缓存里最危险的东西,不是空值,是"看起来有效、实际上已经失效"的值。
空值会报错,有人会来修。失效的值被当成有效值缓存起来,系统照常运行,直到某个时刻,所有依赖它的请求同时失败------那一刻来得很突然,也很难定位。
这一天,我们修的第一件事就是这个。
一、Token缓存:一个看起来不起眼的计算错误
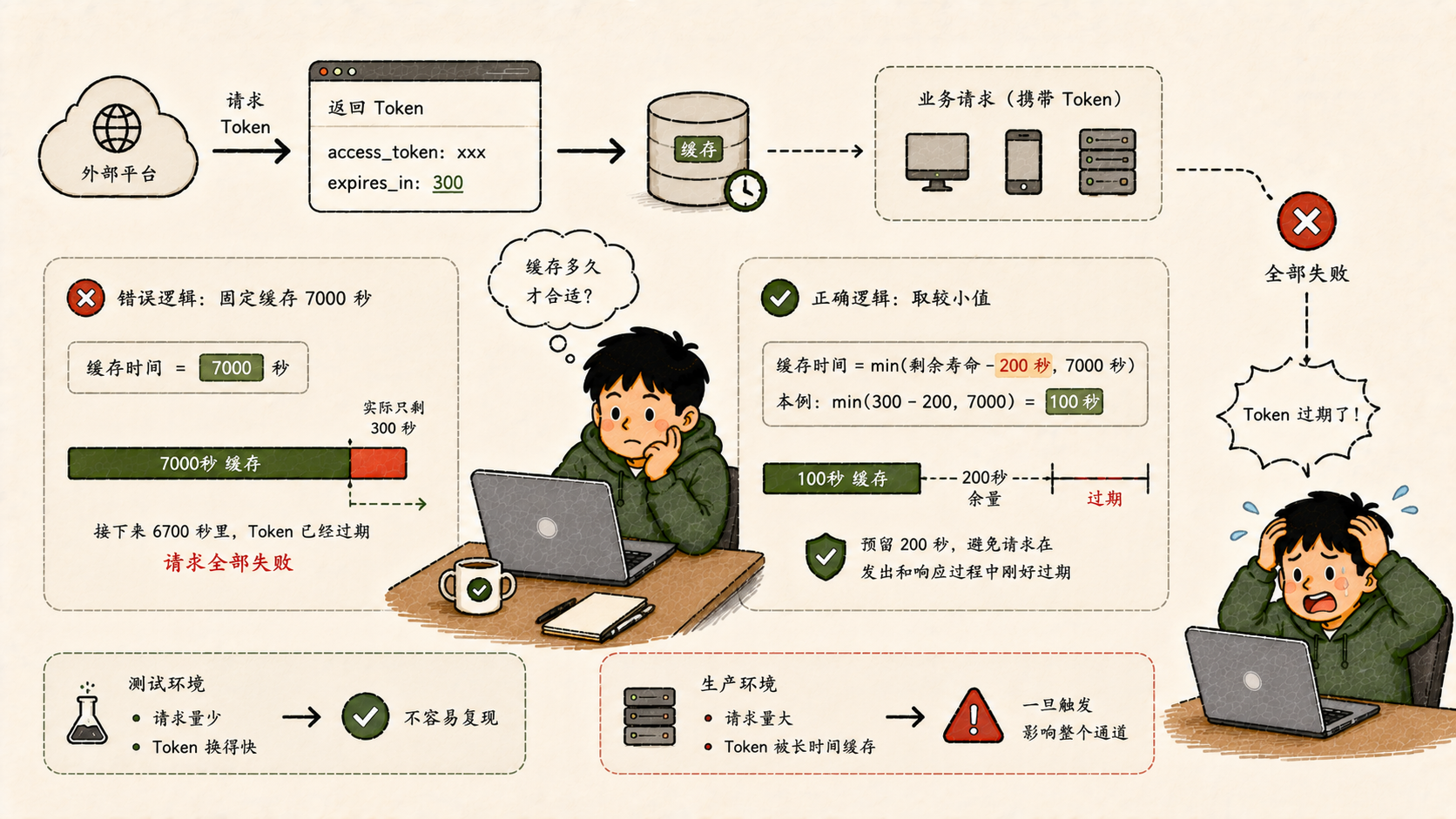
外部平台的访问令牌有过期时间,每次请求都要带着它。系统会缓存这个token,避免每次都重新获取。
缓存多久?之前的逻辑是固定缓存7000秒。问题在于,平台返回token时会告诉你"这个token还剩多少秒有效"。如果一个token拿到手时已经只剩300秒,系统仍然把它缓存7000秒------接下来的6700秒里,所有依赖这个token的操作,拿着一个早就过期的token去请求,全部失败。
修法只改了一行计算逻辑:缓存时间取"平台返回的剩余寿命减200秒"和"7000秒"中的较小值。留200秒的余量是防止边界情况下token在发出请求和收到响应之间刚好过期。
这种Bug的特点是:平时不出问题,只在token快过期时被拿到、又被长时间缓存的情况下才触发。 测试环境请求量少、token换得快,不容易复现。生产环境一旦触发,影响面是整个通道。
二、流式卡片状态残留:一个永远不被清除的"生成中..."
