大模型分享会讲稿:理解上下文,理解大模型
2026年07月03日 公司内部分享会的内容,整理成讲稿分享给大家,分享一些基础概念。
开场
各位好,今天我们不聊那些花哨的应用,也不谈遥远的 AGI,我们只做一件事:把大模型这个"黑盒子"打开一条缝,让大家真正理解它到底是怎么工作的。
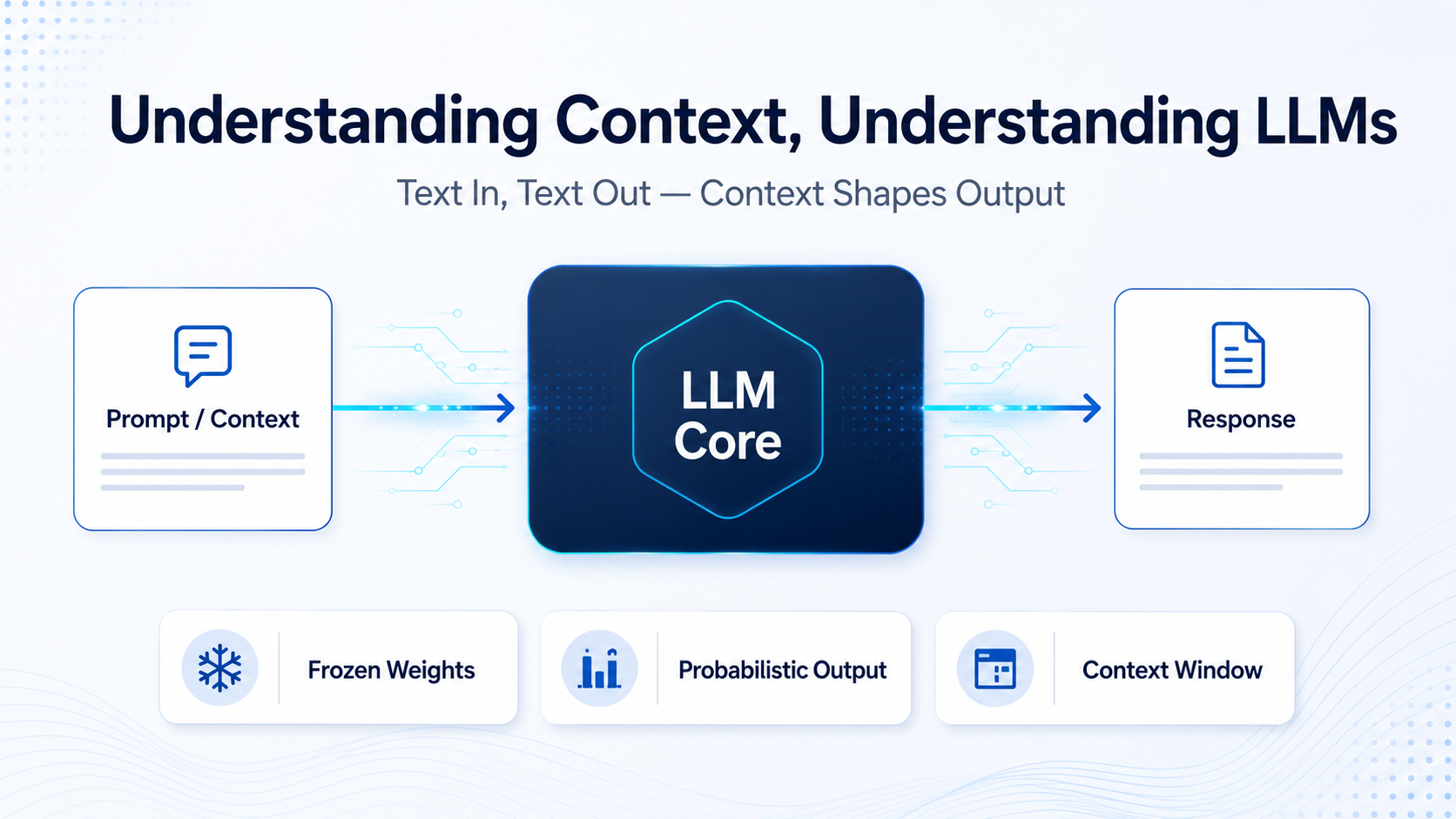
我希望大家听完这次分享后,能建立三个核心认知:第一,大模型的能力在训练完成后就固定了;第二,它本质上只做一件事------文字进,文字出(Text in, Text out);第三,也是最重要的,我们的输入(也就是上下文)会极大地、决定性地影响它的输出。
理解了这三点,你就理解了为什么"提示词工程"如此重要,也理解了我们该如何与这个工具打交道。
第一部分:大模型是什么?结构 + 权重
我们现在说的大模型,基本都是基于深度学习的。你可以把一个大模型理解成由两样东西构成:结构 和权重 。
