- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
前言
-
数据可视化
- 数据可视化不只是画几张漂亮的图,我认为有几个核心点:
- 单变量分析:只看一个变量,了解它的分布形态。常见工具:直方图、密度图、箱线图。
- 双变量分析:看两个变量之间的关系。常见工具:散点图、折线图、分组箱线图。
- 多变量分析:一次看三个或更多变量的交互。常见工具:气泡图(散点图 + 颜色 + 大小)、热力图、成对关系图。热力图可以把所有数值特征之间的相关性一图打尽,气泡图可以同时观察费用 vs BMI vs 年龄 vs 吸烟四个维度的信息。
- 图表选择的黄金法则:想比较大小 → 柱状图/箱线图;想看趋势 → 折线图;想看关系 → 散点图/热力图;想看分布 → 直方图/小提琴图;想看构成 → 饼图/堆叠柱状图。
- 容易忽视的细节:坐标轴标单位要清晰、颜色对比、异常值要明确标注还是裁剪、样本量大时要用透明度避免重叠遮挡。
- 数据可视化不只是画几张漂亮的图,我认为有几个核心点:
代码实现
本地读取并加载数据
-
数据分析思路:
- 本次数据是表格数据(
medical_cost_prediction_dataset.csv),共 5000 行 × 20 列,包含 19 项特征和 1 个回归目标(annual_medical_cost,年度医疗费用)。各字段说明如下:age:年龄(18~89)gender:性别(Male / Female)bmi:身体质量指数(6.4~43.6)smoker:是否吸烟(Yes / No)diabetes:是否患有糖尿病(0 / 1)hypertension:是否患有高血压(0 / 1)heart_disease:是否患有心脏病(0 / 1)asthma:是否患有哮喘(0 / 1)physical_activity_level:身体活动水平(Low / Medium / High)daily_steps:每日步数(1004~14999)sleep_hours:睡眠时长(4.0~9.0 小时)stress_level:压力水平(1~10)doctor_visits_per_year:年均就诊次数(0~14)hospital_admissions:住院次数(0~6)medication_count:用药数量(0~7)insurance_type:保险类型(Private / Government / None,含 1048 条缺失值)insurance_coverage_pct:保险覆盖比例(0%~94%)city_type:城市类型(Urban / Semi-Urban / Rural)previous_year_cost:上一年度医疗费用(500~19996 元)annual_medical_cost:目标变量,年度医疗费用(404.95~44792.10 元,均值 8048.89,偏度 1.68)
- 本次数据是表格数据(
python
import pandas as pd
import torch
import torch.utils.data as data
import matplotlib.pyplot as plt
import seaborn as sns
from torch import nn
from sklearn import metrics
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv('medical_cost_prediction_dataset.csv') # 读取 CSV 文件
df.head(5)
探索性数据分析
热力图:特征间相关性
- 适用场景:热力图是探索数值特征之间线性关系最直接的工具,适用于所有包含多个数值字段的表格数据。
- 读图方法:
- 颜色越红(正相关)或越蓝(负相关),两个变量的线性关系越强;颜色越接近白色,关系越弱。
- 重点关注最后一行/列(各特征与目标变量
annual_medical_cost的相关性):相关性高的特征往往是模型预测的关键依据。 - 对角线永远是 1(自己和自己完全相关),无需关注。
- 本数据关键发现:
- 大部分特征与目标变量的相关性不强(都在 ±0.1 以内),说明单一特征难以线性预测医疗费用------这正是需要 LSTM 等非线性模型的原因。
- 特征之间没有出现 > 0.9 的极端共线性,暂时不需要删除冗余特征。
python
numeric_cols = df.select_dtypes(include=['int64', 'float64'])
