基于YOLO26的水下海洋生物检测系统【YOLO26+数据集+Python项目源码+UI界面】
导读
本文基于YOLO26轻量级模型,开发一套面向水下场景的智能海洋生物检测系统。系统聚焦水下目标检测任务,支持10类海洋生物及人类目标识别,涵盖海参、海胆、扇贝、海星、鱼类、珊瑚、潜水员、乌贼、海龟、水母。项目提供PyQt5桌面界面与Flask Web界面双端支持,集成单张图片检测、批量文件夹检测、视频流检测及实时摄像头检测功能,支持检测结果可视化与结构化数据导出,可应用于海洋生态监测、水下作业辅助等场景,兼具检测精度与实时性。
一、软件功能演示
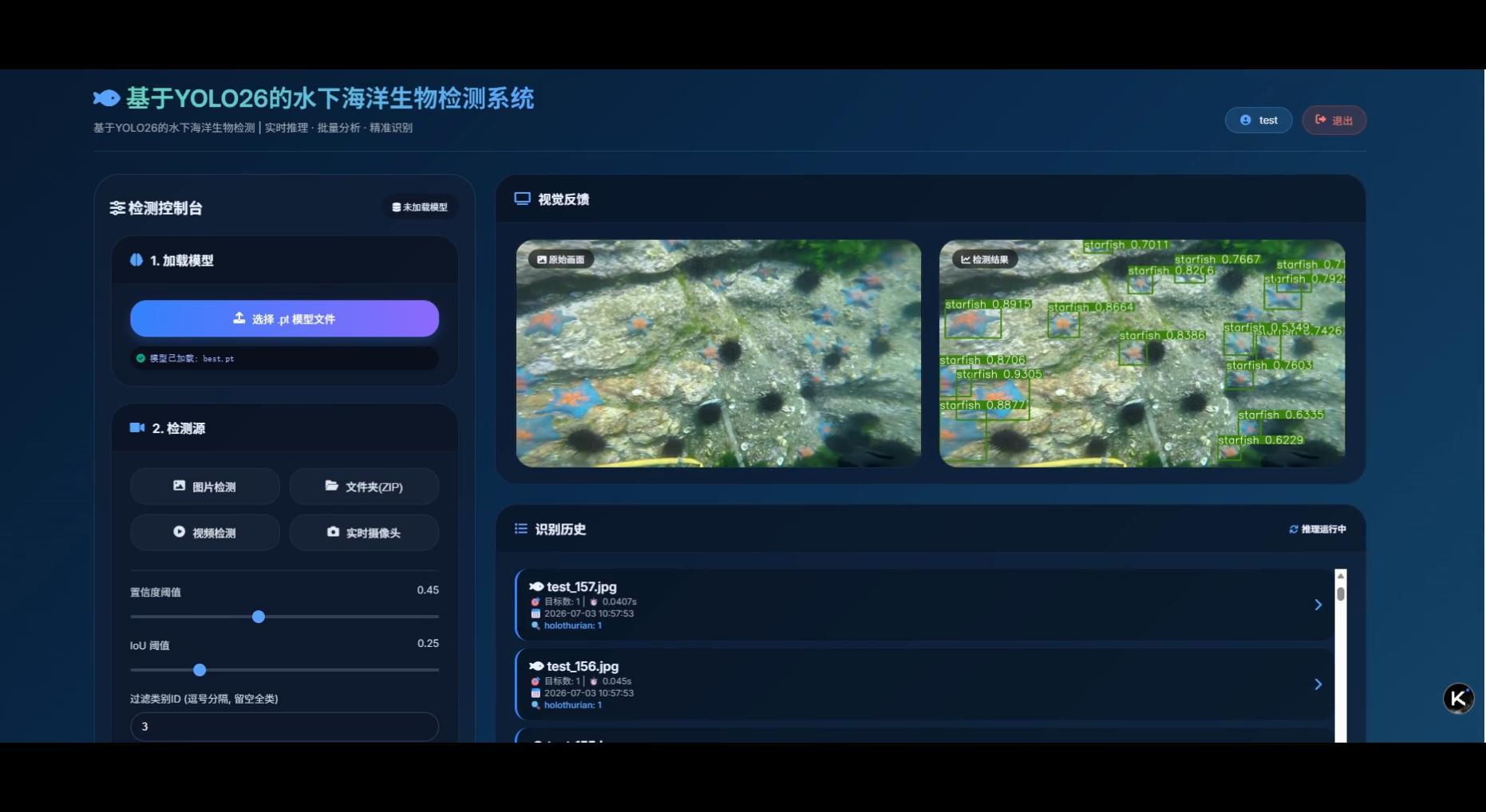
1. 单张、多张图片检测
单张图片检测
通过界面选择单张水下图片,系统自动完成目标检测并在界面展示标注结果,同时生成结构化检测数据统计:
| 序号 | 图片名称 | 检测类型 | 目标类别 | 置信度 | 坐标位置 |
|---|---|---|---|---|---|
| 1 | 000003.jpg | 图片检测 | scallop(扇贝) | 0.89 | (124, 167)-(251, 282) |
| 2 | 000003.jpg | 图片检测 | fish(鱼类) | 0.76 | (302, 114)-(415, 201) |
| 3 | 000003.jpg | 图片检测 | holothurian(海参) | 0.68 | (52, 311)-(147, 405) |
界面支持目标选中查看,点击检测结果列表可查看目标详细坐标信息(Xmin/Ymin/Xmax/Ymax),并支持单张结果图片保存。
文件夹批量检测
选择包含多张水下图片的文件夹,系统自动遍历所有图片完成批量检测,生成汇总统计数据:
- 总检测目标数:24
- 检测类别数:6
- 高频检测目标:fish(8次)、scallop(6次)
同时生成所有图片的检测结果表格,支持导出为CSV文件存档。
2. 视频检测
上传水下作业视频或实时监控视频,系统实时逐帧检测画面中的海洋生物,动态更新检测统计信息:
| 序号 | 画面类型 | 检测类型 | 目标类别 | 置信度 | 坐标位置 |
|---|---|---|---|---|---|
| 1 | 实时画面 | 视频检测 | diver(潜水员) | 0.92 | (197, 144)-(311, 286) |
| 2 | 实时画面 | 视频检测 | turtle(海龟) | 0.87 | (89, 116)-(225, 281) |
| 3 | 实时画面 | 视频检测 | jellyfish(水母) | 0.79 | (401, 203)-(489, 312) |
界面支持视频暂停/播放控制,可随时截取当前帧检测结果保存。
3. 摄像头实时检测
连接USB摄像头或水下专用摄像头,系统实时采集画面并进行检测,适用于水下作业现场实时监测场景。检测结果与视频检测逻辑一致,支持实时统计更新与画面截图保存。
4. 保存检测图片与信息
系统支持两种结果保存方式:
- 检测图片保存:将标注后的图片保存至指定目录,图片名称保留原文件名并添加"_detected"后缀
- 检测数据保存:将所有检测目标的类别、置信度、坐标等信息导出为CSV文件,格式示例如下:
| 图片名称 | 目标类别 | 置信度 | Xmin | Ymin | Xmax | Ymax |
|---|---|---|---|---|---|---|