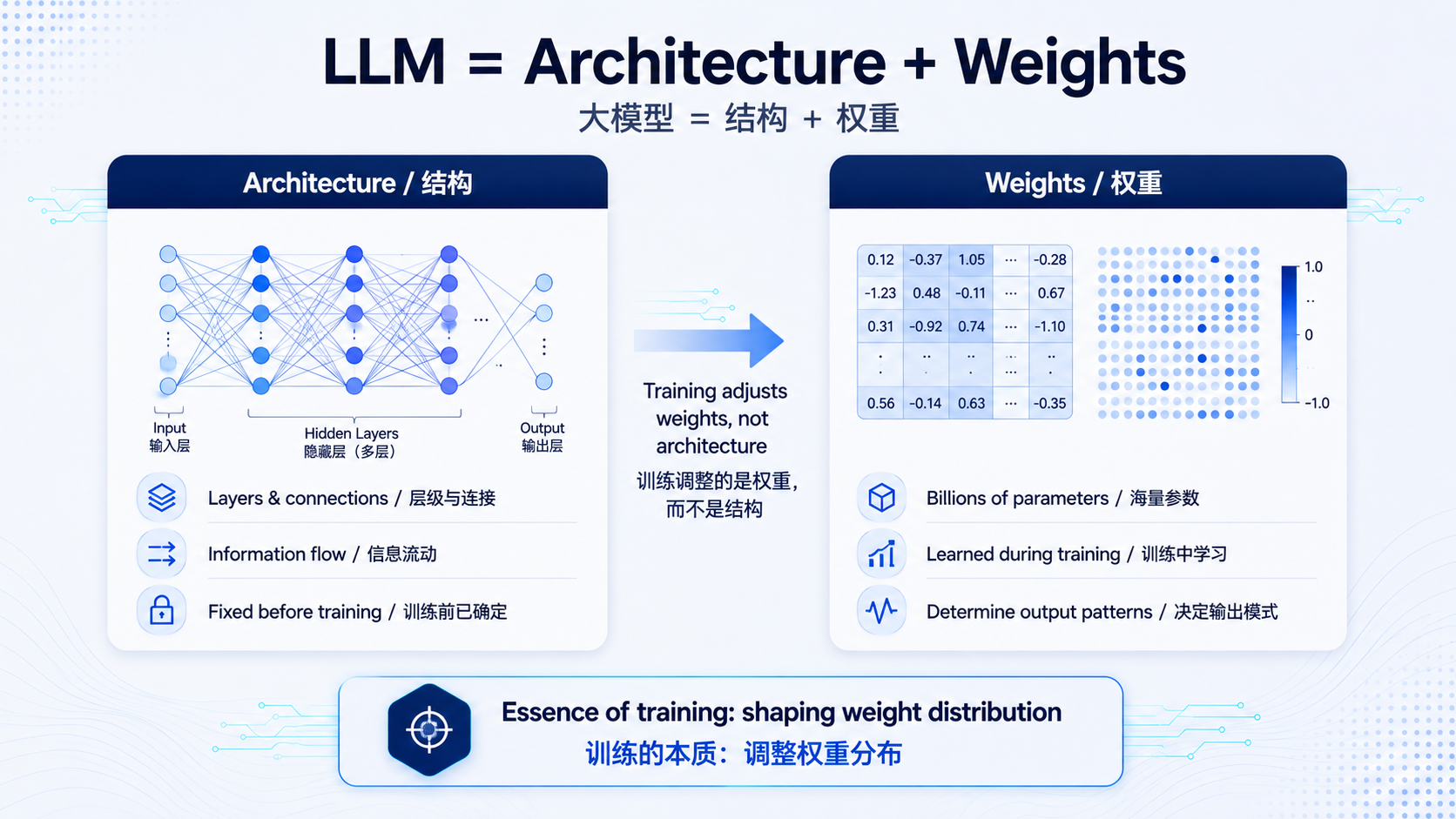
结构就好比一个人的骨架,决定了这个模型有多少层、每一层怎么连接、信息怎么流动。这套结构一旦设计好,在训练前就定下来了。
权重则是挂在这套骨架上的无数个数字参数。所谓"千亿参数大模型",说的就是这里有上千亿个权重数字。
那这些权重是怎么来的?这就是"训练"要干的事。厂商会准备海量的语料、海量的问答对,然后不断地喂给模型:给它一个输入,看它输出什么,再拿输出和"标准答案"对比,如果错了,就微微调整那些权重数字,让它下次的输出更接近期望结果。
这个过程重复亿万次之后,所有的权重就被"调教"到了一个特定的分布状态。说白了,训练的本质,就是在调整这些权重数字的分布。而权重的分布,最终决定了"什么样的输入会产生什么样的输出"。
