聊反羊毛之前,先说一件我们踩过的事。
去年双11,我们做了一个「新用户注册送50元无门槛券」的拉新活动。上线前大家都挺乐观,预算给足了,目标是新增10万用户。
结果活动上线6个小时,监控报错:2万多张优惠券被领走,真实成交几乎没有。
很明显,被薅了。而且薅得不轻。
第一步:复盘,问题出在哪?
初步排查时,几个现象很刺眼:
手机号全是新号,验证码基本通过接收平台秒过。
行为路径高度一致:注册、领券、退出,没有后续浏览和下单。
设备信息看起来又都不一样,传统基于手机号或设备ID的规则没挡住。
当时我们才意识到,之前一直在看「账号是不是正常」,但漏了一个很重要的问题:请求本身是不是来自正常网络环境。
只看账号信息,很难看出问题。但如果在入口就能识别出「这个请求来自数据中心IP」「这个IP短时间内频繁切换地理位置」,很多异常其实可以更早被拦下来。
在本次复盘分析中,我们截取了一段异常流量数据,并与活动前的正常用户数据进行了对比。
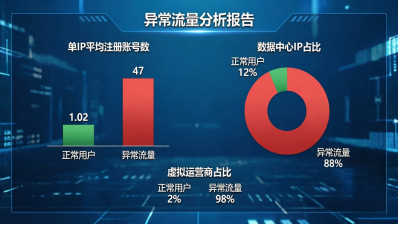
第二步:方案设计,IP查询加设备指纹双引擎
后来我们重新设计了风险识别方案,思路很直接:IP查询加设备指纹联动。
IP侧做什么?
IP侧主要回答一个问题:这个请求来自什么样的网络环境?
我们接入了IP数据云的离线库,本地查询,毫秒级返回,重点看这些字段:
# IP查询返回数据结构
{
"ip": "123.45.67.89",
"location": {
"country": "中国",
"province": "浙江省",
"city": "杭州市"
},
"network": {
"net_type": "数据中心", # 数据中心/住宅/移动/教育网
"asn": "AS37963",
"isp": "阿里云"
},
"risk": {
"risk_score": 85, # 0-100综合风险评分
"proxy": True,
"risk_tag": ["垃圾注册", "薅羊毛", "网络异常设备"]
}
}这里真正有用的不是单个字段,而是组合判断。net_type、proxy、risk_score、risk_tag放在一起,IP查询就不只是查地址,而是在判断网络身份和风险。
比如同样是杭州的IP,一个来自住宅宽带,一个来自数据中心IP,风险识别意义天差地别。
设备指纹侧做什么?
设备指纹解决另一个问题:这个设备是不是真实、稳定、唯一。
我们重点看这些信息:
# 设备指纹关键检测字段
device_fingerprint = {
"device_id": "abc123def456",
"is_emulator": False, # 是否为模拟器
"id_change_freq": 1, # 近7天设备ID变更次数
"account_count": 3, # 该设备关联账号数
"rooted": False, # 是否root或越狱
"first_seen": "2026-07-01"
}单看设备指纹也不够。羊毛组织会换设备ID、跑模拟器、改环境参数。这只能挡一部分,无法全部分辨。
IP查询和设备指纹联动分析
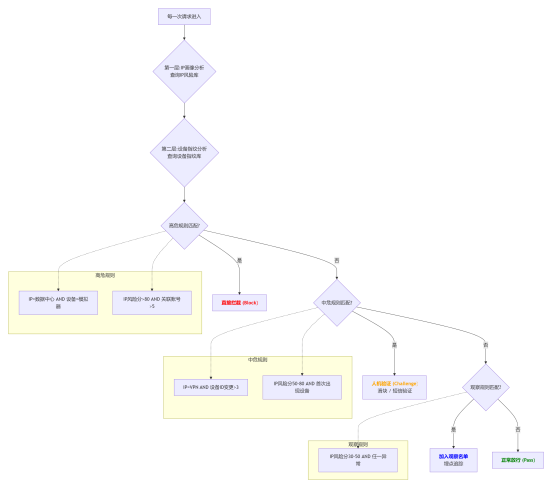
核心决策伪代码如下:
def risk_decision(ip_info, device_info, request_context):
"""IP加设备指纹联动决策引擎"""
risk_score = ip_info.get("risk_score", 0)
net_type = ip_info.get("net_type")
is_proxy = ip_info.get("is_proxy", False)
account_count = device_info.get("account_count", 1)
