01. 当数据研发遇上大模型:瓶颈转移与范式重构
传统 ETL 模式的核心瓶颈在于"人效天花板"与"经验孤岛":需求高度依赖个人经验,难以规模化复用。大模型的引入并未直接消除瓶颈,而是将其转移------准确率成为新红线,知识库成为基础设施,数据消费场景从"给人看报表"延伸至"供 AI 直接调用",协同模式也从串行转向多 Agent 并行。

面对重构生产关系的必然趋势,淘宝直播数据研发团队确立了一条长期主义主线:以工程的确定性,约束大模型的不确定性。 这不是否认 AI 的演进潜力,而是在当前阶段,以可控的工程手段为不可控的模型输出设置护栏。基于此,淘宝直播数据研发团队构建了三层架构:
-
基建层确保 AI"喂得饱"(CDM + 知识库 + 工程平台)
-
AI 能力层确保"管得住"(Skill + SDD + AI Coding)
-
应用层确保"用得好"(多 Agent 协同 + 中心化/本地化 AI Native)

02. 核心技术决策:为何选择 NL2DSL2SQL?
业界多数方案直奔 NL2SQL,但这本质上是在挑战大模型的泛化与后训练能力,过程呈黑盒且难追溯。淘宝直播团队选择了更可控的路径:NL2DSL2SQL 。

在自然语言与 SQL 之间插入 DSL(领域特定语言,以 JSON 结构化描述数据操作),带来三大收益:分段可调试、审计前置、验证成本降低 。当 AI 生成的 DSL 违反平台规范时,系统会精准返回错误位置,触发 报错 → 定位 → AI 自修正 的闭环。这一决策是对"黑盒风险"与"工程可控"的理性权衡:DSL 作为显式中间层,让每个逻辑步骤均可校验、可审计、可迭代。我们将其定义为体系的核心技术锚点------不追求自然语言到SQL的端到端的盲目生成,而是构建可编程、可检测的语义缓冲层。
03. 架构底座:Data Agent 中枢与运行时锚点
