具备 Z 轴移动能力,这限制了它们在大规模室外场景中的能力。近期方法 25, 45 在室外 VLN 中引入了 6-DoF,但它们面向指令跟随任务,移动受到人类语言限制。此外,这些方法缺乏分析数量庞大且分布复杂人群的能力。相比之下,ZECC 是首个可在 6-DoF 中自主动机探索并同时处理人群的智能体。
3. 方法
3.1 问题定义
为确保智能体能够与环境交互并在广阔室外环境中准确进行人群计数,本文提出一个创新任务:具身人群计数(ECC)。在 ECC 中,智能体首先被部署到未知环境中。在时间步 ttt,智能体的输入是 RGB-D 观测 OtO_tOt 及其位姿 ptp_tpt。基于这些信息,智能体在时间步 ttt 为无人机预测一个导航点 p∈R3p \in \mathbb{R}^3p∈R3,无人机随后移动到 ppp。
在探索过程中,智能体可以记录有助于人群计数的观测。当智能体决定停止时,它输出一个整数作为人群计数结果。计数误差和行驶距离被用于评估智能体性能。ECC 可以被视为与 ZSON 任务类似,因为两者都要求智能体在未知环境中检测目标,并且不依赖额外辅助。
然而,两者也存在若干差异。任务设置上的差异包括:
- ZSON 中的目标类别 GGG 在 ECC 中被限定为人群。
- ZSON 中的步数限制在 ECC 中被移除。
- ECC 中的评估标准改为计数误差和行驶距离。
这些差异并不妨碍近期 ZSON 方法通过少量修改应用于 ECC。然而,在 ECC 中,智能体还会面对本质差异:
- Z 轴可用,而大多数近期 ZSON 方法并未考虑这一点。
- 存在复杂人群分布,包括严重遮挡;而 ZSON 方法通常只考虑数量较少的目标。
当前 ZSON 方法在这些差异下的性能仍不明确,因此 ECC 需要新的方法。需要注意的是,ECC 不同于 25, 45 等 VLN 中的指令跟随任务,因为这些任务需要自然语言辅助来驱动智能体。
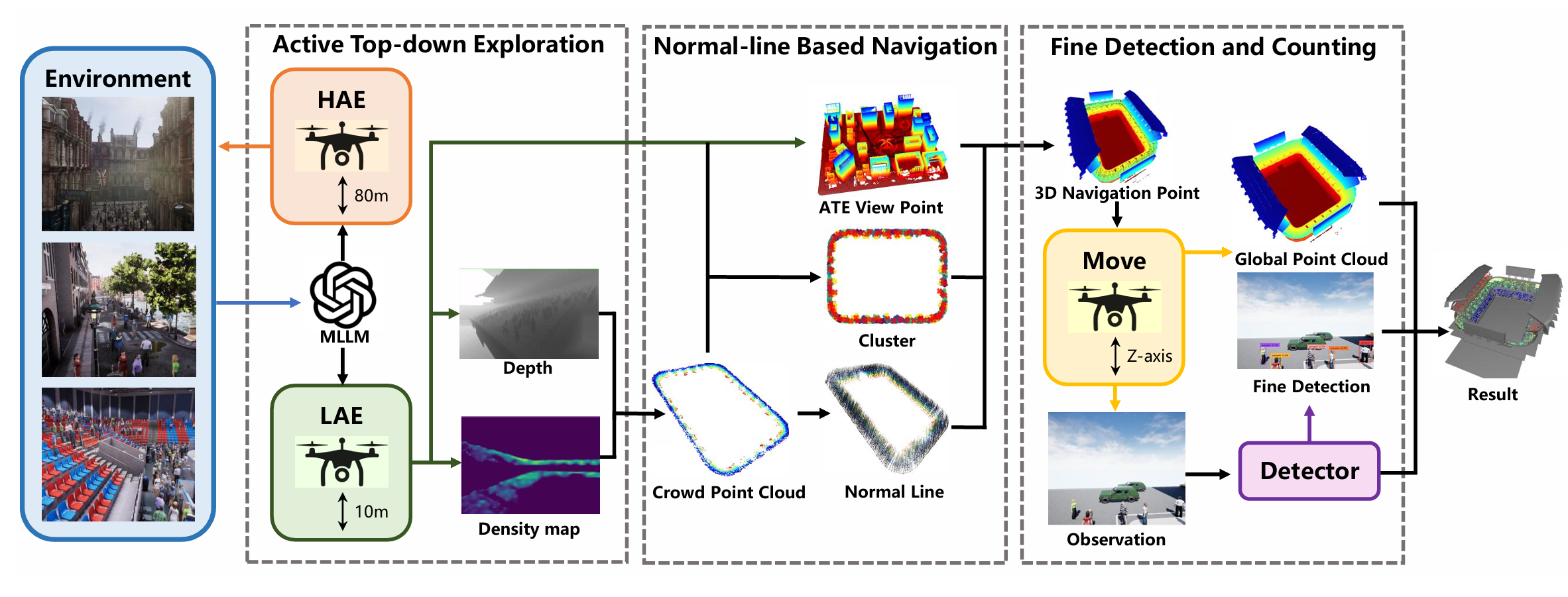
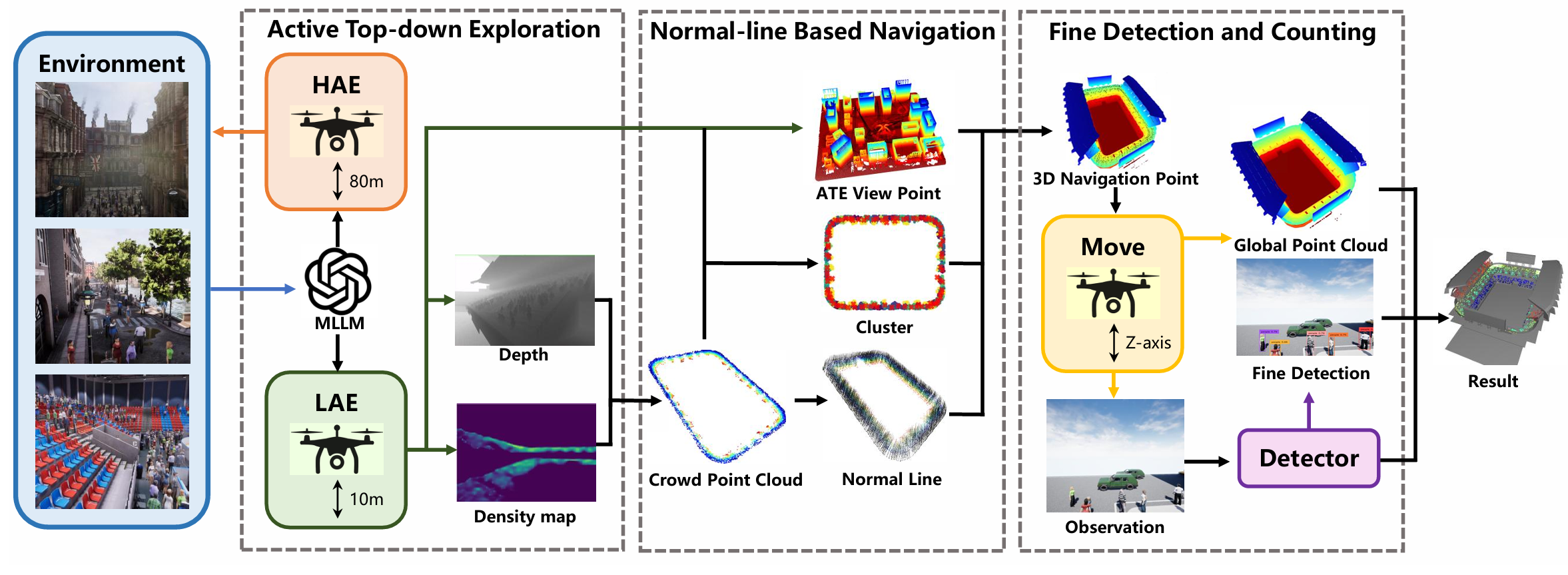
图 2:ZECC 框架。
该框架包含若干关键步骤。首先,基于 FBE 的探索策略被用于通过目标点云创建全局人群分布。随后,我们使用高斯混合模型(GMM)聚类来识别全局目标点云的代表中心,并基于潜在导航方向确定最终导航点。最后,我们将多个检测器获得的检测结果与深度观测整合,并映射到全局点云中。经过过滤后的目标数量被统计并记录为最终人群计数结果。
3.2 具身人群计数数据集(ECCD)
本文提出新的数据集 ECCD,以支持社区进行算法设计和评估。ECCD 使用 Unreal Engine 4 开发。该平台支持可编程环境构建,因而具备场景丰富性和可扩展性。ECCD 的特征如下。
多样性。 不同环境具有不同布局,人群分布和数量也反映不同挑战,因此 ECCD 被设计为包含多样场景。该数据集包含 60 个不同环境。ECCD 面积最高可达 40,000 m2m^2m2,高度最高可达 50 m,并允许单个场景中同时存在超过 15,000 个目标。这与现有机器人导航数据集显著不同,例如 33 的平均可导航空间为 1,000 m2m^2m2;也不同于人群计数数据集,例如 51 包含 1,198 张由静态相机采集的标注图像,共 330,165 个个体。