is_emulator = device_info.get("is_emulator", False)
# 规则1:数据中心IP加模拟器等于直接过滤掉
if net_type == "数据中心" and is_emulator:
return {"action": "BLOCK", "reason": "机房IP加模拟器组合", "code": "R001"}
# 规则2:高风险评分加多账号关联等于直接进行过滤
if risk_score > 80 and account_count > 3:
return {"action": "BLOCK", "reason": "高风险IP加多账号关联", "code": "R002"}
# 规则3:虚拟专用网络加设备频繁变更等于强验证
if is_proxy and device_info.get("id_change_freq", 0) > 3:
return {"action": "CHALLENGE", "challenge_type": "滑块验证", "code": "C001"}
# 规则4:10分钟内同一IP注册超过30次则加入观察名单
if request_context.get("ip_register_count_10min", 0) > 30:
add_to_watchlist(ip_info.get("ip"))
return {"action": "RATE_LIMIT", "code": "L001"}
# 默认:低风险放行
return {"action": "PASS", "code": "P000"}【IP归属地查询和IP风险识别 ipdatacloud.com】
第三步:上线后的效果
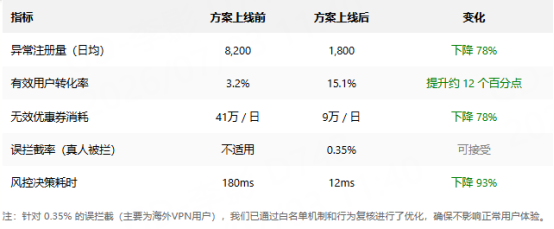
除了上述效果外,还有一个变化十分显著:过去活动结束后,运营复盘往往需要花费数天时间;而现在由于前期阻拦更为彻底,后续分析异常流量的工作也轻松了不少。
第四步:几个实战心得
第一,IP查询不能只查归属地。
只知道IP归属地远远不够。要看这个IP是数据中心还是家庭宽带,有没有历史风险标签。归属地、网络类型、代理检测、风险评分、风险标签组合起来,才更接近完整的IP风险画像。
我们最终选型时,重点看这些能力:

第二,离线库在生产环境里很重要。
双11这种流量峰值,每秒几万笔请求并不夸张。在线API一旦遇到延迟、限流或者网络抖动,风险识别链路就会被拖慢。离线库部署在本地,查询基本就是内存读取,延迟稳定,数据也不出内网。对金融级IP离线库来说,本地化部署基本要纳入选型。
第三,规则需分层设计,避免"一刀切"。
我们将处置策略划分为三个等级:
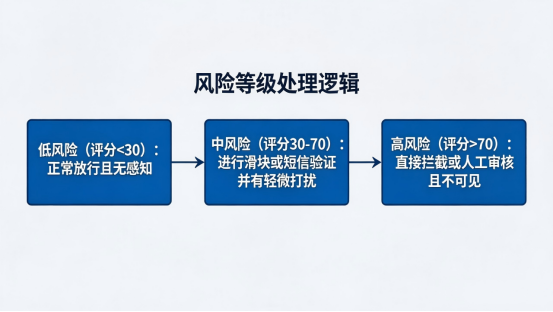
真实业务里,误杀比漏放更麻烦。能验证的尽量验证,明显异常的再标记查封。
第四,数据更新频率建议日更。
动态IP池变化太快,周更数据很容易跟不上。尤其是秒拨IP,今天看着正常,明天可能就被拿去大规模注册。日更的离线库能更好地保持IP归属地查询和风险画像的准确性。
第五,数据处理要合规。
设备指纹、原始设备ID、IP行为日志都涉及用户数据。能脱敏的先脱敏,能哈希的先哈希,权限也要收紧。风险识别要有效,但不能把合规问题留到最后才补。
最后说两句
这次之后,我们对反羊毛的理解变了。
以前更关注账号、手机号、设备ID这些显性信息,后来发现,请求从哪里来、网络环境是否可信,同样重要。IP地址不只是辅助字段,它在很多场景下就是第一道筛选信号。
反羊毛不能只靠某一个技术点。IP查询、设备指纹、行为规则要放在一起看,效果才会稳定。
我们现在接入的是IP数据云的IP离线库,同时支持IP归属地查询和企业级IP风险识别能力。这套方案已经跑了几个月,整体比较稳,至少没有再出现双11那种优惠券被集中薅走的情况。