整个体系以 DataWorks Data Agent 为基座,向上承载研发、运维、验收等全场景 Skill。为有效抑制"AI 幻觉",团队引入了双重运行时锚点:
-
本体论(Ontology):作为符号层锚点,统一定义实体、关系与属性(如"主播 ID"的全局语义),为 AI 提供无歧义的知识参照系。
-
Harness(运行时管控):作为执行层锚点,负责调度 AI 能力与管理上下文,确保长链路任务中会话信息不丢失、不漂移。
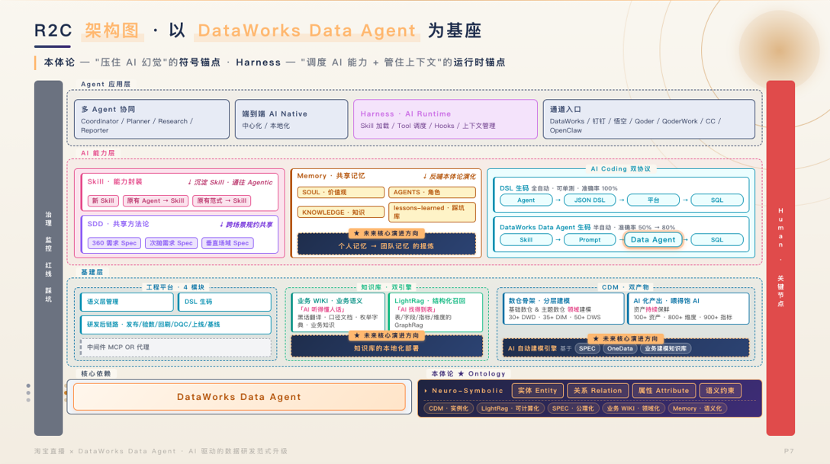
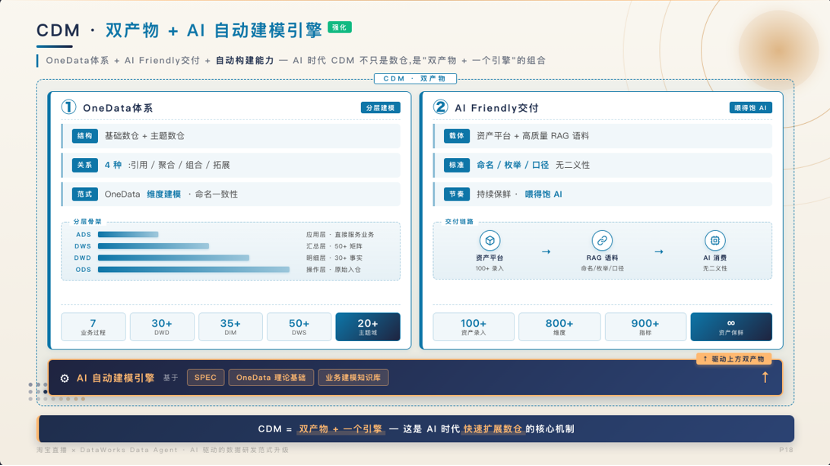
两者协同,本体论解决"AI 应理解什么",Harness 解决"AI 如何正确执行"。在基建层面,我们强调:面向 AI Native 的数据交付绝不能止于"建表"。CDM(公共维度模型)的标准化是基石,表结构、字段注释、枚举值、代码逻辑必须极度精准且持续保鲜,否则 AI 生成的代码将始终伴随概率性偏差。
04. 研发范式重构:全链路标准化与多 Agent 协同
传统数据开发中,编码往往只占极小比例,大量精力消耗在需求澄清与反复对齐。团队将交付流程重构为两大阶段:澄清期 (构建 AI 友好的技术方案,以人工 Check 为主)与执行期(输入完整方案后由 AI 全量驱动,人仅做关键验收)。
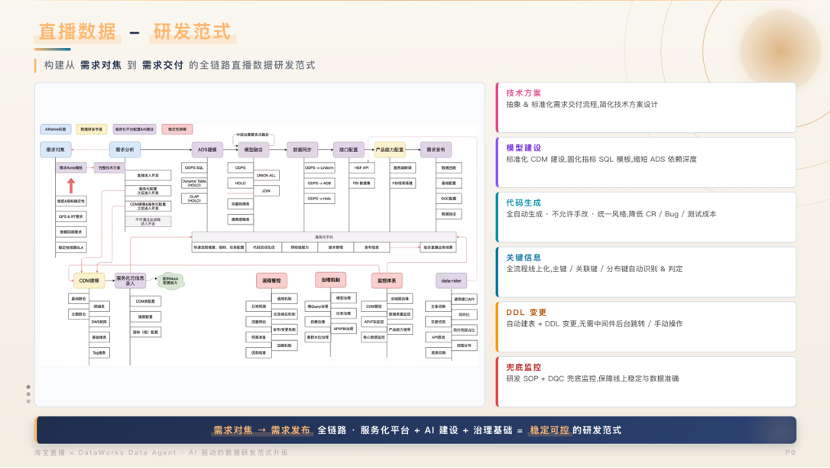
落地层面,研发范式沉淀为六大标准化环节:技术方案抽象简化、模型建设(固化指标 SQL 模板,压平 ADS 依赖)、全自动代码生成(禁止手动编写,统一规范)、关键信息线上化(主键/关联键/分布键自动识别)、自动建表与 DDL 变更(免中间件跳转)、兜底监控(研发 SOP + DQC)。这并非孤立步骤,而是一条从需求对焦到上线交付的自动化流水线。
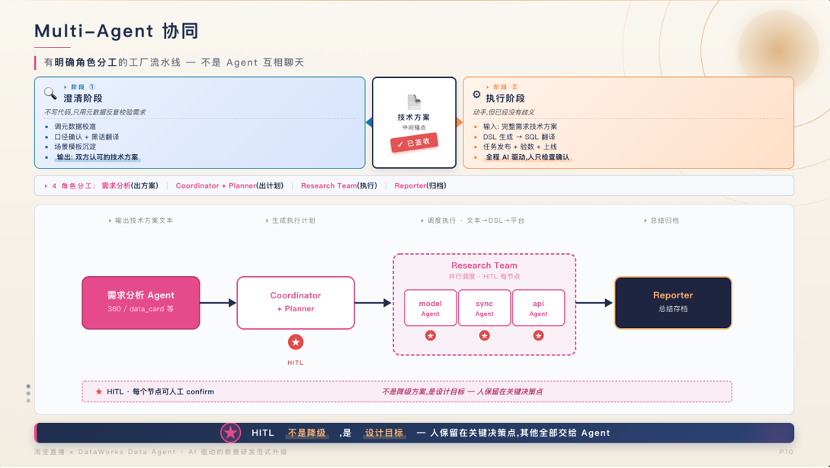
