-
LLM使用关键问题 :
- 幻觉问题 :传统LLM依赖静态训练数据,会生成看似合理但缺乏事实依据的内容,如捏造法律条文、给出错误医学诊断,询问2024年北京天气可能因过时数据给出错误答案。
- 时效性不足 :LLM知识截止于训练时间点,无法动态更新信息,如客服机器人不能提供最新促销信息。
- 领域知识缺失 :LLM缺乏企业私有数据支持,回答通用,缺乏针对性。
- 数据安全风险 :将敏感信息放公有云LLM上有泄露风险,对金融、医疗等有严格隐私合规要求的行业无法容忍。

-
RAG概述 :
- 定义 :RAG全称retrieval augmented generation,通过结合外部知识库检索功能和生成模型,动态提升回答准确性和时效性。
- 工作流程 :分为检索(从知识库找与用户问题最相关文档片段,方式有向量检索、关键词检索等)、增强(将找到片段作为额外上下文信息输入生成模型)、生成(模型融合自身知识和检索到的上下文信息生成完整回答)三个步骤。

-
知识问答流程 :
- 数据准备阶段 :用unstructured loader将本地非结构化文档(如PDF)加载并转化为文本数据,text splitter将长文本分割成小文本片段,embedding将文本片段转换成向量表示,Vector store存储这些向量,可高效检索相似向量。
- 查询和检索阶段 :将用户问题转换为向量表示,计算其与Vector store中所有向量的相似度,找到最相关文本片段。
- 答案生成阶段 :将用户问题和相关文本片段组合成prompt,定义prompt结构引导LLM给出准确答案,LLM基于prompt生成答案。