| 000003.jpg | scallop(扇贝) | 0.89 | 124 | 167 | 251 | 282 |
| 000003.jpg | fish(鱼类) | 0.76 | 302 | 114 | 415 | 201 |
| 000060.jpg | diver(潜水员) | 0.91 | 50 | 89 | 187 | 320 |
二、环境搭建
本文提供两种环境搭建方式,可根据自身需求选择:
1. 通用pip安装教程
适用于大多数Python环境,通过项目提供的requirements.txt一键安装所有依赖:
bash
# 切换至项目根目录
cd "05 Underwater sea creature detection"
# 安装依赖库
pip install -r requirements.txt2. Conda环境安装教程
适用于Anaconda/Miniconda环境用户,可通过配置文件创建独立环境:
bash
# 假设项目提供environment.yml文件(若未提供可自行基于requirements.txt生成)
conda env create -f environment.yml
# 激活环境
conda activate yolo26-underwater注意:若使用NVIDIA GPU加速,需确保已安装对应版本的CUDA与cuDNN,PyTorch会自动适配GPU环境;无GPU设备可使用CPU运行,但检测速度会有所降低。
三、模型训练、评估、预测
1. 数据集准备
数据集基本信息
本项目使用的水下海洋生物数据集包含10类目标,总计约12000张标注图片,采用VOC XML格式标注,数据集按8:1:1比例划分为训练集、验证集和测试集。
格式转换(XML转YOLO格式)
使用xml2txt.py将VOC XML标注转换为YOLO所需的TXT格式:
python
import os
import xml.etree.ElementTree as ET
# 定义类别顺序(需与dataset.yaml一致)
categories = ['holothurian', 'echinus', 'scallop', 'starfish', 'fish',
'corals', 'diver', 'cuttlefish', 'turtle', 'jellyfish']
category_to_index = {category: index for index, category in enumerate(categories)}
# 定义输入输出路径
input_folder = r'./VOCData/VOdevkit/Annotations' # XML标注文件夹
output_folder = r'./VOCData/VOdevkit/labels' # 输出TXT文件夹
os.makedirs(output_folder, exist_ok=True)
for filename in os.listdir(input_folder):
if filename.endswith('.xml'):
xml_path = os.path.join(input_folder, filename)
tree = ET.parse(xml_path)
root = tree.getroot()
# 获取图片尺寸
size = root.find('size')
width = int(size.find('width').text)
height = int(size.find('height').text)
