PriorEye:面向端到端自动驾驶的地理空间视觉先验
作者:Kyuhwan Yeon、Benjamin Ramtoula、Daniele De Martini
单位:英国牛津大学 移动机器人研究组
电子邮箱:{kyuhwan, benjamin, daniele}@robots.ox.ac.uk
摘要
现有的绝大多数端到端自动驾驶方案仅依赖瞬时传感器观测数据,这使得车辆只能做出被动响应式驾驶行为,无法像人类驾驶员那样依托过往经验形成预判视野。本文提出地理空间视觉先验------绑定规划行驶路线的街景视觉上下文,能够脱离车载实时传感器,为模型提供视觉与空间层面的前瞻信息。我们设计了一套记忆增强模块,采用双记忆架构搭配自适应记忆门控机制,可直接嵌入现有任意端到端自动驾驶框架,无需改动主干模型。该架构包含两类互补记忆:存储检索到的地理空间先验的上下文记忆,以及用于兜底保障的持久记忆;模块会根据当前行车状态与先验信息的匹配程度,动态调控两类记忆对模型输出的影响权重。
我们在NAVSIM-v2基准数据集上完成验证,将该模块接入多款主流端到端基线模型后,所有模型综合性能均实现稳定提升。同时,地理空间视觉先验独立于车载传感器采集系统,天然提升了车辆在传感器受损场景下的鲁棒性;双记忆结构则能在先验信息本身失真、不可信时,提供安全兜底输出。
项目开源主页:https://orimrg.github.io/PriorEye
关键词:端到端自动驾驶;先验知识;记忆增强
1 引言
端到端自动驾驶凭借易扩展、逻辑简洁的优势成为主流技术路线,其核心逻辑是将原始传感器观测直接映射为驾驶动作或行驶轨迹7,55。该方案支持模型联合优化,省去人工设计中间表征的步骤,规避了传统模块化自动驾驶管线中逐级传递的误差累积问题9,21,27,28,32,40,50,53,61,72。近期视觉语言大模型的引入进一步提升了端到端模型性能与语义可解释性22,29,43,45,奠定了端到端自动驾驶的主流地位。
尽管现有技术取得长足进步,但仍存在一个核心短板:绝大多数端到端驾驶策略仅能处理数秒内的短时传感器输入,输出纯被动式决策22。而真实驾驶需要对更长时间尺度的路况进行预判推理。人类驾驶员天然会利用过往视觉、空间记忆完成前瞻判断14,42,48。举例:驾驶员凭借记忆,能在车道收窄区域完全未进入视野前,提前变道;也能预判障碍物后方的急弯,提前减速。这类先验信息不会受极端天气、视野遮挡影响。
反观现有端到端自动驾驶系统,完全依赖瞬时传感器画面,在复杂场景中不具备预判能力。同时,过度依赖实时视觉信号会让系统极易受传感器故障干扰------一旦感知临时失效,模型缺少稳定的上下文参考信息。
受人类驾驶认知机制启发,本文提出为现有端到端自动驾驶系统引入地理空间视觉先验作为"驾驶记忆",显式赋予模型视觉与空间前瞻能力。本文定义:空间先验 代表规划行驶路线及沿路空间锚点;视觉先验 为线下采集的街景图像,记录道路环境视觉特征;将视觉先验绑定到空间锚点,即构成地理空间视觉先验。

图1 地理空间视觉先验的设计动机
左图:Boreas数据集车载相机实拍画面,镜头被积雪遮挡,停车标识等关键道路特征完全不可见。仅依靠瞬时观测的自动驾驶算法在该场景极易失效。
右图:沿规划路线线下采集的地理空间视觉先验街景图。该先验不受车载传感器工况影响,画面中停车标识清晰可见,即便车载感知失效,模型仍能依靠先验完成预判驾驶。