这里我要强调一个关键结论:训练一旦完成,这个模型就"石化"了。 它的所有知识、所有能力,全部凝固在这堆权重数字里,永远不会再变。它不会因为跟你聊了一下午就变聪明,也不会记住昨天你教它的东西。你今天用的模型,和明天用的同一版本模型,是一模一样的。
第二部分:它只做一件事------把数字变成数字
现在我们看看,当你输入一句话时,里面到底发生了什么。
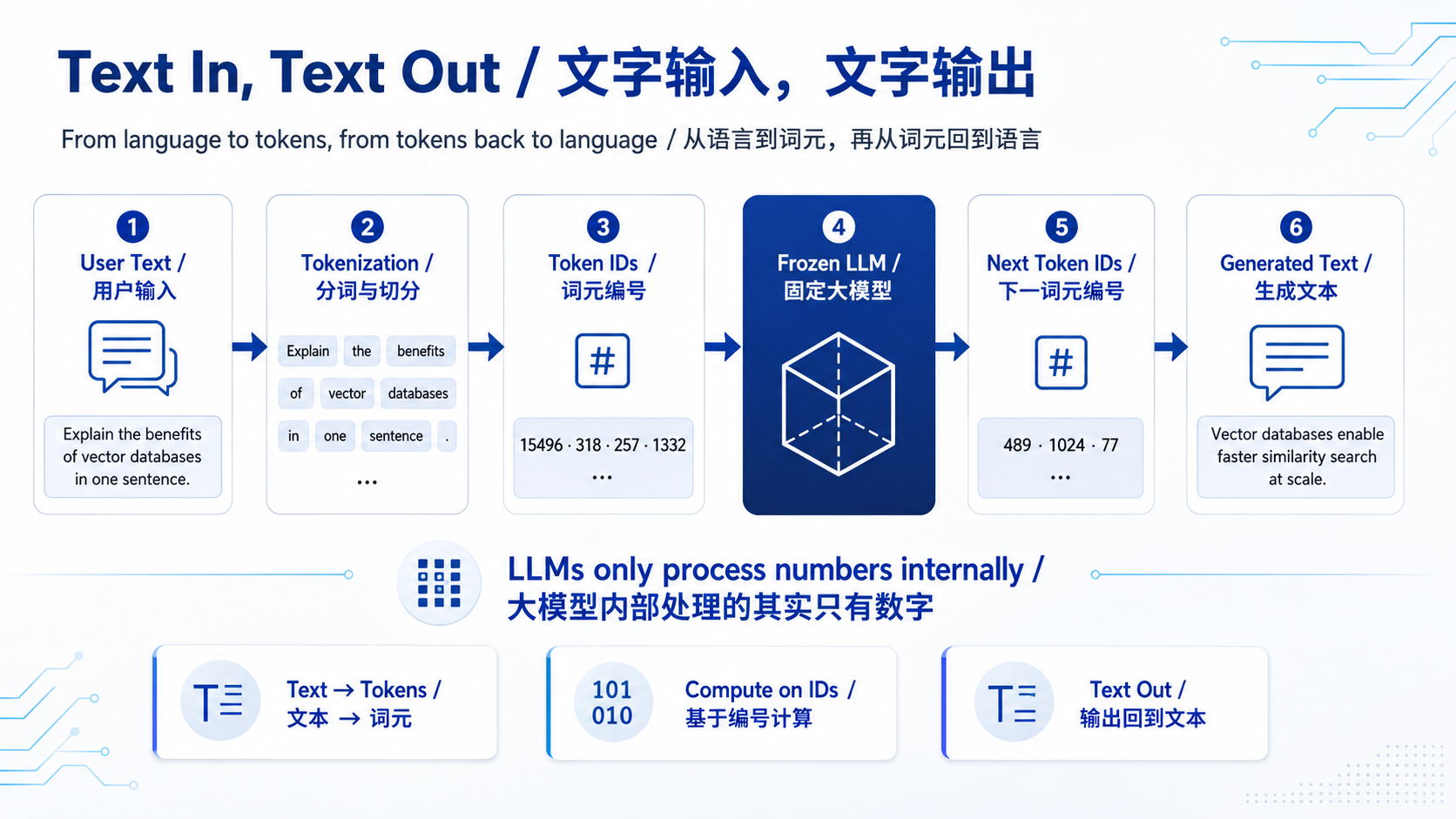
大模型其实根本"看不懂"文字。它能处理的只有数字。所以你输入的每一句话,都会先被切成一个个小片段,这些片段有个专门的名字,叫 Token(词元)。
(注:你之前说的"转换成资源",准确的说法是转换成 Token。这个词很重要,后面我们算"上下文大小"全靠它。)
每一个 Token 都会被换成一个数字编号。所以你的一整句话,进入模型时,其实就是一串数字。
模型拿到这串数字后,经过内部那堆权重的层层运算,最终吐出另一串数字。这串数字再被翻译回文字,就成了你看到的回答。
所以请大家记住这个最朴素的真相:
大模型的本质,就是一个"数字进,数字出"的函数。对我们用户来说,表现为"文字进,文字出"(Text in, Text out)。
它不联网、不查数据库、不会自己打开计算器、也不会主动去调用任何程序。它唯一会的,就是根据你给的这串数字,算出下一串数字。
(延伸说明:现在大家看到的 AI Agent、能调用工具、能搜索、能写代码执行------那些能力都是外面的程序 在做的。外部程序把模型输出的文字解析出来,替它去执行动作,再把结果当成新的文字喂回给模型。模型自己始终只是那个"文字进文字出"的核心。这个认知非常重要,它能帮你分清"模型的能力"和"产品的能力"。)
第三部分:为什么同样的问题,答案每次不一样?
这是今天最有意思的一个问题,也是很多人困惑的地方。
刚才说了,训练完的模型是固定的。那按理说,我输入一个 A,它应该永远输出同一个 B 才对,就像一个写死的函数一样。可为什么我问同一个问题,它每次回答都不太一样?
