设备曲线一旦进入生产判断,就不再只是"看个趋势"。一条温度曲线会影响巡检节奏,一段电流波动可能触发告警,一次能耗预测也可能进入排班和调度流程。安全可靠落到时序分析里,不能只看模型能不能给出预测值,还要看数据从哪里来、处理过程能不能复盘、预测结果能不能追溯。
政策层面对数据和人工智能的要求已经很清楚:数据要依法合规使用,生成式人工智能服务也强调发展和安全并重,鼓励安全可信的基础设施、工具和数据资源。对工业时序场景来说,这些要求最终会落到一批很具体的工程动作上:数据清洗、权限隔离、质量评估、模型调用记录、异常处置记录、预测结果回放。
TimechoAI 的切入点在这里比较自然。官方产品页把它定位为基于 Timer 系列时序大模型的云服务,能力覆盖自然语言问答、趋势预测、异常检测与 API/SDK 集成。它不是替代现场规则,也不是替代数据治理,而是把时序数据从"只能看历史曲线"推进到"能预测、能分析、能接入系统"的阶段。
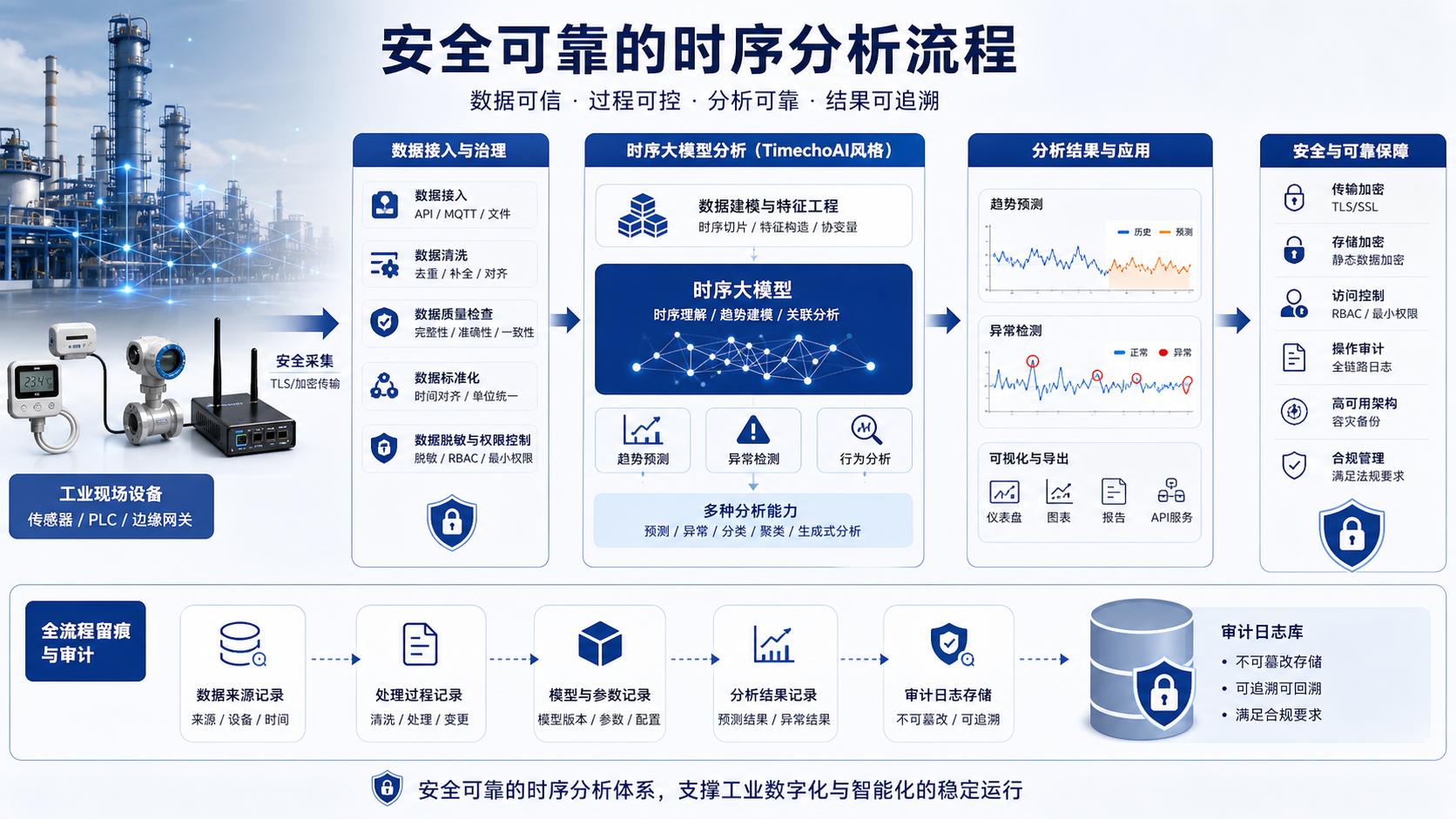
这套流程可以拆成四层:数据可信、过程可控、分析可靠、结果可追溯。只要其中一层缺失,时序大模型的结果就很难进入长期使用。
先把数据可信做扎实
TimechoAI 官方页面提到支持手动输入、绘制曲线、上传 CSV,也支持围绕 TsFile 做数据组织。上手阶段用 CSV 最直接,但不要把 CSV 当成随手上传的临时文件。时序数据最容易出问题的地方通常不是字段名,而是时间戳乱序、采样间隔不一致、缺失值集中、异常值混在正常窗口里。

可以先准备一份简单的设备数据,包含时间、温度、振动、电流和工况标记。真正上传之前,在本地做一次质量检查。
python
import pandas as pd
df = pd.read_csv("device_timeseries.csv")
df["time"] = pd.to_datetime(df["time"])
df = df.sort_values("time").drop_duplicates("time")
required = ["temperature", "vibration", "current"]
for col in required:
if col not in df.columns:
raise ValueError(f"missing column: {col}")
series = (
df.set_index("time")["temperature"]
.asfreq("15min")
)
quality = {
"points": int(series.shape[0]),
"missing": int(series.isna().sum()),
"missing_ratio": float(series.isna().mean()),