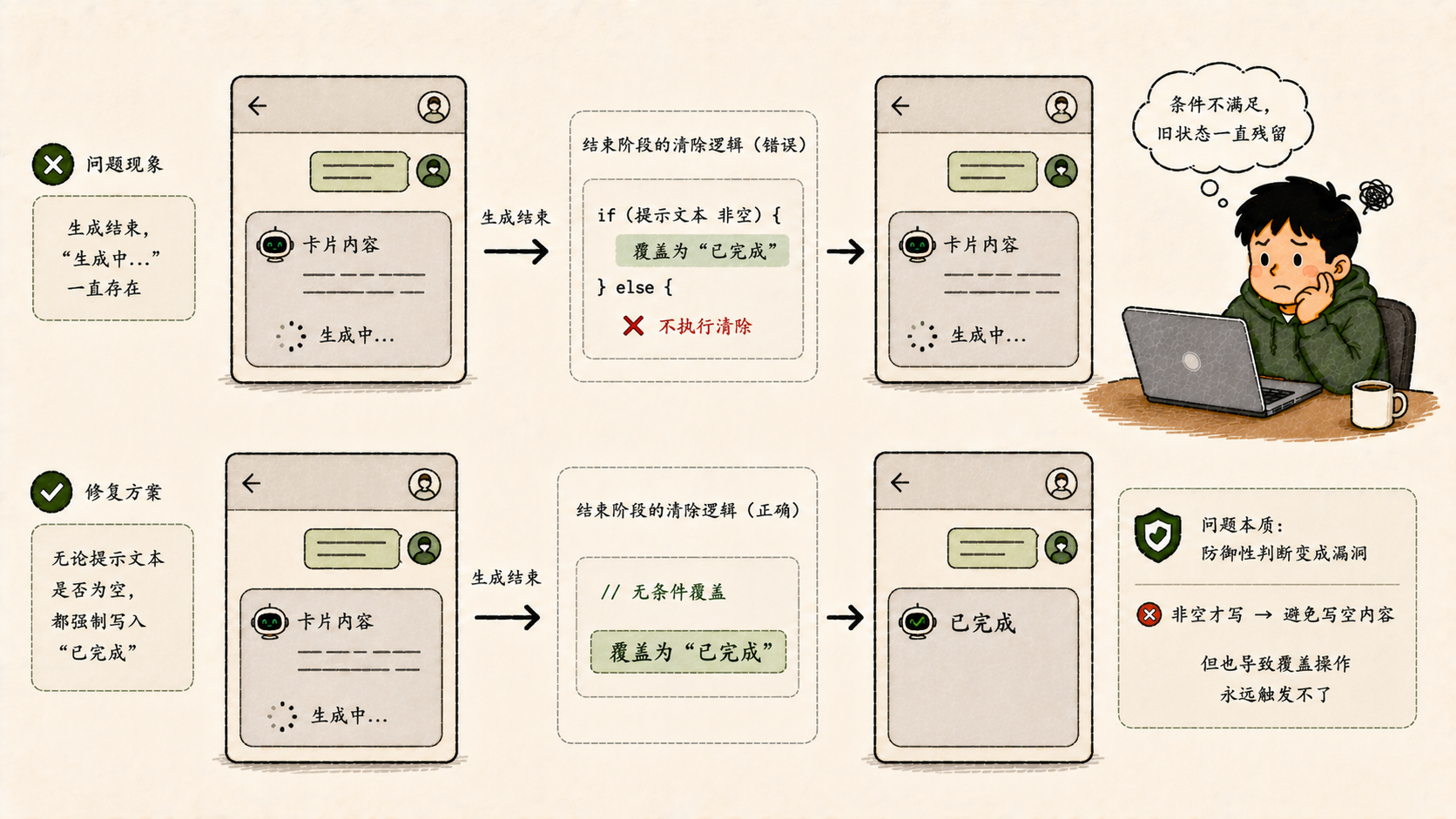
消息渠道里的流式卡片,在AI生成内容时会显示"生成中..."的提示。等生成结束,这段提示应该消失,换成"已完成"。有一段时间,部分场景下"生成中..."会一直留在卡片上。
根因是:结束阶段的清除逻辑有一个条件判断------"只有提示文本非空时才覆盖"。而在某些配置下,这个提示文本可能一直是空字符串,条件不满足,清除就不执行,旧的"生成中..."永远不会被替换掉。
修法:结束阶段不管提示文本是否为空,都强制写一次"已完成"。
这类Bug的本质是防御性判断变成了漏洞: "非空才写"是为了避免写空内容,但这个保护条件本身成了覆盖操作永远触发不了的原因。
三、日志巡检:主动发现沉默的错误
这一天最重的修复,来自一轮日志巡检。
"日志巡检"这件事值得单独说。很多团队的日志策略是被动的:出了问题去查日志。主动巡检是另一种模式------定期扫日志里的错误族,把沉默但持续发生的错误找出来集中修掉,不等它变成用户投诉或服务中断。