objects = []
for obj in root.findall('object'):
name = obj.find('name').text
if name not in category_to_index:
continue
# 获取边界框坐标
bndbox = obj.find('bndbox')
xmin = int(bndbox.find('xmin').text)
ymin = int(bndbox.find('ymin').text)
xmax = int(bndbox.find('xmax').text)
ymax = int(bndbox.find('ymax').text)
# 转换为YOLO格式(归一化中心点坐标+宽高)
x_center = (xmin + xmax) / 2.0 / width
y_center = (ymin + ymax) / 2.0 / height
w = (xmax - xmin) / width
h = (ymax - ymin) / height
objects.append(f"{category_to_index[name]} {x_center:.6f} {y_center:.6f} {w:.6f} {h:.6f}")
# 保存TXT文件
txt_filename = os.path.splitext(filename)[0] + '.txt'
txt_path = os.path.join(output_folder, txt_filename)
with open(txt_path, 'w') as f:
f.write('\n'.join(objects))
print("XML转YOLO格式完成!")数据集划分
使用SplitDataset.py将原始数据集划分为训练集、验证集和测试集:
python
import os
import shutil
import random
def split_data(file_path, label_path, new_file_path, train_rate=0.8, val_rate=0.1, test_rate=0.1):
# 匹配图片与标签文件
images = os.listdir(file_path)
labels = os.listdir(label_path)
images_no_ext = {os.path.splitext(img)[0]: img for img in images}
labels_no_ext = {os.path.splitext(lbl)[0]: lbl for lbl in labels}
# 检查匹配情况
matched_data = []
for name in images_no_ext:
if name in labels_no_ext:
matched_data.append((name, images_no_ext[name], labels_no_ext[name]))
unmatched_images = [images_no_ext[name] for name in images_no_ext if name not in labels_no_ext]
if unmatched_images:
print("未匹配的图片文件:", unmatched_images)