借鉴大语言模型的记忆增强方案2,58,62,本文将地理空间视觉先验建模为长期记忆,设计一套模型无关的记忆增强框架 :检索得到的先验作为上下文记忆,为驾驶策略提供超出相机视野的视觉-空间上下文;为规避检索错误带来的风险,额外引入持久记忆作为兜底参考;自适应记忆门控依据特征相似度,动态平衡实时观测、上下文记忆、持久记忆三者的权重。
本模块可无缝接入各类端到端规划模型,无需修改主干网络结构。本文三大核心创新点如下:
- 提出地理空间视觉先验,为端到端自动驾驶提供绑定空间坐标的视觉前瞻信息;
- 设计模型通用的双记忆架构+自适应记忆门控机制,有效融合地理空间先验,同时避免模型过度依赖失真、错位的先验数据;
- 验证:依托独立于车载传感器的地理空间先验,可大幅提升各类端到端规划模型的综合性能,同时增强传感器劣化场景下的系统鲁棒性。
2 相关工作
2.1 端到端自动驾驶
现有端到端自动驾驶方案可根据轨迹规划逻辑分为三类:
- 回归类模型:直接从传感器输入预测未来轨迹,结构简单、推理高效5,9,20,21,24,53;
- 生成式规划模型(含扩散模型):建模可行轨迹的分布,提升轨迹多样性与鲁棒性26,39,40,66;
- 轨迹打分模型:通过学习打分器从候选轨迹中筛选最优方案,适配多模态、非凸规划不确定性场景32,33,36--38,69。
近期研究进一步融合视觉语言模型增强语义推理能力12,22,29,45,47,49,68,同时广泛探索3D高斯泼溅、世界模型用于数据增广与性能提升4,16,18,23,34,35,56,59,71。
但所有方案存在统一短板:输入视野仅覆盖数秒短时观测,模型只能被动响应,无法预判相机视野外的道路环境。
2.2 自动驾驶领域先验知识
自动驾驶中的先验知识指无法通过车载传感器实时观测、线下提前获取的信息。
- 驾驶记忆/经验先验:用于高层逻辑推理,让模型复用过往场景知识,提升复杂工况鲁棒性41,60,70;
- 空间先验(地图、航拍图、路线信息):编码道路拓扑与交通规则,多用于高精地图重建等上游任务,提供远距离道路结构引导30,44,67;
- 视觉先验(街景图):线下视觉数据,记录道路外观与场景上下文25。
现有研究存在两处空白:
- 先验知识大多仅用于高精地图构建、高层决策等上游任务,极少直接注入端到端规划模块;
- 空间先验与视觉先验通常分开使用,规划模型无法同时获取沿规划路线的完整视觉上下文。
针对上述问题,本文提出地理空间视觉先验,将线下视觉上下文与路线空间信息耦合,直接嵌入端到端驾驶策略,让规划模型获得完整的视觉-空间前瞻信息。
3 方法
本文研究对象:输入原始传感器观测、自车状态、高层导航指令,输出规划轨迹的端到端自动驾驶系统;假设系统可获取部署区域的车道连通图。
整体流程:
- 线下构建全局街景视觉嵌入库;
- 推理时根据当前车辆定位,检索对应路线的视觉嵌入,绑定空间坐标,生成地理空间视觉先验(3.1节);
- 记忆增强模块将检索到的先验融合进端到端模型中间特征,输出增强后的状态表征(3.2节,图2)。
3.1 地理空间视觉先验与记忆库
地理空间视觉先验是将街景视觉上下文锚定在规划行驶路线上的视觉-空间表征,为端到端模型提供前方路况前瞻。为构建该先验,我们设计记忆库,存储全域道路街景图像嵌入与对应地理位置配对数据。