真实性。 为保证基于 ECCD 构建的系统具有实际有效性,ECCD 被设计为模拟真实世界中的大规模室外人群场景,如图 3 所示。数据集中模拟了城市、体育场、停车场等环境。此外,环境还支持现实生活中的复杂建筑结构,例如多层建筑和看台。这些特征使 ECCD 能够反映真实挑战。
人群生成机制。 为建模人群计数中的真实挑战,ECCD 使用泊松点过程对人群数量分布建模 11。在 ECCD 中,模拟器会放置区块来表示人群可能存在的潜在区域。对于每个区块 U⊂R2\mathcal{U} \subset \mathbb{R}^2U⊂R2,该过程定义为:
P(N(U)=k)=(λ⋅∣U∣)kk!e−λ⋅∣U∣,k∈N. \mathbb{P}\left(N(\mathcal{U}) = k\right) = \frac{(\lambda \cdot |\mathcal{U}|)^k}{k!} e^{-\lambda \cdot |\mathcal{U}|}, \quad k \in \mathbb{N}. P(N(U)=k)=k!(λ⋅∣U∣)ke−λ⋅∣U∣,k∈N.
其中,N(U)N(\mathcal{U})N(U) 表示区块 U\mathcal{U}U 中的个体数量,λ\lambdaλ 表示由人类专家根据环境语义设置的人群密度,∣U∣|\mathcal{U}|∣U∣ 是区块面积。这保证 ECCD 生成的人群近似真实情况。相比之下,AirVLN 和 OpenUAV 等基于 UE4 的现有模拟器并未考虑目标数量和分布。

图 3:ECCD 被设计为真实模拟建筑与人群分布。
左侧为 ECCD 样例,右侧为真实场景。
3.3 零样本具身人群计数(ZECC)
3.3.1 概述
以往具身导航智能体要么为室内环境设计 27,要么依赖语言辅助 25, 45,因此在大规模室外场景中受到限制。在这一背景下,本文提出 ZECC:一个能够主动控制高度并进行人群分析的零样本智能体。如图 2 所示,该方法包含两个组件:主动俯视探索(Active Top-down Exploration,ATE)和基于法线的导航(Normal-line based Navigation,NLBN)。ATE 用于调整智能体高度,以高效估计粗略人群分布;NLBN 用于在人群上方估计法线,从而获得准确的人群观察视角并缓解遮挡。
3.3.2 主动俯视探索(ATE)
人群通常集中在特定区域,例如道路和广场,因此没有必要探索环境中的每个区域。为此,本文提出 ATE,用于从高空估计人群的全局分布。该方法将探索集中在最相关区域,并避开不必要位置,从而提升效率。具体而言,高空探索(High-Altitude Exploration,HAE)为决策提供更宽广视野;同时,由于高空障碍物通常较少,高空探索的成本也相对更低。低空探索(Low-Altitude Exploration,LAE)则提供近距离观测,以实现清晰目标检测。智能体需要规划 HAE 和 LAE,以同时实现效率和精度。