plt.figure(figsize=(12,8))
sns.heatmap(numeric_cols.corr(), cmap='coolwarm', annot=True)
plt.title("Correlation Heatmap")
plt.show()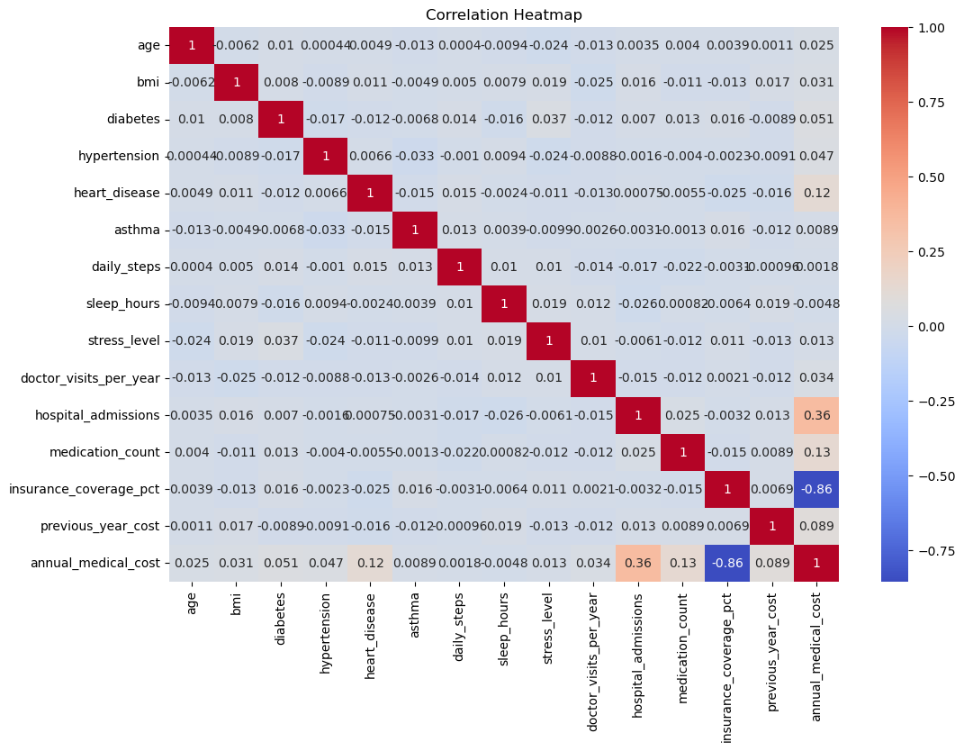
箱线图与小提琴图:分类特征与目标变量的关系
- 适用场景:
- 箱线图:适合快速对比多个组别的中位数、四分位数和异常值。当类别较多(5 个以上)时,箱线图比小提琴图更紧凑、更易读。
- 小提琴图:在箱线图基础上增加了数据分布的密度曲线------"胖"的地方数据密集,"瘦"的地方数据稀疏。适合发现数据是否存在多峰分布。
- 读图方法:
- 箱线图中间横线是中位数,盒子上下边是 Q1 和 Q3,须线外的点为异常值(
whis=3表示 3 倍 IQR 外的点视为异常)。 - 小提琴图的宽度代表该位置的数据密度,左右对称是镜像渲染,没有额外含义。
- 箱线图中间横线是中位数,盒子上下边是 Q1 和 Q3,须线外的点为异常值(
- 本数据关键发现:
- 目标变量
annual_medical_cost呈明显的右偏分布:中位数远低于上须线,大量异常值悬浮在高位(少数人费用极高)。 smoker(吸烟)和heart_disease(心脏病)等分类特征对费用有明显分层------吸烟者 / 心脏病患者的费用中位数显著更高。
- 目标变量
python
sns.set(font='SimHei', font_scale=0.8, style="darkgrid") # 解决Seaborn中文显示问题
# 创建matplotlib的fig对象和子图对象ax
fig, ax = plt.subplots(1,3, figsize=(12,4))
# 多个数值变量的箱线图
sns.boxplot(data=df.loc[:, ['annual_medical_cost']], ax=ax[0], whis=3)
ax[0].set_title('多个数值变量')
# 一个数值变量多个分组的箱线图
sns.boxplot(x=df["hospital_admissions"], y=df["annual_medical_cost"], ax=ax[1], whis=3)
ax[1].set_title('一个数值变量多个分组')
# 一个数值变量多个分组子分组的箱线图
sns.boxplot(x="hospital_admissions", y="annual_medical_cost", hue="smoker",
data=df, palette="Set1", width=0.5, ax=ax[2], whis=3)
ax[2].set_title('一个数值变量多个分组/子分组')
# 调整间距并展示
plt.tight_layout()
plt.show()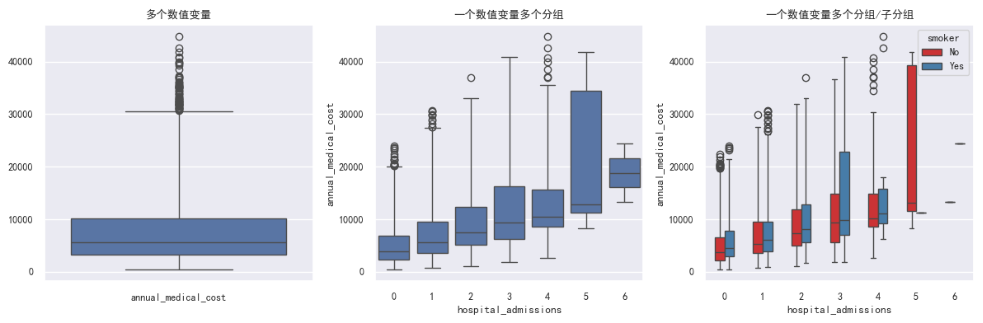
python
sns.set(font='SimHei', font_scale=0.8, style="darkgrid") # 解决Seaborn中文显示问题
# 创建matplotlib的fig对象和子图对象ax
fig, ax = plt.subplots(1,3, figsize=(12,4))
# 多个数值变量的小提琴图
sns.violinplot(data=df.loc[:, ['annual_medical_cost']], ax=ax[0])
ax[0].set_title('多个数值变量')
# 一个数值变量多个分组的小提琴图
sns.violinplot(x=df["heart_disease"], y=df["annual_medical_cost"], ax=ax[1])
ax[1].set_title('一个数值变量多个分组')
# 一个数值变量多个分组子分组的小提琴图
sns.violinplot(x="heart_disease", y="annual_medical_cost", hue="smoker",
data=df, palette="Set1", width=0.5, ax=ax[2])
ax[2].set_title('一个数值变量多个分组/子分组')
# 调整间距并展示
plt.tight_layout()
plt.show()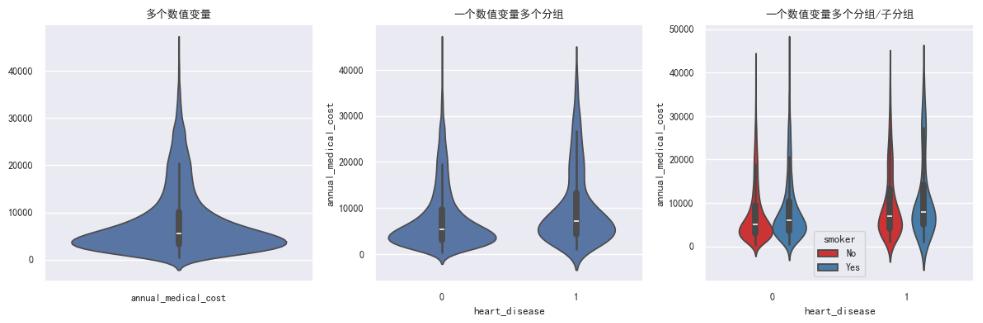
热力图一些字段深度探索