3.1.1 记忆库构建
针对目标部署区域,沿每条车道中心线按固定空间间隔采样街景图像;采用冻结的视觉骨干网络SigLIP257编码每张图像,生成车道关联记忆存入库中。
本框架仅需稀疏分布的街景图,对噪声鲁棒------记忆库的目标是提供导航所需语义视觉线索,而非精准几何重建。
3.1.2 从记忆库检索地理空间视觉先验
训练与推理阶段,仅需检索与当前行车上下文匹配的视觉嵌入:
- 根据自车定位确定当前所在车道;
- 基于车道连通图深度优先搜索(DFS),生成前方候选车道序列;
- 根据高层导航指令(左转/右转/直行)筛选匹配车道序列,提取沿路存储的视觉嵌入。
每条检索得到的视觉嵌入 v i ∈ R D m v_{i} \in \mathbb{R}^{D_{m}} vi∈RDm 绑定沿车道的相对二维坐标 x i ∈ R 2 x_{i} \in \mathbb{R}^{2} xi∈R2, D m D_m Dm 为视觉嵌入维度。堆叠N组配对数据,得到视觉先验矩阵 V ∈ R N × D m V \in \mathbb{R}^{N ×D_{m}} V∈RN×Dm、空间先验矩阵 X ∈ R N × 2 X \in \mathbb{R}^{N ×2} X∈RN×2,二者共同构成检索出的地理空间视觉先验:
{ ( v i , x i ) } i = 1 N (1) \left\{ \left( v_{i},x_{i}\right) \right\} _{i=1}^{N} \tag{1} {(vi,xi)}i=1N(1)
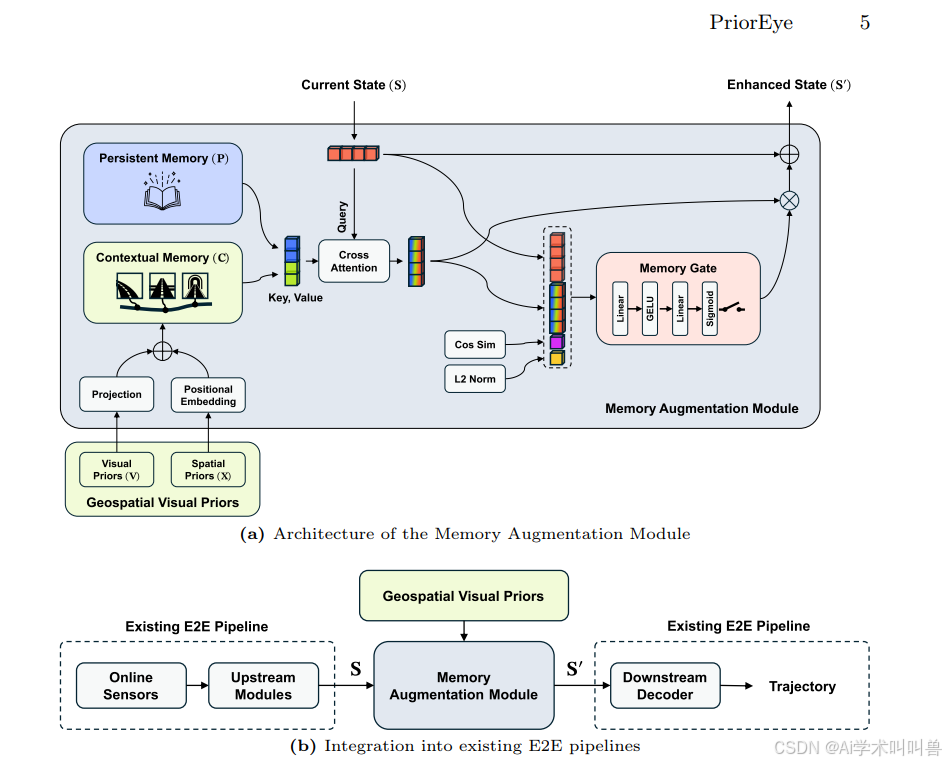
图2 整体框架总览
(a) 记忆增强模块内部详细架构
(b) 嵌入现有端到端管线的通用集成方案
说明:模块接收上游输出的原始行车状态S、地理空间视觉先验作为输入,输出增强状态 S ′ S' S′ 送入下游解码器生成轨迹;虚线框为无需改动的原有模型组件。
3.2 记忆增强模块
本模块用于将检索得到的地理空间视觉先验融合进端到端系统,包含两大核心组件:
- 双记忆架构:将先验编码为上下文记忆,搭配持久记忆作为兜底;
- 记忆融合机制:基于交叉注意力+自适应门控,选择性将两类记忆融入当前行车状态。
3.2.1 双记忆架构
借鉴 Titans模型2设计双记忆结构,将检索先验建模为可读取记忆,分为两类互补模块:
(1)上下文记忆 Contextual Memory
依赖输入动态生成,用于编码地理空间视觉先验,计算公式:
C = ϕ ( V ) + ψ ( X ) (2) C=\phi(V)+\psi(X) \tag{2} C=ϕ(V)+ψ(X)(2)
ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅):将视觉先验投影至端到端模型内部嵌入空间;
ψ ( ⋅ ) \psi(\cdot) ψ(⋅):二维正弦位置编码,把相对坐标形式的空间先验映射至同一嵌入空间;
二者相加,让上下文记忆同时捕捉场景外观语义与粗粒度道路空间布局。
(2)持久记忆 Persistent Memory
线下采集的街景图像可能因季节变化、几何错位出现失真,此时注意力机制会被迫关注无效特征,对应Transformer中的注意力沉没问题13,64。
