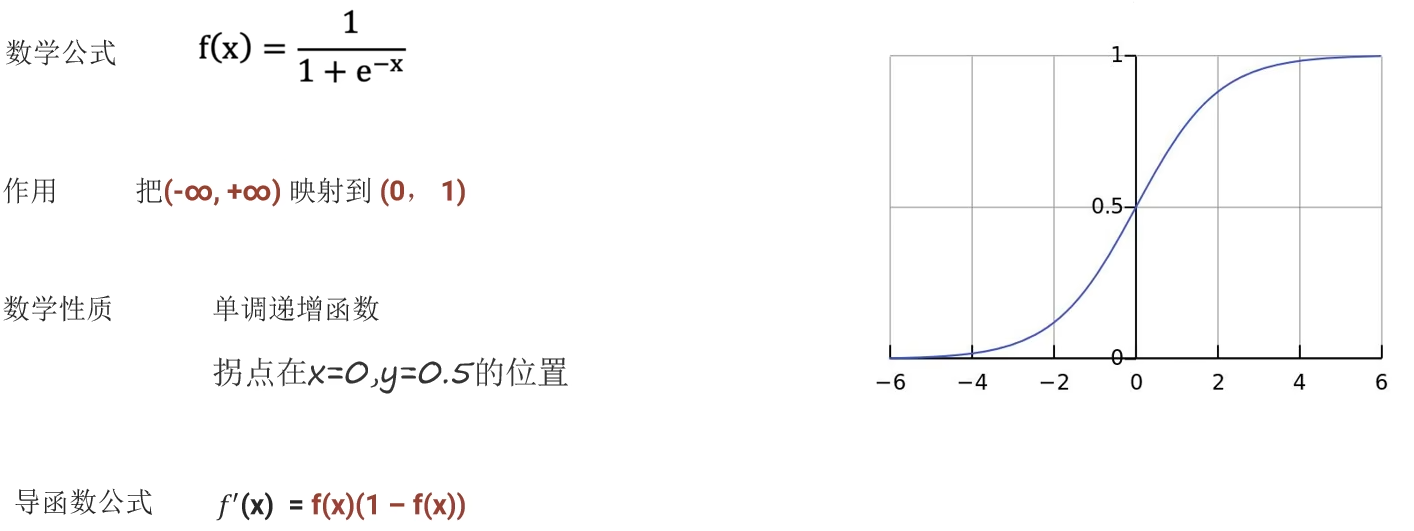
0. 数学基础
sigmoid函数
极大似然估计
极大似然估计(Maximum Likelihood Estimation, MLE)是一种统计方法,用于根据已观测到的数据,估计模型参数。它的基本思想是:找到一组参数,使得在这些参数下,观测到的数据出现的概率最大。
1. 简介
逻辑回归(Logistic Regression):一种分类模型,输出是 (0, 1) 之间的值。
基本思想:把经过处理预测出的值,通过sigmoid激活函数映射到 (0, 1) 之间,结合阈值划分正负样本。
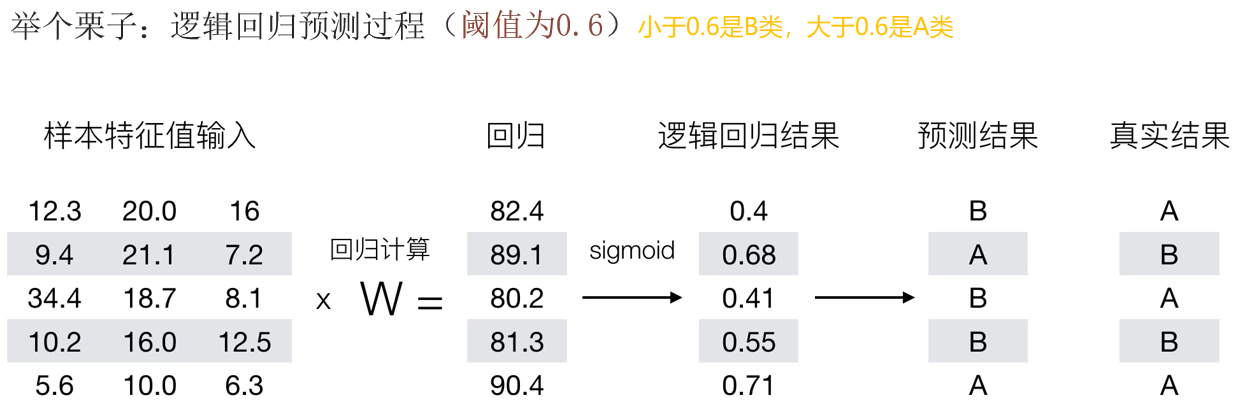
特点:
- 监督学习、有特征、有标签,且标签是离散的
- 应用场景:适用于二分类。
损失函数:
其中,是逻辑回归预估的类别(0或1)。
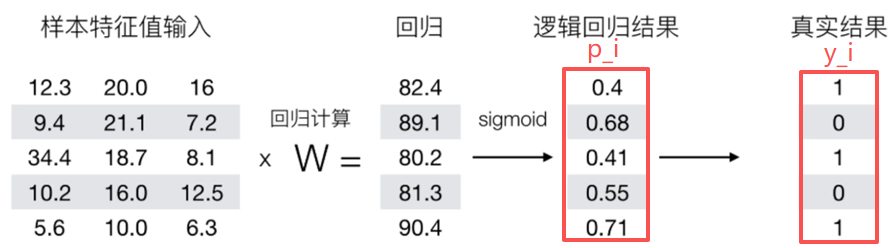
损失函数的手工计算:
Loss = -[1*0.4+(1-1)*(1-0.4) # 第一个特征的损失
+0*0.68+(1-0)*(1-0.68) # 第二个特征的损失
+1*0.41+(1-1)*(1-0.41) # 第三个特征的损失
+...] # 以此类推
工作原理:每个样本预测值有A、B两个类别,真实类别对应的位置,概率值越大越好。
2. API函数
sklearn. linear_model. LogisticRegression(solver = 'liblinear', penalty = '12', C = 1.0)
- solver 损失函数优化方法:
- liblinear 对小数据集场景训练速度更快,sag 和 saga 对大数据集更快一些。
- 正则化:
liblinear支持L1 正则化;
sag支持L2正则化或者没有正则化;
saga支持L1 正则化、支持L2正则化或者没有正则化。