python
# 选取热力图中值得关注的特征:smoker, diabetes, hypertension, asthma, physical_activity_level
sns.set(font='SimHei', font_scale=0.85, style="darkgrid")
fig, axes = plt.subplots(2, 3, figsize=(16, 10))
# 1. smoker ------ 吸烟是医疗费用的最强预测因素之一
sns.boxplot(x='smoker', y='annual_medical_cost', data=df, palette='Set2', ax=axes[0, 0])
axes[0, 0].set_title('吸烟 vs 年度医疗费用')
axes[0, 0].set_xlabel('是否吸烟')
axes[0, 0].set_ylabel('医疗费用(元)')
# 2. diabetes ------ 糖尿病对费用的影响
sns.boxplot(x='diabetes', y='annual_medical_cost', data=df, palette='Set2', ax=axes[0, 1])
axes[0, 1].set_title('糖尿病 vs 年度医疗费用')
axes[0, 1].set_xlabel('是否糖尿病')
axes[0, 1].set_ylabel('医疗费用(元)')
# 3. hypertension ------ 高血压与医疗支出
sns.violinplot(x='hypertension', y='annual_medical_cost', data=df, palette='Set3', ax=axes[0, 2])
axes[0, 2].set_title('高血压 vs 年度医疗费用')
axes[0, 2].set_xlabel('是否高血压')
axes[0, 2].set_ylabel('医疗费用(元)')
# 4. asthma ------ 哮喘的影响
sns.boxplot(x='asthma', y='annual_medical_cost', data=df, palette='Set2', ax=axes[1, 0])
axes[1, 0].set_title('哮喘 vs 年度医疗费用')
axes[1, 0].set_xlabel('是否哮喘')
axes[1, 0].set_ylabel('医疗费用(元)')
# 5. physical_activity_level ------ 运动水平分组
sns.boxplot(x='physical_activity_level', y='annual_medical_cost', data=df,
order=['Low', 'Medium', 'High'], palette='Set3', ax=axes[1, 1])
axes[1, 1].set_title('运动水平 vs 年度医疗费用')
axes[1, 1].set_xlabel('运动水平')
axes[1, 1].set_ylabel('医疗费用(元)')
# 6. city_type ------ 城市类型
sns.violinplot(x='city_type', y='annual_medical_cost', data=df,
order=['Rural', 'Semi-Urban', 'Urban'], palette='Set2', ax=axes[1, 2])
axes[1, 2].set_title('城市类型 vs 年度医疗费用')
axes[1, 2].set_xlabel('城市类型')
axes[1, 2].set_ylabel('医疗费用(元)')
plt.tight_layout()
plt.show()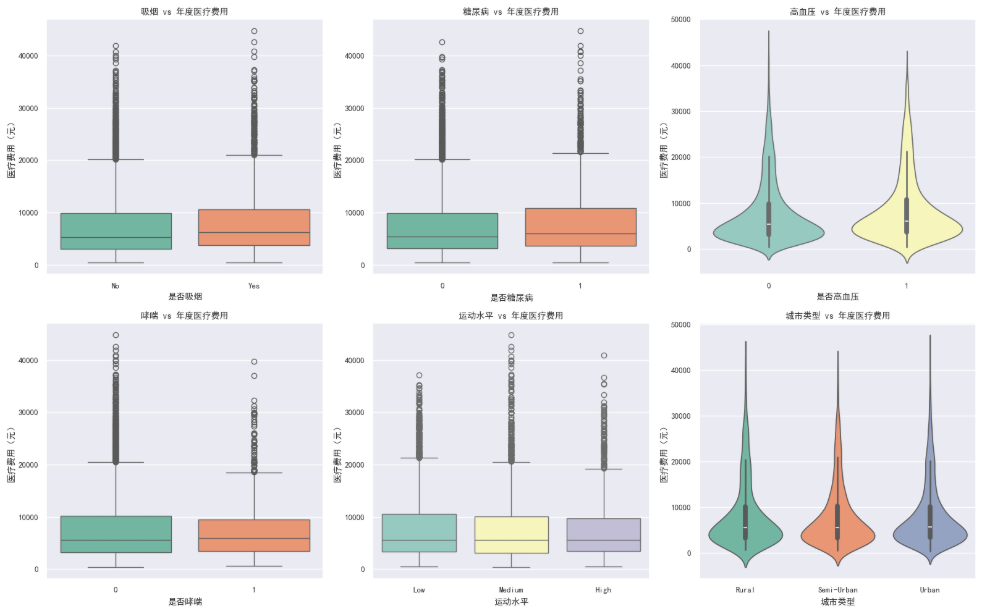
python
# 选取热力图中值得关注的数值特征
sns.set(font='SimHei', font_scale=0.85, style="darkgrid")
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
# 1. age ------ 年龄是最基本的风险因素
sns.regplot(x='age', y='annual_medical_cost', data=df.sample(500),
