这里所说的"对比",其实是在探讨一个架构设计模式 (标准 Agentic Loop)与一个带有特定主张的开源实现(Hermes Agent)之间的差异。
简单来说:标准 Loop 是让 Agent "把事情做完",而 Hermes Agent 的 Loop 是为了让 Agent "越做越好"。
以下是两者在核心架构和运行机制上的深度拆解:
1. 标准 Agentic Loop(如 Claude Code, OpenClaw 等框架)
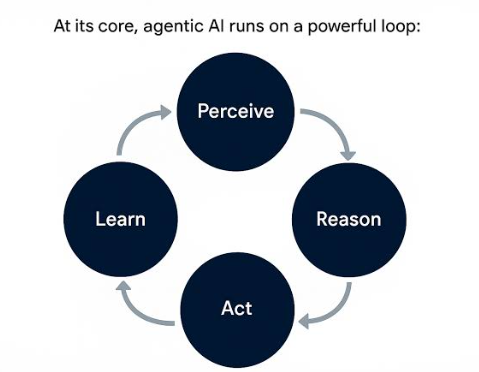
Agentic Loop (智能体循环)是目前几乎所有自主 AI Agent 的底层架构范式。它是一个控制流(Control Flow),通常由 感知 (Perceive) -> 推理 (Reason) -> 行动 (Act) -> 观察 (Observe) 组成。
- 运行机制: 接收任务后,Agent 会在一个
while循环中不断调用工具、查看结果、修正路径,直到满足终止条件(如测试通过,或达到最大迭代次数)。 - 状态管理: 跨会话无状态 (Stateless)。 这是标准 Loop 的最大特点。当一次代码审计或编译任务结束后,Agent 的上下文窗口会被清空。下一次启动时,它又回到了出厂设置,不会记得上一次踩过的坑。
- 核心优势: 确定性强、边界清晰。非常适合构建多步流水线任务,或者需要严格控制执行流的自动化环境。
2. Hermes Agent(内置学习闭环的智能体)
Hermes Agent 是由 Nous Research 在 2026 年初发布的一款开源自主智能体框架。它的核心主张是:反叛"无状态"设计,引入闭合的学习循环 (Closed Learning Loop)。
除了标准的执行循环,Hermes 在任务完成后会多走一步:反思与固化。
- 自动化技能提取: 当 Hermes 成功解决了一个复杂问题(例如绕过了一个特定的沙箱限制或修复了某类 TypeScript 构建错误),它会提取出这段推理模式,并将其打包成一个可复用的"技能"(Skill)。
- 跨会话持久化记忆: 这些技能和记忆不是黑盒的权重微调,而是被直接写入本地的 Markdown 或 YAML 文件中(例如
~/.hermes/skills/目录下),并通过 FTS5 向量搜索在未来的会话中召回。 - 多端网关编排: 提供了一个统一的 Gateway,支持通过 CLI、Telegram 或 Discord 进行跨端连续对话,并且自带 Cron 定时任务执行能力。

核心差异对比
| 对比维度 | 标准 Agentic Loop (如 OpenClaw 工作流) | Hermes Agent 学习循环 |
|---|---|---|
| 生命周期 | 任务驱动。任务结束,生命周期终止。 | 会话持久化。Agent 随时间推移不断积累经验。 |
| 能力进化 | 依赖开发者手动修改 Prompt 或增加 Tool。 | 自主将成功经验固化为本地 Skill 文件,并在后续调用中自我迭代。 |
| 错误重试逻辑 | 同步重试。通常依靠内置的反馈验证回路(Verification Loop)在当前上下文内死磕。 | 跨周期记忆。如果之前记录过绕过某类报错的 Skill,下次遇到直接调用最优解。 |
| 适用场景 | 流程固定的多 Agent 编排、确定的自动化测试。 | 长周期项目、个人专属助理、需要不断积累上下文的漏洞分析挖掘。 |
安全与审计视角
在自动化代码审计和漏洞挖掘的场景中,这两种模式带来的攻击面和审计逻辑截然不同:
对于像 OpenClaw 这样标准的工作流编排框架,安全威胁主要集中在运行时阶段:例如在组装上下文时的 Prompt Injection,或者在执行动态工具代码时发生的沙箱逃逸 (Sandbox Escape)。一旦运行结束,由于上下文被销毁,威胁也随之终止。
而 Hermes Agent 将部分风险转移到了持久化存储层。因为它会将学习到的技能写入本地文件,一次成功的 Prompt Injection 完全有可能"毒化" Agent 的程序化记忆(Procedural Memory)。如果恶意代码被提取为长期 Skill,将影响该 Agent 未来的所有会话。但从防御者的角度来看,这种完全基于本地 Markdown/YAML 文件的"白盒化记忆"设计,也意味着你可以像 review 代码仓库一样,静态审计 Agent 的记忆演进过程。