多 Agent 协同并非让 AI"自由对话",而是打造角色明确的"数字工厂":规划 Agent 拆解需求,职能 Agent 执行任务,报告 Agent 汇总输出。我们在关键节点保留人工 Confirm 机制------这不是能力妥协,而是设计原则:人类聚焦高价值决策(数据建模、指标口径、复杂业务翻译),AI 负责高确定性执行。
05. 双轨演进与能力协同:Skill、SDD 与 AI Coding
在中心化 AI Native 跑通后,团队发现其在个性化迭代与记忆隔离上存在瓶颈。自 2026 年起,我们并行推进本地化 AI Native,核心是引入持久化记忆系统。每个本地 Agent 独立沉淀任务记忆与踩坑记录,新需求到来时优先检索历史 Spec,实现从"每日清空的实习生"向"懂业务的老员工"演进。双轨并存:中心化适合标准化与跨团队协作,本地化专注个性化与高频迭代。
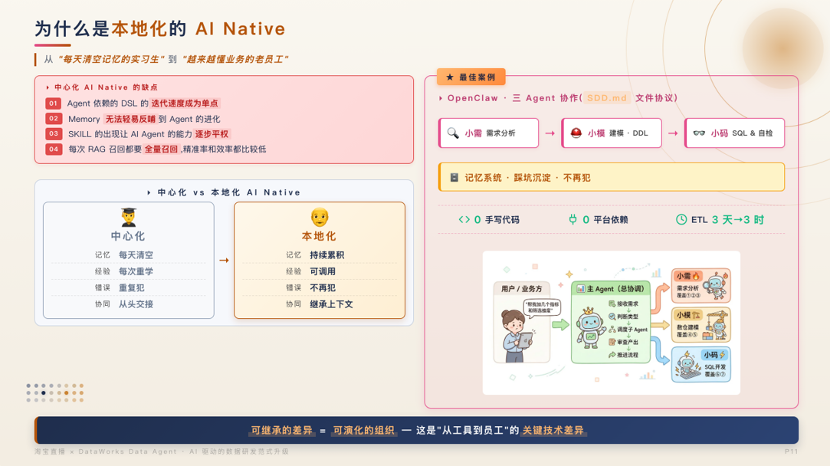
淘宝直播数据研发团队将能力层统一封装为 Skill (源于语义层资产、原生 Agent 转化与范式提炼),实现研发模式零成本复用。

SDD(规范驱动开发) 则是提效关键:每个环节产出标准 Spec 文件,记录需求现状、资源缺口、模型设计与输入输出。它实现上下文不丢失、过程全追溯、Review 前置与模板化执行。我们明确划定 AI 边界:AI 负责上下文管理、过程追溯与模板执行;数据建模决策、指标口径判定与复杂业务翻译,最终责任仍归于人。
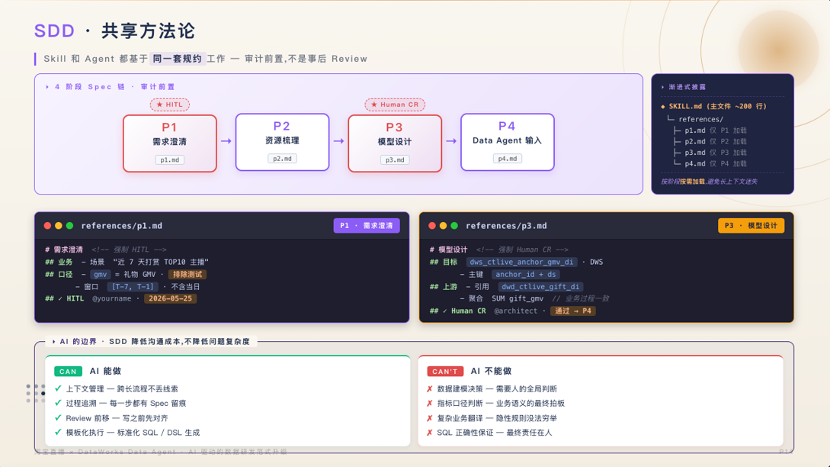
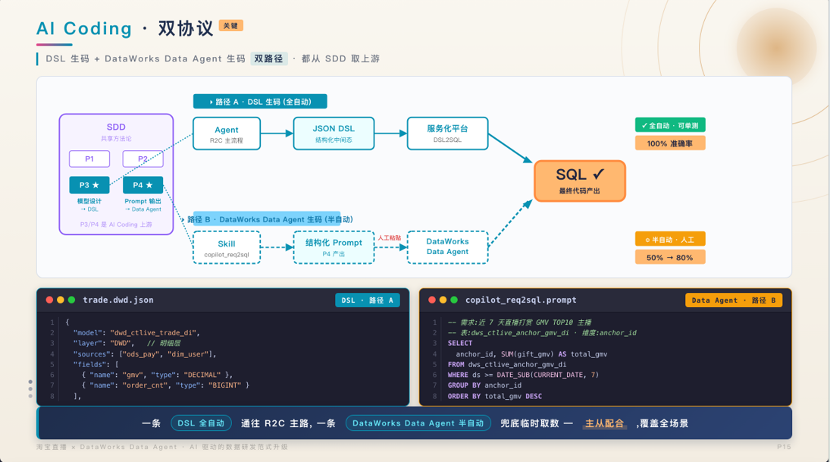
代码生成采用双路径并行:
-
DSL 路径(NL → DSL → SQL):依赖自研语义层,支持单测与工程检测,适合标准化长期需求,承载 70% 以上代码量。