unmatched_labels = [labels_no_ext[name] for name in labels_no_ext if name not in images_no_ext]
if unmatched_labels:
print("未匹配的标签文件:", unmatched_labels)
# 随机打乱数据
random.shuffle(matched_data)
total = len(matched_data)
# 划分数据集
train_data = matched_data[:int(train_rate*total)]
val_data = matched_data[int(train_rate*total):int((train_rate+val_rate)*total)]
test_data = matched_data[int((train_rate+val_rate)*total):]
# 创建目录并复制文件
def copy_files(data_set, set_name):
img_dir = os.path.join(new_file_path, set_name, 'images')
lbl_dir = os.path.join(new_file_path, set_name, 'labels')
os.makedirs(img_dir, exist_ok=True)
os.makedirs(lbl_dir, exist_ok=True)
for name, img_file, lbl_file in data_set:
shutil.copy(os.path.join(file_path, img_file), os.path.join(img_dir, img_file))
shutil.copy(os.path.join(label_path, lbl_file), os.path.join(lbl_dir, lbl_file))
copy_files(train_data, 'train')
copy_files(val_data, 'val')
copy_files(test_data, 'test')
print(f"数据集划分完成:训练集{len(train_data)}张,验证集{len(val_data)}张,测试集{len(test_data)}张")
if __name__ == '__main__':
file_path = r'./VOCData/VOdevkit/images' # 原始图片文件夹
label_path = r'./VOCData/VOdevkit/labels' # 转换后的TXT标签文件夹
new_file_path = r'./VOCData/VOdevkit' # 划分后数据集保存路径
split_data(file_path, label_path, new_file_path)数据集配置文件
编辑VOCData/VOdevkit/dataset.yaml,配置数据集路径与类别信息:
yaml
# 数据集根目录(可改为绝对路径)
path: ./VOCData/VOdevkit
# 训练/验证/测试集路径(相对path)
train: train/images
val: val/images
test: test/images
# 类别总数
nc: 10
# 类别名称(顺序需与转换脚本一致)
names:
0: holothurian
1: echinus
2: scallop
3: starfish
4: fish
5: corals
6: diver