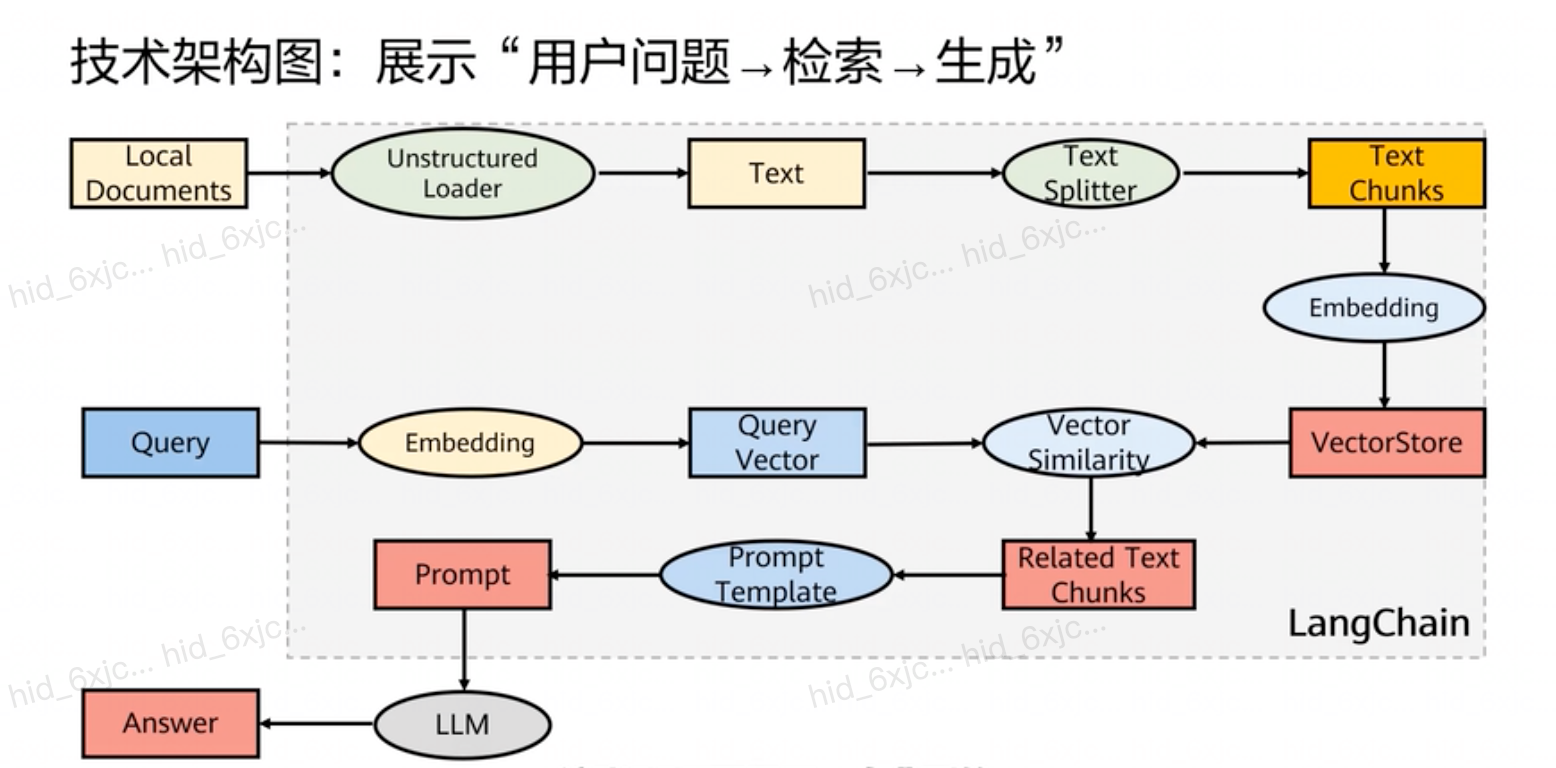
-
RAG实际应用场景 :
- 智能客服领域 :可动态调用商品数据库,提供精准库存和价格查询,让客服直接获取最新信息为客户提供准确答案。
- 企业知识库 :能解析非结构化文档,支持用户用自然语言检索,快速找到关键信息,提高工作效率。
- 医疗咨询方面 :结合最新医学文献为医生提供诊断建议,减少模型编造风险,提升医疗决策可靠性。
- 教育辅助领域 :根据教材和学术论文为学生生成个性化学习答案,帮助学生更好理解知识点。
-
RAG核心组成部分 :
- 知识库 :负责存储各种形式的数据,包括文本、文件、PDF文档、数据库等。
- 检索器 :主要使用向量检索技术(如Faiss),从知识库中高效找到最相关知识片段。
- 生成模型 :选择本地化部署的大型语言模型,如Deepseek 1.5B或CHATGLM3,便于控制成本和数据安全。
- 增强策略 :采用多阶段检索、结合语义信息和关键词、使用重排序模型优化检索结果,提升答案质量。
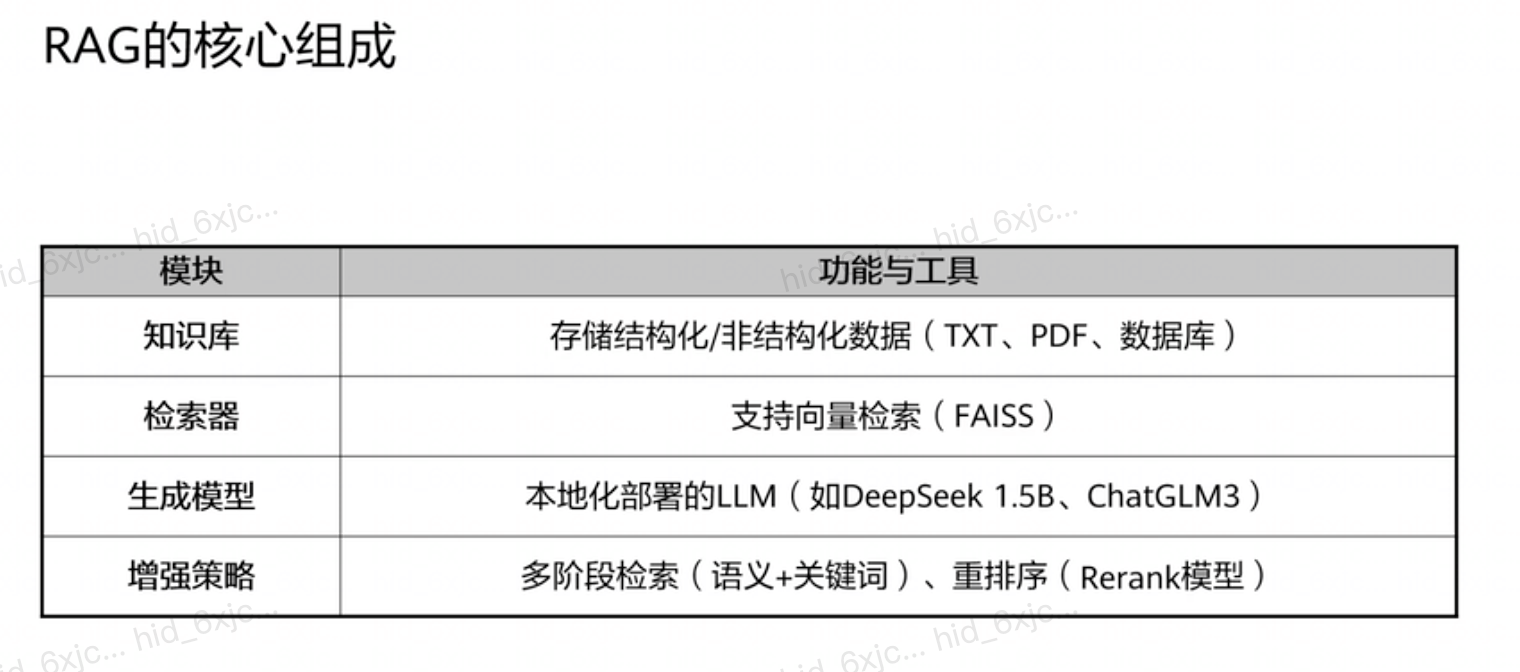
-
RAG架构 :
- 流程 :加载PDF文档,分割成小文本块,进行向量化处理并存储在向量数据库,用户提出问题后将问题向量化,在向量数据库搜索最相似文本块,将检索到的文本块与问题输入大型语言模型(如Deepseek)生成答案。