因此,ATE 利用室外智能体的 Z 轴移动能力和多模态大语言模型(MLLM)的常识,通过对局部环境布局进行推理,在 HAE 与 LAE 之间切换。随后,系统使用人群计数模型预测环境中的密度图,以估计人群分布。
具体而言,智能体在时间步 ttt 收集观测 Ot={ot1,...,otc}O_t=\{o_t^1,\ldots,o_t^c\}Ot={ot1,...,otc} 和位姿 ptp_tpt,其中 ccc 表示智能体的相机数量。随后,使用观测和文本提示驱动 MLLM 进行环境布局推理。MLLM 被要求根据当前人群外观和障碍物布局,预测当前位置是否值得进行 LAE。该过程表示为:
st=MLLM({Ot;I}), s_t = \operatorname{MLLM}\left(\{O_t; I\}\right), st=MLLM({Ot;I}),
其中,MLLM(⋅)\operatorname{MLLM}(\cdot)MLLM(⋅) 表示推理过程,III 是提示词,st∈0,1s_t \in 0,1st∈0,1。如果 st>0.5s_t > 0.5st>0.5,智能体将调整高度进行 LAE。切换高度策略后,智能体将执行常规探索。对于 HAE,系统选择已探索区域和未知区域边界上的一个 frontier 作为导航点。对于 LAE,智能体将持续探索 frontier,直到其在 HAE 期间视野内的区域被完全探索。
在 LAE 期间,当智能体到达 frontier fff 时,它收集观测 Of={of1,...,ofc}O_f=\{o_f^1,\ldots,o_f^c\}Of={of1,...,ofc},并由人群计数模型在观测上预测人群密度图。随后,密度图被投影到全局点云中,形成全局人群分布。该过程表示为:
df=P(G(Of),pf), d_f = \operatorname{P}\left(\operatorname{G}(O_f), p_f\right), df=P(G(Of),pf),
其中,P(⋅)\operatorname{P}(\cdot)P(⋅) 是投影操作,G(⋅)\operatorname{G}(\cdot)G(⋅) 是人群计数模型,pfp_fpf 是智能体在 fff 处的位姿。
3.3.3 基于法线的导航(NLBN)
NLBN 用于精确分析人群中的潜在重叠结构。其直觉在于:虽然随机视角通常会使密集人群中的可见性受阻,但仍存在若干有利观察点能够为识别个体提供清晰视野。这些观察点应位于人群上方,并与人群中心保持一定角度,因为俯视视角能够区分重叠,而特定角度的视角可以确保目标处于智能体视野(FOV)内。
为找到此类观察点,NLBN 将人群检测任务转化为表面检测任务。通过拟合人群分布表面,可以获得表面的法线;再利用法线,可以准确计算满足上述约束的观察点。