为此引入持久记忆:一组可学习token,作为上下文记忆失效时的稳定兜底参考:
P ∈ R K × D (3) P \in \mathbb{R}^{K × D} \tag{3} P∈RK×D(3)
K K K = 持久token数量; D D D = 模型嵌入维度。该组token与输入无关,所有样本共享。
3.2.2 记忆融合机制
定义当前行车状态为查询token集合:
S ∈ R Q × D (4) S \in \mathbb{R}^{Q × D} \tag{4} S∈RQ×D(4)
Q Q Q:端到端模型输出的状态token数量; D D D:嵌入维度。token编码感知特征、自车运动状态等中间行车信息。
采用多头交叉注意力实现记忆关联检索:以当前行车状态S为查询,两类记忆拼接后作为键、值。
先沿token维度拼接持久记忆与上下文记忆:
M = P ; C (5) M=P;C \tag{5} M=P;C(5)
通过交叉注意力计算融合记忆后的行车状态:
S ~ = A t t n ( S , M , M ) (6) \tilde{S}=Attn(S, M, M) \tag{6} S~=Attn(S,M,M)(6)
S ~ \tilde{S} S~:融合记忆信息后的行车状态特征,模型可动态自主关注上下文记忆或持久记忆。
3.2.3 自适应记忆门控 Memory Gate
引入自适应门控调节记忆信息的贡献权重。通过欧式距离d、余弦相似度c衡量原始状态S与融合记忆状态 S ~ \tilde{S} S~的语义一致性:
d = ∥ S − S ~ ∥ 2 D , c = c o s ( S , S ~ ) d=\frac{\| S-\tilde{S}\| _{2}}{\sqrt{D}},\quad c=cos (S, \tilde{S}) d=D ∥S−S~∥2,c=cos(S,S~)
门控输出G由轻量MLP+sigmoid激活生成:
G = σ ( f g ( S ; S \~ ; d ; c ) ) G=\sigma \Bigl (f_{g}\Bigl (S;\\tilde {S};d;c\Bigr )\Bigr ) G=σ(fg(S;S\~;d;c))
G G G = 门控系数; σ ( ⋅ ) \sigma(\cdot) σ(⋅) = Sigmoid激活; f g ( ⋅ ) f_{g}(\cdot) fg(⋅) = 轻量多层感知机。门控根据特征匹配度自适应控制记忆信息的权重。训练初始化将门控偏置置为小值,初始接近关闭状态,稳定训练过程17,51。
3.2.4 最终融合状态更新
采用门控残差更新得到最终增强行车状态:
S ′ = S + G ⊙ S ~ (9) S'=S+G \odot \tilde{S} \tag{9} S′=S+G⊙S~(9)
⊙ \odot ⊙:逐元素相乘。更新后的状态 S ′ S' S′送入端到端模型下游解码器,替代原始状态S完成轨迹预测。
记忆增强模块与基线模型联合训练,复用基线原有损失函数,无需额外新增损失项。
4 实验
4.1 实验设置
数据集
基于NAVSIM-v2大规模真实世界端到端自动驾驶基准4,11(基于nuPlan数据集构建)。全部模型在navtrain完整训练集训练,在navhard-two-stage、navtest测试集评估,严格遵循基准官方协议;消融实验拆分navtrain子集作为验证集。