- 优势 :提高准确性,减少语言模型产生幻觉情况;保持知识更新,可通过更新向量数据库保持知识库最新;具有可追溯性,能追溯答案出处,保证透明度和可信度。
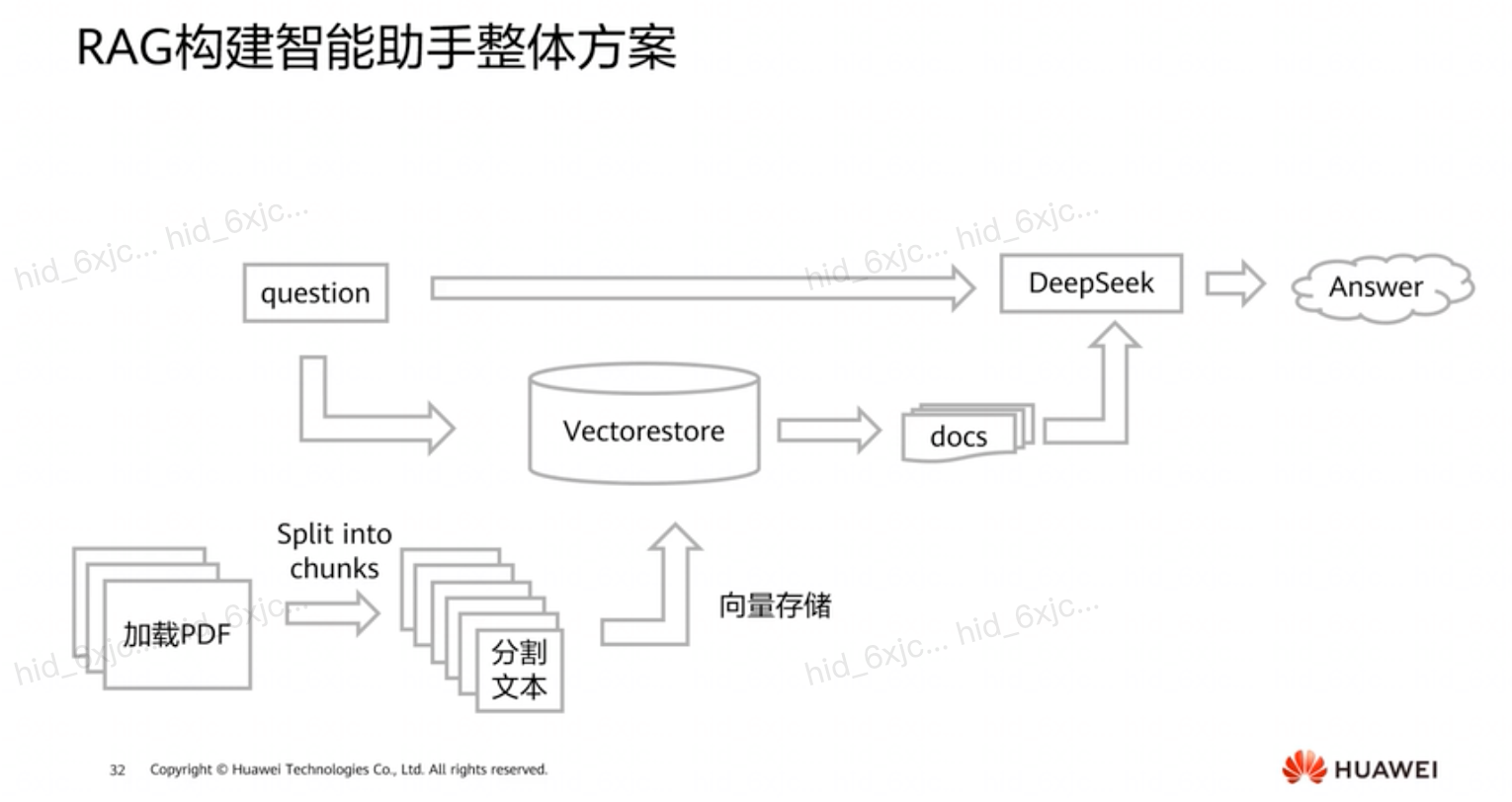
-
智能小助手构建回顾 :
- 需求分析和设计 :构建智能小助手需明确需求和精心设计架构,明确要解决的问题、服务的用户以及如何高效完成任务。
- Rag流程实现 :包括知识库构建(有效组织和准备知识库让模型获取信息)、知识检索(利用检索算法从知识库找相关信息)、生成(将检索信息与用户问题结合,用Deepseek模型生成准确流畅答案)三个关键环节。
(LangChain标准检索增强流程)
整张图分为两大阶段:知识库预处理阶段(离线入库) 、用户提问检索生成阶段(在线问答) ,虚线框为LangChain组件体系,逐个名词解释如下:
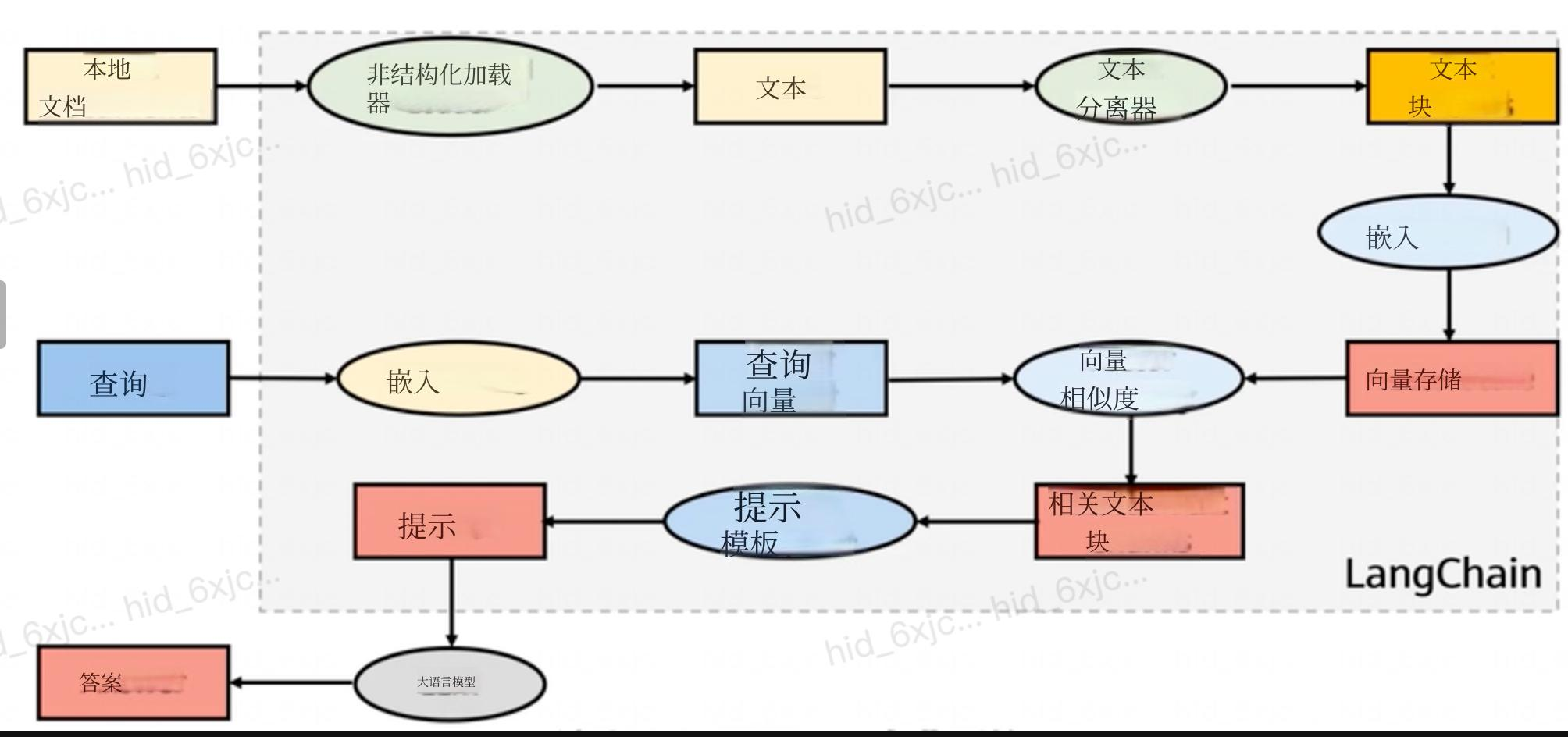
一、离线预处理链路(构建向量知识库)
- Local Documents 本地文档
数据源,企业/个人本地私有文件,包含PDF、Word、TXT、Markdown、PPT等非结构化资料,是整个问答系统的知识来源。 - Unstructured Loader 非结构化加载器
LangChain内置工具,作用:读取各类格式本地文件,解析提取文件里纯文本内容,屏蔽不同文件格式差异,统一输出原始文本。 - Text 原始文本
Loader提取出来未经拆分的完整长篇文本,单份文档全文内容,存在篇幅过长、语义混杂问题,不能直接向量化。 - Text Splitter 文本分割器