"start": str(series.index.min()),
"end": str(series.index.max()),
}
print(quality)这段代码不是为了炫技,而是把预测前的状态固定下来。缺失率、起止时间、采样粒度都应该先有记录。后面预测效果不好时,不能只问模型准不准,也要回看输入窗口是不是已经有问题。
如果缺失点很少,可以做线性插值;如果连续缺失一大段,建议先标记数据质量异常,不要直接补齐后进入预测。
python
clean_series = series.interpolate(limit_direction="both")
data_window = clean_series.tail(256)
if data_window.isna().any():
raise ValueError("data window still contains missing values")
payload_target = data_window.round(4).tolist()TimechoAI 官方页面还提到数据集管理支持数据可视化分析、质量评估,并从完整性、一致性、有效性、时效性等维度评估数据质量。这个能力更适合放在预测之前,而不是等结果异常后再补救。
预测调用要把参数讲清楚
TimechoAI 的时序预测支持纯目标变量、历史协变量、未来协变量三种方式。这个设计对工业数据很有用。只看温度本身可以做初步预测;加入电流、振动、阀门开度等历史协变量后,模型能看到更多工况背景;如果未来排产计划、天气预报、节假日信息是已知的,也可以作为未来协变量参与预测。
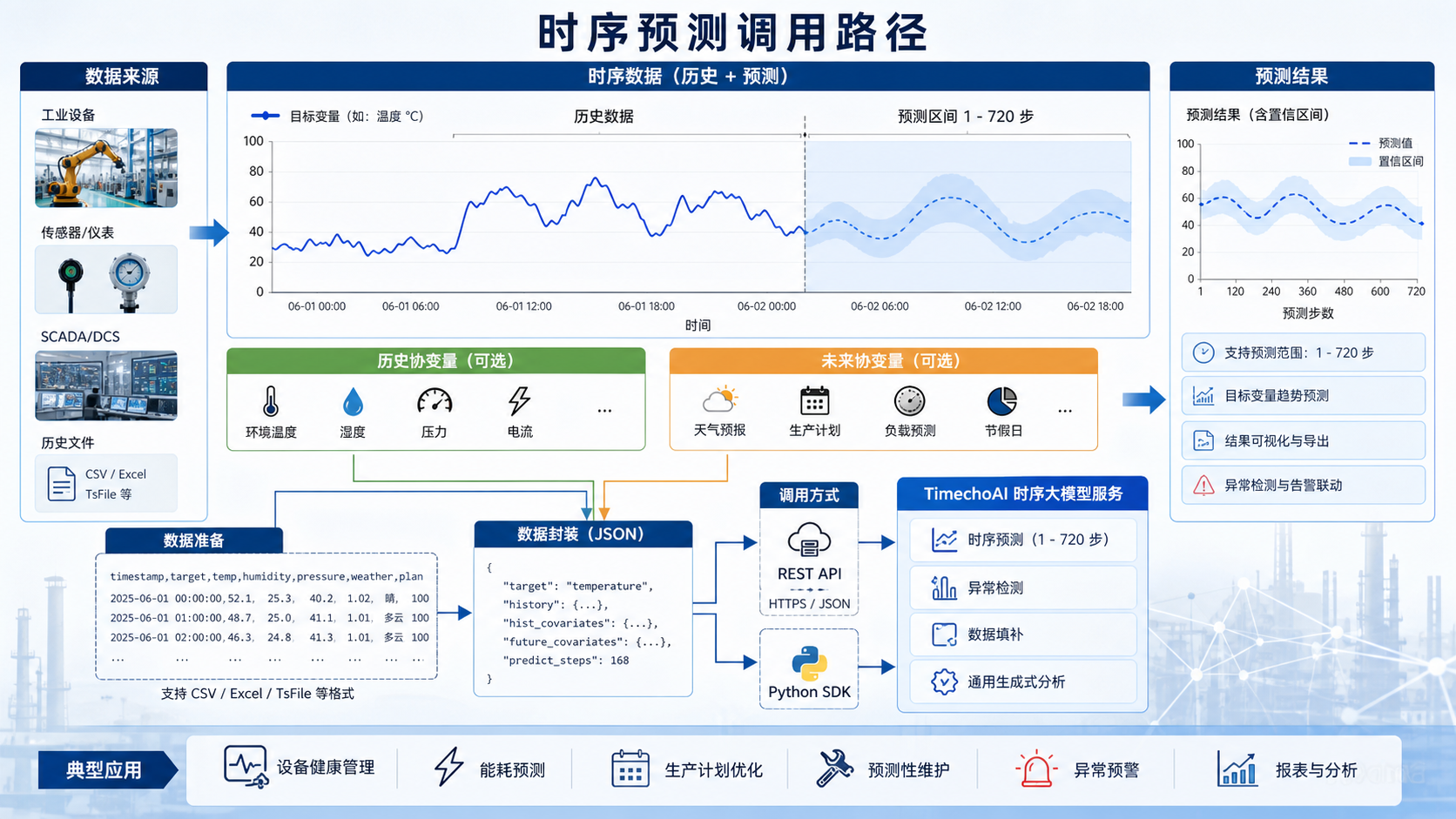
预测步长不能随便写。15 分钟采样预测 96 步,就是未来一天;1 分钟采样预测 720 步,则是未来 12 小时。官方页面提到 TimechoAI 支持 1 到 720 步预测范围,实际使用时要把这个参数和业务时间窗口对应起来。
接口路径和字段名以 TimechoAI 官方文档为准,代码里可以先把 endpoint 做成环境变量,避免把未确认路径写死。
python
import os
import requests
BASE_URL = os.getenv("TIMECHOAI_BASE_URL", "https://ai.timecho.com")
API_KEY = os.environ["TIMECHOAI_API_KEY"]
FORECAST_PATH = os.getenv("TIMECHOAI_FORECAST_PATH", "/<official-forecast-path>")
payload = {
"mode": "target_only",
"time_unit": "15min",
"horizon": 96,
"target": payload_target,
}