scatter_kws={'alpha': 0.3, 's': 10}, line_kws={'color': 'red'}, ax=axes[0, 0])
axes[0, 0].set_title('年龄 vs 年度医疗费用(含回归线)')
axes[0, 0].set_xlabel('年龄')
axes[0, 0].set_ylabel('医疗费用(元)')
# 2. bmi ------ 身体质量指数
sns.scatterplot(x='bmi', y='annual_medical_cost', data=df.sample(500),
hue='smoker', alpha=0.5, palette='Set1', ax=axes[0, 1])
axes[0, 1].set_title('BMI vs 年度医疗费用(颜色=吸烟)')
axes[0, 1].set_xlabel('BMI')
axes[0, 1].set_ylabel('医疗费用(元)')
# 3. daily_steps ------ 每日步数反映整体健康习惯
sns.regplot(x='daily_steps', y='annual_medical_cost', data=df.sample(500),
scatter_kws={'alpha': 0.3, 's': 10}, line_kws={'color': 'red'}, ax=axes[0, 2])
axes[0, 2].set_title('每日步数 vs 年度医疗费用(含回归线)')
axes[0, 2].set_xlabel('每日步数')
axes[0, 2].set_ylabel('医疗费用(元)')
# 4. doctor_visits_per_year ------ 就诊次数
sns.boxplot(x='doctor_visits_per_year', y='annual_medical_cost', data=df, ax=axes[1, 0])
axes[1, 0].set_title('年就诊次数 vs 年度医疗费用')
axes[1, 0].set_xlabel('年就诊次数')
axes[1, 0].set_ylabel('医疗费用(元)')
# 5. stress_level ------ 压力水平
sns.boxplot(x='stress_level', y='annual_medical_cost', data=df, palette='coolwarm', ax=axes[1, 1])
axes[1, 1].set_title('压力水平 vs 年度医疗费用')
axes[1, 1].set_xlabel('压力水平(1-10)')
axes[1, 1].set_ylabel('医疗费用(元)')
# 6. medication_count ------ 用药数量
sns.boxplot(x='medication_count', y='annual_medical_cost', data=df, palette='viridis', ax=axes[1, 2])
axes[1, 2].set_title('用药数量 vs 年度医疗费用')
axes[1, 2].set_xlabel('用药数量')
axes[1, 2].set_ylabel('医疗费用(元)')
plt.tight_layout()
plt.show()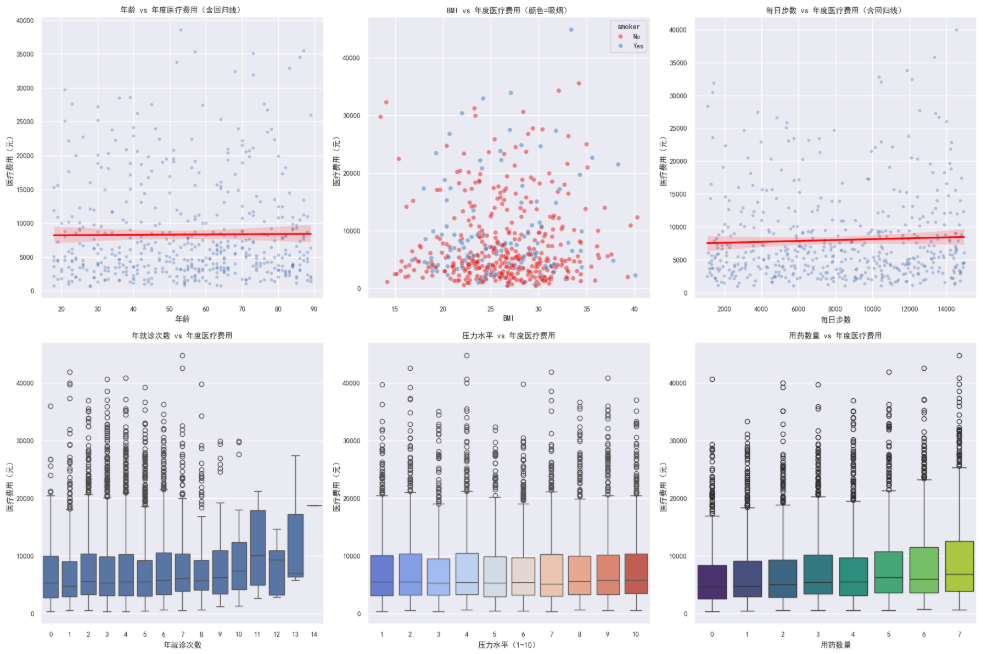
散点图(气泡图):数值特征与目标变量的关系
- 适用场景:散点图用于观察两个连续变量之间的关系,是发现非线性模式、聚类趋势和异常值的最基础工具。气泡图通过将第三维(如
age)映射为气泡大小、第四维(如smoker)映射为颜色,可以在同一张图中展示 4 个维度的信息------这对表格数据的多维探索非常高效。 - 读图方法:
- x 轴和 y 轴是两个数值变量,每个点是一个样本。
- 气泡越大代表第三维值越大;颜色越深/越亮代表类别不同。
- 如果点沿某条斜线聚集,说明两个变量有强相关;如果点分散成团,说明关系弱。
- 本数据关键发现:
previous_year_cost和annual_medical_cost之间呈现出一定的正相关趋势,但非严格的线性关系。- 仅取前 100 条数据绘图可能导致样本偏差。
- 目标变量的极端值(费用极高)在散点图中表现为远离子团的高位孤立点。
python
# 1. 创建3个子图布局
fig, ax = plt.subplots(1, 3, figsize=(12, 4))