评价指标
采用NAVSIM-v2官方综合指标EPDMS(扩展预测驾驶员模型分数) ,整合安全、平顺性9项子指标:
NC(无责碰撞)、DAC(可行驶区域合规)、DDC(行驶方向合规)、TLC(交通信号灯合规)、EP(自车行进效率)、TTC(碰撞安全时间)、LK(车道保持)、HC(历史平顺性)、EC(扩展平顺性)。
navhard-two-stage采用两段式伪仿真评估:阶段1基于真实观测评估规划轨迹;阶段2施加人工扰动,评估模型鲁棒性;navtest仅执行阶段1评估。
基线模型
选取四类代表性端到端自动驾驶方案,验证本模块的模型无关特性:
- 回归类:LTF9
- 扩散生成类:GTRS-DP38
- 轨迹打分类:GTRS-Dense38、DrivoR32
叠加PriorEye模块的模型统一标注后缀"+ PriorEye"。
定性可视化、鲁棒性实验默认以GTRS-Dense为基线;消融实验选用轻量化LTF,降低训练开销。
街景图像数据源
采用谷歌街景API采集目标区域街景图,用于构建记忆库。该数据源存在缺陷:部分点位无图像、存在高度/空间错位,同一车道多位置可能映射至同一张街景图25。但本文框架对缺失、冗余图像具备鲁棒性;且不绑定特定数据源,任意稀疏点位标注驾驶图像均可替换。
实现细节
- 记忆库:SigLIP2(base-patch16-256)编码街景图,采样间隔5米;覆盖6.5平方公里区域,文件总大小939MB;
- 推理检索:单次提取N=20组地理空间先验,覆盖约100米前瞻范围;
- 参数量开销:记忆增强模块仅新增713K参数,相对四大基线占比极低:LTF(56.7M)+1.3%、GTRS-DP(116M)+0.6%、GTRS-Dense(83.6M)+0.9%、DrivoR(41.5M)+1.7%;
- 模型集成点:模块作用于自车状态特征+感知特征拼接后的中间表征:
- LTF/GTRS-DP:BEV鸟瞰特征+自车状态
- GTRS-Dense:图像特征+自车状态
- DrivoR:场景token+自车状态
- 训练硬件:8张RTX 5090显卡,各模型单卡批次、训练轮次:
LTF:64批次/100轮;GTRS-DP:16批次/80轮;GTRS-Dense:16批次/40轮;DrivoR:12批次/20轮。
4.2 主实验定量结果
表1 navhard-two-stage基准性能(S1=阶段1,S2=阶段2)
指标后缀↑代表数值越高性能越好;最后一列EPDMS相对提升百分比标注在末尾
| 模型 | NC | DAC | DDC | TLC | EP | TTC | LK | HC | EC | EPDMS | 相对提升 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| LTF | 95.1 | 79.4 | 80.7 | 68.3 | 98.8 | 83.4 | 99.6 | 98.1 | 86.6 | 24.7 | --- |
| LTF + PriorEye | 95.6 | 78.8 | 86.4 | 76.6 | 99.4 | 86.0 | 99.3 | 98.3 | 85.2 | 32.4 | +31.2% |