resp = requests.post(
BASE_URL.rstrip("/") + FORECAST_PATH,
headers={"Authorization": f"Bearer {API_KEY}"},
json=payload,
timeout=30,
)
resp.raise_for_status()
forecast_result = resp.json()纯目标变量跑通后,再加入协变量会更稳。协变量的时间轴要和目标变量对齐,不能一个字段是 15 分钟采样,另一个字段是小时级采样却直接混在一起。
python
features = (
df.set_index("time")[["temperature", "vibration", "current"]]
.asfreq("15min")
.interpolate(limit_direction="both")
)
window = features.tail(256)
payload = {
"mode": "with_covariates",
"time_unit": "15min",
"horizon": 96,
"target": window["temperature"].round(4).tolist(),
"history_covariates": {
"vibration": window["vibration"].round(4).tolist(),
"current": window["current"].round(4).tolist(),
},
"future_covariates": {}
}未来协变量要谨慎。比如天气预报、排产计划、节假日标记属于预测窗口内可以提前获得的信息;未来的设备振动值并不知道,就不能假装已经知道。这个边界处理不好,验证阶段看起来效果不错,接入真实系统后会立刻失真。
异常检测适合放在预测前后
安全可靠的分析流程不能只做预测。固定阈值只能抓住"超过上限"的问题,很多设备风险更像缓慢偏移:振动轻微变大、电流逐步抬升、温度在同一班次后持续偏高。Timer 官方页面提到异常检测能力,TimechoAI 产品页也把异常检测放在核心能力里。
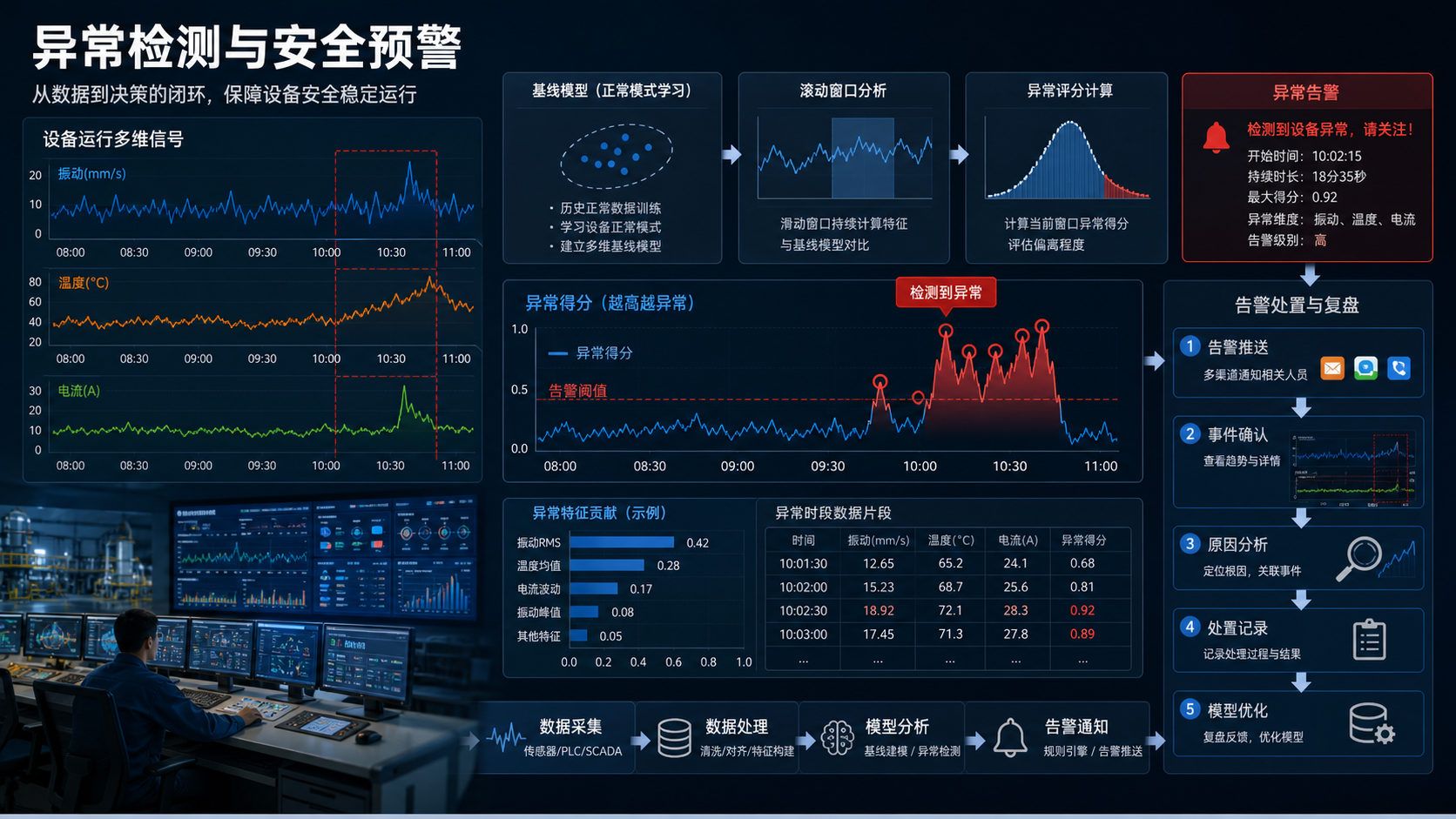
异常检测可以放在预测前,先判断输入窗口里是否已经有异常;也可以放在预测后,观察未来曲线是否会持续进入风险区间。接口结构同样以官方文档为准,调用层可以先封装成统一函数。
python
ANOMALY_PATH = os.getenv("TIMECHOAI_ANOMALY_PATH", "/<official-anomaly-path>")
def call_timechoai(path, payload):
response = requests.post(
BASE_URL.rstrip("/") + path,