# 子图1
sns.scatterplot(
data=df[:100],
x="previous_year_cost", # 第一个数值变量(对应原x轴)
y="annual_medical_cost", # 第二个数值变量(对应原y轴)
size="age", # 气泡大小映射:年龄越大,气泡越大
sizes=(20, 200), # 气泡大小范围(避免过大/过小)
alpha=0.6, # 透明度(避免重叠遮挡)
color="#2E86AB", # 统一气泡颜色(突出大小差异)
ax=ax[0]
)
ax[0].set_title('(气泡大小=年龄)')
ax[0].set_xlabel('上一年费用(元)')
ax[0].set_ylabel('年度医疗费用(元)')
ax[0].legend(title='年龄', bbox_to_anchor=(1.05, 1), loc='upper left') # 图例位置调整
# 子图2
sns.scatterplot(
data=df[:100],
x="bmi", # 分组变量(性别)
y="annual_medical_cost", # 核心数值变量
size="age", # 气泡大小=年龄
sizes=(40, 250),
alpha=0.7,
hue="gender", # 颜色区分性别(增强分组识别)
palette="Set2",
legend=False, # 隐藏重复图例(x轴已体现性别)
ax=ax[1]
)
ax[1].set_title('按bmi分组(气泡大小=年龄)')
ax[1].set_xlabel('bmi')
ax[1].set_ylabel('年度医疗费用(元)')
# 子图3
sns.scatterplot(
data=df[:100],
x="sleep_hours", # 主分组(性别)
y="annual_medical_cost", # 核心数值变量
hue="smoker", # 子分组(吸烟状态)- 颜色区分
size="age", # 气泡大小=年龄(第三维度)
sizes=(40, 300),
alpha=0.7,
palette="Set1", # 子分组颜色(和原代码一致)
ax=ax[2]
)
ax[2].set_title('睡眠时间+吸烟状态(气泡大小=年龄)')
ax[2].set_xlabel('睡眠时间')
ax[2].set_ylabel('年度医疗费用(元)')
ax[2].legend(title='吸烟状态', bbox_to_anchor=(1.05, 1), loc='upper left')
# 调整布局,避免标签重叠
plt.tight_layout()
plt.show()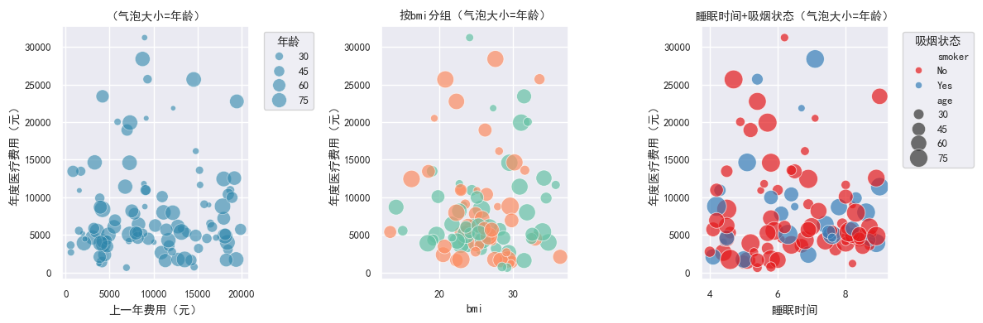
数据预处理
处理缺失值
- 数据探索阶段发现
insurance_type列存在 1048 条缺失值(占比约 21%)。当前处理方式是将缺失值填充为字符串"0",使该列在 OrdinalEncoder 编码时被当作一个独立类别。
python
df.isnull().any() # 检查是否存在缺失值
df["insurance_type"].fillna("0", inplace=True)
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
X = df.iloc[:,:-1]
y = df.iloc[:,-1]编码分类特征
- 共有 5 列 object 类型的分类特征(
gender、smoker、physical_activity_level、insurance_type、city_type)。当前使用OrdinalEncoder(整数编码)将类别转换为整数。 - 整数编码会为类别赋予虚假的大小关系。对于树模型(如随机森林)这种编码方式是可接受的,但对于 LSTM 这类对数值大小敏感的神经网络,One-Hot 编码通常是更好的选择。
python
from sklearn.preprocessing import LabelEncoder,OrdinalEncoder
label_cols = [1, 3, 8, 15, 17] # 需要编码的列索引
oe = OrdinalEncoder()
X.iloc[:, label_cols] = oe.fit_transform(X.iloc[:, label_cols])划分训练集与测试集
python