| GTRS-DP | 95.0 | 81.3 | 80.7 | 72.6 | 97.0 | 83.3 | 98.5 | 99.9 | 83.2 | 26.3 | --- |
| GTRS-DP + PriorEye | 95.3 | 82.0 | 75.3 | 96.4 | 85.7 | 98.5 | 99.8 | 81.5 | 82.3 | 30.1 | +14.4% |
| GTRS-Dense | 91.2 | 98.4 | 89.2 | 95.8 | 94.6 | 99.4 | 99.3 | 98.8 | 72.8 | 44.9 | --- |
| GTRS-Dense + PriorEye | 97.6 | 89.5 | 97.1 | 90.0 | 95.0 | 100.0 | 99.8 | 99.0 | 76.1 | 48.6 | +8.2% |
| DrivoR | 91.8 | 99.1 | 89.4 | 98.2 | 99.3 | 94.1 | 99.3 | 100.0 | 59.0 | 48.9 | --- |
| DrivoR + PriorEye | 98.7 | 87.2 | 89.9 | 99.6 | 93.3 | 99.6 | 99.1 | 99.8 | 70.5 | 49.6 | +1.4% |
结论:四大基线叠加PriorEye后EPDMS全部上涨,证明模块具备通用适配性;轻量基线LTF提升幅度最大(31.2%)。
表2 navtest测试集性能
| 模型 | NC | DAC | DDC | TLC | EP | TTC | LK | HC | EC | EPDMS | 绝对提升 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| LTF | 97.8 | 92.5 | 99.1 | 99.8 | 87.8 | 97.4 | 96.3 | 98.3 | 87.0 | 84.3 | --- |
| LTF + PriorEye | 97.6 | 95.1 | 99.5 | 99.8 | 87.8 | 97.4 | 97.4 | 98.3 | 87.0 | 86.8 | +2.5 |
| GTRS-DP | 97.3 | 92.3 | 98.6 | 99.7 | 86.4 | 97.0 | 95.3 | 98.1 | 79.4 | 82.2 | --- |
| GTRS-DP + PriorEye | 97.5 | 92.7 | 98.7 | 99.8 | 85.9 | 97.1 | 95.6 | 98.2 | 78.3 | 82.5 | +0.3 |
| GTRS-Dense | 99.1 | 98.3 | 99.6 | 99.9 | 82.8 | 99.2 | 94.8 | 98.0 | 47.5 | 85.4 | --- |
| GTRS-Dense + PriorEye | 98.7 | 99.1 | 99.8 | 99.9 | 85.0 | 98.8 | 96.7 | 98.2 | 67.5 | 88.8 | +3.4 |
| DrivoR | 99.4 | 99.2 | 99.8 | 99.9 | 76.6 | 99.4 | 94.9 | 98.3 | 71.7 | 87.2 | --- |