在 ATE 获得全局人群分布后,NLBN 首先使用聚类方法将人群点云划分为子区域。这一步将大规模人群点云划分为易处理的部分,因为导航到每个导航点都可能消耗资源。随后,根据点云数据为这些子区域拟合表面并获得法线。该过程将困难的人群分析任务转化为更易处理的表面分析任务。最后,系统基于法线生成优化后的导航点,确保导航点与人群表面保持一定距离和角度,以实现准确人群检测。系统还采用基于视点的方法确认所选导航点不会与障碍物重叠。
具体而言,本文使用 GMM 35 将全局人群分布划分为可处理的子区域。GMM 能够确保分布中的每个采样点都被分配到一个簇,因此可以将任意人群分布划分为若干 patch。参数 ξ\xiξ 用于确定每个 GMM 簇的大小。
生成簇及其中心后,系统为每个 patch 拟合表面。对于第 NNN 个簇,获得的法线表示为 dNcluster\mathbf{d}^{\text{cluster}}NdNcluster。在角度约束下采样候选视角方向 {dN1view,...,dNmview}N\{\mathbf{d}^{\text{view}}{N1}, \ldots, \mathbf{d}^{\text{view}}_{Nm}\}_N{dN1view,...,dNmview}N:
dNcluster⋅dNmview∥dNcluster∥∥dNmview∥=ζ, \frac{\mathbf{d}N^{\text{cluster}} \cdot \mathbf{d}{Nm}^{\text{view}}} {\|\mathbf{d}N^{\text{cluster}}\| \|\mathbf{d}{Nm}^{\text{view}}\|} = \zeta, ∥dNcluster∥∥dNmview∥dNcluster⋅dNmview=ζ,
其中 ζ\zetaζ 是超参数。这些候选视角方向可以通过沿向量选择一个位置,将智能体带到优化后的观察点。然而这里存在两个问题:
- 该位置可能位于障碍物上。
- 人群簇可能不在智能体的 FOV 内。
为解决这些问题并从潜在导航点中确定最终导航点,本文提出一种简单而有效的技术。在 ATE 过程中,计数模型识别出的每个簇点都至少对应智能体的一个视点。连接视点和目标点的向量能够可靠指示可导航空间,因为光线传播天然指向无遮挡区域。此外,该向量也能保证人群位于 FOV 内,因为目标图像已经在 ATE 期间被识别。基于这一先验,本文使用 ATE 视点生成最终导航点。ATE 视角向量计算为:
dNATE=xNATE−xNcluster, \mathbf{d}_N^{\text{ATE}} = \mathbf{x}_N^{\text{ATE}} - \mathbf{x}_N^{\text{cluster}}, dNATE=xNATE−xNcluster,
其中,xNATE\mathbf{x}_N^{\text{ATE}}xNATE 是智能体在 ATE 期间发现簇中心 xNcluster\mathbf{x}_N^{\text{cluster}}xNcluster 时所在的导航点。随后,选择与 ATE 视角向量夹角最小的潜在导航方向作为最终导航方向:
dNview=argminmdNATE⋅dNmview∥dNATE∥∥dNmview∥, \mathbf{d}_N^{\text{view}} = \arg\min_m \frac{\mathbf{d}N^{\text{ATE}} \cdot \mathbf{d}{Nm}^{\text{view}}} {\|\mathbf{d}N^{\text{ATE}}\| \|\mathbf{d}{Nm}^{\text{view}}\|}, dNview=argmmin∥dNATE∥∥dNmview∥dNATE⋅dNmview,
最终导航点 xNview\mathbf{x}_N^{\text{view}}xNview 计算为:
xNview=xNcluster+η⋅dNview, \mathbf{x}_N^{\text{view}} = \mathbf{x}_N^{\text{cluster}} + \eta \cdot \mathbf{d}_N^{\text{view}}, xNview=xNcluster+η⋅dNview,
其中,η\etaη 是表示智能体与人群簇之间距离的超参数。NLBN 即使在复杂且陌生的环境中,也能够保证近距离、精确目标观察和安全导航。潜在导航向量、法线和 ATE 视角向量如图 4 所示。
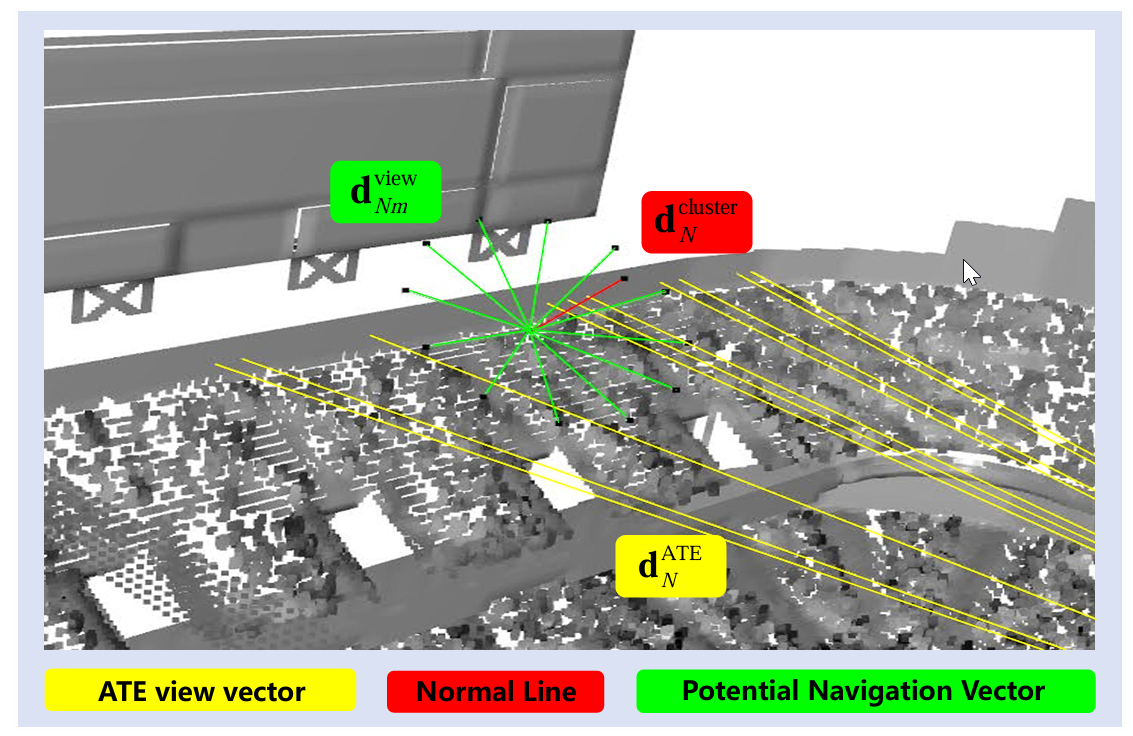
图 4:潜在导航向量、法线和 FBE 视角向量示意图。
可放大查看细节。
3.3.4 精细检测与计数(FDC)
利用 NLBN 生成的导航点,智能体通过路径规划算法从一个点移动到另一个点。到达每个导航点后,智能体可以进行近距离、高分辨率 RGB 观测。这些观测随后被输入检测模型,用于执行精确目标检测。检测结果结合深度传感器和智能体位姿被投影到全局点云中。为防止重复检测,系统只保留特定尺度内每个区域的一个目标。最终结果通过统计过滤后目标的数量得到。
4. 实验
4.1 设置
指标。 平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)被用于评估计数性能,定义为:
MAPE=1M∑i=1M∣yi−y^iyi∣×100%, \text{MAPE}=\frac{1}{M}\sum_{i=1}^{M}\left|\frac{y_i-\hat{y}_i}{y_i}\right|\times 100\%, MAPE=M1i=1∑M yiyi−y^i ×100%,
其中,MMM 是测试环境数量,y^i\hat{y}_iy^i 和 yiy_iyi 分别是在一个环境中的估计计数和真实计数。
相邻导航点之间沿智能体行驶路径的欧氏距离之和被用于评估行驶距离(Travel Distance,TD),定义为:
TD=∑i=1n−1∥xi+1−xi∥, \text{TD}=\sum_{i=1}^{n-1}\left\|\mathbf{x}{i+1}-\mathbf{x}{i}\right\|, TD=i=1∑n−1∥xi+1−xi∥,
其中,nnn 是一个 episode 中导航点的数量,xi\mathbf{x}ixi 和 xi+1\mathbf{x}{i+1}xi+1 分别是两个相邻导航点的坐标。