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 1)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
特征重要性排行
- 使用随机森林回归器对所有特征进行重要性排序,作为特征选择的参考依据。
- 没有尝试但想到的改进方向:
- 如果某些特征的重要性非常低(如接近 0),可以考虑剔除它们以减少噪声、降低模型复杂度。
python
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
feature_importance = pd.DataFrame({
'feature': X_train.columns,
'importance': rf.feature_importances_
}).sort_values('importance', ascending=False)
print("\n前10个重要特征:")
print(feature_importance.head(10))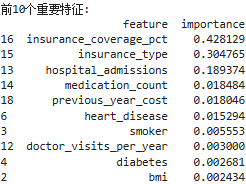
标准化
- 使用
StandardScaler将数值特征标准化为均值为 0、标准差为 1 的分布。
python
from sklearn.preprocessing import StandardScaler
import numpy as np
#将数据归一化,范围是0到1
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
X_train = torch.tensor(X_train, dtype=torch.float32).unsqueeze(1)
X_test = torch.tensor(X_test, dtype=torch.float32).unsqueeze(1)
y_train = torch.tensor(y_train.values, dtype=torch.float32)
y_test = torch.tensor(y_test.values, dtype=torch.float32)
X_train.shape, X_test.shape, y_train.shape, y_test.shape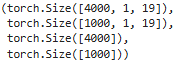
构建 DataLoader
python
from torch.utils.data import DataLoader
batch_size = 32
# 封装数据
train_dataset = data.TensorDataset(X_train, y_train)
test_dataset = data.TensorDataset(X_test, y_test)
# 加载数据
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)#
test_dataloader = DataLoader(test_dataset, batch_size=batch_size) #, shuffle=True构建 LSTM 模型
-
模型结构分析:
-
本次构建的是一个单层单向 LSTM + 一层全连接的回归模型,结构如下:
-
LSTM 层:
nn.LSTM(input_size=19, hidden_size=200, num_layers=1, batch_first=True)。输入为 19 维特征向量,隐藏状态维度为 200,单层 LSTM。batch_first=True让输入张量的形状为(batch, seq_len, input_size)。 -
全连接输出层:
nn.Linear(200, 1),将 LSTM 输出的 200 维隐藏状态映射为 1 个回归值(预测的医疗费用)。
-
-
python
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
python
class model_lstm(nn.Module):
def __init__(self):
super(model_lstm, self).__init__()
self.lstm0 = nn.LSTM(input_size=19 ,hidden_size=200,
num_layers=1, batch_first=True)
self.fc0 = nn.Linear(200, 1)
def forward(self, x):