headers={"Authorization": f"Bearer {API_KEY}"},
json=payload,
timeout=30,
)
response.raise_for_status()
return response.json()
anomaly_payload = {
"series": window["temperature"].round(4).tolist(),
"window": 32,
"sensitivity": "medium",
}
anomaly_result = call_timechoai(ANOMALY_PATH, anomaly_payload)异常结果不要只保存一个布尔值。更合适的做法是保存异常分数、时间段、原始值和触发阈值,后面才能回看。
python
def collect_anomaly_points(index, values, scores, threshold=0.8):
rows = []
for ts, value, score in zip(index, values, scores):
if score >= threshold:
rows.append({
"time": ts.isoformat(),
"value": float(value),
"score": float(score),
"threshold": threshold,
})
return rows
scores = anomaly_result.get("scores", [])
recent_index = window.tail(len(scores)).index
recent_values = window["temperature"].tail(len(scores)).values
anomaly_points = collect_anomaly_points(recent_index, recent_values, scores)
print(anomaly_points[:5])这类记录对安全可靠很关键。告警不能只留一句"模型认为异常",而要保留它为什么异常、异常发生在哪段数据、当时的输入窗口是什么。
结果留痕比一次预测更重要
时序大模型的预测结果如果进入看板、巡检或告警,就需要留痕。留痕不是为了增加复杂度,而是为了在结果被使用后还能回答几个问题:谁发起了预测,使用了哪段数据,预测步长是多少,模型版本是什么,结果有没有被导出或触发规则。
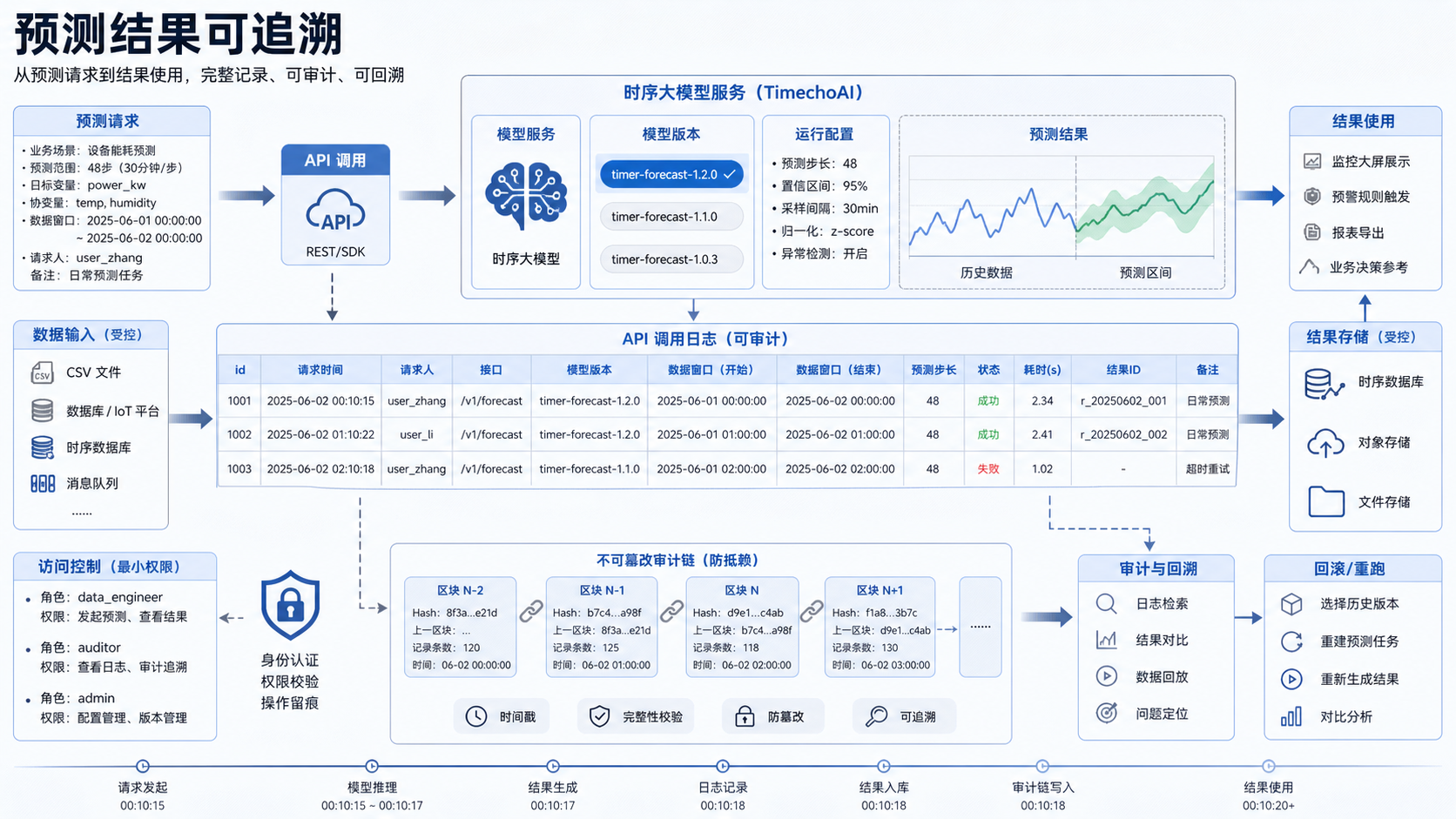
可以先设计两张简单的表,一张记录请求,一张记录预测点。真实系统里字段会更多,但最小版本要覆盖输入窗口、模型版本和调用状态。
sql
CREATE TABLE ai_forecast_request (
id BIGINT PRIMARY KEY,