- penalty:正则化的种类,11 或者 12
- C:正则化力度
- 默认将类别数量少的当做正例
案例:癌症分类预测
数据描述:
(1)699条样本,共11列数据,第一列用语检索的id,后9列分别是与肿瘤相关的医学特征,最后一列表示肿瘤类型的数值。
(2)包含16个缺失值,用 "?" 标出。
(3)2表示良性,4表示恶性。
代码实现:
python
# 癌症预测
# 导包
import numpy as np
import pandas as pd
from scipy.linalg.interpolative import estimate_rank
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据
data = pd.read_csv('E:/数据分析材料/breast-cancer-wisconsin.csv')
print(data.info())
# 数据预处理
# 因为里面有'?' 需要将其替换成np.nan
# 参1:要被替换的值;参2:替换成的值;参3:是否替换源数据
data.replace('?',np.nan,inplace=True)
# 缺失值处理 ------>删除缺失行
data.dropna(axis=0,inplace=True)
# 特征工程
# 获取列名
print(data.columns) # 不要第一列 Sample code number
x = data.iloc[:, 1:-1] # 获得特征
y = data.iloc[:, -1] # 获得标签
# 切割 训练接 和 测试集
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2,random_state=22)
# 标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 模型训练
estimator = LogisticRegression()
estimator.fit(x_train,y_train)
# 模型预测
y_pred = estimator.predict(x_test)
# 模型评估
# 正确率,公式:预测对的/样本总数
print(f'预测前评估,正确率:{estimator.score(x_test,y_test)}')
print(f'预测后评估,正确率:{accuracy_score(y_test,y_pred)}')运行结果:
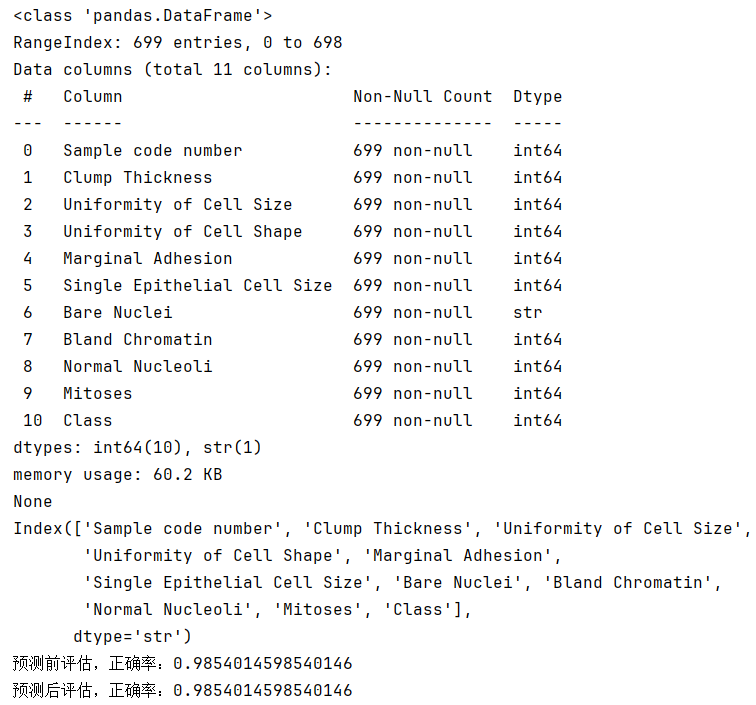
思考:逻辑回归模型能用 准确率 来评测吗?
答案:可以,但是结果不精准,因为逻辑回归模型主要用于 二分类,即:A类还是B类,不能说 97%的A类3%的B类。所以要通过 混淆矩阵 来评测,即:精确率,召回率,F1值(F1-Score),ROC曲线,AUC值.
3. 分类问题评估
3.1. 混淆矩阵
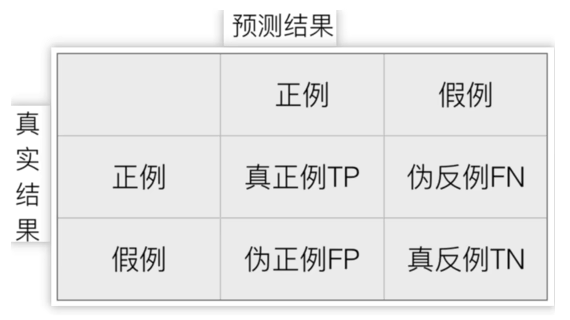
- 真实值是正例的样本中,被分类为正例的样本数量有多少,叫做真正例(TP,True Positive)
- 真实值是正例的样本中,被分类为假例的样本数量有多少,叫做伪反例(FN,False Negative)
- 真实值是假例的样本中,被分类为正例 的样本数量有多少,叫做伪正例(FP,False Positive)
- 真实值是假例的样本中,被分类为假例的样本数量有多少,叫做真反例(TN,True Negative)
精确率(Precision):查准率,正例样本的预测准确率。
召回率(Recall):查全率,指的是预测为真正例样本占所有真实正例样本的比重。
F1-score:模型的综合预测能力。
上诉指标的代码示例:
3.2背景:已知有10个样本,6个恶性肿瘤(正例),4个良性肿瘤(反例).