答案在于:大模型的推理是基于概率的。
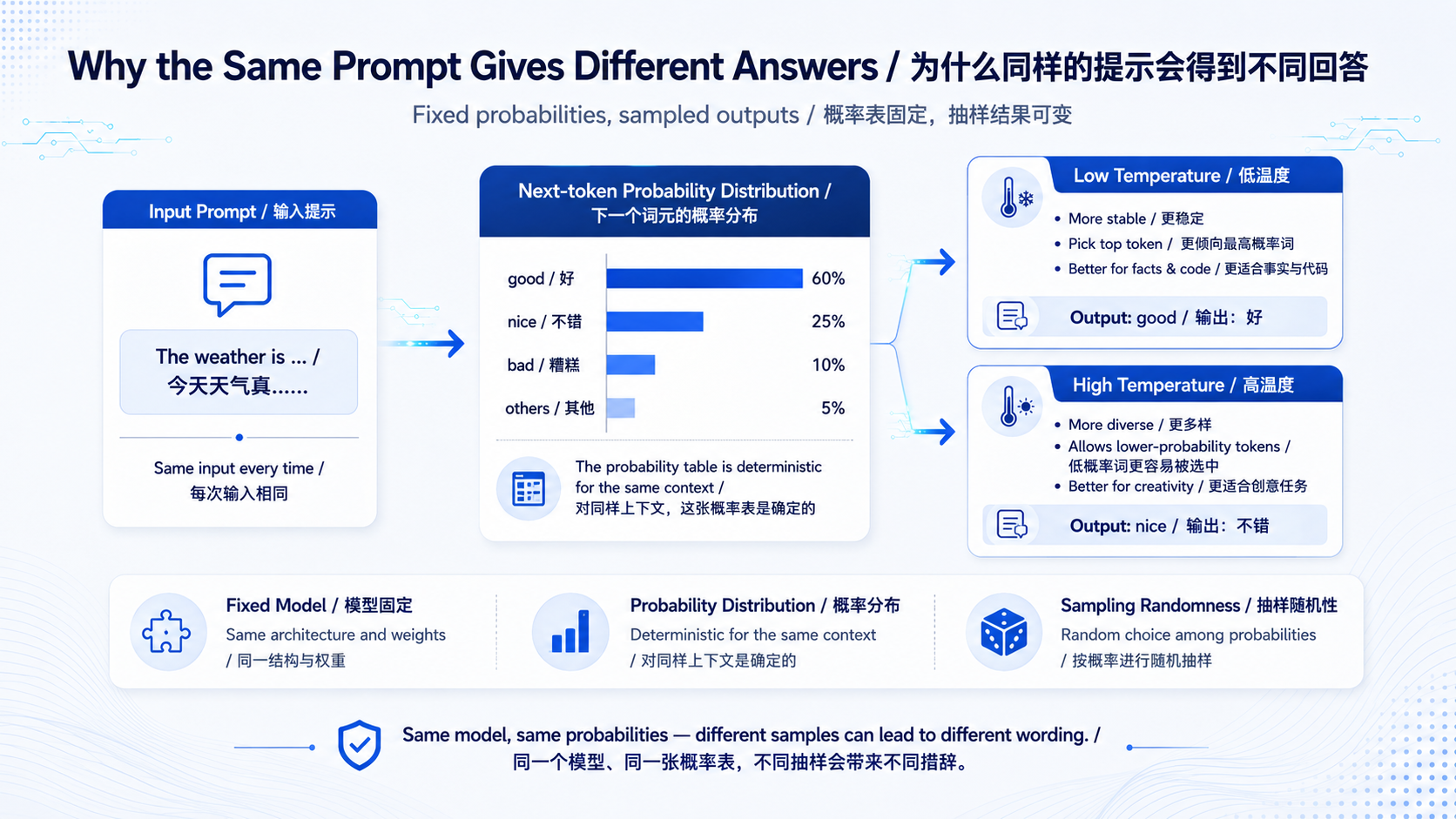
模型算出下一个 Token 时,它给出的不是一个确定的答案,而是一张"概率表"。比如你问"今天天气真",模型可能会算出:
- "好" ------ 概率 60%
- "不错" ------ 概率 25%
- "糟糕" ------ 概率 10%
- 其他各种词 ------ 剩下的 5%
注意,这张概率表本身是完全确定的------同样的输入,模型每次算出的这张表都一模一样。这一点和它"石化"的特性完全不矛盾。
但是!最后到底选哪个词输出,是从这张表里按概率抽签决定的。这一抽签,就带来了随机性。
而你说的"温度(Temperature)"这个设置,控制的就是这个抽签的"随机程度":
- 温度低(比如接近 0):几乎永远只选概率最高的那个词。输出更保守、更确定、更可复现。适合做数学、代码、事实问答。
- 温度高:低概率的词也有机会被抽中。输出更发散、更有创意、也更"跳"。适合写诗、头脑风暴。