实现细节。 ATE 中使用的 MLLM 为 GPT-4V 46。路径规划方法为 A* 算法 37。HAE 的高度为 80 m,LAE 的高度为 10 m。ATE 中的人群密度估计器为 Generalized Loss(GL)41,FDC 中的检测模型为 Grounding DINO(GD)34。超参数方面,导航向量角度 ζ\zetaζ 为 15°,密度阈值 κ\kappaκ 为 0.7,导航点范围 η\etaη 为 8 m,簇大小 ξ\xiξ 为 40。
基线。 我们将 ZECC 与现有探索方法 Frontier-based Exploration(FBE)39 以及 SOTA ZSON 方法进行比较,包括 CoW 8 和 OpenFMNav 22。这些方法使用先进基础模型在导航过程中进行决策。为将基线应用于 ECC,本文移除了 ZSON 方法的探索步数限制,并为它们配备 GD 或 GL,通过 FDC 中的投影方法进行人群计数。
4.2 结果
总体性能。 表 1 报告了总体性能。ZECC 在计数性能和成本之间取得了最佳平衡。相比之下,FBE 的 TD 最优,但缺少目标检测功能,限制了其精细观察能力。这种不完整观察会对整体性能产生负面影响。CoW 和 OpenFMNav 等 ZSON 方法带有感知模块,但它们不像 NLBN 那样选择 3D 精细观察点,因此无法完整观察人群中的每个个体。这一限制会导致个体被重叠人群遮挡,尤其是在密度较高时。在某些情况下,这些方法只能识别单个个体,从而降低效率。相比之下,ZECC 使用 ATE 规划 Z 轴探索,并采用 NLBN 进行细致检测,从而提升了计数效率。
对于使用计数模型进行人群计数的智能体,其性能往往略低于使用检测模型的智能体。这是因为当智能体靠近人群时,人群观测会变得更稀疏。人群计数模型主要训练在密集人群图像上,因此对更稀疏场景的泛化能力有限。此外,当前 ZSON 方法并未考虑寻找用于人群观察的近距离位置,这进一步降低了性能。
表 1:各方法总体性能。 ZECC 在 MAPE 和 TD 之间取得最佳折中。
| 方法 | MAPE (%) | TD (m) |
|---|---|---|
| FBE 39 + GL 41 | 55.92 | 2227.71 |
| FBE 39 + GD 34 | 53.85 | 2227.71 |
| CoW 8 + GL 41 | 51.19 | 3271.07 |
| CoW 8 + GD 34 | 46.70 | 3271.07 |
| OpenFMNav 22 + GL 41 | 59.71 | 4936.79 |
| OpenFMNav 22 + GD 34 | 46.84 | 4936.79 |
| ZECC | 18.91 | 3804.63 |
我们分析了不同人群密度水平的多种环境,并使用 GD 检测器可视化各方法在这些场景中的平均性能和成本。结果如图 5 所示。在被评估的方法中,ZECC 在不同密度水平下表现出最佳平均性能。随着人群密度增加,ATE 中的 MLLM 更有效地识别高密度人群,从而改善性能。相比之下,其他方法难以处理高密度人群,因此性能受限。