模型A预测结果为:预测对了3个恶性肿瘤,预测对了4个良性肿瘤
模型B预测结果为:预测对了6个恶性肿瘤,预测对了2个良性肿瘤
python
# 导包
import pandas as pd
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score
# 1、定义变量,记录:样本数据(真实值
y_train=['恶性','恶性','恶性','恶性','恶性','恶性','良性','良性','良性','良性']
# 2、定义变量,记录:模型A的预测结果
y_pred_A=['恶性','恶性','恶性','良性','良性','良性','良性','良性','良性','良性']
# 3、定义变量,记录:模型B的预测结果
y_pred_B=['恶性','恶性','恶性','恶性','恶性','恶性','良性','恶性','恶性','恶性']
# 4、用标签标记正例、反例
label = ['恶性', '良性']
df_label = ['恶性(正例)', '良性(反例)']
# 5、搭建混淆矩阵
cm_A = confusion_matrix(y_train,y_pred_A,labels=label)
print(f'混淆矩阵A:\n {cm_A}')
# 为了测试结果更好看,将上述混淆矩阵转成DataFrame
df_A = pd.DataFrame(cm_A,index=df_label,columns=df_label)
print(f'混淆矩阵A的DataFrame对象形式:\n {df_A}')
print('---------------------------------------------')
cm_B = confusion_matrix(y_train,y_pred_B,labels=label)
print(f'混淆矩阵B:\n {cm_B}')
# 为了测试结果更好看,将上述混淆矩阵转成DataFrame
df_B = pd.DataFrame(cm_B,index=df_label,columns=df_label)
print(f'混淆矩阵B的DataFrame对象形式:\n {df_B}')
print('---------------------------------------------')
# 6、计算A模型的精确率,召回率,F1值
print(f'模型A的精确率:{precision_score(y_train,y_pred_A,pos_label='恶性')}')
print(f'模型A的召回率:{recall_score(y_train,y_pred_A,pos_label='恶性')}')
print(f'模型A的F1值:{f1_score(y_train,y_pred_A,pos_label='恶性')}')
# 7、计算B模型的精确率,召回率,F1值
print(f'模型B的精确率:{precision_score(y_train,y_pred_B,pos_label='恶性')}')
print(f'模型B的召回率:{recall_score(y_train,y_pred_B,pos_label='恶性')}')
print(f'模型B的F1值:{f1_score(y_train,y_pred_B,pos_label='恶性')}')3.2. AUC指标和ROC曲线