measurement VARCHAR(128) NOT NULL,
data_start TIMESTAMP NOT NULL,
data_end TIMESTAMP NOT NULL,
time_unit VARCHAR(32) NOT NULL,
horizon INT NOT NULL,
model_name VARCHAR(128),
model_version VARCHAR(128),
request_hash VARCHAR(64) NOT NULL,
status VARCHAR(32) NOT NULL,
created_at TIMESTAMP NOT NULL
);
CREATE TABLE ai_forecast_point (
request_id BIGINT NOT NULL,
forecast_time TIMESTAMP NOT NULL,
predicted_value DOUBLE PRECISION NOT NULL,
lower_bound DOUBLE PRECISION,
upper_bound DOUBLE PRECISION,
created_at TIMESTAMP NOT NULL
);请求哈希可以把输入 payload 固定下来。后面同一条曲线重复预测时,只要哈希一致,就能确认输入窗口没有变化。
python
import hashlib
import json
def build_request_hash(payload):
raw = json.dumps(payload, ensure_ascii=False, sort_keys=True)
return hashlib.sha256(raw.encode("utf-8")).hexdigest()
request_hash = build_request_hash(payload)
print(request_hash)预测结果入库时,时间戳要由历史窗口末尾和采样粒度推出来,不能随手用当前时间代替预测时间。
python
prediction = forecast_result.get("prediction", [])
last_time = window.index[-1]
future_index = pd.date_range(
last_time + pd.Timedelta("15min"),
periods=len(prediction),
freq="15min",
)
forecast_rows = [
{
"forecast_time": ts,
"predicted_value": float(value),
}
for ts, value in zip(future_index, prediction)