从成本看,ZECC 的导航点受到人群分布和密度影响。随着密度水平提高,成本也会上升。尽管 ZECC 在后两个密度水平中未达到最低成本,但在保证有效计数性能的同时,其成本仍与基线相当。相比之下,其他方法不会根据人群分布主动调整导航点,因此其成本相对稳定,并限制了它们在低密度场景中的有效性。

图 5:不同人群密度水平下 ZECC 与基线方法的性能和成本。
L1-L5 表示密度水平逐渐增大。该图表明 ZECC 在性能和探索成本之间取得了平衡。
4.3 消融研究
ATE。 我们通过移除 ATE 中的特定组件进行消融研究,结果见表 2。不使用 ATE(w/o ATE)的配置取得最佳性能,因为它贪婪地探索环境并使用 NLBN 进行精细检测,从而获得充分感知。然而,这会导致更大的时间延迟(TD)。相比之下,ZECC 通过同时进行 HAE 和 LAE 取得更好的平衡。w/o HAE 使用与 w/o ATE 相同的设置。w/o LAE 失败是因为它保持在高空,且没有进行近距离检测,因此难以捕获目标。
表 2:ATE 组件消融结果。
w/o ATE 表示使用 FBE + NLBN 结果进行人群计数;w/o HAE 表示将智能体高度固定为 LAE;w/o LAE 表示将智能体高度固定为 HAE。ZECC 以约 8% 的性能下降换取约 17% 的成本降低,取得更好的折中。
| 方法 | MAPE (%) | TD (m) |
|---|---|---|
| ZECC w/o ATE | 17.46 | 4633.67 |
| ZECC w/o HAE | 17.46 | 4633.67 |
| ZECC w/o LAE | 88.08 | 1738.84 |
| ZECC | 18.91 | 3804.63 |
NLBN。 随后我们对 NLBN 进行消融研究,结果见表 3。结果表明,省略 NLBN 的任何组件都会显著降低性能或成功率。如果没有 NLBN,缺少优化视点会使 ZECC 退化为 ZSON 方法。当 NL 和 FBE-VPS 都被移除时,大多数导航点最终位于障碍物上,导致可达导航点稀缺且探索不完整。此外,如果没有 VPS,导航点会直接位于目标上方,使目标落到视野之外,从而导致观测损坏。
表 3:NLBN 组件消融结果。
w/o NLBN 表示使用 ATE 结果进行人群计数;w/o NL 表示不使用法线(NL)计算导航点,而使用簇中心作为导航点;w/o VPS 表示不使用视点选择(VPS),而是在法线向量上以 η\etaη 选择一个点;w/o ATE-VPS 表示不使用基于 ATE 视角向量的视点选择,而是从潜在导航向量中随机选择导航向量。成功率表示 A* 路径规划算法报告的可达导航点比例。
| 方法 | MAPE (%) | 成功率 (%) |
|---|---|---|
| ZECC w/o NLBN | 65.19 | 100.00 |
| ZECC w/o NL | 98.44 | 8.33 |
| ZECC w/o VPS | 92.55 | 100.00 |