- 真正率TPR和假正率FPR
TPR(True Positive Rate):正样本中被预测为正样本的概率。
FPR(False Positive Rate):负样本中被预测为正样本的概率。
- ROC曲线(Receiver Operating Characteristic curve)
ROC曲线是一种常用于评估分类模型性能的可视化工具。ROC曲线以模型的真正率TPR为纵轴,假正率FPR为横轴,它将模型++在不同阈值下++的表现以曲线的形式展现出来。
点坐标说明:图像 x 轴 FPR / y 轴 TPR,任意一点坐标 A ( FPR值, TPR值 )
-
点(0, 0):所有的负样本都预测正确,所有的正样本都预测为错误。相当于点的(FPR值 = 0, TPR值 = 0)
-
点(1, 0):所有的负样本都预测错误,所有的正样本都预测错误。相当于点的(FPR值=1,TPR值=0).最不好的效果.
-
点(1, 1):所有的负样本都预测错误,表示所有的正样本都预测正确。相当于点的(FPR值=1,TPR值=1)
-
点(0, 1):所有的负样本都预测正确,表示所有的正样本都预测正确。相当于点的(FPR值=0,TPR值=1).最好的效果。
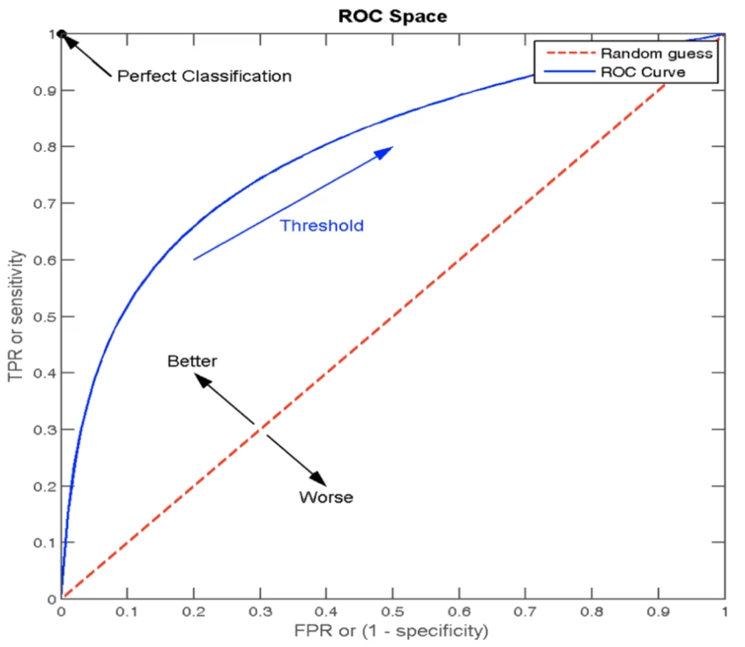
ROC曲线的绘制
背景:在网页某个位置有一个广告图片,该广告共被展示了6次;有2次被浏览者点击了。每次点击的概率见图1其中正样本(1,3} ,负样本为(2,4,5,6}
要求画出:在不同阈值下的ROC曲线。
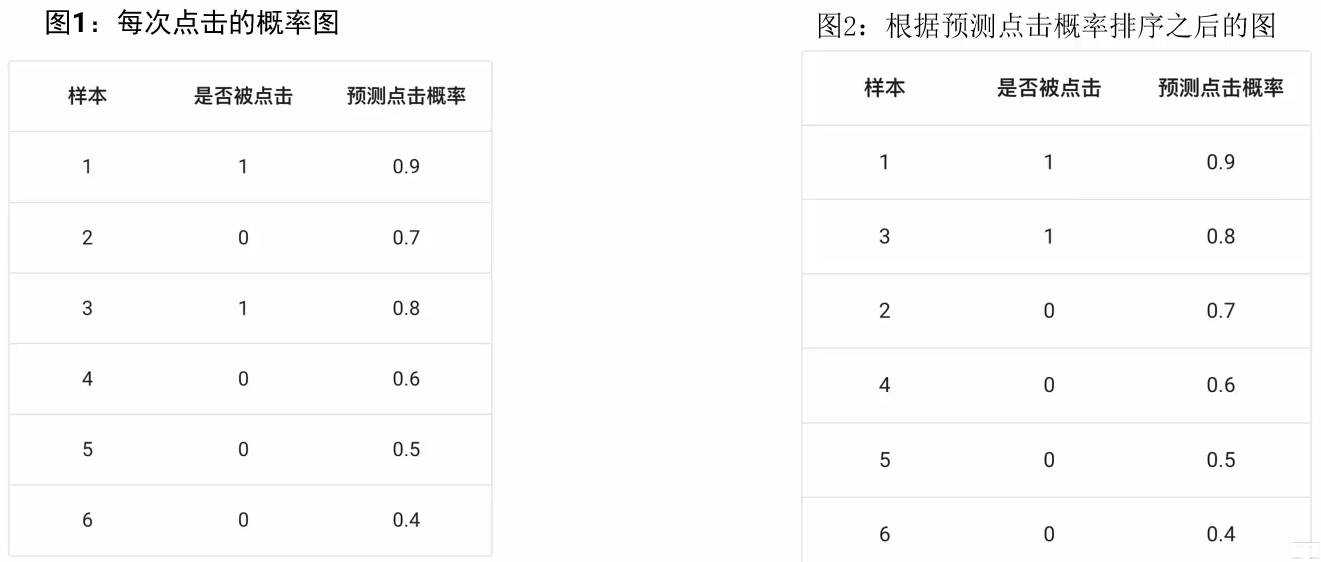
大于阈值被判为正例,小于等于阈值被判为反例。
阈值:0.9
原本为正例的1、3号的样本全部被分类错误,则TPR=0/2=0;原本为负例的2、4、5、6号样本没有一个被分为正例,则FPR=0。所以得到坐标 ( 0, 0 ).
阈值:0.8
原本为正例的1、3号样本中1号被分类正确,则TPR=1/2=0.5;原本为负例的2、4、5、6号样本没有一个被分为正例,则FPR=0。所以得到坐标 ( 0, 0.5 ).
阈值:0.7
原本为正例的1、3号样本全部被分类正确,则TPR= 2/2=1;原本为负例的2、4、5、6号样本没有一个被分为正例,则FPR= 0/4=0。所以得到坐标 ( 0, 1 ).
阈值:0.6
原本为正例的1、3号样本全部被分类正确,则 TPR=2/2=1;原本为负类的2、4、5、6 号样本中2号样本被分类错误,则FPR=1/4= 0.25。所以得到坐标 ( 0.25, 1 ).
阈值:0.5
原本为正例的1、3号样本全部被分类正确,则TPR=2/2=1;原本为负类的2、4、5、6号样本中2、4号样本被分类错误,则FPR=2/4= 0.5。所以得到坐标 ( 0.5, 1 ).
阈值:0.4
原本为正例的1、3号样本全部被分类正确,则TPR=2/2=1;原本为负类的2、4、5、6号样本中2、4、5全部被分类错误,则FPR=3/4=0.75。( 0.75, 1 ).
阈值:0.3/0.2/0.1
原本为正例的1、3号样本全部被分类正确,则TPR=2/2=1;原本为负类的2、4、5、6号样本全部被分类错误,则FPR=4/4=1。( 1, 1 ).