所以,模型是固定的(概率表是固定的),但抽签过程是随机的(选词是随机的)。这就是为什么同一个 A,你会得到略微不同的 B。这和传统深度学习里那种"输入确定就输出确定"的印象不一样,根源就在这个概率抽样的机制上。
第四部分:核心中的核心------上下文(Context)
好,前面都是铺垫,现在进入今天真正的重点:上下文 。
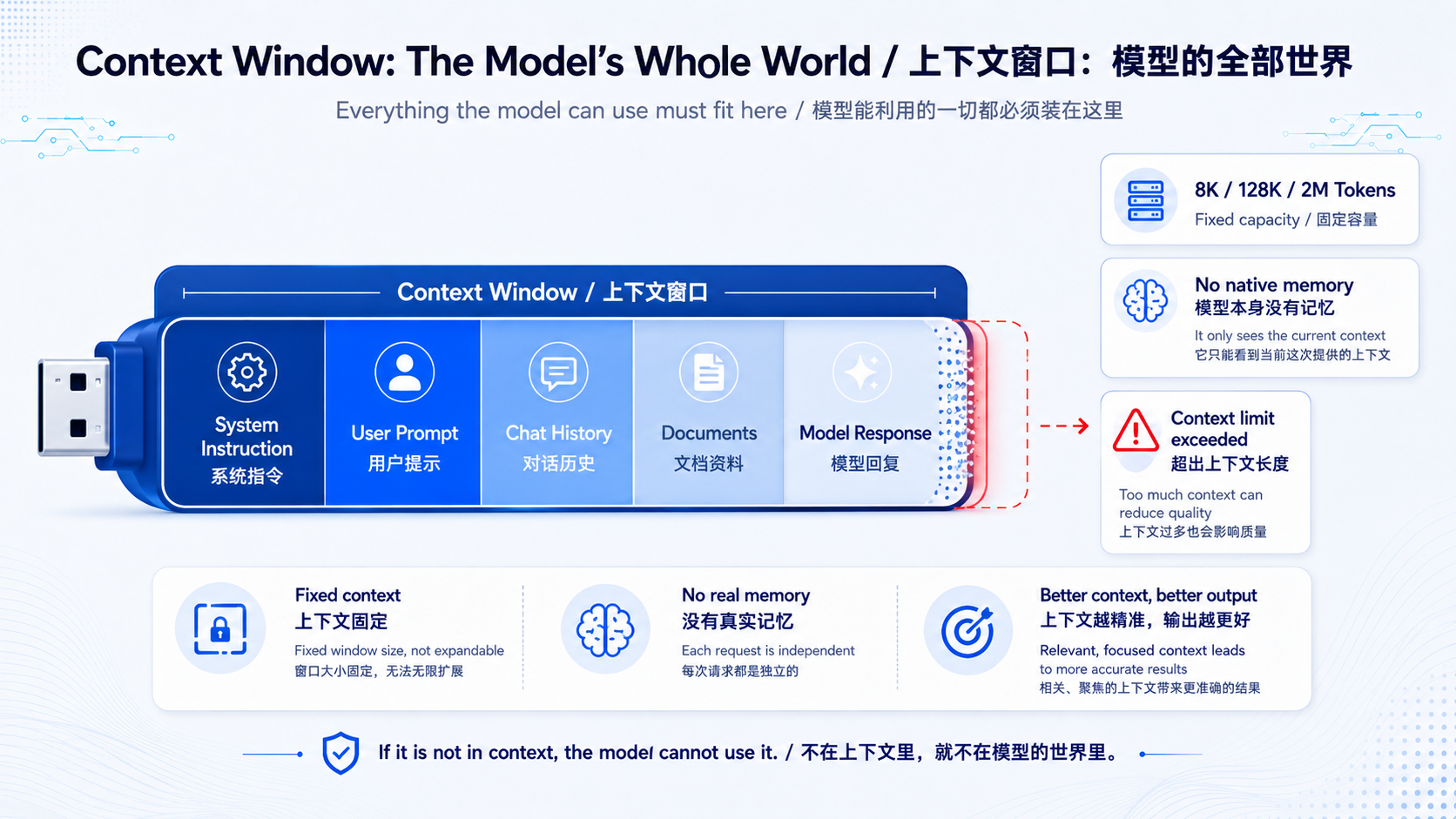
4.1 一个贴切的比喻:一个固定大小的 U 盘
我们跟大模型交流,最好的比喻,就是用一个 U 盘和它沟通。
这个 U 盘的大小是固定的(比如 8K、128K、200 万 Token 等等,不同模型不一样)。
- 你写给它的每一句话,都要占用这个 U 盘的空间。
- 它写回给你的每一句话,同样要占用这个 U 盘的空间。
- 你们之间所有的对话内容,全都必须装在这一个 U 盘里。
这个 U 盘,就是"上下文窗口(Context Window)"。
4.2 最反直觉的一点:AI 没有记忆
这里有一个必须彻底讲清楚的概念:
模型本身是没有记忆的。它不会"记得"你昨天说过什么,甚至不会"记得"你这轮对话上一句说了什么。
那为什么它看起来能"记住"对话呢?