]这一步做完,TimechoAI 的预测就不只是页面上的一条曲线,而是进入了可查询、可对比、可复盘的数据流。安全可靠的落点也在这里:不是不允许模型参与判断,而是模型参与之后必须留下足够的工程证据。
一个更稳的最小脚本
把流程串起来,可以先写一个最小脚本。它只做四件事:读取数据、检查质量、调用预测、保存结果。这个脚本跑稳定后,再加入异常检测和批量任务。
python
def load_clean_window(path, column, freq="15min", points=256):
df = pd.read_csv(path)
df["time"] = pd.to_datetime(df["time"])
df = df.sort_values("time").drop_duplicates("time")
s = df.set_index("time")[column].asfreq(freq)
missing_ratio = s.isna().mean()
if missing_ratio > 0.05:
raise ValueError(f"missing ratio too high: {missing_ratio:.2%}")
return s.interpolate(limit_direction="both").tail(points)
def run_forecast(path):
s = load_clean_window(path, "temperature")
payload = {
"mode": "target_only",
"time_unit": "15min",
"horizon": 96,
"target": s.round(4).tolist(),
}
result = call_timechoai(FORECAST_PATH, payload)
return s, payload, result
history_window, request_payload, result = run_forecast("device_timeseries.csv")如果接入到定时任务,建议把失败原因也保存下来。网络超时、鉴权失败、数据质量不合格、返回字段缺失,属于不同问题,不能都写成"预测失败"。
python
def safe_run(path):
try:
history, payload, result = run_forecast(path)
return {
"status": "success",
"hash": build_request_hash(payload),
"points": len(result.get("prediction", [])),
}
except requests.Timeout:
return {"status": "timeout"}
except ValueError as exc:
return {"status": "data_error", "message": str(exc)}
except requests.HTTPError as exc:
return {"status": "http_error", "message": str(exc)}
print(safe_run("device_timeseries.csv"))这一层处理看起来普通,却是时序分析能否长期使用的分界线。只要预测结果会进入告警、巡检、报表,就必须把失败和成功都记下来。
批量分析时别丢掉边界
真实场景里通常不是一条曲线,而是一组设备、一组测点。TimechoAI 提供 Web、REST API、Python SDK 多种接入方式,适合先用页面验证,再用接口做批量任务。批量任务要控制边界:每条曲线单独校验,单条失败不影响其他测点。
python
measurements = {
"pump_01.temperature": "temperature",
"pump_01.vibration": "vibration",
"pump_01.current": "current",
}
batch_series = []
for name, column in measurements.items():
try:
s = load_clean_window("device_timeseries.csv", column)
batch_series.append({
"name": name,
"target": s.round(4).tolist(),
})
except ValueError as exc:
print(name, exc)
batch_payload = {
"mode": "batch_target_only",
"time_unit": "15min",
"horizon": 96,
"series": batch_series,
}批量分析的结果也要按测点拆开保存。否则后面某个设备报警时,只能翻一整个 JSON,很难定位到对应数据窗口。
总结
围绕安全可靠做时序分析,不是给模型外面套一层口号,而是把每个环节都写实:数据质量先检查,预测参数讲清楚,异常检测留分数,结果入库可追溯。TimechoAI 的价值在于,它把时序预测、异常检测、数据集管理和 API/SDK 接入放到了同一个使用路径里。对已经积累了大量传感器曲线的团队来说,可以先从一条曲线、一份 CSV、一个预测窗口开始,把流程跑通,再逐步扩展到协变量、批量测点和告警联动。
这条路径不会替代数据治理,也不会替代现场判断。它更适合作为时序分析能力的一层增强:让历史曲线能够进入预测,让异常偏离能够被提前发现,让模型结果能在系统里留下证据。
企业版官方链接:https://timecho.com
时序大模型 TimechoAI:https://ai.timecho.com/