| DrivoR + PriorEye | 99.1 | 99.6 | 99.8 | 99.9 | 81.5 | 99.1 | 95.9 | 98.3 | 82.5 | 89.9 | +2.7 |
两段测试集均稳定提升,证明地理空间先验的增益不局限单一评估场景。
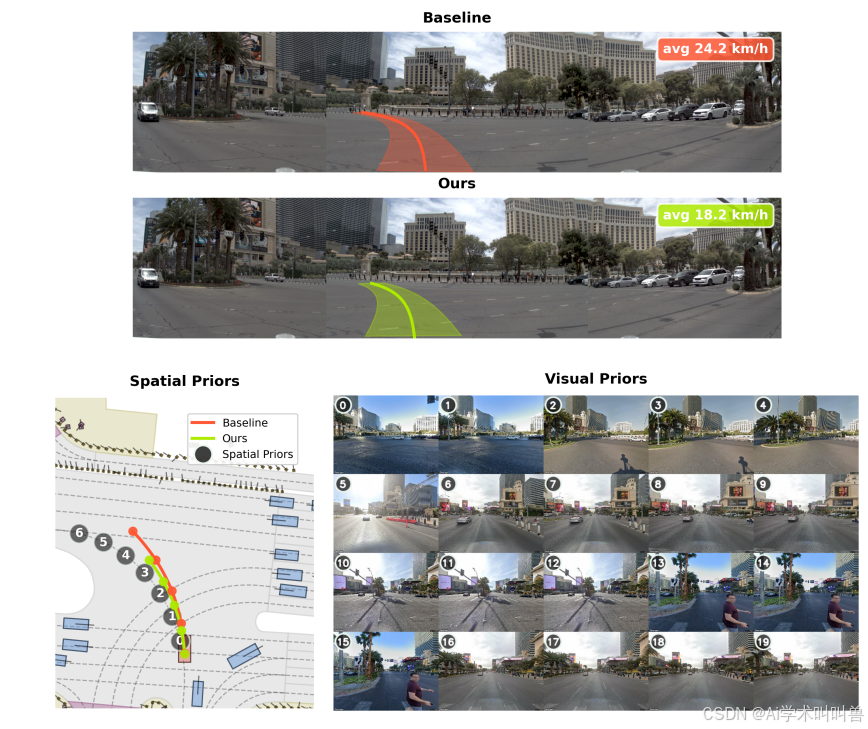
图3 左转场景轨迹定性对比
上图:相机画面叠加预测轨迹,右上角为预测时域平均车速;
左下:BEV鸟瞰地图,展示预测轨迹与5米间隔采样的空间先验;
右下:沿规划路线检索的街景视觉先验索引。
场景说明:下游人行横道被障碍物遮挡,车载相机无法观测。
基线模型(红色轨迹)平均车速24.2km/h;
本文方案(绿色轨迹)依托索引10--15的先验预判人行横道,减速至18.2km/h,提前保守行驶。直观验证地理空间先验弥补瞬时感知缺陷,实现预判驾驶。
4.3 鲁棒性分析
从两大维度验证鲁棒性:①车载传感器画面劣化;②检索得到的地理空间先验本身失真。
4.3.1 传感器劣化鲁棒性
真实驾驶中镜头污渍、结霜、遮挡会造成传感器失效,现有端到端模型仅依赖实时画面,性能断崖下跌。本文先验独立于车载相机,可提供稳定补充信息。
实验方式:对前视相机叠加5类人工合成劣化画面,通过线性叠加/透明蒙版融合原图。
图4 相机劣化样本展示
从左至右、从上至下:正常画面、指纹污渍、手掌印、结霜、轻度泥污、重度泥污。
表3 传感器劣化下EPDMS分数(括号内为相对正常工况性能衰减幅度)
| 模型 | 正常工况 | 指纹污渍 | 手掌印 | 镜头结霜 | 轻度泥污 | 重度泥污 |
|---|---|---|---|---|---|---|
| 基线GTRS-Dense | 44.9 | 40.0(-10.9%) | 40.3(-10.2%) | 34.6(-22.9%) | 42.3(-5.8%) | 21.0(-53.2%) |
| 本文PriorEye | 48.6 | 45.1(-7.2%) | 45.4(-6.6%) | 38.1(-21.6%) | 47.9(-1.4%) | 32.8(-32.5%) |
结果:所有劣化场景下本文方案性能均优于基线;重度泥污场景衰减幅度从53.2%降至32.5%;全场景平均性能衰减由20.6%缩小至13.9%,验证先验可有效补偿传感器失效。
4.3.2 地理空间先验失真鲁棒性
真实部署时,街景图老旧、空间错位、点位缺失会导致检索的上下文记忆C失效。本文引入持久记忆P兜底,设计三类失真仿真:
- 视觉失真:替换为500米外随机点位图像嵌入,语义完全无关;
- 空间失真:视觉嵌入不变,坐标替换为500米外随机位置;
- 双重失真:视觉+空间同步扰动。
表4 先验失真下注意力权重与EPDMS性能
左半部分:完整双记忆模型中持久记忆P、上下文记忆C的平均注意力权重;
右半部分:基线、仅上下文记忆(C only)、完整双记忆(P+C)的EPDMS分数,括号为相对无失真工况衰减幅度
| 失真类型 | P注意力占比 | C注意力占比 | 基线EPDMS | 仅上下文记忆 | 完整双记忆(P+C) |
|---|---|---|---|---|---|
| 无失真 | 0.29 | 0.71 | 44.9 | 47.9 | 48.6 |