秘密在于:每一次你发消息,系统都会把之前的整段对话历史,重新完整地塞进 U 盘,一起发给模型。
也就是说,模型看起来的"记忆",其实是每次都把聊天记录重新读一遍。它没有大脑里的记忆,只有 U 盘里的这份"卷宗"。
所以真正的结论是:
所有的会话,都止步于当前这一次请求所提供的内容。模型的"世界",就是这一次塞进 U 盘里的全部文字,仅此而已。
4.3 U 盘会被撑爆
既然 U 盘大小固定,而每轮对话都要把历史全部重塞一遍,那么聊得越久,U 盘就越满。
- 聊到一定程度,U 盘满了,就会报错:"超出上下文长度",对话没法继续。
- 有些系统会自动帮你"压缩"上下文,比如把前面聊过的内容总结成摘要,腾出空间。但压缩就意味着信息丢失------它可能就忘了你前面提过的某个细节。
这就是为什么早期做 AI 应用开发时,经常会遇到"上下文爆炸"的问题,需要手动清理上下文、开新会话,才能让它恢复正常工作。
而且这里还有一个更微妙的问题:U 盘塞太满,不只是会报错,还会让模型"变笨"。 当有效信息淹没在一大堆无关的历史对话里时,模型很难再抓住重点,推理质量会明显下降。就像一个人桌上堆满了杂乱的资料,反而找不到真正要用的那张纸。所以"上下文不是越多越好",精准、干净的上下文,往往比又长又杂的上下文效果好得多。
第五部分:我的输入,如何决定我的输出?(提示词工程)
现在我们把前面所有的点串起来,回答那个最实用的问题:为什么我的输入会严重影响输出?
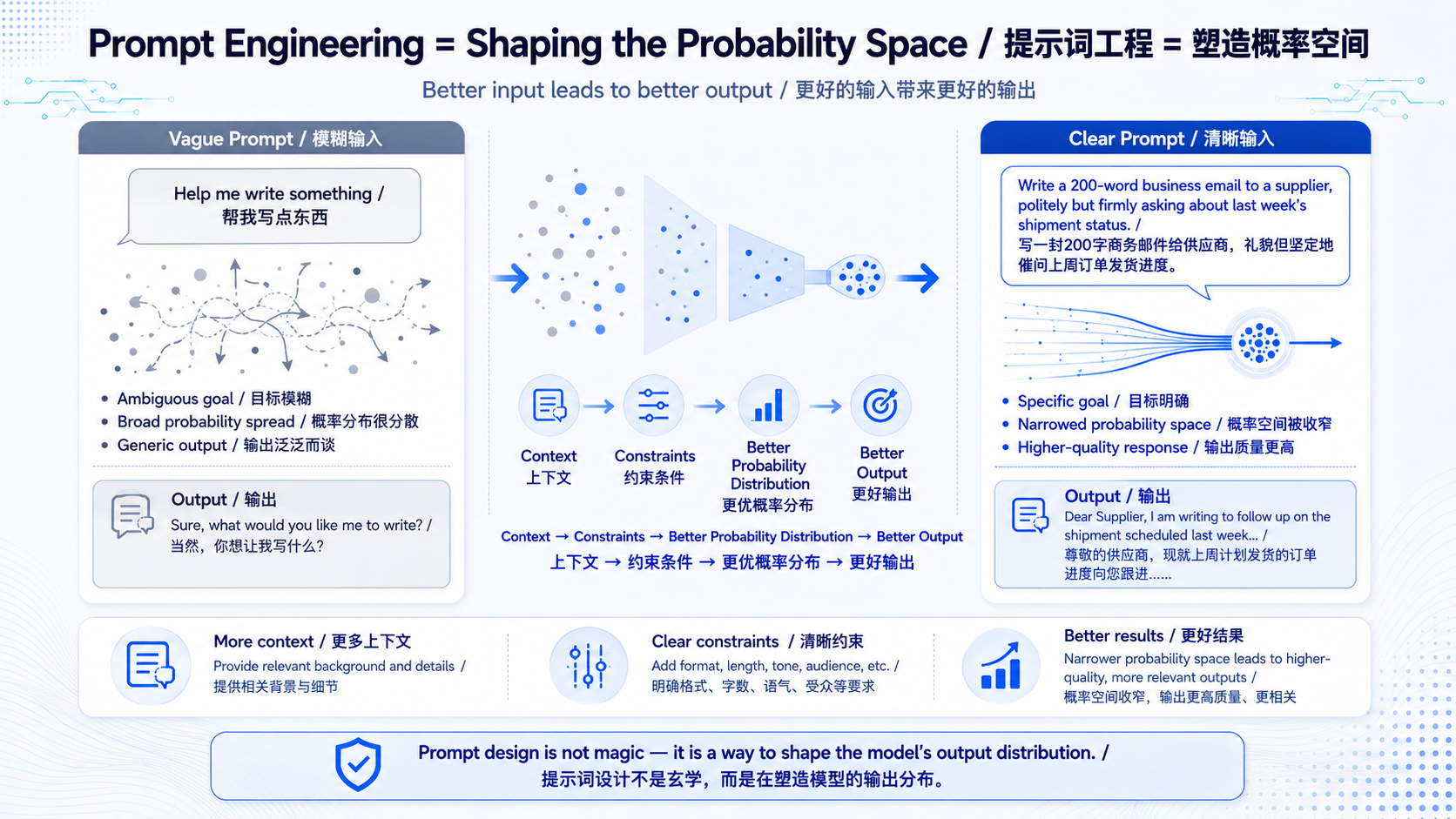
回顾一下机制:模型是根据你给的 Token,算出一张概率表,再抽签选出下一个词。那么------你给的 Token 是什么,直接决定了这张概率表长什么样。
这意味着:
你的输入,就是在为模型"设定舞台"。 你给的每一个词,都会改变后续每一个词的概率分布。
我们来看两个极端:
情况一:模糊的输入。 比如你只说"帮我写点东西"。模型面对这么模糊的输入,它算出的概率表是极度分散的------因为"点东西"可能是任何东西。这时候它只能给你一个最安全、最平庸、最泛泛的回答。这就是大家常说的 AI "偷懒"或者"发散"。其实它没偷懒,是你没给它足够的信息去收窄那张概率表。
情况二:清晰的输入。 比如你说"帮我写一封 200 字的商务邮件,对象是供应商,目的是催促上周订单的发货进度,语气要礼貌但坚定"。这么多限定词,每一个都在大幅收窄模型的概率分布,把它一步步"逼"向你真正想要的那个答案空间。输出质量自然天差地别。
所以,提示词工程的本质,就是:通过精心设计你放进上下文里的文字,来引导模型的概率分布,从而稳定地拿到高质量的输出。
它不是什么玄学咒语,而是基于我们前面讲的整套机制的必然结果:
- 因为模型是概率推理 → 所以清晰的约束能收窄概率、提升质量;
- 因为模型只有上下文、没有记忆 → 所以你必须在这一次输入里,把它需要的所有信息都给全;
- 因为上下文空间有限 → 所以你要写得精准,别塞垃圾。
结尾:三句话总结
如果今天大家只能记住三句话,我希望是这三句:
第一,模型是"石化"的。 训练完成后能力就固定了,它不会进化、不会记忆、也不会自己调用任何程序,本质只是"文字进,文字出"。
第二,它靠概率抽签。 同样的输入之所以有不同输出,是因为它从一张固定的概率表里随机选词,温度控制随机的大小。
第三,上下文就是它的全部世界。 它就像一个大小固定的 U 盘,你们所有的交流都在里面进行。你放进去什么,直接决定它算出什么。所以,想要好的输出,先给出好的输入。
谢谢大家。