7: cuttlefish
8: turtle
9: jellyfish2. 模型训练
使用train.py启动YOLO26模型训练:
python
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 加载YOLO26n预训练模型
model = YOLO('yolo26n.pt')
# 启动训练
results = model.train(
data=r'./VOCData/VOdevkit/dataset.yaml', # 数据集配置文件路径
epochs=100, # 训练轮次
batch=16, # 批量大小(根据GPU显存调整)
imgsz=640, # 训练图像尺寸
workers=8, # 数据加载线程数
device=0, # GPU设备编号,无GPU则改为'cpu'
optimizer='AdamW', # 优化器选择
amp=True, # 开启自动混合精度训练
cache=True # 缓存数据集(加速训练)
)启动训练命令:
bash
python train.py训练过程中,系统会实时输出损失值、精度等指标,训练日志与结果文件会保存至runs/detect/train目录。
3. 训练结果评估
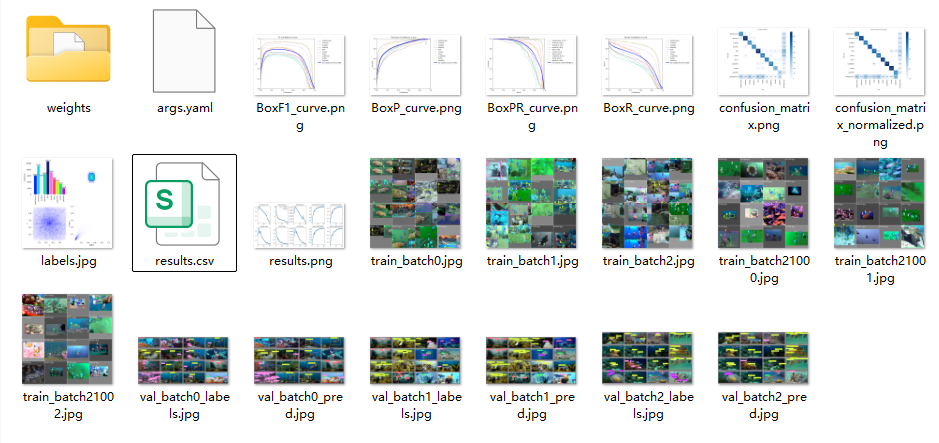
训练完成后,所有结果文件保存在runs/detect/train目录下,关键文件说明:
| 文件名称 | 用途说明 |
|---|---|
| weights/best.pt | 验证集精度最优的模型权重(推荐使用) |
| weights/last.pt | 最后一轮训练的模型权重 |
| results.csv | 训练过程中所有指标的数值记录(可用于绘制训练曲线) |
| results.png | 训练损失曲线、精度曲线可视化图 |
| confusion_matrix.png | 混淆矩阵可视化,展示各类别检测的正误情况 |
| BoxPR_curve.png | PR曲线,展示不同置信度下的精度-召回率关系 |
| labels.jpg | 数据集标签分布统计,展示各类别样本数量 |
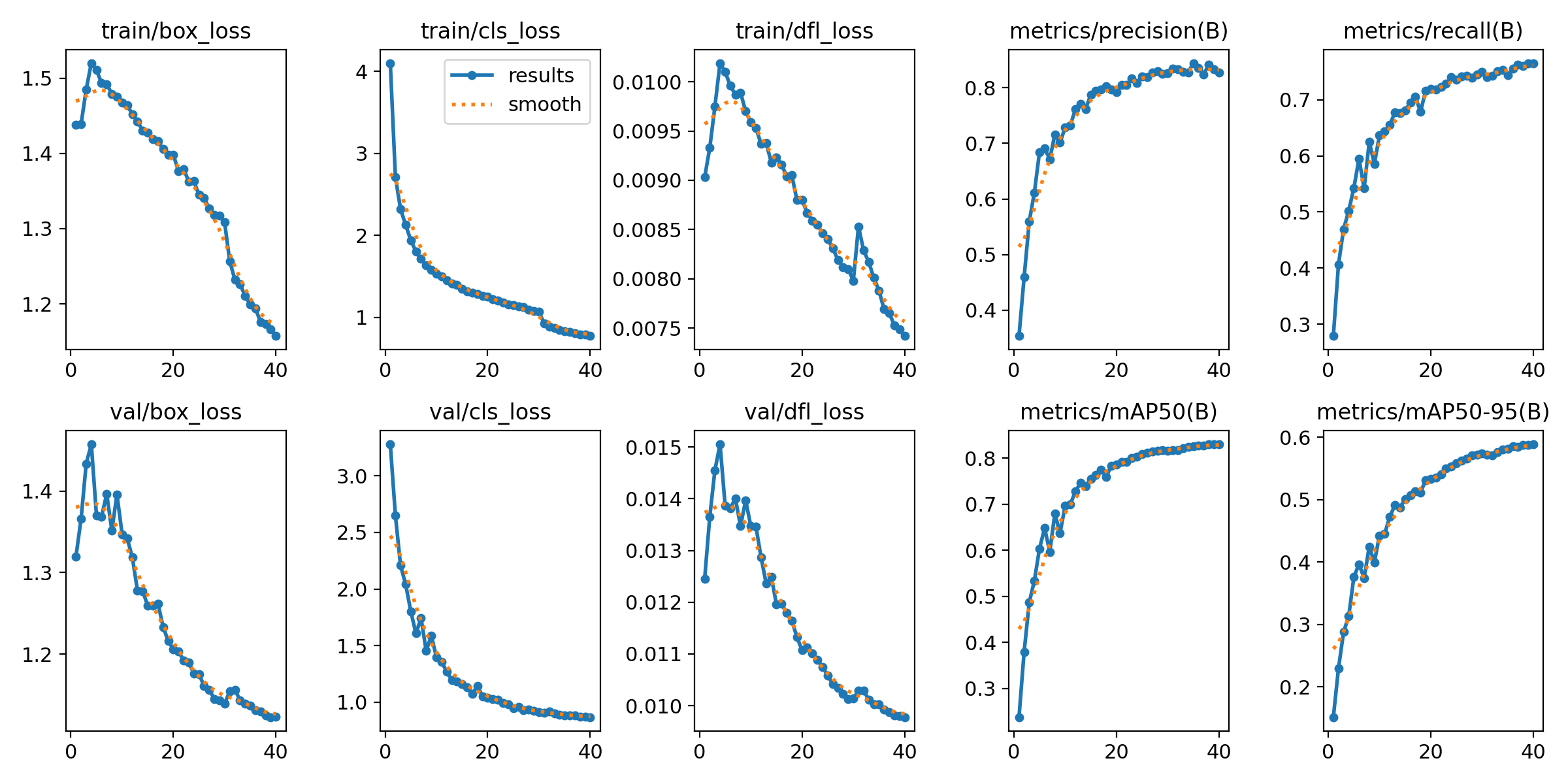

使用val.py进行模型验证,获取详细评估指标:
python
from ultralytics import YOLO
import numpy as np
from datetime import datetime
# 加载最优模型权重
model = YOLO(r"./runs/detect/train/weights/best.pt")
# 在验证集上评估模型
metrics = model.val(data=r"./VOCData/VOdevkit/dataset.yaml")
# 计算平均精度与召回率
mean_p = np.mean(metrics.box.p)
mean_r = np.mean(metrics.box.r)
# 保存评估结果
content = []
content.append("="*60)
content.append(f"验证时间:{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
content.append("="*60)
content.append(f"整体 mAP50: {metrics.box.map50:.4f}")