最后得到的ROC曲线为:
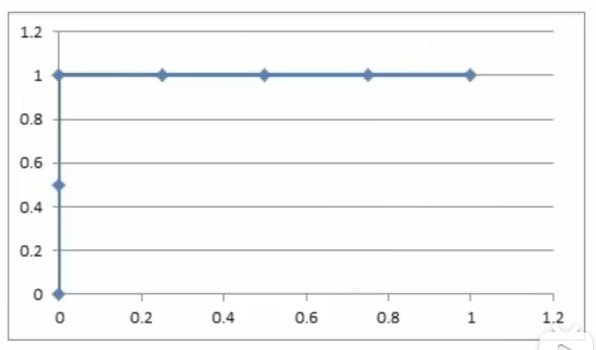
- AUC(Area Under the ROC Curve)曲线下面积
ROC曲线的优劣可以通过曲线下的面积(AUC)来衡量,AUC越大表示分类器性能越好。
当AUC=0.5时,表示分类器的性能等同于随机猜测。
当AUC=1时,表示分类器的性能完美,能够完全正确地将正负例分类。
4. 电信客户流失预测案例
已知:用户个人,通话,上网等信息数据
需求:通过分析特征属性确定用户流失的原因,以及哪些因素可能导致用户流失。建立预测模型来判断用户是否流失,并提出用户流失预警策略。
4.0. 导包
4.1. 数据预处理
python
# 定义函数,数据预处理
def data_preprocess():
# 读取数据
data = pd.read_csv('E:/数据分析材料/churn.csv')
# 显示数据信息
print(data.info())
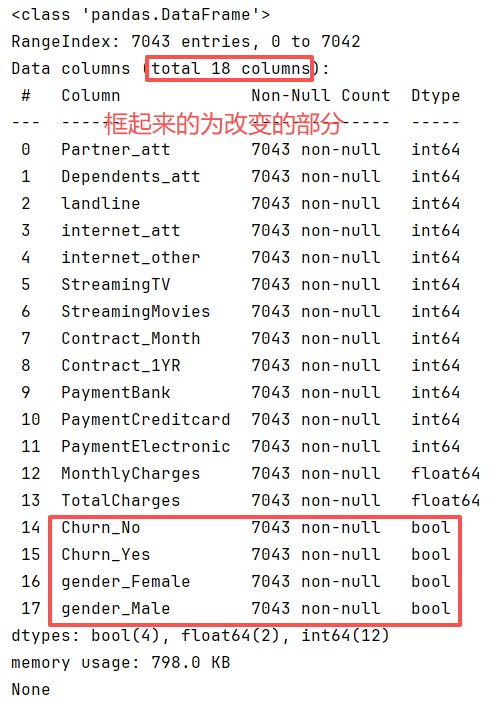
# 因为数据中 Churn 和 gender 列是字符串,所以需要进行one-hot编码处理
data = pd.get_dummies(data,columns=['Churn','gender'])
# 处理后的数据
print(data.info())
# 删除one-hot处理后,冗余的列
# 参1:要删的列 参2:axis=1表示删除列 参3:直接修改源数据
data.drop(['Churn_No','gender_Male'],axis=1,inplace=True)
# 修改列名Churn_Yes,作为标签列
data.rename(columns={'Churn_Yes':'flag'},inplace=True)
# 查看数据值的分布 false-->不流失 True-->流失
print(data.flag.value_counts()) # False:5174 True:1869
# 测试
if __name__ == '__main__':
data_preprocess()原始数据信息:
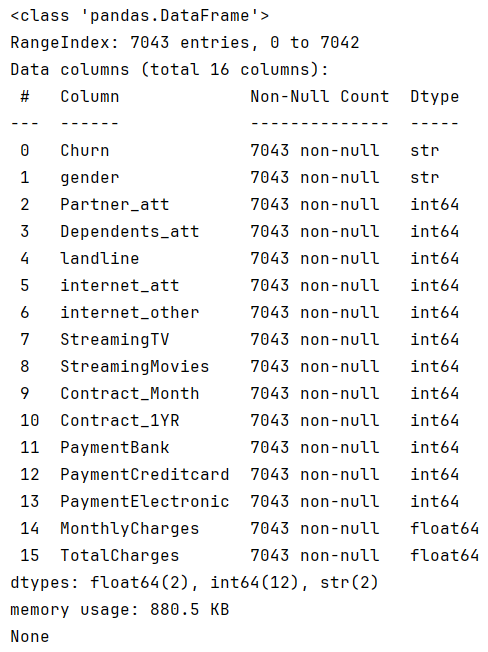
经过one-hot编码后的数据信息:
4.2. 数据的可视化
python
# 定义函数,数据可视化
def data_visualization():
# 前面和上面的数据预处理步骤一样
data = pd.read_csv('E:/数据分析材料/churn.csv')
data = pd.get_dummies(data,columns=['Churn','gender'])
data.drop(['Churn_No','gender_Male'],axis=1,inplace=True)
data.rename(columns={'Churn_Yes':'flag'},inplace=True)
# 查看列名
print(data.columns)