核心预处理工具:把长篇原始文本按固定长度、语义边界切分成短小片段(Chunk)。
目的:解决大文本向量语义混杂、检索匹配不准、LLM上下文长度超限问题。 - Text Chunks 文本片段/文本块
分割后短文本单元,是向量化、检索的最小粒度,每一块承载一段独立完整语义。 - Embedding 嵌入模型(文档侧)
文本向量化模型,接收Text Chunks,把人类自然语言转换成计算机可计算的高维数字向量,让语义能用数值距离衡量。 - VectorStore 向量数据库
专门存储向量+对应原文块的数据库(如FAISS、Chroma、Milvus、Pinecone)。
存储内容:文本块对应的Embedding向量、原始文本Chunk、文档元数据;支持高速相似度检索。
二、在线问答检索链路(用户提问流程)
- Query 用户查询/用户问题
用户输入的自然语言提问,例如"RAG架构分几步"。 - Embedding 嵌入模型(查询侧)
和文档侧共用同一个Embedding模型,将用户问题转换成Query Vector查询向量,保证文档向量与问题向量处于同一向量空间。 - Query Vector 查询向量
用户问题转换后的高维数字向量,用于和向量库中所有文档向量做相似度计算。 - Vector Similarity 向量相似度计算
向量数据库核心逻辑:通过余弦距离、欧氏距离等算法,计算Query Vector和库内全部文档向量的相似度,筛选出语义最匹配的Top-N文本块。 - Related Text Chunks 关联文本块