out, _ = self.lstm0(x)
out = self.fc0(out)
return out
model = model_lstm()
from torchinfo import summary
summary(model, (64, 1, 19))
训练函数
- 训练函数中通过
metrics.r2_score(y_list, pred_list)计算每个 epoch 的 R² 分数。R²(决定系数)衡量模型对目标变量方差的解释比例,越接近 1 表示拟合越好,负值表示模型比简单取均值还要差。
python
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
pred_list = []
y_list =[]
for X, y in dataloader:
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
pred = pred.squeeze()
y_list += [i.detach().numpy() for i in y.cpu()]
pred_list += [i.detach().numpy() for i in pred.cpu()]#
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,y为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
train_loss += loss.item()
R2 = metrics.r2_score(y_list, pred_list) #第一个必须是真实值,第二个必须是预测值,否值 R2 可能会为负数
train_loss /= num_batches
return R2, train_loss测试函数
python
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
test_loss, test_acc = 0, 0
pred_list = []
y_list =[]
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
pred = pred.squeeze()
y_list += [i.detach().numpy() for i in y.cpu()]
pred_list += [i.detach().numpy() for i in pred.cpu()]
loss = loss_fn(pred, y)
test_loss += loss.item()
R2 = metrics.r2_score(y_list, pred_list) #第一个必须是真实值,第二个必须是预测值,否值 R2 可能会为负数
test_loss /= num_batches
return R2, test_loss超参数配置与正式训练
- 关键超参数说明:
- 损失函数:
MSELoss(均方误差),适用于回归任务。 - 优化器:
Adam,自适应学习率优化器,对超参数不敏感,适合快速原型验证。 - 初始学习率:
0.1(配合学习率衰减策略)。 - 学习率衰减:每 5 个 epoch 将学习率乘以 0.92,避免训练后期在最优解附近震荡。
- 训练轮数:50 epochs。
- 损失函数:
python
def adjust_learning_rate(optimizer, epoch, start_lr):
# 每 5 个epoch衰减到原来的 0.92
lr = start_lr * (0.92 ** (epoch // 5))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
learn_rate = 0.1 # 初始学习率
optimizer = torch.optim.Adam(model.parameters(), lr=learn_rate)
python
import torch.nn.functional as F
loss_fn = nn.MSELoss()
epochs = 50
train_loss = []
train_R2 = []
test_loss = []
test_R2 = []
for epoch in range(epochs):
# 更新学习率(使用自定义学习率时使用)
adjust_learning_rate(optimizer, epoch, learn_rate)
model.train()