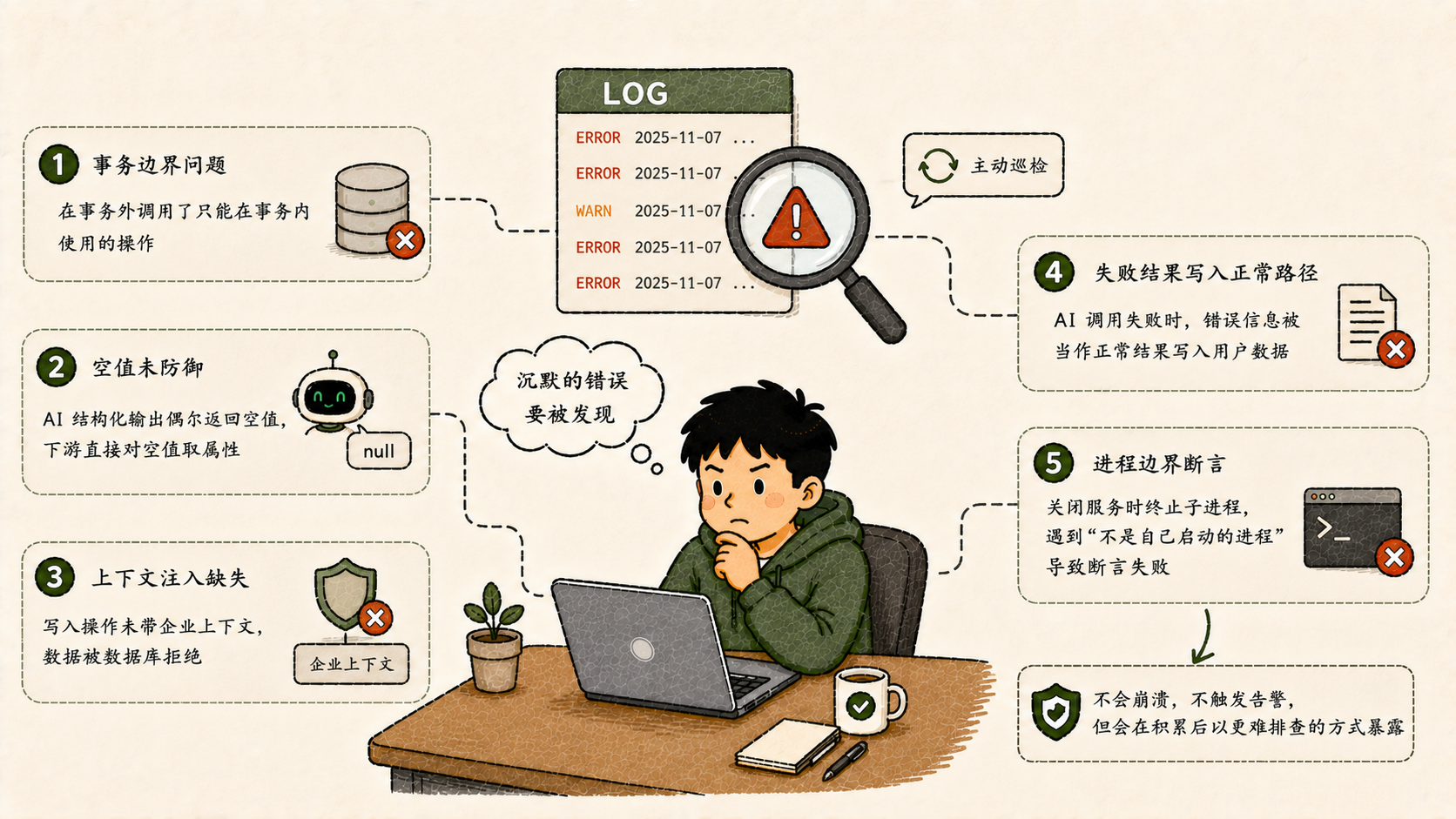
这次巡检找出了5个错误族:
-
事务边界问题:在事务外调用了只能在事务内使用的操作,引发数据库报错,通常被异常捕获静默吞掉。
-
空值未防御:AI做意图分类时,结构化输出偶尔返回空值,下游代码直接对空值取属性触发运行时错误------现实中LLM输出不可能百分之百符合预期,下游必须做空值保护。
-
上下文注入缺失:多租户数据库开启行级安全后,写入操作必须带企业上下文,否则被数据库直接拒绝。某些写入路径没注入上下文,导致数据悄悄丢失,不报错,只是空。
-
失败结果写入正常路径:AI调用失败时,错误信息(比如超时报错)被当作正常结果写进了用户数据里,导致内容中出现奇怪的技术报错文本。修法是失败时什么都不写。
-
进程边界断言:服务关闭时尝试终止子进程,遇到"不是自己启动的进程"时断言失败,后续清理被跳过。修法是捕获异常,确保清理流程继续执行。
这5个错误都不会让系统崩溃,都不会触发告警------直到某一天问题累积到一定程度,才会以另一种更难排查的形式暴露出来。这就是主动巡检的价值所在。
四、容量兜底与资源清理
语音转写功能常驻了一个识别模型。实测下来,模型本身的内存占用加上转写峰值,已经接近原有的内存上限。没有留余量的系统在压力下会触发OOM被强制重启。
这次把对应服务的内存上限翻倍,作为容量兜底------在性能分析精确之前,先保证不崩。
同期也排查了消息服务和进程在关闭时的清理逻辑,补上了资源释放遗漏。

不是优化,是止血。
7个提交,1次发版,覆盖了token缓存、流式状态、事务边界、空值防御、上下文注入、记忆污染、进程清理、容量容量8个不同层面的问题。
没有新功能。全是让系统能够更稳定地运行下去的工作。
这,是第六十天。
**《从0到1:企业级AI项目迭代日记》**记录一个企业级 AI 项目从创意、架构到落地的真实过程。不讲神话,只记录进化。
如果你也在做企业 AI 落地,欢迎留言来聊。或者,把这篇转发给一个正在踩同样坑的朋友。