| 视觉失真 | 0.97 | 0.03 | --- | 38.5(-19.6%) | 45.3(-6.8%) |
| 空间失真 | 0.65 | 0.35 | --- | 45.2(-5.6%) | 46.6(-4.1%) |
| 双重失真 | 0.99 | 0.01 | --- | 39.0(-18.6%) | 45.4(-6.6%) |
现象:上下文记忆失真时,模型自动将注意力转移至持久记忆;仅上下文记忆方案性能大幅下跌,完整双记忆模型衰减幅度显著降低,即便先验失真,性能仍优于原始基线,证明持久记忆兜底机制有效。
4.4 消融实验
以LTF为基线,在验证集开展全模块组件消融,基线原始EPDMS=81.7
表5 各模块消融结果
- 视觉编码器消融
DINOv2:82.9;SegFormer:83.4;SigLIP2:84.4
结论:三类编码器均优于基线,SigLIP2语义表征最强,最适合编码街景先验。 - 检索策略消融
仅就近点位检索:小幅提升;本文导航意图引导检索:大幅提升
结论:单纯空间近邻无关驾驶规划意图,无效信息多;基于转向指令检索匹配路线先验增益更大。 - 记忆组件消融
仅持久记忆P:小幅提升;仅上下文记忆C:明显提升;P+C双记忆:最优
结论:仅可学习token无实际上下文增益有限,双记忆同时提升正常工况性能与失真鲁棒性。 - 上下文记忆组成消融
仅空间编码 ψ ( X ) \psi(X) ψ(X):小幅增益;仅视觉编码 ϕ ( V ) \phi(V) ϕ(V):大幅增益;二者融合:最优
结论:道路几何结构与场景外观语义互为补充,缺一不可。 - 门控特征消融
仅欧式距离d、仅余弦相似度c均有提升;二者同时输入门控性能最优
结论:两种相似度指标捕捉状态匹配度的不同维度,具备互补性。
4.5 推理耗时分析
基于GTRS-Dense基线,单样本批量1,硬件:RTX PRO 6000 GPU + AMD Threadripper 7960X CPU,统计推理延迟。
表6 推理耗时对比(单位ms)
| 模型 | CPU特征计算耗时 | GPU推理耗时 | 总耗时 | 额外开销 |
|---|---|---|---|---|
| GTRS-Dense基线 | 15.5 | 42.4 | 57.9 | --- |
| GTRS-Dense + PriorEye | 19.2 | 48.0 | 67.2 | +9.3 |
| 模块单独开销 | +3.7 | +5.6 | --- | --- |
总耗时67.2ms,满足自动驾驶10Hz(100ms)实时推理要求;街景图像SigLIP2编码线下完成,推理无额外开销。
5 结论
本文提出地理空间视觉先验,为端到端自动驾驶提供超出车载相机视野的视觉-空间前瞻信息;设计模型通用的双记忆自适应门控增强模块,在NAVSIM-v2基准上全面提升各类端到端规划模型性能。
该方案两大核心优势:
- 大幅提升镜头污渍、结霜、遮挡等传感器劣化场景下的驾驶鲁棒性;
- 双记忆兜底机制,在先验图像失真、错位时保障系统稳定输出。
局限性与未来工作
- 当前先验检索仅依靠自车定位,未来可融合图像外观匹配,实现定位失效时的鲁棒检索;
- 记忆库为静态街景图像,后续可增加记忆更新、遗忘机制,利用车队行驶日志持续迭代,适配道路长期环境变化。