epoch_train_R2, epoch_train_loss = train(train_dataloader, model, loss_fn, optimizer)
model.eval()
epoch_test_R2, epoch_test_loss = test(test_dataloader, model, loss_fn)
train_R2.append(epoch_train_R2)
train_loss.append(epoch_train_loss)
test_R2.append(epoch_test_R2)
test_loss.append(epoch_test_loss)
# 获取当前的学习率
lr = optimizer.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_R2:{:.3f}, Train_loss:{:.3f}, Test_R2:{:.4f}, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch+1, epoch_train_R2, epoch_train_loss,epoch_test_R2, epoch_test_loss, lr))
print('Done')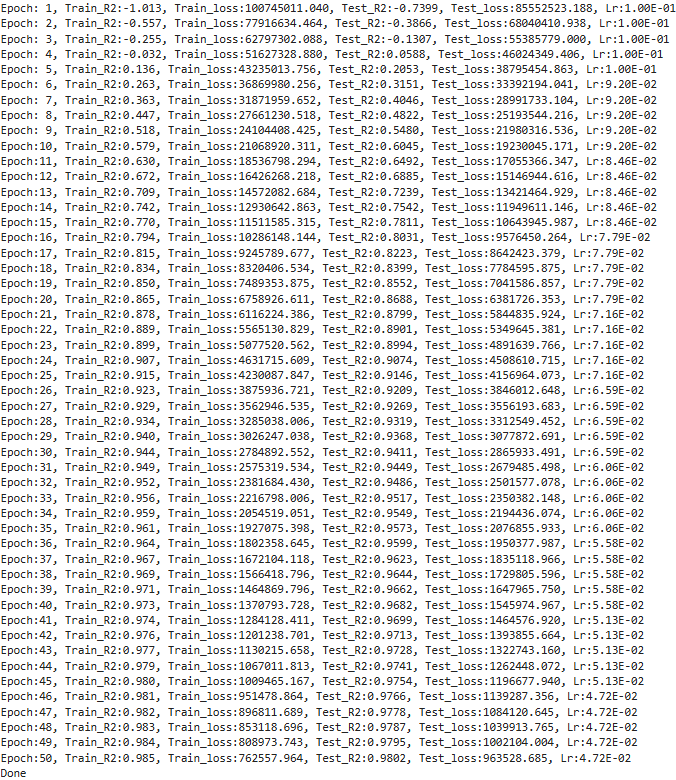
可视化训练结果
python
import matplotlib.pyplot as plt
# 隐藏警告
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
from datetime import datetime
current_time = datetime.now() # 获取当前时间,打卡用
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_R2, label='训练 R²')
plt.plot(epochs_range, test_R2, label='测试 R²')
plt.legend(loc='lower right')
plt.title('训练与验证 R²')
plt.xlabel(current_time)
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='训练损失')
plt.plot(epochs_range, test_loss, label='测试损失')
plt.legend(loc='upper right')
plt.title('训练与验证损失')
plt.show()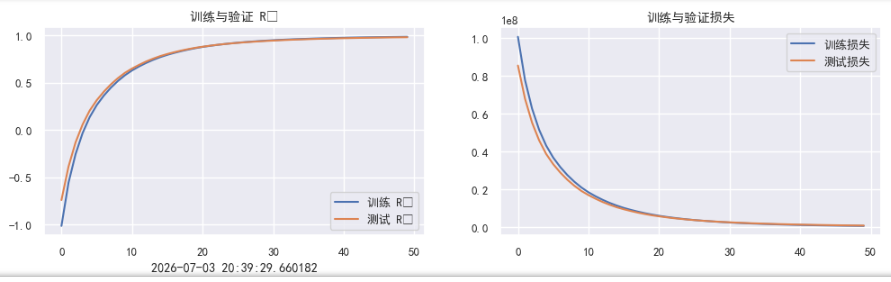
学习总结
- 这周的数据可视化做下来,最直观的感受是画图很重要。先说热力图。第一眼看热力图的时候其实有点失望,因为所有特征和
annual_medical_cost的相关性基本都在 ±0.1 以内,没有哪个特征能一拍即合地"锁定"目标。但反过来想,这恰恰说明了一个问题:如果单靠一个变量就能线性预测医疗费用,那还训练神经网络就没有意义了,正是因为每个特征单独看都不够用,才需要 LSTM 把所有特征揉在一起去学一个非线性的映射。然后是箱线图和小提琴图。这里有两个发现让我印象很深。第一,annual_medical_cost本身的箱线图中位数卡在下面,上面悬浮着一大堆异常值点,典型的右偏分布。这直接解释了为什么偏度高达 1.68。第二,smoker这个字段的分层效果太明显了,吸烟者的费用中位数比不吸烟者高出一大截,小提琴图的密度曲线对非吸烟者是紧贴底部的"矮胖",对吸烟者是往上拉的"高瘦"------几乎不需要统计检验,肉眼就能判断这是个强特征。此外,我挑了 12 个字段分两批画------6 个分类特征和 6 个数值特征,比如doctor_visits_per_year的箱线图------就诊次数从 0 到 14,但费用的增长并不是均匀的,某些区间的中位数跳变特别大。daily_steps的散点图加了回归线后发现斜率接近平的,说明单独靠步数完全预测不了费用,但这个字段和physical_activity_level组合起来可能就不一样了。bmi的散点图用smoker上色之后也很直观:同一 BMI 值下,红点(吸烟者)明显在高位。最后的气泡图虽然只取了 100 条数据可能有点偏差,但思路是对的------一张图同时展示previous_year_cost、age、费用和吸烟四个维度,这就是多维可视化。