content.append(f"整体 mAP50-95: {metrics.box.map:.4f}")
content.append(f"平均 Precision: {mean_p:.4f}")
content.append(f"平均 Recall: {mean_r:.4f}")
content.append("\n各类别详细指标:")
for i, (name, p, r, map50, map) in enumerate(zip(metrics.names, metrics.box.p, metrics.box.r, metrics.box.map50, metrics.box.map)):
content.append(f"类别 {i} ({name}):")
content.append(f" Precision: {p:.4f}")
content.append(f" Recall: {r:.4f}")
content.append(f" mAP50: {map50:.4f}")
content.append(f" mAP50-95: {map:.4f}")
with open("./runs/detect/train/val_results.txt", "w", encoding="utf-8") as f:
f.write("\n".join(content))
print("验证结果已保存至val_results.txt")4. 模型预测
项目支持多场景预测,以下为核心预测方式示例:
单张图片预测
python
from ultralytics import YOLO
import os
# 加载训练好的模型
root = os.getcwd()
model = YOLO(rf'{root}/runs/detect/train/weights/best.pt')
# 单张图片预测
source = r'./img_video/test_imgs/000003.jpg'
results = model.predict(source, save=True, conf=0.5) # conf为置信度阈值
# 显示检测结果
results[0].show()
# 保存检测结果图片
results[0].save(filename=r"./results/000003_detected.jpg")文件夹批量预测
python
# 批量预测文件夹内所有图片
source = r'./img_video/test_imgs'
results = model.predict(source, save=True, conf=0.5, batch=8)视频预测
python
# 视频文件预测
source = r'./img_video/test_MP4.mp4'
results = model.predict(source, save=True, conf=0.5, show=True) # show=True实时显示画面摄像头实时预测
python
# 摄像头实时检测(0为默认摄像头)
source = 0
results = model.predict(source, save=True, conf=0.5, show=True)YOLO26提供n/s/m/l/x多种规模模型,精度与速度权衡关系为:精度x>l>m>s>n,速度n>s>m>l>x,可根据实际场景选择合适模型。
文末互动区
如果您觉得本项目有帮助,欢迎点赞、分享支持!若需要完整项目代码、数据集或有技术问题,欢迎留言交流。