-
DataWorks Data Agent 路径 :弱依赖语义层,仅需数据来源、伪代码与 CTE 参考,适配临时取数、历史任务修改等灵活场景。

双路径互补使代码生成渗透率趋近 100%,在标准化输入下准确率从 50% 跃升至 80%,配合轻量人工修正,实现 24 小时内高质量交付。
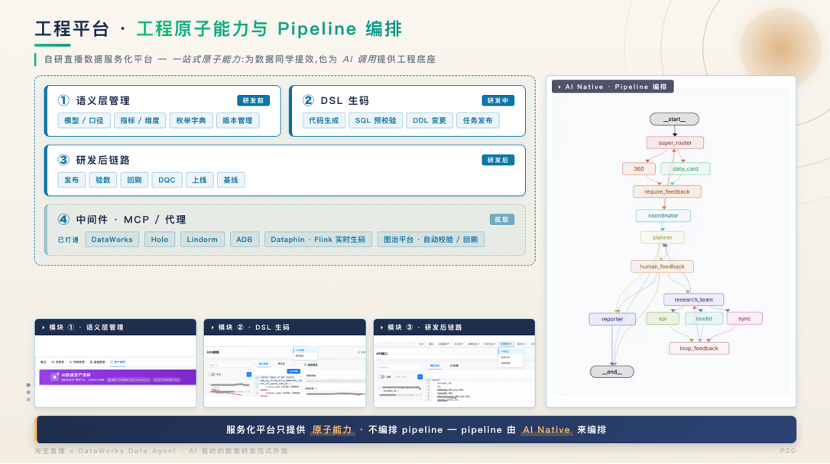
06. 基建基石:OneData、知识双引擎与工程平台
上层能力的稳定运行,依赖三大基建的坚实支撑:

-
OneData 体系 :超越传统数仓分层,强调面向 AI Native 的"精准交付"。表、字段、注释、枚举与代码结构必须高度准确,并建立常态化资产保鲜机制。
-
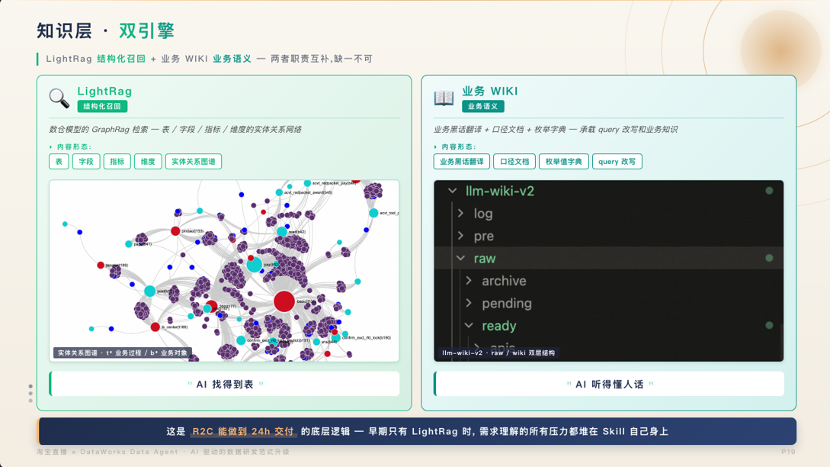
知识双引擎 :LightRAG(基于图结构构建数仓实体关系网络,解决"AI 找得到表")与业务 WIKI(沉淀业务黑话、口径文档、枚举字典,解决"AI 听得懂人话")。两者职责互补,构成完整的语义理解底座。
-
工程平台 :自研直播数据服务化平台,将语义层管理、DSL 校验、Harness 管控等原子能力封装为 API,并通过 AI Native 方式实现动态编排与灵活调用。
07. 未来演进:从 R2C 到 ChatBI,走向数据消费
目前,R2C(Requirement to Code)全链路已高度自动化,代码生成与交付效率实现跃升。但团队判断,下一阶段的战场不在"写代码更快",而在"用数据更智能"。业务方已不再满足于静态报表,而是追问"GMV 为何波动?核心驱动因素是什么?"。
因此,我们将以 ChatBI 为切入点,推动从"数据研发"向"数据消费"的范式延伸------让 AI 不仅替代重复编码,更能直接对话业务、归因分析、辅助决策,最终实现数据价值的实时释放。