| ZECC w/o ATE-VPS | 99.49 | 1.45 |
| ZECC | 18.91 | 100.00 |
4.4 超参数研究
随后,我们考察了方法中若干参数的影响,包括 GMM 簇大小、导航向量角度、导航点范围和密度图阈值。实验使用一个类似体育馆的密集人群场景进行测试。结果如图 6 所示。
GMM 簇大小。 随着 GMM 簇大小增加,性能通常会下降。当 GMM 簇大小设置过低时,方法会生成稀疏导航点,使智能体无法有效探索拥挤区域,从而导致较差的计数性能。虽然较小的 GMM 簇大小在初始时可以获得较高性能,但当簇大小分别达到 30 和 40 时,结果会变差。具体而言,簇大小为 30 时的成本为 4065.02 m,簇大小为 40 时上升到 5125.44 m。选择极端的 GMM 簇大小可能显著增加成本,却不会带来实质性能提升。因此,需要谨慎确定 GMM 簇大小,以在成本和性能之间取得平衡。
导航向量角度。 在 20° 时性能最优,而其他角度下性能下降。这种退化是因为智能体视野有限,无法有效观察视野范围外的目标。这凸显了本文导航点生成方法的重要性。
导航点范围。 在距离为 8 m 时性能最优,较短或较长距离都会使性能下降。该趋势与导航向量角度类似。在极近距离下,智能体视野受限;在远距离下,智能体无法收集详细观测,从而对后续目标检测阶段产生负面影响。因此,选择合适视点并生成合适导航点对于有效的场景探索算法至关重要。
密度图阈值。 结果表明,与 GMM 簇大小类似,阈值增加会导致性能下降。较低的密度图阈值会得到更粗略的目标区域估计,从而生成更多导航点。这允许更细致的探索和观察,并带来更好的计数性能,但成本也会上升。例如,当密度图阈值为 0.7 时,行驶距离为 4720.02 m;当阈值为 0.4 时,行驶距离增加到 7272.02 m。成本显著恶化,而性能提升很小。这强调了参数选择的重要性。

图 6:本文模型中四个超参数的影响。
包括 GMM 簇大小、导航向量角度、导航点范围和密度图阈值。
5. 结论
本文提出了具身人群计数(ECC)任务,使交互式人群计数成为可能。为支持 ECC 相关研究,本文开发了一个模拟器,即具身人群计数数据集(ECCD)。该数据集包含 60 个多样虚拟环境,并使用先验概率分布建模人群密度,以近似真实情况。
本文进一步提出零样本具身计数方法 ZECC 来验证该任务。ZECC 是一个主动智能体,能够在没有额外辅助的情况下探索未知环境。本文提出主动俯视探索(ATE),利用 Z 轴移动能力进行探索规划。该模块配备 MLLM,用于激活高空探索(HAE)或低空探索(LAE),从而平衡人群计数性能和探索成本。本文还提出基于法线的导航(NLBN),用于为人群观察选择优化导航点。该模块从俯视视角生成导航点并保持一定角度,从而缓解人群重叠。同时,估计的导航点支持避障,并确保人群位于 FOV 内。实验结果表明,与近期导航智能体相比,ZECC 在性能和成本之间取得了平衡。未来研究将聚焦于更高效、更可扩展的智能体,以提升性能和适应性。
参考文献
参考文献条目保留在原 PDF 中;本文正文保留原始引用编号,便于与原文互相对应。