相似度匹配得分最高的若干原文片段,就是和用户问题相关的参考资料,用来补充LLM的外部知识。
三、Prompt组装 & LLM生成链路
- Prompt Template 提示词模板
预设固定格式模板,规范输入大模型的内容结构,一般包含三部分:角色设定、参考资料占位符、用户问题占位符。
示例模板:基于下面参考资料回答用户问题,不准编造内容。参考资料:{上下文};用户问题:{query} - Prompt 完整提示词
将「Related Text Chunks关联片段」+「用户原始Query」填充进Prompt Template后,拼接得到发给大模型的完整输入文本。 - LLM 大语言模型
生成核心,接收拼接好的Prompt,结合自身底座知识+检索到的外部文档,推理生成贴合资料、无幻觉的回答。 - Answer 最终回答
LLM输出的、给用户展示的自然语言答案。
补充标注名词
- LangChain:本架构使用的开源大模型应用开发框架,图中虚线框内所有组件均为LangChain提供的标准模块,用于快速搭建RAG流程。
整体流程极简梳理
- 离线:本地文档→加载→拆分成小块→向量化→存入向量库
- 在线:用户提问→问题向量化→向量库检索相似文本→把参考文本+问题塞进提示模板→传给LLM→输出答案

解析:RAG不仅可以解析结构化文档(如数据库表格、CSV),还能通过Unstructured Loader等工具处理大量非结构化文档,比如PDF、Word、TXT、网页内容、图片里提取的文本等,非结构化文档反而是RAG最常用的处理对象