# 数据的可视化 绘制计数柱状图
# 看是否订阅月度会员 与 用户流失之间的关系
# 参1:数据集 参2:x轴的列名 参3:hue分组的字段
sns.countplot(data=data,x='Contract_Month',hue='flag')
plt.show()
# 测试
if __name__ == '__main__':
# data_preprocess()
data_visualization()绘制出的结果:
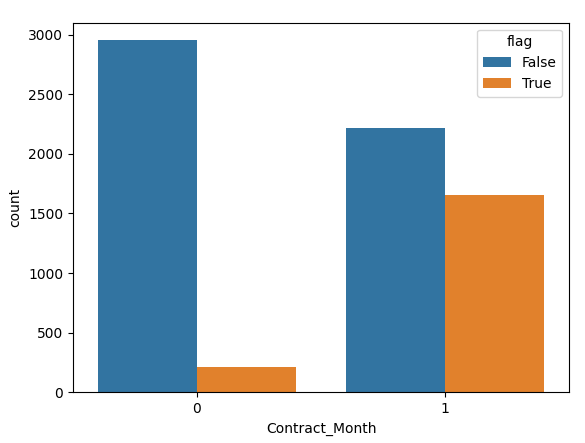
4.3 模型的训练、预测与评估
python
# 定义函数,逻辑回归算法的模型训练,预测,评估
def model_train_test():
data = pd.read_csv('E:/数据分析材料/churn.csv')
data = pd.get_dummies(data,columns=['Churn','gender'])
data.drop(['Churn_No','gender_Male'],axis=1,inplace=True)
data.rename(columns={'Churn_Yes':'flag'},inplace=True)
print(data.info())
print(data.columns)
# 选取特征
x = data[['internet_other','Contract_Month','PaymentBank']]
y = data['flag']
# 分割训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=23)
# 特征预处理,这里不需要
# 模型训练
estimator = LogisticRegression()
estimator.fit(x_train,y_train)
# 模型预测
y_pred = estimator.predict(x_test)
# 模型评估
print(f'精确率:{precision_score(y_test,y_pred)}')
print(f'召回率:{recall_score(y_test, y_pred)}')
print(f'f1值:{f1_score(y_test, y_pred)}')
print(f'分类评估报告:{classification_report(y_test, y_pred)}')
# 测试
if __name__ == '__main__':
# data_preprocess()
# data_visualization()
model_train_test()运行结果:(结果不是很好...)
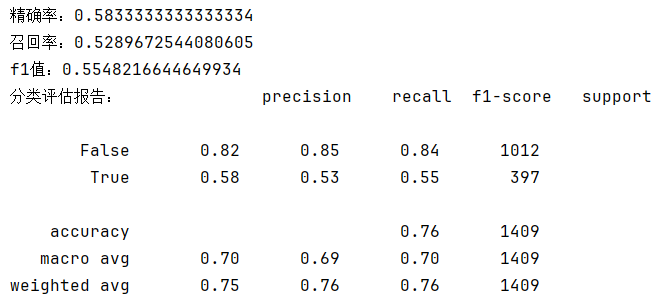
分类评估报告中:
- macro avg:宏平均,即:对每个类别的指标(精确率、召回率、F1)简单算术平均,每个类别权重相同,不考虑类别不平衡。适用于:数据均衡情况。
- weighted avg:对每个类别的指标按该类别的支持度(样本数) 进行加权平均,考虑类别不平衡。适用于:数据不均衡情况。